动机
整合组学分析通过探究性状、组学测量值、遗传变异与流行病学因素之间的关联,有助于深入理解疾病机制及生物标志物。从统计学角度而言,这类分析面临诸多挑战------组学数据维度高、分布非标准,且可能存在复杂的非线性混杂效应,因此需要稳健、灵活的分析方法。
结果
本文提出ROMY框架及对应的R包(romy)。该工具可实现3大功能:
(a)在灵活调整协变量的同时,对2个目标变量进行稳健关联检验;
(b)分析变量对测量方差和协方差的影响(如共表达、共丰度);
(c)开展严格的交互效应检验。
ROMY基于统计学理论和双重机器学习的最新进展构建,确保分析的稳健性和统计有效性。通过模拟研究验证了该框架的性能。
romy是款基于GNU GPLv3许可证的R包,已在GitHub开源。
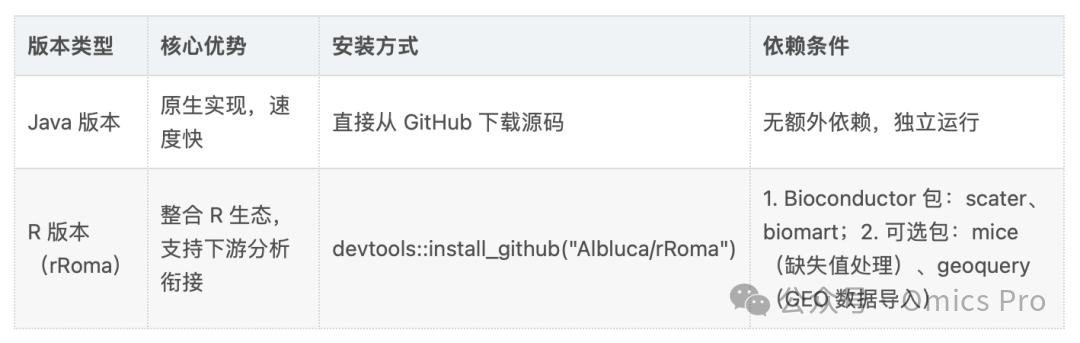
Java版本:https://github.com/sysbio-curie/roma
R版本(rRoma):https://github.com/Albluca/rRoma
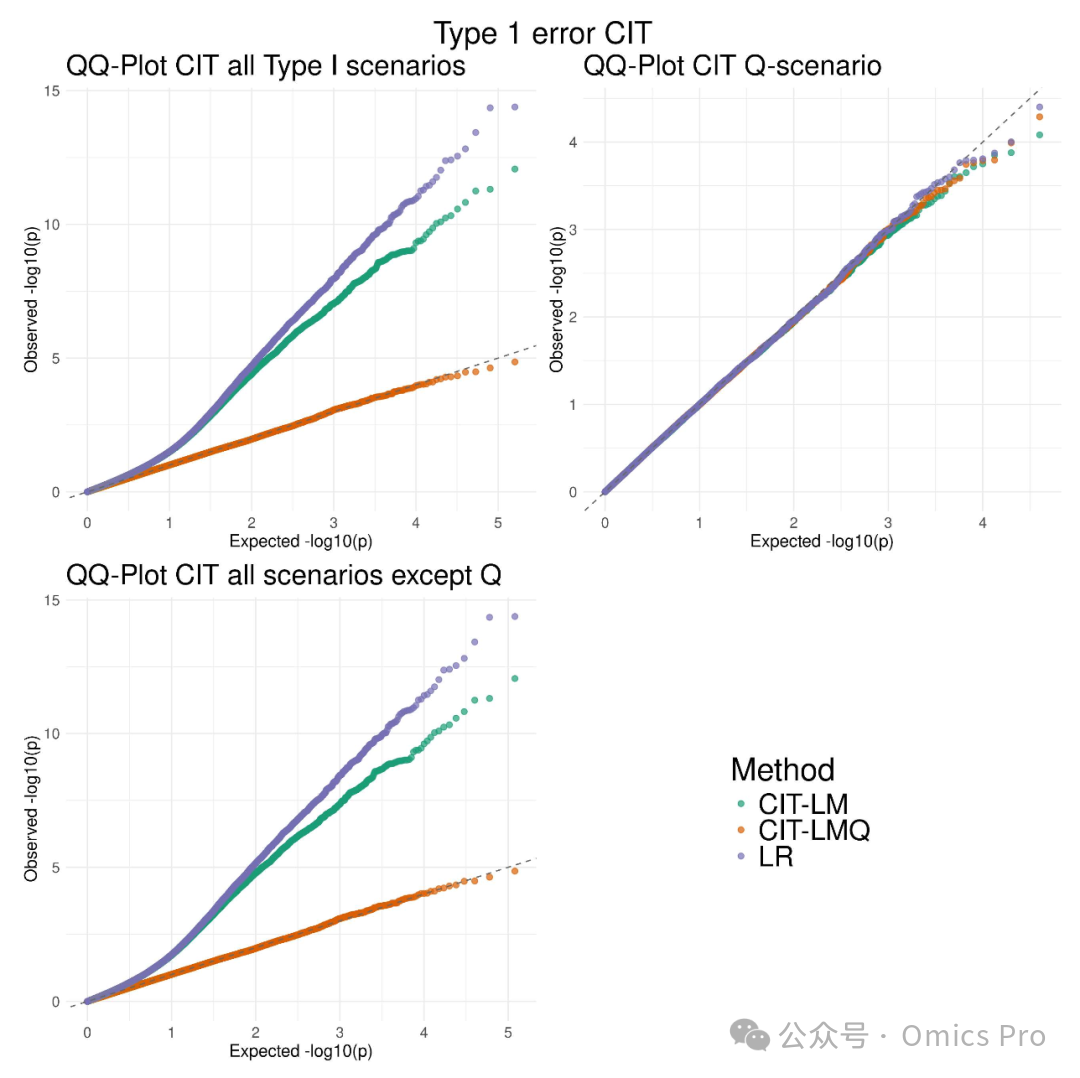
图1 ROMY-CIT的I类错误模拟,含与标准回归方法"LR"的对比
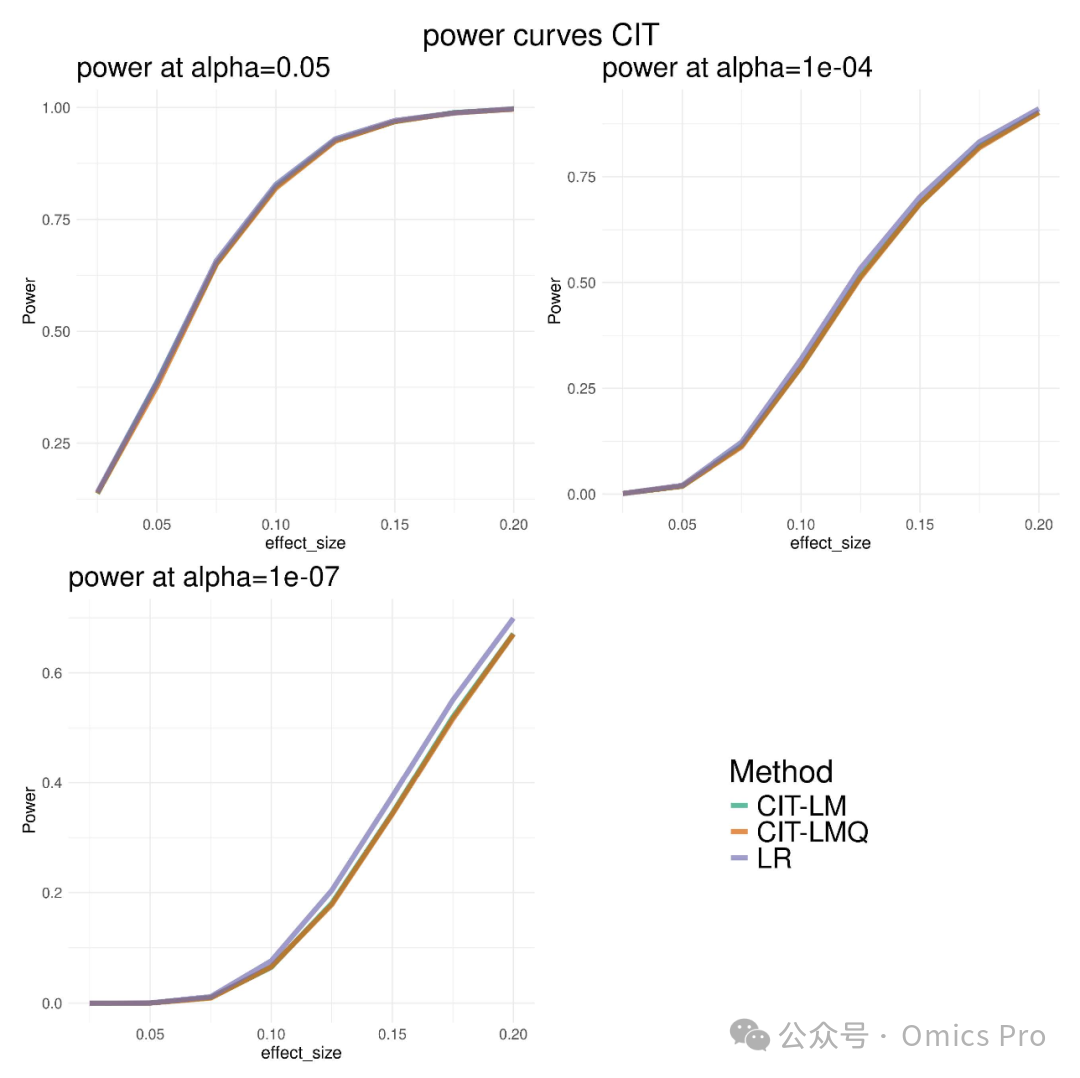
图2 ROMY-CIT的检验效能模拟,含与标准回归方法"LR"的对比
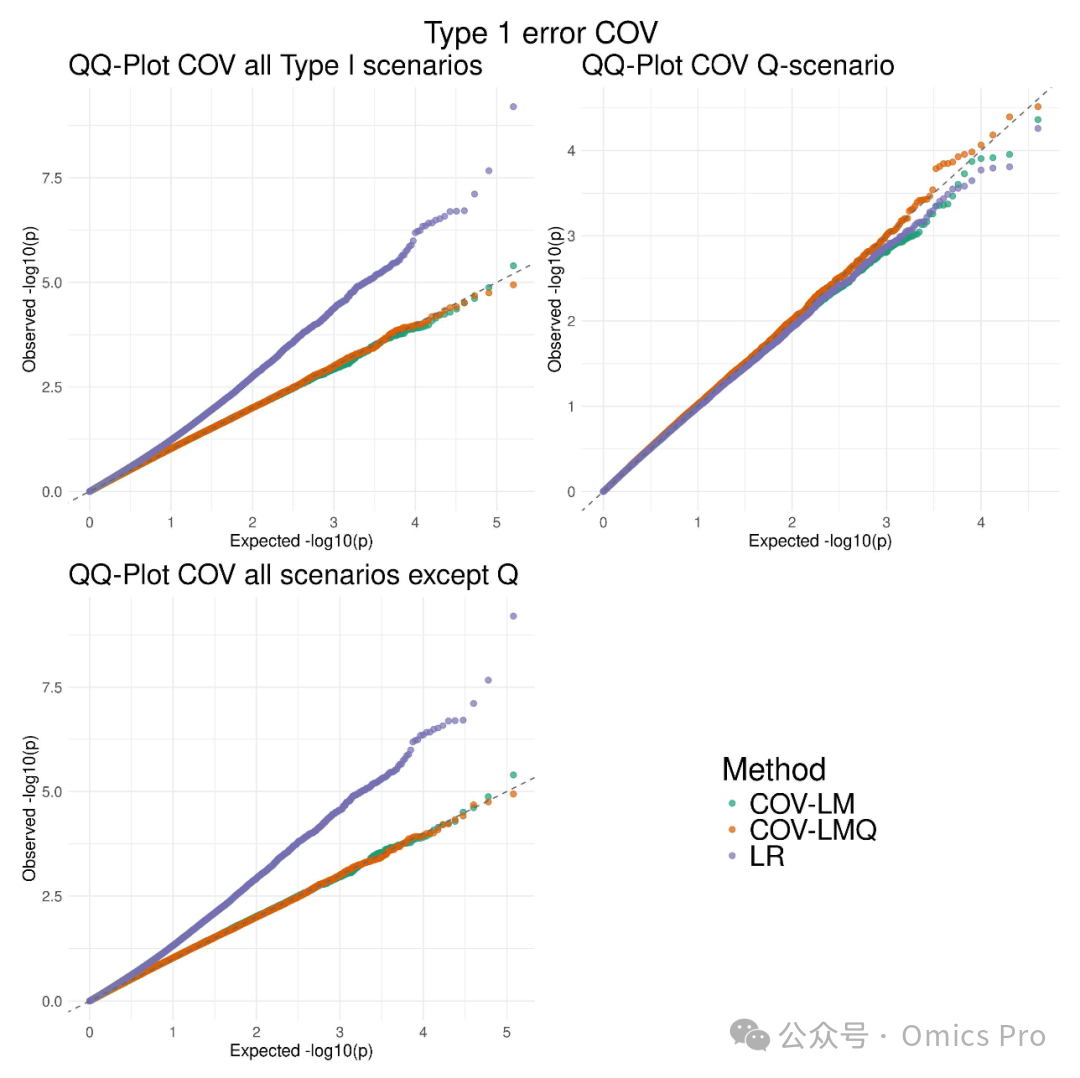
图3 ROMY-COV的I类错误模拟,含与标准回归方法"LR"的对比
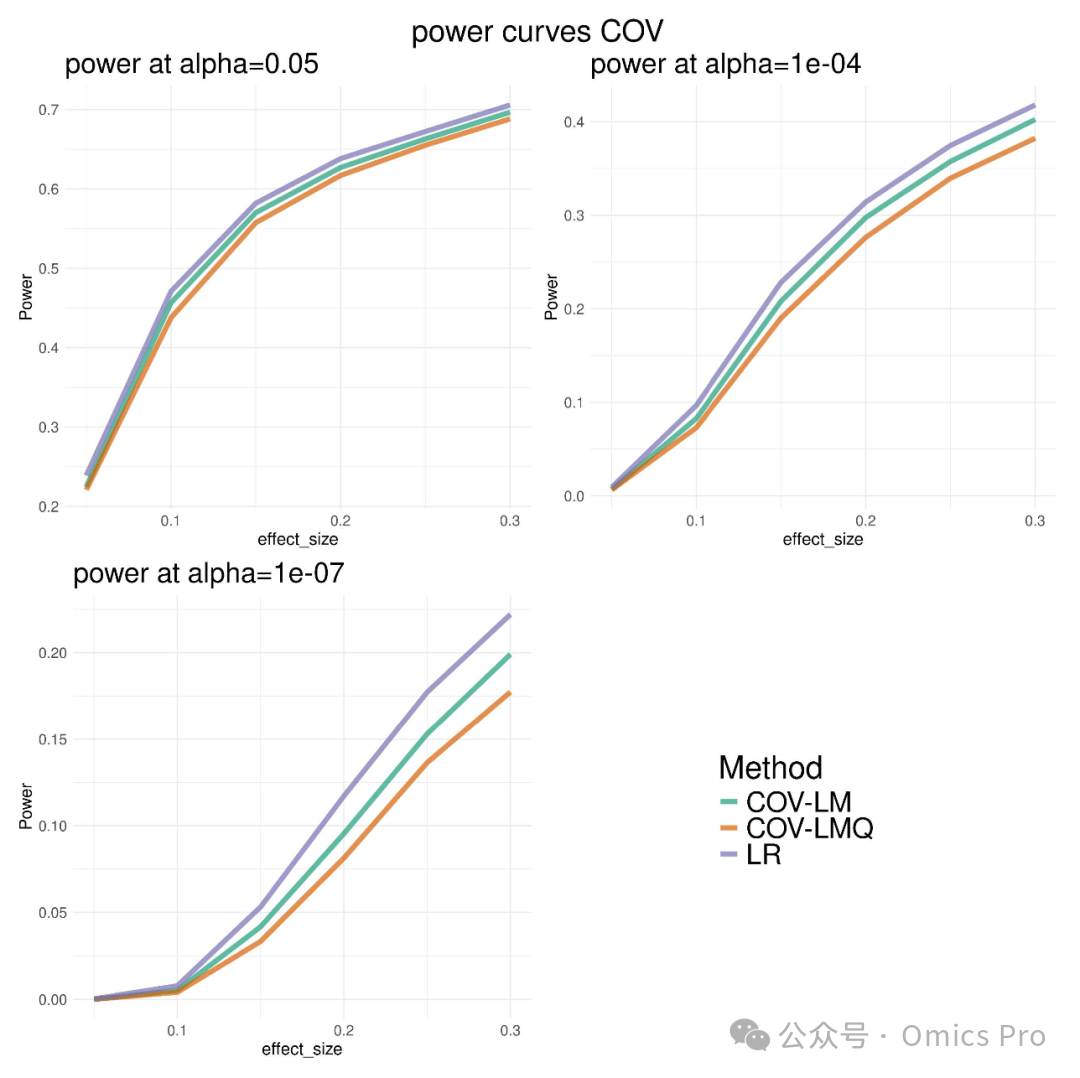
图4 ROMY-COV的检验效能模拟,含与标准回归方法"LR"的对比
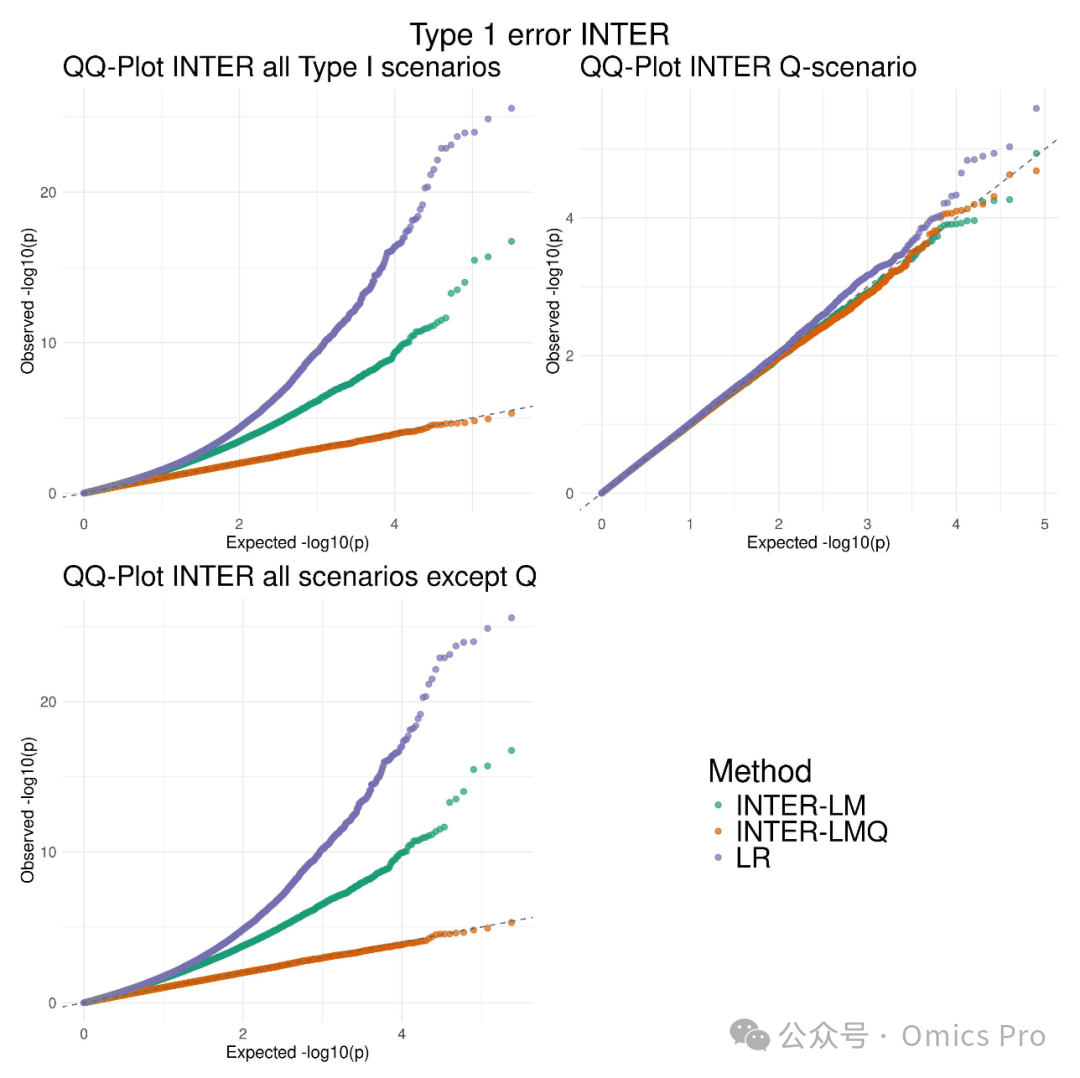
图5 ROMY-INTER的I类错误模拟,含与标准回归方法"LR"的对比
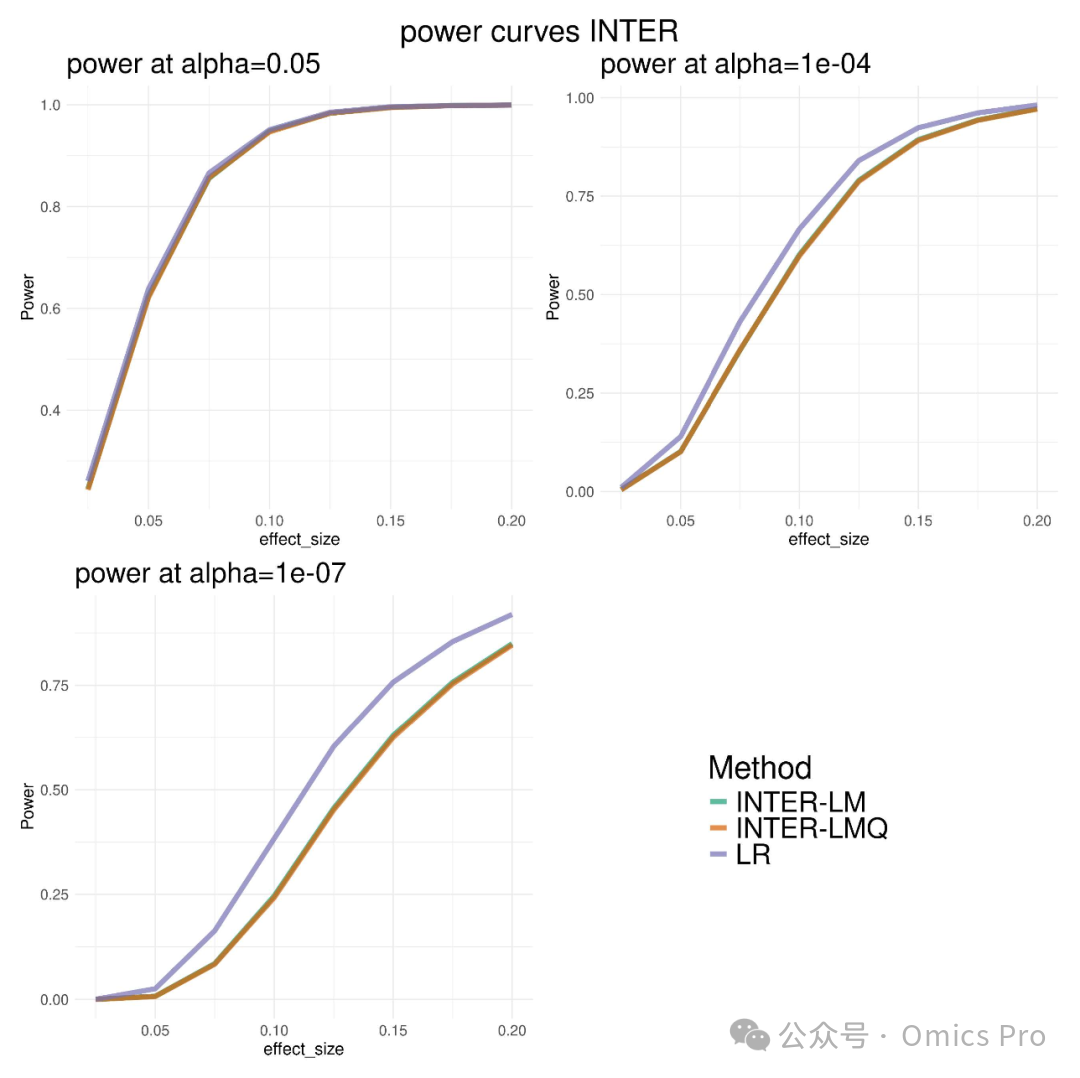
图6 ROMY-INTER的检验效能模拟,含与标准回归方法"LR"的对比
详细总结
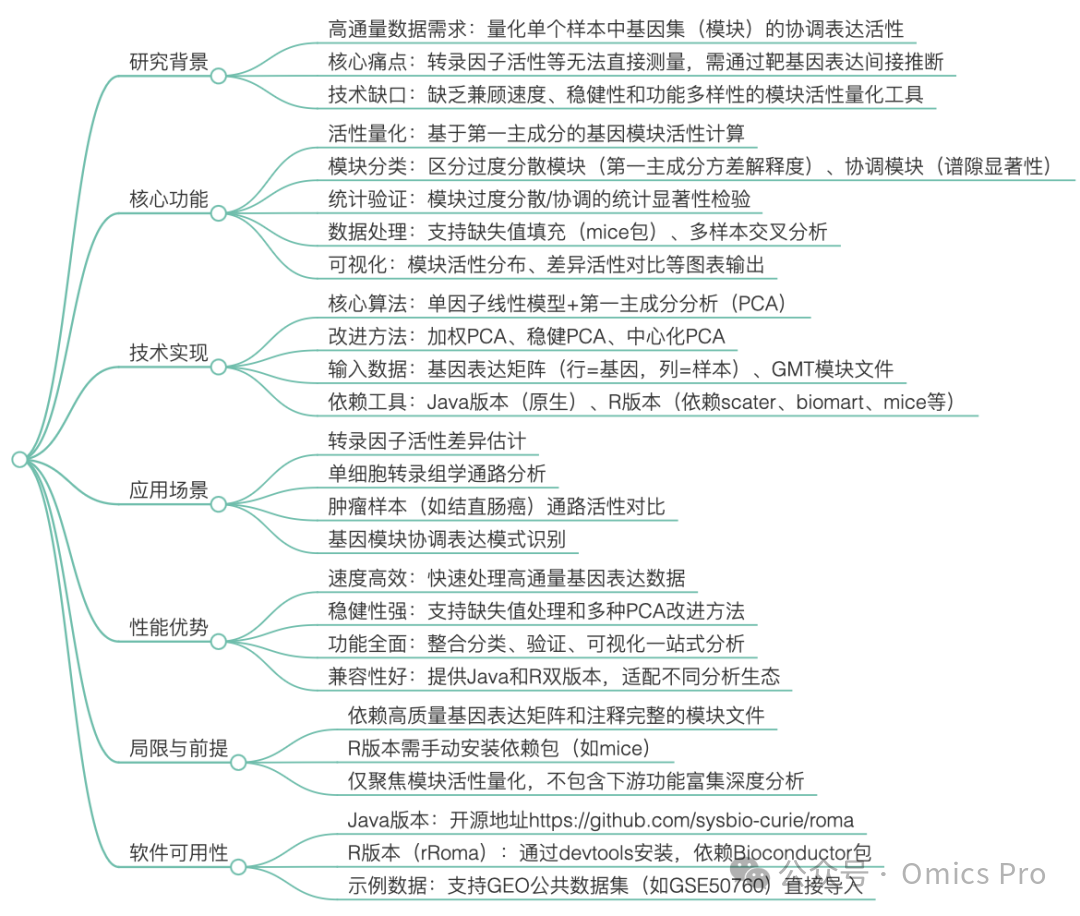
思维导图
核心功能与技术细节
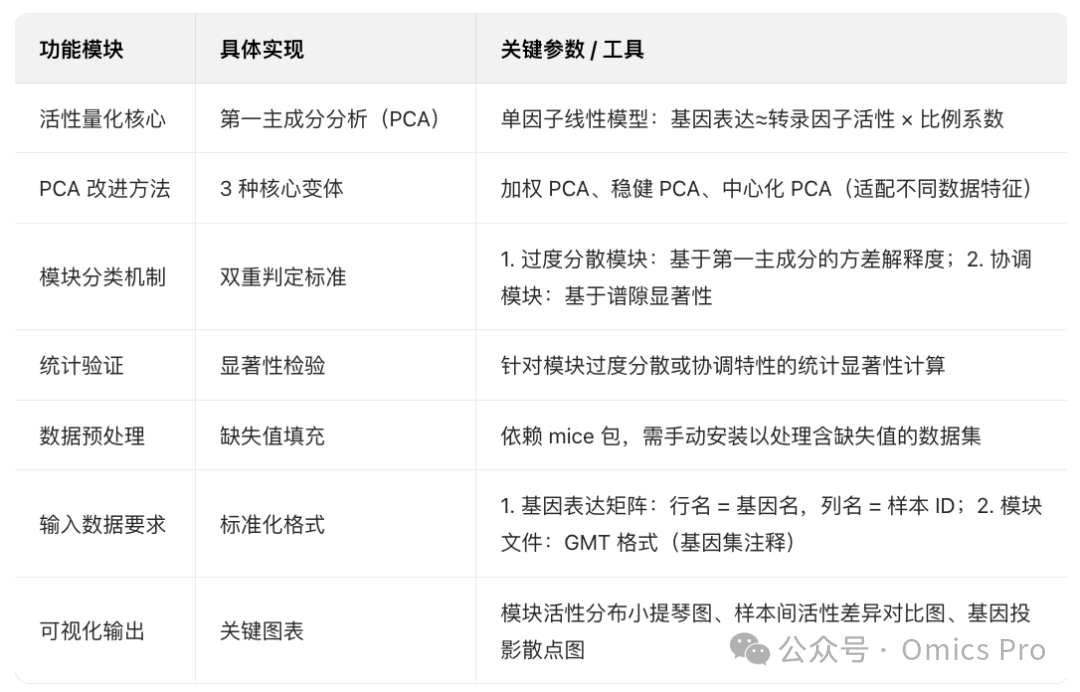
双版本特性对比
参考
bioRxivPreprint. 2025 Dec 8:2025.12.04.691622. doi: 10.64898/2025.12.04.691622. Analyzing associations and higher-order effects in multi-omics data with double machine learning
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。