摘要
蛋白质功能注释是理解生物学机制、设计治疗药物及推进生物医学研究的基础。当前计算方法要么依赖浅层序列相似性,要么将功能预测视为孤立的分类任务,无法实现领域生物学家在推断功能时所进行的、跨越序列、结构、结构域和相互作用的整合推理。本研究推出首款用于蛋白质功能预测的多模态推理大语言模型(LLM)BioReason-Pro,该模型整合蛋白质嵌入与生物语境,生成结构化推理轨迹。BioReason-Pro的核心输入之一是由GO-GPT(本研究构建的自回归转换器,可捕捉GO术语的层级关系与跨维度依赖)生成的GO术语预测结果。通过在13万余种蛋白质的合成推理轨迹上进行监督微调,并经强化学习进一步优化,BioReason-Pro的GO术语预测Fmax值达73.6%,功能摘要的LLM评估得分为8/10,显著优于现有方法。人类蛋白质专家评估显示,在79%的案例中,BioReason-Pro的注释优于UniProt基准注释。值得注意的是,BioReason-Pro能够从头预测经实验验证的结合伴侣,其残基级注意力可精准定位这些复合物冷冻电镜结构中的精确接触残基。综上,GO-GPT与BioReason-Pro共同建立了蛋白质功能预测框架,将精准的本体建模与可解释的生物推理相结合。
#蛋白质功能预测 #多模态推理 #大语言模型 #基因本体 #知识图谱 #检索增强生成 #生物序列分析
结果
构建蛋白质功能预测的生物-语言多模态模型
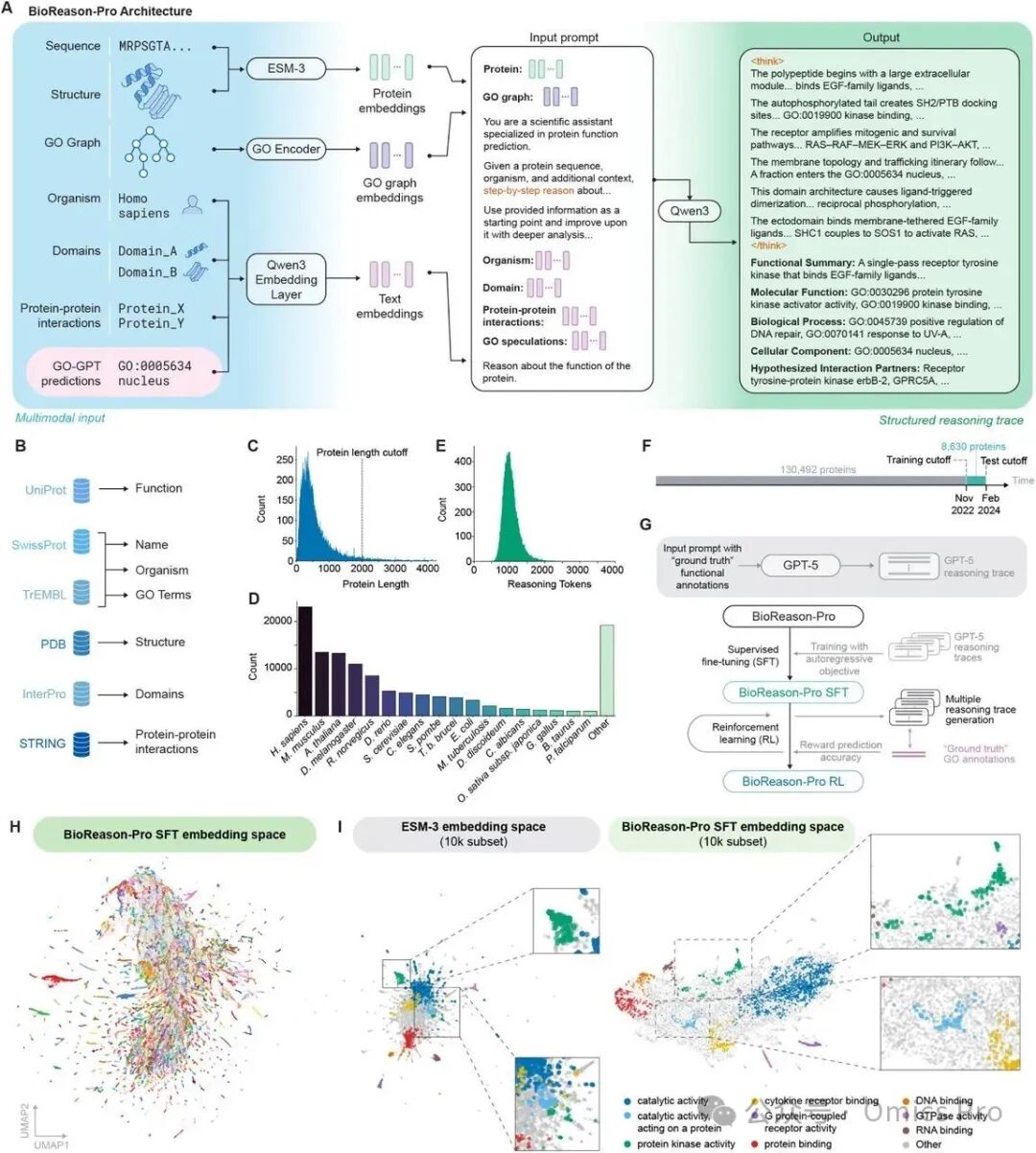
图1 BioReason-Pro用于蛋白质功能预测的概述
(A) BioReason-Pro架构:1种多模态推理大语言模型,整合ESM3蛋白质嵌入、GO图编码器和生物语境,生成结构化推理轨迹和功能注释。
(B) 数据集概述:从UniProt筛选的133,492个蛋白质(涵盖3135个物种),含实验GO注释、InterPro结构域、STRING蛋白质-蛋白质相互作用及PDB蛋白质结构。
(C) 蛋白质长度分布:数据集中蛋白质序列长度分布,截断阈值为2000个残基。
(D) 物种分布:训练数据集的分类多样性。
(E) 推理轨迹分布:训练蛋白质的合成推理轨迹的令牌长度分布。
(F) 时间分割:训练数据截至2022年11月,测试数据为2023年3月至2024年2月。
(G) 训练流程:在GPT-5生成的推理轨迹上进行监督微调,随后以GO术语预测准确性为奖励进行强化学习。
(H) 学习到的嵌入空间:所有训练蛋白质的BioReason-Pro SFT LLM第35层嵌入的UMAP投影,颜色由PCA降维空间中计算的HDBSCAN聚类决定。
(I) 嵌入空间比较:1万个蛋白质子集的ESM3(左)和BioReason-Pro SFT(右)嵌入的UMAP投影。聚类分配源自BioReason-Pro嵌入并应用于2个面板,每个聚类标注其最富集的GO分子功能术语。
GO-GPT提升GO术语预测性能并捕捉生物学意义结构
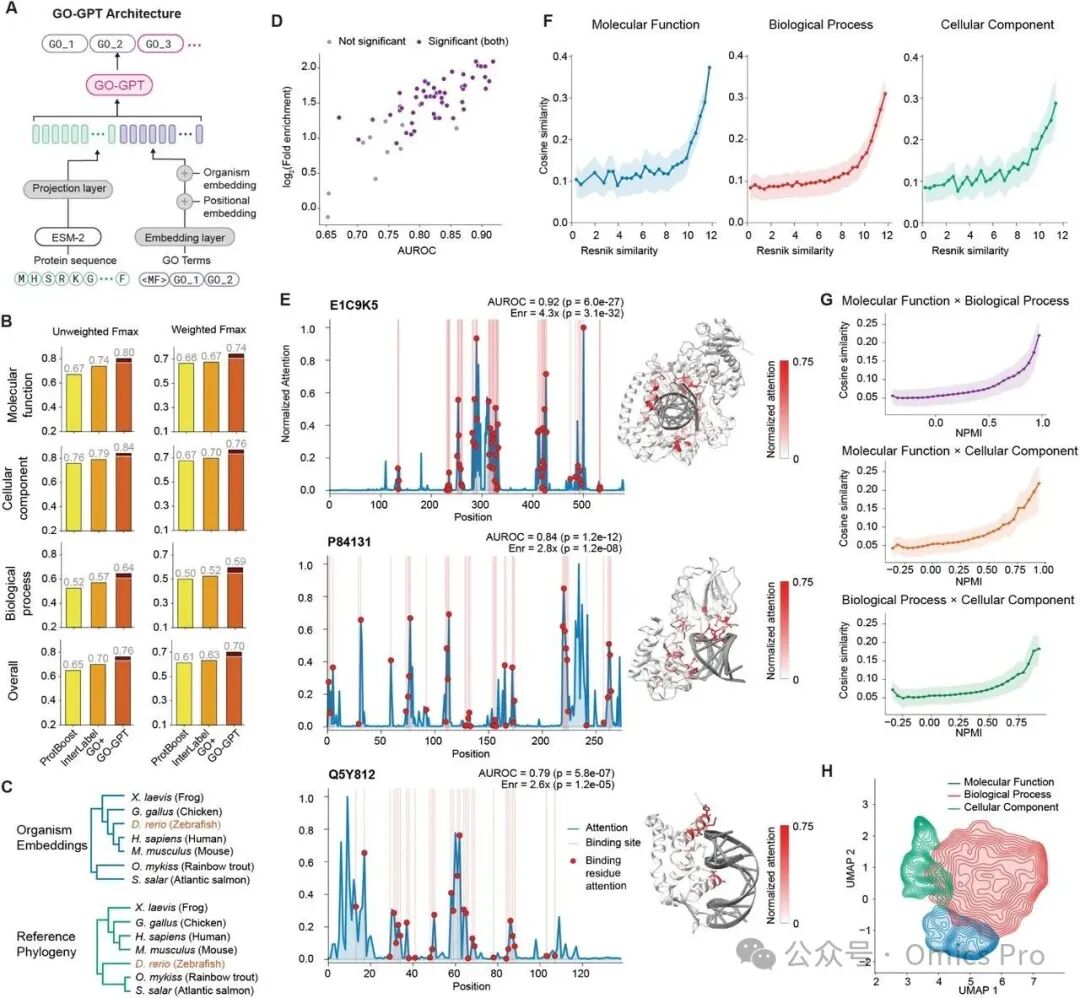
图2 GO-GPT的架构、性能及可解释性分析
(A) GO-GPT架构:自回归转换器通过ESM2编码蛋白质序列,在物种和先前生成术语的条件下生成GO术语。
(B) GO术语预测性能:所有维度的加权和未加权Fmax(深色阴影:10次最优上限;除GO-GPT贪心解码与InterLabelGO+在加权MF上的差异外,所有成对差异均显著,p=0.073)。
(C) 物种嵌入系统发育树:基于学习到的物种嵌入的余弦相似性构建的树状图(上)与参考系统发育树(下)对比。学习到的树重现了已知的系统发育关系,斑马鱼(红色高亮)是唯一错位的物种。
(D) 结合残基注意力富集:63个非训练集BioLiP蛋白质(GO-GPT预测GO:0003677(DNA结合))的AUROC与log2(富集倍数)关系图。紫色:在Mann-Whitney U检验和超几何检验中均显著(p<0.05);灰色:至少在1项检验中不显著。
(E) DNA结合注意力分析:3种蛋白质(E1C9K5、P84131、Q5Y812)预测GO:0003677时的残基级注意力。左:注意力分布图(结合位点阴影标注);右:高注意力残基(红色)的蛋白质-DNA结构。
(F) Resnik相似性与余弦相似性:在所有维度上,余弦嵌入相似性随Resnik语义相似性单调递增(所有p<10−3,Mantel置换检验)。
(G) 跨维度NPMI与余弦相似性:跨维度GO术语对的共注释NPMI与嵌入相似性相关(Spearman ρ=0.10−0.17,p<10−3,置换检验)。
(H) GO术语嵌入图谱:UMAP投影及各维度的核密度估计轮廓(MF蓝色、BP红色、CC绿色),显示维度级空间组织。
表1 前缀因果注意力掩码模式
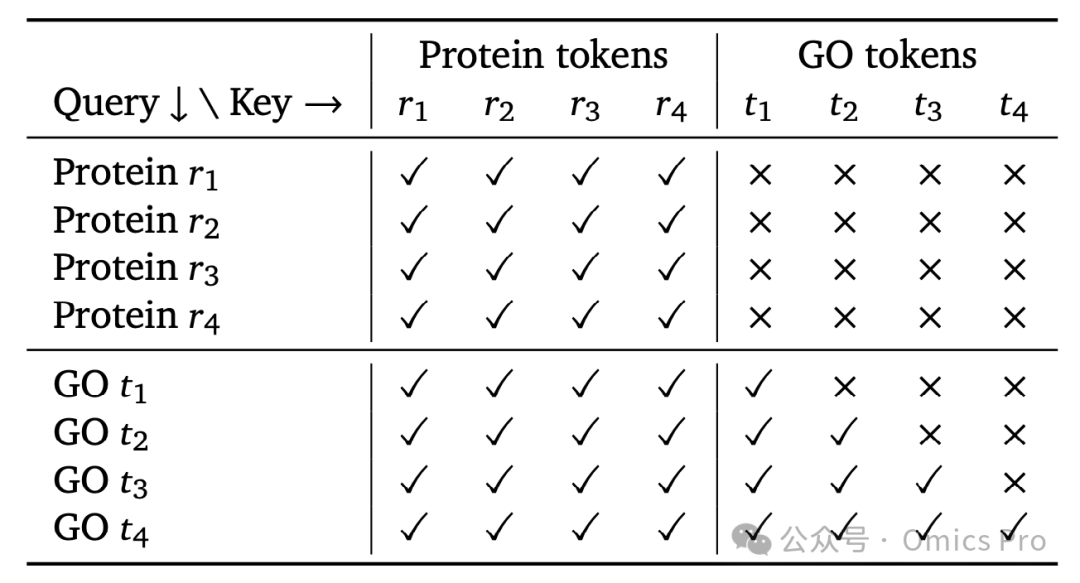
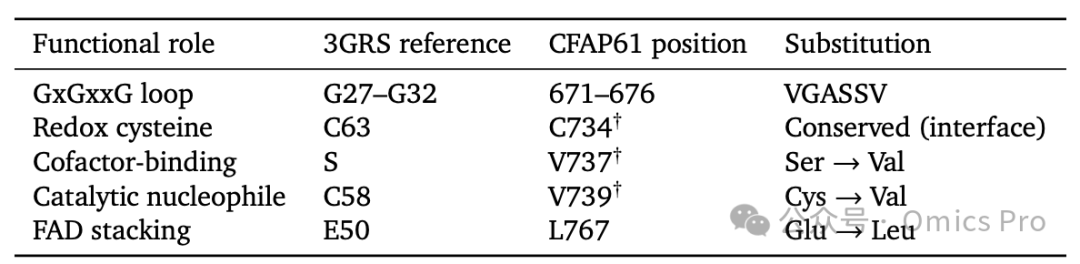
表2 通过拓扑引导比对,将谷胱甘肽还原酶(PDB 3GRS)的催化位点和辅因子结合位点映射至CFAP61的Rossmann结构域
BioReason-Pro展现蛋白质功能的通用专家级推理能力
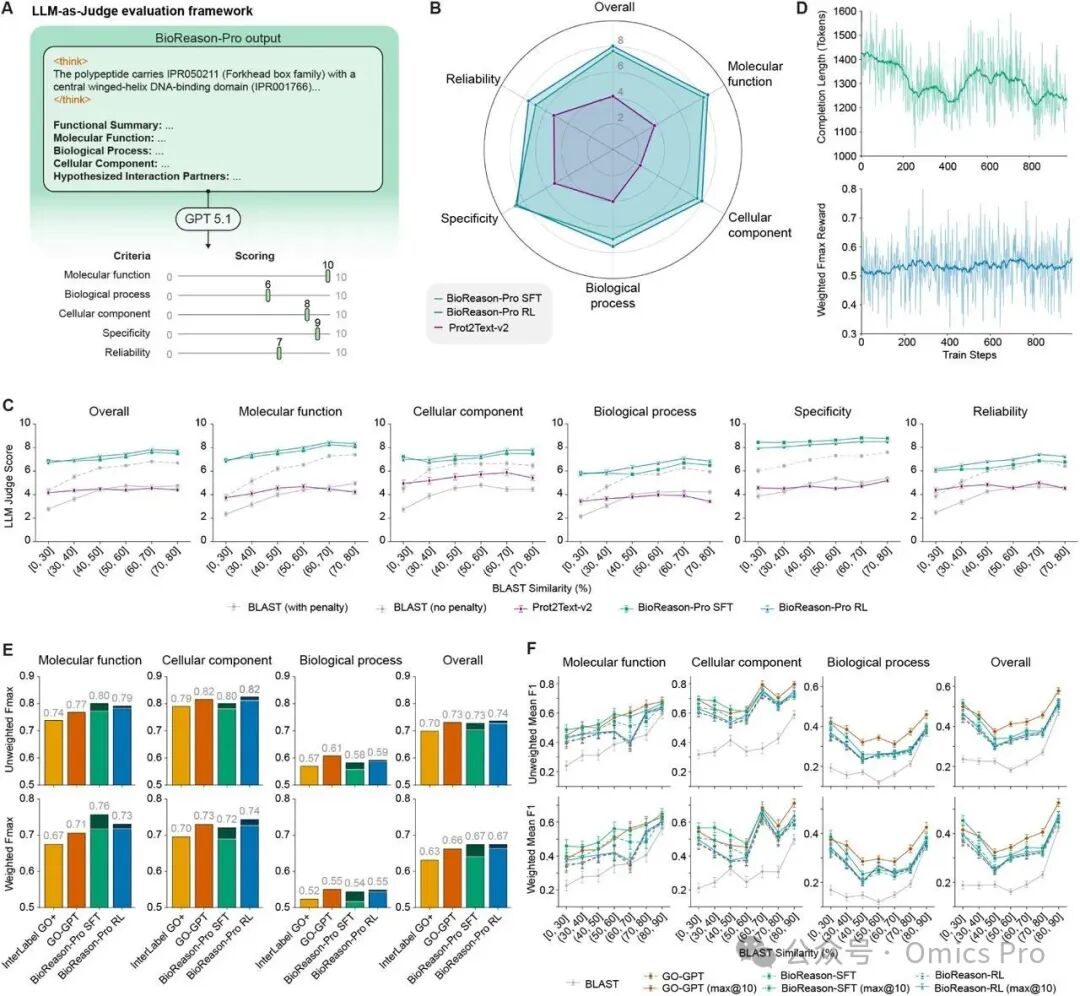
图3 BioReason-Pro在蛋白质功能预测中的评估结果
(A) LLM作为评估者的框架:GPT-5.1对照由UniProt摘要、GO术语、InterPro结构域、已知蛋白质-蛋白质相互作用伴侣、物种和亚细胞定位组成的复合基准真值,对模型预测进行评估。每个预测在五个维度上以 1-10 分评分:分子功能、生物过程、细胞组分、特异性和可靠性。
(B) LLM作为评估者的评分:雷达图比较BioReason-Pro RL、BioReason-Pro SFT和Prot2Text-v2的各维度得分。BioReason-Pro RL的平均得分为8.03 分,SFT为7.65分,Prot2Text-v2为4.15分。
(C) 不同序列相似性下的LLM评估得分:BioReason-Pro SFT、BioReason-Pro RL、Prot2Text-v2和BLAST基准模型(带惩罚和无惩罚)在5个评估维度及总体上的LLM评估得分(按BLAST相似性分组)。
(D) 强化学习动态:GSPO训练步骤中的完成长度(令牌数,上)和Fmaxw奖励(下)。奖励增加而生成长度减少,表明推理更具针对性。
(E) GO术语预测性能:InterLabelGO+、GO-GPT、BioReason-Pro SFT和BioReason-Pro RL在分子功能、细胞组分、生物过程及总体上的加权和未加权Fmax(深色阴影表示10次最优选择上限)。
(F) 不同序列相似性下的GO术语预测泛化性:GO-GPT、BioReason-Pro SFT、BioReason-Pro RL和BLAST在各BLAST相似性分组中的蛋白质平均F1得分(未加权,上;加权,下),每个生成模型均显示10次最优选择变体。
人类专家偏好BioReason-Pro而非基准注释
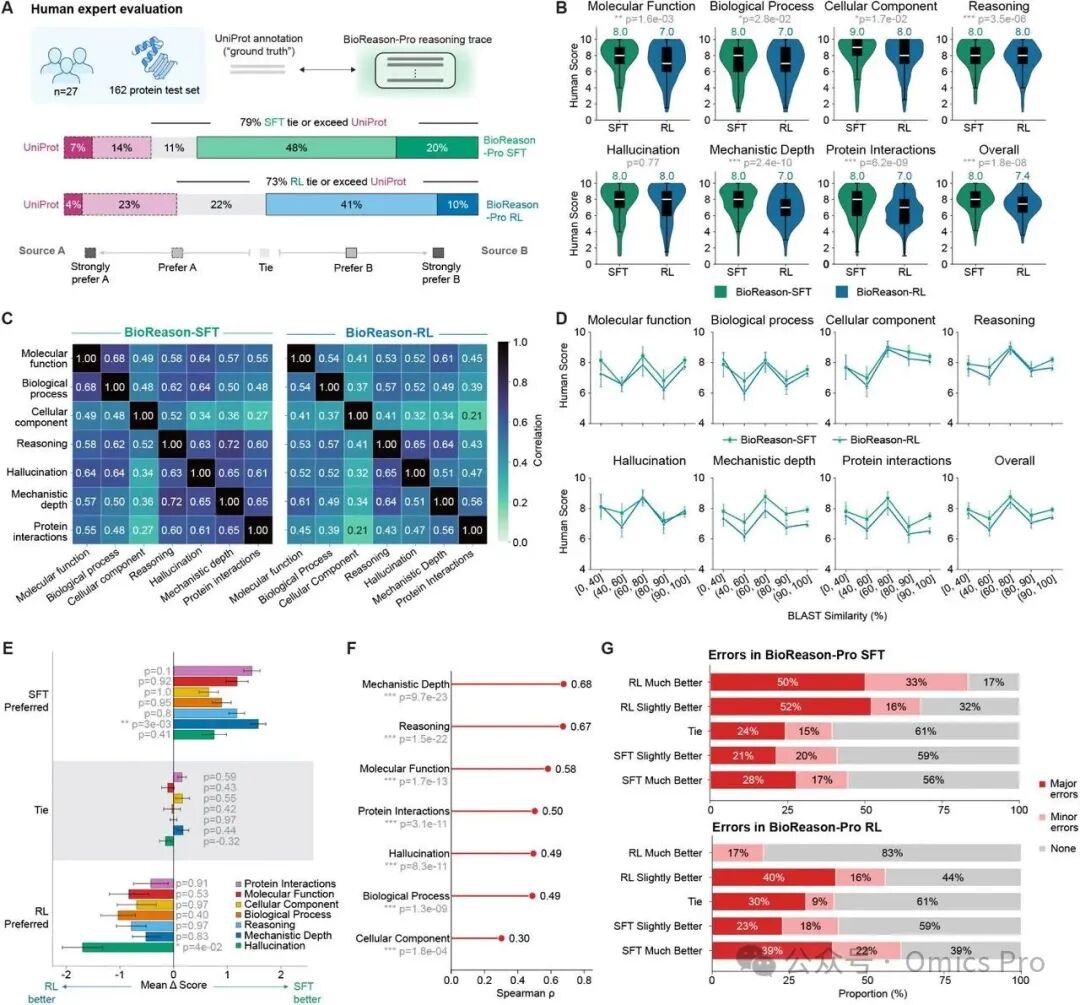
图4 BioReason-Pro预测结果的人类专家评估
(A) 成对偏好比较:27位蛋白质专家在5点偏好量表上对比BioReason-Pro SFT和RL预测与UniProt基准真值。79%的案例中SFT与UniProt持平或更优,RL为73%。
(B) 各维度得分分布:BioReason-Pro SFT和RL在分子功能、生物过程、细胞组分、推理、幻觉、机制深度、蛋白质相互作用及总体上的专家评分小提琴图,标注中位数得分。
(C) 评估维度的相关结构:SFT和RL的7个评估维度之间的成对相关性,表明推理、机制深度和幻觉形成反映整体生物推理质量的相关集群。
(D) 不同序列相似性下的人类评估:BioReason-Pro SFT和RL在所有7个评估维度及总体上的专家评分(按BLAST序列相似性分组),显示性能稳定,低相似性下无退化。
(E) 按偏好分组的得分差异:按专家偏好分层的各维度得分差异(SFT-RL)。SFT的优势源于机制深度(p=3×10−3),而 RL 的优势源于更少的幻觉(p=4×10−2)。
(F) 驱动专家偏好的维度:各维度得分差异与专家偏好的Spearman相关性,确定机制深度和推理是驱动偏好决策的主要维度。
(G) 按专家偏好的错误归因:每个模型中主要错误、次要错误或无错误的比例(由GPT-5-mini根据自由文本响应分类),按专家成对偏好分层。
BioReason-Pro生成经实验结构验证的从头预测
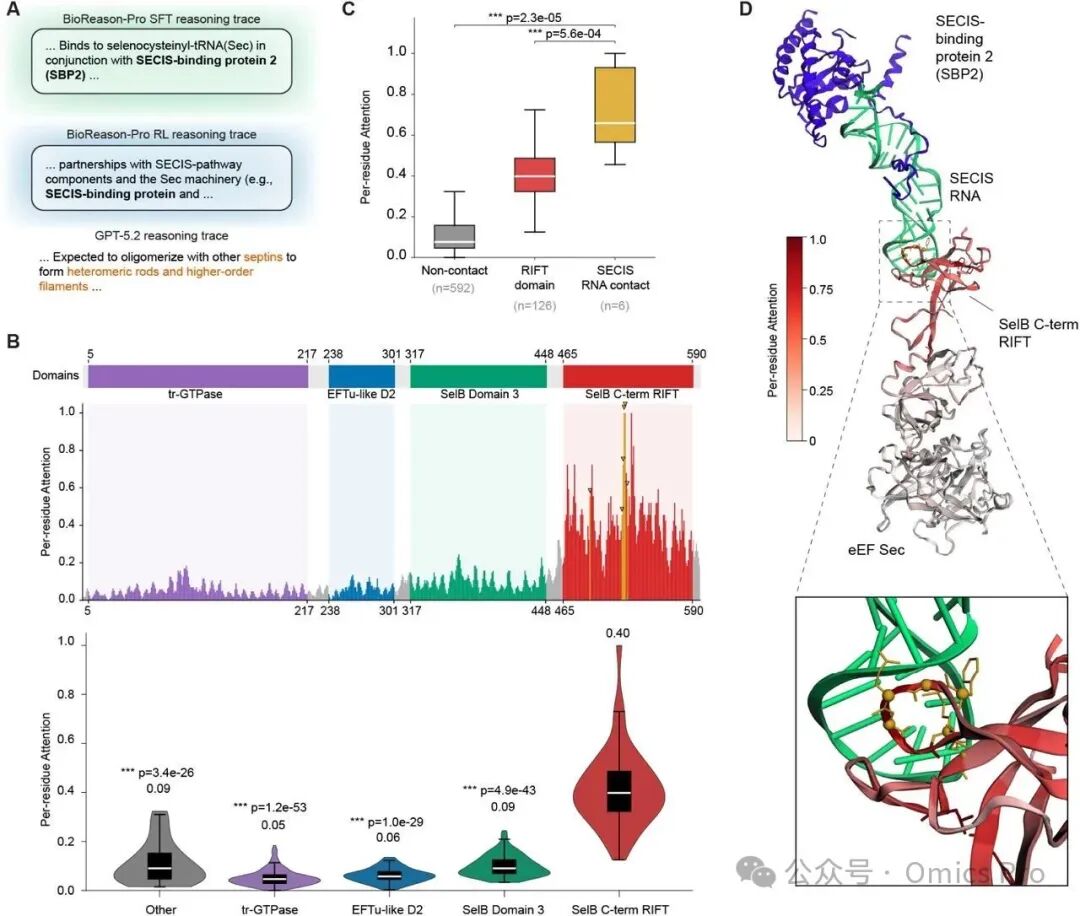
图5 硒代半胱氨酸特异性延伸因子eEFSec(P57772)相关分析
(A) 推理轨迹比较:BioReason-Pro SFT、BioReason-Pro RL和GPT-5.2 Thinking High生成的关键段落。BioReason-Pro SFT从头预测SBP2为必需伴侣(高亮标注),而GPT-5.2将该蛋白质误识别为隔膜家族 GTP 酶。
(B) 结构域架构和残基级注意力:上:区分经典 EF-Tu 机制(结构域1-2)与硒代半胱氨酸特异性元件(结构域3-4)的结构域架构;中:预测伴侣名称前的令牌对序列的残基级注意力映射,黄色条标记SECIS RNA接触残基(PDB 7ZJW中≤5.0 Å);下:各结构域注意力分布的小提琴图,C端RIFT结构域的注意力显著高于其他所有结构域(Mann-Whitney U检验)。
(C) 接触界面富集:非接触残基、RIFT结构域残基和SECIS RNA接触残基的残基级注意力得分比较(Mann-Whitney U 检验,p=2.3×10−5,PDB 7ZJW)。
(D) 结构语境:冷冻电镜硒代体结构(PDB 7ZJW),eEFSec按残基级注意力着色(白色至红色),显示最高注意力位于与SECIS RNA结合界面重叠的RIFT结构域表面。从头预测的伴侣SBP2(紫色)和SECIS RNA(绿色)标注。插图:RIFT结构域接触界面的放大视图。
BioReason-Pro实现超越结构域注释转移的结构推理
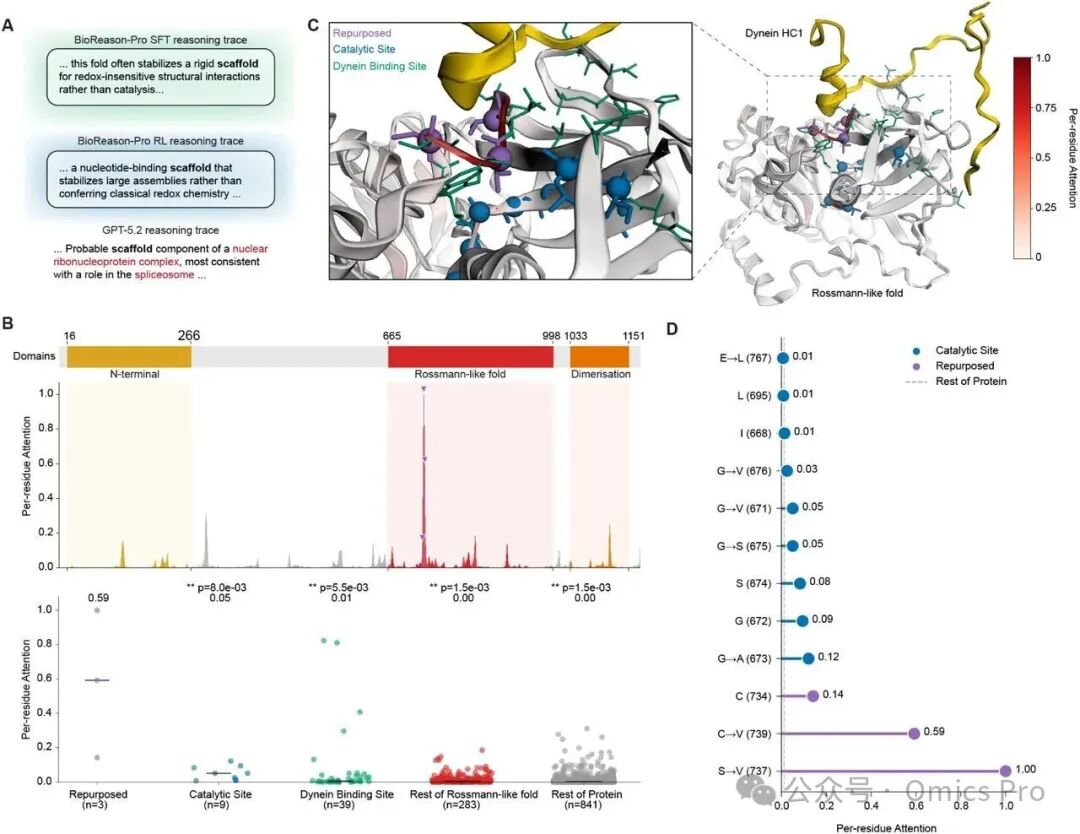
图6 CFAP61(Q8NHU2)------具有再利用活性位点的非酶促轴丝支架蛋白相关分析
(A) 推理轨迹比较:BioReason-Pro SFT、BioReason-Pro RL和GPT-5.2 Thinking High生成的关键段落,正确推断以绿色高亮,错误推断以红色高亮。BioReason-Pro正确识别非酶促支架功能,而GPT-5.2将该蛋白质误识别为核剪接体相关 HEAT 重复蛋白。
(B) 结构域架构和注意力富集:上:标注边界的结构域架构;中:预测非酶促支架功能前的令牌对序列的残基级注意力映射,紫色三角形标记3个再利用残基(C734、V737、V739);下:再利用活性位点残基、其余催化位点残基、动力蛋白结合位点残基、Rossmann结构域其余部分及蛋白质其余部分的残基级注意力比较(相邻类别间Mann-Whitney U检验)。
(C) 结构语境:冷冻电镜轴丝结构(PDB 8J07)的Rossmann结构域双视图。左:近距离视图,再利用残基(紫色)、退化催化位点(蓝色)和动力蛋白重链 1 结合界面(黄色)以球体显示;右:更广泛的结构语境,残基级注意力投影至分子表面(白色至红色),显示最高注意力集中在3个再利用残基。标注动力蛋白重链1。
(D) 催化位点的残基级注意力:按注意力大小排序的各个催化(蓝色)和再利用(紫色)位点的注意力得分,虚线表示蛋白质其余部分的平均注意力作为基准参考。
数据
训练和评估模型的所有数据集
代码
网页
训练与评估代码仓库
含人类蛋白质图谱在内的24万余种蛋白质的BioReason-Pro功能预测结果
GO-GPT
BioReason-Pro SFT
BioReason-Pro RL
详细总结
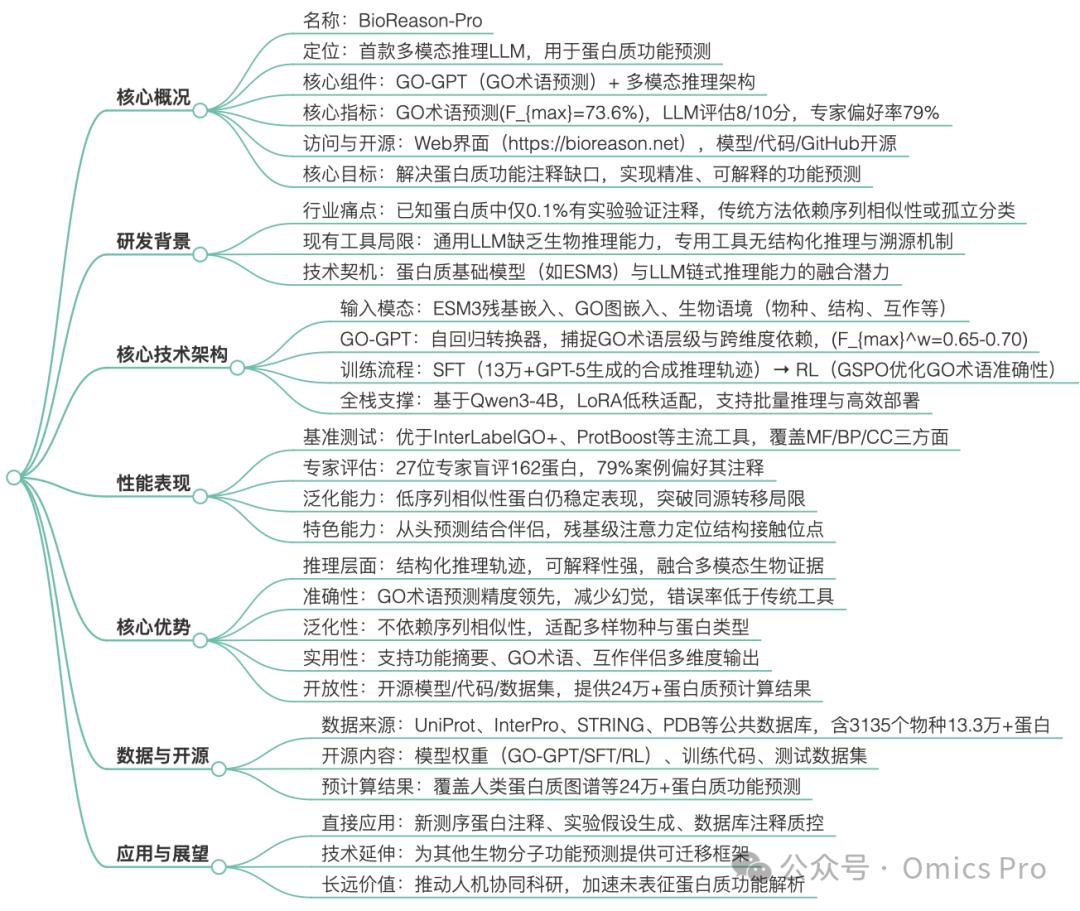
思维导图(mindmap)
BioReason-Pro的技术架构以「多模态输入-结构化推理-精准输出」为核心,搭配GO-GPT作为前置术语预测模块,形成完整技术链:

数据资源与开源详情

参考
BioReason-Pro: Advancing Protein Function Prediction with Multimodal Biological Reasoning
doi: https://doi.org/10.64898/2026.03.19.712954
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。