博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
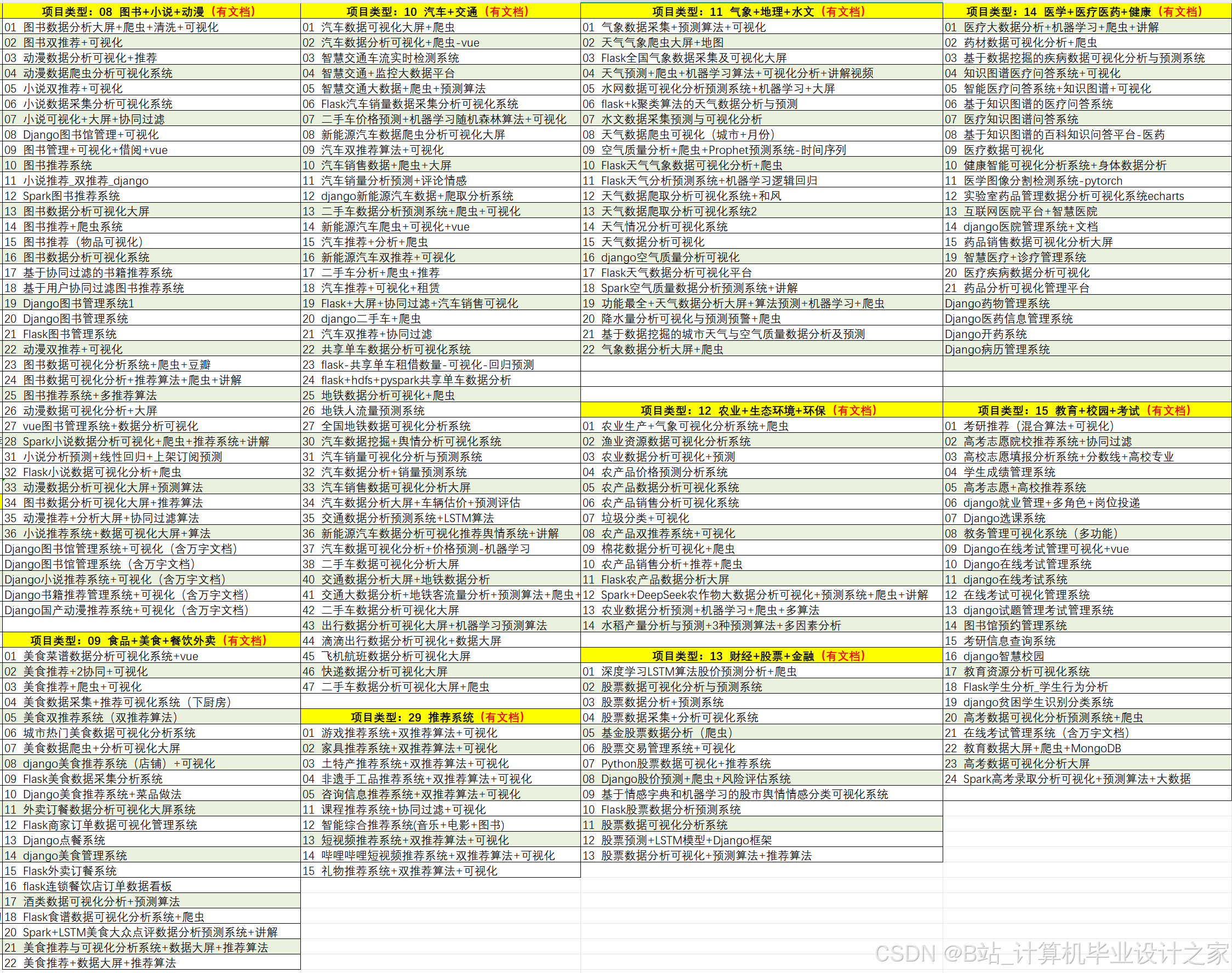
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
python、flask、mysql、echarts、requests、html、高德地图、数据分析
功能模块
地铁线路数量分布
各线路站点数量分布
最爱用门命名的城市
地铁站最爱用的字排行
站点数量分布
各城市分布地图
大学数量与站点数量的关系
各城市各站点数量
地图名词云图分析
地铁数据分布
登录界面
数据采集
项目介绍
本项目是地铁数据可视化分析系统,依托python爬虫完成各城市地铁线路、站点及关联数据的采集与清洗,将数据存入mysql数据库,通过flask框架搭建后端服务实现数据交互,运用pandas完成文本挖掘与相关性分析,结合echarts和高德地图实现多形式可视化展示,系统包含登录验证、数据采集、多维度统计分析等完整功能,可直观呈现地铁网络分布、命名特征及数据关联规律,支持数据动态更新,为地铁相关分析提供全面的可视化支撑。
2、项目界面
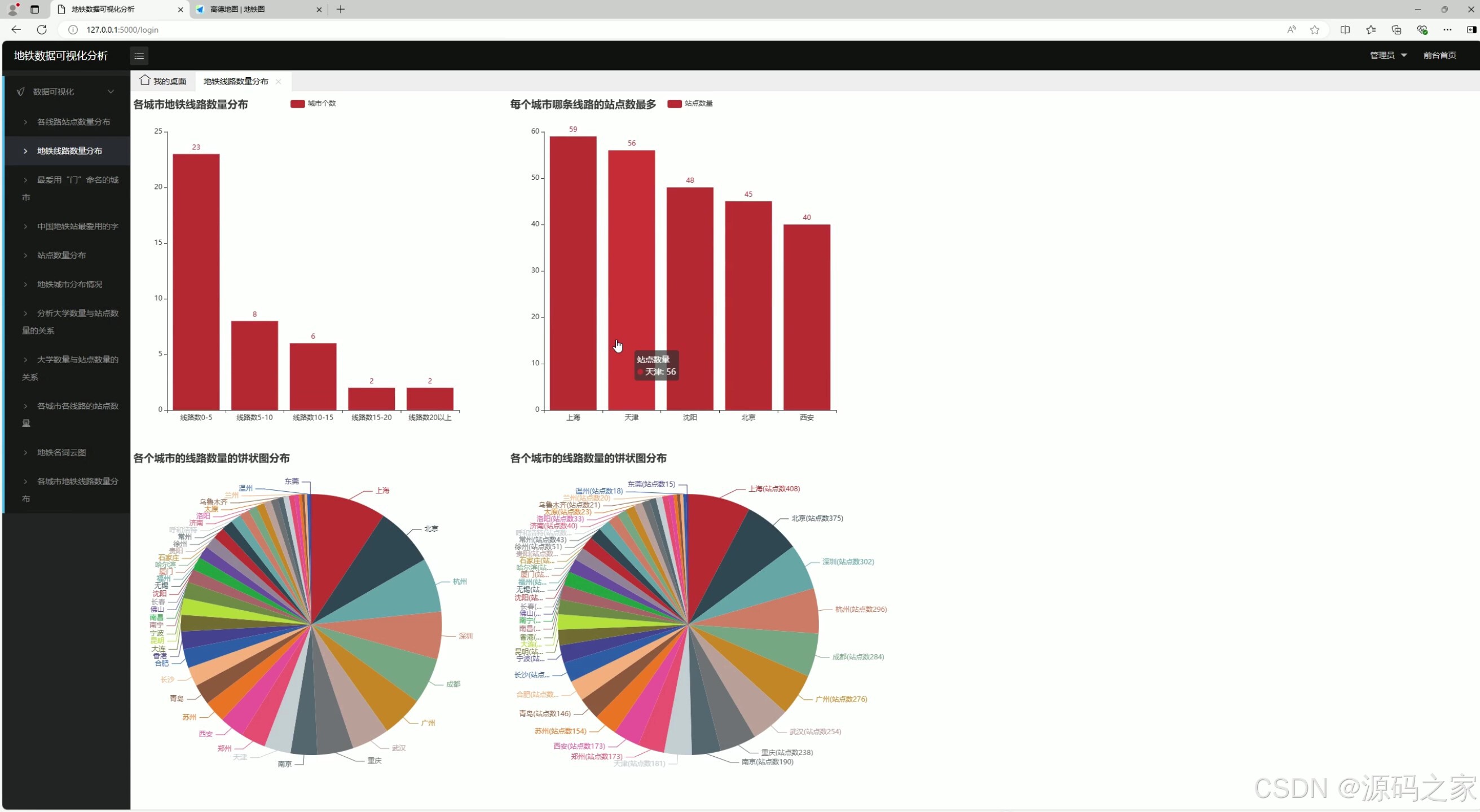
1 、地铁线路数量分布
该页面为地铁数据可视化分析系统的地铁线路数量分布模块,集成了各城市地铁线路数量分布柱状图、各城市站点数最多线路柱状图、各城市线路数量饼状图及对应站点数饼状图,用于直观展示地铁线路与站点相关数据的分布情况。
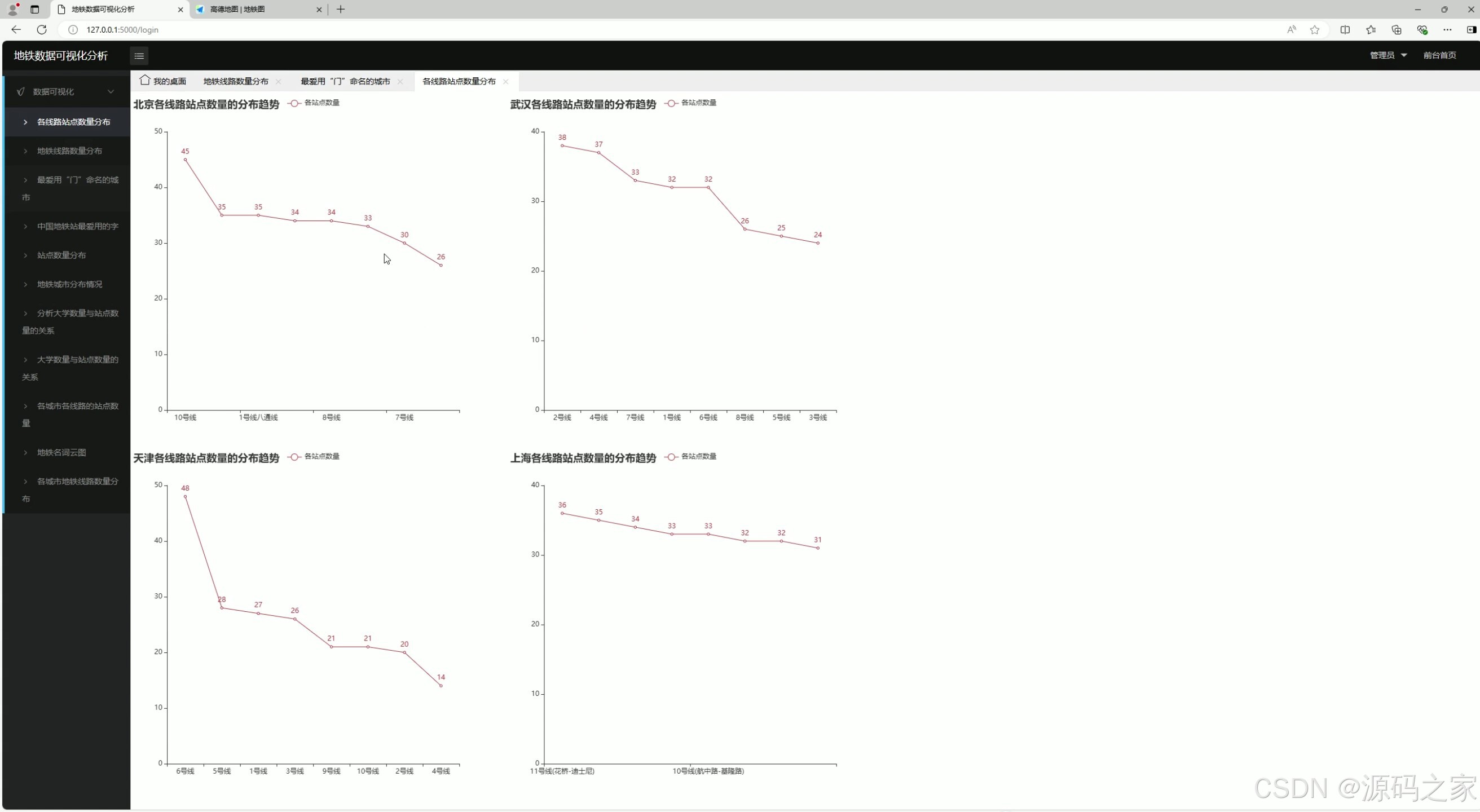
2、各线路站点数量分布
该页面为地铁数据可视化分析系统的各线路站点数量分布模块,通过折线图分别展示北京、武汉、天津、上海等城市各条地铁线路的站点数量分布趋势,直观呈现不同城市各线路的站点规模差异与分布特征。
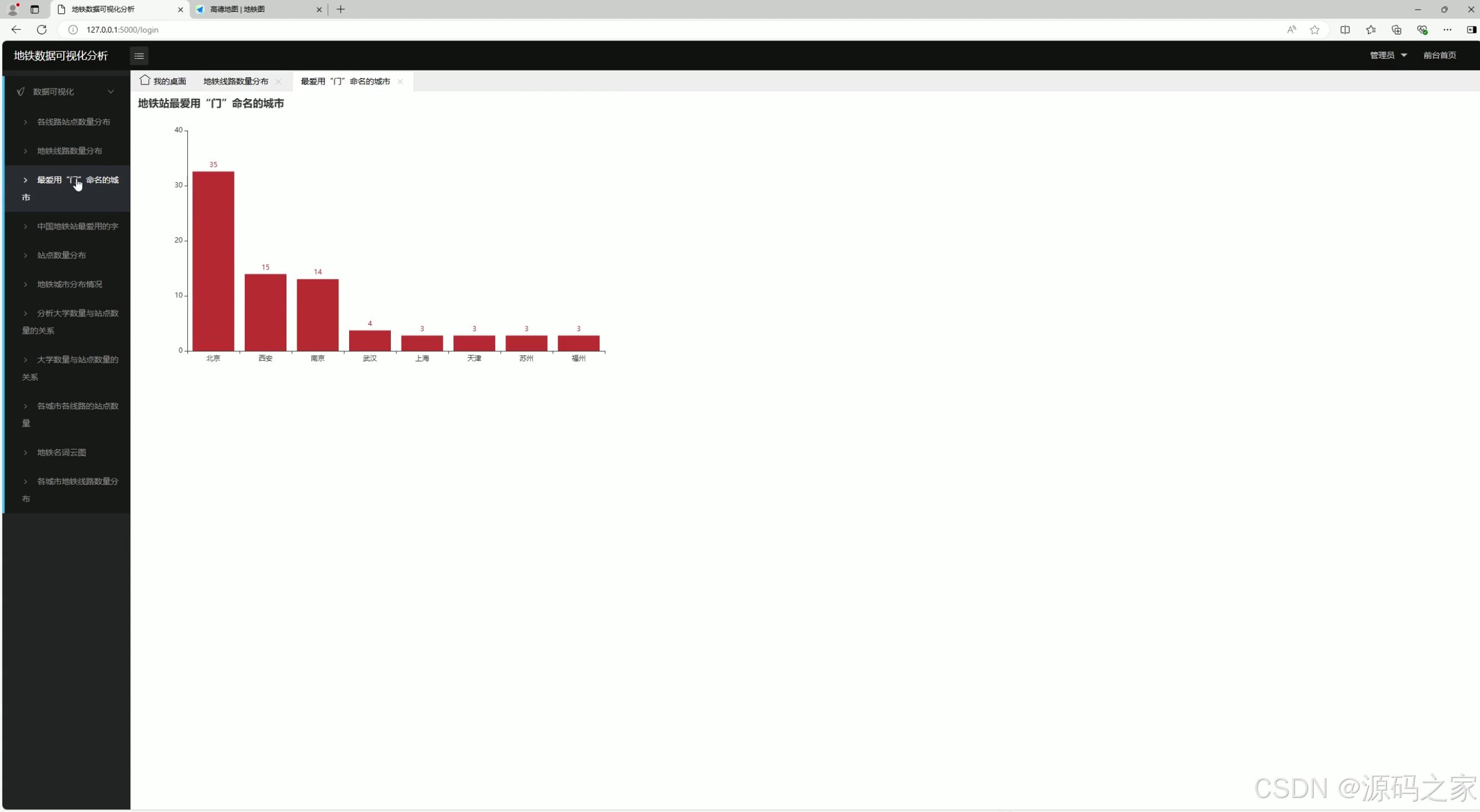
3、最爱用【门】命名的城市
该页面属于地铁数据可视化分析系统中地铁站名命名特征分析模块,以柱状图呈现各城市地铁站使用"门"字命名的数量情况,清晰对比不同城市在地铁站命名用字上的偏好与数量差异。
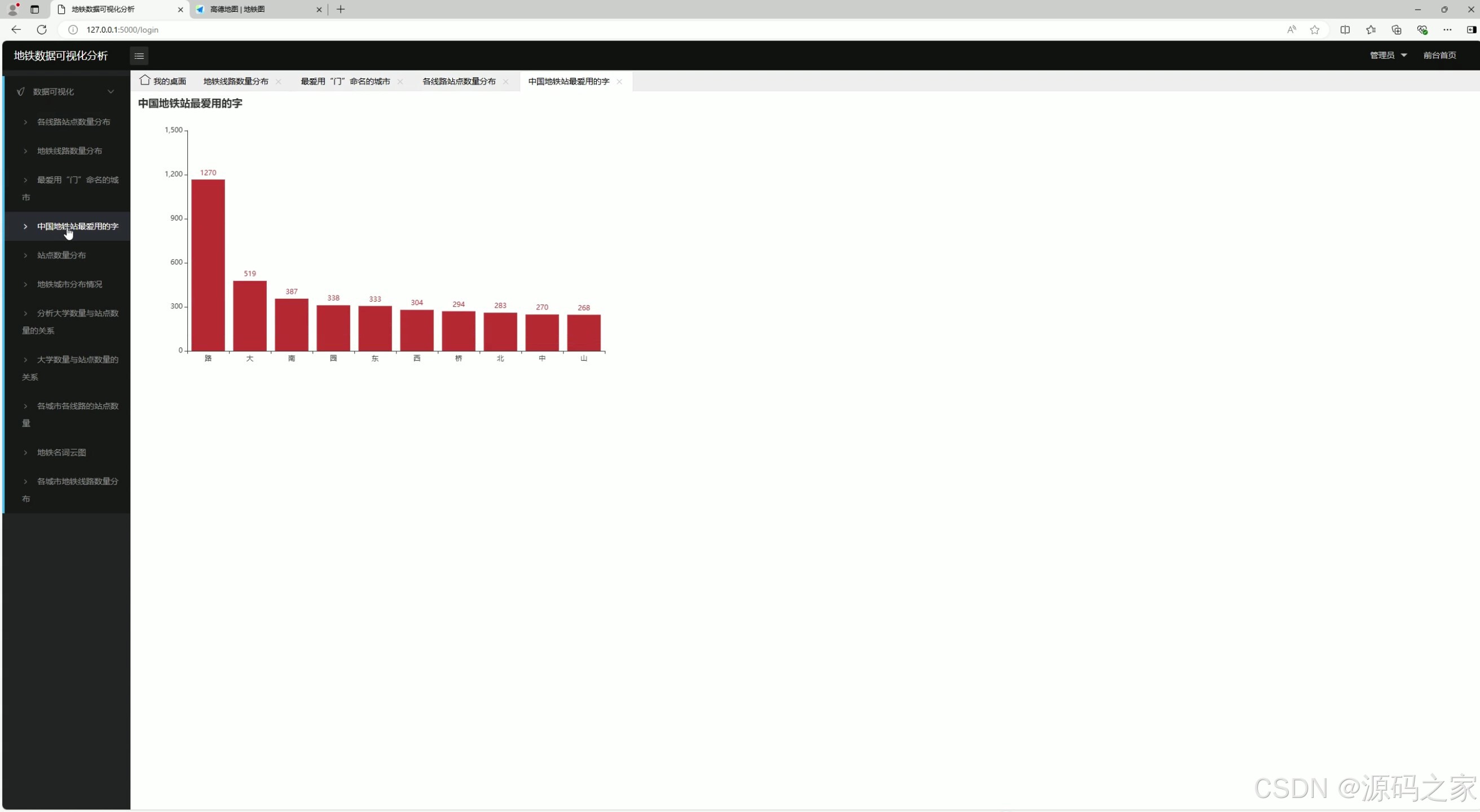
4、地铁站最爱用的字排行
该页面属于地铁数据可视化分析系统的地铁站名用字分析模块,通过柱状图统计并展示中国地铁站名中使用频率最高的汉字,直观呈现地铁站命名的用字偏好与高频用字分布情况。
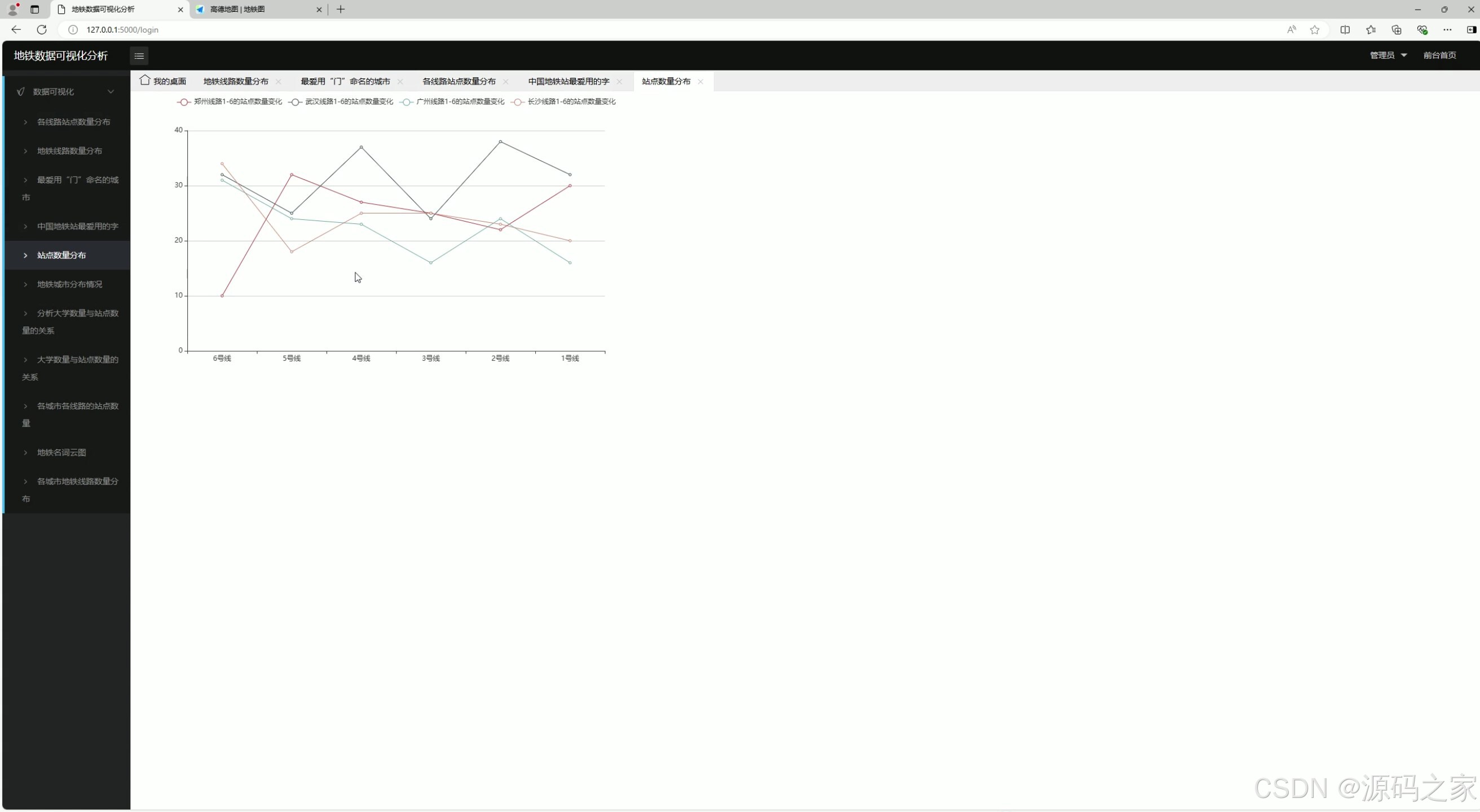
5、站点数量分布
该页面为地铁数据可视化分析系统的站点数量分布模块,通过多组折线图分别展示不同城市各条地铁线路的站点数量变化趋势,直观对比各城市不同线路的站点规模差异与分布特征。
6、各城市分布地图
该页面属于地铁数据可视化分析系统的地铁城市分布情况模块,通过中国地图结合热力标注的形式,直观展示国内地铁开通城市的地理分布与相关规模情况,清晰呈现地铁网络的地域覆盖特征。
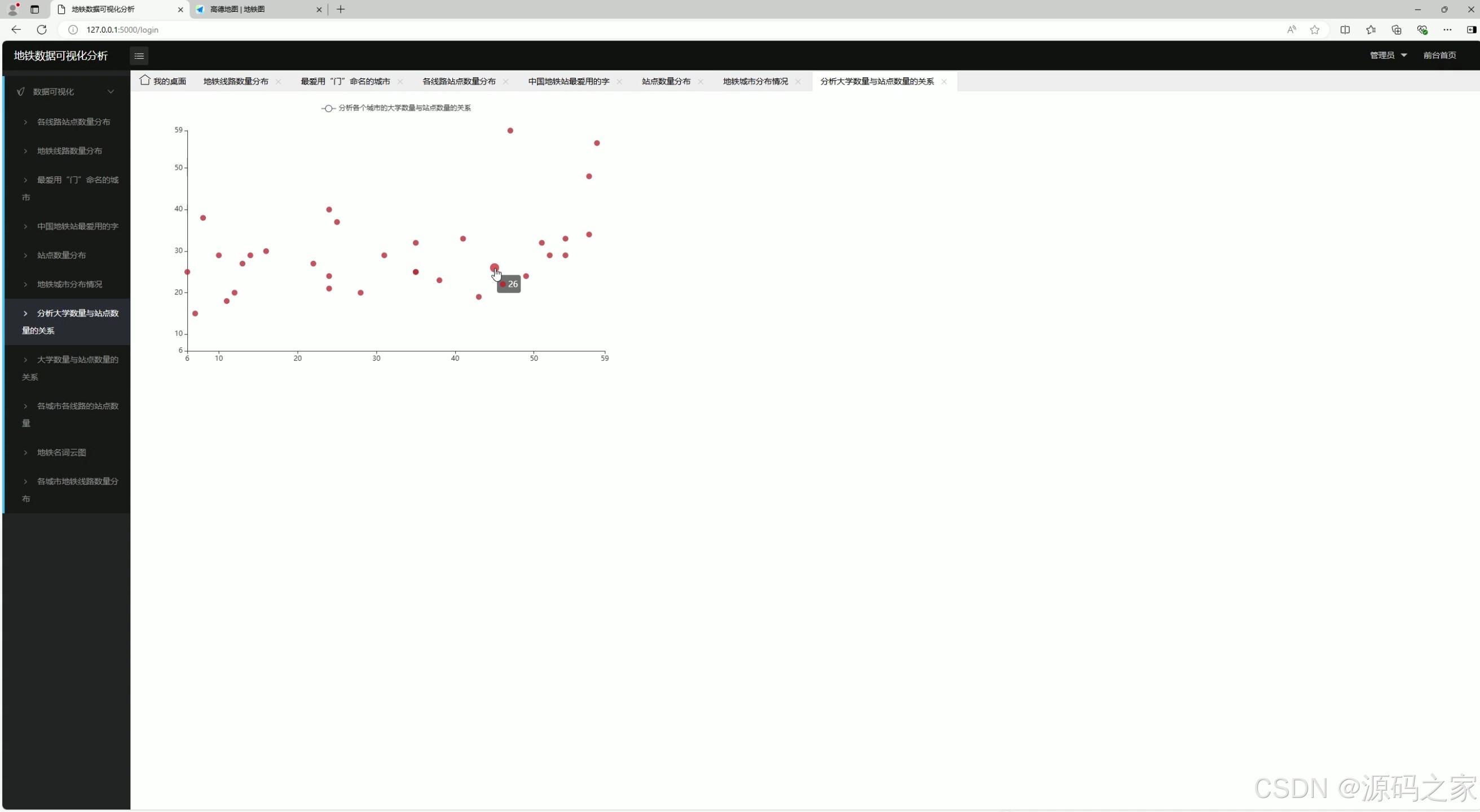
7、大学数量与站点数量的关系
该页面属于地铁数据可视化分析系统的分析大学数量与站点数量的关系模块,通过散点图呈现各城市大学数量与地铁站点数量的对应分布情况,直观展示两者之间的关联趋势与数据特征。
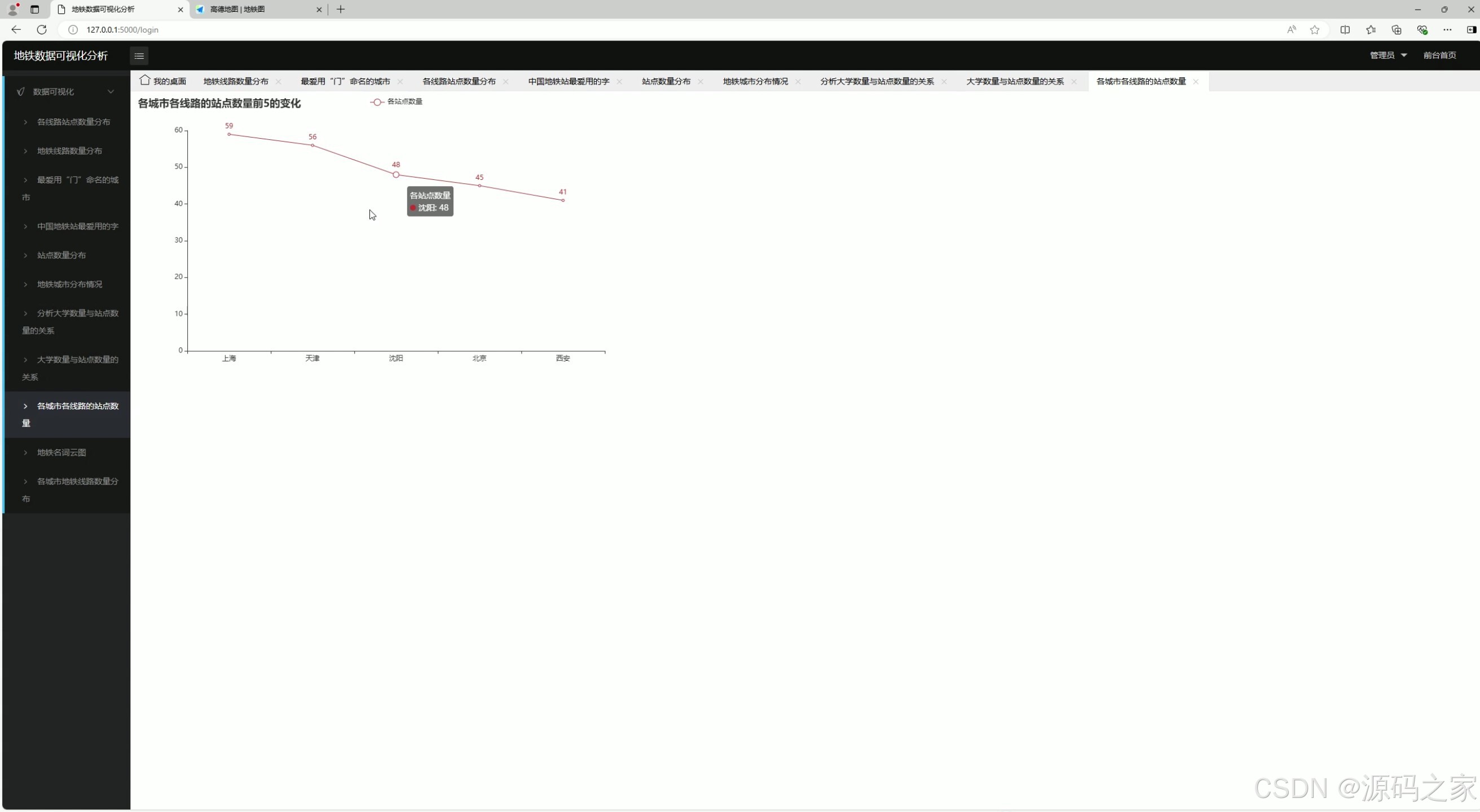
8、各城市各站点数量
该页面属于地铁数据可视化分析系统的各城市各线路站点数量模块,通过折线图展示不同城市各线路站点数量排名前五的变化情况,直观呈现各城市地铁线路站点规模的差异与分布特征。
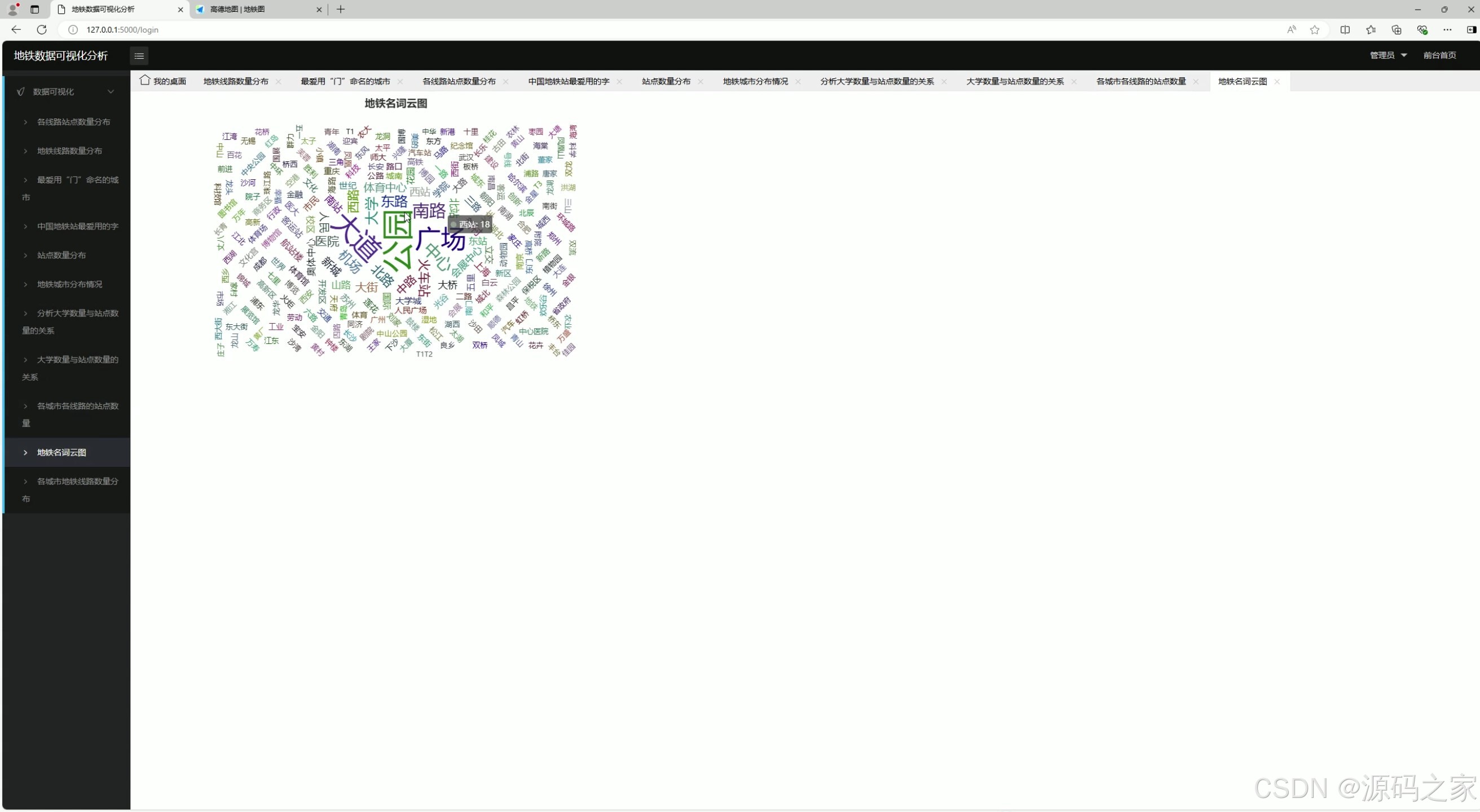
9、地图名词云图分析
该页面属于地铁数据可视化分析系统的地铁名词云图模块,通过词云图直观展示全国地铁站名中高频出现的词汇,呈现地铁站命名的词汇特征与使用频率分布,清晰体现地铁站名的用词规律。
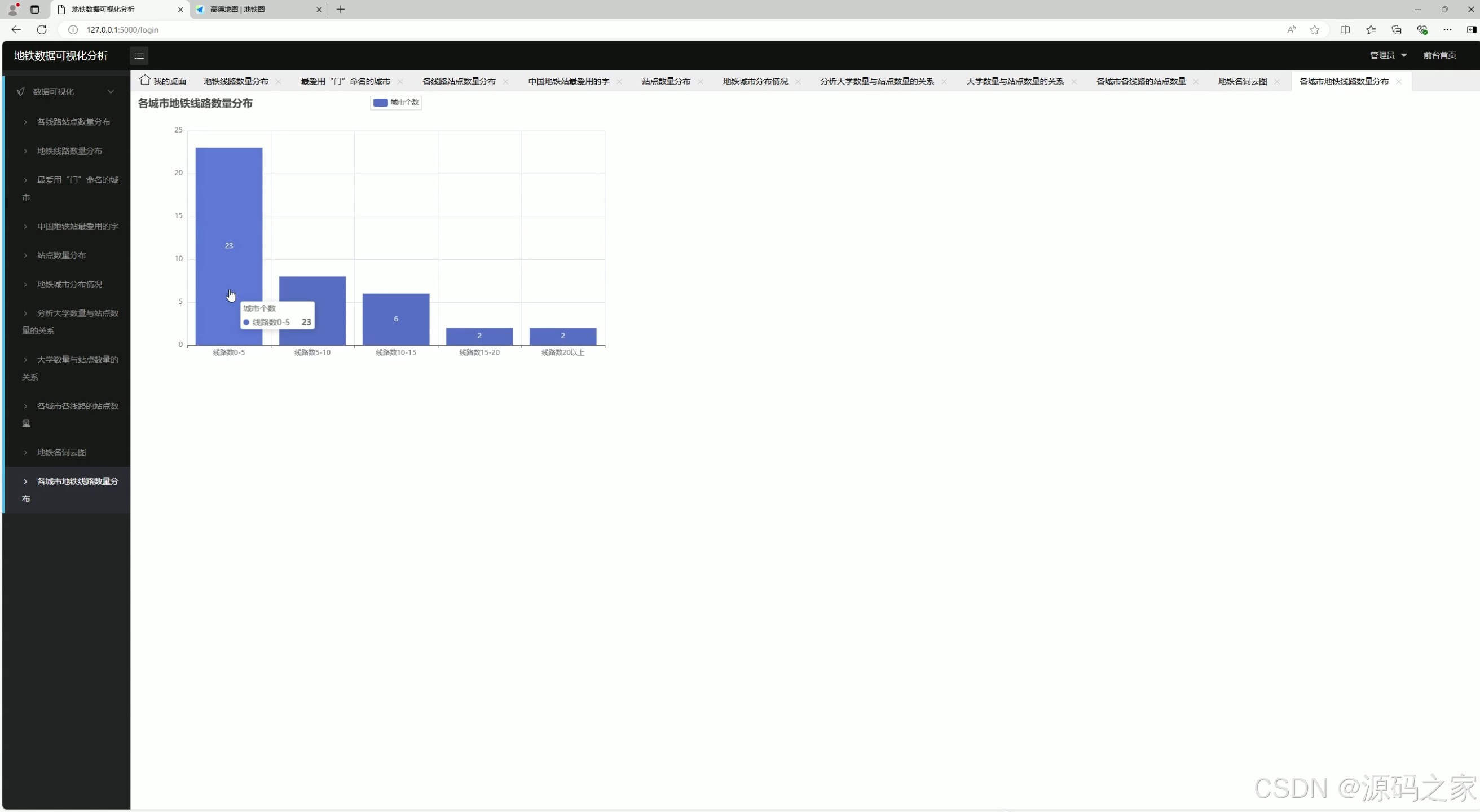
10、地铁数据分布
该页面属于地铁数据可视化分析系统的各城市地铁线路数量分布模块,通过柱状图按线路数量区间统计对应城市的数量,直观呈现不同地铁线路规模的城市分布情况,清晰展示国内地铁线路数量的城市层级与分布特征。
11、登录界面
该页面是地铁数据可视化分析系统的登录界面,以地铁列车实景为背景,设置账号输入、密码输入及登录按钮,用于验证用户身份,通过身份校验后即可进入系统,访问各类地铁数据可视化分析功能模块。

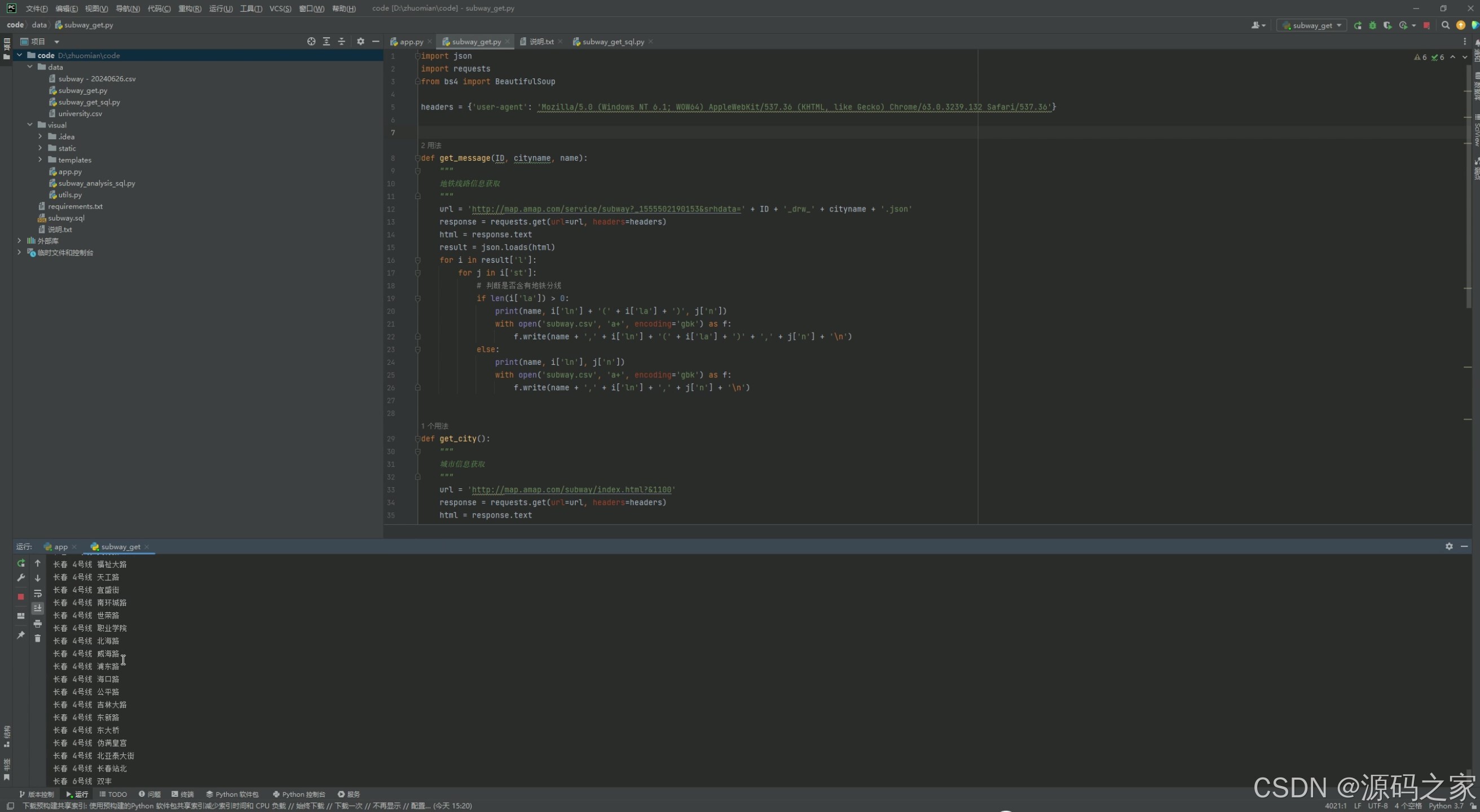
12、数据采集
该页面是地铁数据可视化分析系统的后端数据爬取代码界面,通过Python编写网络请求与解析代码,调用接口获取全国各城市地铁线路及站点信息,将爬取到的地铁数据清洗整理后写入文件,为前端可视化分析提供基础数据支撑。
3、项目说明
一、技术栈简要说明
本项目采用Python作为核心编程语言,结合Flask轻量级框架构建后端服务,实现数据接口与业务逻辑处理。前端采用HTML、ECharts、高德地图API进行可视化图表与地图渲染。数据存储使用MySQL数据库,数据采集借助Requests库完成网络请求与解析,数据分析与文本挖掘运用Pandas库进行清洗、统计及关联性分析。整体技术栈覆盖数据采集、清洗、存储、分析到可视化展示的全流程。
二、各功能模块详细介绍
-
地铁线路数量分布
该模块通过柱状图展示各城市地铁线路数量,通过饼状图展示线路数量占比,同时呈现各城市站点数最多的线路对比。用户可直观了解不同城市地铁网络规模差异,快速识别线路密集城市。
-
各线路站点数量分布
采用多系列折线图分别展示北京、上海、天津、武汉等城市各条地铁线路的站点数量分布趋势。图表清晰呈现不同城市内部各线路的站点规模差异,便于横向对比线路承载力。
-
最爱用"门"命名的城市
该模块聚焦地铁站名命名特征,通过柱状图统计各城市地铁站中包含"门"字的站点数量。直观反映不同城市对"门"字命名的偏好程度,北京等历史古城在此项统计中表现突出。
-
地铁站最爱用的字排行
对全国地铁站名进行汉字频次分析,通过柱状图展示使用频率最高的汉字排行。该模块帮助用户了解地铁站命名的用字规律,如"路""大道""广场"等高频词汇的分布情况。
-
站点数量分布
通过多组折线图展示各城市不同线路的站点数量变化趋势,每条折线代表一个城市内部各线路的站点规模。用户可对比同一城市不同线路的站点数量差异,也可跨城市观察线路设计特点。
-
各城市分布地图
基于高德地图API与热力标注技术,在中国地图上标注所有开通地铁的城市及其相关规模信息。色彩深浅与标记大小反映地铁网络发达程度,直观呈现国内地铁网络的地域覆盖特征与城市层级分布。
-
大学数量与站点数量的关系
采用散点图分析各城市高校数量与地铁站点数量之间的关联性。每个点代表一个城市,横轴为大学数量,纵轴为地铁站点数量,通过点的分布趋势判断两者是否存在正相关关系,为城市交通与教育资源布局研究提供参考。
-
各城市各站点数量
该模块以折线图展示各城市站点数量排名前五的线路情况,突出每个城市规模最大的几条地铁线路。便于用户快速识别各城市的骨干线路及其站点数量规模。
-
地图名词云图分析
将全国地铁站名进行分词处理,生成词云图。词汇字体大小代表出现频率高低,直观呈现地铁站命名中最常用的词汇,如"站""路""中心""大道"等,清晰体现地铁站名的用词规律与地域特色。
-
地铁数据分布
按线路数量区间(如1-3条、4-6条、7-9条、10条以上)对各城市进行分组统计,通过柱状图展示不同规模层级城市的数量分布。该模块清晰呈现国内地铁线路数量的城市层级结构,反映地铁建设的发展阶段。
-
登录界面
系统入口界面,以地铁列车实景为背景,设置账号、密码输入框及登录按钮。用户通过身份验证后方可进入系统,保障数据访问安全性,为不同用户提供个性化的访问权限管理。
-
数据采集
后端爬虫模块,基于Python编写网络请求与解析代码,调用公开API接口获取全国各城市地铁线路、站点及关联信息。爬取完成后进行数据清洗、去重与格式统一,最终存入MySQL数据库,为前端可视化分析提供高质量的基础数据支撑。
三、项目总结
本项目实现了一套完整的地铁数据可视化分析系统,从数据采集、存储、分析到前端展示形成闭环。系统涵盖了地铁线路数量、站点分布、命名特征、地理分布、与大学数量的关联性等多个分析维度,提供了丰富的图表交互体验。通过ECharts与高德地图的融合运用,用户可直观洞察全国地铁网络的发展格局与命名规律。项目具备可扩展性,支持数据动态更新,为城市规划、交通研究及公众出行参考提供了有力的可视化工具。
4、核心代码
python
import json
import requests
from bs4 import BeautifulSoup
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}
def get_message(ID, cityname, name):
"""
地铁线路信息获取
"""
url = 'http://map.amap.com/service/subway?_1555502190153&srhdata=' + ID + '_drw_' + cityname + '.json'
response = requests.get(url=url, headers=headers)
html = response.text
result = json.loads(html)
for i in result['l']:
for j in i['st']:
# 判断是否含有地铁分线
if len(i['la']) > 0:
print(name, i['ln'] + '(' + i['la'] + ')', j['n'])
with open('subway.csv', 'a+', encoding='gbk') as f:
f.write(name + ',' + i['ln'] + '(' + i['la'] + ')' + ',' + j['n'] + '\n')
else:
print(name, i['ln'], j['n'])
with open('subway.csv', 'a+', encoding='gbk') as f:
f.write(name + ',' + i['ln'] + ',' + j['n'] + '\n')
def get_city():
"""
城市信息获取
"""
url = 'http://map.amap.com/subway/index.html?&1100'
response = requests.get(url=url, headers=headers)
html = response.text
# 编码
html = html.encode('ISO-8859-1')
html = html.decode('utf-8')
soup = BeautifulSoup(html, 'lxml')
# 城市列表
res1 = soup.find_all(class_="city-list fl")[0]
res2 = soup.find_all(class_="more-city-list")[0]
for i in res1.find_all('a'):
# 城市ID值
ID = i['id']
# 城市拼音名
cityname = i['cityname']
# 城市名
name = i.get_text()
get_message(ID, cityname, name)
for i in res2.find_all('a'):
# 城市ID值
ID = i['id']
# 城市拼音名
cityname = i['cityname']
# 城市名
name = i.get_text()
get_message(ID, cityname, name)
if __name__ == '__main__':
get_city()5、项目列表



6、项目获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻