
前言:
- Redis对于程序员来讲应该说是必学的内存数据库。
- 这篇是作者大二学习的时候做的笔记,有可能有错误,请各位批评指正。
- 提示:学习C++的时候最好腐朽java/go,否者学习redis很多场景没办法实践,我当时学redis的时候也是,看尚硅谷课程,前面还好,后面就是学不懂了。
- 参考:尚硅谷redis。
- 欢迎大家收藏 + 关注,作者将会持续更新。
文章目录
- Redis十大数据类型
- Redis持久化
- Redis事件
- Redis管道
- Redis发布订阅
- Redis复制
- Redis哨兵
-
- 哨兵的主要任务
- 哨兵模式的搭建
- 如果途中master挂了?
- 哨兵运行流程
-
- [主观下线(Subjectively Down)](#主观下线(Subjectively Down))
- [客观下线(Obejctively Down)](#客观下线(Obejctively Down))
- 哨兵选举(基于Raft算法)
- 故障转移
- 消息通知
- 使用建议
Redis十大数据类型
前言
-
Redis可以看作是一个SQL的秘书,基于内存的数据库
-
Redis是k-v键值对进行存储的,这里的数据类型指的是value的数据类型,key是字符串。
-
命令不区分大小写,但是key区分大小写
-
查看数据类型命令
help @+数据类型
-
常用命令:
| 命令 | 解释 |
|---|---|
| keys * | 当前库的所有key |
| exists key | 查看该key值是否存在 |
| type key | 查看key值是存储的是什么类型的数据 |
| del key | 删除指定的key数据 |
| unlink key | 非阻塞性删除,仅仅将key移除keyspqce,但是没用真正删除,后续依然可以异步操作 |
| ttl key | 查看key数据还有多少秒过期 |
| expire key 秒 | 给key设置过期时间 |
| move key dbsize(0-15) | j将当前key值移植到到指定数据库中(Redis默认16个数据库) |
| select dbesize(0-15) | 选择指定的数据库 |
| flushdb | 清空当前数据库 |
| flushall | 清空16个数据库(慎用) |
| type key | 获取key数据类型 |
字符串(String)
- string是redis最基本的类型
- string类型的二进制是安全的,可以存储任何数据,包括png图片
- string类型最大容量是512M
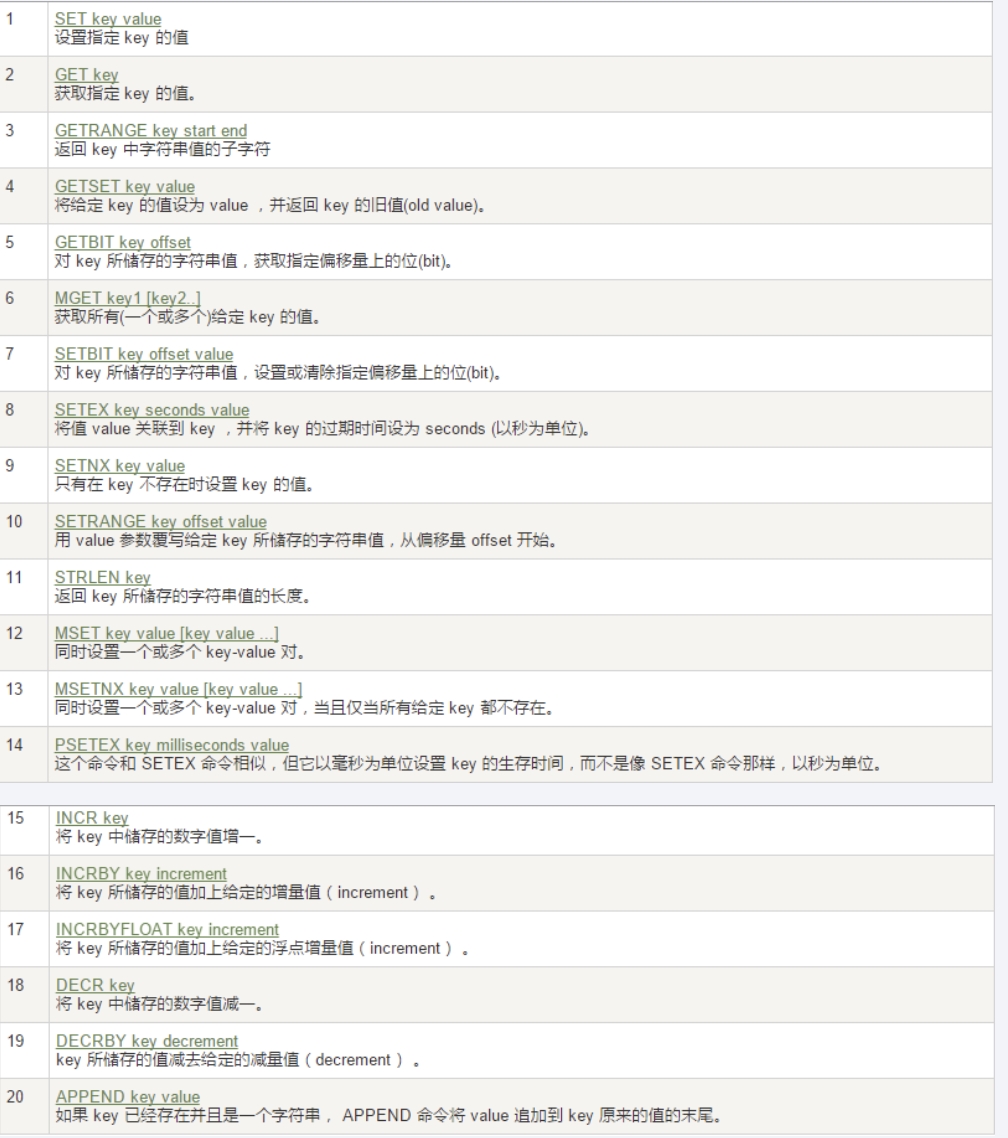
设置键值和得到键值(最常用)
redis
set key value
get keyset命令重要参数
- EX:设置过期秒数
- PX :设置过期毫秒数
- NX:键不存在时候设置键值
- XX:键存在时候设置键值
同时设置/获取多个键值
redis
MSET [key1] [value1] [key2] [value2] [key3] [value3] // 同时设置一个或多个键值对
MGET [key1] [key2] [key3] // 同时获取多个key的值
MSETNX [key1] [value1] [key2] [value2] // 同时设置一个或多个 key-value 对 注意:必须保证key都不存在才能成功获取指定区间
redis
GETRANGE [key] 0 -1 // 获取这个key的值的全部
GETRANGE [key] 0 2 // 获取这个key的值索引0到索引2之间的值(相当于字符串的截取)
SETRANGE [key] 1 xxx // 设置指定区间范围内的值(如这个:从1开始,替换xxx)数值增减
redis
INCR [key] // 递增数字 +1
INCRBY [key] [increment] // 直接增加到指定的整数 +increment
DECR [key] // 递减数字 -1
DECRBY [key] [increment] // 直接减少指定的整数 -increment 获取字符串长度和内容相加
redis
STRLEN [key] // 获取key对应的值的长度
APPEND [key] [vale] // 添加字符串内容分布式锁(后面详解)
redis
setnx/setex [key] [过期时间] [value] // 设置带过期时间的key,动态设置
setnx [key] [value] // 只有在 key 不存在时设置 key 的值。- 具体使用看高级篇分布式锁的使用
getset
先get后set
redis
getset [key] [value] - 注意: 执行顺序是先设置新值,后面再返回旧值
应用
- 点赞/收藏等
- 使用 incr key
列表(List)
- 数据结构:双向链表(如C++中的list),在两端添加、删除数据效率高
- 使用情况:
- 如果键不存在,则创建新的链表
- 如果键已存在,则增加内容
- 如果键移除,则与键关联的数据也会被清除
- 常用命令:

添加数据
redis
lpush [key] [value] ... // 往 列表头部(左边)放入元素
Rpush [key] [value] ... // 往 列表(右边)放入元素遍历链表
redis
lrange [key] 0 -1 // 从左开始遍历弹出数据
redis
lpop [key] // 最左边的出栈
rpop [key] // 最右边的出栈 索引获取值
redis
llen [key] // 获得元素个数通过元素值插入数据
redis
linsert [key] before/after [value1] [value2] 注意:不是通过索引插入数据
截取值
redis
ltrim [key] [开始] [结束] //截取指定范围的值后再赋给[key](即删除这个区间外的值)删除
redis
lrem [key] [num] [value] // 从左往右删除 num个值为 value的值
lrem [key] 0 [value] // 从左往右删除所有值为value的值注意:如果要删除的数量大于列表拥有值的数量,则失效返回为0
其他
redis
//将key的第index个索引值改为value
lset [key] [index] [value]
//获取元素的个数
llen [key] 应用场景
- 公众号订阅消息
- 关注的人发布文章,就会在我的List中添加发布者文章的id
- 查看自己订阅的文章(存储订阅文章的id)
哈希(Hash)
- hash数据的结构:key--value
- 作用:快速查阅值,适合存储经常需要查阅的数据
- key1-value(key2-value),注意 :一个key1可以对应多个key2,用hgetall获取
- 常用命令:

设置和得到值
redis
hset //设置hash值
hget //得到hash值
hmset //设置多个hash值
hmget //得到多个哈希值
hgetall //得到改hash键的** 所有 ** 值,键和值都输出得到键值和数据值
redis
hkeys //得到键值
hvals //得到数据值自动增加
redis
hincrby // key里面k1的值增长num 整数
hincrbyfloat // key里面k1的值增长num 小数其他
redis
hlen // 获取在某个key内的全部数量
hexists // 查看key值是否存在 k1 键值应用场景
- 早期购物车设置
集合(Set)
- 可以存储多个set,底层是整数集合,C++是红黑树
- 注意:存储无重复值
- 常用:
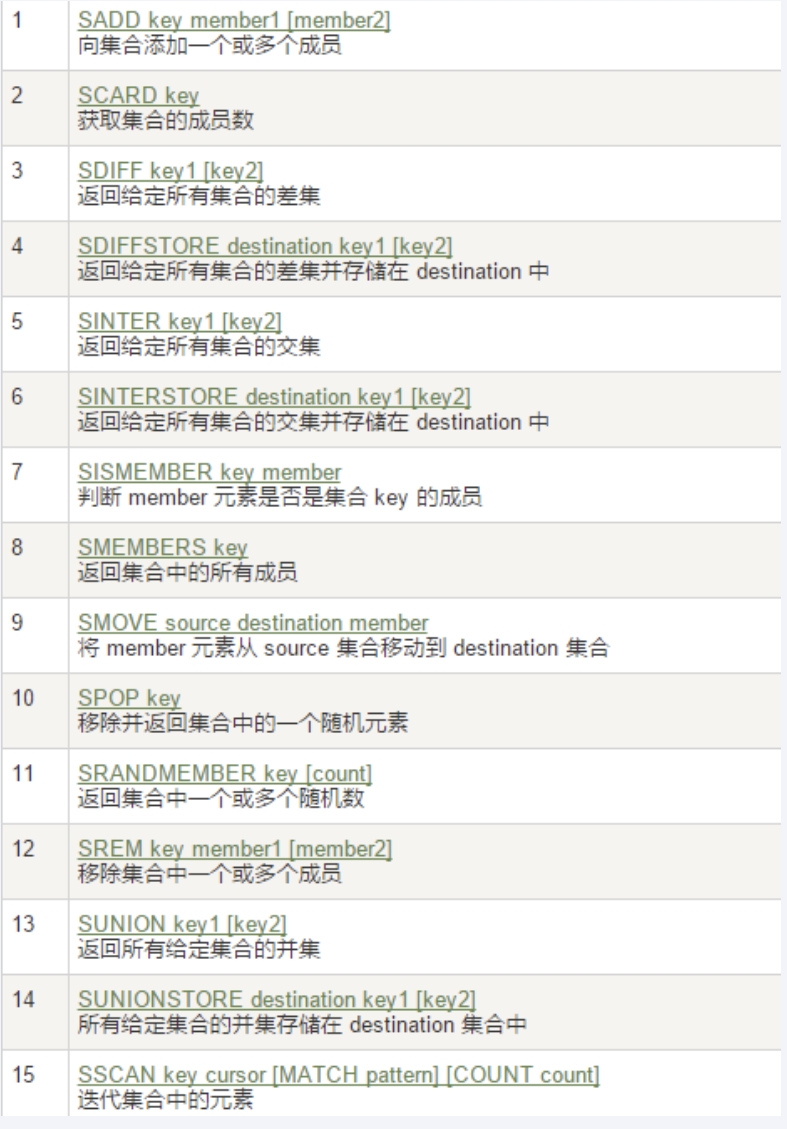
添加元素
redis
sadd key member...遍历元素
redis
smembers key获取集合长度
redis
scard key取元素
redis
// 随机取m个元素
srandmember key m
// 将key1存在的某个元素赋值给key2
smove key1 key2删除
redis
srem key member判断元素是否存在集合中
redis
sismember key member集合运算
redis
SDIFF keyA keyB // A - B 属于A但不属于B的元素构成的集合
SUNION keyA keyB // A U B 属于A或者属于B的元素合并后的
SINTER keyA keyB // A ∩ B 属于A同时属于B
SINTERCARD numkeys keyA keyB [LIMIT limit] // 不返回结果集,只返回结果的基数应用
- 抽象小程序
- 将所有抽奖用户添加(sadd key)用户ID
- 显示多少人参( SCARD key)
- 从set中任意选取N个人中奖
- 如:SRANDMENBER KEY 2 随机选取两人中间
- 如:SPOP key 2 随机选取两个人,元素会删除
- 朋友圈点赞
- 新增点赞 SADD
- 取消点赞 SREM
- 展现所有点赞过的用户 SMENBERS
- 点赞用户统计 ACAED
- 判断某个朋友是否对某个up点过赞 SISMEMBER
- 可能认识的人
- 求两人的差集 ADIFF user1 user2
有序集合(Zset)
- 别名:sorted set
- 底层:跳表和压缩列表
- Zset和set区别:在set基础上,每个val值添加了一个score,很适合做排行榜
- 常用的
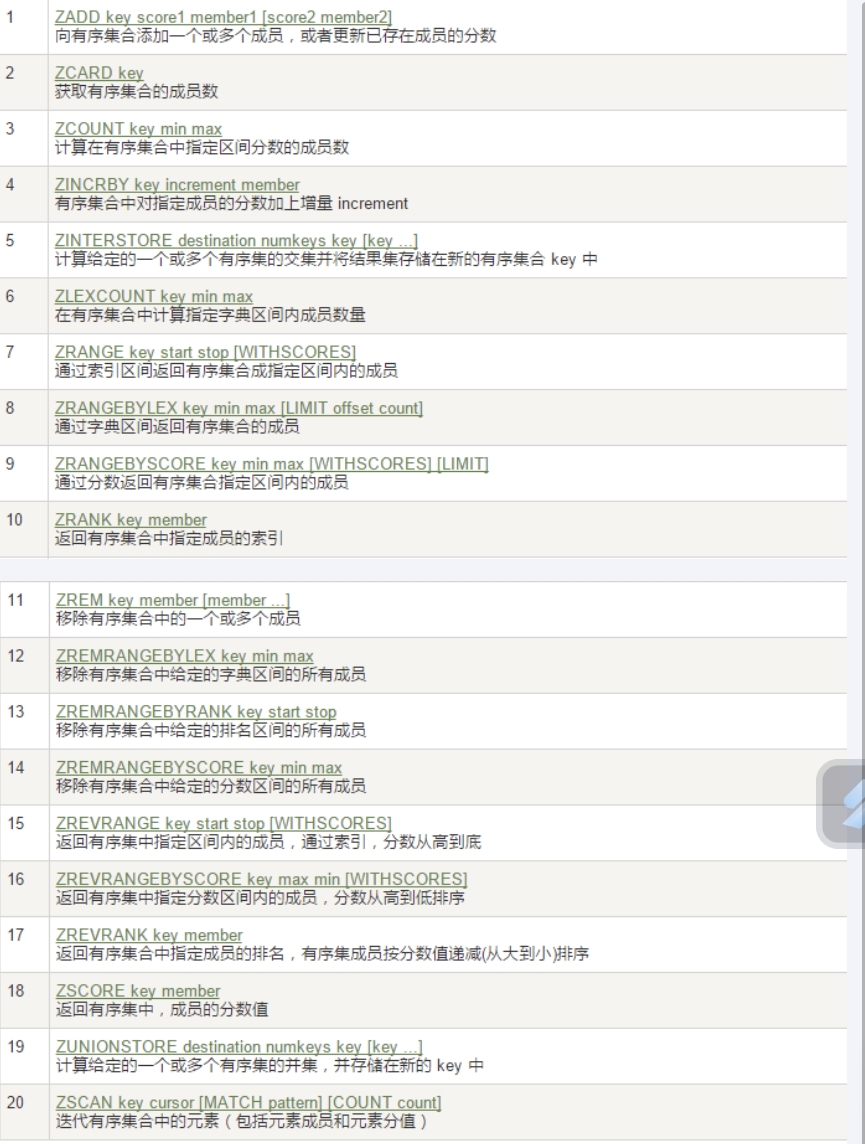
添加元素
redis
// 添加元素
ZADD key score member
// 增加某个元素的分数
ZINCRBY key increment member查询元素
redis
// 按照元素的分数从小到大
ZRANGE key start stop
// 反序
ZREVARNGE key 0 -1 反序
// 获取指定分数范围内的元素个数
ZCOUNT key min max
// 获取下标值,集合有多个
ZRANK key values
// 逆序获得下标值
ZREVARNK key values
// 获取元素分数
ZSCORE key member
// 查询元素的数量
ZCARD key删除元素
redis
// 删除元素
ZREM key score对应的values值
// 弹出元素
ZMPOP numkeys key [key ...] <MIN | MAX> [COUNT count]
例子:(弹出最小分值的数据)
127.0.0.1:6379> zmpop 1 zset1 min count 1
1) "zset1"
2) 1) 1) "v2"
2) "70"其他
redis
// 获取指定分数范围的元素(min,max) 不包含 limit是返回限制,返回多少个
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] 应用
- 根据商品销售对商品进行排序显示
- 思路:定义商品销售排行版(sorted set集合), key为goods:sellsort,分数为商品销售数量
- 商品编号1001的销量是9,商品编号的1002的销量是15
- zadd goods:sellsort 9 1001 15 1002
- 有一个客户又买了2件商品1001,商品编号1001销量加2
- zincrby goods:sellsort 2 1001
- 求商品销量前10名
- zrange goods:sellsort 0 9 withsores
位图(Bitmap)
- 存储值:0或者1
- 本质是数组(储存0、1),底层是String
- 最大位数2^32位
常用命令
redis
//将第offset的值设置为value,value只能是0/1
setbit key offset value
//获得第offset位的值
getbit key offset
//获取直节长度
strlen key
//得出改key里面含有几个1
bitcount key
//对一个或者多个key进行逻辑并
bitop and destkey key1 key2
//对一个或者多个key进行逻辑或
bitop or destkey key1 key2
//对一个或者多个key进行逻辑异或
bitop xor destkey key1 key2
//对key进行逻辑非
bitop not destkey key应用
- 签到
- 最好设置过期时间
- 对于电影和广告是否被点击
基数统计(HyperLogLog)
- 只存储一个集合不重复元素的个数,不储存实际数据
- 基数:去重后真实的个数
- 内存:12KB,但是能记录2^64次方的基数
- 误差:大概在0.81%
常用命令
redis
//添加元素到key中
pfadd key element[element......]
//返回key基数的估计值
pfadd key[key......]
//合并
pfmerge deskey sourcekey[sourcekey]应用场景
- 统计某个网页的UV、某个文章的UV
- UV独立访客,一般指ip地址
- 用户搜索网站的关键词数量
- 统计用户每天搜索不同词条的个数
地图空间(GEO)
- 存储某个东西的经纬度
- 使用方法:网站查询+赋值粘贴,经纬度网站
常用命令
redis
//存储一个/多个经纬度
geoadd
//查看所有经纬度
geopos
//返回两个位置之间距离
geodist
//以给定经纬度为中心,返回与中心的距离不超过给定最大距离
georandlus
//返回一个或者多个位置元素的geohash表示
geohash应用
- 美团附近饭店
- 高德附近酒店
流(Stream)
实现消息队列方式
-
List实现消息队列
-

-
常用来做异步队列,将需要延后处理 的任务结构体序列化字符串 ,另外一个线程从这个列表中轮询进行数据处理,如:asio异步读写
-
-
Pub/Sub发布订阅
-
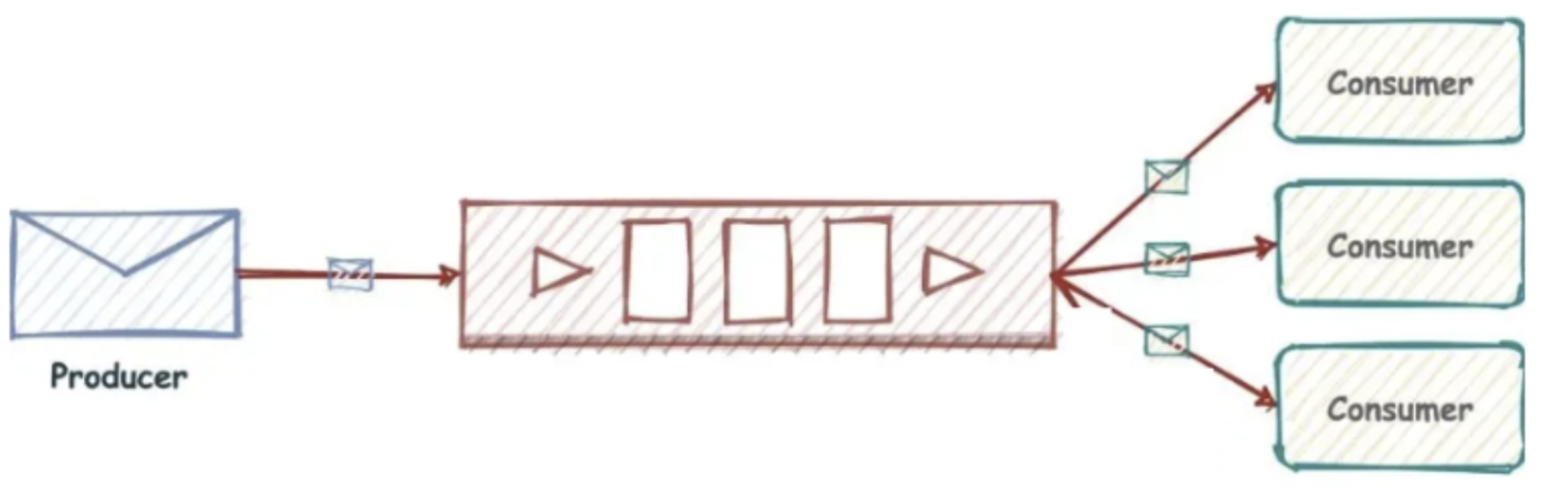
-
发布订阅者模式缺点是消息无法持久化,如果出现断网等,消息会被丢弃。
-
-
Stream流(Redis的MQ消息中间件+阻塞队列)
-
-
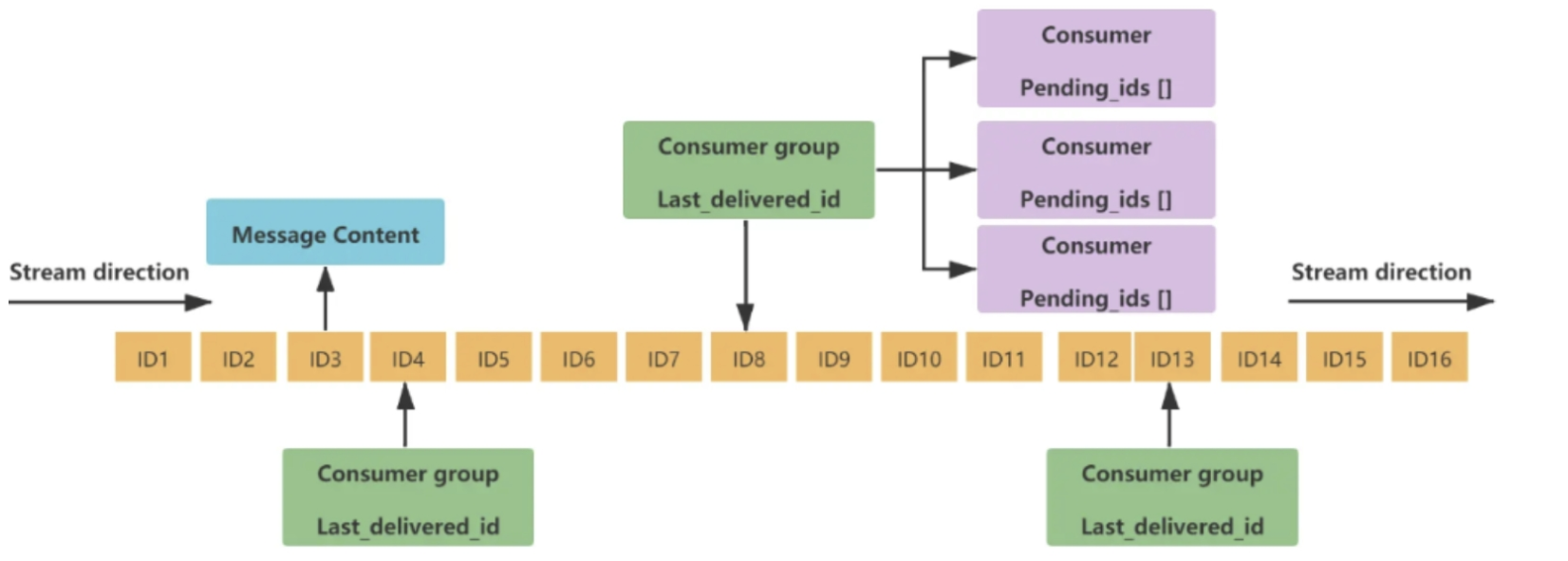
Stream流实现消息队列,支持消息的持久化,支持自动生成全局唯一ID,支持ack确认消息的模式,支持消费的模式等,让消息队列更加稳定可靠
-
数据结构 :一个消息链表,将所有加入的消息都串起来,每一个消息都有唯一的ID和对于内容
-
内容解释:
- Message Content:消息内容
- Consumer Group: 消息组,
xgroup create命令创建,同一个消费组可以有多个消费者 - Last_delivered_id: 游标,每一个消费组都有一个游标,任意一个消费组读取了一个消息,游标都会往前走
- Consumer: 消费组
- Pending_ids: 消费组有一个状态量,记录当前消费组已读但是还没有ack消息id,Pending_ids的状态就是已读但是还没有ack确认
-
队列命令
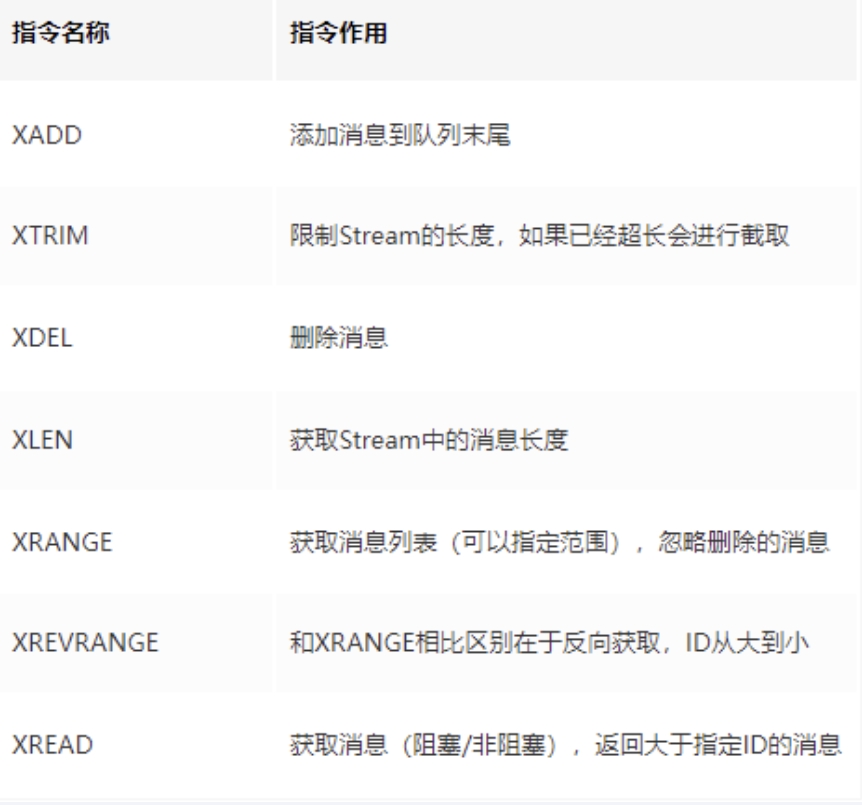
注意:
- XADD,
*系统自动生成MessageID,Redis中对ID有强制要求,格式必须时间戳-自增ID,并且后面id不能小于前面的 - Message Content结构类似于Hash的,以key-value的形式存在
redis
127.0.0.1:6379> xadd mystream * k1 v1 k2 v2 k3 v3
"1720336029607-0"
127.0.0.1:6379> xrange mystream 0 +
1) 1) "1720336029607-0"
2) 1) "k1"
2) "v1"
3) "k2"
4) "v2"
5) "k3"
6) "v3"
// read STREAMS是固定的,$代表从没有读的时候开始读,读取一般需要通过id
XREAD STREAMS mystream $
// 最大长度为100(裁剪)
127.0.0.1:6379> xtrim mystream maxlen 100
(integer) 0
// 通过ID裁剪
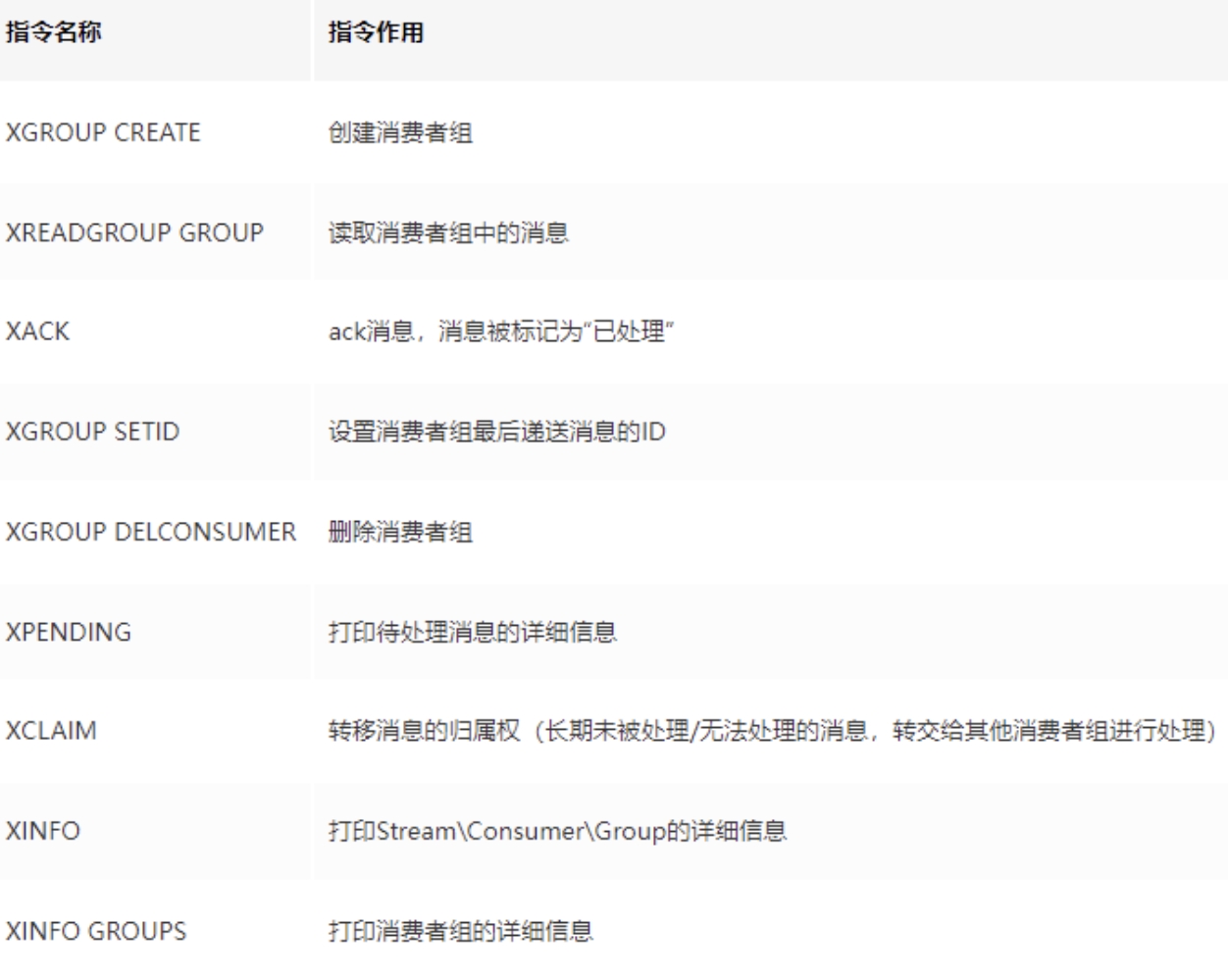
XTRIM mystream ~/ > / < ID消费组命令
工作流程
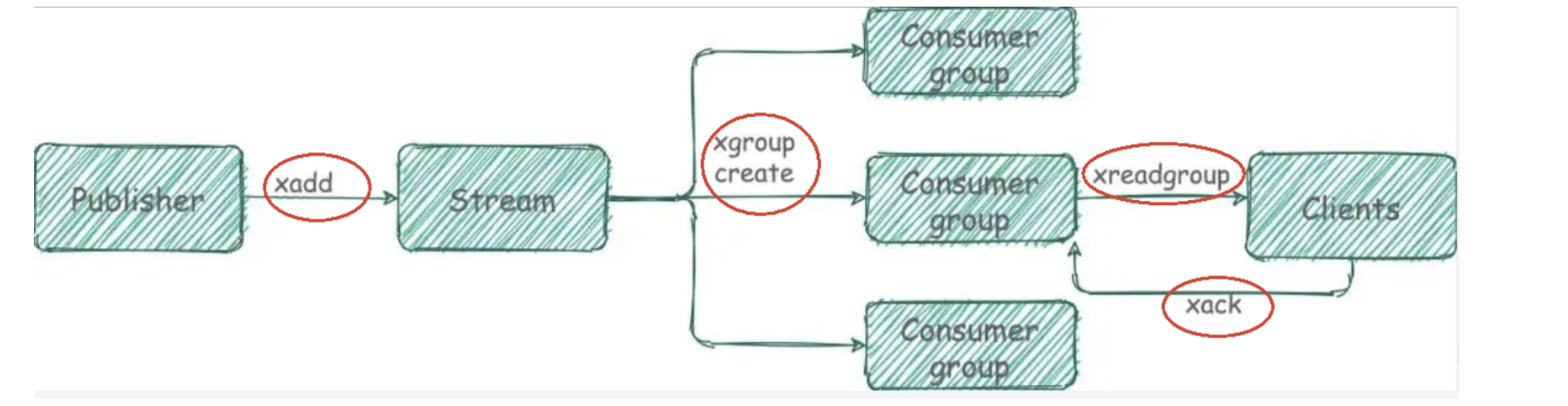
基于Stream实现消息队列,如何确保消费组在发生事故再次重启后任然可以读取未处理完的消息?
- Stream会使用内部的队列,留存消费组每个消费者读取的消息保底措施,直到消费者使用XACK命令通知Streams消息处理完成后
- 故一遍在业务处理完后,选哟执行XACK,命令确定消息已经被消费者完成
实践
redis
// 创建两个组 $表示从Stream尾部开始消费0表示从Stream头部开始消费
127.0.0.1:6379> xgroup create mystream gorupA $
OK
127.0.0.1:6379> xgroup create mystream groupB $
OK
// stream中的消息一旦被消费组的消费者读取后,就不再被其他组内成员读取了
// 同时注意:XREADGROUP GROUP是读取新添加的数据,如果创建的时候添加的数据是读取不到的
127.0.0.1:6379> XADD my1 * k1 v1
"1720338309431-0"
127.0.0.1:6379> XREADGROUP GROUP groupA consumer1 STREAMS my1 >
1) 1) "my1"
2) 1) 1) "1720338309431-0"
2) 1) "k1"
2) "v1"
127.0.0.1:6379> XREADGROUP GROUP groupA consumer1 STREAMS my1 >
(nil)
127.0.0.1:6379> 重要: 四个特殊符号的运用
建议
- Stream不能完全代替Kafra等消息队列,生产用的少,慎用
四个特殊符号

- 这四个符号是工具
- 对消息队列排序输出,用到 +/-符号
位域(Bitfield)
- 了解即可
- 作用:将一个Redis字符串看作是一个由二进制组成的数组,不能对变长宽度和任意没有对齐的指定整型位域进行寻找和修改
- 遇到查阅资料
Redis持久化
Redis持久化方式:
- RDB
- AOF
RDB
-
是什么?
-
在指定的时间间隔,执行数据集的时间点快照
-
能做什么?
- 在指定的时间间隔内将内存中数据集快照写入磁盘,恢复的时候快照文件读回内存
-
RDB保存的文件是dump.rdb文件(默认),redis7配置文件482行
-
快照文件(dump.rdb)文件存储的是二进制,是压缩过的二进制
-
优点:
- 简单、快速,适合大规模数据存储
-
缺点:
-
数据可能会丢失,因为 Redis 只会在指定的时间点生成快照文件。如果在快照文件生成之后,但在下一次快照文件生成之前服务器宕机,那么这期间的数据就会丢失。
-
redis下可以通过
config get/set......查找redis相关的配置 -
本机redis配置文件存储地方
/etc/redis文件夹下 -
本机设置RDB时间
# save ""(433行附近) save 900 1 save 300 10 save 60 10000- 在900s内,对数据库修改了1次,备份
- 在300s内,对数据库修改了1次,备份
- 在60s内,对数据库修该了10000次,备份
触发方式
自动触发
-
自动方式是指通过服务器配置文件的 save 选项,来让 Redis 每隔一段时间自动执行 bgsave ,本质上还是通过 bgsave 命令去实现。
-
配置文件的 save 选项允许配置多个条件,只要其中任何一个条件满足,就会触发 bgsave。
手动触发
-
save命令,禁止使用,会阻塞主进程
-
bgsave命令,原理使用父子进程,不阻塞,原理图如下:
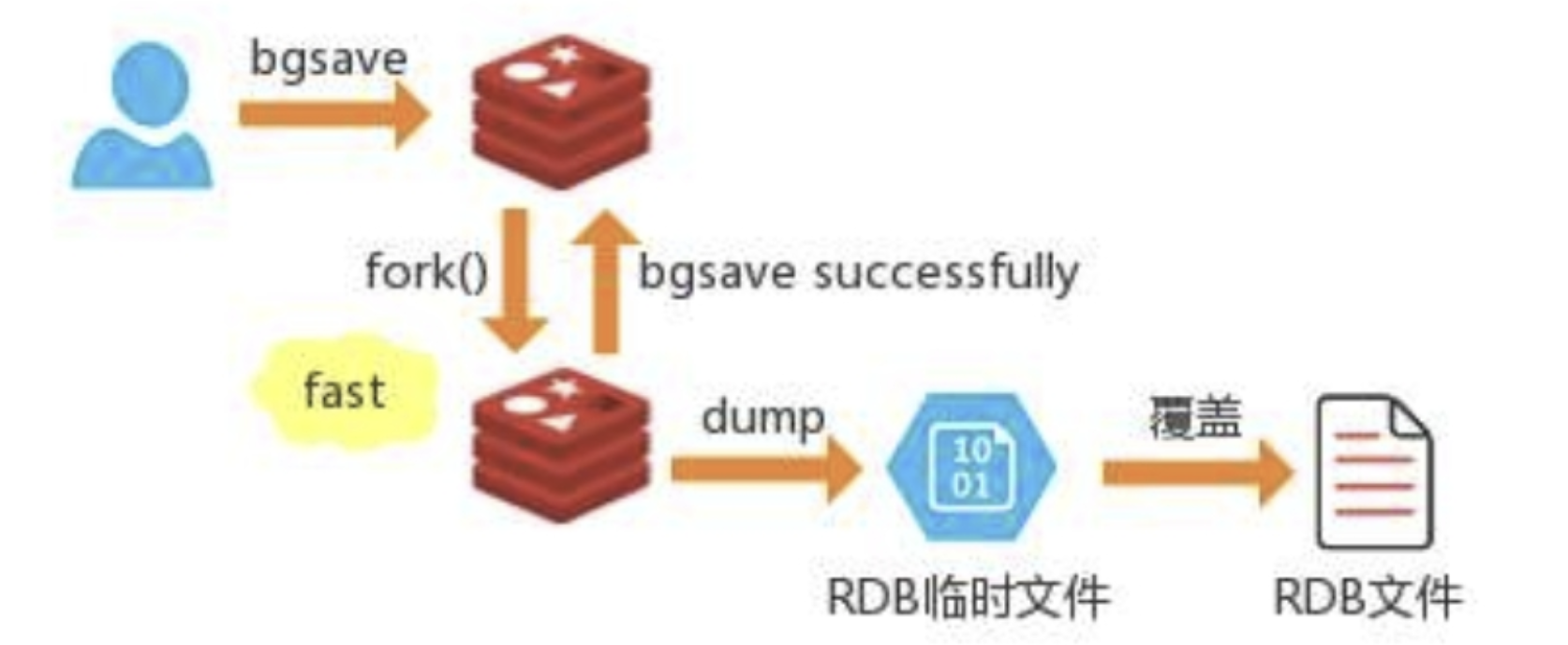
- fork机制:读时共享,写时拷贝
- fork 的这个过程主进程是阻塞的,fork 完之后不阻塞。
- **当数据集比较大的时候,fork 的过程是非常耗时的,**过程可能会持续数秒,可能会因为数据量大而导致主进程长时间被挂起,造成Redis服务不可用。
save选项,Redis是通过什么判断的?
Redis 服务器内部维护了一个计数器:dirty 和一个时间戳:lastsave。
- dirty计数器:dirty计数器记录距离上一次成功执行 save 命令或者 bgsave 命令之后,服务器对数据库状态(服务器中的所有数据库)进行了多少次修改(包括写入、删除、更新等操作),命令修改了多少次数据库,dirty计数器的值就增加多少。
- lastsave时间戳:lastsave时间戳则记录了服务器上一次成功执行 save 命令或者 bgsave 命令的时间。
Redis 判断的时机是什么时候?
Redis通过周期性操作函数 serverCron 默认每隔100毫秒就会执行一次检查,来判断 save 选项所设置的保存条件是否已经满足。
RDB其他配置(配置文件中)
- stop-writes-on-bgsave-error:指定在 RDB 持久化过程中如果出现错误是否停止写入操作。如果设置为 yes,当 Redis 在执行 RDB 操作时遇到错误时,Redis 将停止接受写入操作;如果设置为 no,Redis 将继续接受写入操作。
- rdbcompression:指定是否对 RDB 文件进行压缩。如果设置为 yes,Redis 会在生成 RDB 文件时对其进行压缩,从而减少磁盘占用空间;如果设置为 no,Redis 不会对生成的 RDB 文件进行压缩。
- rdbchecksum:指定是否对 RDB 文件进行校验和计算。如果设置为 yes,在保存 RDB 文件时,Redis 会计算一个 CRC64 校验和并将其追加到 RDB 文件的末尾;在加载 RDB 文件时,Redis 会对文件进行校验和验证,以确保文件没有受到损坏或篡改。
- replica-serve-stale-data:这是 Redis 4.0 中新增的一个配置项,用于指定复制节点在与主节点断开连接后是否继续向客户端提旧数据。**当设置为 yes 时,在复制节点与主节点断开连接后,该节点将继续向客户端提供旧数据,直到重新连接上主节点并且同步完全新的数据为止;**当设置为 no 时,复制节点会立即停止向客户端提供数据,并且等待重新连接上主节点并同步数据。需要注意的是,当 replica-serve-stale-data 设置为 yes 时,可能会存在一定的数据不一致性问题,因此建议仅在特定场景下使用。
- repl-diskless-sync :这是 Redis 2.8 中引入的一个配置项,用于指定复制节点在进行初次全量同步(即从主节点获取全部数据)时是否采用无盘同步方式。当设置为 yes 时,复制节点将通过网络直接获取主节点的数据,并且不会将数据存储到本地磁盘中;当设置为 no 时,复制节点将先将主节点的数据保存到本地磁盘中,然后再进行同步操作。采用无盘同步方式可以避免磁盘 IO 操作对系统性能的影响,但同时也会增加网络负载和内存占用。
AOF
- 是什么?
- 以日志的形式记录每个操作,将redis执行的每个指令记录下来
- 注意 :默认情况下,redis是没有开启 的,选哟在配置文件中设置:
appendonly yes
- 保存文件名字:
appendonly.aof
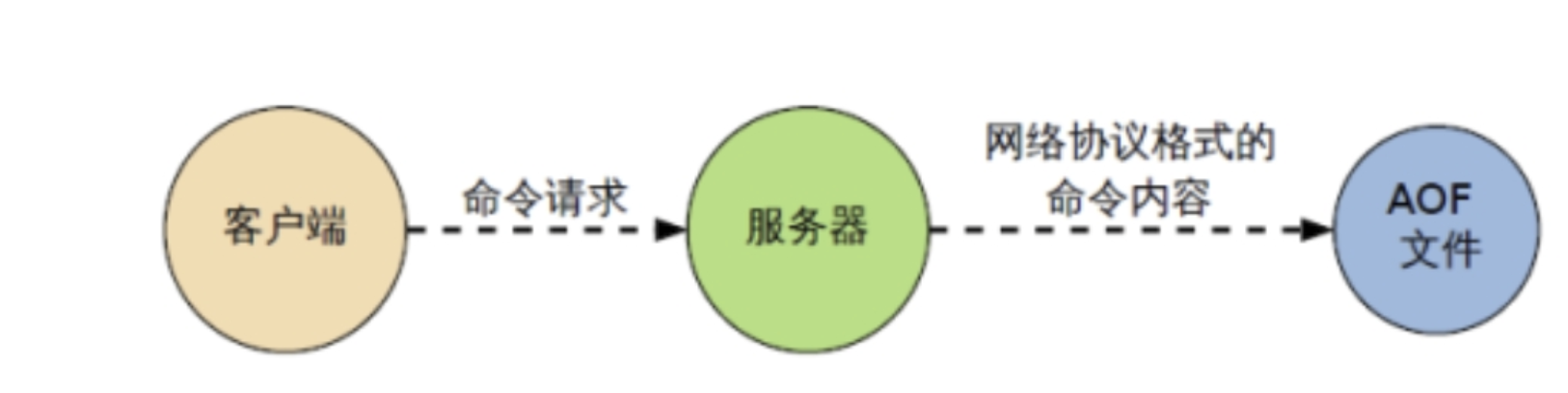
AOF工作流程
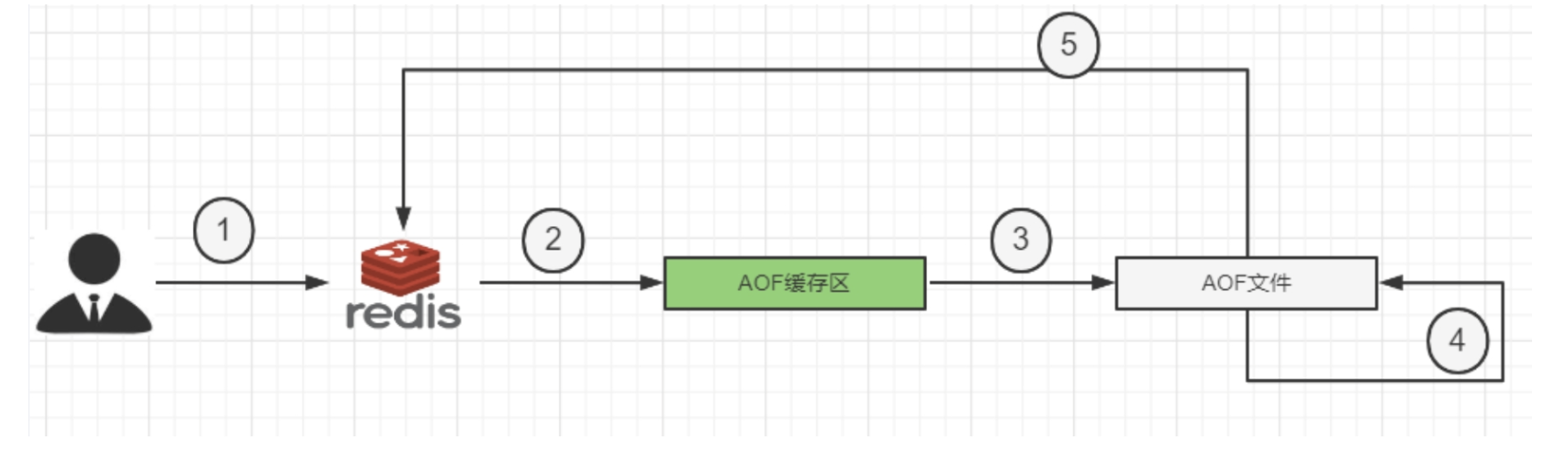
- Client,命令来源
- 命令到达Redis服务器的时候,首先到达AOF的缓冲区进行保存,等待到达一定数量的时候,在进行保存,写入磁盘中(缓冲区:一块内存区域)
- AOF缓存根据AOF缓冲区同步文件的三种写回策略将命令存入AOF文件中(文件存在磁盘中)
- 等AOF内容很多的时候,AOF文件会膨胀,这个时候Redis会对AOF重写(命令的合并),从而起到压缩的目的
- 例子:
- set k1 111
- set k1 222
- set k1 333
- 以上命令结果是设置键值k1数据是333,前两个没用了,可以删去
- 例子:
- 当Redis Server服务器启动的时候会从AOF文件进行载入数据
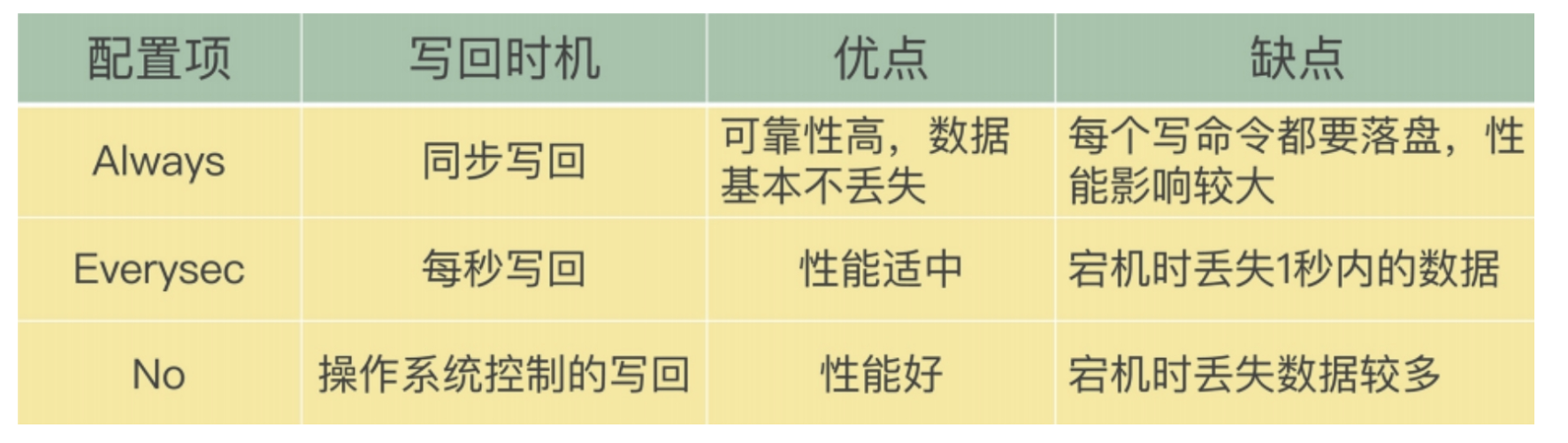
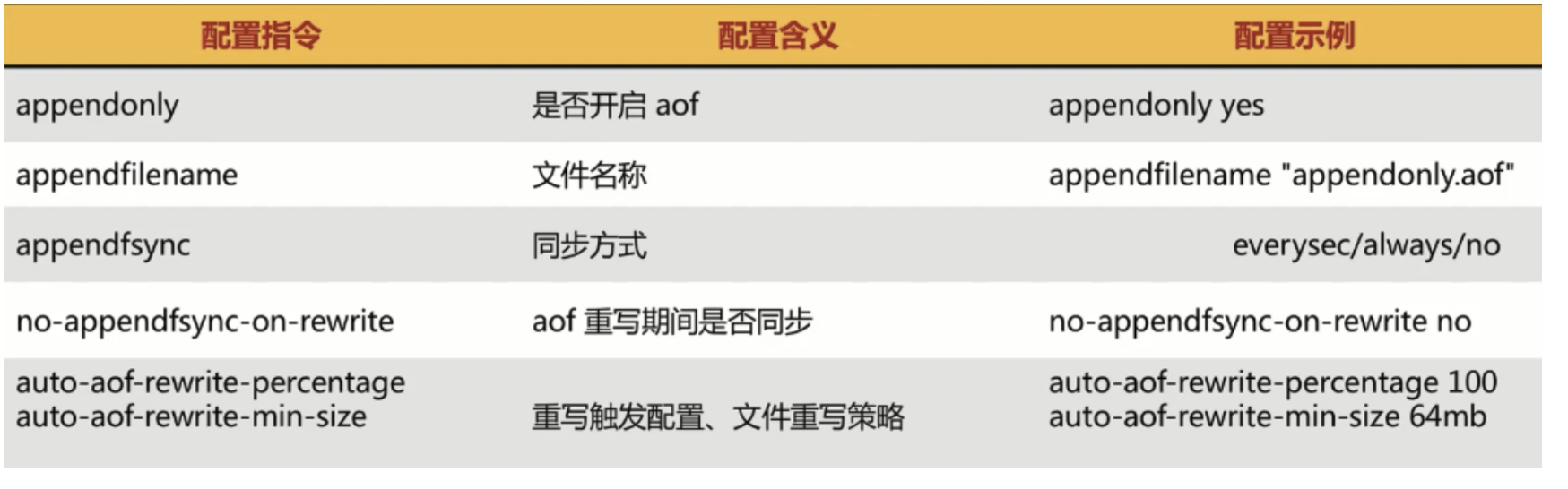
AOF三种写入策略(面试)
AOF文件存在新式
txt
1、基本文件
appendonly.aof.1.base.rdb
2、增量文件
appendonly.aof.1.incr.aof
3、清单文件
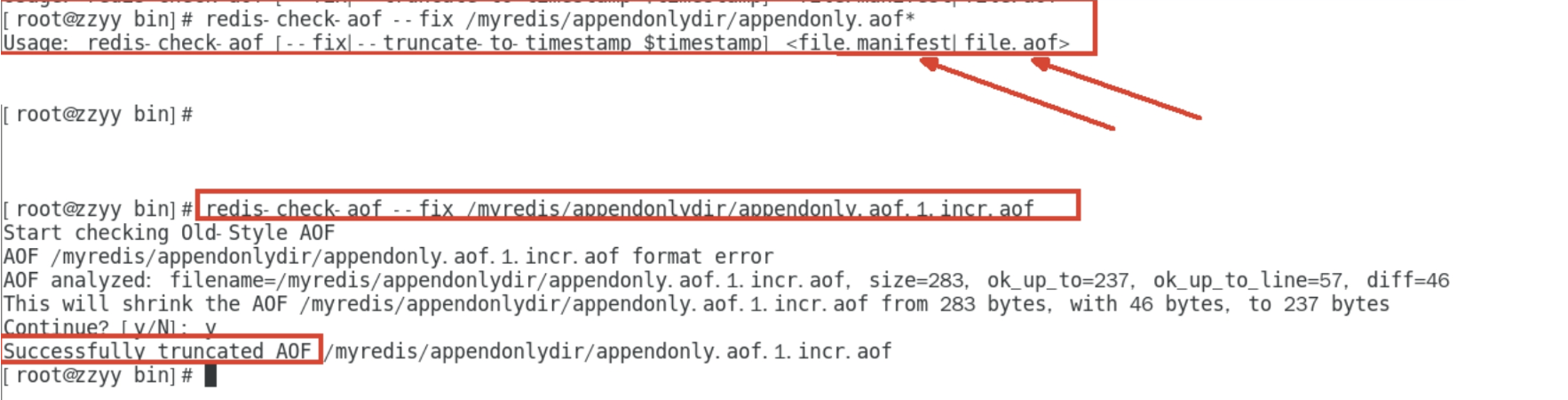
appendonly.aof.manifestAOF异常恢复
-
发送异常:
-
故意乱写AOF文件,在书写Redis文件中断网,这个时候会发现AOF载入启动会发生错误
-
解决方法:
AOF重写机制
- 是什么?
- 压缩AOF内容,只保留可以恢复数据的最小指令集
触发机制
自动触发
- 满足配置文件选项后,Redis会记录上次重写的AOF大小。默认配置AOF文件大小是上次rewirte后大小的一倍且大于64M
手动触发
- 客户端向服务器发送bgrewriteaof命令
AOF重写原理
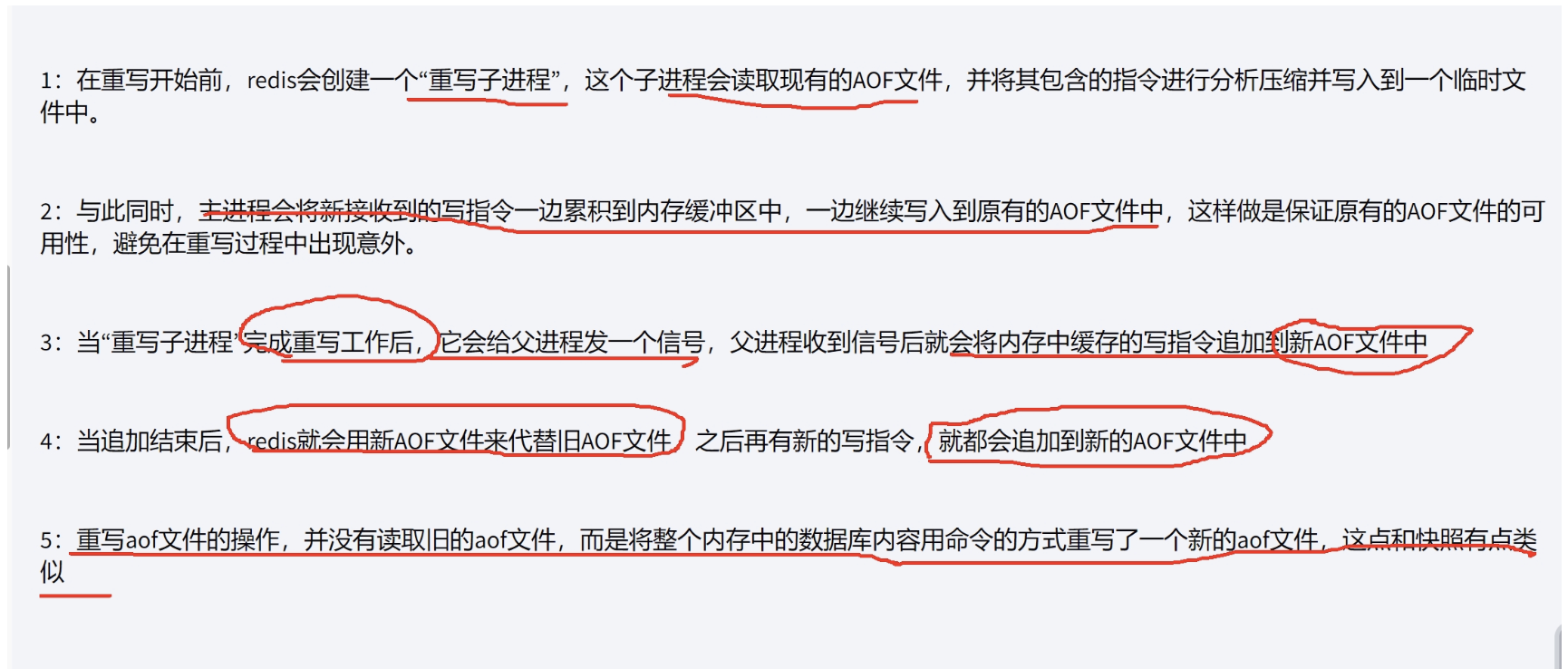
AOF其他优化命令
AOF总结
- Redis可以在AOF文件体积过大的时候自动对AOF进行重写
- AOF文件有序对数据库执行的所有写入操作,这些写入操作以Redis协议格式保存,容易阅读
- 相同数据集合来说,AOF体积大于RDB
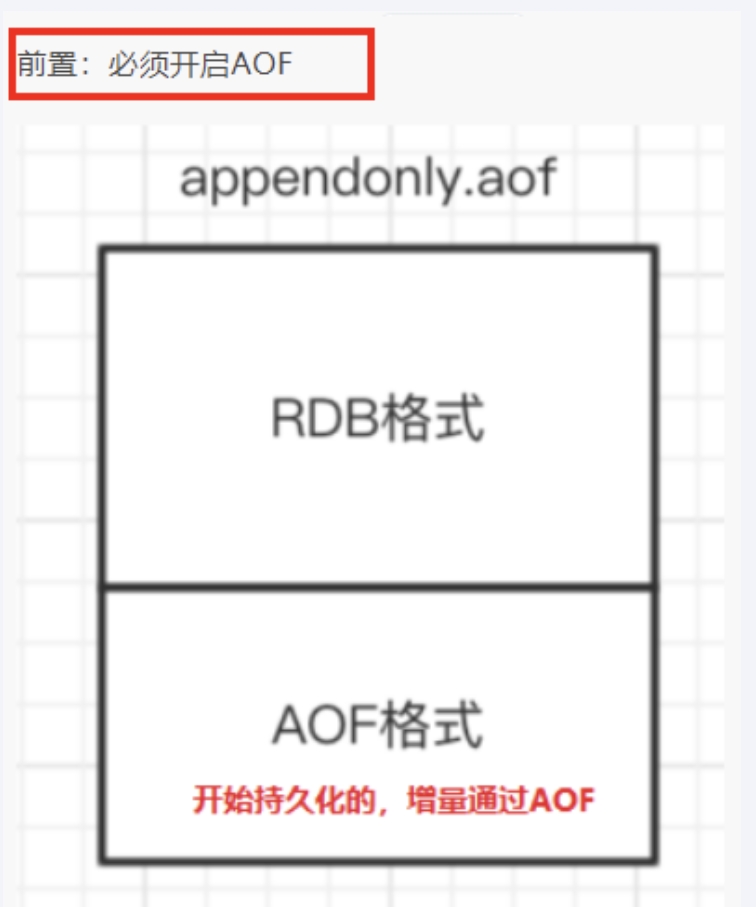
RDB-AOF混合持久化
- RDB和AOF可以共存,在同时开始的时候,会制动优先使用AOF进行缓存
- 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整,RDB的数据不实时,但是 RDB更适合用于备份数据库(AOF在不断变化不好备份),即 RDB镜像做全量持久化,AOF做增量持久化
混合方式工作流程
开启混合化
设置aof-use-rdb-preamble的值为 yes yes表示开启,设置为no表示禁用
Redis事件
- 是什么?
- 一组命令的集合,可以一次性执行多个命令
- 在一个事务中,命令存在队列 中,按顺序的执行,发送服务器的时候也是一条一条发送的(结合与管道特点)
- 作用:
- 一次性、有序的、排他性的执行一系列命令
与MySQL事务的区别
- 单独的隔离级别
- Redis是单线程的数据库,Redis天然具有隔离性,因为同一时间只有同一操作的执行,不存在并发问题。
- 但是MySQL具有隔离性,不同的事务隔离级别相互访问数据,防止数据交叉执行导致不一致
- 没有隔离级别这一概念
- 在事务提交前指令都不会杯执行,故不存在"事务内的查询要看到事务里的更新,在事务外查询不能看到"这种问题
- 不能保证原子性
- Redis单个命令 是具有原子性的,但是事务不保证,即不保证所有指令同时执行成功或者同时失败,如:下面的Case4
- 排他性
- Redis会保证一个事务内的命令依次执行,不会被其他命令插入
常用操作
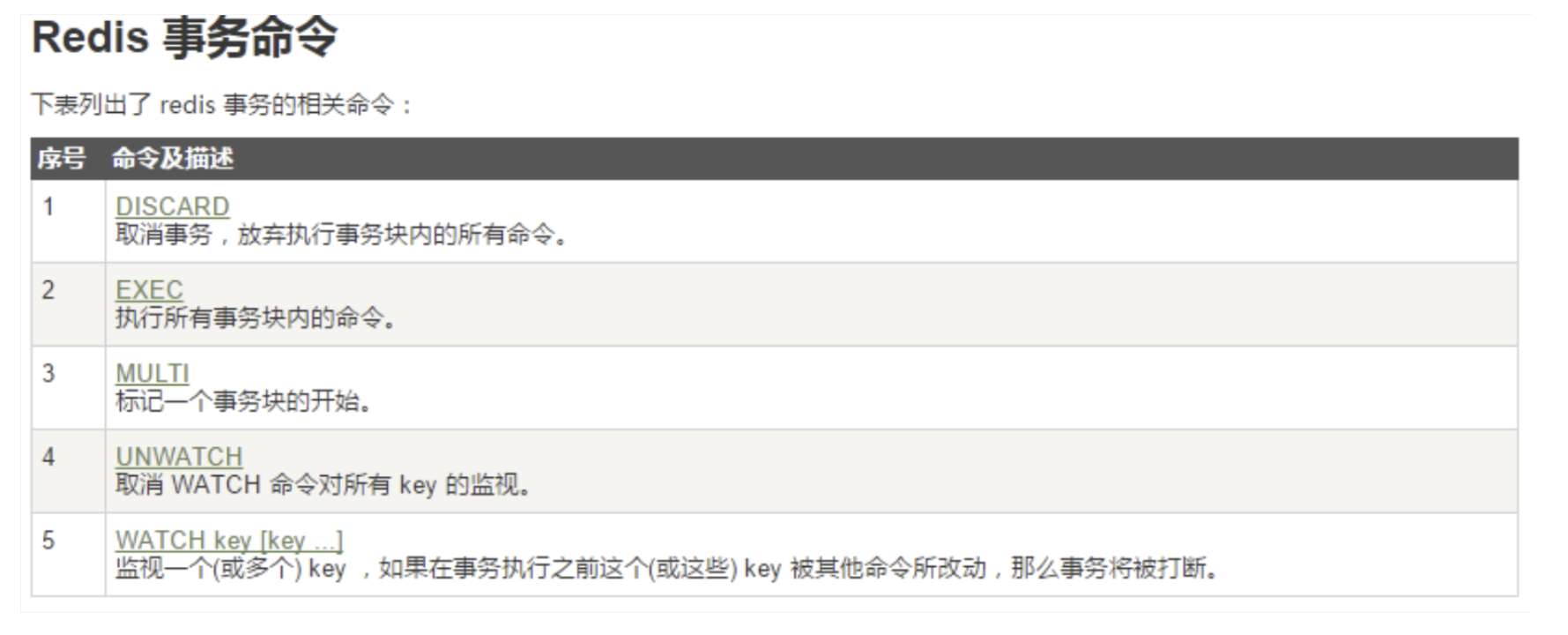
Case1:正常执行
- multi开启事务
- exec执行事务
Case2:放弃事务
- discard命令,开启事务后,不想执行了,取消
Case3:全体连坐
-
开启事务后,一个指令(语法)错误,检查出来,那这一组事务exec后后取消
redis127.0.0.1:6379> set k1 6 OK 127.0.0.1:6379> set k2 7 OK 127.0.0.1:6379> set k3 8 OK 127.0.0.1:6379> multi OK 127.0.0.1:6379(TX)> set k1 8 QUEUED 127.0.0.1:6379(TX)> set k2 // 失败 (error) ERR wrong number of arguments for 'set' command 127.0.0.1:6379(TX)> exec (error) EXECABORT Transaction discarded because of previous errors. //取消 or 'get' command 127.0.0.1:6379> get k1 //k1没有修改成功 "6"
Case4:冤头债主
- 开启事务后,如果某一条执行语句错误,但是没有被检测出来(语法没用错误),执行的时候,只有那一条语句没有执行成功,其他都会执行成功,不相互影响
redis
127.0.0.1:6379> set k1 1
OK
127.0.0.1:6379> set k2 3
OK
127.0.0.1:6379> set email seshdfssiuh
OK
127.0.0.1:6379> multi //开启事务
OK
127.0.0.1:6379(TX)> set k1 6
QUEUED
127.0.0.1:6379(TX)> set k2 88
QUEUED
127.0.0.1:6379(TX)> incr email //邮件,一堆字符串增加不了,但是语法没有问题
QUEUED
127.0.0.1:6379(TX)> exec //执行
1) OK
2) OK
3) (error) ERR value is not an integer or out of range //只有那一条没用执行成功
127.0.0.1:6379> get k1
"6"
127.0.0.1:6379> get email
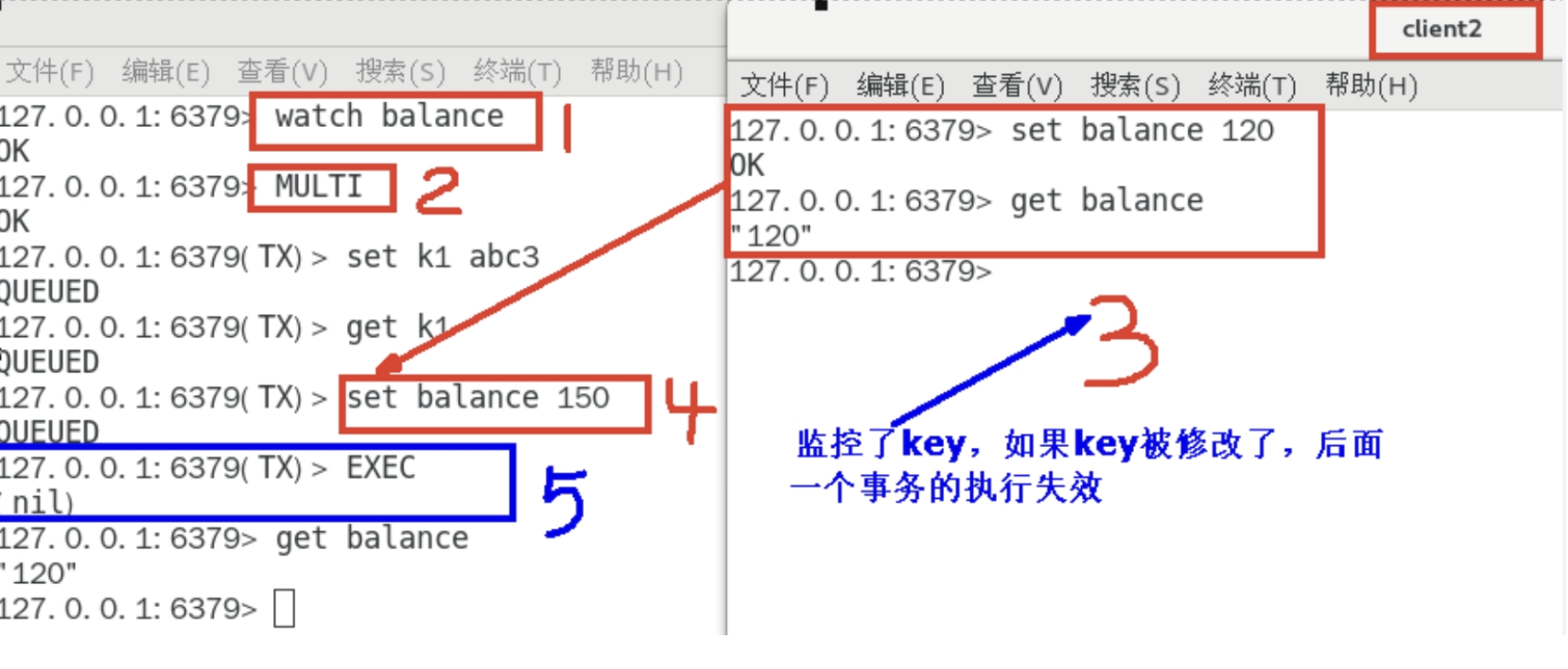
"seshdfssiuh"Case5:watch监控
- watch提供乐观锁锁定
- 乐观锁简介:每次拿数据的时候,默认以为他不会被修改,不会上锁,但是会在更新的时候判断一下有没有人去更新这把锁
- 悲观锁简介:认为每次拿数据的时候别人都还会被修改,故加上锁
- watch:首先监控一个变量,如果开启事务后修改它,没用提交,这个时候发现另外客户端修改了这个变量,则执行失败
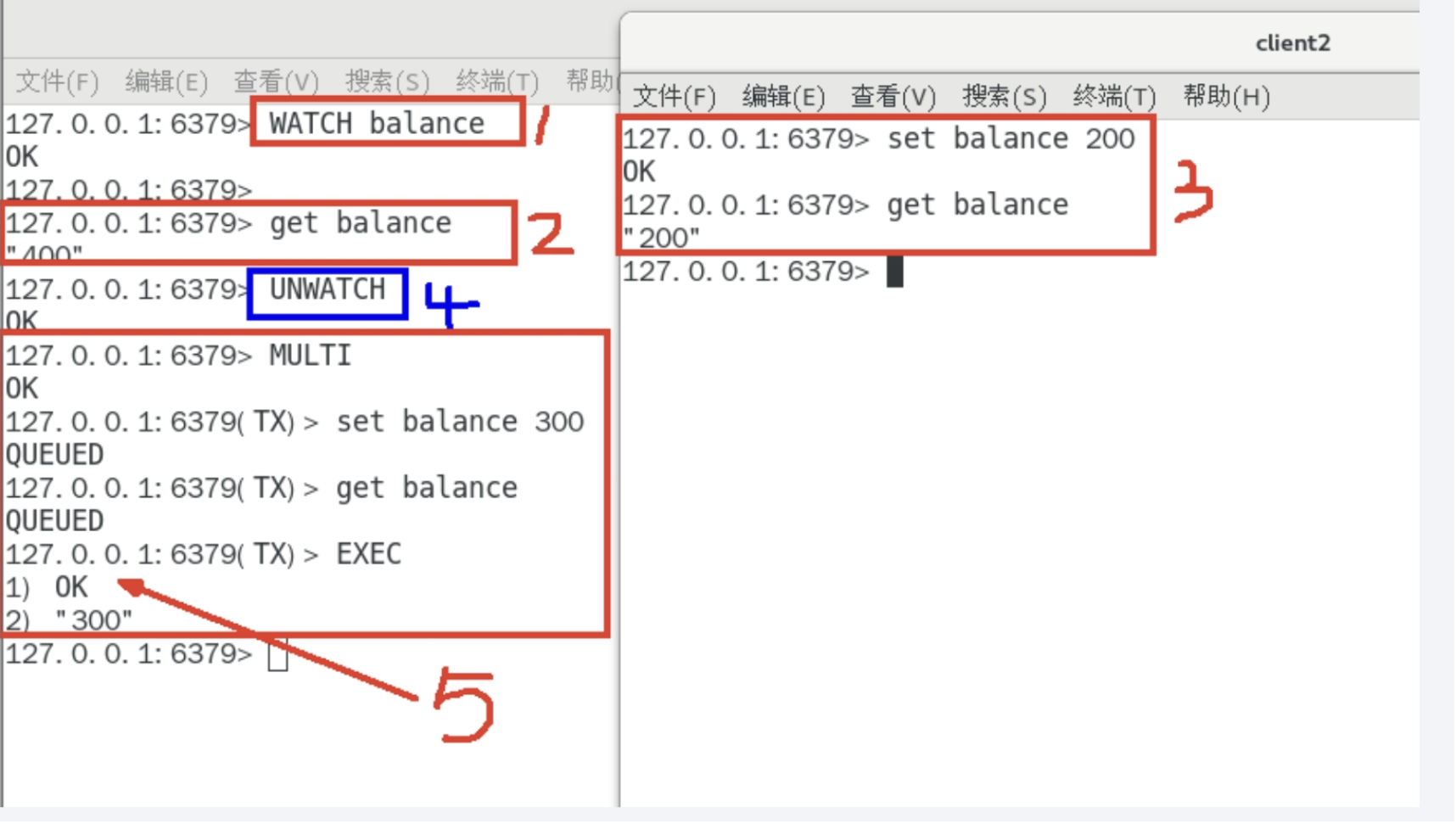
- 解锁:unwatch
- 在事务中,我知道了别的客户端已经修改过这个变量了,则我自动取消!
总结
- 开启
- multi开启事务
- 入队
- 将多个命令入队到事务中,接到这些命令并不立即执行,而是放到队列中
- 执行
- exec命令执行
Redis管道
- Linux的管道用来进程间的通信,Redis是具体实现
面试题
如何优化频繁命令往返造成的性能瓶颈?
- Redis是一种基于客户端-服务端模型以及请求/响应协议的TCP服务。一个请求会遵循以下步骤:
- 客户端向服务端发送命令分四步**(发送命令→命令排队→命令执行→返回结果)**,并监听Socket返回,通常以阻塞模式等待服务端响应服务端处理命令,并将结果返回给客户端。
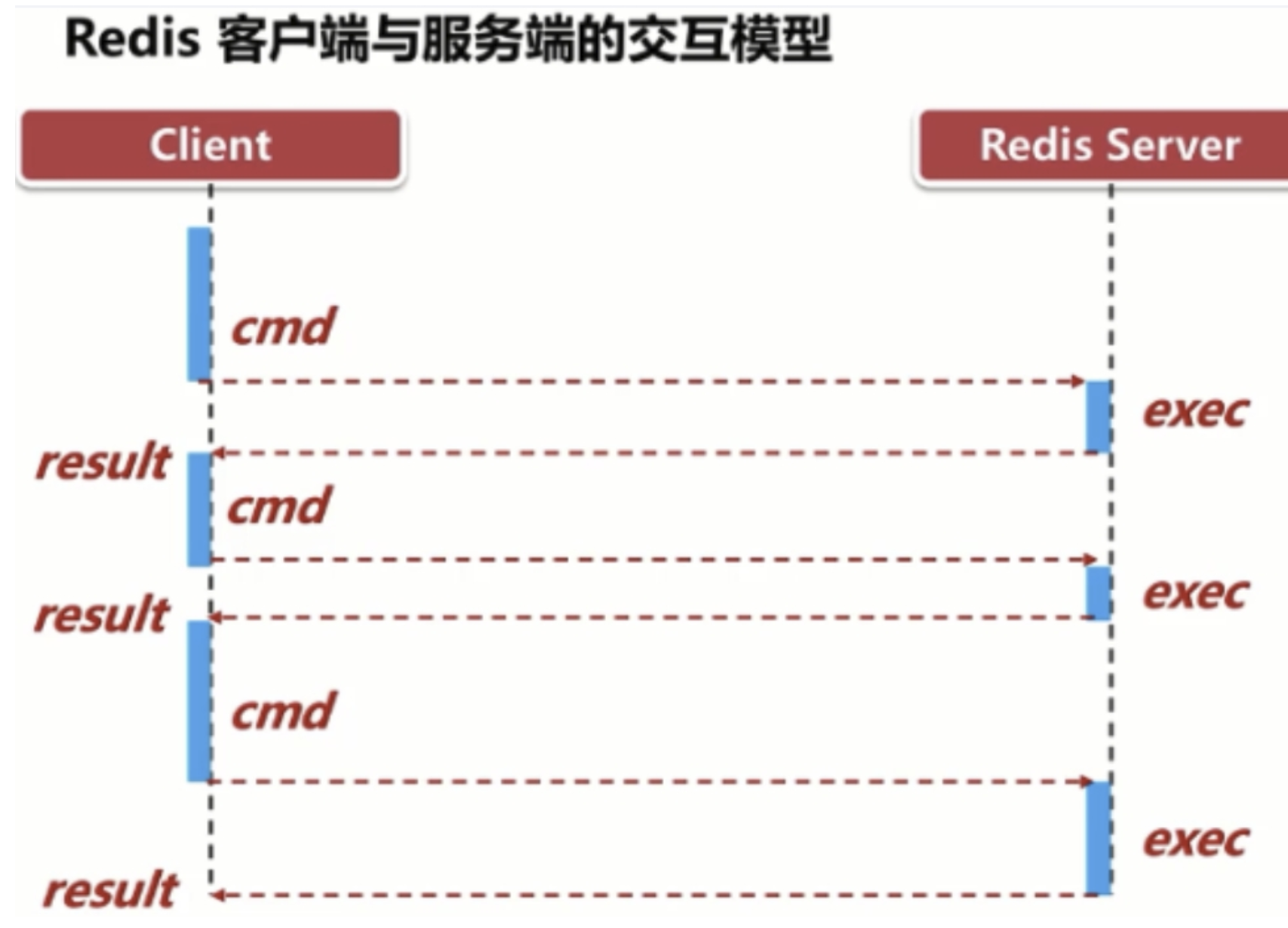
- 如果同时需要执行大量的命令,那么就要等待上一条命令应答后再执行,这中间不仅仅多了RTT(Round Time Trip),而且还频繁调用系统IO,发送网络请求,同时需要redis调用多次read()和write()系统方法,系统方法会将数据从用户态转移到内核态,这样就会对进程上下文有比较大的影响了,性能不太好。
- 解决方法:管道
简介
- Pipeline是为了解决RTT往返时,仅仅是将命令打包一次性发送 ,对整个Redis的执行不造成任何影响,即批量处理命令各种变化,类似于(mget和mset)
- 实际操作的时候需要与redis环境隔离,需要用到linux命令
总结
- Pipeline 与原生批量
- 原生批量命令是原子性 (如:mset,mget),pipeline是非原子性
- 原生批量命令一次只能执行一种命令,pipeline支持批量执行不同命令
- 原生批命令是服务端实现,而pipeline需要服务端与客户端共同完成
- Pipeline 与事务对比
- 事务具有原子性,管道不具有原子性
- 管道一次性将多条命令发送到服务器,事务是一条一条发的(队列),事务只有在接收到exec命令后才会执行,管道不会
- 执行事务时会阻塞其他命令的执行(单独隔离级别),而执行管道中的命令时不会
- Pipeline 注意事项
- pipeline缓冲的指令只是会依次执行,不保证原子性,如果执行中指令发生异常,将会继续执行后续的指令
- 使用pipeline组装的命令个数不能太多,不然数据量过大客户端阻塞的时间可能过久,同时服务器也被迫回复一个队列答复,占用很多内存
Redis发布订阅
- 一种设计模式----观察者模式
- 只需要了解即可
- 模式介绍:
- 发送者,发送消息
- 订阅者,接受消息
- 是实现Redis的一个消息中间件的方式
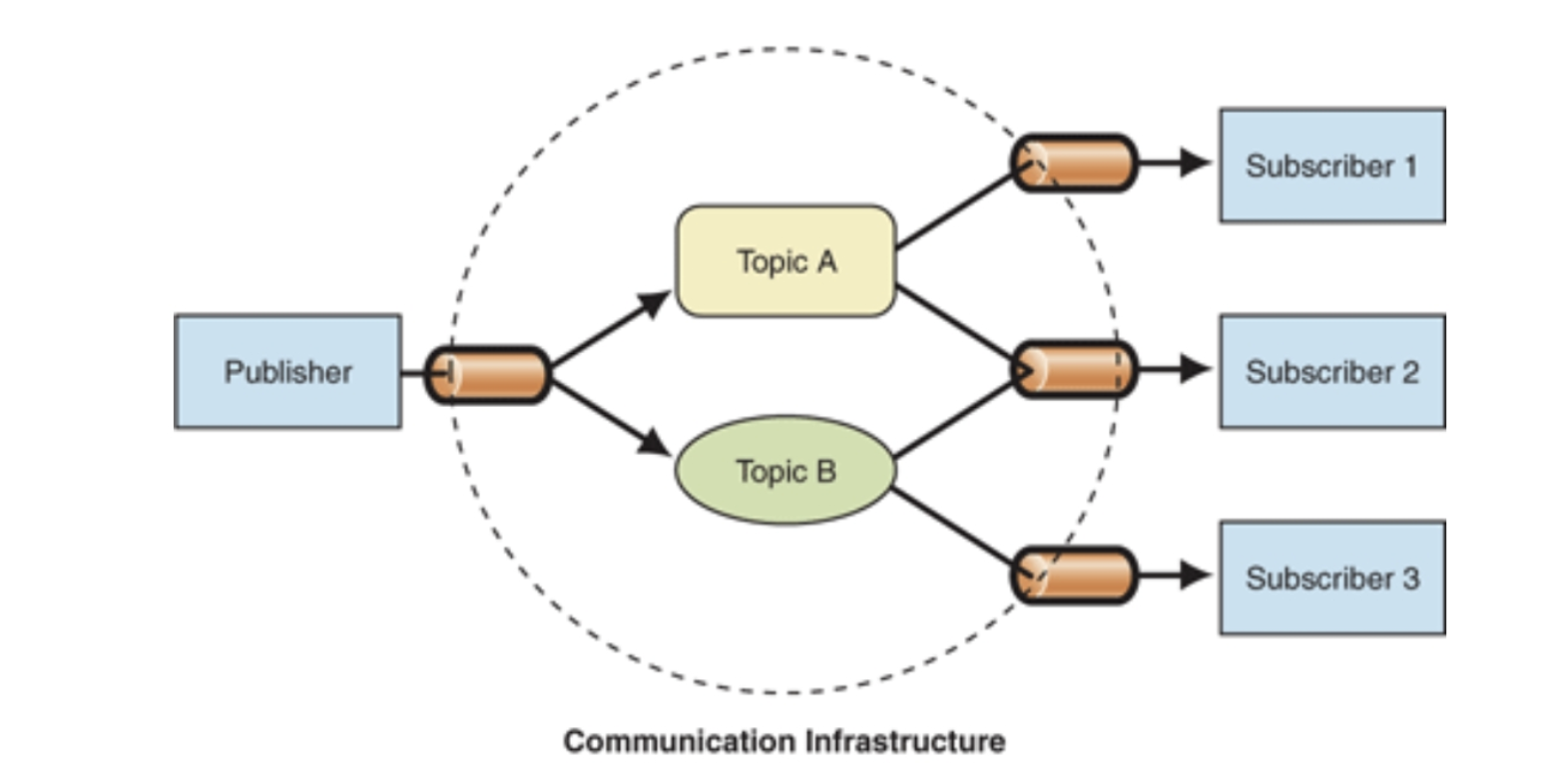
C++实现简要的发布订阅者模式
C++
#include <iostream>
#include <vector>
class Teacher;
class Student
{
public:
Student(std::string name, Teacher teacher) :m_name(name), m_teacher(teacher) {}
// server updata status
void updata(std::string pub_action)
{
if ("老师来了" == pub_action)
{
std::cout << "学习中......" << std::endl;
}
else if ("老师走了" == pub_action)
{
std::cout << "摸鱼中......" << std::endl;
}
}
private:
std::string m_name;
Teacher m_teacher;
};
class Teacher
{
public:
void addServer(Student server)
{
m_servers.push_back(server);
}
void notify()
{
for (auto& it : m_servers)
{
it.updata(m_action);
}
}
// the status of publisher changes
void setAction(std::string action)
{
m_action = action;
notify();
}
private:
std::string m_action;
std::vector<Student> m_servers;
};
int main()
{
Teacher th;
Student st1("wy", th);
Student st2("lt", th);
th.addServer(st1);
th.addServer(st2);
th.setAction("老师来了");
th.setAction("老师走了");
return 0;
}Redis复制
- 是什么?
- 叫做主从复制,MySQL也有,当master数据变化时候,自动同步异步更新到其他slave数据库
- 特点
- 读写分离
- down恢复
- 数据备份
- 水平扩容支撑高并发
基本操作
- 注意 :在配置的时候, 配置从库不配置主库
- 权限设置:
- 如果master配置了requirepass参数,则需要密码登录,且slave申请连接的时候需要配置masterauth来设置校验密码,否则master会拒绝salve的请求
redis
info replication
可以查看主、复制节点的关系和配置文件
replicaof 主库IP 主库端口
slave连接主库,但是一般写在redis的配置文件里
slaveof 主库IP 主库端口
修改slave的主库,如果没有写入配置文件,则每一次slave与master断开都需要重新连接
slaveof no one
使当前数据库停止与其他数据库同步,**转为主数据库,自立为王**配置文件修改
详细看尚硅谷课件
redis
1、开启 daemonize yes
2、注释掉 bind 127.0.0.1
3、protected-mode no
4、指定端口
5、指定当前工作目录,dir
6、pid文件名字,pidfile
7、log文件名字,logfile
8、requirepass //代表slave需要密码
9、dump.rdb名字
10、aof文件,appendfilename
11、slave访问主机的通行密码,masterauth,必须设置- 如果用多虚拟机模拟的时候,注意配置防火墙
shell
启动: systemctl start firewalld
关闭: systemctl stop firewalld
查看状态: systemctl status firewalld
开机禁用 : systemctl disable firewalld
开机启用 : systemctl enable firewalld
添加 :firewall-cmd --zone=public --add-port=80/tcp --permanent (--permanent永久生效,没有此参数重启后失效)
重新载入: firewall-cmd --reload
查看: firewall-cmd --zone= public --query-port=80/tcp
删除: firewall-cmd --zone= public --remove-port=80/tcp --permanent三大命令
主从复制
- 命令:replicaof 主库IP 主库端口
- 注意:配置从库不配主库
- 先启动主库,再配置从库,依次配置,配置好查看命令:info replication
改换门庭
- 命令:slaveof 新主库IP 新主库端口
自立为王
- 命令:slaveof no one
常用三招
一主二仆
Case1:配置文件固定写死
- 在slave库中配置文件设置好,matser库的IP地址、端口号等其他
- 问题
- 从机可以执行写命令么?
- 不行,master既可以写也可以执行读,但是slave只能执行读
- 从机切入问题
- 从机在主机启动后很久接入,一样可以享受主机所有数据
- 主机shutdown后,从机会上位吗?
- 不会,从机依然是slave身份
- 主机shudown后,重启后主从关系还在么?从机是否还可以顺利复制?
- 还在,可以顺利复制
- 某台从机down后,master继续,从机启动后它可以跟上大部队么?
- 可以
- 从机可以执行写命令么?
Case2:命令操作指定
- slaveof 主机IP 主机端口
- 注意 :使用命令的话,从机关机重启,主从复制关系就不存在了
薪火相传
- 介绍
- 一个slave可以是下一个slave的master,slave可以接受别的slave的连接和请求,即该slave作为了链中另外一个slave的master
- 作用
- 有效减轻master的压力
- 注意
- slave中途改变了master,之前的数据也会被清处,重新建立新的连接
- 命令
- slaveof 新主库IP 新主库端口
反客为主
- 命令
- slaveof no one
- 作用
- 使当前数据库停止与其他数据库同步,转换成其他数据库
复制原理
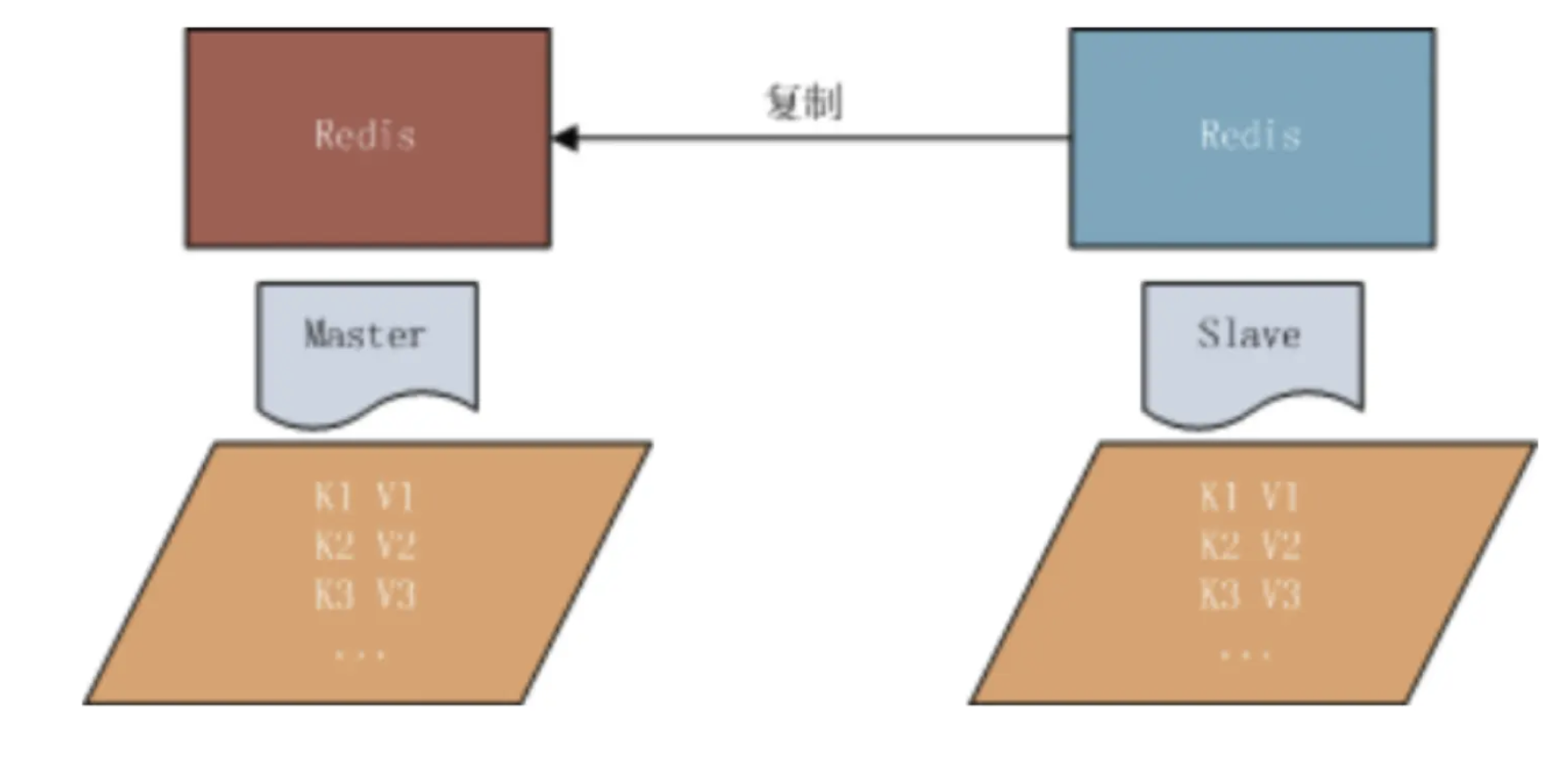
- slave启动,同步请求
- 首次连接,全量复制
- 心跳持续,保持通信
- 每10s,master会发送ping命令检查通信是否畅通
- 进入平稳。增量复制
- master会持续将自己更新的数据自动依次传给slave
- 从机下线,重连续传
- master 会检查backlog里面的offset,master和slave都会保存一个复制的offset怀有一个masterId
- offset 是保存在backlog 中的。master只会把已经复制的offset后面的数据赋值给slave,类似断电续传
缺点
- 复制延时,发送缓存
- 由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
- master挂了,slave不会自动重新连接其他,需要人工干预
Redis哨兵
本机sentinel.conf位置地方:
shell
/etc/redis
# 全局查找命令----> 查找文件所在地方
sudo find / -name "sentinel.conf"- 哨兵是什么?
- 哨兵巡查后台主机master主机是否出现了故障,如果出现了,则从slave中投票产生一个新的主机,并且通知其他slave
- 作用
- 监控redis的状态,包括master和slave
- 当master挂机的时候,选举出一个新的slave
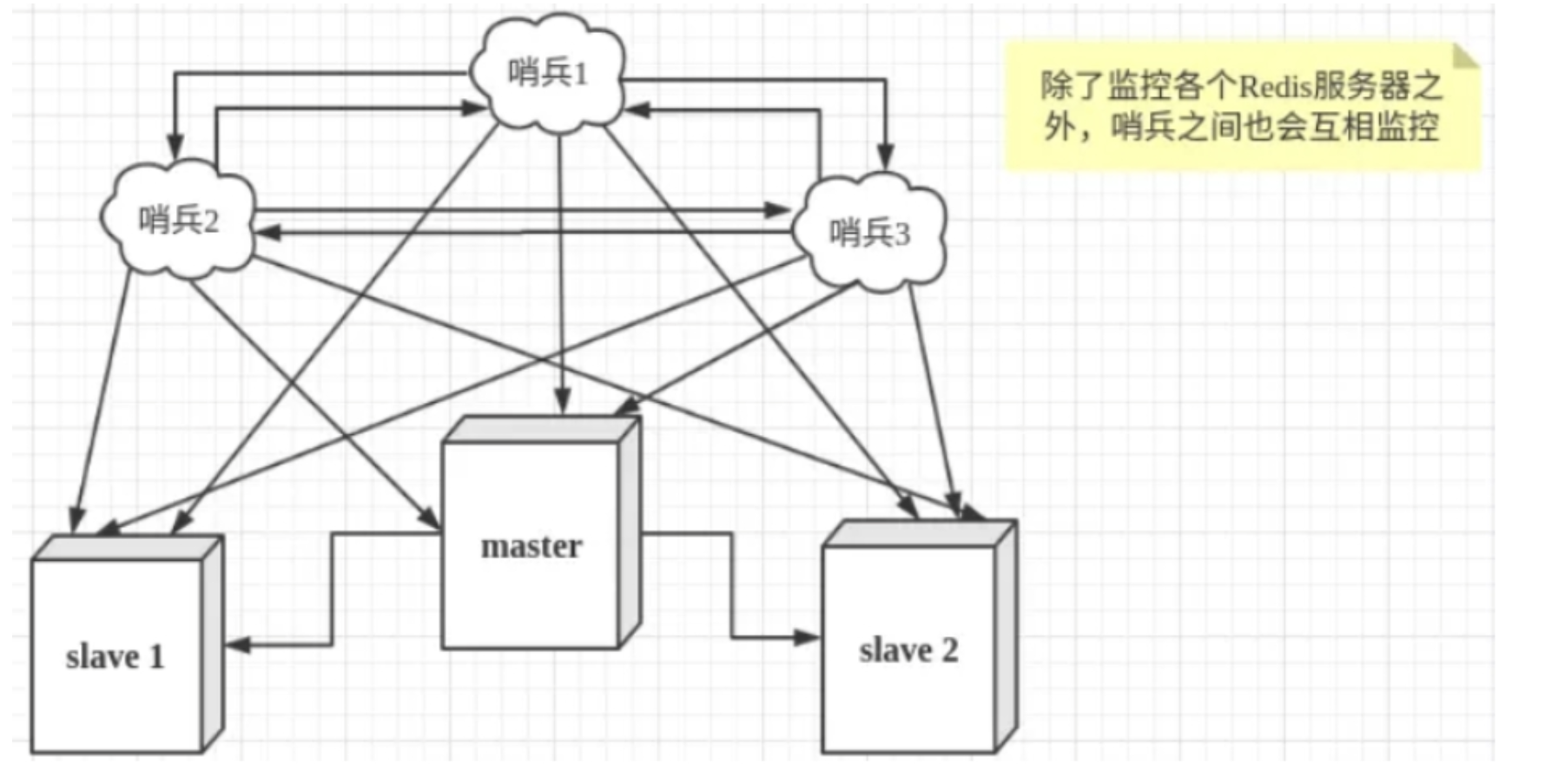
哨兵的主要任务
- 主从监控
- 监控主从redis是否运行正常
- 消息通知
- 哨兵可以将故障转移等结果发送给客户端
- 故障转移
- 当master发生异常,则会运用raft算法在slave中进行选举一个新的master作为主库,并且给通知其他从库
- 配置中心
- 客户端通过连接哨兵来获取当前Redis服务的主节点地址
哨兵模式的搭建
-
找到配置文件(sentinel.conf),本机的配置文件在/etc/redis下
-
在尚硅谷课堂上演示的是一个主机两个从机,三个集群
-
配置文件文件参数
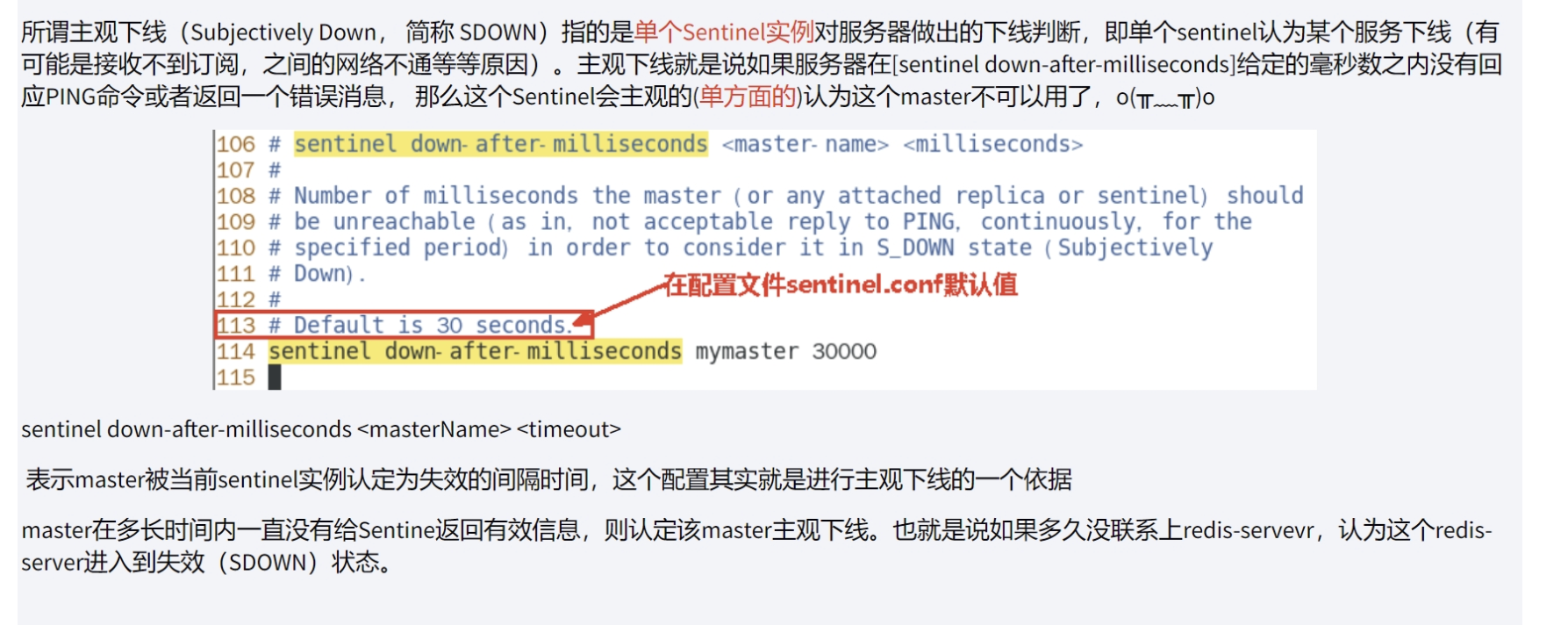
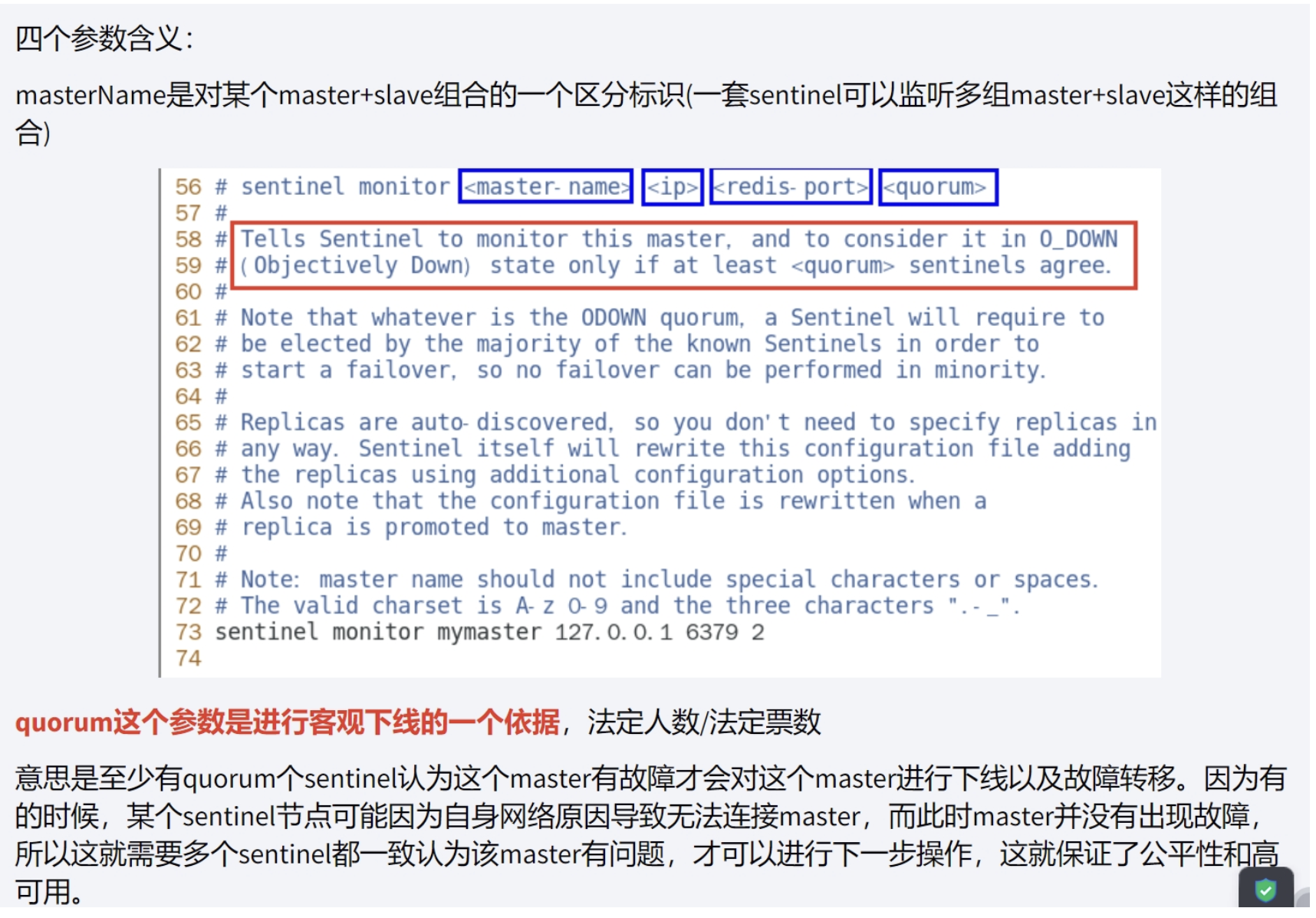
shellbind 服务器监听地址,用于客户端连接,默认为本机地址"127.0.0.1" daemonize 是否以后台daemon方式运行 protected-mode 安全模式 port 端口 logfile 目录文件路径 pidfile pid文件路径 dir 工作目录 sentinel monitor <master-name> <ip> <redis-port> <quorum> 设置要监听的master服务器数量,quorum表示最少有几个哨兵认可 ** 客观下线** , 统一故障迁移的法定票数 sentinel auth-pass <master-name> <password> master设置了密码,连接master服务的密码 -
启动顺序
- 先启动主从服务器 ,在启动哨兵
如果途中master挂了?
- 从机数据是否还存在 ?
- 还存在
- 是否会从剩下的从机中选取新的master?
- 会
- 选取出新的master后,如果这个时候之前挂的master又恢复了,谁会是新的老大呢?
- 新选出来的,之前的master变成slave了(哨兵会帮我们制动修改配置文件)
哨兵运行流程
-
以尚硅谷课程为例
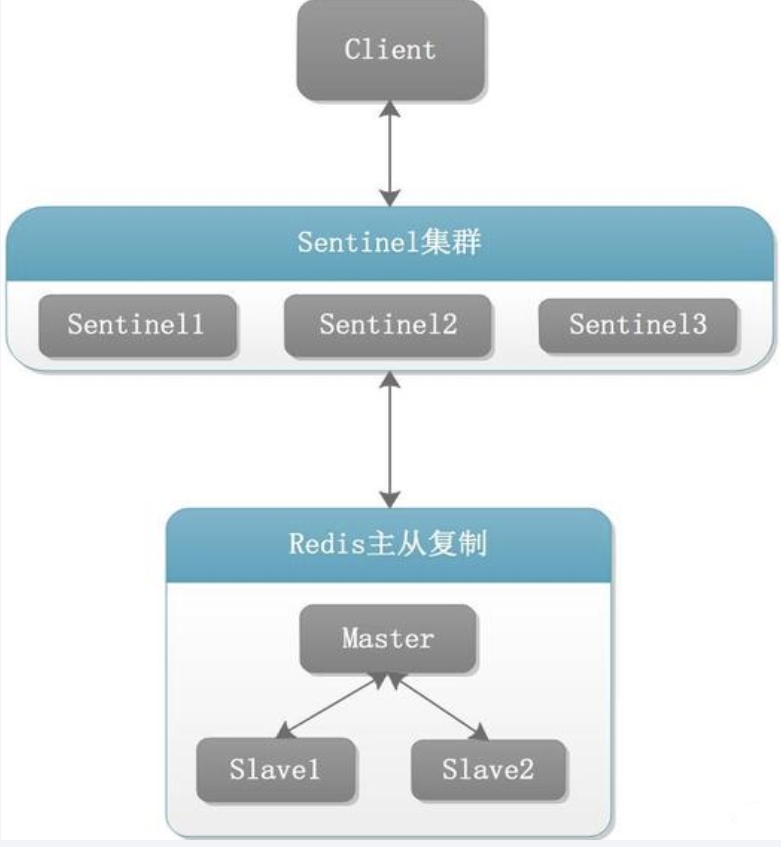
当一个主从配置中的master失效之后,sentinel可以选举出一个新的master,用于接替原master的工作,主从配置中其他redis服务器自动指向新的master同步数据。一般建议sentinel采用奇数台,防止某一台sentinel无法连接到master导致误切换。
主观下线(Subjectively Down)
客观下线(Obejctively Down)
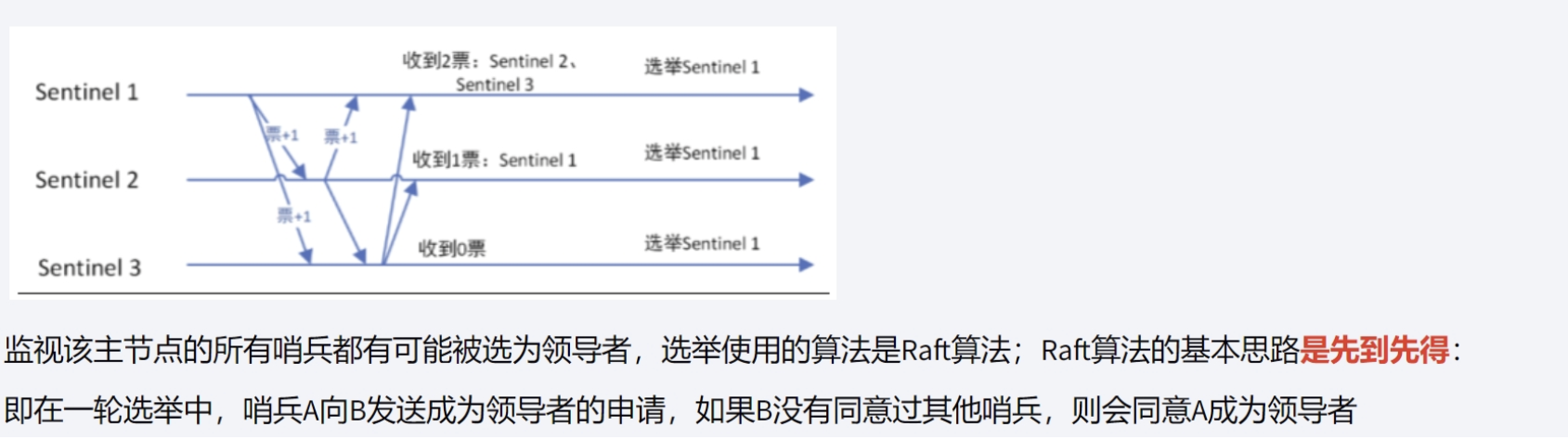
哨兵选举(基于Raft算法)
选取主节点第一步,先在哨兵中选leader
- 判断客观下线的sentinel节点向其他 sentinel 节点发送 SENTINEL is-master-down-by-addr ip port current_epoch runid (这时的runid是自己的run id,每个sentinel节点都有一个自己运行时id)
- 目标sentinel回复是否同意master下线并选举领头sentinel,选择领头sentinel的过程符合先到先得的原则。举例:sentinel1判断了 客观下线,向sentinel2发送了第一步中的命令,sentinel2回复了sentinel1,说选你为领头,这时候sentinel3也向sentinel2发送第一步的命令,sentinel2会直接拒绝回复
- 当sentinel发现选自己的节点个数超过**majority(N/2向上取整)**的个数的时候,自己就是领头节点
- 如果没有一个sentinel达到了majority的数量,等一段时间,重新选举
故障转移
由新的leader选举出新的master
- 新主登基
- 某一个slave成为新的master
- 群臣俯首
- slave重新认老大
- 旧主拜访
- 老的master回来也成为slave
消息通知
新的master节点选择出来之后,还需要做一些事情配置的修改,如下:
1、领头sentinel会对选出来的从节点执行**slaveof no one **命令让其成为主节点
2、领头sentinel 向别的slave发送slaveof命令,告诉他们新的master是谁谁谁,你们向这个master复制数据
3、如果之前的master重新上线时,领头sentinel同样会给起发送slaveof命令,将其变成从节点
使用建议
- 哨兵节点的数量应为多个,哨兵本身应该集群,保证高可用
- 哨兵节点的数量应该是奇数个
- 各个哨兵节点的配置应该一致
- 如果哨兵节点部署在Docker等容器里,要注意端口的正确映射
- 注意: 哨兵集群+主从复制,并不能保证数据零丢失