作者:来自 Elastic Gustavo Llermaly
学习如何使用 Elastic Workflows 每 30 分钟收集 Kibana 仪表板视图 metrics,并将其索引到 Elasticsearch 中,从而在你自己的数据之上构建自定义分析和可视化。
动手体验 Elasticsearch:深入探索 Elasticsearch Labs 仓库中的示例 notebooks,开始免费云试用,或现在就在本地运行 Elastic。
Kibana 会跟踪每个仪表板被查看的次数,但这些数据并不会在任何内置仪表板中原生展示。在本文中,我们将使用 Elastic Workflows 每 30 分钟自动收集这些数据,并将其索引到 Elasticsearch 中,从而在其基础上构建我们自己的分析。
Elastic Workflows 是 Kibana 内置的自动化引擎,允许你使用简单的 YAML 配置定义多步骤流程。每个 workflow 可以通过定时、事件或作为 Elastic Agent Builder 中的工具触发,每一步都可以调用 Kibana API、查询 Elasticsearch 或转换数据。
我们将以仪表板查看次数为具体示例,但同样的模式适用于任何通过 Kibana saved objects API 暴露的指标。
前提条件
- Elastic Cloud 或自托管集群运行 9.3
- 已启用 Workflows(Advanced settings)
步骤 1:探索原始数据
在构建任何内容之前,先了解我们拥有的数据。Kibana 将大部分配置和元数据存储为 saved objects,位于一个专用的内部索引中。其中一个被这样跟踪的内容是仪表板查看次数,使用一种称为 usage counters 的特殊 saved object 类型。你可以通过 Dev Tools 直接查询它们:
GET kbn:/api/saved_objects/_find?type=usage-counter&filter=usage-counter.attributes.domainId:"dashboard"%20and%20usage-counter.attributes.counterType:"viewed"&per_page=10000响应如下所示:
{
"page": 1,
"per_page": 10000,
"total": 1,
"saved_objects": [
{
"type": "usage-counter",
"id": "dashboard:346f3c64-ebca-484d-9d57-ec600067d596:viewed:server:20260310",
"attributes": {
"domainId": "dashboard",
"counterName": "346f3c64-ebca-484d-9d57-ec600067d596",
"counterType": "viewed",
"source": "server",
"count": 1
},
...
}
]counterName 字段是仪表板 ID,而 count 是该仪表板在特定日期的累计查看次数。Kibana 每天为每个仪表板创建一个 counter 对象;你可以在对象 ID 中看到日期后缀(...viewed:server:20260310)。随着用户打开仪表板,count 会在一天中持续增长。
我们不会在索引中复刻这种按天分文档的模型,而是为每次 workflow 执行创建一个文档。每个文档记录在采集时刻该仪表板当天累计的查看次数。
步骤 2:创建目标索引
我们需要一个索引来存储仪表板查看快照。以下命令使用显式 mappings 创建索引,以便后续进行聚合和可视化。在 Dev Tools 中运行:
PUT dashboard-views
{
"mappings": {
"properties": {
"captured_at": {
"type": "date"
},
"dashboard_id": {
"type": "keyword"
},
"dashboard_name": {
"type": "keyword"
},
"view_count": {
"type": "integer"
}
}
}
}对 ID 和名称使用 keyword mappings 可以支持聚合。对 view_count 使用 integer 是一个安全的默认选择,因为 Kibana 会每天重置计数器,在单日内达到 32 位上限(超过 20 亿次查看)并不现实。同时它仍支持数值运算,例如 max、avg 和 min 等。
步骤 3:创建 workflow
进入 Stack Management > Workflows > New Workflow,并粘贴以下 workflow YAML 配置:
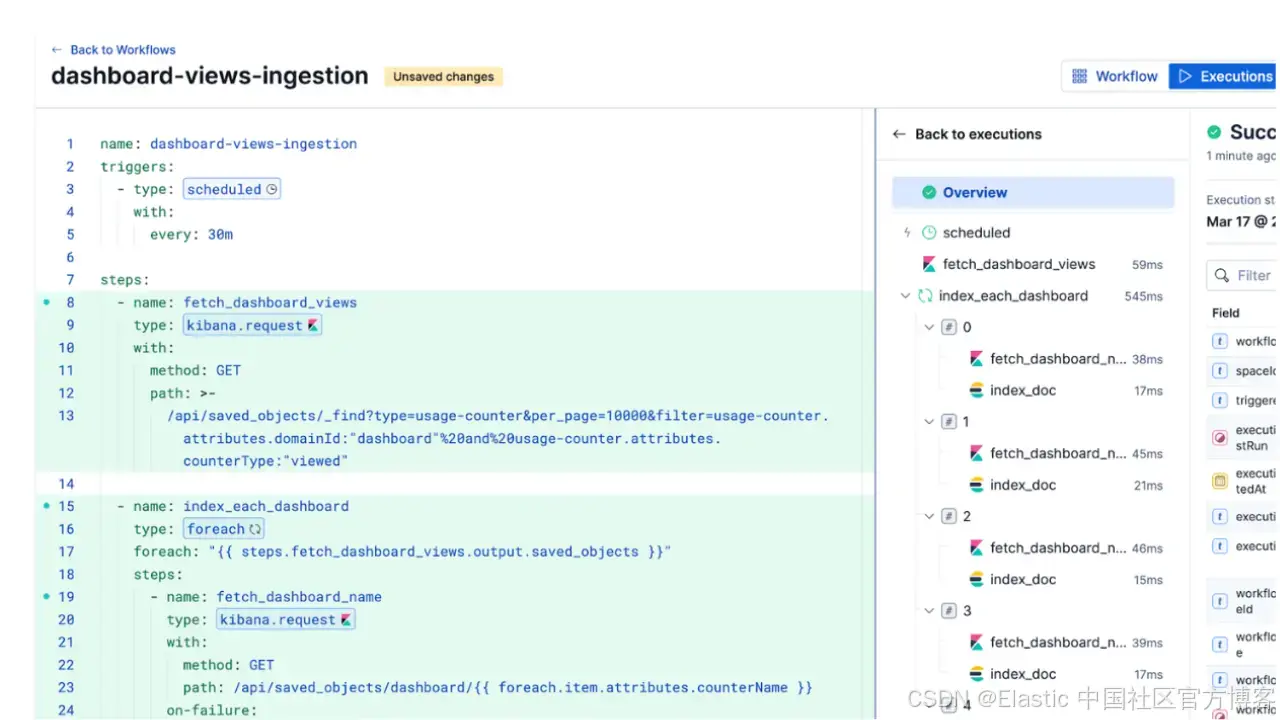
name: dashboard-views-ingestion
triggers:
- type: scheduled
with:
every: 30m
steps:
- name: fetch_dashboard_views
type: kibana.request
with:
method: GET
path: >-
/api/saved_objects/_find?type=usage-counter&per_page=10000&filter=usage-counter.attributes.domainId:"dashboard"%20and%20usage-counter.attributes.counterType:"viewed"
- name: index_each_dashboard
type: foreach
foreach: "{{ steps.fetch_dashboard_views.output.saved_objects }}"
steps:
- name: fetch_dashboard_name
type: kibana.request
with:
method: GET
path: /api/saved_objects/dashboard/{{ foreach.item.attributes.counterName }}
on-failure:
continue: true
- name: index_doc
type: elasticsearch.request
with:
method: POST
path: /dashboard-views/_doc
body:
dashboard_id: "{{ foreach.item.attributes.counterName }}"
dashboard_name: "{{ steps.fetch_dashboard_name.output.attributes.title }}"
view_count: "${{ foreach.item.attributes.count | plus: 0 }}"
captured_at: "{{ execution.startedAt | date: '%Y-%m-%dT%H:%M:%SZ' }}"在下一部分,我们将逐步拆解这个 workflow。
Workflow 的工作原理
触发器
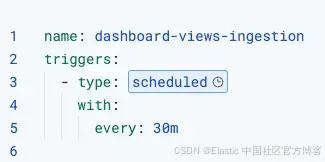
该 workflow 通过定时触发器每 30 分钟运行一次。这使我们能够获取时间序列数据,同时不会对 API 造成过大压力。
fetch_dashboard_views
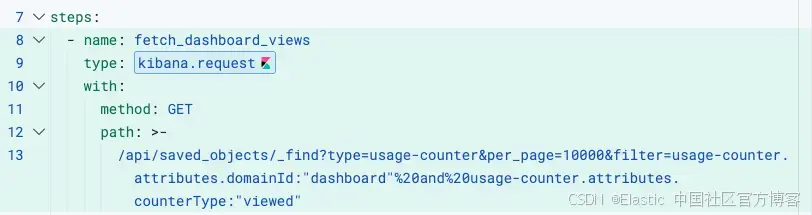
使用 kibana.request 调用 Kibana saved objects API。无需设置身份验证:workflow 引擎会根据执行上下文自动附加正确的 headers。
index_each_dashboard(foreach)

遍历前一步返回的 saved_objects 数组。每次迭代的当前项可通过 foreach.item 访问。在循环内部,我们为每个 dashboard 运行两个嵌套步骤。
1)fetch_dashboard_name:

通过调用 GET /api/saved_objects/dashboard/{id} 获取可读的 dashboard 标题。我们添加 on-failure: continue: true,这样如果某个 dashboard 已被删除但仍有 view counters,循环会继续,而不会导致整个执行失败。
2)index_doc:
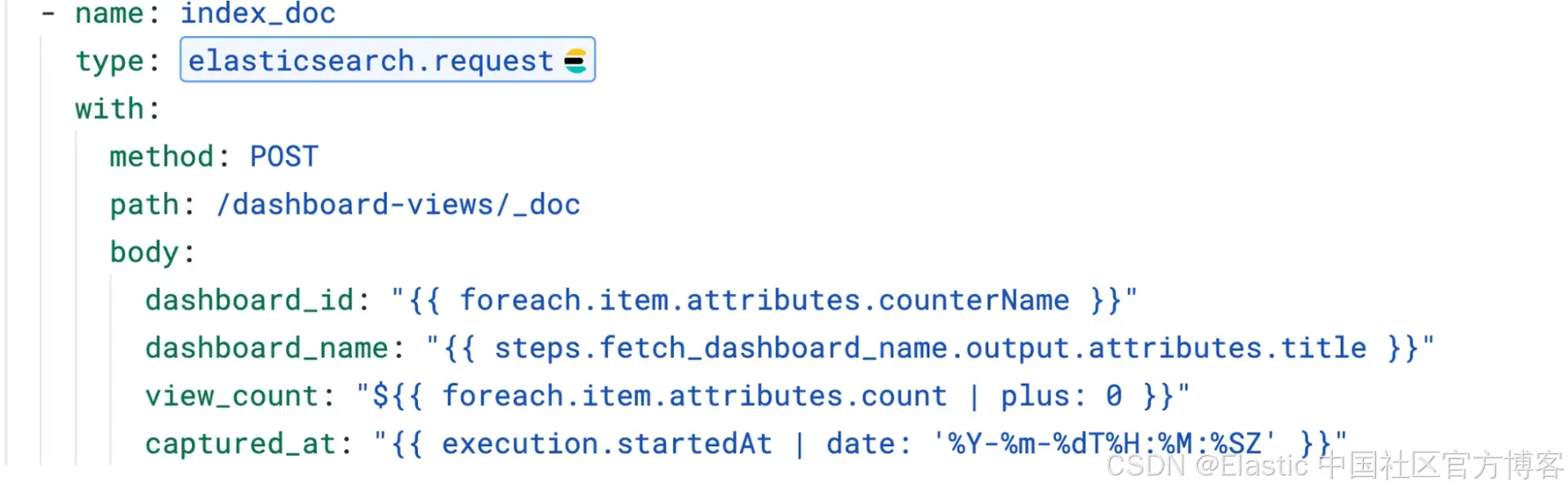
将每条文档索引到 POST /dashboard-views/_doc(不指定 ID),让 Elasticsearch 自动生成 ID。这样每次运行都会创建一条新文档,从而保留历史 view count,而不是覆盖之前的快照。
值得注意的两点:
-
captured_at 字段使用 date filter 格式化为 ISO 8601 时间戳。否则它会输出 JavaScript 日期字符串,例如
Tue Mar 10 2026 05:03:47 GMT+0000,Elasticsearch 无法映射为日期类型。 -
view_count 使用
${``{ }}语法并加上| plus: 0来保持数值类型。如果直接用{``{ }},它会被渲染为字符串,从而阻止仪表盘上的数学操作。
UI 允许你方便地调试每一个 workflow 步骤。
Step 4: 构建统计仪表盘
当 workflow 运行几次并收集到数据后,可以在 Kibana 中使用 dashboard-views 数据视图创建新的仪表盘。
一些入门面板示例:
-
Top dashboards by views :使用 Bar chart(柱状图),X 轴为
dashboard_name,Y 轴为last_value(view_count)。显示每个仪表盘当前的日累计访问量。 -
Views over time :使用 Line chart(折线图),X 轴为
captured_at,Y 轴为last_value(view_count),按dashboard_name拆分。由于每次运行都会追加新文档,使用 last value 获取每个时间桶的峰值,而不是求和重复值。 -
Current snapshot :使用 Data table(数据表),显示最新的
captured_at,呈现所有仪表盘的最新访问量快照。
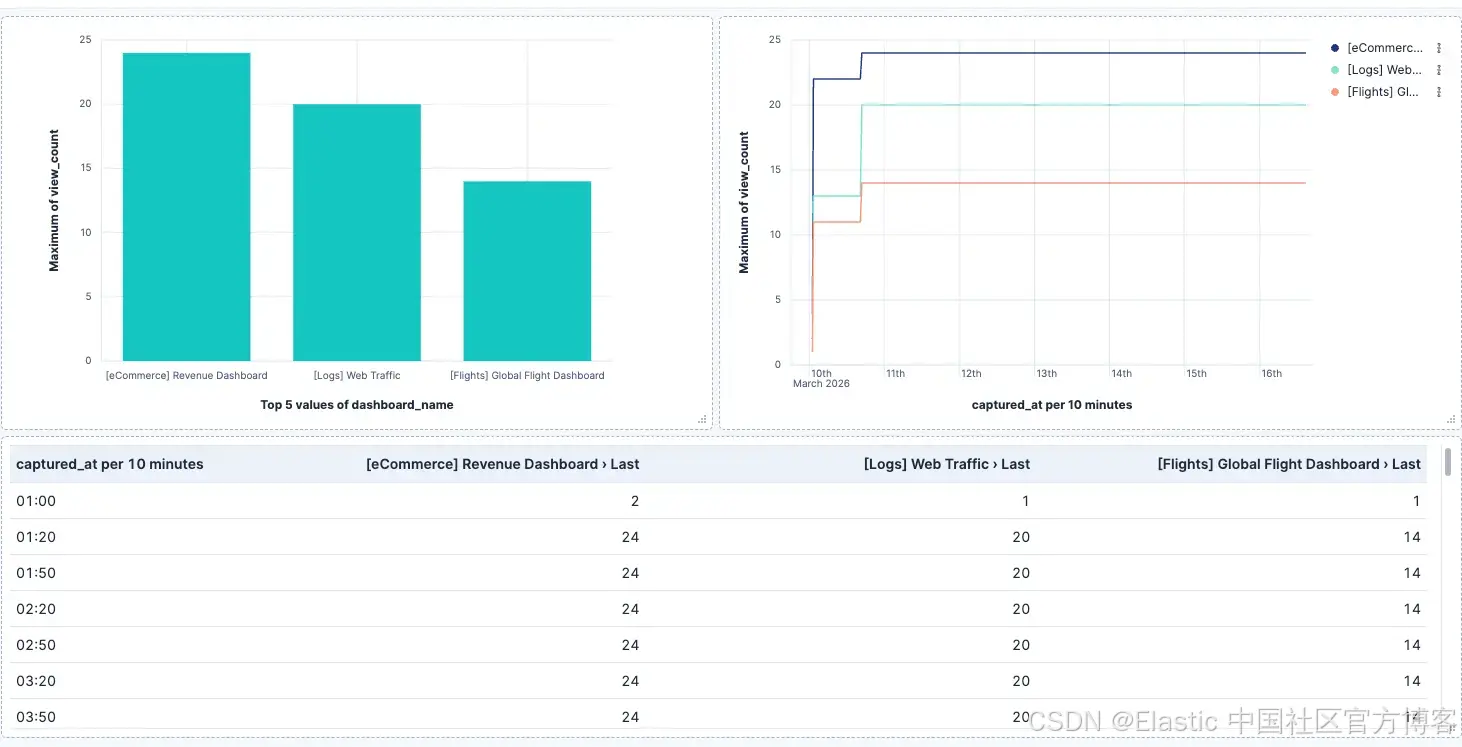
由于每次 workflow 都会创建一个新文档,你可以按时间范围过滤数据,以分析特定时期的仪表盘活动、进行周比周的对比,或者在仪表盘访问量低于阈值时触发告警。
结论
Elastic Workflows 非常适合这类周期性数据采集场景,因为数据源(Kibana API)和目标(Elasticsearch)都是原生的,这意味着无需管理凭据。Workflow 引擎会自动为 kibana.request 和 elasticsearch.request 步骤处理认证,你只需要编写业务逻辑即可。
资源
原文:https://www.elastic.co/search-labs/blog/monitor-kibana-dashboard-views-elastic-workflows