tips:该模型用于baseline!
前言
基于TF-IDF特征工程和Bagging随机森林算法(sklearn - RandomForestClassifier)实现文本分类的基线模型(Baseline Model)功能,最终目的是通过模型算法提高推荐系统的用户点击率和访问量
随机森林算法 sklearn-RandomForestClassifier
集成学习的思想:多个基学习器组合成一个精度更高的模型
bagging随机森林算法,有放回采样,并行,平权投票,预测结果
特征工程TF-IDF
TF词频,IDF逆文档频率
tf:样本中某特征的数量➗样本中总特征数量
idf:log(总样本数➗(出现某特征的样本数量+1) ) +1
简单高效计算速度快,有效过滤掉停用词,发现文档中关键词
无语捕捉语义,无法理解上下文
整体实现逻辑如下:
EDA分析
Config统一管理文件分发,EDA完成整体数据分析
数据预处理
Config完成模型文件路径分发
EDA_processing完成数据预处理(jieba分词)
模型训练-评估-保存
TF_IDF完成特征工程提取
train_test_split完成数据集划分
RandomForestClassifier实例化模型
模型训练-模型评估(准确率,精确率,召回率,F1-score)
模型和tfidf向量化器保存
模型验证
加载模型和tfidf向量化器
加载验证数据集并通过tfidf向量化器将数据向量化
模型评估(准确率,精确率,召回率,F1-score)
验证结果持久化存储
开放推理方法
加载模型和tfidf向量化器
数据jieba分词并向量化
模型推理,获取标签名称并返回
基于flask构建后端服务
基于falsk+html或者streamlit构建前端服务
数据集整体分析
本部分完成两个py脚本 config.py dataEDA.py
config.py 实现文件数据及路径的同一管理分发
dataEDA (Exploratory Data Analysis)探索性数据分析,观测相关数据量,样本和类别占比是否平衡
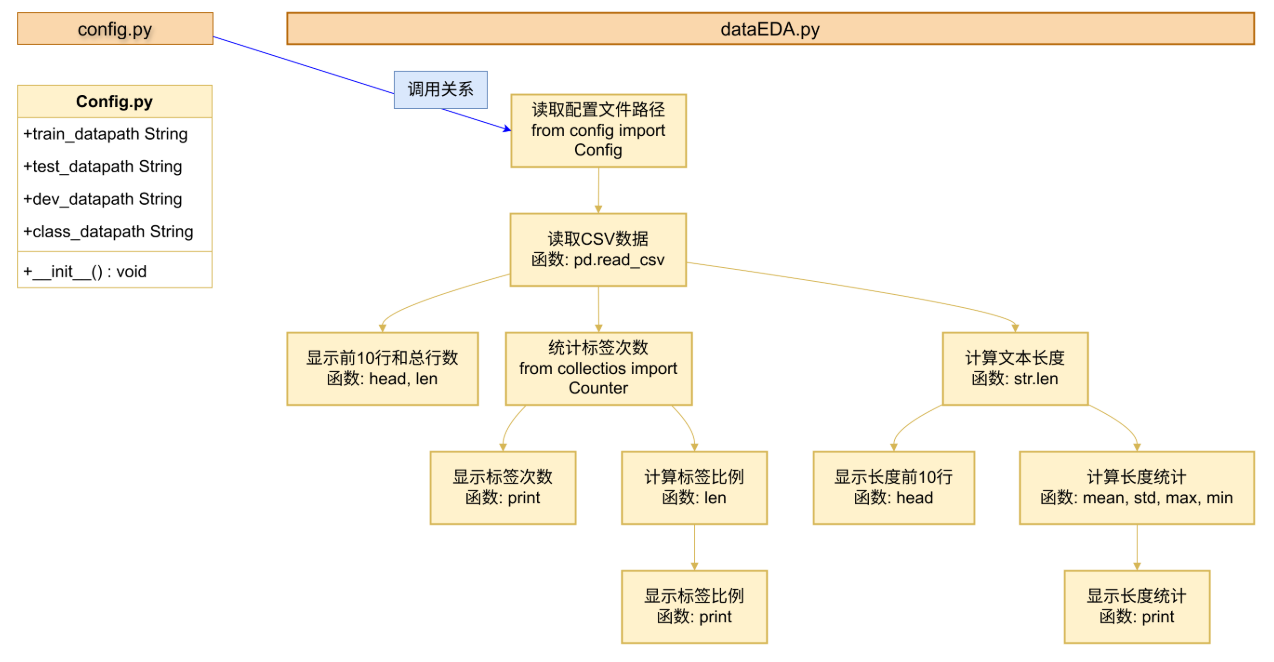
config文件
python
# 存储路径/数据库配置信息/API的信息等
# 创建类
class Config(object):
# 初始化文件路径属性
def __init__(self):
# 文件路径
self.train_datapath = './train.txt' # 相对路径, 也可以使用绝对路径
self.test_datapath = './test.txt'
self.dev_datapath = './dev.txt'
self.class_datapath = './class.txt'
if __name__ == '__main__':
# 实例化对象
config = Config()
# 获取对象属性
class_file = config.class_datapath
with open(class_file, 'r', encoding='utf-8') as f:
data = f.read()
print(data)数据EDA
python
import pandas as pd
from config import Config
from collections import Counter # 聚合
import seaborn as sns
import matplotlib.pyplot as plt
# todo:1-实例config类对象, 获取文件路径属性
config = Config()
# todo:2-定义函数, 进行探索性数据分析
def dataEDA(path):
# todo:2.1-加载数据集
# sep: 分隔符
# names: 指定列名
data = pd.read_csv(path, sep='\t', names=['text', 'label'])
print('查看前5条数据--->\n', data.head())
# todo:2.2-探索性数据分析 EDA
# 数据集行列数
print('查看数据集的行列数--->\n', data.shape)
# 数据集基本信息
data.info()
print('=' * 80)
# todo:2.3-不同标签的样本数/占比
label_counts = Counter(data['label']) # 分组聚合
print('不同标签的样本数--->\n', type(label_counts), label_counts)
# label_counts.items(): dict.items()->获取字典中的 (key, value)
for label, count in label_counts.items():
print(f'标签{label}的样本数是{count}')
# 占比
data_len = len(data) # 统计数据集总样本数
for label, count in label_counts.items():
ratio = (count / data_len) * 100 # 当前标签的样本数/总样本数
print(f'标签{label}的样本占比是{ratio:.2f}%')
# 通过绘图进行数据分析
plt.figure(figsize=(16, 8))
sns.countplot(data=data, x='label')
plt.show()
print('=' * 80)
# 文本长度统计 平均值/标准差/最大值/最小值
# 增加一列文本字符长度列
data['text_length'] = data['text'].str.len()
print(data.head())
# 绘图
plt.figure(figsize=(16, 8))
sns.countplot(data=data, x='text_length')
plt.show()
print('文本平均长度--->\n', data['text_length'].mean())
print('文本长度标准差--->\n', data['text_length'].std())
print('文本最大长度--->\n', data['text_length'].max())
print('文本最小长度--->\n', data['text_length'].min())
if __name__ == '__main__':
# 获取文件路径属性
train_datapath = config.train_datapath
test_datapath = config.test_datapath
dataEDA(train_datapath)
dataEDA(test_datapath)随机森林模型构建
我们这里拿随机森林算法实现的主要是个基线模型(Baseline Model)
Baseline Model主要的目标是: 1.快速验证可行性 2.提供性能参考 3.降低开发成本 4.发现问题
bagging模式的config分发文件
python
import os
# 创建config类
class Config(object):
# 初始化路径属性
def __init__(self):
# 原始文件路径
self.train_datapath = '../01-data/train.txt'
self.test_datapath = '../01-data/test.txt'
self.dev_datapath = '../01-data/dev.txt'
self.class_datapath = '../01-data/class.txt'
self.stop_words_path = '../01-data/stopwords.txt'
# 处理后的文件路径
self.process_train_datapath = './data/process_train.csv'
self.process_test_datapath = './data/process_test.csv'
self.process_dev_datapath = './data/process_dev.csv'
# 模型保存路径
self.rf_model_save_path = './save_model'
# 预测结果保存路径
if not os.path.exists('./result'): # 如果不存在result文件夹,则创建
os.mkdir('./result')
self.model_predict_result = './result'
if __name__ == '__main__':
# 创建对象
config = Config()
print(config.train_datapath)
print(config.rf_model_save_path)数据预处理processing
python
from config import Config
import pandas as pd
import jieba
# todo:1-实例化config对象, 获取原始文件路径属性
config = Config()
# 获取原始文件的路径 训练集 测试集 验证集
file_paths = [config.train_datapath, config.test_datapath, config.dev_datapath]
# todo:2-rf数据处理
for file_path in file_paths:
# todo:2-1 加载数据集
data = pd.read_csv(file_path, encoding='utf-8', sep='\t', names=['text', 'label'])
print('查看数据集1--->\n', data.head())
# todo:2-2 新增一列, 对text列分词后合并的字符串数据 -> '金科 西府 名墅 天成'
# x->text列中的每一行数据
# jieba.lcut(x)->分词
# [:30]->切片, 没有实际的业务意义, 可以不用进行切片
data['words'] = data['text'].apply(func=lambda x: ' '.join(jieba.lcut(x)[:30]))
print('查看数据集2--->\n', data.head())
# todo:2-3 保存处理后的数据集
if 'train' in file_path:
data.to_csv(config.process_train_datapath, index=False, encoding='utf-8')
print(f'成功保存处理后的训练集{config.process_train_datapath}')
elif 'test' in file_path:
data.to_csv(config.process_test_datapath, index=False, encoding='utf-8')
print(f'成功保存处理后的测试集{config.process_test_datapath}')
elif 'dev' in file_path:
data.to_csv(config.process_dev_datapath, index=False, encoding='utf-8')
print(f'成功保存处理后的验证集{config.process_dev_datapath}')模型训练
TF-IDF特征工程思路
我们有很多方式可以实现文本到数值的转换,比如one-hot,我们在这里使用tf-idf实现文本的数值化,它的核心是将文本转换为一组数字(向量),这个过程就是文本向量化或者特征提取
**tf-idf 核心思想:**一个特征(词语)在一条样本(句子)中出现的次数越多,同时在所有样本(句子)中出现的次数越少,那就代表越是独特和稀有,越是能代表其主题,其权重就应该越高.
TF term frequency 词频, IDF inverse document frequency 逆文档频率
TF-IDF计算流程


TF:词语A在文档B中出现的次数➗文档B中的总词数
IDF:总文档数ALL➗出现词语A的文档数 取对数log
IDF分母中的1是为了不让分母为0,也可以是1e-9, 对数的结果+1是为了不让IDF小于0
TF-IDF优点简单高效,计算速度快
效果显著,能有效过滤掉停用词,发现文档中的关键主题词
TF-IDF缺点
无法捕捉语义 cat和猫被视为两个词
无法理解上下文
对新词不友好
权重倾向稀有词
应用场景
信息检索和搜索引擎
文本分类和聚类
关键词提取
文本相似度计算
特征工程实现
python
import pandas as pd
import pickle
from sklearn.feature_extraction.text import TfidfVectorizer # IF-IDF
from sklearn.model_selection import train_test_split # 模拟数据分割
from sklearn.ensemble import RandomForestClassifier # 随机森林分类算法
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 评估指标
from config import Config
from tqdm import tqdm # 引入 tqdm 用于进度条
import warnings
import time
warnings.filterwarnings("ignore")
pd.set_option('display.expand_frame_repr', False) # 避免宽表格换行
pd.set_option('display.max_columns', None) # 确保所有列可见
conf = Config()
# todo:1-加载训练数据集
train_data = pd.read_csv(conf.process_train_datapath, encoding='utf-8')
print('查看数据集--->\n', train_data.head())
# todo:2-获取words和lables两列数据
words = train_data['words']
labels = train_data['label']
print('查看words数据--->\n', words.head())
print('查看labels数据--->\n', labels.head())
# todo:3-tf-idf向量化计算
# 加载停用词词表, 过滤掉
with open(conf.stop_words_path, 'r', encoding='utf-8') as f:
stop_words = f.read().split('\n')
print('停用词数量--->\n', len(stop_words), stop_words)
# 实例化TfidfVectorizer对象
tfidf = TfidfVectorizer(stop_words=stop_words)
# 训练并转换生成词向量
features = tfidf.fit_transform(words)
print('查看tf-idf信息--->\n', features.shape,'\n', features)
# 查看tf-idf信息
# print('查看tf-idf信息--->\n', len(tfidf.get_feature_names_out()))
# print(list(tfidf.get_feature_names_out()))
# 查看词表, 词2id
print(tfidf.vocabulary_)
# todo:4-数据集划分 可选,使用的是训练集
x_train, x_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=22)
# todo:5-模型训练
# 实例化模型对象
# n_jobs:使用所有可用的cpu核数进行训练,加快训练速度
# verbose:打印训练进度
model = RandomForestClassifier(n_jobs=-1, verbose=1)
# 训练
for _ in tqdm(range(1), desc='RF模型正在训练中...'):
start_time = time.time()
model.fit(x_train, y_train) # 模型训练
end_time = time.time()
print(f'模型训练耗时{(end_time - start_time):.2f}秒')
# 加载模型
# with open(conf.rf_model_save_path + '/rf_model.pkl', 'rb') as f:
# model = pickle.load(f)
# todo:6-模型评估
# 预测结果
y_pred = model.predict(x_test)
print('准确率--->\n', accuracy_score(y_test, y_pred))
print('精确率--->\n', precision_score(y_test, y_pred, average='micro'))
print('召回率--->\n', recall_score(y_test, y_pred, average='micro'))
print('F1-score--->\n', f1_score(y_test, y_pred, average='micro'))
# # todo:7-模型/向量化器保存
# rf模型 算法模型
with open(conf.rf_model_save_path + '/rf_model.pkl', 'wb') as f:
pickle.dump(model, f)
# 向量化器 tf-idf模型
with open(conf.rf_model_save_path + '/tfidf_vectorizer.pkl', 'wb') as f:
pickle.dump(tfidf, f)模型预测评估
python
import pandas as pd
import pickle
from config import Config
import warnings
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
warnings.filterwarnings('ignore')
# 设置pandas显示选项
pd.set_option('display.max_columns', None)
# 加载配置
conf = Config()
# todo:1-加载rf模型和向量化器
with open(conf.rf_model_save_path + '/rf_model.pkl', 'rb') as f:
model = pickle.load(f)
# TF-IDF向量化器
with open(conf.rf_model_save_path + '/tfidf_vectorizer.pkl', 'rb') as f:
tfidf: TfidfVectorizer = pickle.load(f)
# todo:2-加载验证数据集
dev_data = pd.read_csv(conf.process_dev_datapath, encoding='utf-8')
print('查看数据集--->\n', dev_data.head())
# todo:3-通过向量化器进行向量化
dev_features = tfidf.transform(dev_data['words'])
print('查看dev_features信息--->\n', dev_features.shape, dev_features)
# todo:4-模型评估
y_pred = model.predict(dev_features)
print('准确率--->\n', accuracy_score(dev_data['label'], y_pred))
print('精确率--->\n', precision_score(dev_data['label'], y_pred, average='micro'))
print('召回率--->\n', recall_score(dev_data['label'], y_pred, average='micro'))
print('f1-score--->\n', f1_score(dev_data['label'], y_pred, average='micro'))
# todo:5-预测结果持久化存储
df = pd.DataFrame(data={'words': dev_data['words'], 'predicted_label': y_pred})
print('查看df--->\n', df.head())
df.to_csv(conf.model_predict_result + '/dev_predictions.csv', index=False)向外提供模型推理func
python
import jieba
import pandas as pd
import pickle
from config import Config
import warnings
warnings.filterwarnings('ignore')
# 设置pandas显示选项
pd.set_option('display.max_columns', None)
# 后端接口 API
def predict(data):
"""
后端预测接口
:param data: {text: xxxxxx}
:return: data -> {text: xxxxx, pred_class: xxxx}
"""
# todo:1-实例化Config类对象
config = Config()
# todo:2-加载模型和向量化器
with open(config.rf_model_save_path + '/rf_model.pkl', 'rb') as f:
model = pickle.load(f)
with open(config.rf_model_save_path + '/tfidf_vectorizer.pkl', 'rb') as f:
tfidf = pickle.load(f)
# todo:3-data数据进行处理
# 分词, 合并字符串
words = ' '.join(jieba.lcut(data['text'])[:30])
# print('words--->\n', words)
# 向量化
features = tfidf.transform([words])
# print('features--->\n', features)
# todo:4-模型推理
y_pred = model.predict(features)
# print('预测结果--->\n', y_pred)
# todo:5-获取标签名称
# 获取id2class映射关系字典
id2class = {}
with open(config.class_datapath, 'r', encoding='utf-8') as f:
class_data = f.readlines()
# print('class_data--->\n', class_data)
for i, line in enumerate(class_data):
id2class[i] = line.strip()
# print('id2class--->\n', id2class)
# 获取预测标签名称保存到data中
# id2class[y_pred[0]]: 字典key获取value
data['pred_class'] = id2class[y_pred[0]]
# print('预测结果--->\n', data)
return data
if __name__ == '__main__':
data = {"text": "体验2D巅峰 倚天屠龙记十大创新概览"}
data = predict(data)
print('预测结果--->\n', data)模型部署
工业界中的AI是指"能落地的AI", 即指在生产环境中可以部署并提供在线, 或离线作业的模型.
- 例如:随机森林模型的在线服务地址(http://127.0.0.1:8001)
服务端
构建flask应用:
注:requests 是一个简单易用的 HTTP 客户端工具,允许我们通过 Python 代码向服务器发送 HTTP 请求并处理响应。
基于flask的后端api服务
python
from flask import Flask, request, jsonify
from predict_fun import predict
import warnings
warnings.filterwarnings('ignore')
# todo:1-创建app对象
app = Flask(__name__)
# todo:2-创建路由
@app.route('/predict', methods=['POST'])
def predict_api():
# 获取前端数据
data = request.get_json()
print('data--->\n', data)
# 判断是否有数据, 没有收集异常信息
if not data or 'text' not in data:
# 状态码: 2xx->请求成功 3xx->重定向 4xx->请求端报错 5xx->服务端报错
return jsonify({'error': 'Missing text field in JSON'}), 400
# 调用模型预测接口实现预测
result = predict(data)
print('result--->\n', result)
# 返回json结果
return jsonify(result)
if __name__ == '__main__':
# 启动服务端
app.run(host='0.0.0.0', port=8000, debug=True)
# 0.0.0.0 表示监听所有地址flask api服务测试
python
# 不要求掌握
import requests
import time
# 定义预测接口地址
url = 'http://127.0.0.1:8000/predict'
# 构造请求数据
data = {'text': "中国人民公安大学2012年硕士研究生目录及书目"}
start_time = time.time()
try:
# 发送post请求, 获取响应对象
response = requests.post(url, json=data)
print('response--->\n', response)
# 耗时
duration = (time.time() - start_time) * 1000 # ms
print(f'耗时: {duration:.2f}ms')
# 判断状态码是否为200, 如果是, 获取响应数据
if response.status_code == 200:
result = response.json()
print('result--->\n', type(result), result)
print('预测结果--->\n', result['pred_class'])
# 如果不是, 获取错误信息
else:
error = response.json()['error']
print(f"请求失败: {response.status_code}, {error}")
except Exception as e:
print(f"请求出错: {str(e)}")基于streamlit的前端服务
python
import streamlit as st
import requests
import time
# todo:1-设置页面标题
st.title('文本分类系统')
# todo:2-创建输入框
data_text = st.text_area('请输入预测文本:', "中国人民公安大学2012年硕士研究生目录及书目")
# todo:3-创建预测按钮
if st.button('预测'):
# todo:4-调用模型推理接口实现预测
start_time = time.time()
try:
# 构造请求数据
data = {'text': data_text}
url = 'http://127.0.0.1:8000/predict'
# 发送post请求, 获取响应对象
response = requests.post(url, json=data)
duration = (time.time() - start_time) * 1000
# 判断状态码是否为200
if response.status_code == 200:
result = response.json()
# todo:5-显示预测结果
st.success(f"预测结果: {result['pred_class']}")
st.info(f"请求耗时: {duration:.2f}ms")
else:
st.error(f"请求失败: {response.json()['error']}")
except Exception as e:
st.error(f"请求出错: {str(e)}")
# todo:6-页面提示内容
st.write("请确保 Flask API 服务已在 localhost:8000 运行")基于flask+html文件的前端服务
python
from flask import Flask, render_template, request, jsonify
import time
from predict_fun import predict
import json
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/predict', methods=['POST'])
def predict_route():
try:
data = request.get_json()
if not data or 'text' not in data:
return jsonify({"error": "缺少 'text' 字段"}), 400
start_time = time.time()
result = predict(data) # 调用你的预测函数
print('result--->\n', result)
end_time = time.time()
duration = round((end_time - start_time) * 1000, 2) # 毫秒
return jsonify({
"pred_class": result.get("pred_class", None),
"duration_ms": duration
})
except Exception as e:
return jsonify({"error": str(e)}), 500
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000)