一句话总结:南京大学团队提出CompactRAG,通过"离线预处理+轻量推理"的双阶段架构,将多跳问答的LLM调用次数固定在2次,大幅降低token消耗的同时保持准确率。
为什么多跳问答"烧钱"?
多跳问答(Multi-hop QA)需要模型跨文档推理,比如回答"发现青霉素的科学家出生在哪里",得先找到"弗莱明",再查他的出生地。传统迭代式RAG(如Self-Ask、IRCoT)每跳都要调用LLM检索和推理,导致三个痛点:
-
成本随跳数线性增长:2跳问题调2次,4跳就调4次,token账单爆炸
-
实体漂移:子问题如"他出生在哪里?"缺少指代实体,容易检索跑偏
-
冗余信息:原始文档段落长、噪音多,检索效率低
现有解法要么需要模型内部信号(如注意力熵),对闭源模型不友好;要么仍需多次LLM调用,治标不治本。
核心思路:把重活挪到离线
论文提出"离线重构知识库,在线轻量推理"的解耦架构,像把图书馆整理和读者咨询分开:
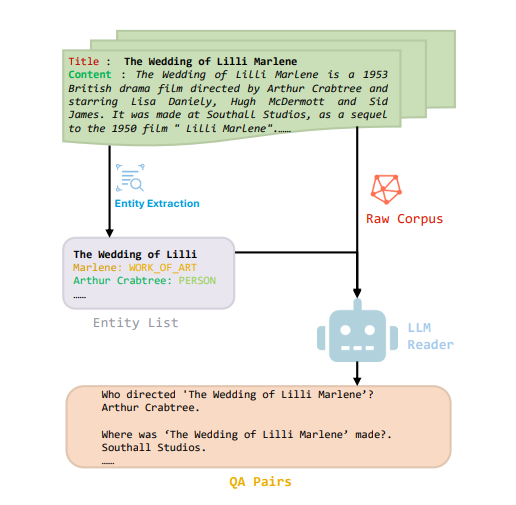
🔧 离线阶段:一次LLM调用,构建原子化QA知识库
用LLM(如GPT-4或LLaMA-3.1-8B)通读全文,将文档转化为细粒度QA对。例如:
- 原文:"《Lilli的婚姻》是1919年德国无声电影,由Jaap Speyer执导,是电影《Lilli》的续集"
- 转化为:
- Q: "谁执导了《Lilli的婚姻》?" A: "Jaap Speyer"
- Q: "《Lilli的婚姻》是哪一年的电影?" A: "1919年"
关键设计:
- 强制使用SpaCy提取的实体名,避免遗漏关键指代
- 问答对拼接编码(q;a),提升语义检索匹配度
- 一次预处理,永久使用,成本随查询量摊薄
⚡ 在线阶段:固定2次LLM调用,轻量模块接力
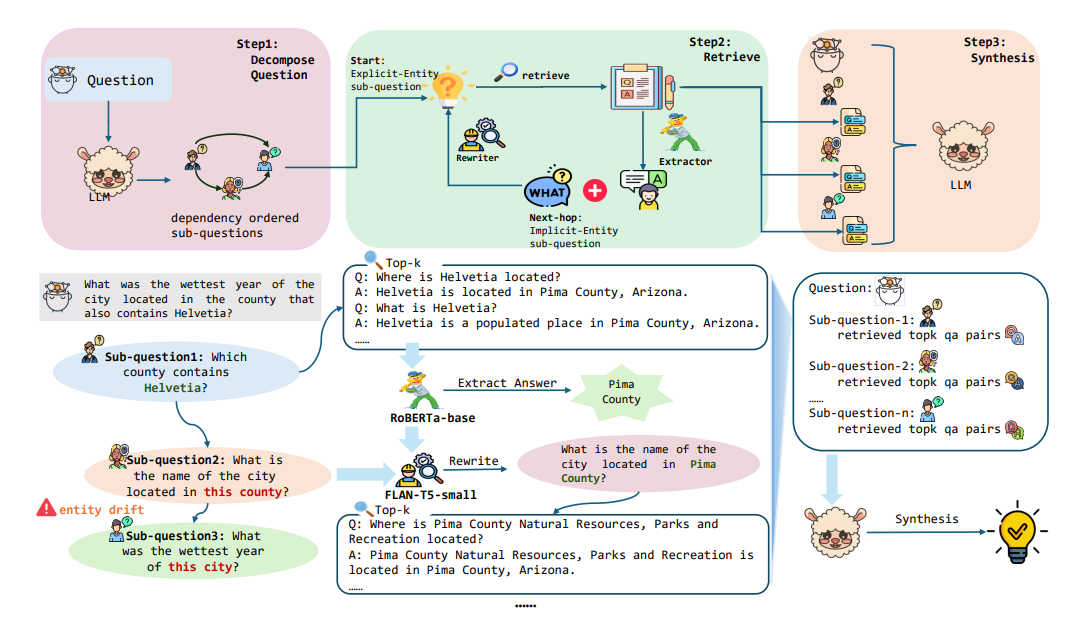
复杂查询的处理流程:
-
第1次LLM调用:分解问题为依赖子问题图(如"发现青霉素的科学家→出生地")
-
轻量模块迭代处理(无需LLM):
- Answer Extractor(RoBERTa-base,125M参数):从检索的QA对中提取答案片段
- Sub-Question Rewriter(Flan-T5-small,80M参数):将"他出生在哪里?"重写为"亚历山大·弗莱明出生在哪里?",解决实体漂移
- 第2次LLM调用:汇总所有子问题答案,生成最终回复
无论问题多复杂,LLM只调2次------一次分解,一次综合。
实验结果:省钱不降质
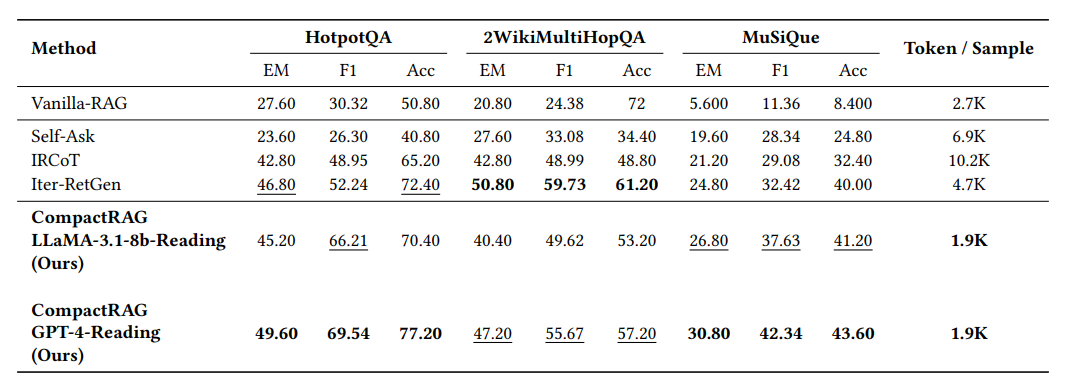
在HotpotQA、2WikiMultiHopQA、MuSiQue三大基准测试:
| 方法 | HotpotQA准确率 | 平均Token/查询 |
|---|---|---|
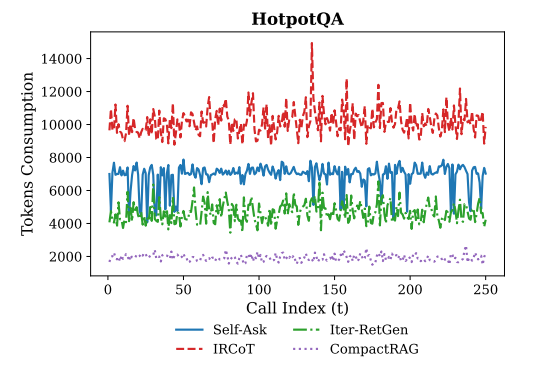
| IRCoT(迭代式) | 65.2% | 10.2K |
| Iter-RetGen(迭代式) | 72.4% | 4.7K |
| CompactRAG(LLaMA-8B) | 70.4% | 1.9K |
| CompactRAG(GPT-4离线) | 77.2% | 1.9K |
核心发现:
- Token效率:比IRCoT省81%,比Iter-RetGen省60%
- 准确率:用LLaMA-3.1-8B即可接近或超越迭代式基线,换GPT-4构建知识库还能再提升
- 可扩展性:查询量越大,离线成本摊得越薄,长期优势越明显
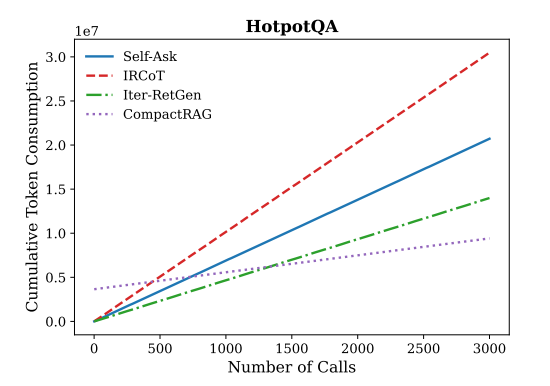
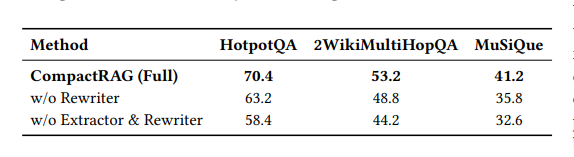
消融实验
证明两个轻量模块缺一不可:
- 去掉Rewriter:实体漂移导致准确率降7-13%
- 去掉Extractor+Rewriter:直接检索原始子问题,准确率再降5-9%
为什么这个方法能成?
-
语义对齐:LLM生成的QA对天然贴近查询语义,比原始文档检索更精准(引用32的发现)
-
解耦架构:把"理解文档"的重活放在离线,在线只做"轻量检索+组装",避免重复劳动
-
实体连续性:Rewriter显式注入前序答案,根治多跳推理中的指代丢失问题
局限与未来:
- 离线构建知识库需要一次性投入(但可复用)
- 目前依赖静态QA库,未来可探索动态更新、跨领域迁移
对于需要处理大量多跳查询的场景(如企业知识库、科研文献问答),CompactRAG提供了成本可控的落地路径:
-
用中小模型(8B)即可达到大模型迭代式的性能
-
Token成本降低60-80%,响应速度更快
-
架构简洁,不依赖模型内部状态,兼容开源/闭源LLM
CompactRAG: Reducing LLM Calls and Token Overhead in Multi-Hop Question Answering
https://arxiv.org/pdf/2602.05728
https://github.com/How-Young-X/CompactRAG
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇
1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图 ,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。

2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础 。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程 ,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
