《Attention is all you need》论文阅读与代码实战
文章目录
- [1. 模型架构与模块分解](#1. 模型架构与模块分解)
-
- [1.1 模型架构图:](#1.1 模型架构图:)
- [1.2 缩放点积注意力:](#1.2 缩放点积注意力:)
- [1.3 多头自注意力:](#1.3 多头自注意力:)
- [2. 数据流如何通过模型](#2. 数据流如何通过模型)
- [3. 代码实战:实现完整的Encoder-Decoder Transformer](#3. 代码实战:实现完整的Encoder-Decoder Transformer)
-
- [3.1 Encoder-only的Transformer block](#3.1 Encoder-only的Transformer block)
- [3.2 完整可训练的Transformer](#3.2 完整可训练的Transformer)
- [3.3 手撕实现千问3Dense,实现对话功能。(学习他人的开源项目)](#3.3 手撕实现千问3Dense,实现对话功能。(学习他人的开源项目))
1. 模型架构与模块分解
1.1 模型架构图:
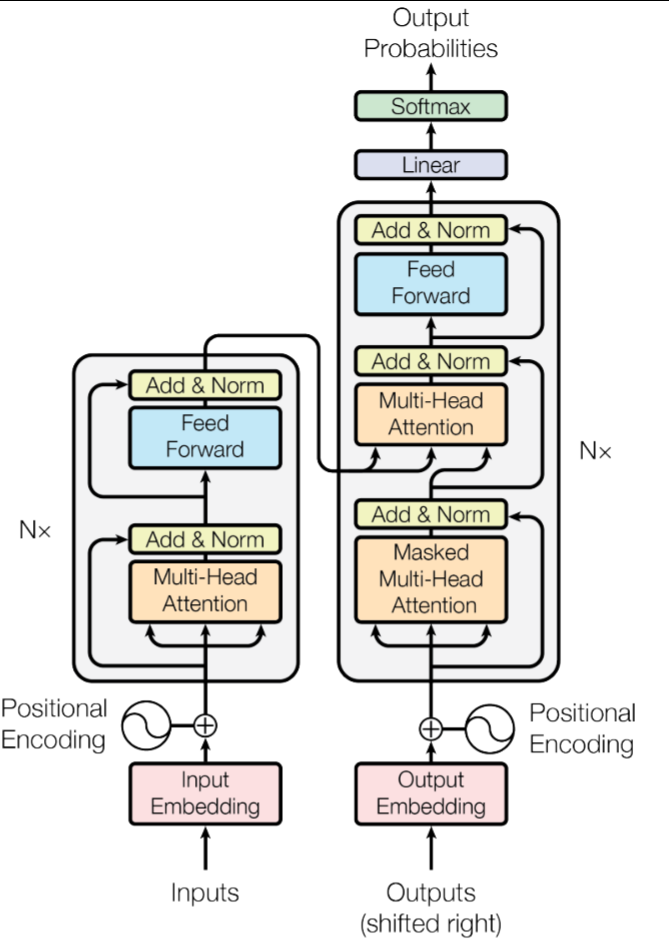
由Embedding层、位置编码、TransformerBlock(Decoder和Encoder,多头自注意力+残差连接+归一化+FNN前馈层),最后有一个线性层(作用是把d_model长度的特征映射为vocab_size长度的向量),再经softmax层得到下一个token对应vocab_size大小的词表中的概率。
1.2 缩放点积注意力:
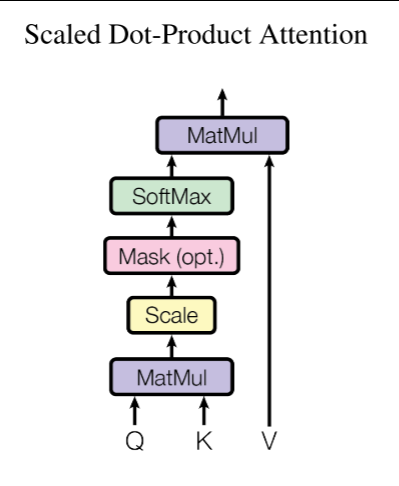
通俗来说就是输入一段序列,序列经过自注意力之后,序列中的各个token能够根据自己的目标(Query),重点关注序列和自己最相关的其他token。自注意力的核心目标是:给输入序列里的每一个token,都生成一个融合了整个序列所有上下文信息的新向量。
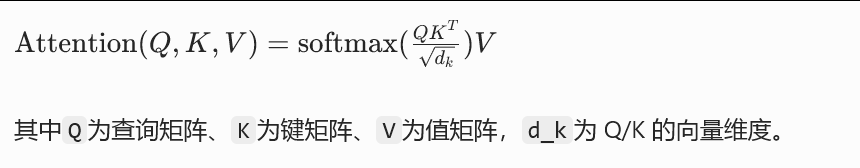
1.3 多头自注意力:
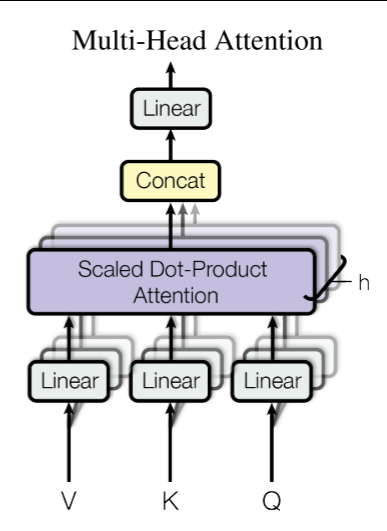
使用多头注意力来建模序列内各token之间的多维度关系,比如动宾关系、主谓关系等等,具体做法是把注意力计算拆成h个独立的「头」(按特征维度拆分),每个头都是一个完整的「单头缩放点积注意力」,每个头专门学习一种类型的语义 / 语法依赖,最后把所有头的结果汇总,模型的表达能力直接翻倍。
2. 数据流如何通过模型
一、先看整体架构总览
这张图完全对应《Attention Is All You Need》的标准Transformer结构,分为两大核心部分:
-
左半部分:编码器(Encoder):负责「理解输入文本」,把输入序列转化为带全局上下文的语义编码。
-
右半部分:解码器(Decoder):负责「生成输出文本」,基于编码器的语义编码,自回归地逐token生成目标序列。
-
图中N×:代表该模块会重复堆叠N次(原论文默认N=6,即编码器、解码器各堆叠6层)。
二、左半部分:编码器(Encoder)全拆解
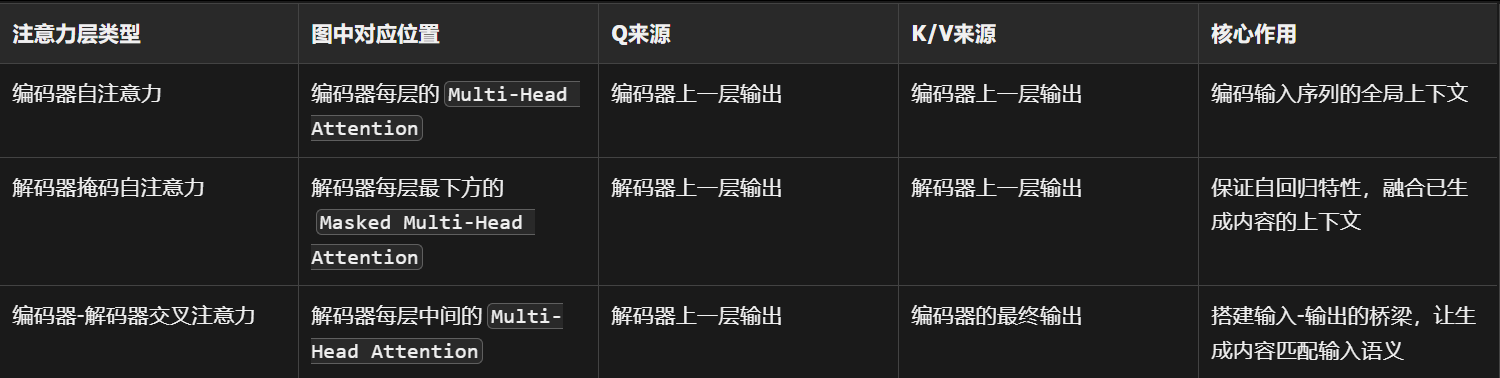
对应你之前学的编码器自注意力层,我们从下到上,跟着箭头走通每一步:
- 编码器输入预处理层(最底部)
python
Inputs → Input Embedding → 【+ Positional Encoding】 → 输入编码器堆叠层
-
Inputs:输入的原始文本序列(比如机器翻译的源语言句子),会先拆成一个个token。
-
Input Embedding:嵌入层,把离散的token转化为固定维度的稠密向量,让文本变成模型可计算的数值。
-
Positional Encoding:位置编码,和嵌入向量直接相加,为token注入序列位置信息(Transformer没有循环结构,无法天然感知顺序)。
- 编码器单层结构(N次堆叠的核心)
同样每个子模块都标配残差连接+Add & Norm,3个子模块从下到上依次是:
① 第一个子模块:Masked Multi-Head Attention → 【解码器掩码自注意力层】
这就是带因果掩码的自注意力,完全对应:
-
Q、K、V的来源:全部来自解码器上一层的输出,三者同源,也是自注意力。
-
掩码设计:核心的因果掩码,在Softmax计算前,把得分矩阵的上三角(当前位置之后的token)全部设为-∞,Softmax后权重为0。
效果:解码器的每个token,只能关注到当前位置及之前已经生成的token,完全看不到未来的内容,严格保证自回归生成的合理性。
- 核心作用:给已生成的输出序列做上下文融合,同时杜绝信息泄露。
② 第二个子模块:Multi-Head Attention → 【编码器-解码器交叉注意力层】
这就是交叉注意力,是连接编码器和解码器的核心桥梁,完全对应:
-
Q、K、V的来源:
-
Q(查询):来自解码器上一层(也就是下面Masked Attention)的输出;
-
K(键)、V(值):全部来自左边编码器的最终输出。
-
-
掩码设计:无掩码,解码器的每个位置都能关注到输入序列的所有位置。
-
核心作用:让解码器生成每一个token时,都能动态关注输入序列里最相关的内容。比如翻译时,生成中文「苹果」,会重点关注英文输入里的apples。
③ 第三个子模块:Feed Forward → 前馈神经网络
和编码器里的前馈层完全一致,对每个token的向量做独立的非线性变换,提炼特征,同样标配残差连接+Add & Norm。
- 编码器的最终输出
堆叠N层后的解码器输出,向上进入最终的预测环节:
python
解码器输出 → Linear → Softmax → Output Probabilities-
Linear:线性层,把解码器输出的高维语义向量,映射到和目标词表大小一致的维度。
-
Softmax:归一化层,把线性层的输出转化为词表中每个token的生成概率,概率最高的token就是当前步的预测输出。
-
Output Probabilities:最终的输出概率,就是模型生成的目标序列。
四、三种注意力层与图的精准对应表
五、一句话走通完整数据流
以机器翻译为例,输入英文I love apples,目标输出中文我爱苹果,整个流程在图里的走向是:
-
英文输入进入左半部分编码器,经过嵌入+位置编码,再通过6层编码器的自注意力+前馈层,得到英文句子的完整语义编码;
-
解码器先接收已生成的内容(初始是句子开始符),经过嵌入+位置编码,进入6层解码器:
-
先过掩码自注意力,融合已生成的内容,且不偷看未来;
-
再过交叉注意力,用当前生成的特征,去匹配编码器的英文语义编码,找到最相关的内容;
-
最后过前馈层提炼特征;
-
解码器输出经过Linear+Softmax,预测出下一个token(比如第一个预测出「我」);
-
把「我」加入解码器的输入,重复上述步骤,依次预测出「爱」「苹果」,直到生成句子结束符,完成整个生成过程。
3. 代码实战:实现完整的Encoder-Decoder Transformer
3.1 Encoder-only的Transformer block
这是很容易实现的,架构为:
text
x ──┬──────────────────────► (+) ─► LayerNorm ──┬────────────────► (+) ─► LayerNorm ─► y
│ ▲ │ ▲
│ │ │ │
└──► Multi-Head Attention ─┘ └──► FeedForward ───┘仓库中提交了上述架构的代码:https://github.com/QiZhang603/Mini-Transformer-Block/commit/45fac77efe1972e319c26602f70178c535dc1976。
3.2 完整可训练的Transformer
在 Encoder-only的Transformer block的基础上,需要做:
- "在 mini_Transformer.py 中添加 Token Embedding 与正弦/可学习位置编码,输出 shape 与 d_model 对齐,并在 forward 中相加后加 dropout。"
- "实现 padding mask 与 look-ahead mask 生成函数,返回可直接喂给 MultiheadAttention(手动实现,而不是调用nn.MultiheadAttention) 的 attn_mask 和 key_padding_mask。"
- "新增 DecoderBlock:masked self-attn、cross-attn、FFN、LayerNorm+残差(Pre-LN),支持返回注意力权重。"
- "创建完整 Transformer 类,持有嵌入、Encoder、Decoder,前向接受 src/tgt 及掩码,输出 logits;可选权重共享。"
- "添加输出投影到 vocab_size 的线性层;提供最小训练脚手架(CE loss、optimizer 占位、梯度裁剪、lr 调度钩子)与简单自测(形状、掩码、tiny 过拟合)。"
该版本并没有对数据集进行编码、分词、训练与输出。仍有瑕疵。
3.3 手撕实现千问3Dense,实现对话功能。(学习他人的开源项目)
数据集为TinyStory。是一位博主的开源项目,目前已经阅读完了源码,还差:训练分词器、对TinyStory数据集进行分词、本地跑一次实验训练模型看结果、租服务器训练模型看结果。