一、引言
云计算与大数据是软考数据系统工程师考试 "新技术应用" 模块的核心考点,同时也是当代数据系统设计的基础架构支撑。其中云计算起源于 2006 年 AWS 推出 EC2 服务,历经 17 年发展已形成成熟的产业生态;大数据概念则在 2011 年由麦肯锡正式提出,目前已成为企业数据价值挖掘的核心技术体系。本文将系统梳理两大技术的核心原理、分类体系、应用场景及考试重点,覆盖软考大纲全部相关考点,同时提供可落地的架构设计实践方法。
二、云计算核心原理与特征
2.1 定义与核心思想
云计算是一种按需分配的 IT 资源交付模式,通过网络向用户提供可弹性伸缩的共享计算、存储、网络、应用等资源池,核心逻辑是实现 IT 资源的社会化分工,将基础设施建设、运维等工作交由专业服务商完成,企业只需聚焦业务本身。该模式的底层技术基础包括虚拟化技术、分布式存储、资源调度算法三大支柱,其中虚拟化实现了物理资源的逻辑抽象,分布式存储保障了资源池的可靠性,资源调度算法实现了多租户环境下的资源动态分配。
典型案例如 AWS RDS 云数据库服务,底层基于 EC2 虚拟化服务器、EBS 分布式存储构建资源池,通过自动化调度系统为不同用户提供独立的数据库实例,用户无需关心底层硬件运维,只需按实际使用量付费。
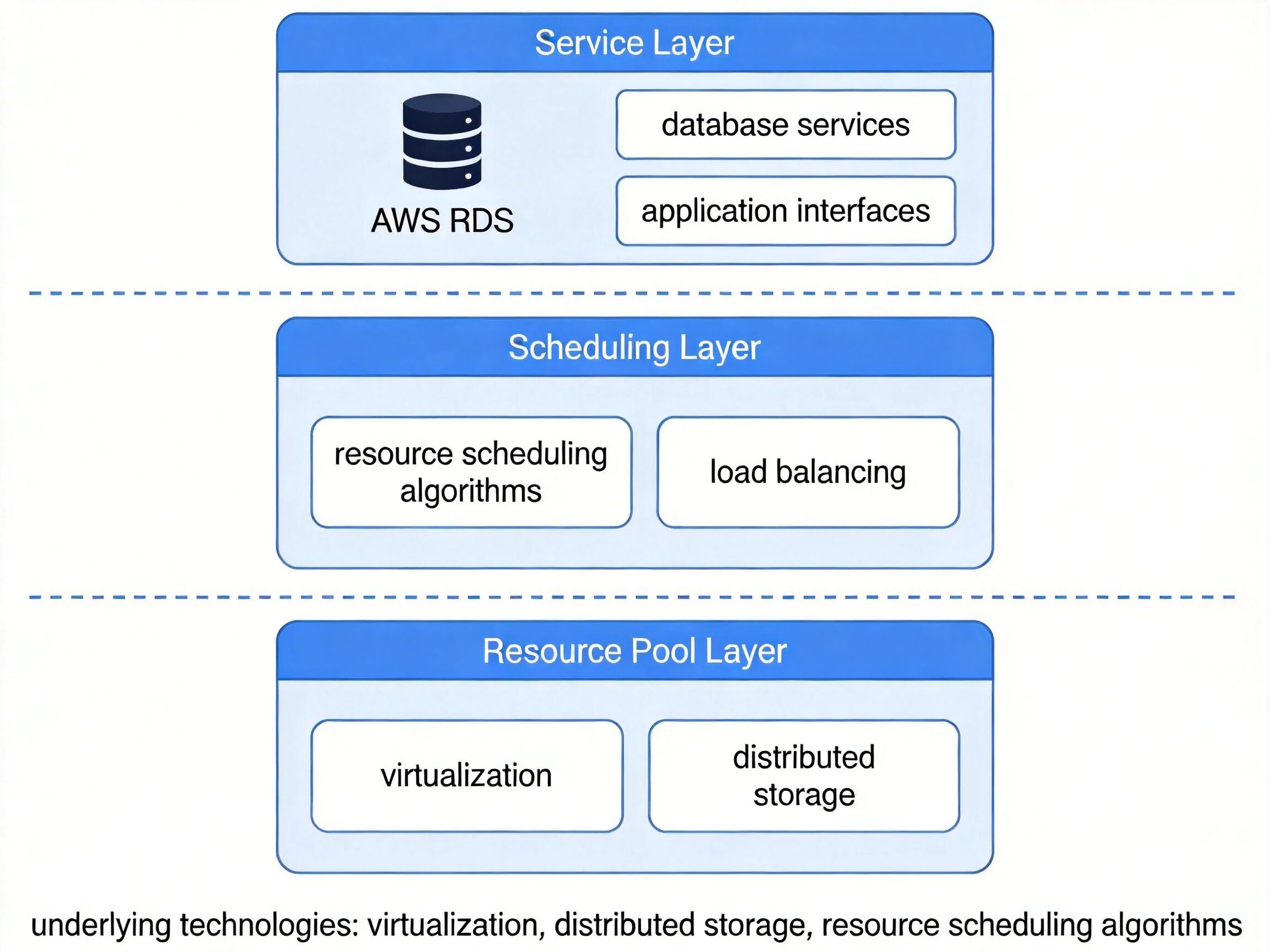
云计算核心架构示意图,展示资源池层、调度层、服务层的分层结构
2.2 五大关键特征
根据 NIST(美国国家标准与技术研究院)SP 800-145 标准,云计算具备五大核心特征,是判断服务是否属于云计算的核心依据:
按需自服务 :用户可通过控制台自助申请资源,无需与服务商人工交互,资源开通时间通常在分钟级,例如阿里云 ECS 实例从下单到启动仅需 30 秒。
广泛网络接入 :支持通过互联网、专线等标准网络协议,从各类终端(PC、手机、服务器)访问服务,无地域限制。
资源池化 :服务商的物理资源被统一抽象为资源池,通过多租户技术实现多用户隔离共享,资源分配对用户透明。
快速弹性 :资源可根据负载动态伸缩,峰值时快速扩容,低谷时自动释放,例如电商大促场景下数据库可在 10 分钟内完成 3 倍算力扩容。
可计量服务 :资源使用量可精准监控、计量、计费,支持按小时、按流量等多种付费模式,相比传统自建 IT 设施平均可降低 40% 以上的 IT 成本。
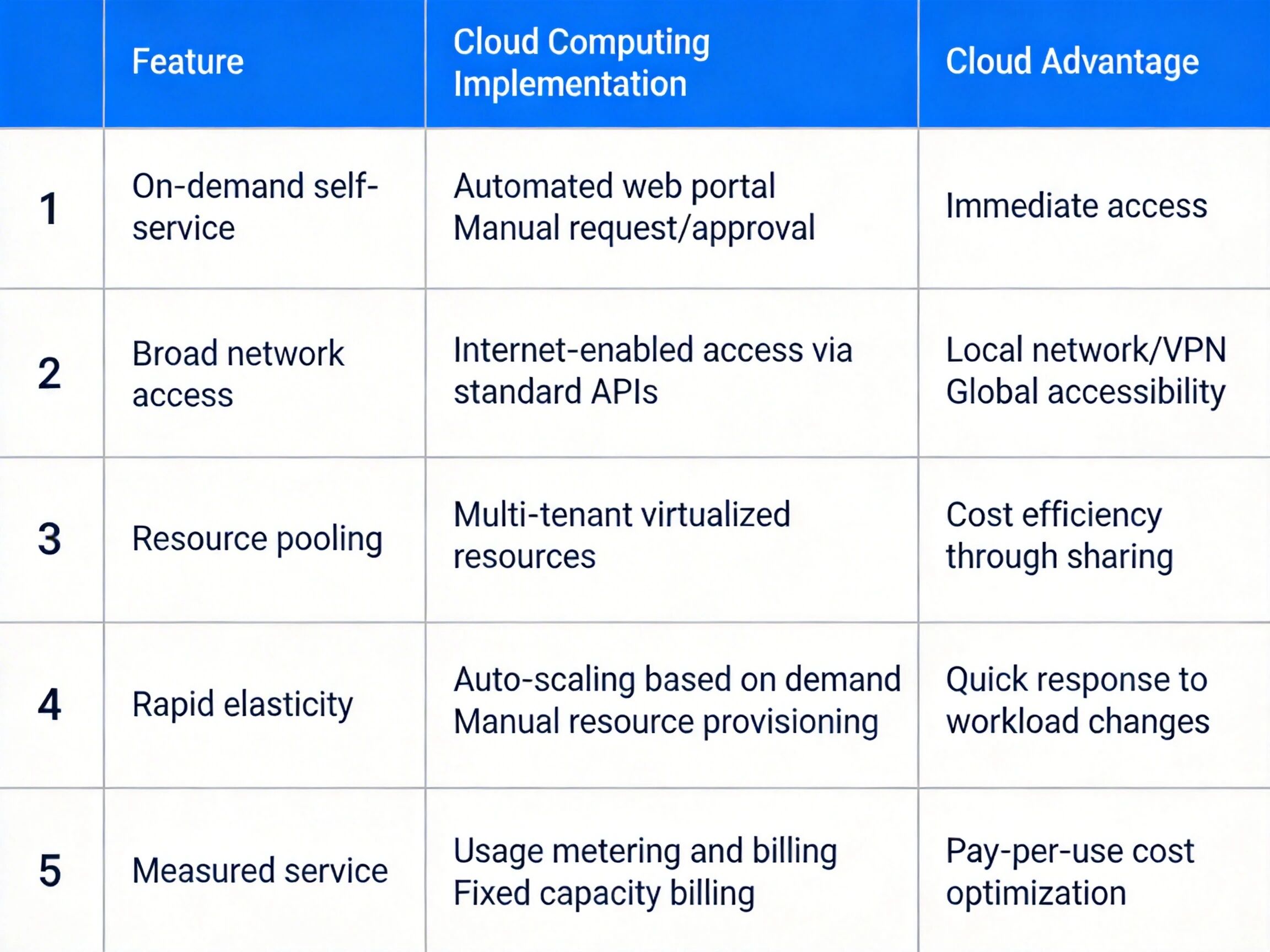
云计算五大特征与传统 IT 模式对比表,包含特性、实现方式、优势三个维度的对比
2.3 两大分类维度
(1)按部署模式分类
根据资源归属和服务对象的不同,云计算部署模式分为四类,不同模式对应不同的数据安全要求:
| 部署模式 | 拥有者 | 核心特点 | 数据库应用场景 |
|---|---|---|---|
| 公有云 | 第三方云服务商 | 成本低、免运维、弹性好 | 互联网应用、创业公司的业务数据库部署 |
| 私有云 | 单一企业自建 | 可控性强、安全等级高 | 金融、政务等对数据主权有严格要求的场景 |
| 社区云 | 多个关联组织共建 | 成本分摊、行业合规统一 | 产业链上下游企业共建共享数据平台 |
| 混合云 | 公有云 + 私有云组合 | 兼顾安全与灵活性 | 核心交易数据存私有云,分析、灾备负载跑公有云 |
(2)按服务层次分类(软考高频考点)
根据服务商提供的资源层级,云计算服务分为 IaaS、PaaS、SaaS 三层,用户的管理责任随层级升高而降低:
IaaS(基础设施即服务) :提供虚拟机、存储、网络等底层基础设施,用户需自行安装操作系统、数据库、中间件,典型产品如 AWS EC2、阿里云 ECS,适合需要完全控制数据库配置的场景,例如企业自建 Oracle RAC 集群。
PaaS(平台即服务) :提供操作系统、运行时、中间件等平台层资源,用户只需关注应用开发和数据设计,无需管理底层基础设施,典型产品如 AWS RDS、阿里云 PolarDB,用户可直接使用开箱即用的数据库服务,自动获得备份、补丁、扩缩容能力。
SaaS(软件即服务) :提供完整的应用软件服务,用户仅需使用软件功能,无需接触底层技术实现,典型产品如 Salesforce、企业级 SaaS CRM 系统,用户作为使用者不直接管理底层数据库。
三类服务可简化记忆为:IaaS 是租毛坯房自行装修,PaaS 是租精装房拎包入住,SaaS 是住酒店享受全服务。
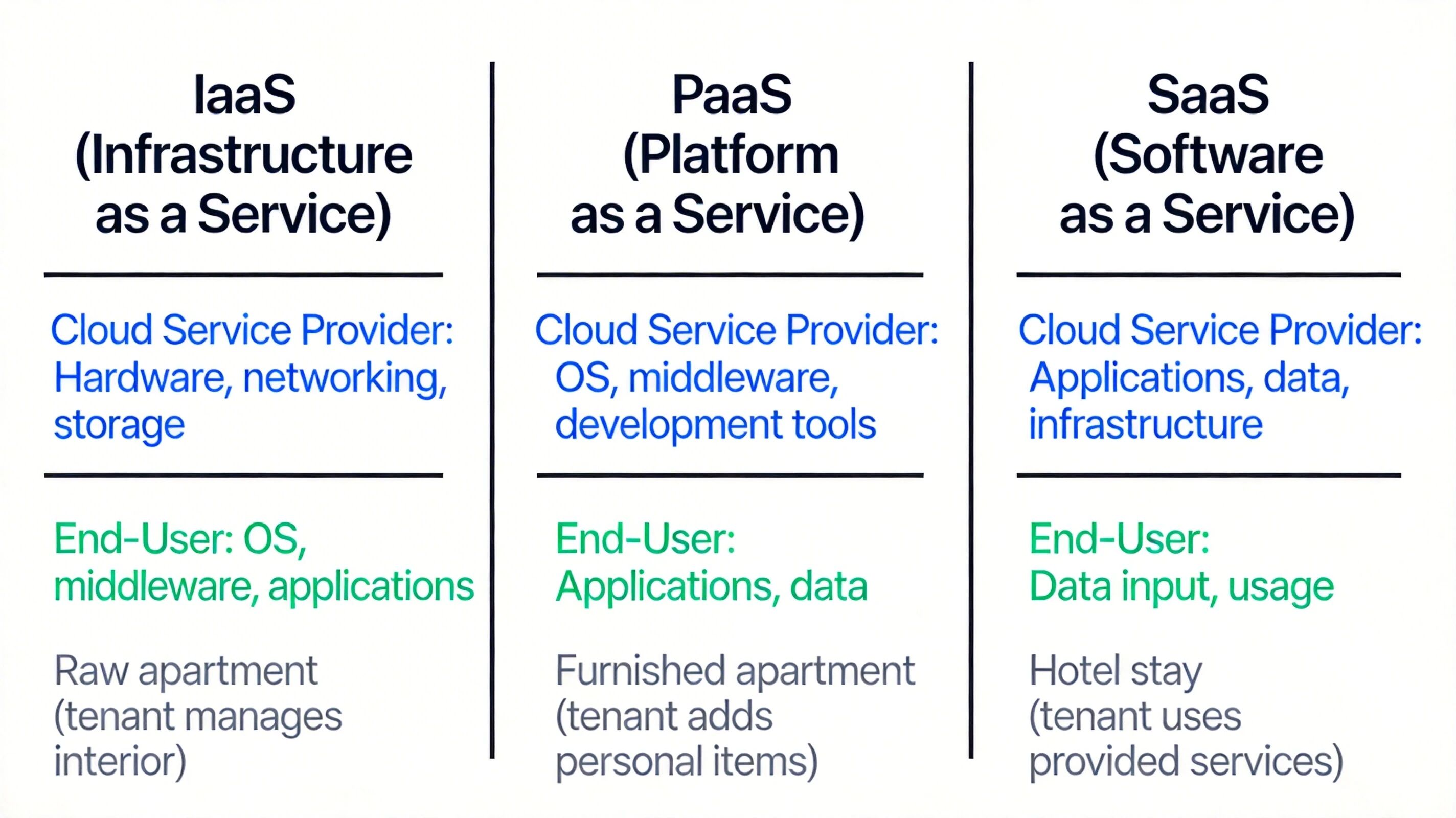
云计算服务层次责任划分图,明确服务商与用户的责任边界
三、大数据核心体系与处理流程
3.1 5V 核心特征
大数据的核心特征可通过 5V 模型概括,也是软考中概念辨析题的核心考点:
大量(Volume) :数据体量达到 TB、PB 甚至 EB 级,传统单机数据库无法支撑存储与计算,典型案例如电商平台每日产生的 PB 级用户行为日志。
高速(Velocity) :数据产生和处理的速度要求高,部分场景需要毫秒级处理延迟,例如实时风控系统需要在 100 毫秒内完成用户交易行为的风险判断。
多样(Variety) :数据类型涵盖结构化(交易表)、半结构化(JSON 日志、XML 配置)、非结构化(图片、视频、文本)三类,传统关系型数据库仅能处理结构化数据,无法覆盖全类型数据处理需求。
价值(Value) :价值密度低,海量数据中仅小部分具备业务价值,例如监控视频中 99% 的内容为无效信息,仅异常事件片段具备分析价值。
真实(Veracity) :数据来源复杂,存在噪声、缺失、错误等问题,需要通过数据质量管理流程保障数据准确性,例如多渠道采集的用户数据需要进行去重、补全、校验后才能用于分析。
核心概念辨析:结构化数据同样属于大数据范畴,只要体量达到大规模即可;大数据分析的复杂度远高于传统数据仓库,需要分布式计算框架支撑,不存在 "大数据分析更简单" 的说法。
3.2 大数据处理基本流程
大数据处理全流程分为三个核心阶段,数据库工程师主要参与前两个阶段的工作:
数据采集阶段 :从业务数据库、日志系统、传感器、第三方接口等数据源采集原始数据,对应 ETL(抽取 - 转换 - 加载)或 ELT(抽取 - 加载 - 转换)流程,典型工具包括 DataX、Flink CDC、Sqoop 等,需要保障数据采集的完整性、一致性和低延迟。
数据分析阶段 :核心处理环节,首先对原始数据进行清洗、转换、标准化,存入数据湖或数据仓库,再通过分布式计算框架进行离线分析、实时计算、数据挖掘,典型技术栈包括 Hadoop HDFS 存储、Spark 计算引擎、Flink 流处理框架,支持 TB 级数据的小时级分析。
数据可视化阶段 :将分析结果通过报表、BI Dashboard、可视化大屏等方式呈现,辅助业务决策,典型工具包括 Tableau、FineBI、Grafana 等。
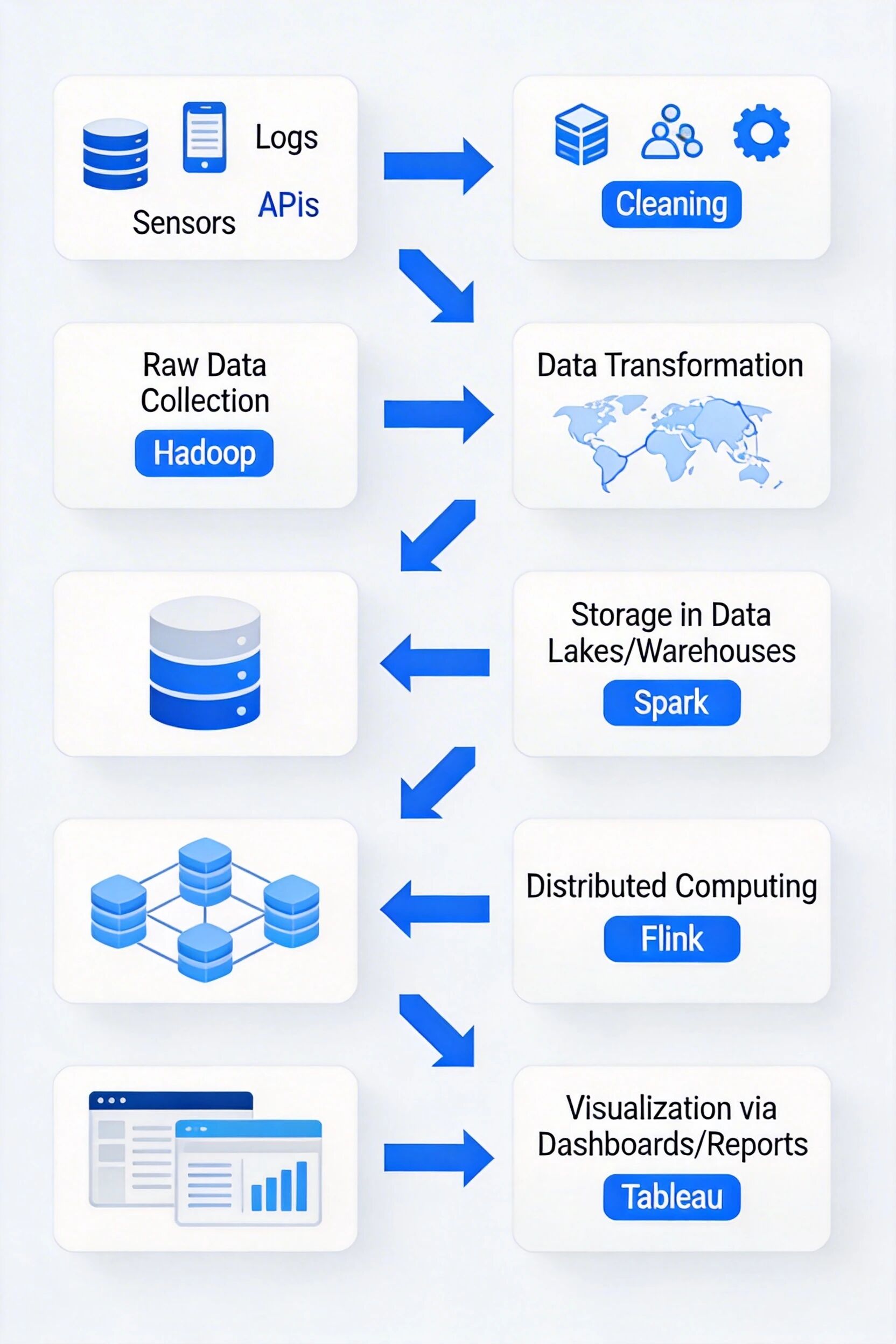
大数据处理全流程示意图,展示从数据采集到价值输出的完整链路
四、典型应用场景与架构设计
4.1 云计算在数据库领域的应用
云计算模式下的数据库架构设计主要有三种典型方案,适用于不同业务场景:
云托管数据库方案:基于 IaaS 层虚拟机自行部署数据库,适合对数据库版本、配置有特殊要求的业务,例如企业需部署特定版本的 Oracle 数据库,可在 EC2 实例上自行安装配置,完全掌控运维流程,缺点是需要投入较多运维人力。
云原生数据库方案:直接使用 PaaS 层云数据库服务,例如 AWS Aurora、阿里云 PolarDB,支持自动备份、故障切换、弹性扩缩容,运维成本相比自建降低 60% 以上,性能比传统 MySQL 高 3-5 倍,是目前大多数企业的首选方案。
混合云数据库方案:核心交易数据库部署在私有云保障数据安全,分析型数据库部署在公有云利用弹性算力,通过数据同步工具实现跨云数据流转,适合金融、政务等监管要求严格的行业。
三类方案的对比维度包括成本、运维复杂度、可控性、弹性能力,其中云原生数据库方案的综合性价比最高,混合云方案的安全合规性最好。
4.2 大数据典型应用案例
用户行为分析系统:电商平台采集用户浏览、点击、加购、交易等全链路行为日志,每日数据量达 PB 级,通过 Spark 离线分析用户画像、消费偏好,支撑个性化推荐、精准营销,转化率平均提升 20% 以上。
实时风控系统:金融机构采集用户交易、登录、设备等实时数据,通过 Flink 流处理引擎进行毫秒级风险识别,欺诈交易识别准确率达 99.5%,资损率降低 80% 以上。
物联网数据平台:工业企业采集设备传感器的实时运行数据,单厂每日数据量达 10TB 以上,通过大数据平台进行设备故障预测、生产效率优化,设备非计划停机时间减少 30%。
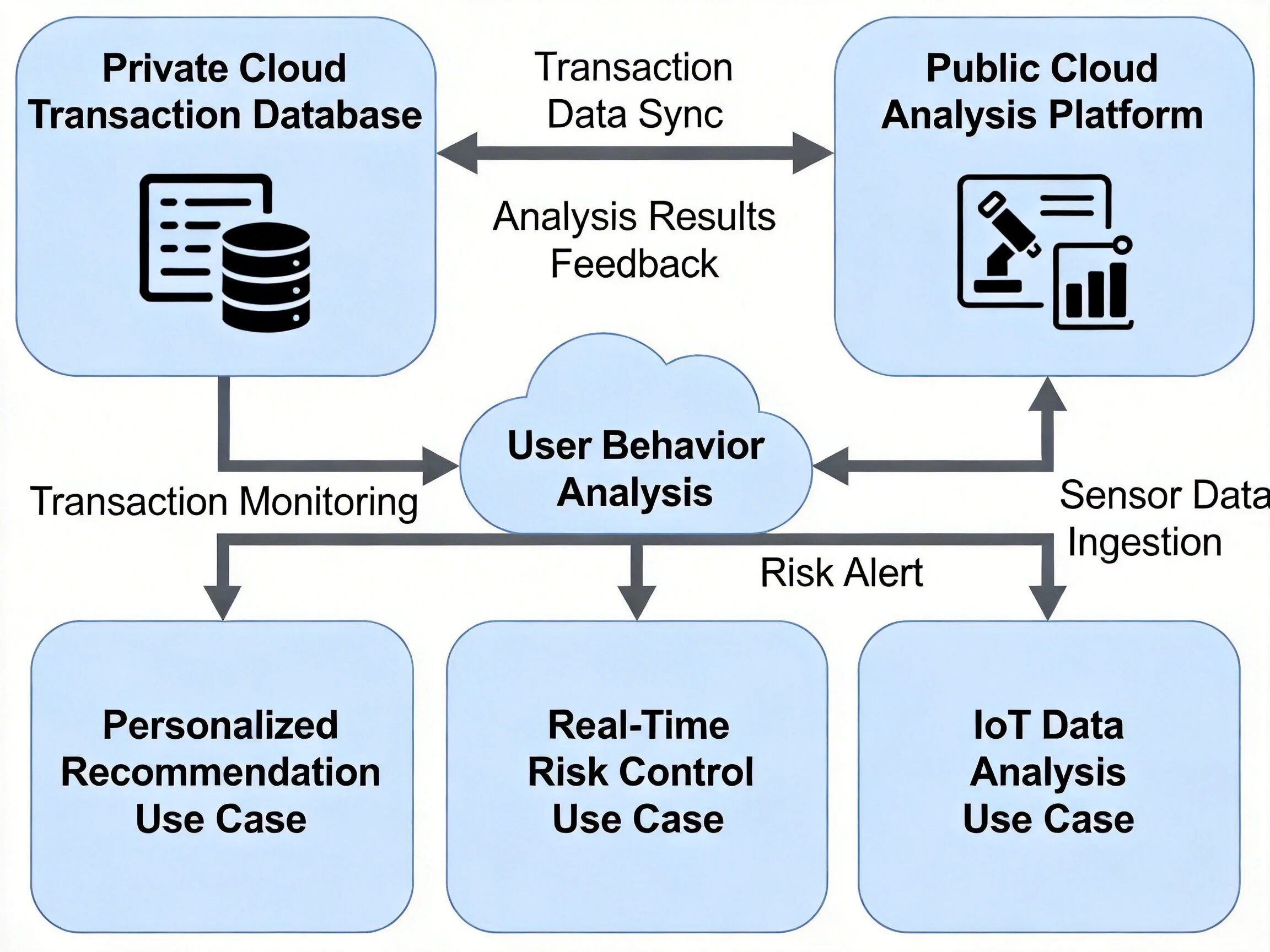
混合云大数据平台架构图,展示私有云交易库与公有云分析平台的协同关系
五、前沿发展趋势与考试动态
5.1 技术发展趋势
云原生数据库持续演进 :Serverless 数据库逐步普及,实现按实际算力消耗付费,资源自动扩缩容,无需手动配置实例规格,典型产品如 AWS Aurora Serverless V2,峰值与低谷算力可实现 1:100 的弹性伸缩,成本相比固定配置实例降低 70%。
湖仓一体技术成熟 :数据湖与数据仓库融合,支持结构化、半结构化、非结构化数据的统一存储与分析,减少数据冗余和链路复杂度,典型产品如 Databricks Lakehouse、阿里云湖仓一体平台,分析效率相比传统架构提升 2 倍以上。
大模型与大数据融合 :大语言模型与大数据平台结合,支持自然语言查询、自动数据建模、智能归因分析,降低数据分析的使用门槛,非技术人员也可自主完成数据查询与分析工作。
5.2 软考考试趋势
近年软考数据系统工程师考试中,云计算与大数据相关考点占比稳定在 10%-15%,出题趋势呈现三个特点:一是概念辨析题占比高,主要考查云计算服务类型判断、大数据特征辨析;二是结合架构设计的应用题增多,要求考生根据业务场景选择合适的云服务模式和大数据技术栈;三是新技术考点逐步增加,Serverless、湖仓一体等前沿技术已出现在近年考题中。
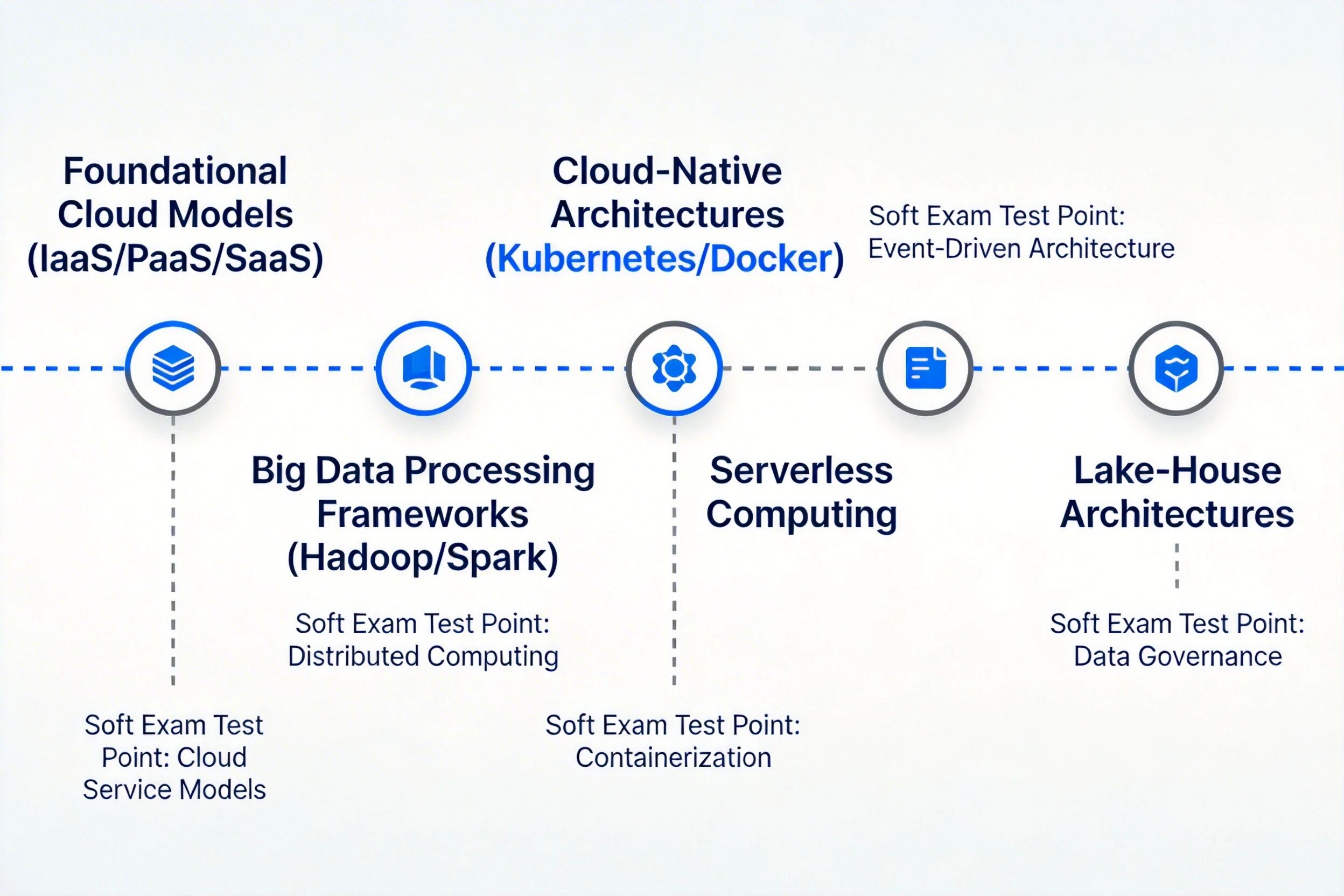
云计算与大数据技术演进路线图,标注历年软考考点对应技术节点
六、总结与备考建议
6.1 核心知识点提炼
云计算核心 :牢记 NIST 定义的五大特征,熟练掌握按部署模式(公有云、私有云、社区云、混合云)和服务层次(IaaS、PaaS、SaaS)的分类,明确不同类型的责任边界和适用场景。
大数据核心 :掌握 5V 特征的具体含义,能够辨析常见错误概念(如 "结构化数据不属于大数据"" 大数据分析更简单 " 等),熟悉大数据处理的三个核心阶段。
技术关联 :IaaS 对应自行运维数据库,PaaS 对应使用云数据库服务,SaaS 对应直接使用软件服务,大数据场景需要配合 Hadoop、Spark、NoSQL 等分布式技术栈。
6.2 软考备考建议
高频考点优先突破:云计算服务层次分类是每年必考题,务必掌握 IaaS、PaaS、SaaS 的典型产品和场景判断,部署模式分类通常以多选题形式出现,需明确四类模式的核心差异。
易混淆点重点区分:大数据特征辨析题常见错误选项包括 "因果关系比关联关系更重要"" 大数据仅包含非结构化数据 " 等,需通过真题练习强化记忆。
真题驱动查漏补缺:本章考点集中,完成近 5 年的 15 道相关真题即可覆盖 90% 以上的考点,错题需回归知识点原理进行巩固,避免概念混淆。
6.3 实践应用最佳实践
云数据库选型优先考虑 PaaS 层服务,除非有特殊的合规或版本要求,否则无需在 IaaS 层自行部署运维数据库,可显著降低运维成本。
大数据架构设计遵循 "存储计算分离" 原则,存储层采用低成本分布式存储,计算层按需弹性扩容,相比传统一体机架构可降低 50% 以上的硬件成本。
混合云架构设计需统一数据标准和访问接口,避免出现数据孤岛,保障跨云数据流转的一致性和安全性。