AI 生成代码的速度很快,快到常常让人产生一种错觉: "看起来能跑,就差不多可以用了。"
但真正进入项目以后,问题往往也来得很快:异常处理不完整、输入校验缺失、业务逻辑直接堆在路由里、领域对象和 API schema 混用、测试覆盖不足......这些并不是偶发情况,而几乎是 AI 代码的"标准附带品"。
所以,在真正把 AI 生成的代码放进生产环境之前,我通常会走一套固定的清理流程。它的目标不是"把代码修得更好看",而是把一段能演示的原型,整理成一段可维护、可测试、可上线 的工程代码。
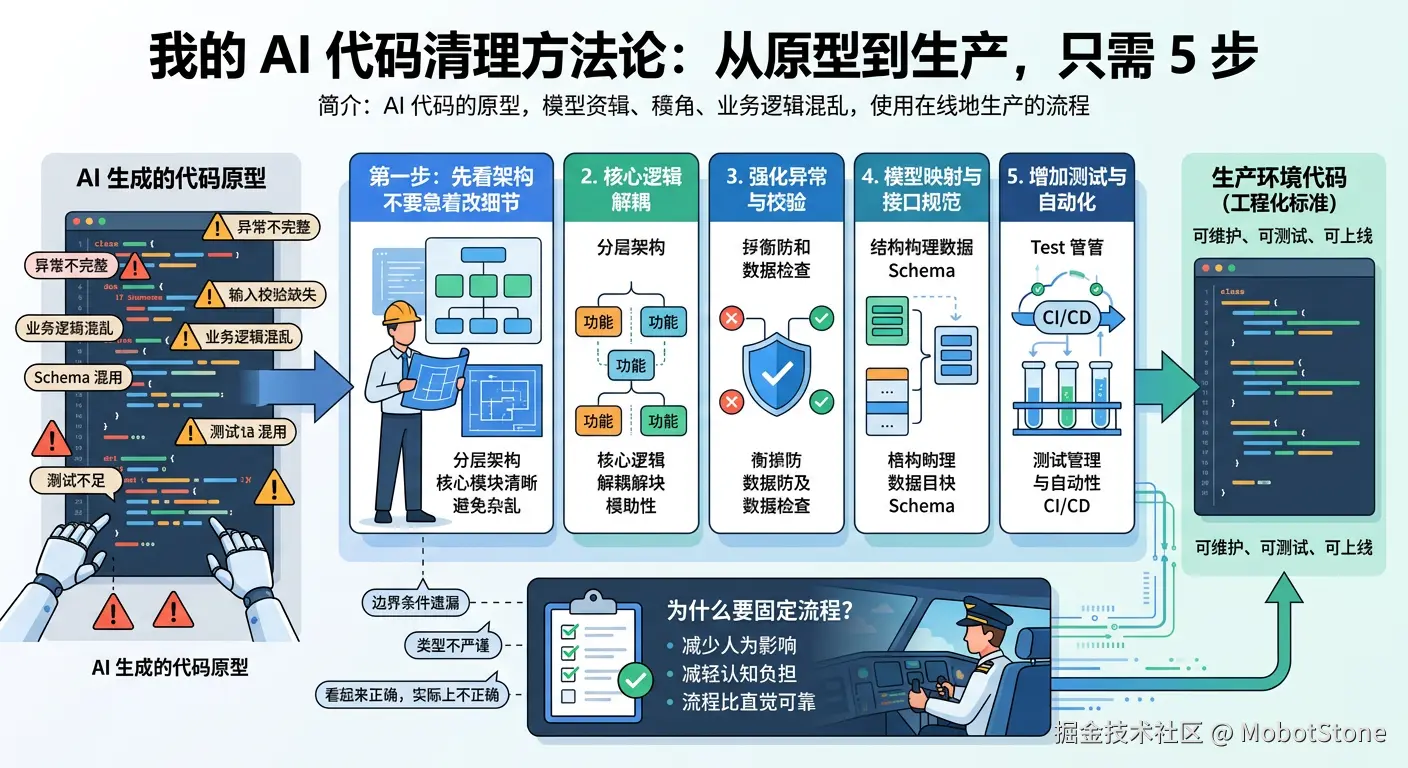
这套流程,我已经在多个项目中反复使用。今天把它整理出来,供你参考。
为什么需要一套固定流程
如果你第一次审查 AI 生成的代码,大概率能一眼看出很多问题;第二次审查时,你会发现问题开始变多,因为第一轮你没看到的细节正在慢慢浮现;到了第三次,若项目又赶进度,人就容易动摇:"其实也还能用吧?"
这正是固定 playbook 的意义。
它不是为了限制开发者,而是为了减少人为状态对代码质量的影响。因为人在疲劳、赶工、认知负担较重时,很容易对"看起来没问题"的代码放松警惕。飞行员会使用检查单,不是因为他们不专业,而是因为他们足够专业,知道流程比直觉更可靠。
相关经验也反复证明了这一点。很多团队在使用 Copilot 或其他代码生成工具后,确实能提升编写速度,但后续也常伴随着更多细节问题,比如边界条件遗漏、类型不严谨、测试不足、错误处理松散。AI 生成代码最常见的问题之一,不是"完全不能用",而是"看起来正确,实际上不正确"。后续验证和修复所消耗的时间,往往会抵消一部分甚至大部分效率收益。
第一步:先看架构,不要急着改细节
AI 生成代码最常见的问题,不是语法错误,而是结构不对。它往往能把功能拼出来,但不一定符合你现有系统的分层方式。
所以我会先问几个基础问题:
- 代码是否放在正确的层?
- 路由层、服务层、数据访问层的职责是否清晰?
- API 层有没有把 Pydantic 模型和 ORM 模型混在一起?
- 包结构是否符合项目规范?
- 命名风格是否与现有代码库保持一致?
一个很典型的问题:所有逻辑都挤在路由里
AI 很喜欢把验证、业务规则、数据库操作写在同一个函数里。短期看,这样确实"省事";长期看,这种写法几乎一定会变成维护负担。
修改前:路由函数里塞满所有逻辑
python
from fastapi import APIRouter, HTTPException, Request
from datetime import datetime
router = APIRouter()
@router.post("/orders")
def create_order(request: Request):
data = request.json()
if not data.get("items"):
raise HTTPException(status_code=400, detail="No items")
total = 0
for item in data["items"]:
total += item["price"] * item["quantity"]
order = {
"items": data["items"],
"total": total,
"status": "CREATED",
"created_at": datetime.utcnow(),
}
# 假装这里直接写数据库
return order这段代码的问题很明显: 接口层、业务层、持久化层全混在了一起。
修改后:按职责拆分
python
from fastapi import APIRouter, Depends, HTTPException
from pydantic import BaseModel, Field
from datetime import datetime
from sqlalchemy.orm import Session
router = APIRouter()
class CreateOrderItem(BaseModel):
product_id: str
quantity: int = Field(gt=0)
price: float = Field(gt=0)
class CreateOrderRequest(BaseModel):
items: list[CreateOrderItem]
class OrderService:
def __init__(self, session: Session):
self.session = session
def create_order(self, request: CreateOrderRequest):
if not request.items:
raise ValueError("No items")
total = sum(item.price * item.quantity for item in request.items)
order = Order(
total=total,
status="CREATED",
created_at=datetime.utcnow(),
)
self.session.add(order)
self.session.commit()
self.session.refresh(order)
return order
@router.post("/api/orders", status_code=201)
def create_order(
request: CreateOrderRequest,
service: OrderService = Depends(get_order_service),
):
order = service.create_order(request)
return OrderResponse.from_orm(order)这样拆开以后,好处非常直接:
业务逻辑可以脱离 HTTP 层单独测试,接口调整也不会牵一发动全身。更重要的是,后面如果要扩展订单状态、增加风控校验或引入事件发布,代码结构仍然扛得住。
第二步:安全加固,别让"能用"变成"有风险"
AI 生成代码在安全方面经常比较"天真"。它默认世界是友好的,但真实环境显然不是。
因此,输入和输出一定要单独审查。
输入侧:不要直接接收 ORM 模型
常见问题
less
@router.post("/users")
def create_user(user: User):
db.add(user)
db.commit()
return user这种写法的问题在于,外部请求和内部实体直接绑定。
一旦字段设计稍有变化,或者外部传入了不该写入的字段,就容易出问题。
更稳妥的做法:使用请求模型
python
from pydantic import BaseModel, EmailStr, Field
class CreateUserRequest(BaseModel):
name: str = Field(min_length=1, max_length=100)
email: EmailStr
bio: str | None = Field(default=None, max_length=500)这样做的好处是:
- 外部输入和内部模型解耦
- 可以明确约束字段长度、格式和必填项
- 后续扩展字段时,不容易影响已有逻辑
输出侧:不要直接返回 ORM 对象
很多人会忽略这一点,但它同样重要。 如果直接返回 ORM 对象,数据库中的内部字段可能会被一并暴露出去,比如password_hash、internal_notes 之类的内容。
更合理的做法:使用响应模型
python
from pydantic import BaseModel
class UserResponse(BaseModel):
id: int
name: str
email: str
bio: str | None = None
class Config:
from_attributes = True建议检查项
- 是否使用请求模型,而不是直接使用 ORM 模型?
- 是否启用了参数校验?
- 是否通过响应模型控制输出字段?
- 是否存在 SQL 注入风险?
- 是否有权限校验?
- 日志里有没有打印敏感信息?
- 对外接口有没有必要的限流措施?
可以记住一句非常实用的原则:
所有进入系统的数据都不应默认可信,所有输出给外部的数据都应默认可见。
这个原则虽然简单,但在代码评审时非常管用。
第三步:错误处理要统一,不要让异常"自由发挥"
高质量代码的一个标志,是它在出错时依然表现稳定。 而 AI 生成代码最容易出的问题之一,就是异常处理不统一:有的地方直接raise Exception,有的地方返回空值,有的地方打印日志后悄悄吞掉错误。
这会让系统非常难维护。
我通常采用三层错误处理方式
第一层:领域异常
python
class BusinessError(Exception):
def __init__(self, message: str, code: str = "BUSINESS_ERROR"):
super().__init__(message)
self.code = code
class InsufficientStockError(BusinessError):
def __init__(self, product_id: str, requested: int, available: int):
super().__init__(
f"Product {product_id}: {requested} requested, only {available} available",
code="INSUFFICIENT_STOCK",
)这类异常的重点是:用业务语言表达问题,而不是直接关心 HTTP 返回码。
第二层:全局异常处理器
如果是 FastAPI,可以这样做:
python
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse
from datetime import datetime
app = FastAPI()
@app.exception_handler(BusinessError)
async def handle_business_error(request: Request, exc: BusinessError):
return JSONResponse(
status_code=422,
content={
"status": 422,
"message": str(exc),
"code": exc.code,
"timestamp": datetime.utcnow().isoformat(),
},
)
@app.exception_handler(KeyError)
async def handle_not_found(request: Request, exc: KeyError):
return JSONResponse(
status_code=404,
content={
"status": 404,
"message": "Resource not found",
"code": "NOT_FOUND",
"timestamp": datetime.utcnow().isoformat(),
},
)
@app.exception_handler(Exception)
async def handle_unexpected(request: Request, exc: Exception):
# 这里应该接入日志系统
return JSONResponse(
status_code=500,
content={
"status": 500,
"message": "An internal error occurred",
"code": "INTERNAL_ERROR",
"timestamp": datetime.utcnow().isoformat(),
},
)这一层负责把内部异常转换成统一的 HTTP 响应。
第三层:统一错误返回格式
python
from pydantic import BaseModel
from datetime import datetime
class ErrorResponse(BaseModel):
status: int
message: str
code: str
timestamp: datetime为什么这套方式有效
因为它将三种关注点分开了:
- 领域异常:描述业务问题
- 异常处理器:负责协议转换
- 错误响应:负责客户端消费体验
这样一来,前端、网关或其他调用方收到的错误格式始终一致,系统也更容易排查和演进。
第四步:测试不是"可选项",而是收尾动作的一部分
AI 生成的代码通常不会自动附带足够的测试。
但没有测试的代码,即使当前能跑,也很难说是稳的。
我一般会要求每个功能至少补齐以下几类测试:
- 正常路径测试:主流程是否能正确完成
- 失败路径测试:异常条件是否处理得当
- 边界条件测试:空值、空集合、极值是否稳定
- 集成测试:接口到服务的完整链路是否可用
服务层测试示例
ini
from unittest.mock import Mock
def test_create_order_calculates_total():
request = CreateOrderRequest(
items=[
CreateOrderItem(product_id="PROD-1", quantity=2, price=29.99),
CreateOrderItem(product_id="PROD-2", quantity=1, price=49.99),
]
)
session = Mock()
service = OrderService(session)
result = service.create_order(request)
assert result.total == 109.97接口层集成测试示例
python
from fastapi.testclient import TestClient
client = TestClient(app)
def test_full_order_flow_returns_201(mocker):
mock_service = mocker.patch("path.to.module.get_order_service")
mock_service.return_value.create_order.return_value = test_order_response()
response = client.post(
"/api/orders",
json={
"items": [
{"product_id": "PROD-1", "quantity": 2, "price": 29.99},
{"product_id": "PROD-2", "quantity": 1, "price": 49.99},
]
},
)
assert response.status_code == 201
assert "location" in response.headers
assert response.json()["total"] == 109.97
assert response.json()["status"] == "CREATED"一个经验判断
如果一个功能只覆盖了"正常情况",却没有覆盖异常路径和边界条件,那测试通常是不够的。
测试的目的不只是证明"它能跑",更是证明"它在出问题时也不会乱跑"。
第五步:把质量要求放进 CI/CD,而不是靠人工记忆
很多团队的问题不是没有规范,而是规范只存在于脑子里。
但人的记忆并不适合长期承担质量控制这种工作,尤其是在需求密集、节奏紧张的项目里。
所以,最后一步是把这些要求放进 CI/CD 流水线里,让系统替你做检查。
一个基础流水线可以这样设计
markdown
stages:
- lint
- test
- security
- build
lint:
script:
- ruff check .
- black --check .
- mypy .
test:
script:
- pytest
- pytest tests/integration
security:
script:
- bandit -r .
- pip-audit
build:
script:
- python -m build
only:
- main对 AI 代码建议增加的检查
- 是否引入了无用的依赖
- 是否出现重复逻辑
- 是否存在未使用的 import
- Python 版本是否与项目一致
- 是否破坏了原有的构建规范
- 是否通过了类型检查
- 是否有格式化和 lint 问题
CI/CD 的价值就在这里:它不是在"最后抓人",而是在"过程里拦截问题"。
一份可以直接使用的检查清单
如果你希望把这套方法固定下来,可以直接把下面这份清单放进代码评审流程里:
AI 代码清理清单 架构审查
□ 分层是否正确?
□ 是否使用 Pydantic 模型而非 ORM 模型暴露接口?
□ 包结构是否一致?
□ 是否复用了现有项目模式?
□ 是否有输入校验?
安全加固
□ 是否通过响应模型控制输出?
□ 是否存在 SQL 注入风险?
□ 是否做了权限校验?
□ 日志是否泄露敏感信息?
错误处理
□ 是否定义了领域异常?
□ 是否有全局异常处理?
□ 是否返回统一错误格式?
□ 是否避免未处理异常?
测试策略
□ 是否覆盖正常路径?
□ 是否覆盖失败路径?
□ 是否覆盖边界条件?
□ 是否至少有一个集成测试?
CI/CD 集成
□ 是否自动格式化检查?
□ 是否把测试纳入流水线?
□ 是否做了依赖安全扫描?
□ 是否清理了无用依赖?
结语:AI 只是起点,流程才决定上限
AI 正在改变开发方式,但它并不会自动替你解决工程问题。
它更像一个高产但不够谨慎的初级 开发者:能快速产出,但往往需要强约束、强审查和强测试来把结果拉回生产标准。
所以,真正重要的不是"AI 写了多少代码",而是你有没有一套稳定的方法,把这些代码变成可维护、可交付的系统资产。
从这个角度看,代码清理不是额外成本,而是工程化的一部分。甚至可以说,流程本身,就是产品质量的一部分。