
| 🔭 个人主页: 散峰而望 |
|---|
《C语言:从基础到进阶》《编程工具的下载和使用》《C语言刷题》
《C++》《算法竞赛从入门到获奖》《人工智能》《AI Agent》
愿为出海月,不做归山云
🎬博主简介



【数据结构】并查集从入门到精通:基础实现、路径压缩、扩展域、带权,一网打尽
- 前言
- [1. 并查集](#1. 并查集)
-
- [1.1 双亲表示法](#1.1 双亲表示法)
- [1.2 并查集的概念](#1.2 并查集的概念)
- [1.3 并查集的实现](#1.3 并查集的实现)
-
- [1.3.1 初始化](#1.3.1 初始化)
- [1.3.2 查询操作](#1.3.2 查询操作)
- [1.3.3 合并操作](#1.3.3 合并操作)
- [1.3.4 判断操作](#1.3.4 判断操作)
- [1.4 并查集的优化](#1.4 并查集的优化)
-
- [1.4.1 路径压缩](#1.4.1 路径压缩)
- [1.4.2 按秩合并](#1.4.2 按秩合并)
- [1.4.3 按大小合并](#1.4.3 按大小合并)
- [1.5 【模板】并查集](#1.5 【模板】并查集)
- [1.6 亲戚](#1.6 亲戚)
- [1.7 Lake Counting S](#1.7 Lake Counting S)
- [2. 扩展域并查集](#2. 扩展域并查集)
-
- [2.1 团伙](#2.1 团伙)
- [2.2 食物链](#2.2 食物链)
- [3. 带权并查集](#3. 带权并查集)
-
- [3.1 带权并查集的代码实现](#3.1 带权并查集的代码实现)
- [3.2 食物链](#3.2 食物链)
- [3.3 银河英雄传说](#3.3 银河英雄传说)
- 结语
前言
1. 并查集
并查集是一种树型数据结构,专为解决动态连通性问题设计。其核心功能包括快速合并集合(Union)和查询元素所属集合(Find),广泛应用于图的连通分量统计、等价关系维护等场景。
通过路径压缩和按秩合并优化,操作时间复杂度可接近常数级。扩展域与带权并查集进一步赋予其处理复杂关系(如敌对、传递性约束)的能力,使得算法能高效解决诸如团伙判定、食物链关系等经典问题。
本内容涵盖基础实现至高级应用,结合代码模板与例题解析,系统讲解如何利用并查集高效解决实际问题。
1.1 双亲表示法
接下来要学习到的并查集,本质上就是用双亲表示法实现的森林。因此,我们先认识一下双亲表示法。
在学习树这个数据结构的时,讲到树的存储方式有很多种:孩子表示法,双亲表示法、孩子双亲表示法以及孩子兄弟表示法等。对一棵树而言,除了根节点外,其余每个结点一定有且仅有一个双亲,双亲表示法就是根据这个特点存储树的,也就是把每个结点的双亲存下来。因此,我们可以采用数组来存储每个结点的父亲结点的编号,这就实现了双亲表示法。
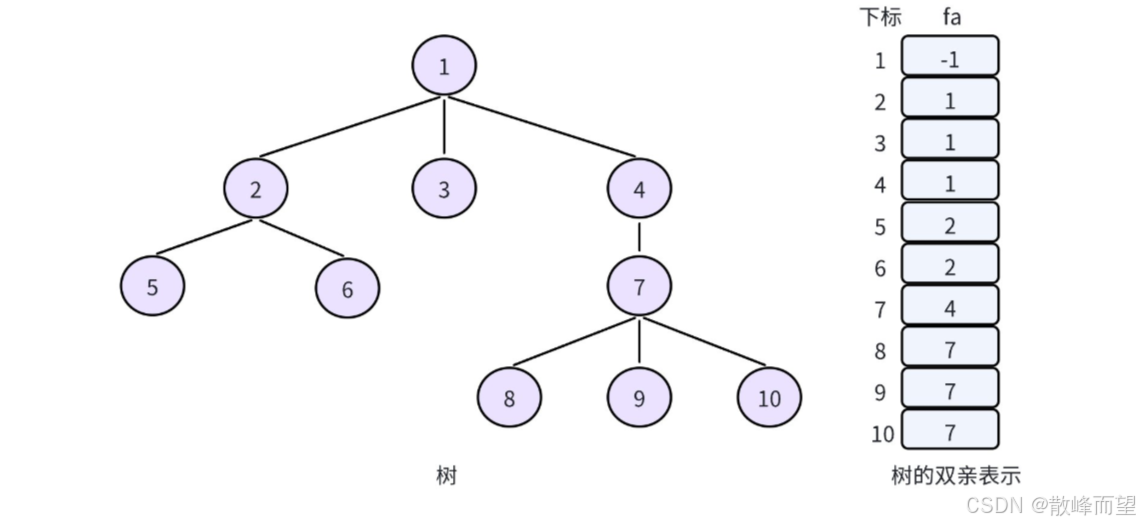
但是,在实现并查集的时,我们一般让根节点自己指向自己。因此,上述存储就变成:
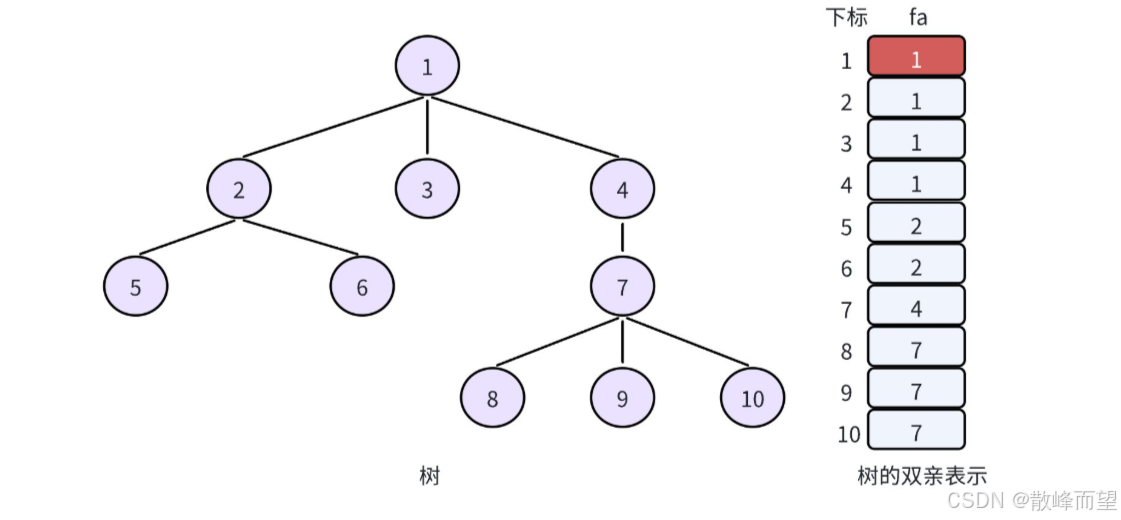
1.2 并查集的概念
在有些问题中,我们需要维护若干个集合,并且基于这些集合要频繁执行下面的操作:
- 查询操作:查找元素x属于哪一个集合。一般会在每个集合中选取一个元素作为代表,查询的是这个集合中的代表元素;
- 合并操作:将元素x所在的集合与元素y所在的集合合并成一个集合;(注意,合并的是元素所在的集合,不是这两个元素!)
- 判断操作:判断元素 x 和 y 是否在同一个集合。
并查集(Union Find):是一种用于维护元素所属集合的数据结构,实现为一个森林,其中每棵树表示一个集合,树中的节点表示对应集合中的元素,根节点来代表整个集合。
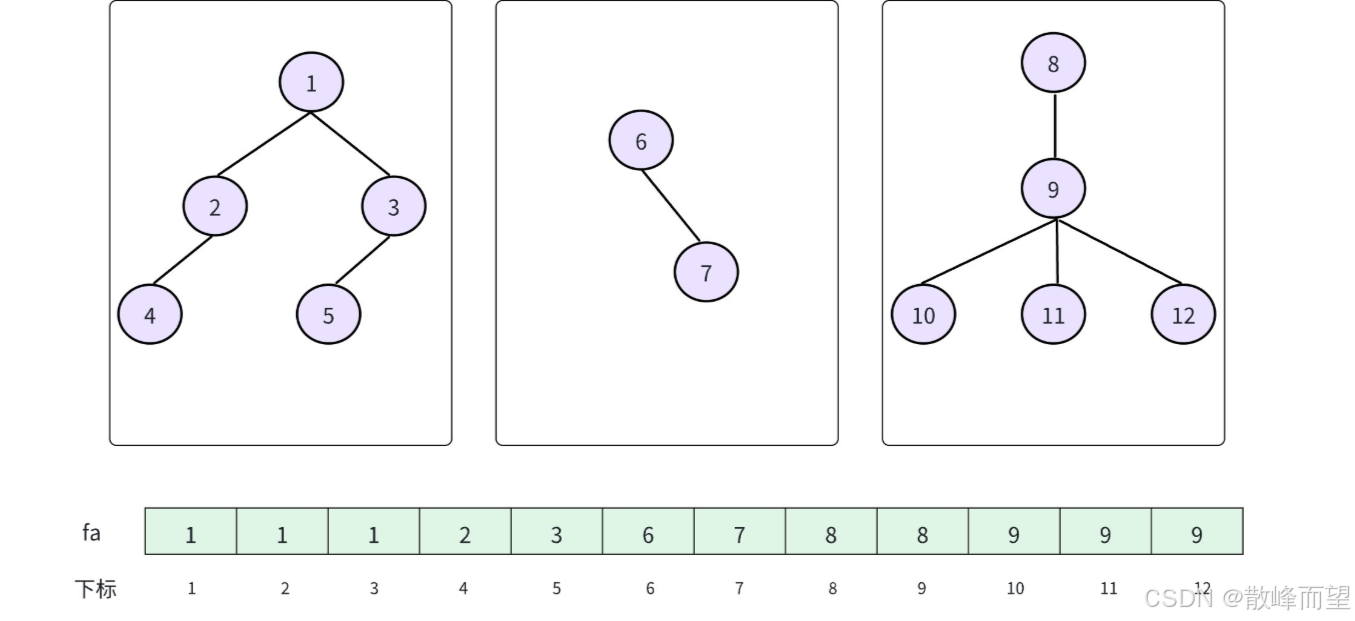
1.3 并查集的实现
1.3.1 初始化
初始状态下,所有的元素单独成为一个集合:
- 让元素自己指向自己即可
代码实现:
cpp
const int N = 1e6 + 10;
int n;
int fa[N];//双亲表示法
//初始化
void init()
{
for(int i = 1; i <= n; i++) fa[i] = i;
} 1.3.2 查询操作
查询操作是并查集的核心操作,其余所有的操作都是基于查询操作实现的!
找到元素 x 所属的集合:
- 一直向上找爸爸
代码实现:
cpp
int find(int x)
{
if(fa[x] == x) return x;
else find(fa[x]);
//一行实现
return fa[x] == x ? x : find(fa[x]);
} 1.3.3 合并操作
将元素 x 所在的集合与元素y所在的集合合并成一个集合:
- 让元素 x 所在树的根节点指向元素 y 所在树的根节点。(反过来也是可以的)
代码实现:
cpp
void un(int x, int y)
{
int fx = find(x);
int fy = find(y);
fa[fx] = fy;
} 1.3.4 判断操作
判断元素 x 和元素 y 是否在同一集合:
- 看看两者所在树的根节点是否相同
代码实现:
cpp
bool issame(int x, int y)
{
return find(x) == find(y);
} 1.4 并查集的优化
**极端情况:**在合并的过程中,整棵树变成一个链表。
因此在这种情况下需要进行优化,下面有三种优化方式。
1.4.1 路径压缩
在查询时,把被查询的节点到根节点的路径上的所有节点的父节点设置为根节点,从而减小树的深度。也就是说,在向上查询的同时,把在路径上的每个节点都直接连接到根上,以后查询时就能直接查询到根节点。
代码实现:
cpp
int find(int x)
{
if(fa[x] == x) return x;
return fa[x] == find(fa[x]);
//一行实现
return fa[x] == x ? x : fa[x] == find(fa[x]);
} 1.4.2 按秩合并
在合并时,总是将**树高度较小(或相等)** 的集合的根节点,连接到树高度较大的集合的根节点上。这里的"秩"是树高度的上界估计。也就是说,在连接两棵树时,永远让"矮个子"站在"高个子"的肩膀上,从而避免树的高度快速增长,保证查询效率。
代码实现:
cpp
int fa[N];
int h[N];
void init()
{
for(int i = 1; i <= n; i++) fa[i] = i, h[i] = 1;
}
void un(int x, int y)
{
int fx = find(x);
int fy = find(y);
if(fx != fy)
{
if(h[fx] < h[fy]) fa[fx] = fy;
else if(h[fx] > h[fy]) fa[fy] = fx;
else fa[fx] = fy, h[fy]++;
}
}1.4.3 按大小合并
在合并时,总是将元素数量较少 的集合的根节点,连接到元素数量较多的集合的根节点上。也就是说,在连接两个集合时,将"小家族"并入"大家族",以平衡整个集合树的结构。
代码实现:
cpp
int fa[N];
int s[N];
void init()
{
for(int i = 1; i <= n; i++) fa[i] = i, s[i] = 1;
}
void un(int x, int y)
{
int fx = find(x);
int fy = find(y);
if(fx != fy)
{
if(s[fx] < s[fy]) fa[fx] = fy, s[fy] += s[fx];
else fa[fy] = fx, s[fx] += s[fy];
}
}按秩合并 和按大小合并 还可以把 f[N]、s[N] 优化掉,可以自行尝试一下,这里就不过多介绍了。因为经过路径压缩优化后,并查集的时间复杂度就很优秀了。
在《算法导论》中有严格的证明,并查集查询根节点的最坏时间复杂度为 O(α(n)) ,是一个很小的常数。因此,并查集查询以及合并的效率近似可以看成 O(1) 。
1.5 【模板】并查集

算法原理:
模板直接套。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 2e5 + 10;
int n;
int fa[N];
int find(int x)
{
if(fa[x] == x) return x;
return fa[x] = find(fa[x]);
}
int main()
{
int T;
cin >> n >> T;
//初始化
for(int i = 1; i <= n; i++) fa[i] = i;
while(T--)
{
int z, x, y; cin >> z >> x >> y;
if(z == 1)//合并
{
int fx = find(x);
int fy = find(y);
fa[fx] = fy;
}
else//判断
{
if(find(x) == find(y)) cout << "Y" << endl;
else cout << "N" << endl;
}
}
return 0;
}1.6 亲戚
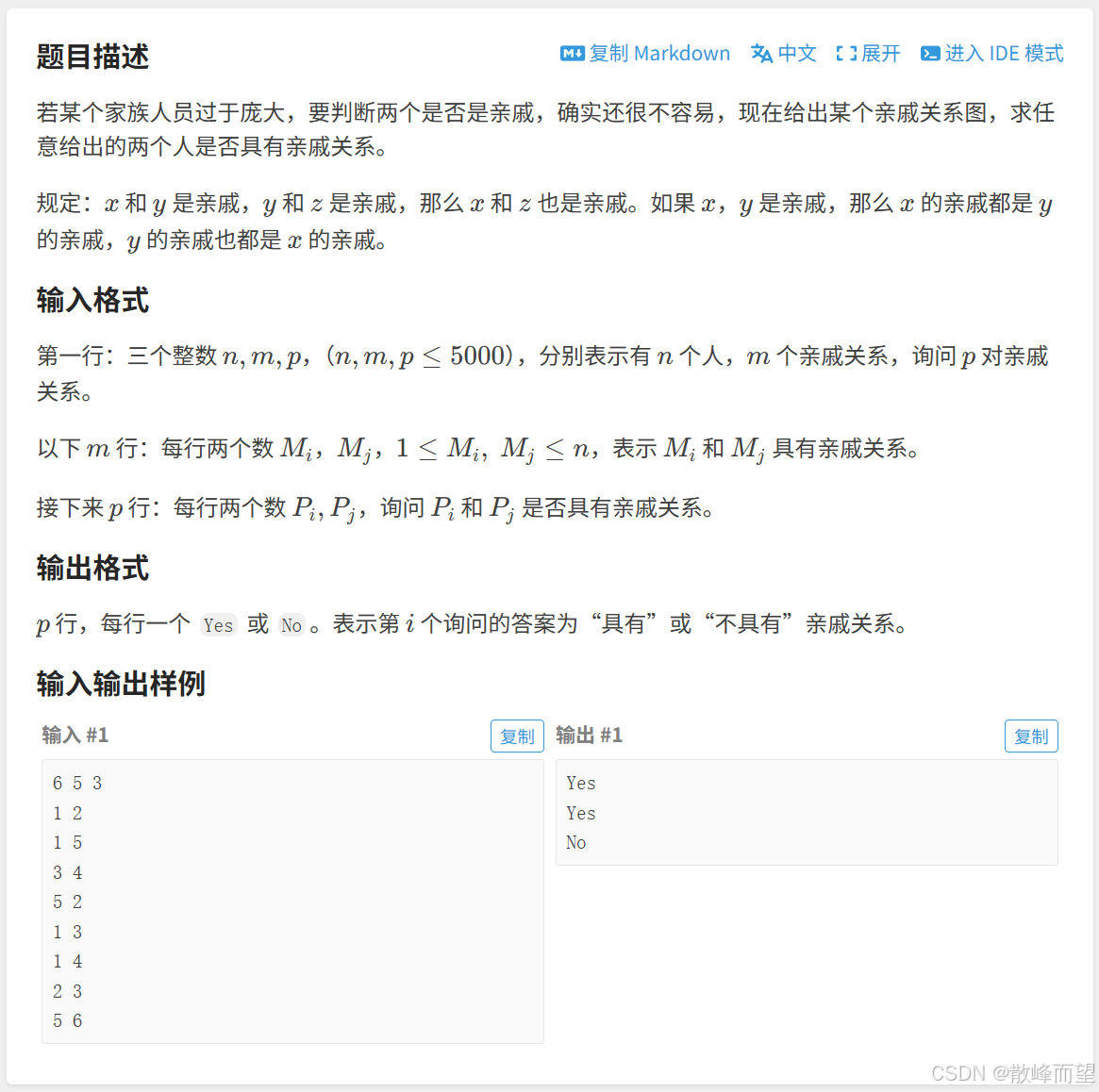
算法原理:
具有亲戚关系的两个集合就合并在一个集合中。因此,可以用并查集解决。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 5010;
int n, m, p;
int fa[N];
int find(int x)
{
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
void un(int x, int y)
{
int fx = find(x), fy = find(y);
fa[fx] = fy;
}
bool issame(int x, int y)
{
return find(x) == find(y);
}
int main()
{
cin >> n >> m >> p;
//初始化
for(int i = 1; i <= n; i++) fa[i] = i;
while(m--)
{
int x, y; cin >> x >> y;
un(x, y);
}
while(p--)
{
int x, y; cin >> x >> y;
if(issame(x, y)) cout << "Yes\n";
else cout << "No\n";
}
return 0;
}1.7 Lake Counting S
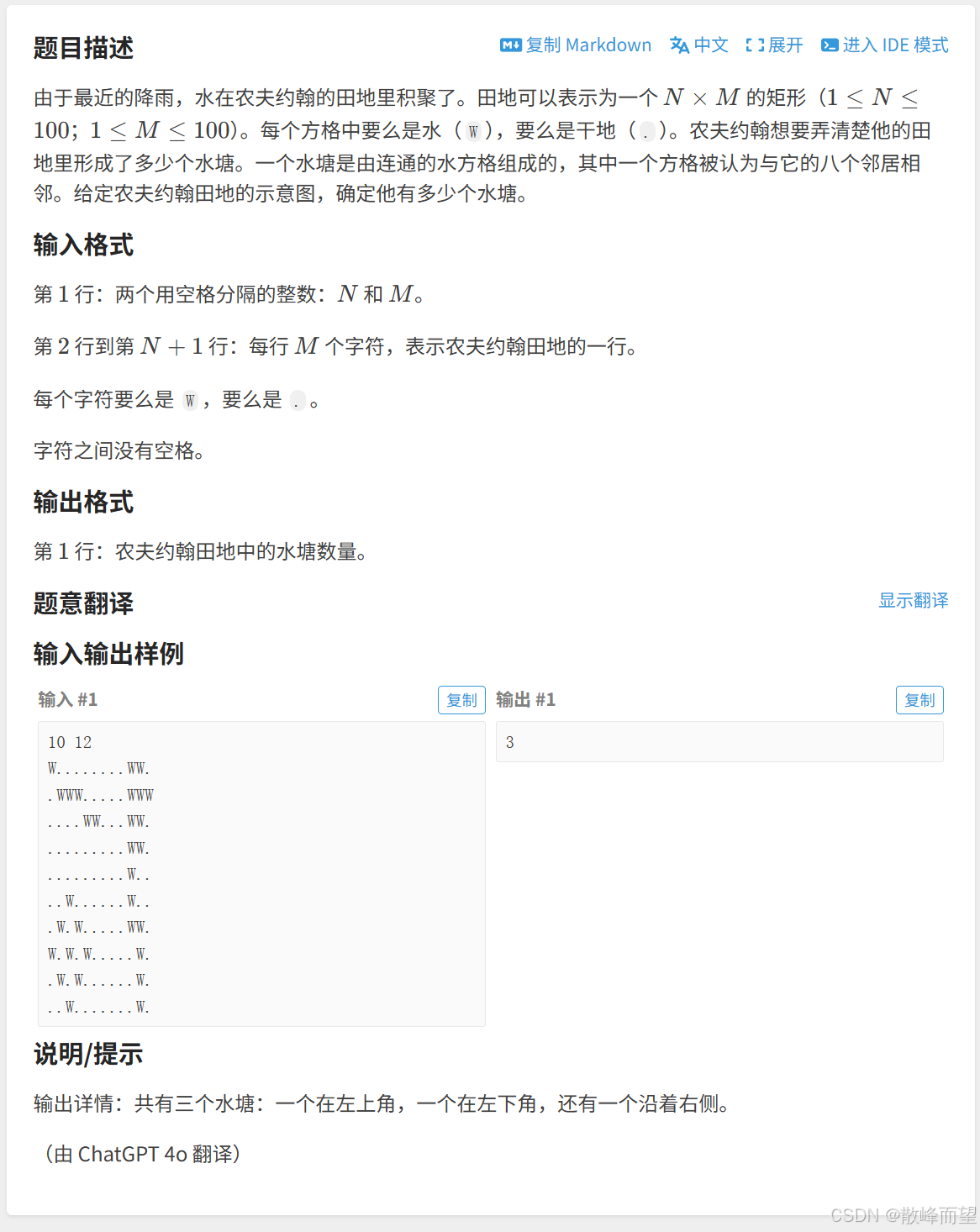
算法原理:
我们可以将上下左右,左上左下,右上右下放在一个集合中,但是我们该怎么将其放在一个集合中呢,以及如何统计结果呢?
- 怎么把相邻的
w合并在同一个集合中
因为并查集没法用二维数组,因此我们可以将二维 数组转换成一维 ,具体可见【基础算法】BFS 广度优先搜索全攻略:基础、多源、01 BFS,一网打尽 "八数码难题"。
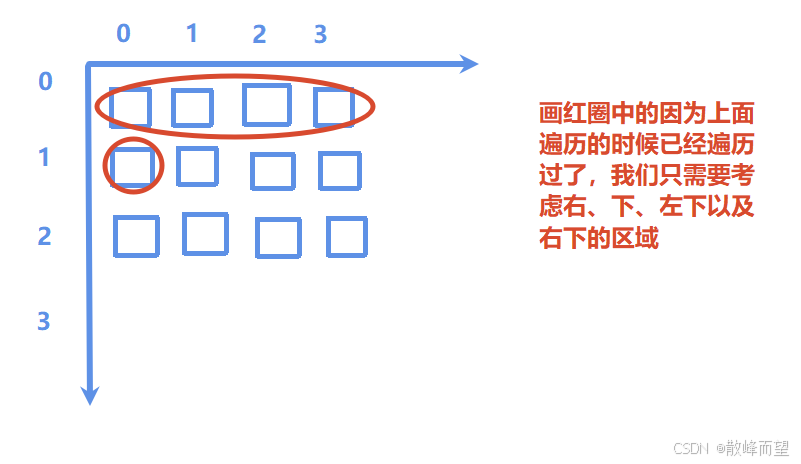
- 如何统计结果
遍历并查集找一共有多少 fa[i] == i
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 110;
int n, m;
char a[N][N];
int fa[N * N];
int dx[] = {0, 1, 1, 1};
int dy[] = {1, 1, 0, -1};
int find(int x)
{
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
void un(int x, int y)
{
fa[find(x)] = find(y);
}
int main()
{
cin >> n >> m;
for(int i = 0; i < n; i++)
for(int j = 0; j < m; j++)
cin >> a[i][j];
//初始化
for(int i = 0; i < n * m; i++) fa[i] = i;
for(int i = 0; i < n; i++)
{
for(int j = 0; j < m; j++)
{
if(a[i][j] == '.') continue;
for(int k = 0; k < 4; k++)
{
int x = i + dx[k], y = j + dy[k];
if(y >= 0 && a[x][y] == 'W')//防止越界访问
{
un(i * m + j, x * m + y);
}
}
}
}
int ret = 0;
for(int i = 0; i < n * m; i++)
{
//一维转二维
int x = i / m, y = i % m;
if(a[x][y] == 'W' && fa[i] == i) ret++;
}
cout << ret << endl;
return 0;
}
if(a[x][y] == 'W' && fa[i] == i) ret++;可以改成这样写if(a[x][y] == 'W' && find(i) == i) ret++;
2. 扩展域并查集
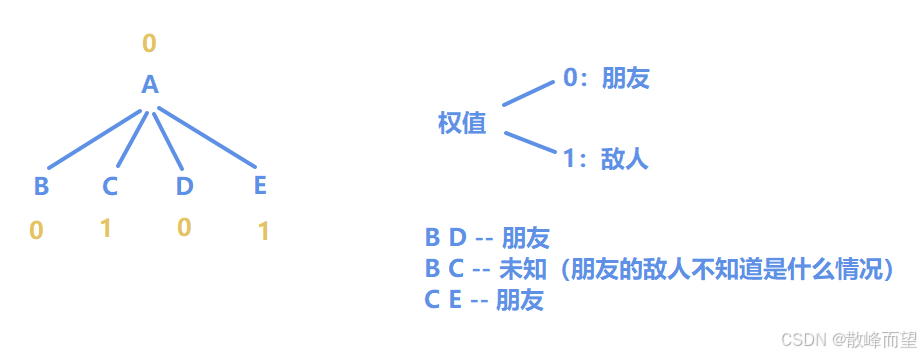
标准并查集仅能处理元素间单一关系的情况,例如《亲戚》题目中:
- 若 a 与 b 是亲戚,b 与 c 是亲戚,则可推断 a 与 c 也是亲戚。
但当元素间存在多种关系时,普通并查集就难以应对。例如:
- 若 a 与 b 是敌人,b 与 c 是敌人,此时 a 与 c 实际上并非敌人而是朋友关系。
这种情况涉及多种关系的复杂交互。为此,我们需要扩展并查集结构:将每个元素拆分为多个域,每个域代表不同状态或关系,通过维护域间关系来处理复杂约束。
以敌友问题为例,我们将 x 拆分为两个域:朋友域 x 和敌人域 y:
- 当 x 与 y 是朋友时,直接合并两个集合;
- 当x与y是敌人时:
- 合并 x 与 y 的敌人域 y+n(即 x 与 y+n 为朋友)
- 合并 y 与 x 的敌人域 x+n(即 y 与 x+n 为朋友)
通过这种双域结构,我们就能有效维护所有复杂关系。
2.1 团伙

扩展域并查集模板题:
-
a 和 b 如果是朋友,那就直接合并在一起;
-
a 和 b 如果是敌人,那就把 a 和 b+n 以及 a+n 和 b 合并在一起。
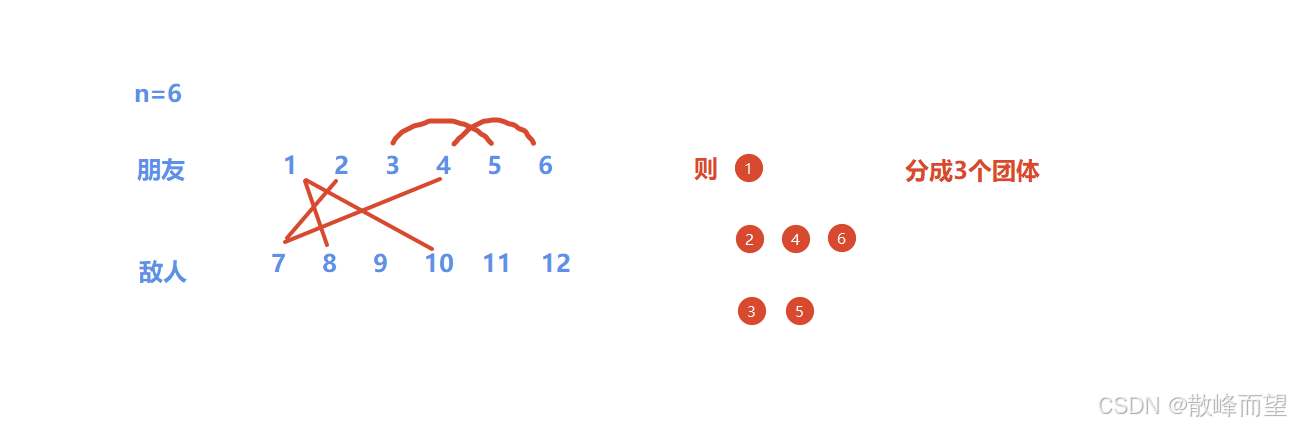
不过有几个点需要注意一下:
- 题目没有告诉我们:朋友的敌人是敌人;
- 如何统计一共有多少个集合:符合
fa[i] == i有多少个; - 父节点只能在朋友域不能在敌人域,因为不统计敌人域。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 1010;
int n, m;
int fa[N * 2];
int find(int x)
{
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
//朋友域做父节点
void un(int x, int y)
{
fa[find(y)] = find(x);
}
int main()
{
cin >> n >> m;
//初始化
for(int i = 1; i <= n * 2; i++) fa[i] = i;
while(m--)
{
char op;
int x, y;
cin >> op >> x >> y;
if(op == 'F')
{
un(x, y);
}
else
{
un(x, y + n);
un(y, x + n);
}
}
int ret = 0;
for(int i = 1; i <= n; i++)
{
if(fa[i] == i) ret++;
}
cout << ret << endl;
return 0;
}2.2 食物链

算法原理:
针对 x,扩展三个域:同类域 x,捕食域 x + n,被捕食域 x + n + n 。
如果 x 和 y 是同类:
-
x 和 y 是同类
-
x + n 与 y + n 是同类
-
x + n + n 与 y + n + n 是同类
如果 x 捕食 y :
-
x + n 与 y 同类
-
x 与 y + n + n 同类
-
x + n + n 与 y + n 同类
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 5e4 + 10;
int n, k;
int fa[N * 3];
int find(int x)
{
return fa[x] == x ? x : fa[x] = find(fa[x]);
}
void un(int x, int y)
{
fa[find(x)] = find(y);
}
int main()
{
cin >> n >> k;
for(int i = 1; i <= n * 3; i++) fa[i] = i;
int ret = 0;
while(k--)
{
int op, x, y; cin >> op >> x >> y;
if(x > n || y > n) ret++;
else if(op == 1)//同类
{
if(find(x) == find(y + n) || find(x) == find(y + n + n)) ret++;
else
{
un(x, y);
un(x + n, y + n);
un(x + n + n, y + n + n);
}
}
else//x吃y
{
if(find(x) == find(y) || find(x) == find(y + n)) ret++;
else
{
un(x, y + n + n);
un(x + n, y);
un(x + n + n, y + n);
}
}
}
cout << ret << endl;
return 0;
} 3. 带权并查集
-
带权并查集的概念
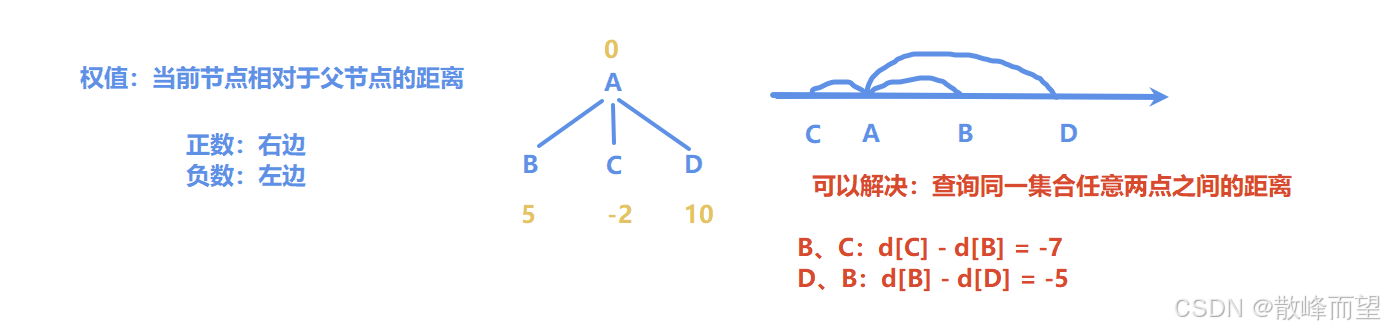
带权并查集在普通并查集的基础上,为每个结点增加了一个权值。这个权值可以表示当前结点与父结点之间的关系、距离或其他信息(注意,由于我们有路径压缩操作,所以最终这个权值表示的是当前结点相对于根结点的信息)。有了这样一个权值,就可以推断出集合中各个元素之间的相互关系。
-
带权并查集的实现
我们以最简单的距离问题为例,实现一个能够查询任意两点之间距离的并查集。
实现带权并查集的核心是在进行 Find 和 Union 操作时,不仅要维护集合的结构,还要维护结点的权值。
注意:带权并查集的实现是多种多样的,基本上换一道题,实现的代码就要更改。因此一定要重点关注实现过程的思考方式,这才是通用的。
3.1 带权并查集的代码实现
- 初始化
init:
cpp
const int N = 1e5 + 10, INF = 0x3f3f3f3f;
int n;
int fa[N], d[N];//存储权值
void init()
{
for(int i = 1; i <= n; i++)
{
fa[i] = i;
d[i] = 0;//根据题目要求来
}
} - 查询根节点操作
find:
cpp
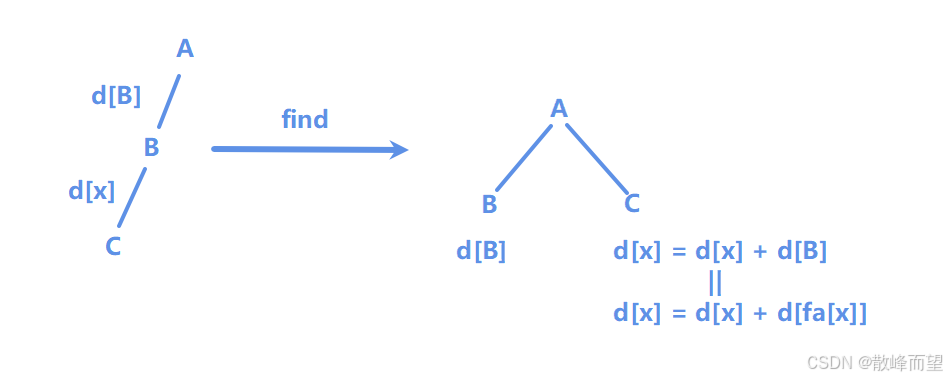
int find(int x)
{
if(fa[x] == x) return x;
int t = find(fa[x]);//这句代码一定要先执行,先让父结点挂在根节点的后面
d[x] += d[fa[x]];//注意,可能会根据权值的意义有所改变
return fa[x] = t;
}
- 合并操作
union:
cpp
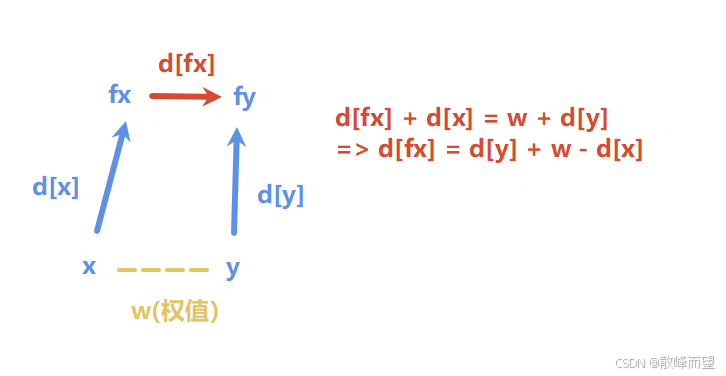
void un(int x, int y, int w)
{
int fx = find(x), fy = find(y);
if(fx != fy)//不在一个集合
{
fa[fx] = fy;
d[fx] = d[y] + w - d[x];//注意可能会根据权值的意义有所改变
}
}
- 查询距离操作
query:
cpp
int query(int x, int y)
{
int fx = find(x), fy = find(y);
if(fx != fy) return INF;//如果不在同一个集合中,说明距离未知
return d[y] - d[x];
}3.2 食物链

算法原理:
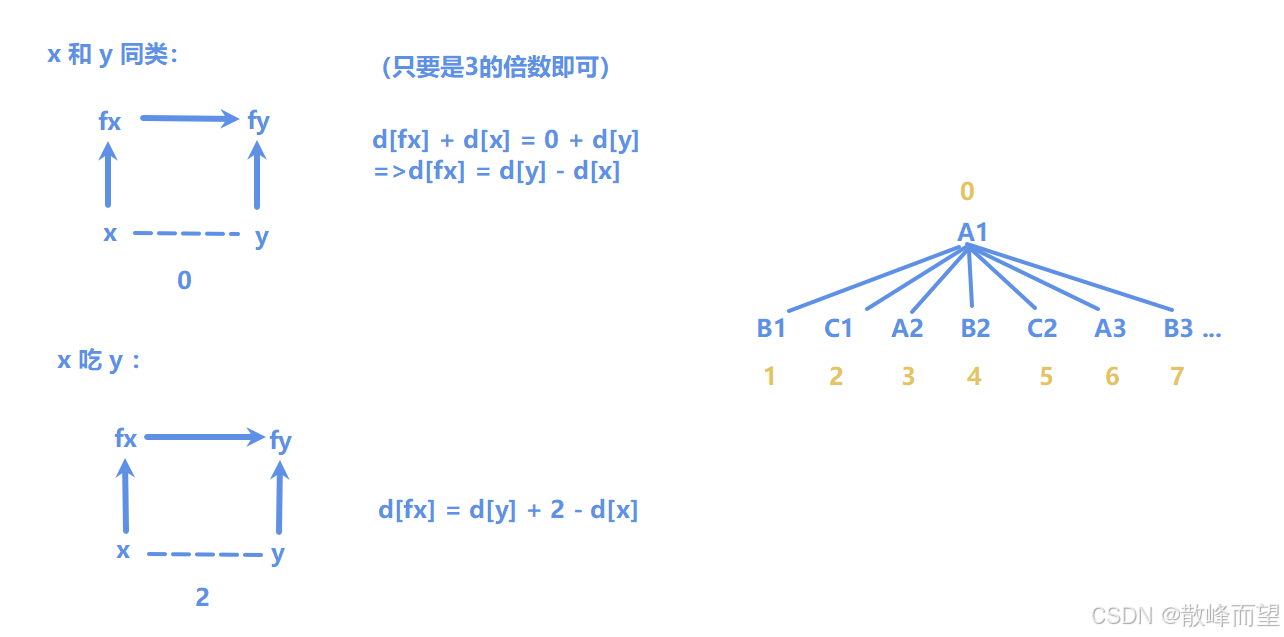
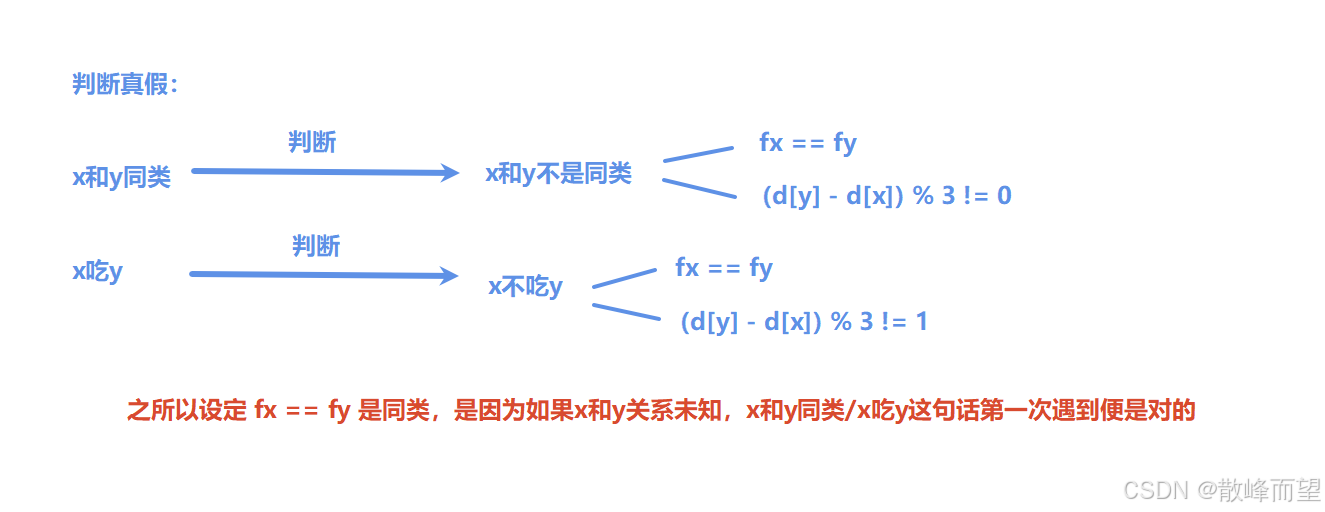
把真话里面的相互关系,用"带权并查集"维护起来,权值表示当前节点相对于根节点的距离。那么对于集合中的任意两点 x 和 y :
- 如果(dy - dx)% 3 == 0,表示两者是同类关系;
- 如果(dy - dx)% 3 == 1,表示两者是捕食关系;
- 如果(dy - dx)% 3 == 2,表示两者是天敌关系。
find 操作:
- 更新 d 数组:按照最基础的距离更新的方式,dx = dx + dfa\[x] 。
union 操作:
- 如果 x 和 y 是同类,那么边权就是 0 ;
- 如果 x 吃 y ,那么边权就是 1 。
细节问题:负数取模需要 模 + 模 补正:
(d[y] - d[x]) % 3 + 3) % 3
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 5e4 + 10;
int n, k;
int fa[N], d[N];
int find(int x)
{
if(fa[x] == x) return x;
int t = find(fa[x]);
d[x] += d[fa[x]];
return fa[x] = t;
}
void un(int x, int y, int w)
{
int fx = find(x), fy = find(y);
if(fx != fy)
{
fa[fx] = fy;
d[fx] = d[y] + w - d[x];
}
}
int main()
{
cin >> n >> k;
for(int i = 1; i <= n; i++) fa[i] = i;
int ret = 0;
while(k--)
{
int op, x, y; cin >> op >> x >> y;
int fx = find(x), fy = find(y);
if(x > n || y > n) ret++;
else if(op == 1)//同类
{
if(fx == fy && ((d[y] - d[x]) % 3 + 3) % 3 != 0) ret++;
else un(x, y, 0);
}
else//x吃y
{
if(fx == fy && ((d[y] - d[x]) % 3 + 3) % 3 != 1) ret++;
else un(x, y, 2);
}
}
cout << ret << endl;
return 0;
}3.3 银河英雄传说

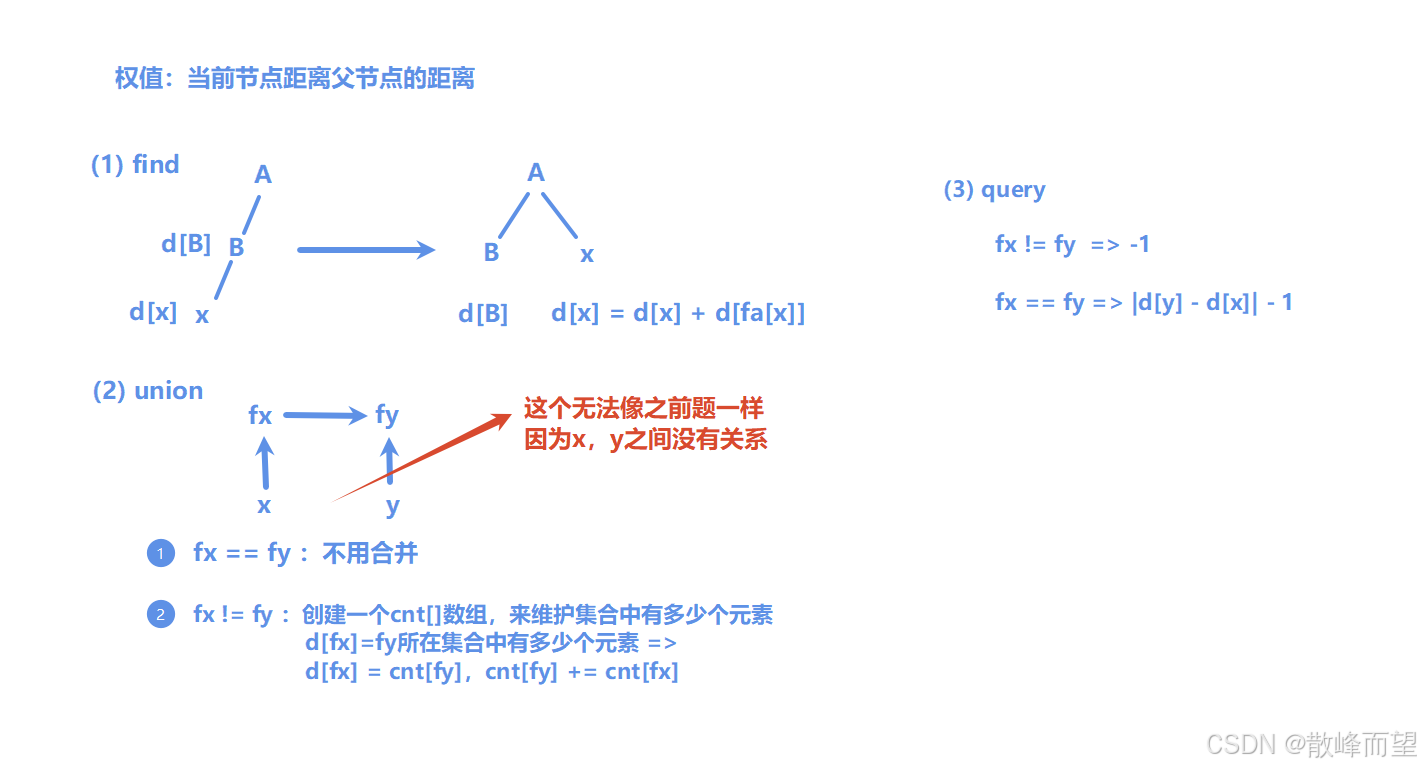
算法原理:
这道题中有明显的边权关系,因此可以用"带权并查集"解决。
参考代码:
cpp
#include <iostream>
using namespace std;
const int N = 3e4 + 10;
int n = 3e4;
int fa[N], d[N], cnt[N];//维护集合的合并、维护权值、维护集合的大小
int find(int x)
{
if(fa[x] == x) return x;
int t = find(fa[x]);
d[x] += d[fa[x]];
return fa[x] = t;
}
void un(int x, int y)
{
int fx = find(x), fy = find(y);
if(fx != fy)
{
fa[fx] = fy;
d[fx] = cnt[fy];
cnt[fy] += cnt[fx];
}
}
int query(int x, int y)
{
int fx = find(x), fy = find(y);
if(fx != fy) return -1;
else return abs(d[y] - d[x]) - 1;
}
int main()
{
//初始化
for(int i = 1; i <= n; i++)
{
fa[i] = i;
cnt[i] = 1;
}
int T; cin >> T;
while(T--)
{
char op; int x, y;
cin >> op >> x >> y;
if(op == 'M')//合并
un(x, y);
else
cout << query(x, y) << endl;
}
return 0;
}结语
结语
并查集作为一种高效处理不相交集合合并与查询的数据结构,在算法竞赛和实际问题中应用广泛。从基础的路径压缩与按秩合并优化,到扩展域解决复杂关系,再到带权并查集维护节点间动态权值,其灵活性和效率使其成为解决连通性、分类问题的利器。
通过经典问题如"亲戚关系""食物链"等实践,可以深入理解并查集的核心思想与变体。掌握其实现与优化技巧,能够显著提升对图论、动态连通性等问题的解决能力。
愿诸君能一起共渡重重浪,终见缛彩遥分地,繁光远缀天。
