作者:来自 Elastic Jeffrey Rengifo

学习如何将五种常见的 Elasticsearch runtime field 模式迁移到其 ES|QL 等价实现,包含并排代码对比以及在何种情况下适合使用每种方法的指导。
动手体验 Elasticsearch:深入了解 Elasticsearch Labs 仓库中的示例 notebooks,开始免费的云试用,或现在就在本地机器上试用 Elastic。
Elasticsearch runtime fields 解决了在查询时计算值而无需重新索引(reindexing)的问题。但它们伴随着 Painless 脚本的复杂性以及随文档数量增长而增加的性能成本。Elasticsearch Query Language(ES|QL)提供了更强大的替代方案,具有专用执行引擎、管道处理,并且无需脚本。在本文中,你将学习如何将五种常见的 runtime field 模式映射到其 ES|QL等价实现,从而使你的查询现代化,并理解在何种情况下使用每种方法更合适。
前置条件
- Elasticsearch 8.15+(用于支持 :: 类型转换操作符;核心 ES|QL 功能从 8.11 开始可用)
Runtime fields 与 ES|QL 对比
Runtime fields 于 Elasticsearch 7.11 引入,用于在查询时定义字段。你无需重新索引数据,而是可以编写 Painless 脚本来动态计算值:
PUT my-index/_mapping
{
"runtime": {
"full_address": {
"type": "keyword",
"script": {
"source": "emit(doc['address'].value + ':' + doc['port'].value)"
}
}
}
}这可以工作,但也带来一些权衡:
- Painless 脚本开销:每个 runtime field 都需要脚本知识,而且语法类似 Java,而不是查询式语法。
- 性能成本:runtime fields 在查询时对每个文档进行计算。Elasticsearch 将其归类为 "昂贵查询",可能会被集群设置拒绝。
- 隔离计算:每个 runtime field 独立计算。在同一查询中,无法将多个转换串联或使用一个字段的输出作为另一个字段的输入。
ES|QL 改变了这一局面。它拥有自己的执行引擎(不转换为 Query DSL),在节点间并发运行查询,并提供完整的字段计算工具集:EVAL、GROK、DISSECT、类型转换以及管道链式处理。
让我们看看每种 runtime field 模式如何映射到 ES|QL。
设置示例数据
本文中的所有代码片段都可以在 Kibana Dev Tools 控制台中执行。
为了跟随操作,创建一个包含数据的示例索引,用于演示这五种模式。这模拟了一个服务器日志场景,包含混合字段类型、原始消息以及一些有意设置的数据质量问题:
PUT server-logs
{
"mappings": {
"properties": {
"host": { "type": "keyword" },
"port": { "type": "keyword" },
"raw_message": { "type": "text" },
"response_time": { "type": "keyword" },
"status_code": { "type": "keyword" },
"region": { "type": "keyword" }
}
}
}现在索引一些示例文档:
POST _bulk
{ "index": { "_index": "server-logs" } }
{ "host": "web-01", "port": "8080", "raw_message": "2024-01-15 INFO user=alice action=login duration=230ms", "response_time": "145", "status_code": "200", "region": "us-east" }
{ "index": { "_index": "server-logs" } }
{ "host": "web-02", "port": "443", "raw_message": "2024-01-15 ERROR user=bob action=upload duration=1200ms", "response_time": "not_available", "status_code": "500", "region": "eu-west" }
{ "index": { "_index": "server-logs" } }
{ "host": "api-01", "port": "3000", "raw_message": "2024-01-15 WARN user=charlie action=query duration=890ms", "response_time": "890", "status_code": "200", "region": "us-east" }
{ "index": { "_index": "server-logs" } }
{ "host": "api-02", "port": "3000", "raw_message": "2024-01-16 INFO user=diana action=export duration=3400ms", "response_time": "3400", "status_code": "200", "region": "ap-south" }
{ "index": { "_index": "server-logs" } }
{ "host": "web-01", "port": "8080", "raw_message": "2024-01-16 ERROR user=eve action=login duration=50ms", "response_time": "50", "status_code": "401", "region": "US-EAST" }注意 ,response_time 被存储为 keyword(这是现实中常见的错误),而最后一个文档使用了 "US-EAST" 而不是 "us-east"(这是一个我们稍后会修复的数据质量问题)。
模式 1:字段拼接
一个常见的 runtime field 使用场景是将两个字段组合成一个。例如,创建一个 host:port 标识符。
runtime field 方法
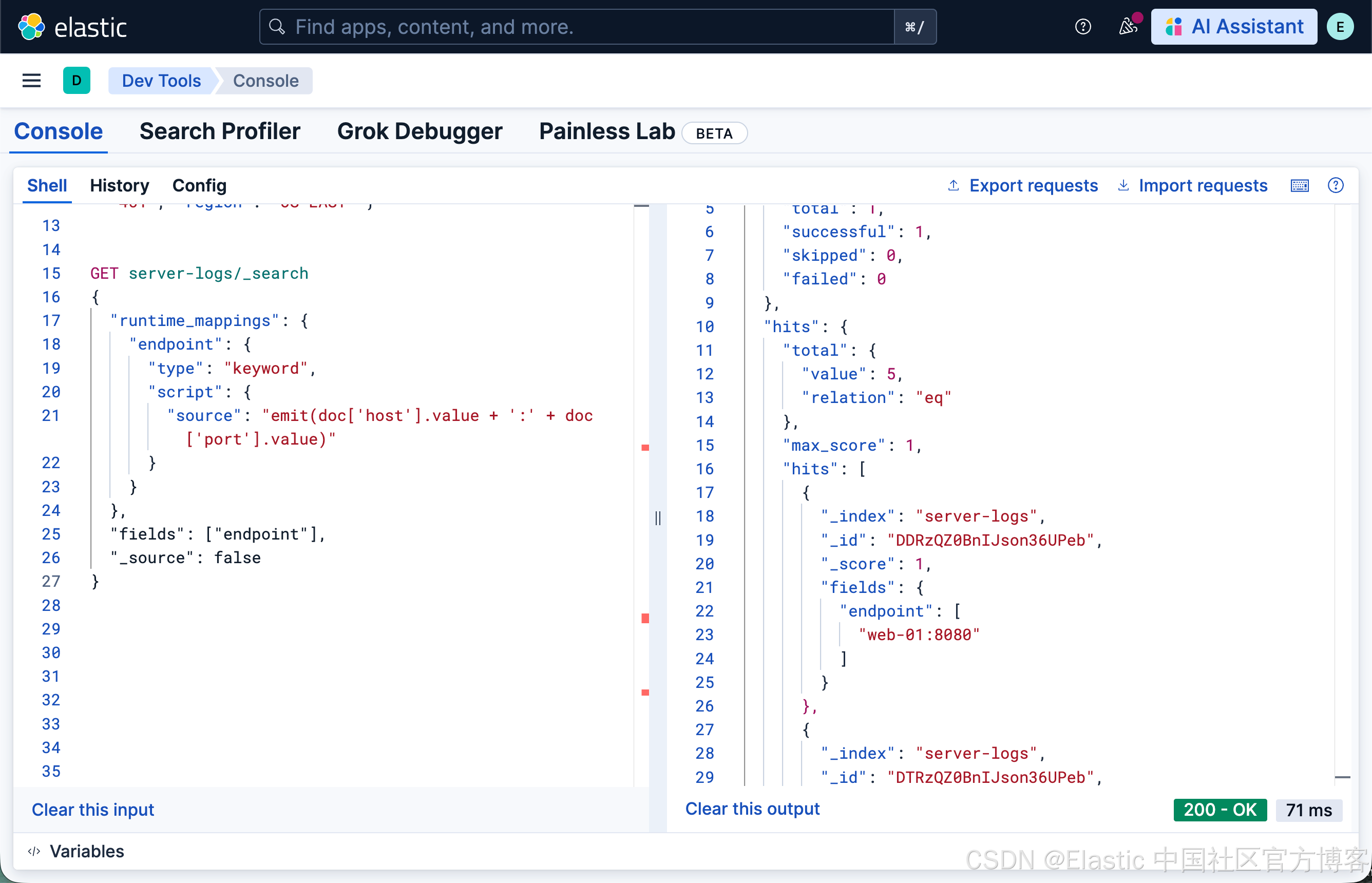
你可以在查询时内联定义它。查询时的方法避免修改 mapping,但仍然需要 Painless 脚本,并且只作用于单个搜索请求:
GET server-logs/_search
{
"runtime_mappings": {
"endpoint": {
"type": "keyword",
"script": {
"source": "emit(doc['host'].value + ':' + doc['port'].value)"
}
}
},
"fields": ["endpoint"],
"_source": false
}
ES|QL 方法
你可以使用 _query API endpoint 运行 ES|QL 查询:
POST _query
{
"query": """
FROM server-logs
| EVAL endpoint = CONCAT(host, ":", port)
| KEEP host, port, endpoint
| LIMIT 1
"""
}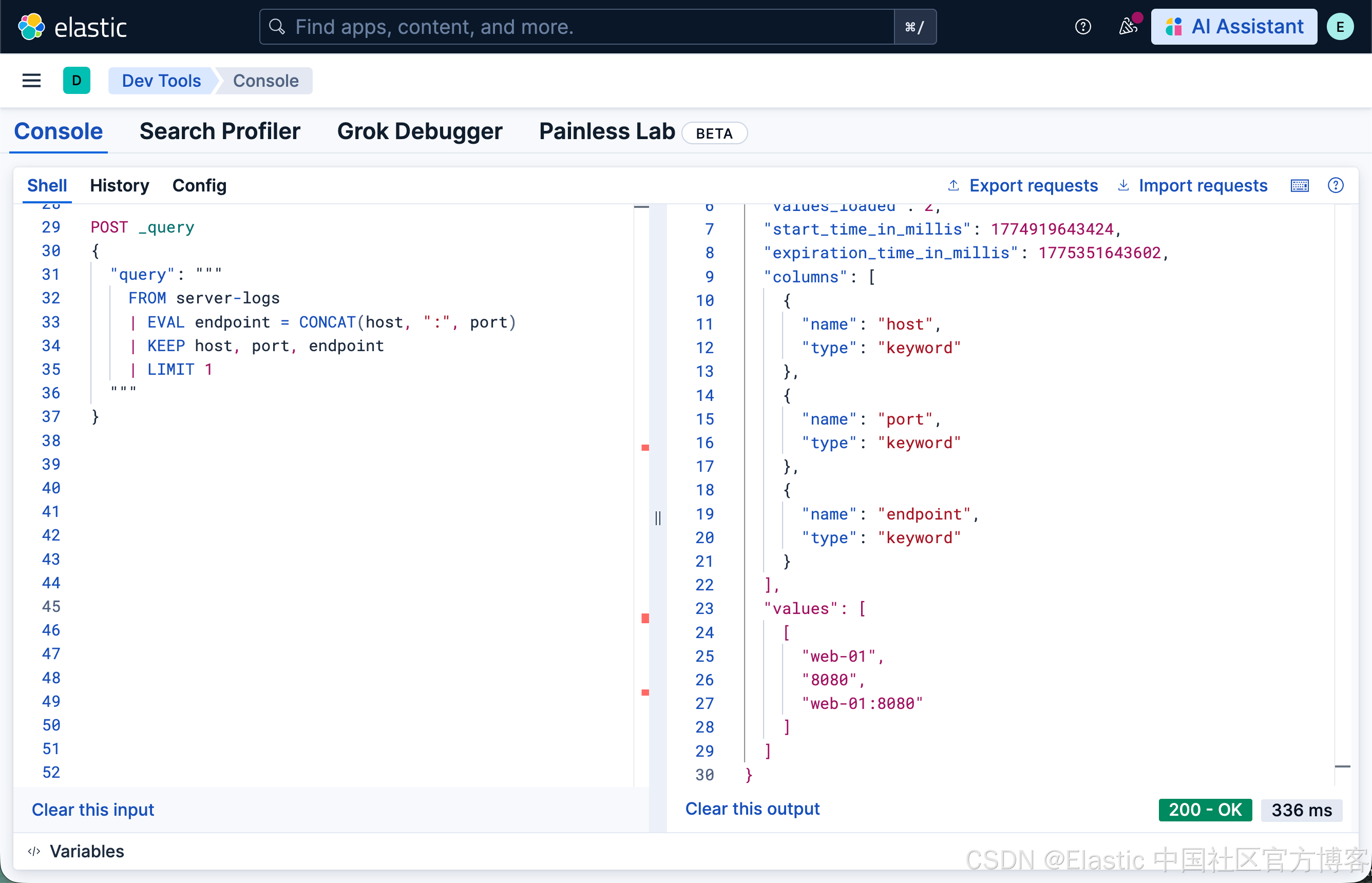
CONCAT 接受两个或多个参数,并始终返回 keyword。
注意:为简洁起见,本文其余的 ES|QL 示例仅展示查询本身。在 Kibana Dev Tools 中运行时,请将它们包裹在 POST _query { "query": "..." } 中。
何时使用
如果你需要该字段在所有查询中持久存在,并在 Kibana 仪表板中可用,请使用 mapping 级别的 runtime field。如果你只在 Query DSL 的单次搜索请求中需要它,请使用查询时的 runtime field。如果你用于临时分析或探索性工作,ES|QL 更简单。
模式 2:从非结构化文本中提取数据
从原始日志消息中提取结构化数据是另一个经典的 runtime field 模式。
Runtime field 方法
Painless 使用 Java 的 regex Matcher 类:
GET server-logs/_search
{
"runtime_mappings": {
"log_user": {
"type": "keyword",
"script": {
"source": "def matcher = /user=(\\w+)/.matcher(params._source['raw_message']); if (matcher.find()) { emit(matcher.group(1)); }"
}
}
},
"fields": ["log_user"],
"_source": false
}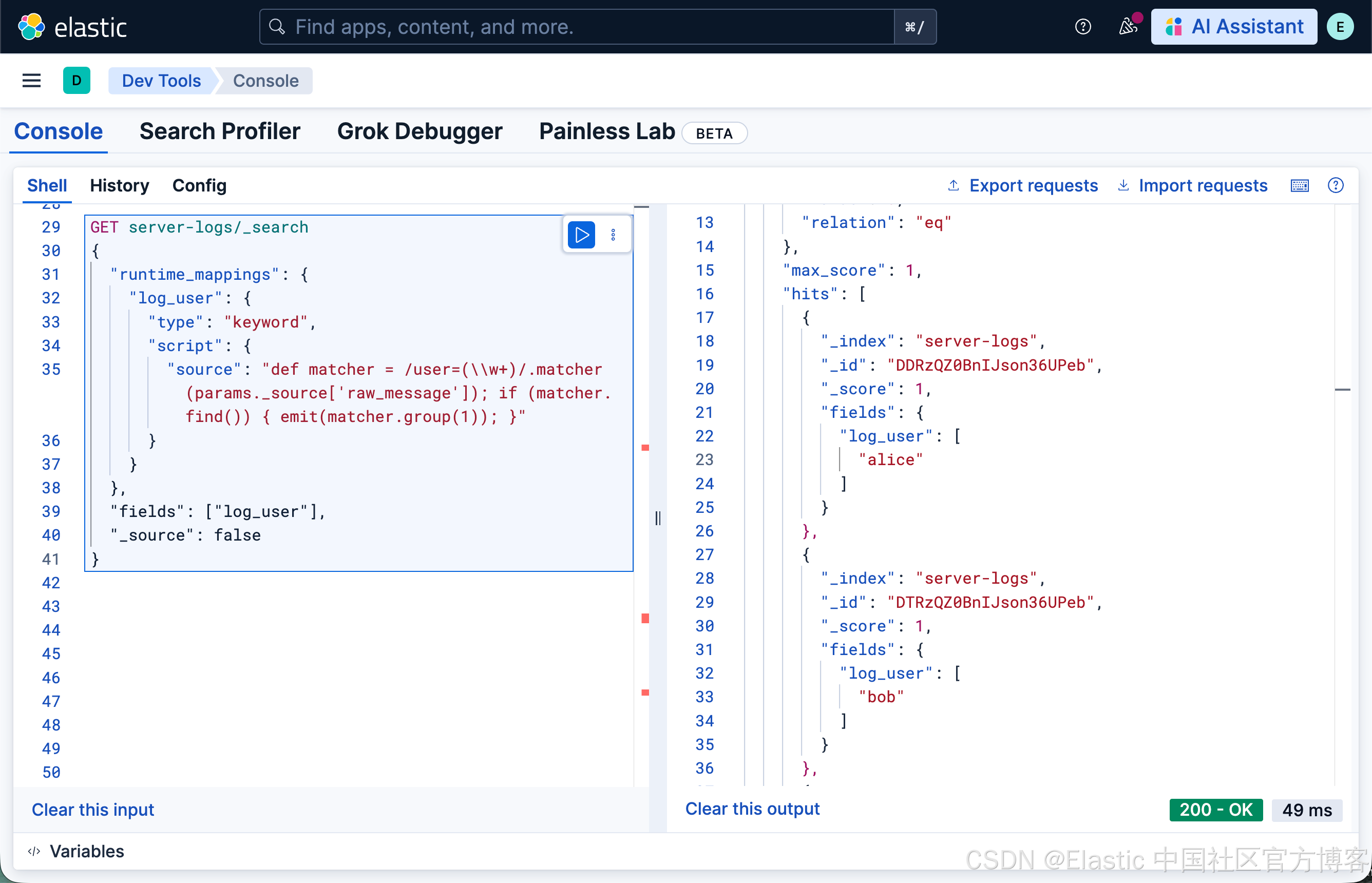
这种方法冗长。你需要了解 Painless 的正则语法、处理 Matcher 对象,并正确调用 emit()。
ES|QL 方法:GROK
ES|QL 提供了两个专门用于文本提取的命令。GROK 使用基于正则的模式:
FROM server-logs
| GROK raw_message "%{WORD:timestamp_date} %{WORD:log_level} user=%{WORD:user} action=%{WORD:action} duration=%{WORD:duration}"
| KEEP user, log_level, action, duration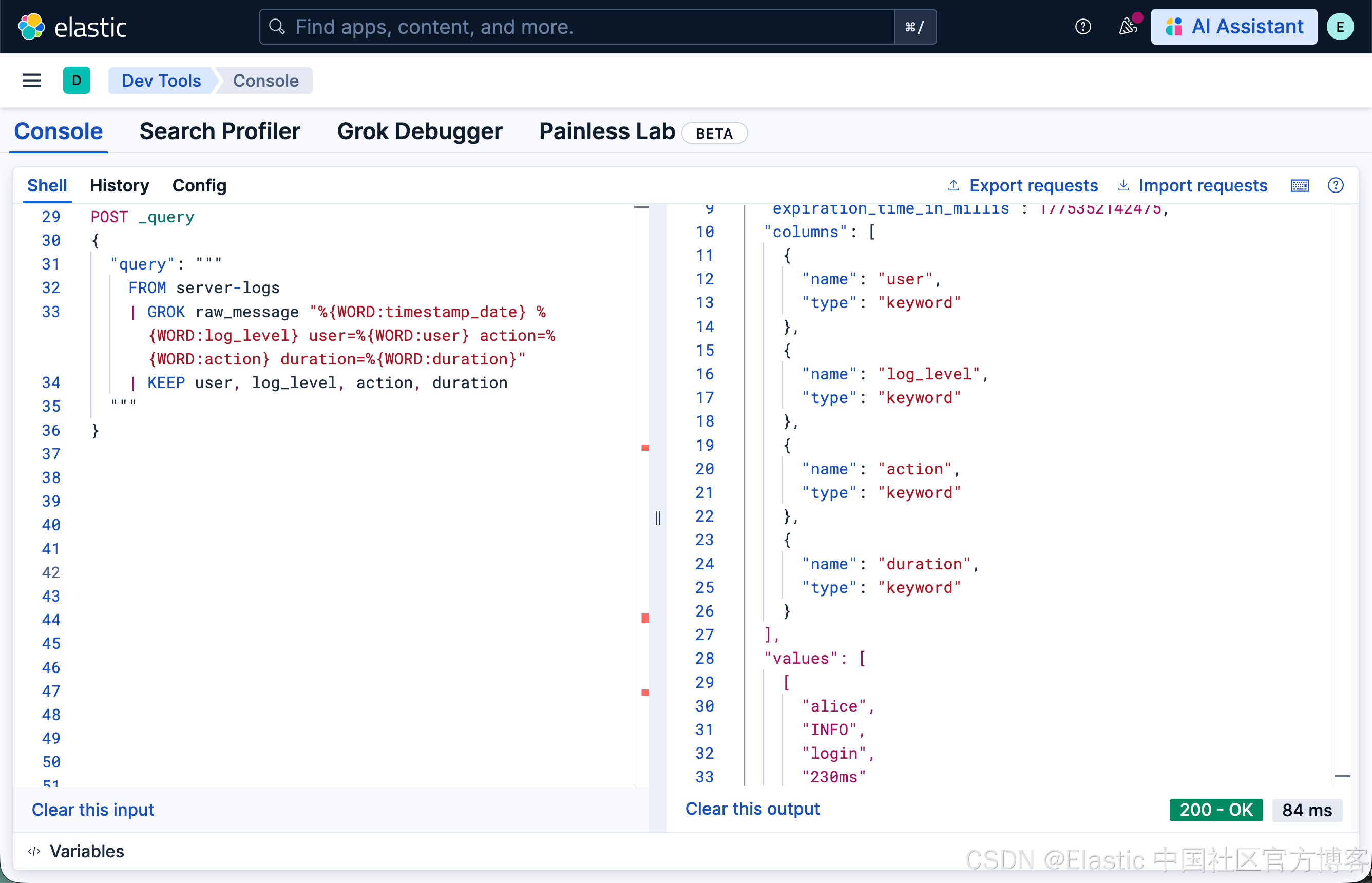
GROK 使用 %{SYNTAX:SEMANTIC} 模式格式。它可以在单条可读命令中提取多个字段。
ES|QL 方法:DISSECT
对于具有一致分隔符的结构化数据,DISSECT 更快,因为它不使用正则表达式:
FROM server-logs
| DISSECT raw_message "%{timestamp_date} %{log_level} user=%{user} action=%{action} duration=%{duration}"
| KEEP user, log_level, action, duration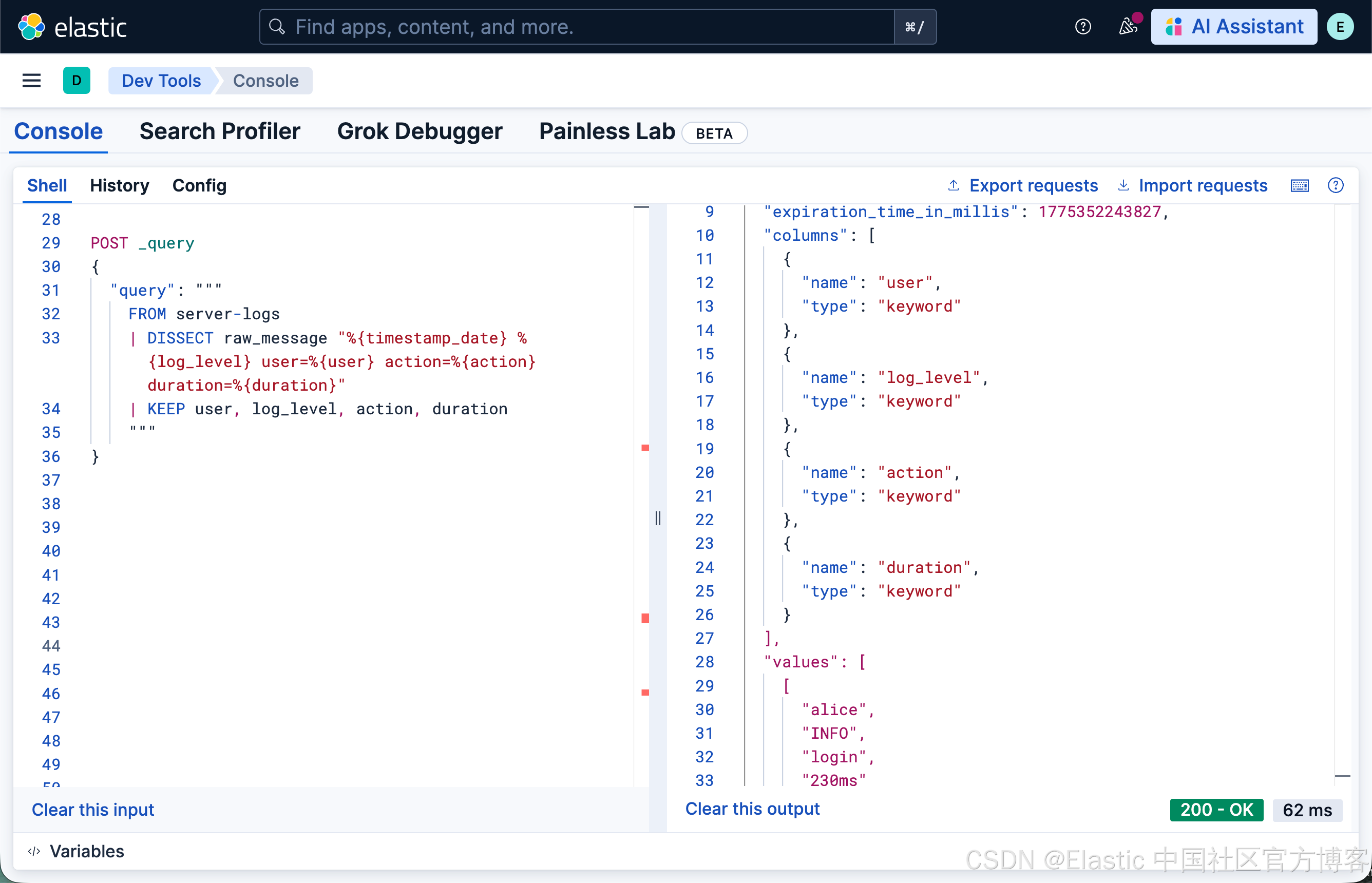
语法与 GROK 几乎相同,但 DISSECT 通过分隔符拆分数据,而不是匹配正则模式。这使得它在处理遵循一致格式的数据时更快。
何时使用 GROK 与 DISSECT
当你的数据结构可预测(相同分隔符、相同字段顺序)时使用 DISSECT。当你需要正则灵活性时使用 GROK,例如字段可能是可选的或格式不一致时。
模式 3:动态类型转换
当字段被映射为 keyword 但包含数字数据(这是一个意外常见的情况)时,runtime field 可以在查询时进行类型转换。
Runtime field 方法
GET server-logs/_search
{
"runtime_mappings": {
"response_time_long": {
"type": "long",
"script": {
"source": """
def val = doc['response_time'].value;
if (val != 'not_available') {
emit(Long.parseLong(val));
}
"""
}
}
},
"fields": ["response_time_long"],
"_source": false
}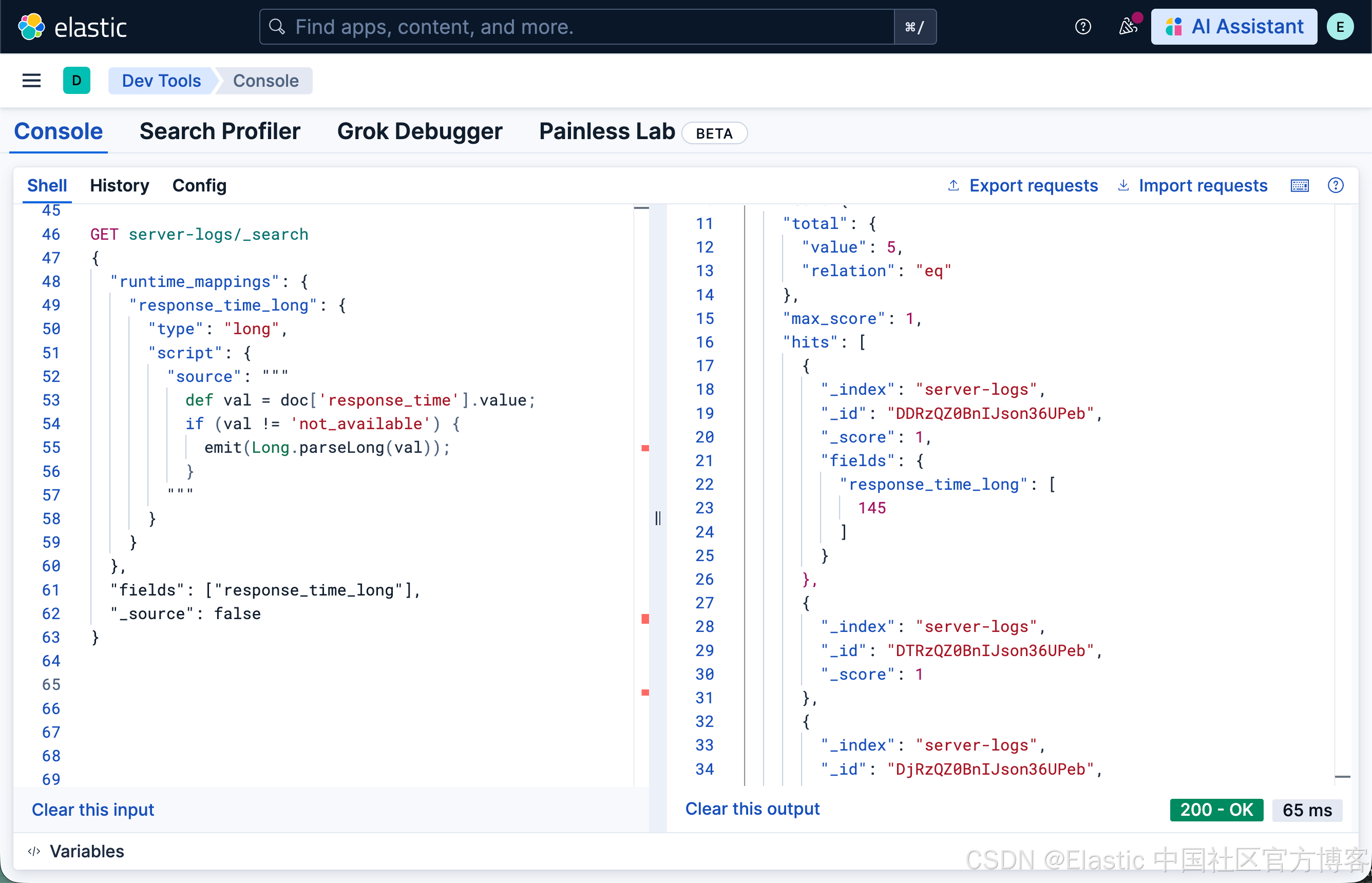
你需要手动处理解析异常。如果 Long.parseLong 在遇到意外值时失败,脚本会抛出错误。
ES|QL 方法
ES|QL 提供了显式的转换函数以及简写的类型转换操作符:
FROM server-logs
| EVAL response_ms = TO_LONG(response_time)
| KEEP host, response_time, response_ms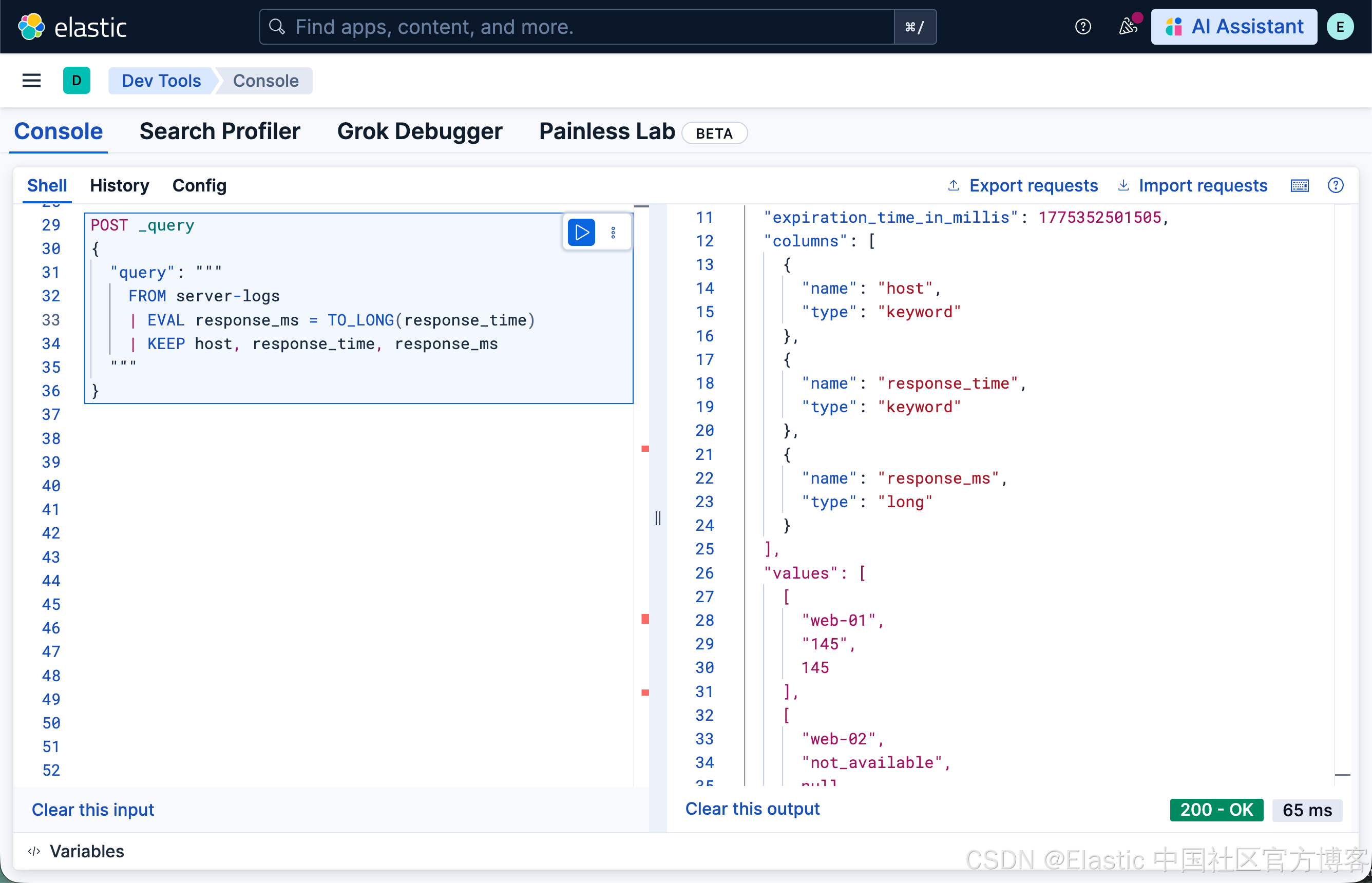
或者使用 :: cast 操作符(自 8.15 起可用):
FROM server-logs
| EVAL response_ms = resonse_time::long
| KEEP host, response_time, response_msp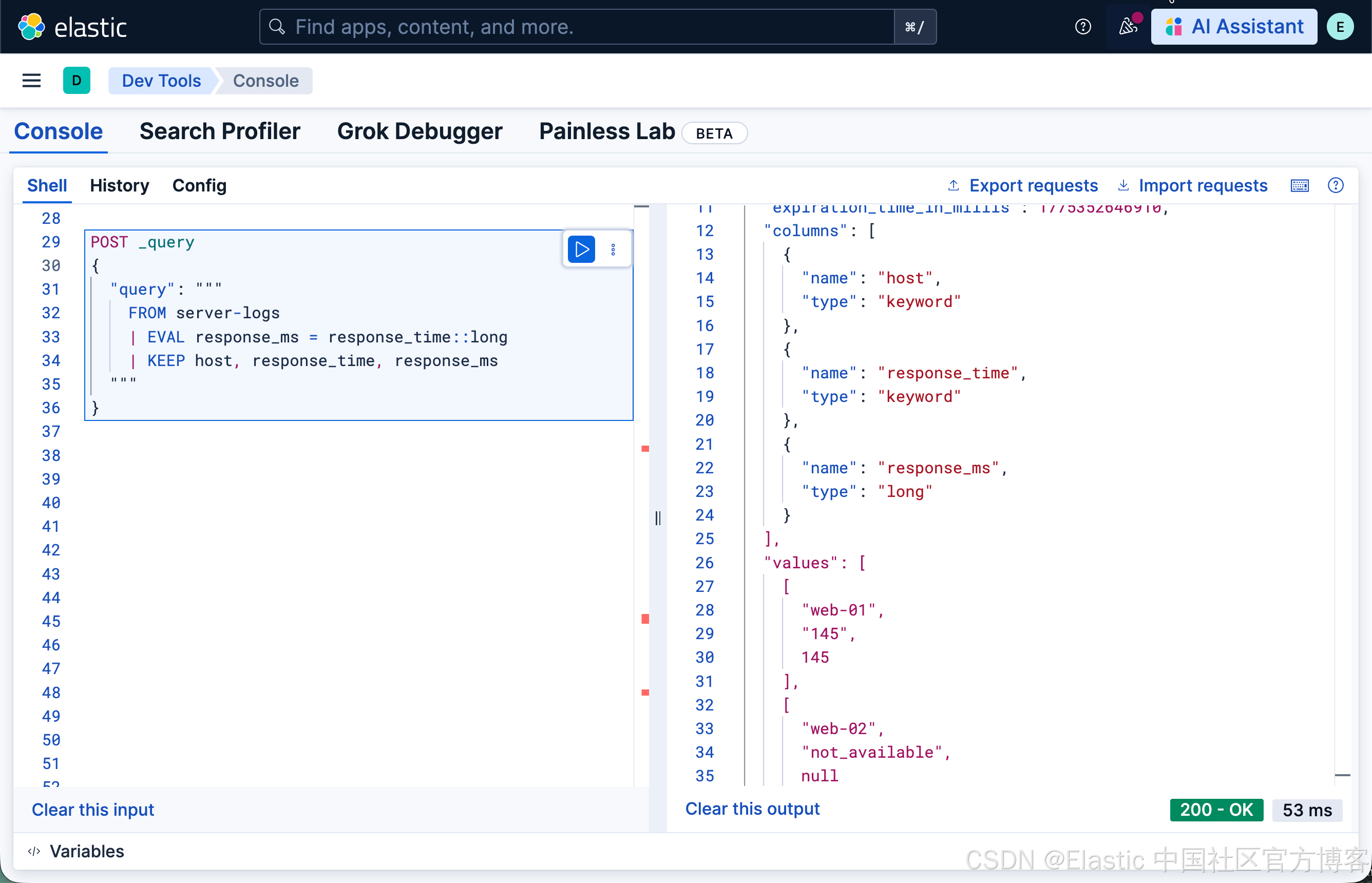
两者产生相同结果。与 Painless 的关键区别在于:转换失败会返回 null,而不是抛出异常。包含 "not_available" 的文档的 response_ms 字段将返回 null,ES|QL 会发出警告。
常用转换函数包括:
| Function | Converts to |
|---|---|
| `TO_LONG()` | Long integer |
| `TO_INTEGER()` | Integer |
| `TO_DOUBLE()` | Double |
| `TO_DATETIME()` | Date |
| `TO_BOOLEAN()` | Boolean |
| `TO_IP()` | IP address |
| `TO_VERSION()` | Version |
:: 操作符适用于所有这些类型(例如,field::double、field::datetime)。
何时使用
ES|QL 的优雅 null 处理使其在处理脏数据时更安全。使用 Painless 的 runtime fields 可以对错误处理进行细粒度控制,但需要更多代码。对于类型转换,ES|QL 几乎总是更好的选择。
模式 4:
Runtime fields 支持 mapping 中的 "dynamic": "runtime",通过将所有新字段创建为 runtime fields 而不是索引字段,从而防止 mapping 爆炸:
{
"mappings": {
"dynamic": "runtime",
"properties": {
"timestamp": { "type": "date" }
}
}
}发送到该索引的任何新字段都会自动成为 runtime field。当你摄取具有不可预测字段名的半结构化数据时,这非常有用。
ES|QL 的适用场景
ES|QL 提供查询时的灵活性,但仍然需要字段在 mapping 中可见。这时 runtime fields 与 ES|QL 是互补的,而不是互相竞争。
如果字段存在于 _source 中但未映射,ES|QL 无法直接访问它。当前的解决方法是定义一个 runtime field,使未映射字段可见:
PUT dynamic-logs/_mapping
{
"runtime": {
"custom_field": {
"type": "keyword",
"script": {
"source": "emit(params._source['custom_field'])"
}
}
}
}定义后,ES|QL 就可以查询它:
FROM dynamic-logs
| WHERE custom_field == "some_value"
| KEEP timestamp, custom_field这是 runtime fields 仍然不可或缺的一个场景。它们充当桥梁,使未映射的数据对 ES|QL 可访问。
模式 5:字段覆盖用于错误修正
Runtime fields 可以通过定义与现有字段同名的 runtime field 来覆盖(shadow)索引字段。这对于无需重新索引即可修正数据非常有用。
Runtime field 方法
还记得我们的数据质量问题吗,region 字段的大小写不一致("US-EAST" 与 "us-east")?
GET server-logs/_search
{
"runtime_mappings": {
"region": {
"type": "keyword",
"script": {
"source": "emit(params._source['region'].toLowerCase())"
}
}
},
"fields": ["region"],
"_source": false
}这会覆盖索引的 region 字段,应用于所有查询。每次搜索、聚合和 Kibana 可视化都将看到小写版本。
FROM server-logs
| EVAL region = TO_LOWER(region)
| KEEP host, port, region当你在现有列名上使用 EVAL 时,ES|QL 会删除原始列并用计算值替换它。这与字段覆盖完全等效,但作用范围仅限于当前查询。
你还可以在管道中链式执行多个修正:
FROM server-logs
| EVAL region = TO_LOWER(region)
| EVAL region = CASE(region == "us-east", "US East", region == "eu-west", "EU West", region == "ap-south", "AP South", region)
| KEEP host, region何时使用
如果修正应适用于所有查询和 Kibana 仪表板,请使用 runtime field 覆盖。如果你只需针对特定分析修正数据,ES|QL 更灵活,因为你可以在不同查询中应用不同的转换,而无需修改 mapping。
ES|QL 管道的优势:超越 runtime fields
这就是 ES|QL 在根本上超越 runtime fields 的地方。runtime fields 是孤立的:每个字段独立计算,无法在同一查询中将一个 runtime field 的输出作为另一个的输入。
ES|QL 管道可以链式转换。以下是一个结合多个模式的单条查询:
FROM server-logs
| GROK raw_message "%{WORD:log_date} %{WORD:log_level} user=%{WORD:user} action=%{WORD:action} duration=%{INT:duration_raw}ms"
| EVAL duration_ms = duration_raw::long
| EVAL region = TO_LOWER(region)
| WHERE log_level == "ERROR" AND duration_ms > 100
| STATS avg_duration = AVG(duration_ms), error_count = COUNT(*) BY region这条单独的查询:
- 从原始文本中提取字段(GROK)。
- 将 duration 转换为数字(EVAL + cast)。
- 规范化 region 大小写(EVAL + TO_LOWER)。
- 筛选高 duration 的错误(WHERE)。
- 按 region 聚合(STATS)。
要用 runtime fields 达到同样效果,你至少需要定义三个独立的 runtime fields(用于提取、转换和规范化),然后再写一个包含过滤和聚合的 Query DSL 查询。而 ES|QL 版本是一条可读性强的管道。
你甚至可以在聚合中直接使用表达式:
FROM server-logs
| EVAL response_ms = response_time::long
| STATS
avg_response = AVG(response_ms),
p95_response = PERCENTILE(response_ms, 95),
slow_count = COUNT(CASE(response_ms > 1000, 1, null))
BY host结论
我们涵盖的内容:
- ES|QL 提供了完整工具集(EVAL、GROK、DISSECT、:: 类型转换),可以在无需 Painless 脚本的情况下替代大多数 runtime field 模式。
- ES|QL 中的类型转换失败会返回 null 而不是抛出异常,这对于真实数据更安全。
- 管道处理(将 GROK 链入 EVAL,再链入 WHERE,再链入 STATS)超出了 runtime fields 独立使用时的能力。
- Runtime fields 对于持久计算字段、跨所有查询的字段覆盖以及作为 ES|QL 未映射数据的桥梁仍然有价值。
一个重要的注意事项:runtime fields 和 ES|QL 都是在查询时计算值,这意味着每次查询都会付出成本。如果你发现自己重复应用相同的转换(类型修正、字段提取、数据规范化),可以考虑使用 ingest pipelines 在索引时修正数据。Ingest pipeline 允许在文档存储前进行解析、丰富和转换,使查询可以直接使用干净、类型正确的字段。runtime fields 和 ES|QL 非常适合探索性和临时分析,但对于生产工作负载,从一开始就索引正确的数据几乎总是更好的选择。
关键结论:runtime fields 并未被弃用,也不会消失。但对于大多数查询时计算模式,ES|QL 提供了更简单、更强大、更高性能的方法。当转换在前期已知时,ingest pipeline 是最有效的选项。
下一步
原文:https://www.elastic.co/search-labs/blog/elasticsearch-runtime-fields-to-esql