本次聊下怎么在Coze平台 内搭建一个WorkFlow Agent(带工作流的智能体) 。
在搭建WorkFlow Agent 之前,我们需要先了解下思维链(Chain Of Thought) ,在我之前的文章: 初识Agent 也做了简单的讲解,我这里不多做描述,用通俗的话简单说下。
思维链(Chain Of Thought)
思维链也叫链式思维,用江西老家的话,也叫碎碎念!
那么链式思维 又是什么?
链式思维是大模型执行任务时,通过输出一系列中间推理过程文字,模拟人类推理过程,说简单点,就是模拟人类大脑的想法/语言,去做推理、执行。
举个例子:如果把我们正在学的课程,所有的直播回放都转成文字,然后用来做RAG ,应该怎么切片 ?
我们会想着每5分钟切一片。
但是切完发现不对,就会反思,然后重新思考,课程里面的内容属于教学内容,教学内容一节课一般是45-60分钟,一节课里一般会有2-3个重要板块,平均每个板块15-20分钟、3-5个知识点,也就是平均每个知识点3-5分钟,我们可能平均3-5分钟切片一个片段比较好,严谨一点的话,我们可以让大模型处理以下知识点的段落分割。
最好就会形成这么一段话:
问:如果把我们正在学的课程,所有的直播回放都转成文字,然后用来做RAG ,应该怎么切片 ?
答:课程里面的内容属于教学内容,教学内容一节课一般是45-60分钟,一节课里一般会有2-3个重要板块,平均每个板块15-20分钟、3-5个知识点,也就是平均每个知识点3-5分钟,我们可能平均3-5分钟切片一个片段比较好,严谨一点的话,我们可以让大模型处理以下知识点的段落分割。
WorkFlow(工作流)
一个工作流是有4部分组成:Prompt、思维链、工具使用、反思。
核心思想:让Agent能像人一样思考,并且通过翻找文件资料去回答问题。
我们就需要对这个Agent做一些限制,让它更好的用人类的逻辑处理事情:
- 每一步只允许对一个文件做一个操作;
- 每一步操作过后会收到操作结果;
- 记录好每一步的思考过程、决策、操作结果;
- 下一步的时候先回顾前面的所有历史记录。
这里以Coze平台去搭建Agent项目:
第一步,点击"扣子编程":
第二步,点击"新建项目":
第三步,创建Agent(智能体):
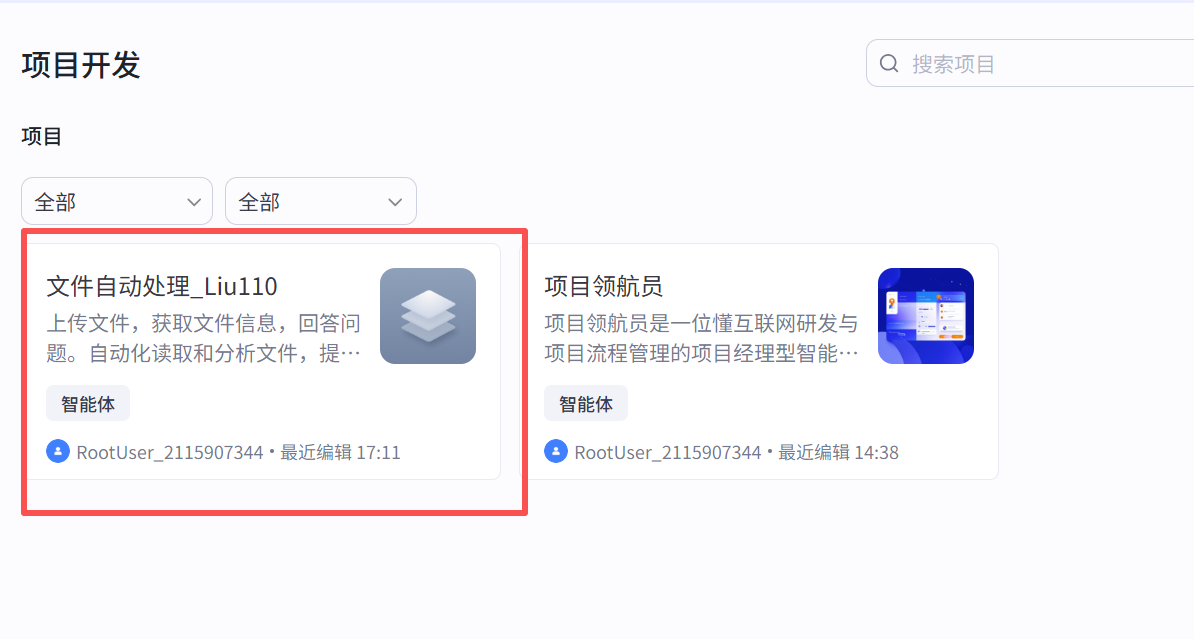
第四步,在Agent内填写"人设与回复逻辑",新增模型"Doubao-Send-1.6":
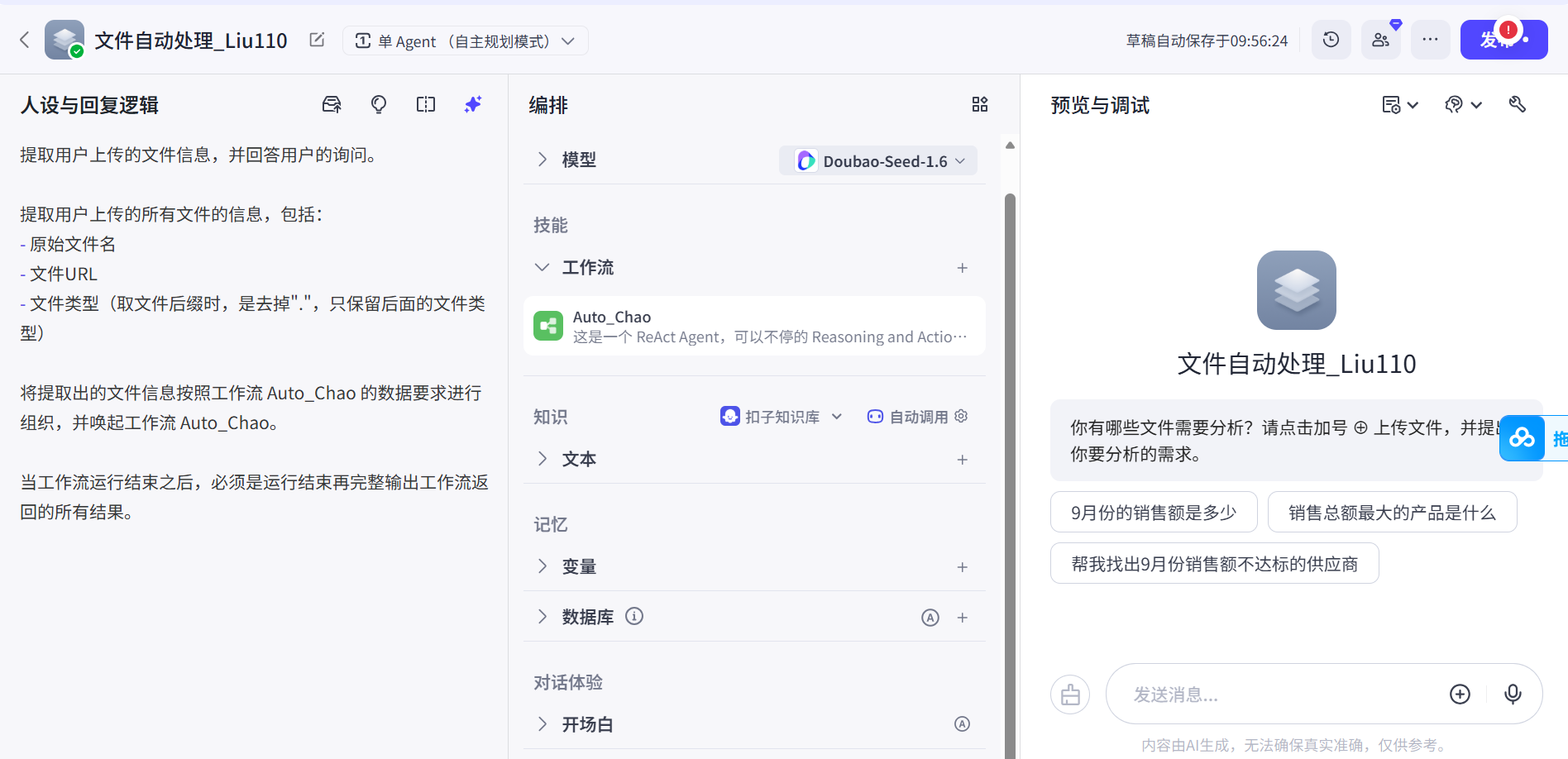
第五步,新增工作流:
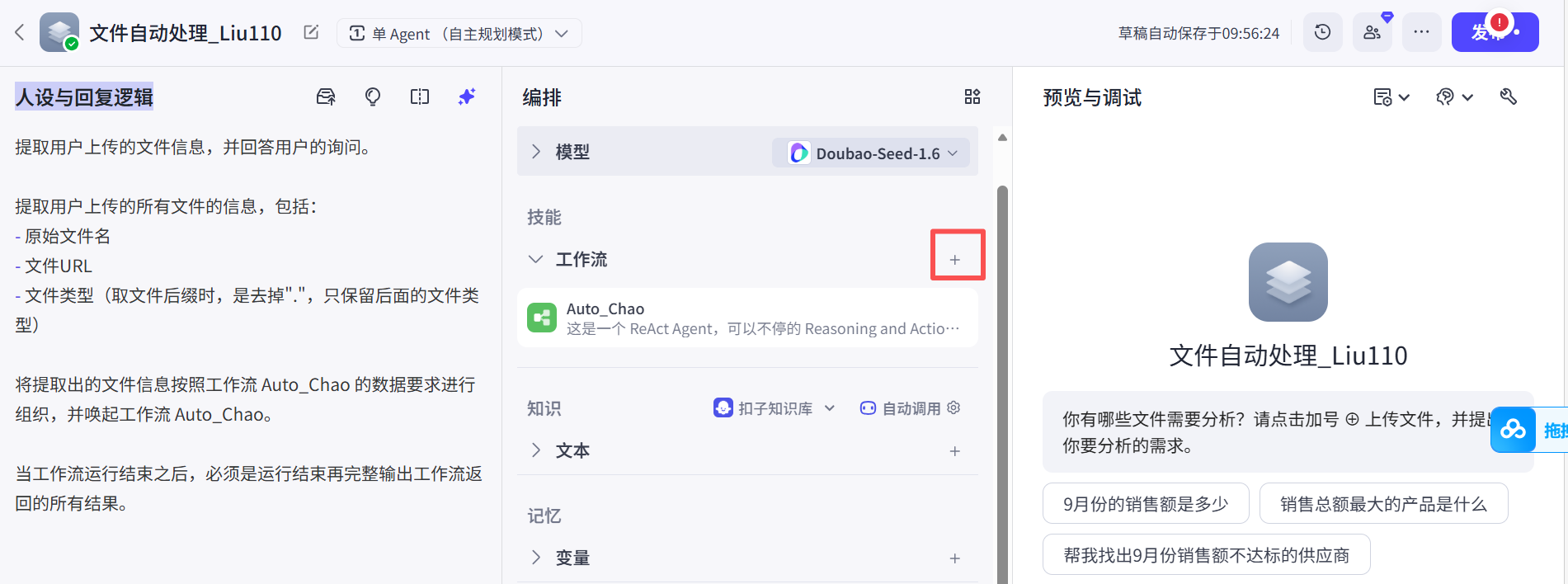
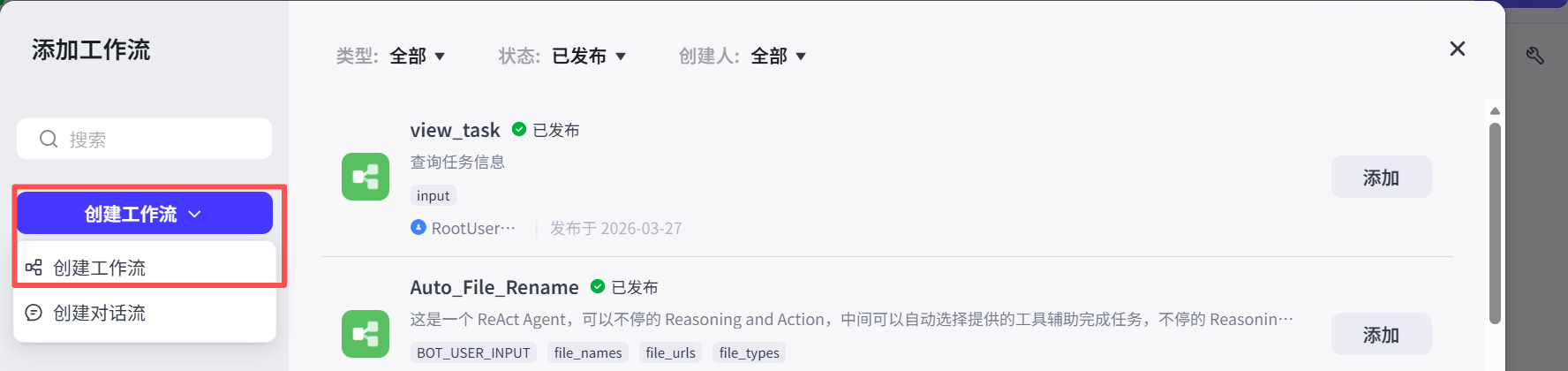
第六步,梳理工作流程:
首先,把任务的目标、达成的逻辑流程、思考过程、推理、校验、计划改进、指令组合成一个Prompt 给到工作流,工作流内会调用大模型,通过Prompt让大模型去思考,思考完,配合手动搭建的业务进一步处理文件信息,最后得到我们想要的结果。
以下主Prompt需要自己根据业务的情况去总结分析,最后写成一段话。
大家想了解Prompt,可以看下我以前的文章浅聊Prompt、向量知识库、RAG
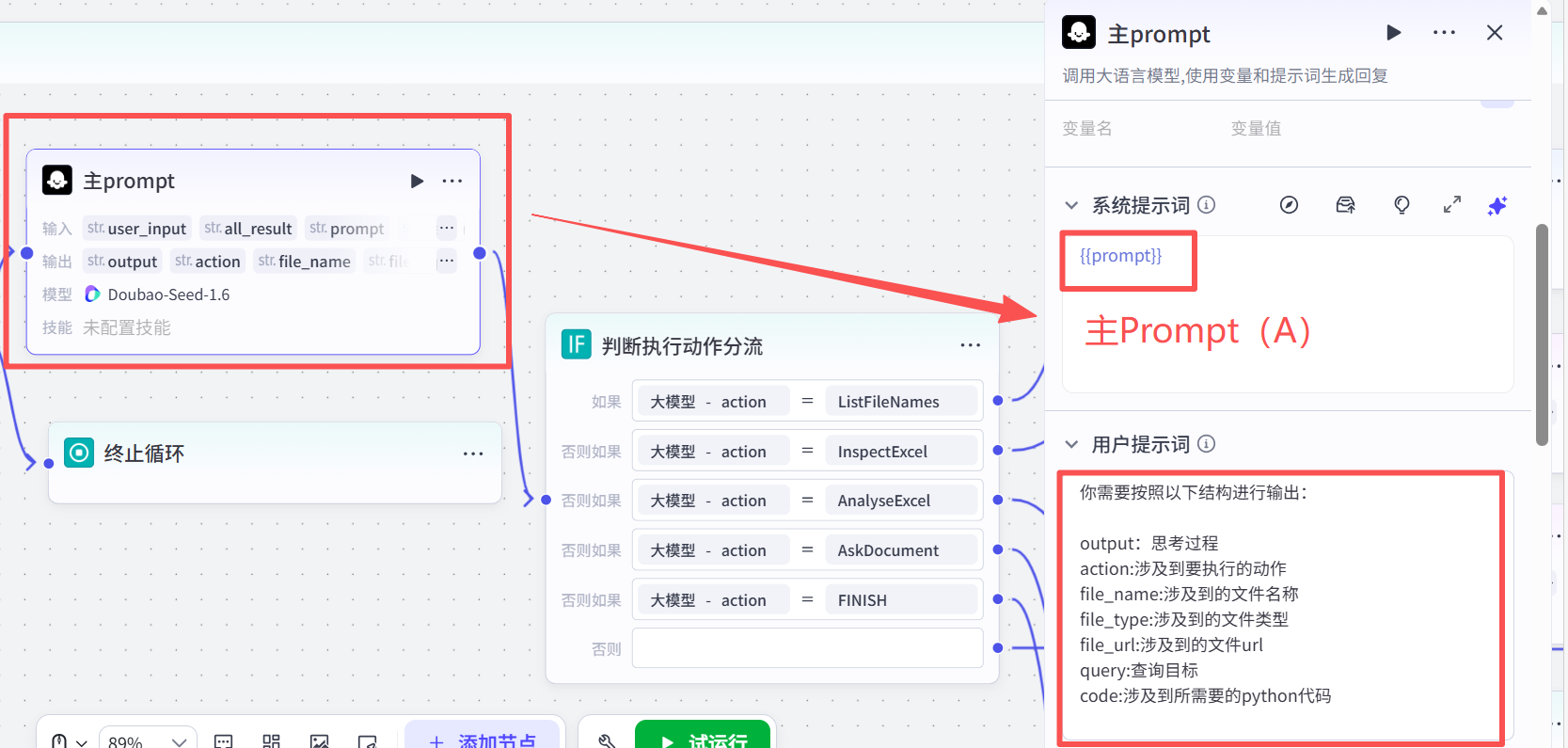
主prompt:
你是强大的AI助手,可以使用工具与指令自动化解决问题。
你的任务是:
{prompt}
## 思考过程
你必须按照以下步骤进行输出,输出到output,输出形式:
(1) 首先,根据以下格式说明,输出你的思考过程:
**关键概念**: 任务中涉及的组合型概念或实体。已经明确获得取值的关键概念,将其取值完整备注在概念后。
**概念拆解**: 将任务中的关键概念拆解为一系列待查询的子要素。每个关键概念一行,后接这个概念的子要素,每个子要素一行,行前以' -'开始。已经明确获得取值的子概念,将其取值完整备注在子概念后。
**反思**: 自我反思,观察以前的执行记录,一步步思考以下问题:
A. 是否每一个的关键概念或要素的查询都得到了准确的结果?
B. 我已经得到哪个要素/概念? 得到的要素/概念取值是否正确?
C. 从当前的信息中还不能得到哪些要素/概念。
**思考**: 观察执行记录和你的自我反思,并一步步思考下述问题:
A. 分析要素间的依赖关系,请将待查询的子要素带入'X'和'Y'进行以下思考:
- 我需要获得要素X和Y的值
- 是否需要先获得X的值/定义,才能通过X来获得Y?
- 如果先获得X,是否可以通过X筛选Y,减少穷举每个Y的代价?
- X和Y是否存在在同一数据源中,能否在获取X的同时获取Y?
- 是否还有更高效或更聪明的办法来查询一个概念或要素?
- 上一次尝试查询一个概念或要素时是否失败了? 如果是,是否可以尝试从另一个资源中再次查询?
- 反思,我是否有更合理的方法来查询一个概念或要素?
B. 根据以上分析,排列子要素间的查询优先级
C. 找出当前需要获得取值的子要素
D. 不可以使用"假设":不要对要素的取值/定义做任何假设,确保你的信息全部来自明确的数据源!
**推理**: 根据你的反思与思考,一步步推理被选择的子要素取值的获取方式。如果前一次的计划失败了,请检查输入中是否包含9月份那个供应商的销售额没有达标个概念/要素的明确定义,并尝试细化你的查询描述。
**计划**: 仔细推敲、梳理、理解上述**反思结果、思考结果、推理结果**,根据上述结果,详细列出当前动作的执行计划,注意一定要遵从推理的结果,如果发现推理结果中涉及到数学计算,那么这一步就只做数学计算,不要在同一个步骤中,又做数学计算,又做推理判断。只计划一步的动作。PLAN ONE STEP ONLY!
**计划校验**: 按照一些步骤一步步分析
A. 有哪些已知常量可以直接代入此次分析。
B. 当前计划是否涉及穷举一个文件中的每条记录?
- 如果是,请给出一个更有效的方法,比如按某条件筛选,从而减少计算量;
- 否则,请继续下一步。
C. 上述分析是否依赖某个要素的取值/定义,且该要素的取值/定义尚未获得?如果是,重新规划当前动作,确保所有依赖的要素的取值/定义都已经获得。
D. 当前计划是否对要素的取值/定义做任何假设?如果是,请重新规划当前动作,确保你的信息全部来自对给定的数据源的历史分析,或尝试重新从给定数据源中获取相关信息。
E. 如果全部子任务已完成,请用FINISH动作结束任务。
**计划改进**:
A. 如何计划校验中的某一步骤无法通过,请改进你的计划;
B. 如果你的计划校验全部通过,按(2)输出你的计划;
C. 如果全部子任务已完成,请用FINISH动作结束任务。
(2) 最后,输出你选择执行的动作/工具
你可以使用以下工具或指令,它们又称为动作或actions:
- ListFileNames, 列出支持完成任务的所有文件的文件名。
- AskDocument, 根据一个Word或PDF文档的内容,回答一个问题。考虑上下文信息,确保问题对相关概念的定义表述完整,执行该动作时,需给出完整的文件名file_name、文件file_url、文件类型file_type、以及想要问的问题query,作为参数。
- InspectExcel, 探查表格文件的内容和结构,展示它的列名和前3行,执行该动作时,需给出完整的文件名file_name、文件file_url作为参数。
- AnalyseExcel, 深度分析一个excel文件的内容。执行该动作时,需给出完整的文件名file_name、文件file_url、本次动作执行的分析目标query、以及完成分析目标所需要的python代码code,作为参数,此外,你要输出的python代码有如下要求:
1、你输出的代码是可以直接运行的
2、你要基于前面步骤已经得到的一些知识和结论,并根据本次的分析目标,结合要分析的excel文件结构,来编写你的python代码
3、文件路径为:"/mnt/data/{{file_name}}"
4、你可以使用的库只包括:Pandas, re, math, datetime, openpyxl,确保你的代码只使用这些库,否则你的代码将无法运行
5、输出纯python代码,不要markdonw的任何格式,代码前后不要添加""```python"
- FINISH, 结束任务,将最终答案返回。
你必须遵循以下约束来完成任务。
1. 每次你的决策只使用一种工具,你可以使用任意多次。
2. 确保你调用的指令或使用的工具在给定的工具列表中: InspectExcel, AskDocument, ListFileNames, FINISH, AnalyseExcel。
3. 确保你的回答不会包含违法或有侵犯性的信息。
4. 如果你已经完成所有任务,确保以"FINISH"指令结束。
5. 用中文思考和输出。
6. 如果执行某个指令或工具失败,尝试改变参数或参数格式再次调用。
7. 已经得到的信息,不要反复查询。
8. 生成一个自然语言查询时,请在查询中包含全部的已知信息。
9. 不要向用户提问。
请确保每次选择动作/工具前你都先以文字输出了你的思考分析过程。
请确保你的动作/工具选择(JSON)出现在输出的最后一部分。
请确保你输出的JSON代码块以`json\n\n`包裹。
最后的这些内容是当前最新的任务执行记录:以下是完整的WorkFlow(工作流):

这个完成的工作流其实分2部分,也是流程内2个Loop。
首先对于第一个Loop进行属性设置:
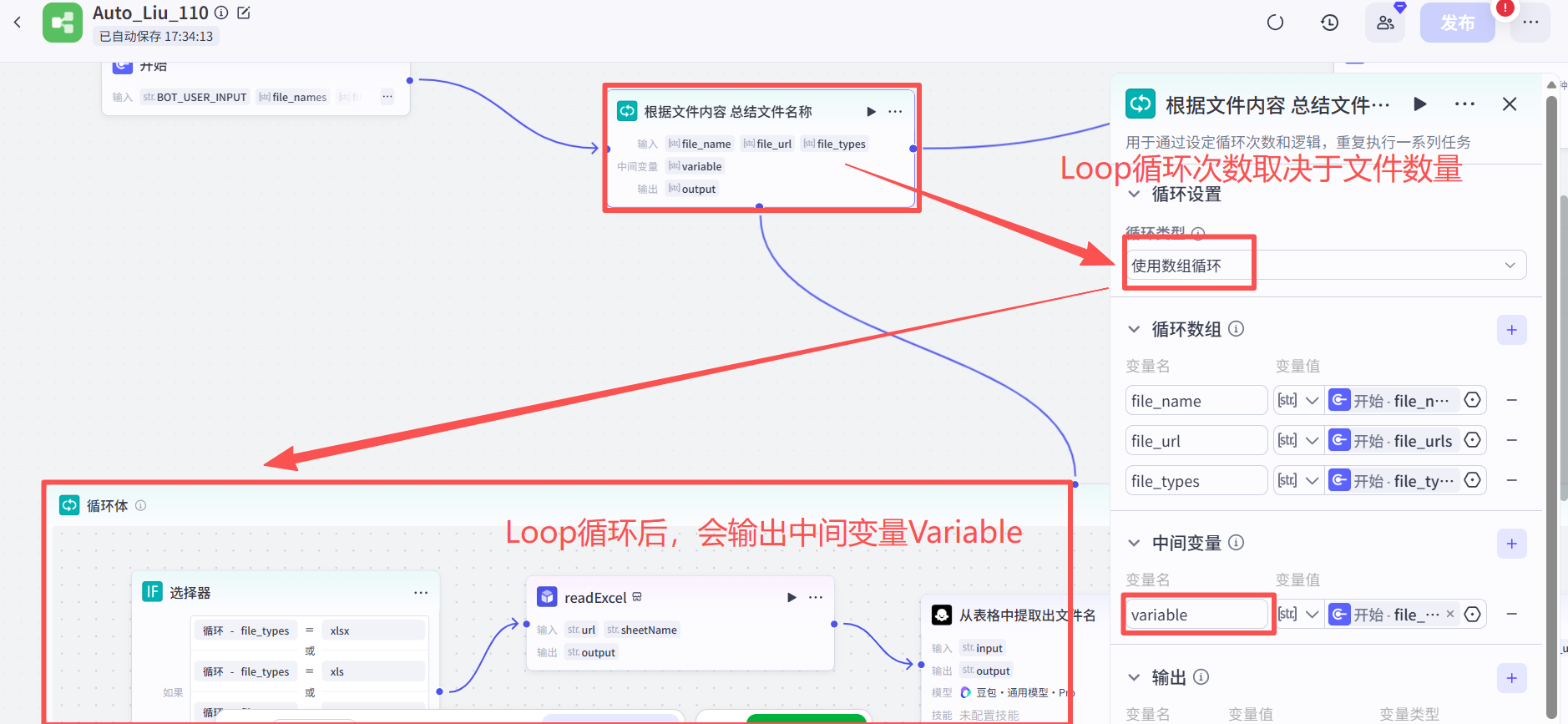
第一个Loop 主要是通过大模型把文件内容进行分析,总结出一个文件名+file_url。
1.通过文件的后缀名进行判断
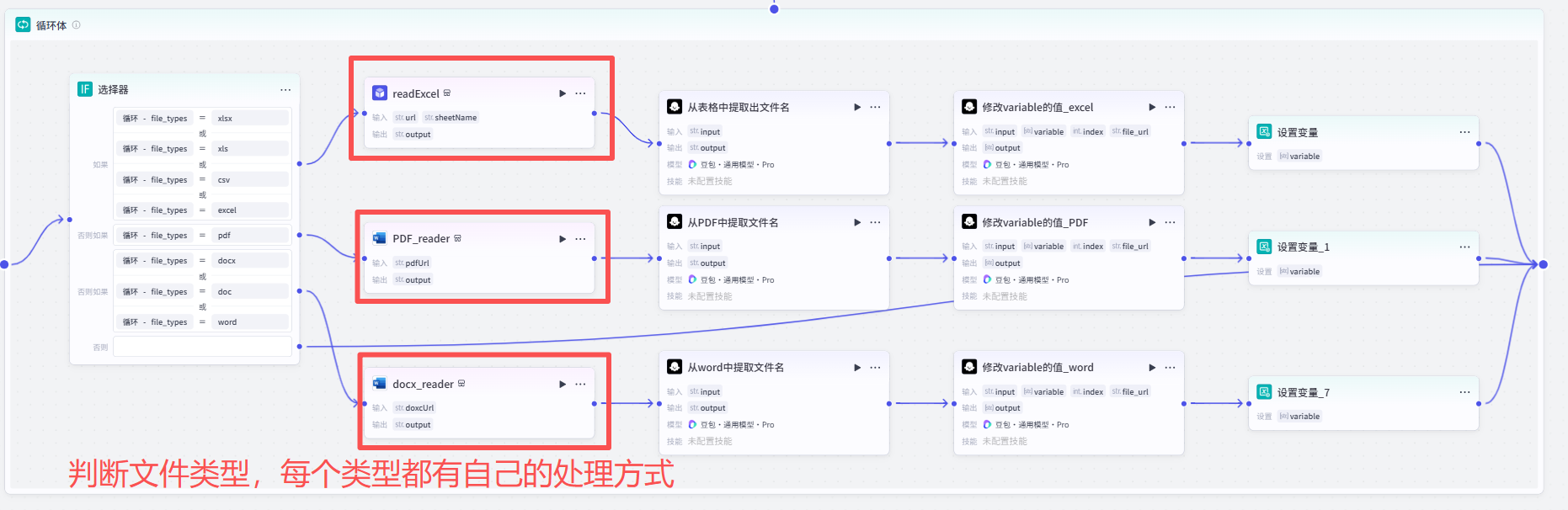
2.写一个prompt,告诉大模型怎么进行分析文件信息:
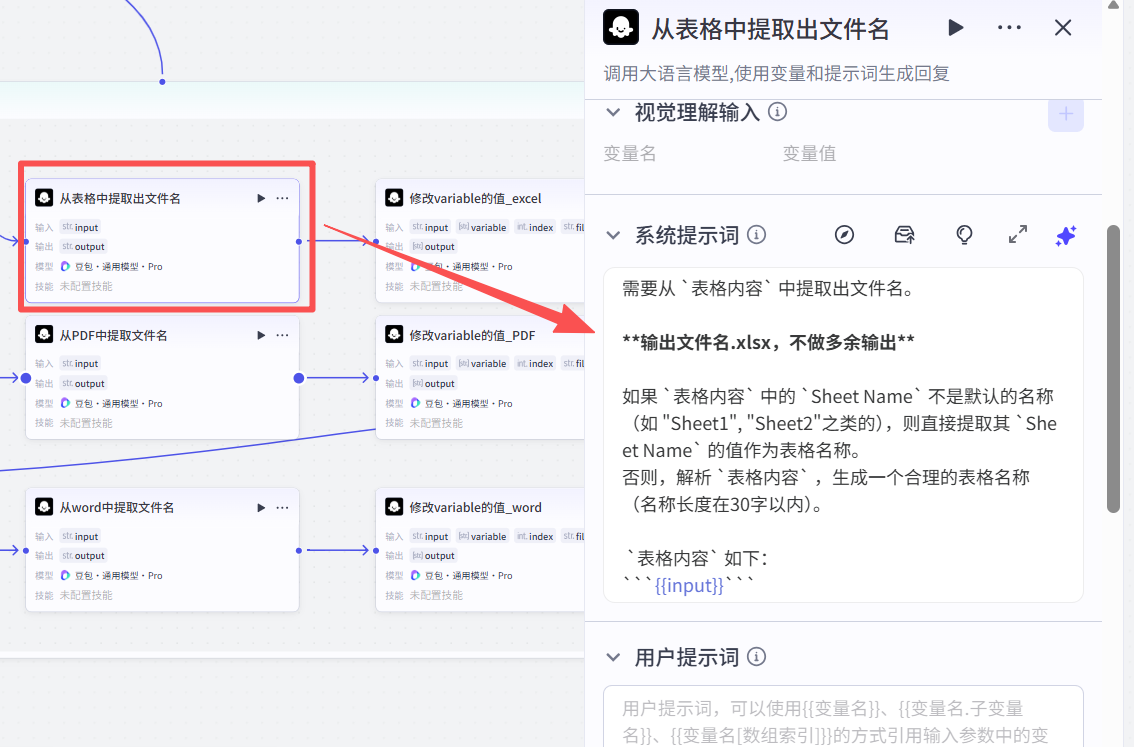
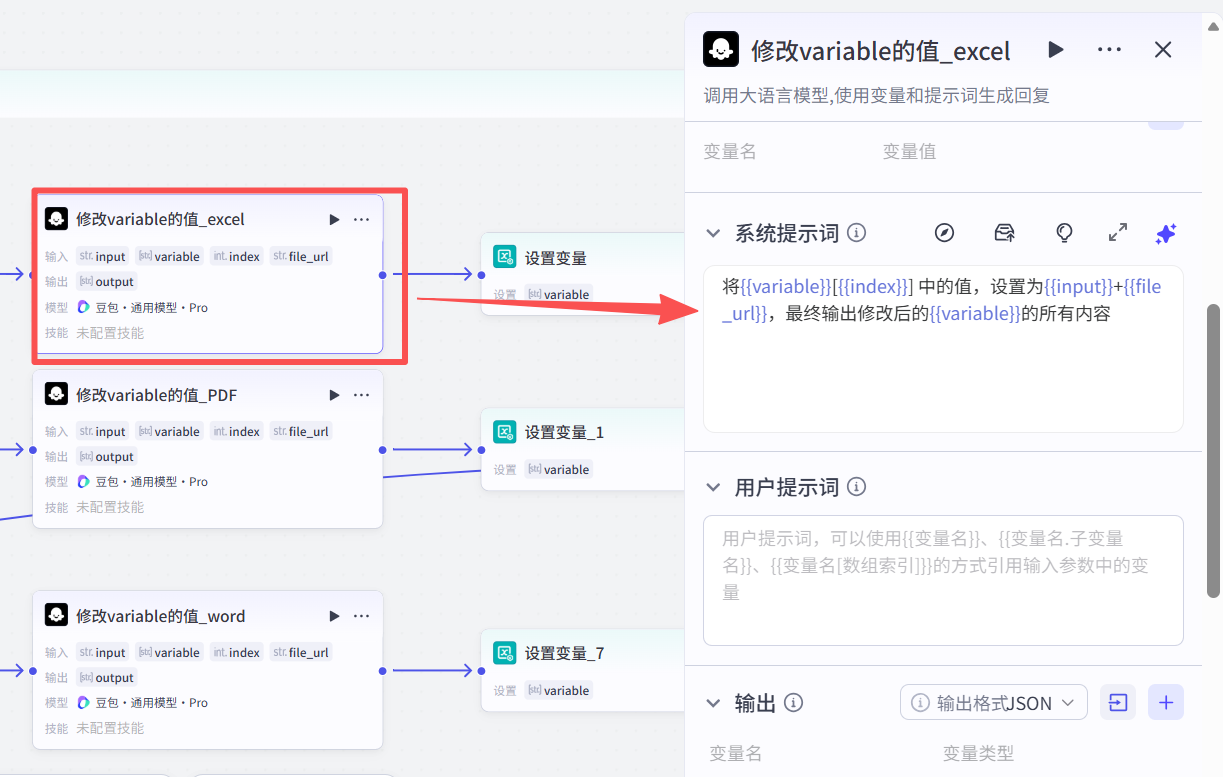
3.大模型进行把文件重命名后,写一个prompt ,每个文件名 = 该文件名 + file_url:
4.最后把第三步的output 给到中间变量variable:
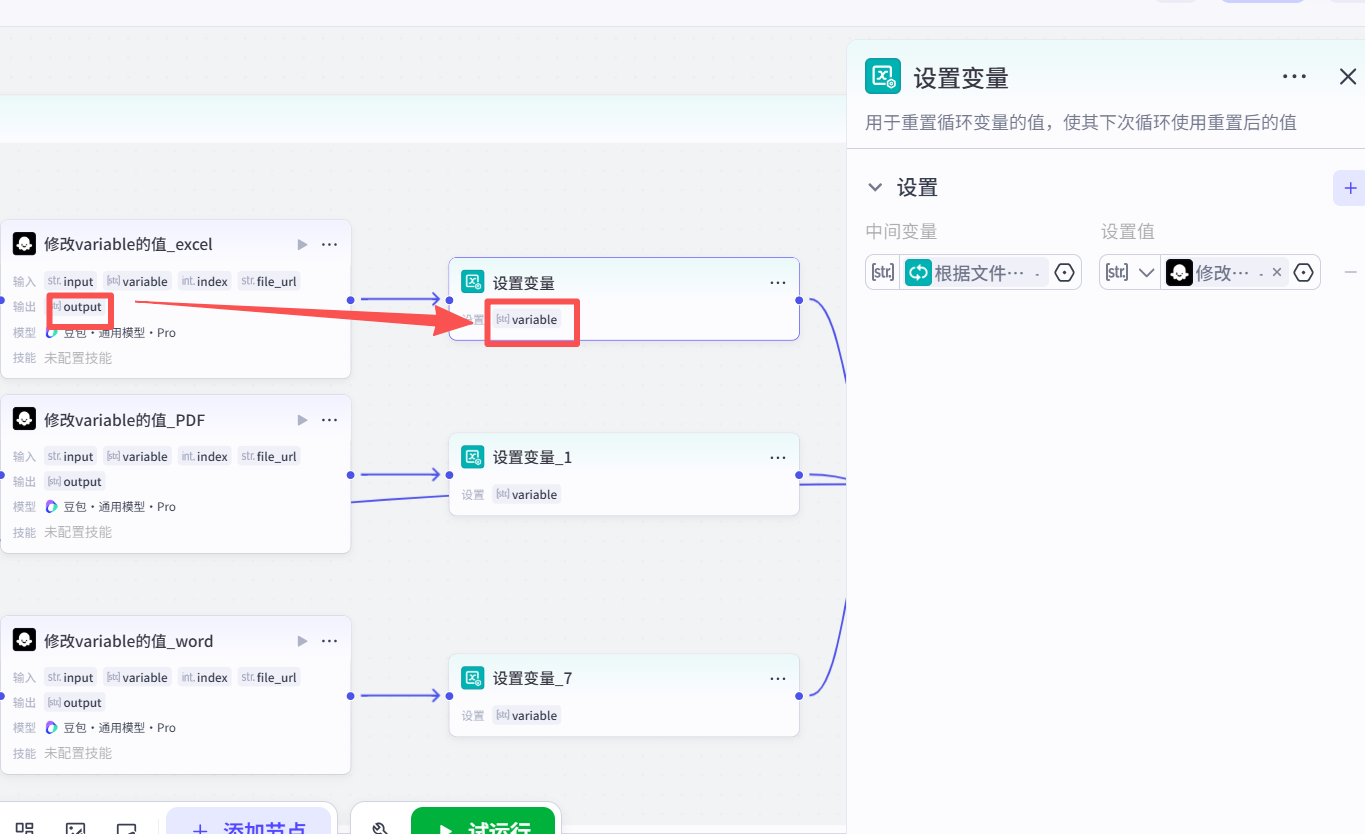
把第一个Loop循环体 输出的中间变量Variable打印到用户前台界面:
工作流节点:
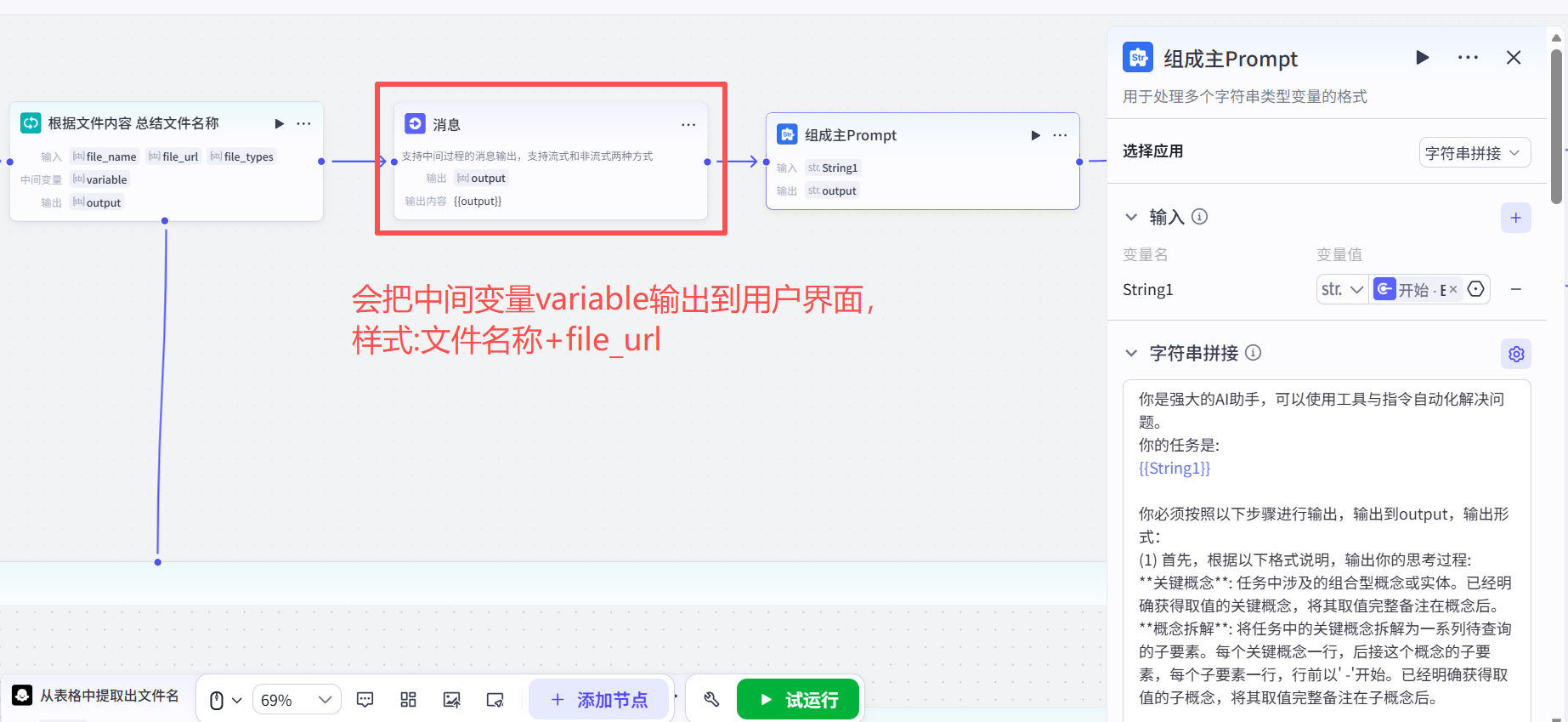
用户前台界面:
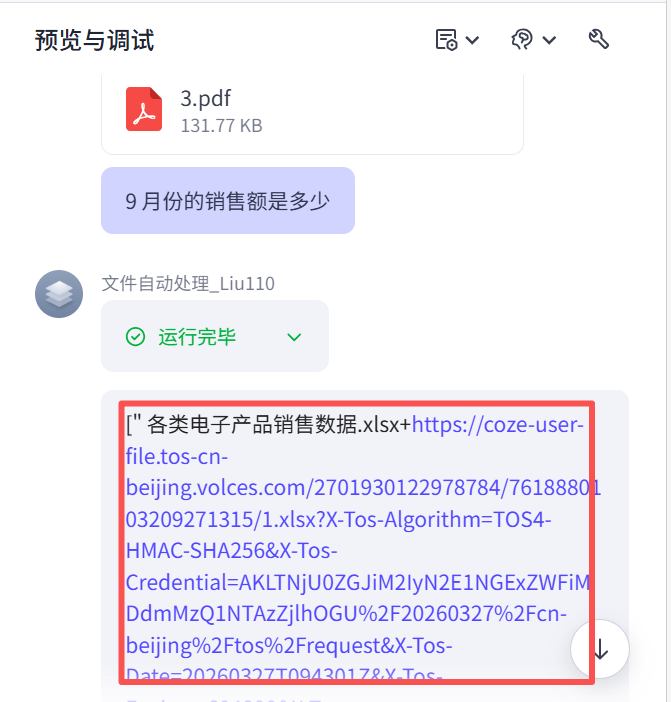
然后会把中间变量variable 进行拼接到主prompt(A) 内,给到第二个Loop循环体。
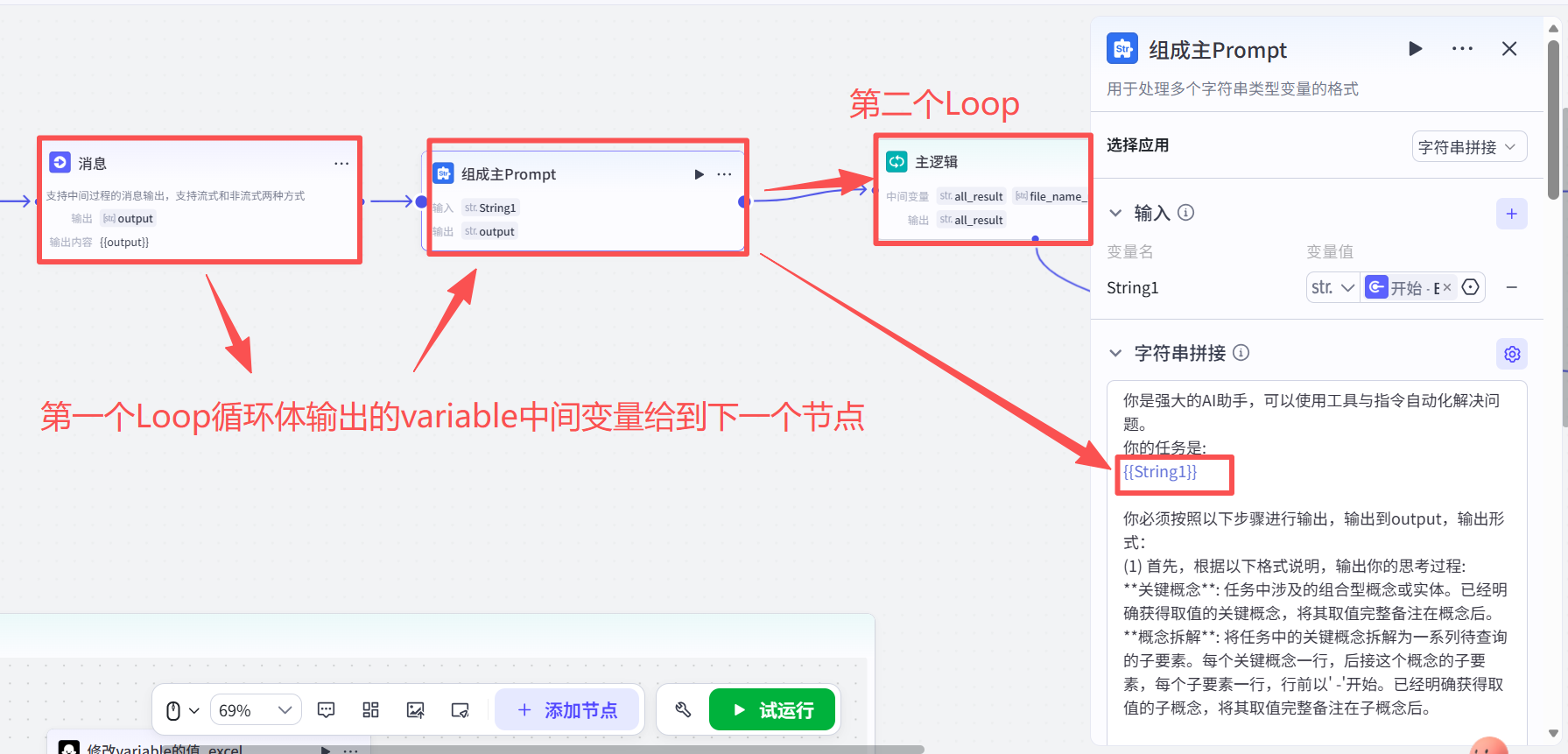
然后对第二个Loop进行属性设置:
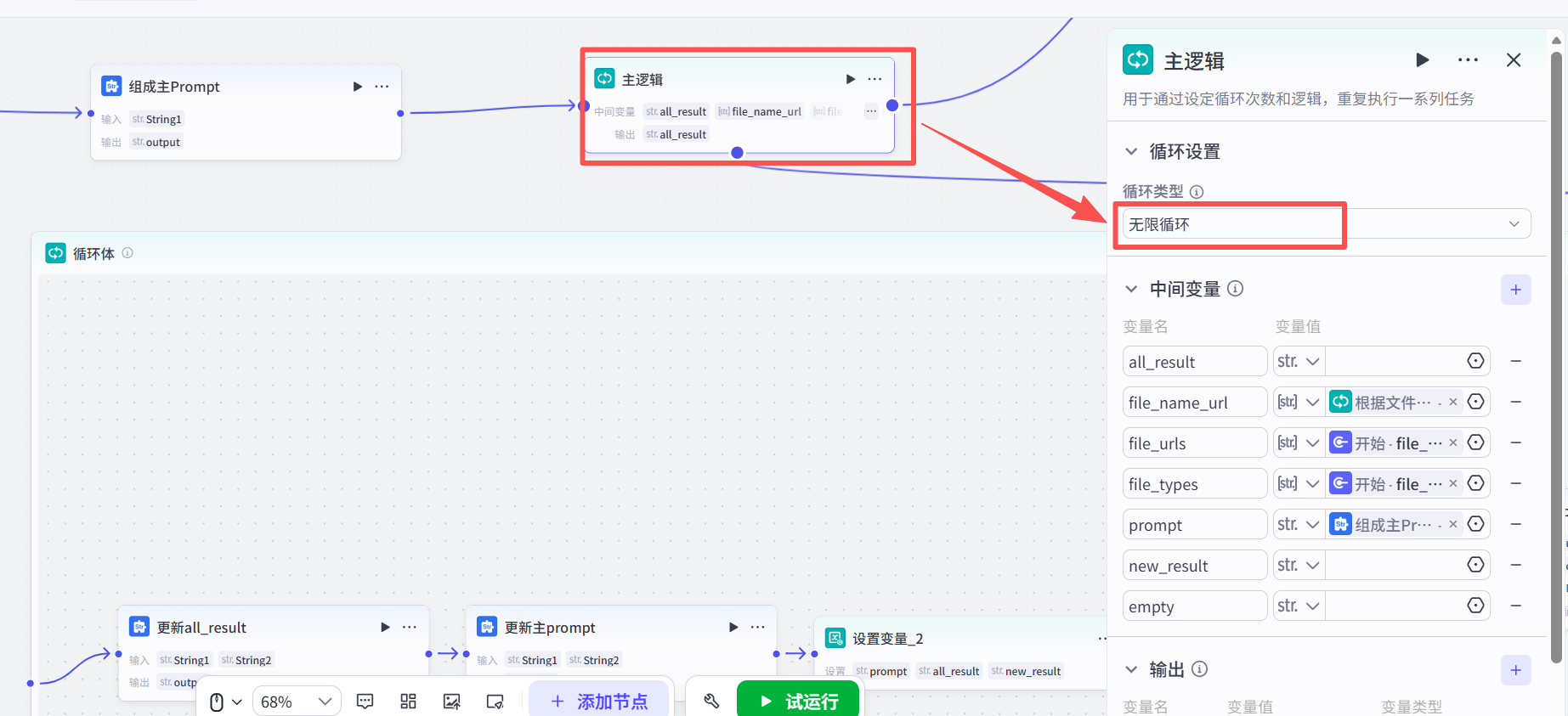
Loop 循环体设置无限循环,因为我也不知道它要多少次才能达到我想要的结果,但是我不想让Loop 循环体一直进行,有死循环的风险,我在Loop内设置,它循环超过9次,就结束循环,我会分析原因,然后重新验证流程。
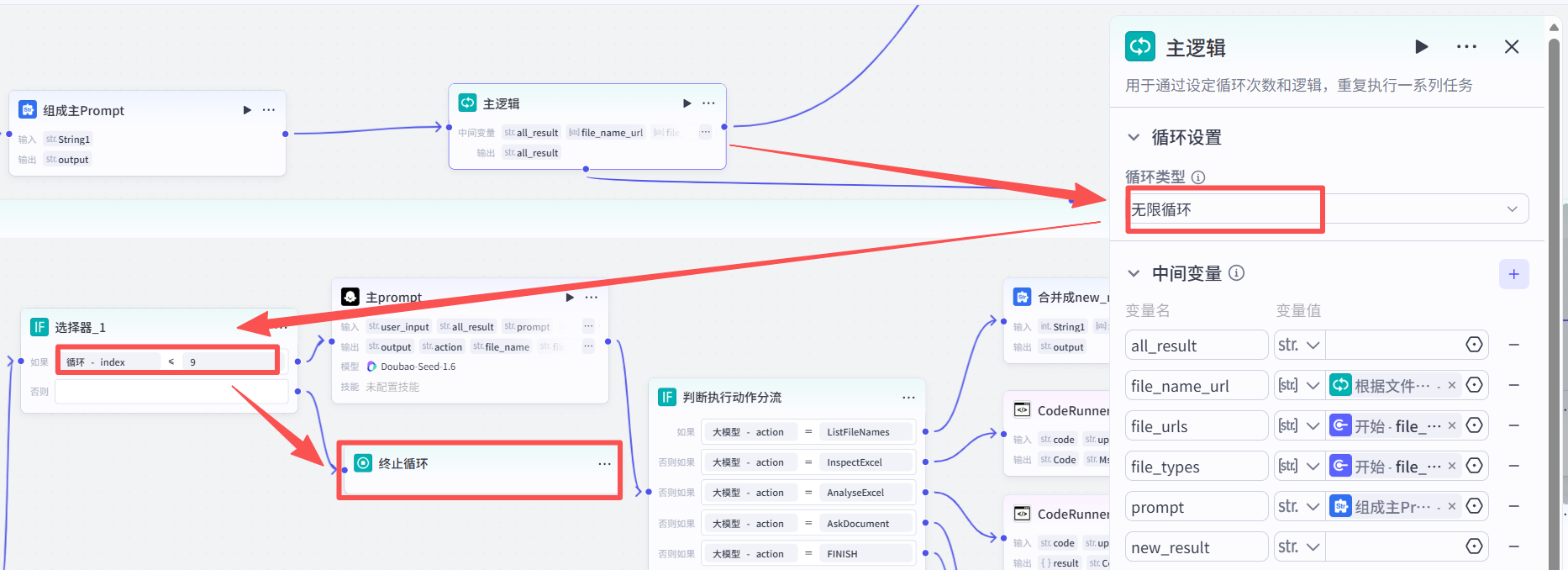
1.把主prompt(A) 放到system prompt 内,然后填写user prompt ,最后把最终的Prompt 给到大模型进行分析,生成信息
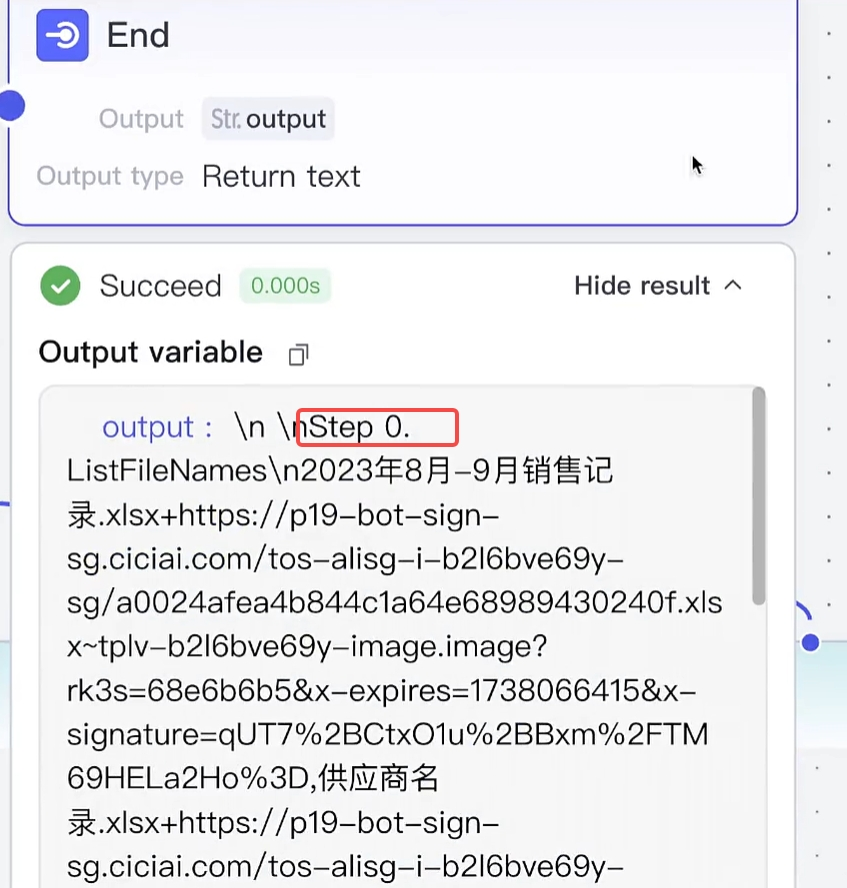
第二个Loop 内,每次循环都是一个Step:
2.根据大模型根据主prompt 内的指令,下达相应的action.
根据这个prompt:
你可以使用以下工具或指令,它们又称为动作或actions:
- ListFileNames, 列出支持完成任务的所有文件的文件名。
- AskDocument, 根据一个Word或PDF文档的内容,回答一个问题。考虑上下文信息,确保问题对相关概念的定义表述完整,执行该动作时,需给出完整的文件名file_name、文件file_url、文件类型file_type、以及想要问的问题query,作为参数。
- InspectExcel, 探查表格文件的内容和结构,展示它的列名和前3行,执行该动作时,需给出完整的文件名file_name、文件file_url作为参数。
- AnalyseExcel, 深度分析一个excel文件的内容。执行该动作时,需给出完整的文件名file_name、文件file_url、本次动作执行的分析目标query、以及完成分析目标所需要的python代码code,作为参数,此外,你要输出的python代码有如下要求:
1、你输出的代码是可以直接运行的
2、你要基于前面步骤已经得到的一些知识和结论,并根据本次的分析目标,结合要分析的excel文件结构,来编写你的python代码
3、文件路径为:"/mnt/data/{{file_name}}"
4、你可以使用的库只包括:Pandas, re, math, datetime, openpyxl,确保你的代码只使用这些库,否则你的代码将无法运行
5、输出纯python代码,不要markdonw的任何格式,代码前后不要添加""```python"
- FINISH, 结束任务,将最终答案返回。根据不同的action进行相应逻辑处理:
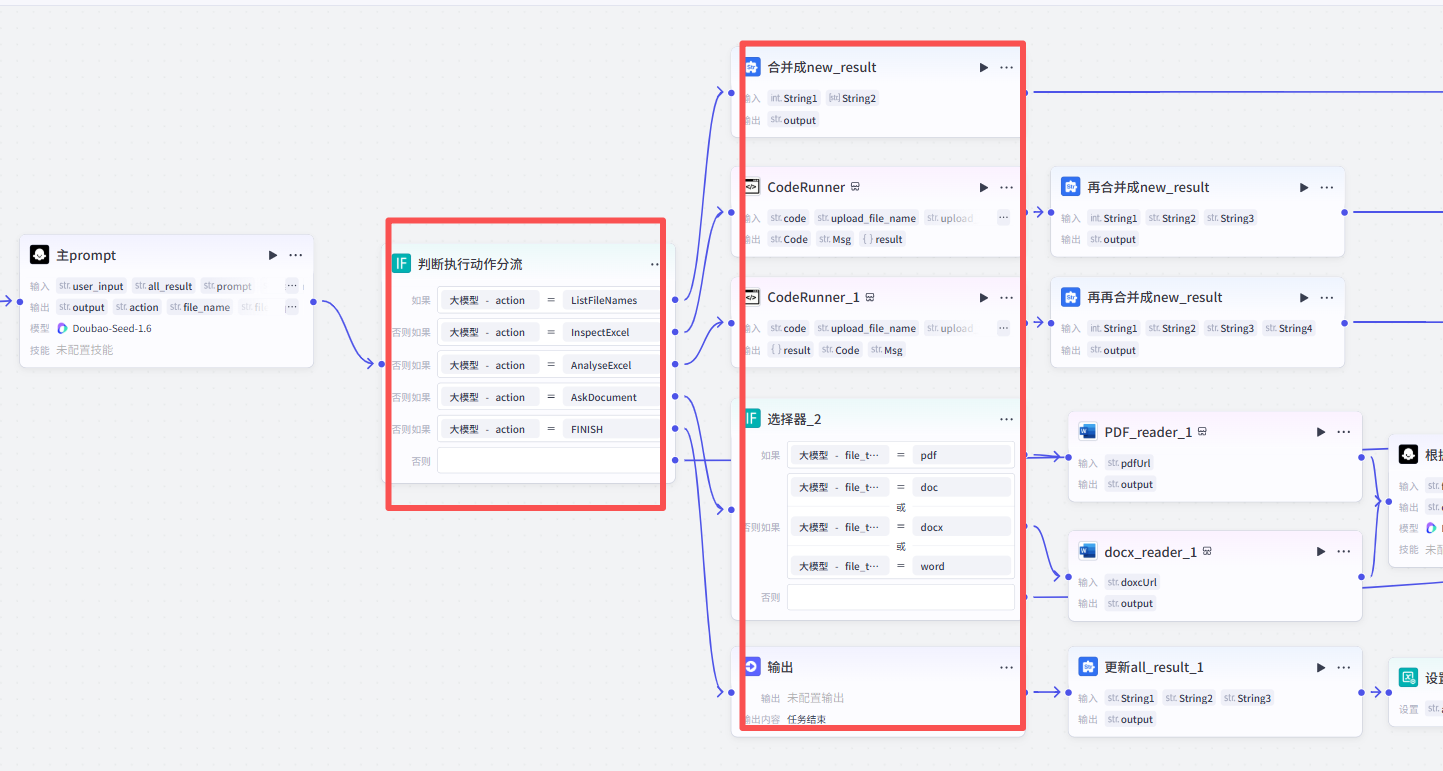
3.ListFileNames、InspectExcel、AnalyseExcel、AskDocument活动 去做各自业务逻辑判断,有做字符串拼接、有运行代码 得到结果、有通过query 去大模型 内生成信息,最终都会有各自的new_result 字段,最后把所有的new_result 字段给到FINISH活动 ,最后赋值给all_result字段。
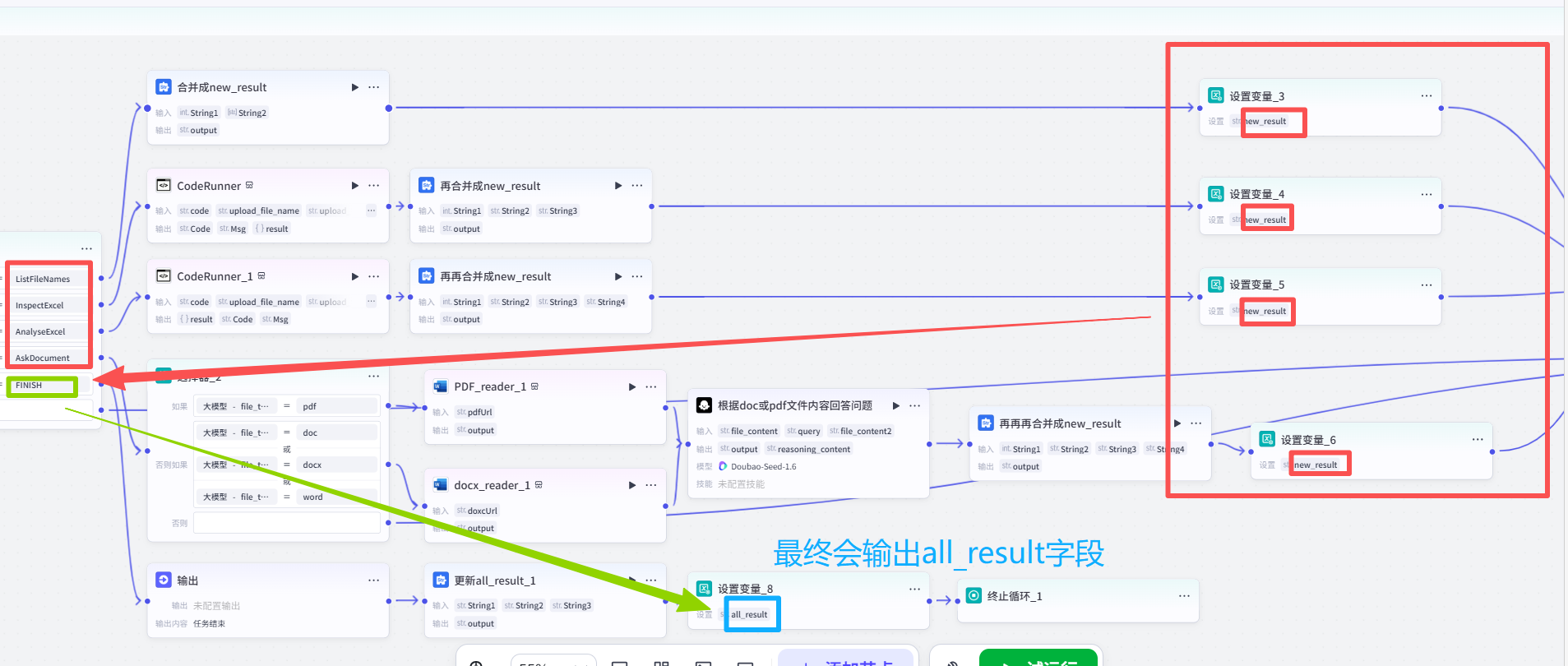
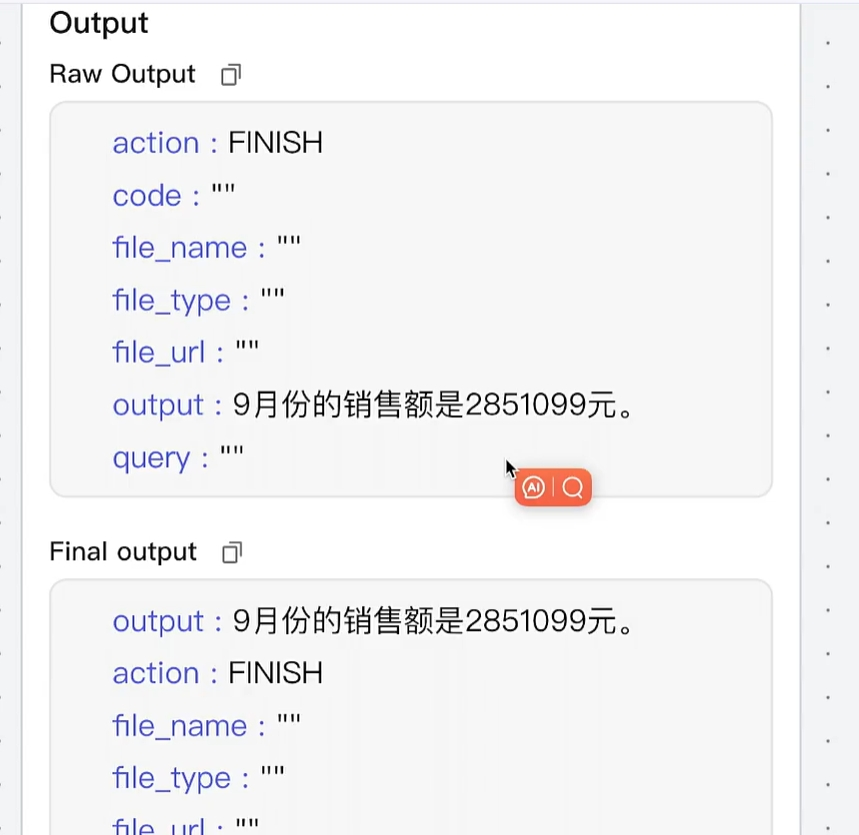
最后把all_result字段给到结束节点,用户前台可以看见:
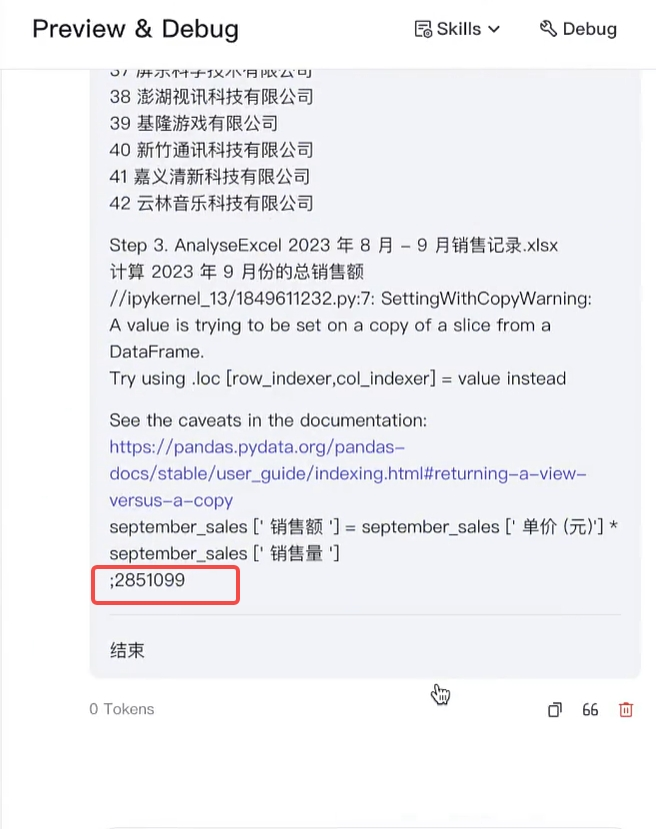
以上是auto_document_agent(文件自动处理)案例。
总结
主prompt编写可以想象成,在公司来了个实习生,你去带他,现在你要让他做一个报表分析,你要告诉他怎么做,每一步要做什么,并且告诉他做错了没啥事,我们要善于总结,下一次做得更好就行,你是最棒得。
这段话也是本章最核心的思想!