文章目录
- [一、Transformer 架构概述](#一、Transformer 架构概述)
- [二、Transformer 架构设计](#二、Transformer 架构设计)
- 三、编码器(Encoder)
-
- [1. Input Embedding (输入嵌入层)](#1. Input Embedding (输入嵌入层))
- [2. Positional Encoding(位置编码)](#2. Positional Encoding(位置编码))
- [3. Multi-Head Attention(多头注意力机制)](#3. Multi-Head Attention(多头注意力机制))
- [4. Layer Normalization(层归一化)](#4. Layer Normalization(层归一化))
- [5. Residual Connection(残差连接)](#5. Residual Connection(残差连接))
- [6. Feed-Forward Neural Network(前馈神经网络)](#6. Feed-Forward Neural Network(前馈神经网络))
- 四、解码器(Decoder)
-
- [1. Output Embedding(输出嵌入)](#1. Output Embedding(输出嵌入))
- [2. Positional Encoding(位置编码)](#2. Positional Encoding(位置编码))
- [3. Masked Multi-Head Attention(掩码多头注意力机制)](#3. Masked Multi-Head Attention(掩码多头注意力机制))
- [4. Layer Normalization(层归一化)](#4. Layer Normalization(层归一化))
- [5. Residual Connection(残差连接)](#5. Residual Connection(残差连接))
- [6. Multi-Head Attention(多头注意力机制)](#6. Multi-Head Attention(多头注意力机制))
- [7. Feed-Forward Neural Network(前馈神经网络)](#7. Feed-Forward Neural Network(前馈神经网络))
- [8. Output Processing(输出处理层)](#8. Output Processing(输出处理层))
- 五、总结
Transformer是一种由Google研究团队在2017年提出的深度学习模型架构,它彻底颠覆了序列处理模型的范式,完全摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)结构 ,仅依靠自注意力机制(Self-Attention) 来处理序列数据。这种设计使其在处理长序列时具有显著优势,并能够实现高度并行化计算,从而奠定了现代大语言模型(如GPT、BERT)的基础。
一、Transformer 架构概述
Transformer是一种用于自然语言处理(NLP)和其他任务的深度学习模型,由Vaswani等人在2017年的论文《Attention is All You Need》中首次提出。
Transformer 是深度学习领域的阶段性成果或者说是具有里程碑意义的成果,相较于RNN和CNN架构,他有效的解决了以下问题:
- 解决了长距离依赖问题:传统RNN在处理长序列时存在梯度消失/爆炸问题。
- 实现了并行计算:大幅提升训练效率。
- 成为大模型基石:GPT、BERT、LLaMA等所有主流大语言模型都基于Transformer架构。
二、Transformer 架构设计
Transformer的架构核心由编码器(Encoder)和解码器(Decoder)构成:
- 编码器(Encoder):由多个(一般为6个)相同的编码器层(Encoder Layer)堆叠而成。
- 解码器(Decoder):由多个(一般为6个)相同的解码器层(Decoder Layer)堆叠而成。
每个编码器层又包括两个关键的子模块 多头注意力机制(Multi-Head Attention) 和 前馈神经网络(Feed-Forward Neural Network) ,解码器层则在此基础上增加了一个用于编码器-解码器之间交互的多头注意力机制。
此外,模型还使用了 残差连接(Residual Connection) 和 层归一化(Layer Normalization) ,以便加速训练和稳定梯度。
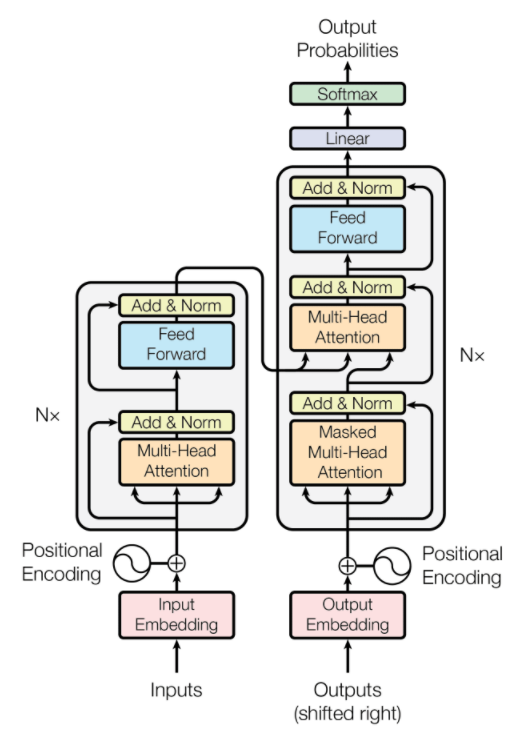
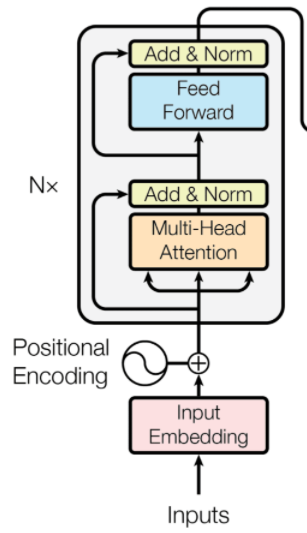
三、编码器(Encoder)
编码器(Encoder)主要构成为 Input Embedding (输入嵌入)、Positional Encoding(位置编码)、 Multi-Head Attention(多头注意力机制)、Layer Normalization(层归一化)、Residual Connection(残差连接)、Feed-Forward Neural Network(前馈神经网络)。
1. Input Embedding (输入嵌入层)
Input Embedding (输入嵌入层)主要作用是将输入的文本语句(Inputs)拆分为词元(Token),再将 Token 转化为大模型能够识别的固定维度的向量。
1.1. Tokenization(词元化)
所谓词元化(Tokenization)就是利用分词算法将输入文本转换为词元(Token),常见的分词方式包括字级、词级、子词级(如BPE、WordPiece)、空格分词等。在 Transformers 中,词元化(Tokenization)实际上包含以下几个步骤:
- 标准化(Normalization):对文本进行必要的清理操作,例如删除多余空格或重音符号、进行 Unicode 标准化等。
- 预分词(Pre-tokenization):将输入拆分为单词。
- 通过模型处理输入(Running the input through the model):使用预分词后的单词生成一系列词元(tokens)。
- 后处理(Post-processing):添加分词器的特殊标记,生成注意力掩码(attention mask)和词元类型 ID(token type IDs)。
常见的分词算法主要分为三大类:基于规则/词典、基于统计/序列标注、基于子词(Subword)。现代大模型(如GPT、BERT)主要使用的是基于子词的算法,以平衡词汇表大小和OOV(未登录词)问题。
| 算法类别 | 算法名称 | 核心原理 | 优点 | 缺点 | 典型应用/代表模型 |
|---|---|---|---|---|---|
| 基于规则/词典 | 最大正向匹配 (FMM) | 从左到右扫描,切出词典中最长的词 | 速度极快,实现简单 | 歧义处理差(如"结合成"可能切错),无法处理未登录词 | 早期中文分词系统、简单工业场景 |
| 最大逆向匹配 (BMM) | 从右到左扫描,切出词典中最长的词 | 切分歧义比FMM略少(汉语中后缀较固定) | 同上,速度略慢于FMM | 早期中文分词系统 | |
| 双向最大匹配 (BiMM) | 同时进行FMM和BMM,根据规则(如词数少)选择结果 | 准确率显著高于单方向匹配 | 需要两次扫描,速度稍慢 | Jieba分词(默认模式) | |
| 基于统计/序列标注 | HMM (隐马尔可夫) | 将分词视为序列标注任务(B/M/E/S),用Viterbi算法解码 | 不需要词典,能识别未登录词(新词) | 依赖标注数据训练,对长上下文依赖捕捉弱 | 早期统计分词工具、NLP基础任务 |
| CRF (条件随机场) | 在HMM基础上引入更多特征(如词性、上下文),全局最优 | 准确率高,特征灵活 | 训练慢,特征工程繁琐 | 中科院NLPIR、哈工大LTP | |
| 感知机/SVM | 将分词看作字的分类问题,利用大量特征训练分类器 | 精准度较高 | 同样需要繁琐的特征工程 | 百度LAC、清华大学THULAC | |
| 基于子词 (Subword) 现代大模型主流 | BPE (Byte-Pair Encoding) | 迭代合并高频相邻字节/字符对,直到达到词表大小 | 极好处理OOV;压缩率高;实现简单 | 可能产生不直观的子词(如"ing");对非拼音文字不友好 | GPT系列、LLaMA、RoBERTa |
| WordPiece | 类似BPE,但合并标准是最大化语言模型似然度(Perplexity下降最多) | 生成的子词更符合语言模型概率;BERT原生 | 合并过程比BPE复杂 | BERT、DistilBERT、Electra | |
| Unigram (SentencePiece) | 假设所有子词独立,通过EM算法裁剪词表,保留高概率子词 | 支持动态采样(同一句有多种切法,增强鲁棒性);不依赖预分词 | 训练成本高;推理时需采样或Viterbi解码 | T5、XLNet、ALBERT | |
| N-gram / Byte-level BPE | 直接在字节(Byte)层面进行BPE合并,而非Unicode字符 | 彻底解决OOV(任何文本都是字节);多语言通用(无需分词器) | 序列长度变长(一个词可能切成很多字节),增加计算量 | GPT-2/3/4(主要使用Byte-level BPE) | |
| 现代神经网络 | BertTokenizer | WordPiece + 子词正则化 + NFKC规范化 | 标准化程度高,生态完善 | 词表固定,无法适应新领域术语 | HuggingFace Transformers库 |
| Segment Anything (SAM) | 主要用于图像,但在文本中指代基于Prompt的切分 | 零样本能力强 | 主要针对视觉,文本应用较少 | Meta SAM (视觉领域) |
什么是 OOV ?其实就是不在词汇表中的词,也称之为:未登录词。
以下是BPE分词器代码示例:
python
from transformers import AutoTokenizer
# 使用 GPT-2 的分词器(BPE)
tokenizer = AutoTokenizer.from_pretrained("gpt2")
text = "Hello,transformer!"
# 编码
# 1. 将文本分词为 Tokens
tokens = tokenizer.tokenize(text)
print("Tokens:", tokens)
# 2. 将 Tokens 转换为 Token IDs
token_ids = tokenizer.convert_tokens_to_ids(tokens)
print("Token IDs:", token_ids)
# 解码
# 1. Token IDs 转换为 Tokens
tokens = tokenizer.convert_ids_to_tokens(token_ids)
print("Tokens:", tokens)
# 2. Tokens 拼接为文本
decoded_text = tokenizer.convert_tokens_to_string(tokens)
print("Decoded Text:", decoded_text)输出结果:
Tokens: ['Hello', ',', 'trans', 'former', '!']
Token IDs: [15496, 11, 7645, 16354, 0]
Tokens: ['Hello', ',', 'trans', 'former', '!']
Decoded Text: Hello,transformer!1.2. Token Embedding(Token向量化)
在对输入完成分词后进行Embedding,通过使用Embedding向量模型将分词结果(单词或子词)转化成为固定维度的向量表示,使其能被模型处理。(因为计算机本身并不能处理文字等信息,需要将其转为向量来处理。)
2026年市场流行的Embedding向量模型
| 模型名称/系列 | 开发机构/来源 | 模型类型 | 核心特点/优势 | 典型应用场景 | 流行度/地位 |
|---|---|---|---|---|---|
| BGE 系列 (BGE-M3, BGE-VL, BGE-Code) | 智源研究院 (BAAI) | 开源通用 | 中文场景首选,支持100+语言,集稠密/稀疏/多向量检索于一体,长文本支持达8192 token。 | RAG、语义搜索、代码检索、多语言任务 | 开源界"事实标准",Hugging Face下载量超6亿次,MTEB/C-MTEB榜单常客。 |
| Qwen3-Embedding (0.6B/4B/8B) | 阿里巴巴 (通义千问) | 开源通用 | 多语言能力极强,支持代码与100+种语言混合检索,支持Matryoshka表示学习(维度可调),MTEB多语言榜单第一。 | 跨语言检索、代码库语义搜索、技术文档问答、电商推荐 | 开源多语言王者,2025年下半年发布后迅速登顶,性能与商业模型媲美。 |
| Gemini Embedding 2 | 商业/多模态 | 原生五模态统一(文本、图像、视频、音频、PDF),上下文窗口达8192 token,支持交错输入。 | 跨模态检索(以图搜文)、视频分析、医疗影像报告、电商商品理解 | 多模态领域的统治者,通过Gemini API提供服务,是构建多模态RAG的首选。 | |
| OpenAI text-embedding-3 | OpenAI | 商业/文本 | 商业级SOTA,与OpenAI生态无缝集成,支持超长上下文(8192 tokens),维度更高(1536/3072),语义细腻。 | 已使用OpenAI服务的企业级RAG、代码搜索、多语言任务 | 商业API的标杆,闭源但效果稳定,是许多企业的"默认选项"。 |
| Jina Embeddings (V2系列) | Jina AI | 开源/商业 | 长文本专家,支持8k token上下文,中英/英德双语优化,API与OpenAI完全兼容,轻量高效。 | 长文档分析(法律/医学)、RAG系统构建、需要低成本替换OpenAI的场景 | RAG开发者的利器,因其长文本能力和OpenAI兼容性而广受欢迎,提供免费额度。 |
| nomic-embed-text v1.5 | Nomic AI | 开源/本地 | Agent记忆优化首选,2048 token上下文,专为本地部署和Agent记忆管理设计,在OpenClaw等框架中表现优异。 | AI Agent记忆系统、本地RAG、对成本和隐私敏感的项目 | Agent和本地部署领域的黑马,在特定场景(如Agent记忆)中被实测为"最优选择"。 |
| ACGE (通用文本向量) | 合合信息 | 开源/商业 | 分类与聚类能力顶尖,C-MTEB中文榜单第一,模型小巧(3.26亿参数),资源效率高。 | 舆情分析、金融文档分类、商品评论情感分析、医疗文本聚类 | 垂直领域(分类/聚类)的冠军,在需要高精度分类的场景下表现超越大型模型。 |
| M3E (多语言、多粒度、多功能) | 阿里巴巴 | 开源/专用 | 电商和中文领域优化,专为中文信息检索设计,在电商商品标题检索、中文问答场景下准确率极高。 | 中文电商搜索、客服系统、企业内部知识库 | 中文垂直场景的佼佼者,尤其在电商和企业应用中效果显著。 |
| LightRetriever | 中科院信工所 & 澜舟科技 | 开源/研究 | 极致非对称架构,查询端计算量降低1000倍,QPS提升10倍以上,检索性能达对称模型的95%。 | 高并发、低延迟的实时检索服务、对推理速度要求极高的场景 | 效率革命者,2026年ICLR接收论文,为高并发检索提供了全新范式。 |
2. Positional Encoding(位置编码)
位置编码(Positional Encoding, PE)是Transformer架构中用于向模型注入序列位置信息的关键机制。它的核心作用是弥补自注意力机制的排列不变性缺陷,让模型能够理解token在序列中的顺序关系。
为什么需要位置编码?
因为自然语言的含义高度依赖词序,例如"我爱你"和"你爱我"的语义完全不同,为了让模型感知到词序,区分不同词序下的不同语义,必须将位置信息注入到词向量中。
位置编码通常直接加(Add)到词嵌入向量(Token Embedding)上,而不是拼接(Concatenate),因为这样不会增加额外的参数量,且计算效率高。
2.1. 原始 Transformer:正弦/余弦位置编码 (Sinusoidal PE)
正弦/余弦位置编码(Sinusoidal Positional Encoding)是2017年Transformer原始论文《Attention Is All You Need》中提出的第一种位置编码方案。它使用不同频率的正弦和余弦函数为序列中每个位置生成唯一的编码向量。
核心公式 :
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d model ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d model ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
- p o s pos pos:词在句子中的位置(0, 1, 2, ...)。
- i i i:向量维度的索引(0 到 d model / 2 d_{\text{model}}/2 dmodel/2)。
- d model d_{\text{model}} dmodel:模型的嵌入维度(如 512, 768, 1024)。
- 100000 100000 100000:波长缩放因子。
优缺点:
- 优点:无需训练参数,计算固定;能自然表达相对位置;外推性较好。
- 缺点:手动设计的,不一定是最优的;在超长文本下,高频部分容易混淆。
2.2. 学习式位置编码 (Learnable PE)
学习式位置编码(Learnable Positional Encoding/Embedding)是一种将位置信息作为可训练参数嵌入到Transformer模型中的技术。与原始Transformer使用的固定正弦/余弦函数不同,学习式位置编码让模型在训练过程中自动学习最优的位置表示。
- 原理 :不使用固定的 Sin/Cos 函数,而是随机初始化一个位置矩阵 W p o s ∈ R L max × d model W_{pos} \in \mathbb{R}^{L_{\max} \times d_{\text{model}}} Wpos∈RLmax×dmodel,其中 L max L_{\max} Lmax 是最大序列长度。在训练过程中,通过反向传播更新这个矩阵,让模型自己"学习"出最适合的位置向量。
- 代表模型 :BERT 、GPT-2(早期版本)。
- 优缺点 :
- 优点:更灵活,模型可以根据数据自动调整,通常在训练数据分布内效果更好。
- 缺点:无法外推。如果训练时最大长度是 512,推理时输入 513 个词,模型没见过第 513 个位置的向量,效果会崩溃。
2.3. 现代大模型的主流:相对位置编码 (Relative PE)
随着模型越来越大(如 LLaMA, GPT-3, PaLM),研究人员发现绝对位置 (第几个词)不如相对位置(两个词相隔多远)重要。绝对位置编码在长文本中会浪费模型容量去记忆"这是第100个位置",而相对位置直接告诉模型"这两个词相邻"。
2.3.1. RoPE (Rotary Positional Embedding) ------当前最主流
- 提出者 :RoFormer (苏剑林),现已被 LLaMA, Qwen, Yi, Mistral 等几乎所有开源大模型采用。
- 核心思想 :旋转 。不再是"加"到词向量上,而是通过旋转矩阵 改变 Query ( Q Q Q) 和 Key ( K K K) 向量的角度。
- 位置 m m m 的向量旋转 m θ m\theta mθ 度。
- 位置 n n n 的向量旋转 n θ n\theta nθ 度。
- 当计算 Q Q Q 和 K K K 的点积(Attention Score)时,旋转的差值 ( m − n ) θ (m-n)\theta (m−n)θ 自然就包含了相对距离信息。
- 公式简化版 :
f ( q , m ) = cos m θ − sin m θ sin m θ cos m θ q 1 q 2 f(q, m) = \begin{bmatrix} \cos m\theta & -\sin m\theta \\ \sin m\theta & \cos m\theta \end{bmatrix} \begin{bmatrix} q_1 \\ q_2 \end{bmatrix} f(q,m)=cosmθsinmθ−sinmθcosmθq1q2 - 优点 :
- 完美保留相对位置信息。
- 具有极好的长度外推性(通过线性插值或 NTK-Aware 方法,可以将 4k 上下文扩展到 32k 甚至 128k)。
- 计算高效,不增加额外参数量。
2.3.2. ALiBi (Attention with Linear Biases)
- 提出者:华盛顿大学 (2021)。
- 核心思想 :惩罚 。在计算 Attention Score 时,直接减去一个与距离成正比的偏置(Bias)。
- S c o r e ( q , k ) = q ⋅ k − α ⋅ ∣ i − j ∣ Score(q, k) = q \cdot k - \alpha \cdot |i - j| Score(q,k)=q⋅k−α⋅∣i−j∣
- 其中 α \alpha α 是一个超参数, ∣ i − j ∣ |i-j| ∣i−j∣ 是两个词的距离。距离越远,分数越低(被屏蔽)。
- 代表模型 :MPT (MosaicML), Vicuna 早期版本。
- 优点:推理速度极快(不需要复杂的旋转计算),外推性极强(训练 1k 长度,推理 10k 长度效果不降反升)。
- 缺点:实现上需要修改 Attention 掩码逻辑,不如 RoPE 通用。
2.3.3. KERPLE / T5 Relative PE
T5相对位置编码(T5 Relative Position Bias)是Google在2019年提出的T5(Text-to-Text Transfer Transformer)模型中引入的一种相对位置编码方案。与传统的绝对位置编码不同,T5将相对距离映射为一个可学习的 Bias 加入到 Attention 中。效果好,但外推性不如 RoPE 和 ALiBi。
3. Multi-Head Attention(多头注意力机制)
多头注意力机制(Multi-Head Attention, MHA)是Transformer架构的核心组件,由Google在2017年《Attention Is All You Need》论文中首次提出。它的核心思想是"分而治之"------通过并行的多个注意力"头",让模型同时从不同子空间捕捉输入序列中多种类型的关联信息。
3.1. 为什么要 "多头" ?
在单头注意力(Single-Head Attention)中,模型计算 Query(Q)、Key(K)和 Value(V)之间的相关性,生成一个加权平均的输出。然而,单头注意力有局限性:
- 平均值陷阱:如果一个词同时需要关注"语法主语"和"语义指代对象",单头注意力往往只能产生一个"平均"的关注点,无法同时清晰地捕捉两种不同类型的关系。
- 子空间限制:单一的线性变换将 Q、K、V 投影到同一个空间,限制了模型捕捉多样特征的能力。
- 优化困难:需要同时学习多种关系,使得训练时候很不稳定。
而将模型分为多个独立的"头"(Heads),每个头拥有独立的参数(权重矩阵)。这相当于让多个"专家"从不同的角度(子空间)去理解数据,最后将他们的意见汇总。
通俗的说,假设我们看到这句话:"The animal didn't cross the street because it was too tired."
如果只有一个注意力头,模型可能会混淆 "it" 到底指代 "animal" 还是 "street"。
但如果有 8 个头:
- Head 1 (语法头):发现 "it" 是代词,应该指代前面的名词。
- Head 2 (语义头):分析 "tired"(累)这个属性,"street" 不会累,所以 "it" 指 "animal"。
- Head 3 (位置头):关注局部上下文,发现 "it" 离 "animal" 比离 "street" 更近(虽然这不总是对的,但在某些情况下有用)。
- Head 4 (标点头):关注句子结构,发现 "because" 引导了原因状语从句。
- ...
最后,输出层 W O W^O WO 就像一个主编,它根据当前任务的需要,决定听取哪个头的意见更多(例如在指代消解任务中,它会给 Head 2 更高的权重)。
3.2. 核心公式
多头注意力的基础是 Scaled Dot-Product Attention(缩放点积注意力)。
3.2.1. 缩放点积注意力(基础)
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dk QKT)V
参数说明:
- Q ∈ R n × d k Q \in \mathbb{R}^{n \times d_k} Q∈Rn×dk:查询矩阵(Query)。
- K ∈ R m × d k K \in \mathbb{R}^{m \times d_k} K∈Rm×dk:键矩阵(Key)。
- V ∈ R m × d v V \in \mathbb{R}^{m \times d_v} V∈Rm×dv:值矩阵(Value)。
- d k d_k dk:键向量维度。
- d v d_v dv:值向量维度。
- n n n:查询序列长度。
- m m m:键值序列长度。
3.2.2. 多头注意力(核心)
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , . . . , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,...,headh)WO
其中每个头 :
head i = Attention ( Q W i Q , K W i K , V W i V ) \text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V) headi=Attention(QWiQ,KWiK,VWiV)
参数说明:
- h h h:注意力头数量。
- W i Q ∈ R d m o d e l × d k W_i^Q \in \mathbb{R}^{d_{model} \times d_k} WiQ∈Rdmodel×dk:第i头的查询投影矩阵。
- W i K ∈ R d m o d e l × d k W_i^K \in \mathbb{R}^{d_{model} \times d_k} WiK∈Rdmodel×dk:第i头的键投影矩阵。
- W i V ∈ R d m o d e l × d v W_i^V \in \mathbb{R}^{d_{model} \times d_v} WiV∈Rdmodel×dv:第i头的值投影矩阵。
- W O ∈ R h ⋅ d v × d m o d e l W^O \in \mathbb{R}^{h \cdot d_v \times d_{model}} WO∈Rh⋅dv×dmodel:输出投影矩阵。
3.2.3. 自注意力(Self-Attention)
当 Q = K = V Q=K=V Q=K=V 时,称为自注意力:
SelfAttention ( X ) = MultiHead ( X W Q , X W K , X W V ) \text{SelfAttention}(X) = \text{MultiHead}(XW^Q, XW^K, XW^V) SelfAttention(X)=MultiHead(XWQ,XWK,XWV)
其中 : X ∈ R s e q _ l e n × d m o d e l X \in \mathbb{R}^{seq\len \times d{model}} X∈Rseq_len×dmodel是输入序列。
3.3. 维度关系计算
d k = d v = d m o d e l h d_k = d_v = \frac{d_{model}}{h} dk=dv=hdmodel
示例:
- d m o d e l = 512 d_{model} = 512 dmodel=512, h = 8 h = 8 h=8 → d k = d v = 64 d_k = d_v = 64 dk=dv=64
- d m o d e l = 768 d_{model} = 768 dmodel=768, h = 12 h = 12 h=12 → d k = d v = 64 d_k = d_v = 64 dk=dv=64
- d m o d e l = 1024 d_{model} = 1024 dmodel=1024, h = 16 h = 16 h=16 → d k = d v = 64 d_k = d_v = 64 dk=dv=64
参数量计算:
Params M H A = h ⋅ ( d m o d e l ⋅ d k + d m o d e l ⋅ d k + d m o d e l ⋅ d v ) ⏟ QKV投影 + h ⋅ d v ⋅ d m o d e l ⏟ 输出投影 \text{Params}{MHA} = \underbrace{h \cdot (d{model} \cdot d_k + d_{model} \cdot d_k + d_{model} \cdot d_v)}{\text{QKV投影}} + \underbrace{h \cdot d_v \cdot d{model}}_{\text{输出投影}} ParamsMHA=QKV投影 h⋅(dmodel⋅dk+dmodel⋅dk+dmodel⋅dv)+输出投影 h⋅dv⋅dmodel
简化 (当 d k = d v = d m o d e l / h d_k = d_v = d_{model}/h dk=dv=dmodel/h时):
Params M H A = 4 ⋅ d m o d e l 2 \text{Params}{MHA} = 4 \cdot d{model}^2 ParamsMHA=4⋅dmodel2
3.4. 多头注意力计算流程
假设输入序列长度为 L L L,模型维度 d m o d e l = 512 d_{model}=512 dmodel=512,头数 h = 8 h=8 h=8。
-
输入:
- X X X (形状: L × 512 L \times 512 L×512)
- 在自注意力中, Q = K = V = X Q=K=V=X Q=K=V=X。
-
切分与投影:
- 将 Q , K , V Q, K, V Q,K,V 分别乘以 W Q , W K , W V W^Q, W^K, W^V WQ,WK,WV (形状: 512 × 64 512 \times 64 512×64)。
- 结果形状仍为 L × 512 L \times 512 L×512。
- Reshape :将 512 512 512 维切分为 8 × 64 8 \times 64 8×64。现在数据形状视为 ( L × 8 × 64 ) (L \times 8 \times 64) (L×8×64)。这相当于把 512 维切成了 8 份,每份 64 维,分别给 8 个头。
-
缩放点积注意力 (并行):
- 每个头独立计算: S o f t m a x ( Q i K i T 64 ) V i Softmax(\frac{Q_i K_i^T}{\sqrt{64}})V_i Softmax(64 QiKiT)Vi。
- 每个头输出形状: L × 64 L \times 64 L×64。
-
拼接:
- 将 8 个头的输出拼回去: L × ( 8 × 64 ) = L × 512 L \times (8 \times 64) = L \times 512 L×(8×64)=L×512。
-
输出层:
- 乘以 W O W^O WO (形状: 512 × 512 512 \times 512 512×512)。
- 最终输出形状: L × 512 L \times 512 L×512。
3.5. 注意力变体技术演进
| 时间 | 里程碑 | 关键技术 |
|---|---|---|
| 2014 | 注意力机制提出 | Bahdanau Attention (NMT) |
| 2015 | 自注意力萌芽 | Self-Attention概念 |
| 2017 | 多头注意力诞生 | Transformer论文 |
| 2018 | 广泛应用 | BERT、GPT采用MHA |
| 2020 | 效率优化 | Sparse Attention |
| 2021 | 架构改进 | Multi-Query Attention(MQA) |
| 2023 | 效率突破 | Grouped-Query Attention(GQA) |
| 2024-2025 | 新范式 | Multi-Head Latent Attention(MLA) |
3.5.1. Multi-Query Attention (MQA)
提出:2019年,用于加速推理。
核心思想:所有头共享同一组K和V。
MQA ( Q , K , V ) = Concat ( head 1 , . . . , head h ) W O \text{MQA}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O MQA(Q,K,V)=Concat(head1,...,headh)WO
head i = Attention ( Q W i Q , K W K , V W V ) \text{head}_i = \text{Attention}(QW_i^Q, KW^K, VW^V) headi=Attention(QWiQ,KWK,VWV)
注意 : K , V K, V K,V只投影一次,所有头共享。
| 特性 | MHA | MQA |
|---|---|---|
| KV参数量 | h ⋅ 2 ⋅ d m o d e l 2 h \cdot 2 \cdot d_{model}^2 h⋅2⋅dmodel2 | 2 ⋅ d m o d e l 2 2 \cdot d_{model}^2 2⋅dmodel2 |
| KV缓存大小 | h ⋅ d k ⋅ s e q h \cdot d_k \cdot seq h⋅dk⋅seq | d k ⋅ s e q d_k \cdot seq dk⋅seq |
| 推理速度 | 基准 | 3-5x加速 |
| 质量 | 最优 | 略有下降 |
3.5.2. Grouped-Query Attention (GQA)
提出:2023年,LLaMA 2采用。
核心思想:头分组,组内共享KV。
GQA : h 个头分成 g 组,每组共享一组KV \text{GQA}: h \text{个头分成} g \text{组,每组共享一组KV} GQA:h个头分成g组,每组共享一组KV
| 配置 | MHA | GQA | MQA |
|---|---|---|---|
| 头数 | 32 | 32 | 32 |
| KV组数 | 32 | 8 | 1 |
| KV参数量 | 100% | 25% | 3% |
| 质量 | 100% | 98% | 95% |
3.5.3. Multi-Head Latent Attention (MLA)
提出:2024-2025年,DeepSeek V3/R1采用。
核心思想:将QKV投影到低维潜在空间,再解码回高维。
传统MHA: X → [W^Q, W^K, W^V] → [Q, K, V] (高维)
MLA: X → W^DQ → DQ → W^UQ → Q (低维潜在空间压缩)
X → W^DK → DK → W^UK → K
X → W^DV → DV → W^UV → V3.6. 注意力变体技术对比
| 变体技术 | KV缓存 | 推理速度 | 质量 | 代表模型 |
|---|---|---|---|---|
| MHA | 100% | 1x | 100% | 原始Transformer |
| MQA | 3% | 5x | 95% | PaLM、Falcon |
| GQA | 25% | 3x | 98% | LLaMA 2/3、Qwen |
| MLA | 20% | 4x | 99% | DeepSeek V3/R1 |
3.7. 核心优势
| 优势 | 详细说明 | 实际价值 |
|---|---|---|
| 并行计算 | 所有头可同时计算 | GPU利用率高,训练快 |
| 多关系捕捉 | 不同头学习不同关系 | 表达能力强 |
| 位置无关 | 配合PE可处理任意位置 | 灵活性强 |
| 可解释性 | 注意力权重可可视化 | 便于调试分析 |
| 架构通用 | 编码器/解码器均可使用 | 适用场景广 |
| 硬件友好 | 矩阵运算密集 | 适合现代加速器 |
3.8. 主要劣势
| 劣势 | 详细说明 | 影响 |
|---|---|---|
| 计算复杂度 | O(n²)注意力矩阵 | 长序列计算开销大 |
| 内存占用 | 存储n×n注意力矩阵 | 显存消耗大 |
| KV缓存 | 推理时需缓存KV | 长上下文显存压力大 |
| 头冗余 | 部分头可能学习相似模式 | 参数效率有提升空间 |
| 固定头数 | 无法动态调整头数量 | 灵活性受限 |
4. Layer Normalization(层归一化)
Layer Normalization(层归一化,简称 LN) 是深度学习中一种非常重要的技术,主要用于加速神经网络的训练、提高模型的稳定性,并允许使用更大的学习率。
它由 Geoffrey Hinton 团队在 2016 年的论文《Layer Normalization》中提出,最初是为了解决 Batch Normalization(批归一化,BN)在循环神经网络(RNN)和小批量训练场景下的缺陷。
4.1. 为什么需要 Layer Normalization ?
在深度神经网络训练过程中,随着参数的更新,每一层输入的分布会不断变化,这种现象被称为Internal Covariate Shift(内部协变量偏移)。
- 问题:如果输入分布剧烈变化,后一层需要不断适应新的分布,导致训练变慢,且容易出现梯度消失或爆炸。
- 解决方案:通过归一化(Normalization)将每一层的输入强制拉回到均值为 0、方差为 1 的标准正态分布,然后再通过可学习的参数进行缩放和平移,保持网络的表达能力。
什么是梯度消失或爆炸?
指在反向传播(Backpropagation)过程中,梯度(用来更新权重的信号)在从输出层向输入层传递时,要么越来越小直至消失(变成0),要么越来越大直至失控(变成无穷大/NaN)。需要结合 ReLU、残差连接、归一化层(LN/BN)和梯度裁剪等技术进行处理。
通俗理解
假设我们在玩一个传话游戏(类似电话传声筒),队伍有 100 个人(100层网络):
- 梯度消失:每个人传话的声音都比上一个人小一点(0.9倍)。传到第 100 个人时,声音已经微乎其微,根本听不见了。结果:最后一个人不知道前面说了什么,无法修正错误。
- 梯度爆炸:每个人传话的声音都比上一个人大一点(1.1倍)。传到第 100 个人时,声音已经震耳欲聋,甚至把耳朵震聋了(NaN)。结果:信息完全失真,游戏崩盘。
- ResNet(残差) :除了口头传话,还拉了一根电话线直接连到下一个人。即使口头声音消失了,电话线里的声音还是清晰的。
- ReLU:规定传话时声音不能变小(只能保持原样或变大),保证声音能传得更远。
- 梯度裁剪:规定声音最大不能超过 100 分贝,超过了就按 100 分贝喊,防止震聋耳朵。
4.2. Layer Normalization 的核心公式
Layer Normalization 的核心思想是:在单个样本内部,对该层的所有神经元(特征维度)进行归一化。
假设一个样本在某一层的输入向量为 x = x 1 , x 2 , . . . , x H x = x_1, x_2, ..., x_H x=x1,x2,...,xH(其中 H H H 是该层的隐藏单元数/特征维度)。
-
计算均值 μ \mu μ :
μ = 1 H ∑ i = 1 H x i \mu = \frac{1}{H} \sum_{i=1}^{H} x_i μ=H1i=1∑Hxi -
计算方差 σ 2 \sigma^2 σ2 :
σ 2 = 1 H ∑ i = 1 H ( x i − μ ) 2 \sigma^2 = \frac{1}{H} \sum_{i=1}^{H} (x_i - \mu)^2 σ2=H1i=1∑H(xi−μ)2 -
归一化 :
x ^ i = x i − μ σ 2 + ϵ \hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} x^i=σ2+ϵ xi−μ -
缩放与平移(Scale and Shift) :
y i = γ x ^ i + β y_i = \gamma \hat{x}_i + \beta yi=γx^i+β参数说明:
- μ \mu μ:特征均值(标量)。
- σ 2 \sigma^2 σ2:特征方差(标量)。
- ϵ \epsilon ϵ:数值稳定性常数(是一个极小的常数,防止分母为 0,通常 10 − 5 10^{-5} 10−5 或 10 − 6 10^{-6} 10−6)。
- γ \gamma γ:可学习的缩放参数(Scale)。
- β \beta β:可学习的平移参数(Shift)。
- H H H:隐藏层维度。
4.3. Layer Normalization vs Batch Normalization 区别
| 特性 | Batch Normalization (BN) | Layer Normalization (LN) |
|---|---|---|
| 归一化维度 | 跨样本(在同一个特征上,对 Batch 内所有样本归一化) | 跨特征(在同一个样本上,对该层所有特征归一化) |
| 依赖 Batch Size | 强依赖。Batch Size 太小(如 1 或 2)时,均值和方差统计不准,效果极差。 | 不依赖。每个样本独立计算,Batch Size=1 也能完美工作。 |
| 训练/推理差异 | 训练时用 Batch 统计量,推理时用移动平均(Moving Average)统计量,存在不一致。 | 训练和推理计算方式完全一致(都是基于当前输入计算)。 |
| 适用模型 | CNN(卷积神经网络)效果极佳。 | RNN、Transformer、NLP 模型。 |
| 计算开销 | 需在 GPU 间同步 Batch 统计量,通信开销大。 | 完全在样本内计算,无同步开销。 |
直观比喻:
- BN :像是班级考试,把全班(Batch)同学的同一道题(特征)的分数拉平,看谁相对高。
- LN :像是个人体检,看一个人(样本)各科成绩(特征)的平均水平,把这个人的各科分数标准化,看哪科偏科。
4.4. Layer Normalization 的优势
- 不受 Batch Size 限制 :
- 这是 LN 最大的优势。在 NLP 任务中,由于显存限制,Batch Size 往往很小(如 1, 2, 4),BN 在这种情况下几乎失效,而 LN 表现稳定。
- 适用于在线学习(Online Learning)或流式数据(Batch Size = 1)。
- 适用于变长序列(RNN/Transformer) :
- RNN 处理序列时,不同时间步(Time Step)的隐藏状态需要独立归一化。BN 很难处理变长序列(因为不同序列长度不一样,无法在 Batch 维度对齐),而 LN 对每个时间步的样本独立操作,非常适合。
- 训练更稳定,收敛更快 :
- 平滑了损失曲面(Loss Landscape),允许使用更大的学习率。
- 减少了梯度消失/爆炸的风险。
- 推理时无需存储额外统计量 :
- BN 需要在训练时保存全局的 Moving Average Mean/Var 用于推理;LN 直接用当前输入计算,推理逻辑更简单。
5. Residual Connection(残差连接)
Residual Connection(残差连接,又称 Skip Connection / Shortcut Connection) 是深度学习历史上最具革命性的技术之一。它由微软研究院的何恺明团队在 2015 年的论文《Deep Residual Learning for Image Recognition》(ResNet)中提出。
简单来说,残差连接就是允许网络的输入直接"跳过"一层或多层,直接加到后面的层的输出上。
5.1. 为什么要引入残差连接?
在 ResNet 出现之前,人们认为网络越深,特征提取能力越强,效果应该越好。但实验发现:
-
现象 :当网络层数加深(如从 20 层加深到 56 层)时,训练误差反而上升了(不是过拟合,而是训练集上的误差都变大了)。
-
问题 :这不是过拟合,而是优化困难。深层网络很难训练,梯度在反向传播时会消失,导致前几层的权重几乎不更新。
-
核心直觉 :如果一个深层网络比浅层网络强,那么深层网络至少应该能做到浅层网络的效果(即恒等映射 H ( x ) = x H(x) = x H(x)=x)。但实际上,让一堆非线性层(Conv + ReLU)去拟合一个恒等映射 y = x y=x y=x 非常困难(因为 ReLU 会把负值截断,权重初始化很难刚好是单位矩阵)。
-
解决方案 :既然拟合 H ( x ) = x H(x) = x H(x)=x 很难,那我们换个目标:让网络去拟合残差函数 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x。如果恒等映射是最优的,那么只需要让 F ( x ) → 0 F(x) \to 0 F(x)→0 即可。而让一堆层去拟合 0(也就是让权重趋向于 0)比拟合单位矩阵容易得多!
5.2. 核心原理及公式
假设某一层的输入是 x x x,我们期望的输出是 H ( x ) H(x) H(x)。传统的网络直接学习 H ( x ) H(x) H(x),而残差网络学习 F ( x ) F(x) F(x)。
公式 :
y = F ( x , { W i } ) + x y = F(x, \{W_i\}) + x y=F(x,{Wi})+x
- x x x:输入(Shortcut / Skip connection)。
- F ( x ) F(x) F(x):残差映射(比如两个卷积层 + 激活函数)。
- y y y:输出。
- 最后通常会经过一个激活函数: y f i n a l = ReLU ( y ) y_{final} = \text{ReLU}(y) yfinal=ReLU(y)(或者 Pre-activation 形式)。
维度不一致怎么办?
如果 F ( x ) F(x) F(x) 改变了通道数或尺寸(例如 stride=2 的卷积), x x x 和 F ( x ) F(x) F(x) 的维度不同,无法直接相加。
此时需要用一个投影矩阵 W s W_s Ws (通常是 1x1 卷积)来调整 x x x 的维度:
y = F ( x , { W i } ) + W s x y = F(x, \{W_i\}) + W_s x y=F(x,{Wi})+Wsx
5.3. 为什么残差连接能解决梯度消失?
这是理解残差连接最关键的部分。我们从反向传播的角度看。
假设损失函数为 L L L,输入为 x x x,输出为 y = F ( x ) + x y = F(x) + x y=F(x)+x。
根据链式法则,梯度回传到 x x x 时:
∂ L ∂ x = ∂ L ∂ y ⋅ ∂ y ∂ x = ∂ L ∂ y ⋅ ( ∂ F ( x ) ∂ x + I ) \frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \cdot \frac{\partial y}{\partial x} = \frac{\partial L}{\partial y} \cdot \left( \frac{\partial F(x)}{\partial x} + \mathbf{I} \right) ∂x∂L=∂y∂L⋅∂x∂y=∂y∂L⋅(∂x∂F(x)+I)
- ∂ F ( x ) ∂ x \frac{\partial F(x)}{\partial x} ∂x∂F(x):经过权重层的梯度,可能很小(导致梯度消失)。
- I \mathbf{I} I:单位矩阵(恒等项)。
关键在于 :梯度 ∂ L ∂ x \frac{\partial L}{\partial x} ∂x∂L 被拆成了两部分。即使 ∂ F ( x ) ∂ x \frac{\partial F(x)}{\partial x} ∂x∂F(x) 非常小(甚至接近 0),还有一项 ∂ L ∂ y ⋅ I \frac{\partial L}{\partial y} \cdot \mathbf{I} ∂y∂L⋅I 保证了梯度可以无损地传向前一层。
直观比喻:
- 普通网络:像是走迷宫,每一层都要拐弯,如果路太长(层太深),信号容易迷路(消失)。
- 残差网络 :像是修了高速公路 。梯度不仅可以走迷宫( F ( x ) F(x) F(x)),还可以直接走高速( + x +x +x)直达起点。这就保证了即使迷宫里堵车了,信号也能传过去。
5.4. 残差连接的两种主要形式
在 ResNet 和 Transformer 中,残差连接的位置略有不同:
-
Post-Activation (原始 ResNet)
这是最经典的形式,激活函数在加法之后。
y = ReLU ( F ( x ) + x ) y = \text{ReLU}(F(x) + x) y=ReLU(F(x)+x)
问题 :如果 F ( x ) + x F(x) + x F(x)+x 总是负的,ReLU 会把它们都截断为 0,导致残差块失效。 -
Pre-Activation (现代主流,如 ResNet V2, Transformer)
将激活函数和归一化层放在残差分支之前。
y = x + F ( Norm ( x ) ) y = x + F(\text{Norm}(x)) y=x+F(Norm(x))或者更常见的(Transformer中):
x o u t = x + Dropout ( Sublayer ( Norm ( x ) ) ) x_{out} = x + \text{Dropout}(\text{Sublayer}(\text{Norm}(x))) xout=x+Dropout(Sublayer(Norm(x)))
优点 :梯度可以直接从 x x x 流向 x o u t x_{out} xout,没有经过任何激活函数的截断,训练极深网络(如 1000 层)更加稳定。
现状:现在的 LLM(如 GPT、LLaMA)和现代 CNN 基本都用 Pre-activation 配合 LayerNorm。
5.5. 在 Transformer 中的应用
在 Transformer 架构中,残差连接是绝对核心,几乎无处不在。
- Self-Attention 层后 :
x o u t = x i n + MultiHeadAttention ( x i n ) x_{out} = x_{in} + \text{MultiHeadAttention}(x_{in}) xout=xin+MultiHeadAttention(xin) - Feed-Forward Network (FFN) 层后 :
x o u t = x i n + FFN ( x i n ) x_{out} = x_{in} + \text{FFN}(x_{in}) xout=xin+FFN(xin)
作用:
- Transformer 非常深(GPT-3 有 96 层,GPT-4 可能上百层),没有残差连接根本无法训练。
- 它允许模型在训练初期"复制"输入( F ( x ) ≈ 0 F(x) \approx 0 F(x)≈0),随着训练慢慢增加非线性变换的复杂度,保证了训练的稳定性。
5.6. Transformer中残差连接与归一化的关系
在残差连接(Residual Connection)之后,Transformer模型中的每个子层都伴随一个残差连接,然后紧接着一个层归一化操作。具体来说,对于每个子层(例如自注意力或前馈网络),输入首先通过子层自身,然后将子层的输出与输入进行相加(残差连接),最后对这个相加的结果进行层归一化。
6. Feed-Forward Neural Network(前馈神经网络)
Feed-Forward Neural Network(前馈神经网络,简称 FNN) 是人工神经网络中最基础、最经典的架构,也是深度学习的基石。在简单任务中,它可以单独作为分类器(MLP)。而在复杂模型中(Transformer),它是核心的特征处理引擎,负责在 Attention 提取完全局信息后,对每个位置的信息进行独立的、非线性的深度变换。
虽然现在大家更多地谈论 Transformer、CNN 或 RNN,但这些复杂模型的核心组件往往就是 FNN(或其变体,如 MLP)。在 Transformer 架构中,它通常被称为 Position-wise Feed-Forward Network (FFN)。
6.1. 什么是"前馈"?
"前馈" 指的是信息的流动方向是单向的:
- 从 输入层 (Input Layer) 开始。
- 经过一层或多层 隐藏层 (Hidden Layer) 的处理。
- 最后到达 输出层 (Output Layer)。
关键点 :FNN 网络中没有环路(Loop),输出不会反馈回输入。这与循环神经网络(RNN)形成鲜明对比,RNN 是有记忆的(有环路),而 FNN 是"健忘"的(每次输入都是独立的)。
6.2. 网络结构与组件
一个典型的多层前馈神经网络(Multi-Layer Perceptron, MLP)包含以下部分:
-
输入层:接收原始数据(如图片像素、单词嵌入向量)。
-
隐藏层:位于输入和输出之间,负责特征提取和非线性变换。可以有几十层甚至上百层。
-
输出层:产生最终结果(如分类概率、回归数值)。
┌─────────────────────────────────────────────────────────────────┐
│ 标准 FNN 架构 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 输入层 │───→│ 隐藏层1 │───→│ 隐藏层2 │───→│ 输出层 │ │
│ │ │ │ │ │ │ │ │ │
│ │ n₀ 神经元 │ │ n₁ 神经元 │ │ n₂ 神经元 │ │ n₃ 神经元│ │
│ │ │ │ │ │ │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
│ │ │ │ │ │
│ ▼ ▼ ▼ ▼ │
│ 原始特征 低级特征 高级特征 预测结果 │
│ │
│ 层间连接:全连接(每个神经元连接下一层所有神经元) │
│ 信息流:单向(输入→输出,无反馈) │
│ │
└─────────────────────────────────────────────────────────────────┘
核心计算单元(神经元)
每一层由多个神经元组成。对于第 l l l 层的一个神经元,其计算过程如下:
- 线性变换 :
z ( l ) = W ( l ) ⋅ a ( l − 1 ) + b ( l ) z^{(l)} = W^{(l)} \cdot a^{(l-1)} + b^{(l)} z(l)=W(l)⋅a(l−1)+b(l)- W W W:权重矩阵(Weight),网络要学习的核心参数。
- b b b:偏置(Bias)。
- a ( l − 1 ) a^{(l-1)} a(l−1):上一层的输出。
- 非线性激活 :
a ( l ) = σ ( z ( l ) ) a^{(l)} = \sigma(z^{(l)}) a(l)=σ(z(l))- σ \sigma σ:激活函数(如 ReLU, Sigmoid, Tanh, GeLU)。如果没有这一步,多层网络就退化成单层线性模型。
6.3. 神经元信息如何流动?
假设一个简单的 3 层 FNN(输入层、1个隐藏层、输出层):
- 输入 : x x x
- 隐藏层 : h = ReLU ( W 1 x + b 1 ) h = \text{ReLU}(W_1 x + b_1) h=ReLU(W1x+b1)
- 输出 : y ^ = Softmax ( W 2 h + b 2 ) \hat{y} = \text{Softmax}(W_2 h + b_2) y^=Softmax(W2h+b2)
前向传播(Forward Propagation) 就是把 x x x 代入公式,一层层算出 y ^ \hat{y} y^ 的过程。
为什么需要非线性激活函数?
如果只是 y = W 2 ( W 1 x + b 1 ) + b 2 y = W_2(W_1 x + b_1) + b_2 y=W2(W1x+b1)+b2,根据矩阵乘法结合律,这等价于 y = ( W 2 W 1 ) x + ( W 2 b 1 + b 2 ) y = (W_2 W_1) x + (W_2 b_1 + b_2) y=(W2W1)x+(W2b1+b2),也就是 y = W ′ x + b ′ y = W'x + b' y=W′x+b′。
这意味着:无论堆多少层线性层,效果等同于一层。只有加入 ReLU 等非线性函数,深层网络才有意义,才能拟合复杂的函数(如曲线、曲面)。
6.4. 反向传播 (Backpropagation)
FNN 的训练核心是反向传播算法 + 梯度下降。
- 计算损失 :比较预测值 y ^ \hat{y} y^ 和真实值 y y y,计算 Loss(如交叉熵、MSE)。
- 求梯度 :利用链式法则,从输出层向输入层反向计算每个权重 W W W 对 Loss 的贡献(梯度 ∂ L ∂ W \frac{\partial L}{\partial W} ∂W∂L)。
- 这就是为什么深层 FNN 容易遇到梯度消失/爆炸问题(前面介绍过的)。
- 更新权重 : W n e w = W o l d − η ⋅ ∂ L ∂ W W_{new} = W_{old} - \eta \cdot \frac{\partial L}{\partial W} Wnew=Wold−η⋅∂W∂L ( η \eta η 是学习率)。
6.5. 通用近似定理 (Universal Approximation Theorem)
这是 FNN 的理论基石:只要隐藏层包含足够多的神经元,一个单层前馈神经网络就可以以任意精度拟合任何连续函数。
这意味着,理论上 FNN 可以解决任何模式识别问题(图像识别、语言翻译、股票预测等)。但在实践中,为了提高效率和泛化能力,我们通常使用深层网络(Deep FNN / MLP)而不是极宽的单层网络。
6.6. FNN 在 Transformer 中的角色
在现代大语言模型(如 GPT、BERT、LLaMA)中,FNN 以 Position-wise Feed-Forward Network 的形式出现,通常位于 Self-Attention 层之后。
结构:
FFN ( x ) = W 2 ( Activation ( W 1 x + b 1 ) ) + b 2 \text{FFN}(x) = W_2(\text{Activation}(W_1 x + b_1)) + b_2 FFN(x)=W2(Activation(W1x+b1))+b2
通常是一个两层的 MLP:
- 第一层(升维):将维度扩大(例如从 512 扩到 2048),并使用激活函数(如 ReLU 或 GeLU)。
- 第二层(降维):将维度压缩回原来的大小(2048 -> 512)。
特点:
- Position-wise :对序列中的每一个 Token(单词)独立处理,不涉及 Token 之间的交互(交互由 Attention 层负责)。
- 作用 :
- 引入非线性,增强模型的表达能力。
- 可以看作是对每个单词的特征进行"深度加工"或"查表/记忆扩充"。
- 包含了模型约 2/3 的参数量(Transformer 中 FFN 通常比 Attention 层更"胖")。
配合残差连接和归一化:
在 Transformer 中,FFN 块通常这样包裹:
x o u t = x i n + FFN ( LayerNorm ( x i n ) ) x_{out} = x_{in} + \text{FFN}(\text{LayerNorm}(x_{in})) xout=xin+FFN(LayerNorm(xin))
(这是 Pre-LN 结构,利用残差连接防止梯度消失,利用 LayerNorm 稳定训练)。
6.7. FNN 核心优势
| 优势 | 详细说明 | 实际价值 |
|---|---|---|
| 结构简单 | 易于理解和实现 | 入门首选 |
| 通用近似 | 可拟合任意连续函数 | 理论保证 |
| 训练快速 | 并行计算效率高 | GPU 友好 |
| 灵活性强 | 可适配各种输入输出 | 应用广泛 |
| 基础组件 | Transformer/LLM 的核心 | 不可或缺 |
6.8. FNN 主要劣势
| 劣势 | 详细说明 | 影响 |
|---|---|---|
| 无空间感知 | 无法捕捉局部结构 | 不适合图像原始像素 |
| 无时间感知 | 无法处理序列依赖 | 不适合时间序列 |
| 参数量大 | 全连接导致参数多 | 容易过拟合 |
| 特征工程依赖 | 需要手工提取特征 | 表格数据效果好 |
| 深层训练困难 | 梯度消失/爆炸 | 通常不超过 10 层 |
6.9 FNN 技术变体
- MLP (Multi-Layer Perceptron):最经典的 FNN,层与层之间全连接。
- ResNet 中的 FNN:包含残差连接的 FNN。
- Transformer FFN :通常使用 GELU 或 Swish 激活函数,而不是传统的 ReLU,效果更好。
- Autoencoder (自编码器):由 FNN 构成,用于无监督学习和降维。
四、解码器(Decoder)
解码器(Decoder)由N个(在原论文中是6个)相同的解码器层(Decoder Layer)堆叠而成,它的核心逻辑是 自回归生成(Autoregressive Generation),即根据已经生成的词,预测下一个词。
Decoder主要结构为Output Embedding(输出嵌入)、Positional Encoding(位置编码)、Masked Multi-Head Attention(掩码多头注意力机制)、Layer Normalization(层归一化)、Residual Connection(残差连接)、Multi-Head Attention(多头注意力机制)、Feed-Forward Neural Network(前馈神经网络)、Output Processing(输出处理层)。
什么是自回归生成(Autoregressive Generation)?
在Transformer模型中,自回归任务指的是一种序列生成任务,其中模型在生成每个新元素时都依赖于之前已生成的序列。简言之,就是模型在预测下一个输出时,会使用到目前为止已经生成的所有输出作为上下文信息。这也是为什么ChatGPT的回答是一个字一个字往外蹦的原因。
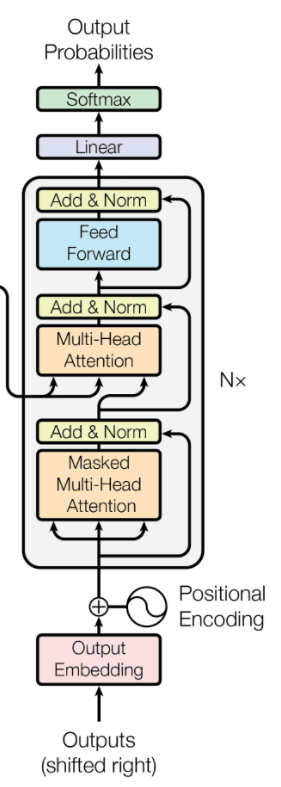
1. Output Embedding(输出嵌入)
Output Embedding(输出嵌入)是 Transformer Decoder 的输入层组件,与输入嵌入类似,输出嵌入是负责将目标序列的单词 ID(Token IDs)转换为稠密向量表示,这些嵌入向量会被加上位置编码,以引入序列中单词的位置信息,作为 Decoder 的初始输入。
目标序列 Token IDs 是什么?
- 训练阶段:是【期望的回答结果】。
- 人工标注的真实答案。
- 用于计算损失,指导模型学习。
- 右移一位后作为 Decoder 输入。
- 推理阶段:是【模型自己生成的回答】。
- 没有真实答案可用。
- 模型生成的 token 作为下一步输入。
- 自回归循环,直到生成结束符。
在训练阶段,为了提高效率和稳定性,我们不会等模型生成一个词再把它喂回去,而是直接将整个目标序列(也就是我们期望模型生成的正确答案)输入给解码器。但为了防止模型"作弊"(在预测第 i 个词时看到第 i+1 个词),我们会将目标序列向右移动一位,并在开头加上一个起始符 <sos> (start of sequence)。
2. Positional Encoding(位置编码)
参考编码器(Encoder) 中介绍的 Positional Encoding(位置编码)。
3. Masked Multi-Head Attention(掩码多头注意力机制)
Masked Multi-Head Attention(掩码多头注意力机制) 是 Transformer 解码器(Decoder)的核心组件,也是它与编码器(Encoder)最显著的区别所在。它的核心作用是:在生成序列时,确保模型在预测第 t t t 个位置的词时,只能利用前 t − 1 t-1 t−1 个位置的信息,而不能"偷看"未来的信息(第 t + 1 t+1 t+1 及之后的词)。
3.1. 为什么需要"掩码"(Mask)?
在自然语言生成任务(如翻译、写诗、对话)中,模型是**自回归(Autoregressive)**的,即一个词一个词地往外"蹦"。
- 推理阶段(Inference):当你预测第 3 个词时,你确实只有前 2 个词作为输入,这是符合逻辑的。
- 训练阶段(Training) :为了加速计算,我们通常不会一个词一个词地串行训练,而是把整个目标句子 (Ground Truth)一次性塞给模型。
- 例如翻译
I love you->我爱你,训练时输入解码器的是[<sos>, 我, 爱, 你, <eos>]。 - 如果在计算
我爱的注意力时,模型看到了后面的你,这就相当于考试作弊。模型会学会直接复制后面的词,而不是学会根据上文去预测下文。
- 例如翻译
Masked Attention 的目的就是通过人为屏蔽未来的信息,强制模型只能关注过去和当前的信息,从而保证训练和推理的一致性。
<sos>:序列的开始标记,即 start of sequence。
<eod>:输出结束标记,即 end of sequence。
3.2. 如何实现"掩码"?
掩码主要发生在 Scaled Dot-Product Attention 计算中的 Softmax 之前,主要实现步骤如下:
-
计算注意力分数(Scores) :
假设我们有 Query ( Q Q Q), Key ( K K K), Value ( V V V)。
计算 Q × K T Q \times K^T Q×KT,得到一个分数矩阵 S S S,形状为
(seq_len, seq_len)。- S i j S_{ij} Sij 代表第 i i i 个词对第 j j j 个词的关注程度。
-
缩放(Scale) :
除以 d k \sqrt{d_k} dk ,防止梯度消失。
-
应用掩码(Apply Mask) :
这是关键一步。我们构造一个掩码矩阵(Mask Matrix) ,通常用 − ∞ -\infty −∞(负无穷)填充需要屏蔽的位置。
公式表达:
MaskedScores = { Score i j if j ≤ i − ∞ if j > i \text{MaskedScores} = \begin{cases} \text{Score}_{ij} & \text{if } j \le i \\ -\infty & \text{if } j > i \end{cases} MaskedScores={Scoreij−∞if j≤iif j>i- 对于第 i i i 个位置,所有 j > i j > i j>i 的位置(未来的词)都会被设置为 − ∞ -\infty −∞。
- 其他位置(过去的词和当前词)保持原值(通常是 0 或者保留分数)。
-
Softmax 归一化 :
对 MaskedScores 做 Softmax。
- 因为 e − ∞ = 0 e^{-\infty} = 0 e−∞=0,所以未来位置的权重被强制变为 0。
- 过去位置的权重正常归一化,总和为 1。
-
加权求和 :
用归一化后的权重乘以 V V V,得到输出。
3.3. 多头(Multi-Head)的作用
单纯的掩码注意力只能捕捉一种依赖关系。引入多头机制(通常 8 头或 12 头)有以下好处:
- 多角度关注 :
- Head 1 可能关注语法结构(如主语关注谓语)。
- Head 2 可能关注词汇搭配(如 "J'aime" 关注名词)。
- Head 3 可能关注指代关系(如 "it" 关注前面的 "cat")。
- 独立掩码 :每个头都有自己独立的 Q , K , V Q, K, V Q,K,V 投影矩阵,并且每个头都独立应用相同的掩码逻辑。这意味着每个头都在用不同的视角"回顾历史",但都看不到未来。
- 表达能力增强:最后将所有头的输出拼接(Concat)并线性变换,融合了多种不同的上下文信息。
3.4. 如何通俗理解掩码?
假设我们让模型翻译 "I love you",目标法语序列是:[<sos>, 我, 爱, 你, <eos>]。
我们在训练阶段一次性输入这个序列,看看 Masked Multi-Head Attention 是如何工作的:
| 当前预测词 | 输入序列 (Q, K, V 来源) | 允许关注的位置 (Key) | 屏蔽的位置 (Key) | 结果 |
|---|---|---|---|---|
预测 <sos> |
[<sos>] |
<sos> |
无 | 只能关注起始符 |
预测 我 |
[<sos>, 我] |
<sos>, 我 |
爱, 你, <eos>] |
模型根据 <sos> 预测出 我 |
预测 爱 |
[<sos>, 我, 爱] |
<sos>, 我, 爱 |
你, <eos> |
模型根据 <sos> 我 预测出 爱 |
预测 你 |
[<sos>, 我, 爱, 你] |
<sos>, 我, 爱, 你 |
<eos> |
模型根据 <sos> 我爱 预测出 你 |
预测 <eos> |
[<sos>, 我, 爱, 你, <eos>] |
全部 | 无 | 模型根据全句预测结束符 |
可视化注意力矩阵(下三角为有效区域):
K: <sos> 我 爱 你 <eos>
Q:
<sos> [ X 0 0 0 0 ] <-- 只能看自己
我 [ X X 0 0 0 ] <-- 能看:<sos>和自己
爱 [ X X X 0 0 ] <-- 能看前面所有和自己,不能看:你, <eos>
你 [ X X X X 0 ] <-- 能看前面所有和自己,不能看:<eos>
<eos> [ X X X X X ] <-- 能看所有
注:X 代表有数值,0 代表被 Mask 掉。3.5. 训练模式 vs 推理模式下掩码的区别
这是一个非常重要的细节:
- 训练时(Teacher Forcing) :
- 输入是完整的目标序列(右移一位)。
- Mask 是必须的,否则模型会作弊。
- 因为是并行计算,Mask 矩阵是一个固定的上三角矩阵(对角线及以下为 0,以上为 − ∞ -\infty −∞)。
- 推理时(生成模式) :
- 输入是动态增长的:
[<sos>]->[<sos>, word1]->[<sos>, word1, word2]... - Mask 仍然存在,但形式变了。因为序列长度在变,Mask 矩阵的大小也在变(从 1x1 变成 2x2,再变成 3x3...)。
- 实际上,在实现时(如 PyTorch/TensorFlow),为了效率,推理时通常也会预分配一个最大长度的 Mask 矩阵,或者利用缓存(KV Cache)机制,但逻辑上依然是"看不到未来"。
- 输入是动态增长的:
4. Layer Normalization(层归一化)
参考编码器(Encoder) 中介绍的 Layer Normalization(层归一化)。
5. Residual Connection(残差连接)
参考编码器(Encoder) 中介绍的 Residual Connection(残差连接)。
6. Multi-Head Attention(多头注意力机制)
Decoder 的Multi-Head Attention(多头注意力机制)与编码器(Encoder)介绍的实现原理基本相同。
但需要注意的是,这一部分主要是将解码器当前生成的序列与原始输入序列(经过编码器处理的)联系起来,用于生成下一个目标单词。这部分的注意力机制作用主要有两个:
- 连接源序列和目标序列:通过关注编码器的输出,解码器可以根据需要从源序列中提取相关的上下文信息;
- 动态关注不同部分:同时,在解码过程中,模型可能会选择关注输入序列的不同部分。
举个例子:
假设我们正在进行英译法的语言翻译任务:
- 输入:The cat sits on the mat.
- 目标结果:Le chat est assis sur le tapis.
经过编码器处理后,解码器开始逐步生成法文翻译:
- 当解码器准备生成下一个法文词时,不带掩码的编码器-解码器注意力机制会参考整个英文句子的编码(Encoder的结果)表示。
- 这个机制允许解码器在生成每个法文词时都能够根据需要关注英文句子中的相应部分,比如在生成"le chat"(猫)时,可能会特别关注"the cat"的编码表示。
7. Feed-Forward Neural Network(前馈神经网络)
参考编码器(Encoder) 中介绍的 Feed-Forward Neural Network(前馈神经网络)。
8. Output Processing(输出处理层)
输出处理层(Output Processing Layer)位于整个 Decoder 架构的最顶端。它负责将 Decoder 的隐藏状态转换为词汇表上的概率分布,从而预测下一个 token。它主要包含三个关键组件:Linear层(线性变换层/全连接层)、Softmax(概率归一化)、Output Probabilities(输出概率)。
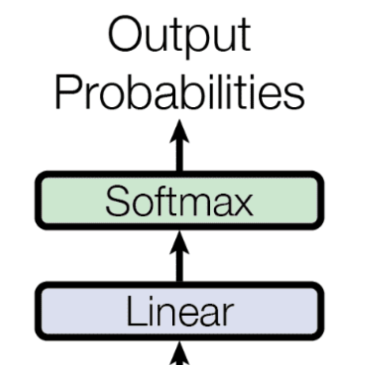
8.1. Linear层(线性变换层/全连接层)
Linear层核心作用是将Decoder输出的高维隐藏状态 映射到词汇表大小的维度 ,得到每个词汇的未归一化得分(Logits):
- 假设 Decoder 的隐藏状态维度为 d d d(如 Transformer 中的 768 维),词汇表大小为 V V V(如 30,000 个词),则 Linear 层是一个权重矩阵 :
W ∈ R V × d m o d e l {W \in \mathbb{R}^{V \times d_{model}}} W∈RV×dmodel - 计算方式:对于 Decoder 输出的隐藏状态向量 h ∈ R d m o d e l h \in \mathbb{R}^{d_{model}} h∈Rdmodel,Linear 层输出 Logits 向量 z ∈ R V z \in \mathbb{R}^{V} z∈RV(可选加偏置 b ∈ R V b \in \mathbb{R}^{V} b∈RV):
z = W ⋅ h + b {z = W \cdot h + b} z=W⋅h+b
其中, z i z_i zi 表示词汇表中第 i i i 个词的 "得分"(未归一化的概率)。
关键细节:
- 权重共享(Tie Weights) :部分模型(如Transformer)会将Linear层的权重与输入嵌入层(Embedding Layer) 的权重共享(即 W W W ) 同时作为嵌入层的"词→向量"矩阵和Linear层的"向量→词"矩阵)。这样可以减少参数数量(约 50%),同时利用嵌入层的语义信息,以提升性能。
- 数值范围 :Logits的取值范围是 ( − ∞ , + ∞ ) (-\infty, +\infty) (−∞,+∞),无概率意义,仅表示每个词的"相对重要性"。
8.2. Softmax(概率归一化)
Softmax(概率归一化)的作用是将Linear层输出的Logits 转换为概率分布 ,满足"非负且和为1"的概率公理,便于后续的采样 (如贪心采样、束搜索)或损失计算(如交叉熵)。
- Softmax 函数的数学定义:对于 Logits 向量 z = z 1 , z 2 , . . . , z V z = z_1, z_2, ..., z_V z=z1,z2,...,zV,第 i i i 个词的概率 p i p_i pi 为:
p i = exp ( z i ) ∑ j = 1 V exp ( z j ) p_i = \frac{\exp(z_i)}{\sum_{j=1}^{V} \exp(z_j)} pi=∑j=1Vexp(zj)exp(zi)
其中, exp ( ⋅ ) \exp(\cdot) exp(⋅) 是指数函数,分母是所有词的指数和(归一化项)。
关键细节:
-
数值稳定性优化 :直接计算 exp ( z i ) \exp(z_i) exp(zi) 可能因 z i z_i zi 过大导致数值溢出(如 z i = 100 z_i = 100 zi=100 时, exp ( 100 ) ≈ 2.688 × 10 43 \exp(100) \approx 2.688 \times 10^{43} exp(100)≈2.688×1043,远超 32 位浮点数范围)。实际实现中会先对 Logits 做平移(减去最大值 m = max ( z 1 , . . . , z V ) m = \max(z_1, ..., z_V) m=max(z1,...,zV)),再计算 Softmax:
p i = exp ( z i − m ) ∑ j = 1 V exp ( z j − m ) p_i = \frac{\exp(z_i - m)}{\sum_{j=1}^{V} \exp(z_j - m)} pi=∑j=1Vexp(zj−m)exp(zi−m)平移后所有 z i − m ≤ 0 z_i - m \le 0 zi−m≤0,指数值限制在 ( 0 , 1 ] (0, 1] (0,1],避免溢出,且结果与原 Softmax 一致。
-
温度系数 (Temperature Scaling) :推理时可引入温度 T > 0 T > 0 T>0 调整概率分布的"尖锐度":
p i = exp ( z i / T ) ∑ j = 1 V exp ( z j / T ) p_i = \frac{\exp(z_i / T)}{\sum_{j=1}^{V} \exp(z_j / T)} pi=∑j=1Vexp(zj/T)exp(zi/T)- T = 1 T = 1 T=1:标准 Softmax;
- T > 1 T > 1 T>1:分布更平缓(增加随机性,避免过早收敛到高频词);
- T < 1 T < 1 T<1:分布更尖锐(增强确定性,倾向选高概率词)。
-
概率意义 :输出的 p i p_i pi 表示"当前 Decoder 状态下,下一个 token 是第 i i i 个词的概率",所有 p i p_i pi 之和为 1。
8.3. Output Probabilities(输出概率)
Output Probabilities(输出概率) 是 Transformer Decoder 输出处理层的最终产物,连接模型内部表示与外部 Token 生成的关键桥梁。他表示在当前上下文条件下,词汇表中每个词作为下一个 Token 的概率分布。
8.3.1. 核心公式:
对于词汇表中的第 i i i 个词,其输出概率为:
p i = P ( token i ∣ context ) = exp ( z i / T ) ∑ j = 1 V exp ( z j / T ) {p_i = P(\text{token}i | \text{context}) = \frac{\exp(z_i / T)}{\sum{j=1}^{V} \exp(z_j / T)}} pi=P(tokeni∣context)=∑j=1Vexp(zj/T)exp(zi/T)
其中:
- p i p_i pi:第 i i i 个词的概率。
- z i z_i zi:第 i i i 个词的 Logit 值(Linear 层输出)。
- T T T:温度系数(Temperature,默认为 1)。
- V V V:词汇表大小(vocab_size)。
8.3.2. 核心作用
Output Probabilities是Decoder输出处理层的最终产物,直接服务于训练 和推理两大核心场景。
训练阶段:计算损失
模型的训练目标是让 Output Probabilities(输出概率分布) 尽可能接近 真实标签的 One-Hot 分布 (真实 token 的概率为 1,其余为 0)。因此用 交叉熵损失(Cross-Entropy Loss) 衡量差异:
- 设真实标签为第 k k k 个词 → One-Hot 向量 y \mathbf{y} y,满足 y k = 1 y_k = 1 yk=1,其余分量为 0;
- 损失公式:
L = − ∑ i = 1 V y i log ( p i ) = − log ( p k ) L = -\sum_{i=1}^{V} y_i \log(p_i) = -\log(p_k) L=−i=1∑Vyilog(pi)=−log(pk)
(仅真实词对应的项非零,因此简化为 $ -\log(p_k) \)。
说明 :损失值越小,模型预测分布越接近真实标签;通过反向传播,据此更新 Linear 层、Softmax 层及 Decoder 的权重。
推理阶段:生成 token
Output Probabilities 作为 采样策略的输入,决定下一个输出 token:
- 贪心采样(Greedy Sampling) : 选择概率最大的词,即: token = arg max i p i \text{token} = \arg\max_i p_i token=argimaxpi
- 随机采样(Random Sampling): 根据概率分布随机选择词(高概率词更易被选中)。
- 束搜索(Beam Search):维护 "Top-K 个高概率序列" ,逐步扩展生成最优序列。
- Top-K/Top-P 采样:限制采样范围(如 "概率最高的 10 个词" 或 "累积概率达 0.9 的词" ),平衡生成结果的多样性和质量。
关键细节
- 稀疏性 :大词汇表中,Output Probabilities通常稀疏------仅少数词有显著概率(如Top-10词的概率之和可能超90%),其余词概率接近0。
- 动态性:Output Probabilities随Decoder隐藏状态实时变化------每一步生成的token会作为下一步输入,改变隐藏状态,进而改变概率分布(这是序列生成"上下文相关"的核心)。
8.4. 三大组件的协同作用
| 组件 | 核心角色 | 输入 | 输出 | 关键特性 |
|---|---|---|---|---|
| Linear层 | 语义→得分的线性映射 | Decoder隐藏状态 ( h ) | Logits向量 ( z ) | 维度匹配词汇表,权重可共享 |
| Softmax层 | 得分→概率的归一化 | Logits向量 ( z ) | Output Probabilities ( P ) | 数值稳定,满足概率公理 |
| Output Probabilities | 最终的概率分布,生成依据 | Softmax输出 | 概率向量 ( P ) | 非负、归一,对应词汇表每个词 |
Decoder输出处理层的工作流程可总结为语义特征→得分→概率→生成的四步转换:
- 输入 :Decoder最后一层输出隐藏状态 ( h )(抽象语义,如"当前上下文是'我喜欢吃',下一个词可能是食物");
- Linear层 :将 ( h ) 映射为Logits向量 ( z )(如"苹果"得5分,"香蕉"得3分,"汽车"得-2分);
- Softmax层 :将 ( z ) 归一化为Output Probabilities ( P )(如"苹果"概率0.7,"香蕉"0.2,"汽车"0.001);
- 输出 :Output Probabilities ( P ) 作为最终结果,用于训练损失计算 或推理token采样。
五、总结
Transformer架构原理可能很多人觉得比较绕弯弯难以理解,毕竟涉及到很多专业数学理论知识,但如果不是要深入模型算法开发的话,我个人觉得只需要大概了解掌握就行,毕竟大部分人也只是学习了去做应用层开发。这种专业的事情就交给专业的人去做,就像手机电脑,我们不用过多关注手机是怎么做成的,而是我们用他去做什么,关键在于用,所以也不用太担心。