1.Numpy
| 维度 | 数学上叫 | NumPy 中叫 | 例子 |
|---|---|---|---|
| 1维 | 向量 | 1维数组 | [1,2,3] |
| 2维 | 矩阵 | 2维数组 | [[1,2],[3,4]] |
| 3维+ | 张量 | 多维数组 | 图片、视频数据 |
1.1Numpy数组
📌 一维数组
python
import numpy as np
arr1 = np.array([1, 2, 3])
print(arr1.shape) # (3,) ------ 一维,3个元素📌 二维数组(矩阵)
python
arr2 = np.array([[1, 2, 3],
[4, 5, 6]])
print(arr2.shape) # (2, 3) ------ 2行3列📌 三维数组(如彩色图片:高×宽×通道)
python
arr3 = np.array([[[1, 2], [3, 4]],
[[5, 6], [7, 8]]])
print(arr3.shape) # (2, 2, 2) ------ 2层×2行×2列📌 更高维
python
arr4 = np.array([[[[1]]]]) # 四维
print(arr4.shape) # (1, 1, 1, 1)1.2 各种属性
1.2.1数组本身
python
import numpy as np #numpy是基于矩阵的运算
array=np.array([[1,2,3],
[2,3,4]]) #将列表转换成数组(矩阵)的方法
print(array)
print('number of dim:',array.ndim) #输出array是几维数组
print('shape:',array.shape) #输出array的行数是多少,列数是多少
print('size:',array.size) #array里有多少元素
输出: [[1 2 3] [2 3 4]] number of dim: 2 shape: (2, 3) size: 6
python
import numpy as np
a=np.array([2,23,4]) #array元素之间用空格隔开
print(a) #array元素之间用空格隔开,和列表不同(用逗号隔开)[ 2 23 4]1.2.2定义类型
python
#可在创建时定义array的type(整数型,浮点型等)
a1=np.array([2,3,4],dtype=np.int) #整数型 np.int64
print(a1.dtype)
a2=np.array([2,3,4],dtype=np.float) #浮点型 np.float32
print(a2.dtype)int32
float641.2.3定义矩阵
python
#定义矩阵
a=np.array([[1,2,3],[4,5,6]])
print(a)[[1 2 3]
[4 5 6]]1.2.4定义特殊矩阵
python
#定义特殊矩阵
a=np.zeros((3,4)) #定义三行四列的零矩阵
print(a)
b=np.ones((2,3),dtype=np.int16) #定义2行3列的单位矩阵
print(b)
c=np.empty((3,4)) #定义空矩阵
print(c)
d=np.arange(10,20,2) #生成有序矩阵:起始值是10,终止值是20(不等于20),步长是2
print(d)
d2=np.arange(12).reshape((3,4)) #生成从0到11的3行4列矩阵
print(d2)
#生成线段
e=np.linspace(1,10,5) #从1到10生成5段的数列
print(e)
e2=np.linspace(1,10,6).reshape((2,3)) #更改形状:2行3列矩阵
print(e2)[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
[[1 1 1]
[1 1 1]]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
[10 12 14 16 18]
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[ 1. 3.25 5.5 7.75 10. ]
[[ 1. 2.8 4.6]
[ 6.4 8.2 10. ]]1.3 基础运算
python
import numpy as np
a=np.array([10,20,30,40])
b=np.arange(4)
print(a,b)
c=a-b #矩阵减法
print(c)[10 20 30 40] [0 1 2 3]
[10 19 28 37]
python
c=a+b #矩阵加法
print(c)[10 21 32 43]
python
c=b**2 #在Python中平方、次方用**
print(c)[0 1 4 9]
python
c=10*np.sin(a) #三角函数,通过调用numpy中的函数
print(c)[-5.44021111 9.12945251 -9.88031624 7.4511316 ]
python
print(b)
print(b<3) #判断b中哪些值是小于3的,返回元素为布尔型的列表[0 1 2 3]
[ True True True False]
python
a=np.array([[1,1],[0,1]])
b=np.arange(4).reshape((2,2))
print(a)
print(b)[[1 1]
[0 1]]
[[0 1]
[2 3]]
python
c=a*b #逐位相乘
print(c)
c_dot=np.dot(a,b)
c_dot1=a.dot(b)
print(c_dot) #矩阵相乘
print(c_dot1) #另一种写法[[0 1]
[0 3]]
[[2 4]
[2 3]]
[[2 4]
[2 3]]
python
a=np.random.random((2,4)) #随机创建一个2行4列的矩阵
print(a)
print(np.sum(a)) #矩阵所有元素之和
print(np.min(a)) #矩阵最小元素
print(np.max(a)) #矩阵最大元素
print(np.sum(a,axis=1)) #axis表示维度,axis=1对行求和
print(np.sum(a,axis=0)) #axis=0对列求和
#关于axis这个属性的定义是基于数组.shape 的这个属性,
#它是一个Python元组,对于二维数组而言,axis=0表示这个元组的第一个元素,axis=1表示第二个元素.
#假如这个数组是三维数组,axis=0代表的是第一个维度也就是页,axis=1,表示的是行,axis=2表示列[[0.03021769 0.2205137 0.71329625 0.13152101]
[0.24729601 0.37339794 0.16424974 0.1769258 ]]
2.057418144568723
0.03021768837981753
0.7132962510835831
[1.09554865 0.9618695 ]
[0.2775137 0.59391164 0.877546 0.30844681]
python
A=np.arange(2,14).reshape((3,4))
print(A)
print(np.argmin(A)) #搜索最小值的索引
print(np.argmax(A)) #搜索最大值的索引
print(np.mean(A)) #矩阵平均值
print(A.mean()) #矩阵平均值另一种方法
print(np.average(A)) #矩阵加权平均值,尽量用mean()
print(np.median(A)) #矩阵中位数
print(np.cumsum(A)) #累加,结果元素个数与A相同,第二个数是A前两个值想加,第k个数是A前k个数相加
print(np.diff(A)) #累差,A是3*4,累差结果为3*3,相邻两个数之间的差
print(np.nonzero(A)) #返回非零数的索引,第一个array表示行,第二个array表示列
print(np.sort(A)) #矩阵逐行排序
print(np.transpose(A)) #矩阵转置
print(A.T) #矩阵转置另一种方法
print((A.T).dot(A)) #矩阵乘法示例
print(np.clip(A,5,9)) #滤波,在A中,比5小的数都变成5,比9大的数都变成9,5-9的数保留
print(np.mean(A,axis=0)) #axis=0对列求均值
print(np.mean(A,axis=1)) #axis=1对行求均值输出
python
[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
0
11
7.5
7.5
7.5
7.5
[ 2 5 9 14 20 27 35 44 54 65 77 90]
[[1 1 1]
[1 1 1]
[1 1 1]]
(array([0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2], dtype=int64), array([0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3], dtype=int64))
[[ 2 3 4 5]
[ 6 7 8 9]
[10 11 12 13]]
[[ 2 6 10]
[ 3 7 11]
[ 4 8 12]
[ 5 9 13]]
[[ 2 6 10]
[ 3 7 11]
[ 4 8 12]
[ 5 9 13]]
[[140 158 176 194]
[158 179 200 221]
[176 200 224 248]
[194 221 248 275]]
[[5 5 5 5]
[6 7 8 9]
[9 9 9 9]]
[6. 7. 8. 9.]
[ 3.5 7.5 11.5]1.4索引
python
import numpy as np
A=np.arange(3,15) #一维array
print(A)
print(A[3])[ 3 4 5 6 7 8 9 10 11 12 13 14]
6
python
A=np.arange(3,15).reshape((3,4)) #二维array
print(A)
print(A[2])
print(A[0][3])
print(A[0,3])
#用冒号:代替该行(列)所有的数
#左闭右开
print(A[2,:])
print(A[:,1])
print(A[1,1:3]) #输出A[1][1],A[1][2][[ 3 4 5 6]
[ 7 8 9 10]
[11 12 13 14]]
[11 12 13 14]
6
6
[11 12 13 14]
[ 4 8 12]
[8 9]
python
for row in A: #迭代每一行
print(row)
#因为系统没有专门的迭代每一列,所以可以将矩阵先转置
for column in A.T: #迭代每一列
print(column)
#将矩阵转换成列表/1*n
print(A.flatten()) #A.flat()返回的是一个object,也就是迭代器
for item in A.flat: #迭代每一项
print(item)
[3 4 5 6] [ 7 8 9 10] [11 12 13 14] [ 3 7 11] [ 4 8 12] [ 5 9 13] [ 6 10 14] [ 3 4 5 6 7 8 9 10 11 12 13 14] 3 4 5 6 7 8 9 10 11 12 13 14
1.5array合并
python
import numpy as np
A=np.array([1,1,1])
B=np.array([2,2,2])
print(np.vstack((A,B))) #上下合并 vertical垂直合并
print(np.hstack((A,B))) #左右合并 horizontal水平合并
print(A.T) #定义的是数组,不是矩阵,转置不了
print(A[np.newaxis,:]) #给数组A添加维度,此时变成了一维矩阵1*3:向量
print(A[:,np.newaxis]) #变成了3*1的矩阵[[1 1 1]
[2 2 2]]
[1 1 1 2 2 2]
[1 1 1]
[[1 1 1]]
[[1]
[1]
[1]]
python
#先将array添加维度,不然没有axis=1这个维度
A=np.array([1,1,1])[:,np.newaxis]
B=np.array([2,2,2])[:,np.newaxis]
C=np.concatenate((A,B,B,A),axis=0) #多个array合并,同时可指定哪个方向上
#axis=0,对行操作(增加行),垂直合并
#axis=1,对列操作(增加列),水平合并
print(C)[[1]
[1]
[1]
[2]
[2]
[2]
[2]
[2]
[2]
[1]
[1]
[1]]1.6分割
python
import numpy as np
A=np.arange(12).reshape((3,4))
print(A)
#等量分割
print(np.split(A,2,axis=1)) #对列进行操作,将A均分成2快
print(np.split(A,3,axis=0)) #对行进行操作,将A均分成3块
#不等量分割
print(np.array_split(A,3,axis=1))
print(np.vsplit(A,3)) #垂直分割
print(np.hsplit(A,2)) #水平分割
[[ 0 1 2 3] [ 4 5 6 7] [ 8 9 10 11]] [array([[0, 1], [4, 5], [8, 9]]), array([[ 2, 3], [ 6, 7], [10, 11]])] [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])] [array([[0, 1], [4, 5], [8, 9]]), array([[ 2], [ 6], [10]]), array([[ 3], [ 7], [11]])] [array([[0, 1, 2, 3]]), array([[4, 5, 6, 7]]), array([[ 8, 9, 10, 11]])] [array([[0, 1], [4, 5], [8, 9]]), array([[ 2, 3], [ 6, 7], [10, 11]])]
1.7 numpy-copy&deepcopy.ipynb
python
import numpy as np
a=np.arange(4)
print(a)
#此时abcd其实是相互关联的
b=a
c=a
d=b
a[0]=10
print(a)
b is a
d is a[0 1 2 3]
[10 1 2 3]
True True
python
b=a.copy() #deep copy,把a的值赋给b,但a,b不关联
a[2]=44
print(a)
print(b)[10 1 44 3]
[10 1 2 3]2.pandas
2.1 pandas基础介绍
python
#numpy:提供序列化好了的矩阵(序列)
#pandas:类似于一个字典形式的numpy,若numpy是列表的话,pandas就相当于字典
#pandas可以给不同的行,不同的列命名
import pandas as pd
import numpy as np
s=pd.Series([1,3,6,np.nan,44,1]) #定义一个序列,[]内是每个元素的值,默认浮点型
print(s)0 1.0
1 3.0
2 6.0
3 NaN
4 44.0
5 1.0
dtype: float64DatetimeIndex(['2020-03-19', '2020-03-20', '2020-03-21', '2020-03-22',
'2020-03-23'],
dtype='datetime64[ns]', freq='D')
python
#数据表 DataFrame
#np.random.randn(5,4)生成一个 5 行 4 列的随机数组,数组中的每个数都服从"标准正态分布"。
df=pd.DataFrame(np.random.randn(5,4),index=dates,columns=['a','b','c','d'])
#没有给行或列的名字时,pandas默认成0123...,如果给了,按照给定的排序
#DataFrame是一个大的matrix,类似于一个二维numpy
#np.random.random(6,4)其实就是numpy的数据
#index是行索引,columns是列索引
df
df1=pd.DataFrame(np.arange(12).reshape(3,4))
df1
#用字典生成DataFrame,字典中的一对key和value表示一列
df2=pd.DataFrame({'A':1,
'B':pd.Timestamp('20200319'),
'C':pd.Series(1,index=list(range(4)),dtype='float32'),
'D':np.array([3]*4,dtype='int32'),
'E':pd.Categorical(["test","train","test","train"]),
'F':'fool'})
print(df2)
print(df2.dtypes) #返回每一列的类型
print(df2.index) #返回所有行的序号
print(df2.columns) #返回所有列的名称
print(df2.values) #返回DataFrame中的所有值
df2.describe() #描述DataFrame,如均值,最大值,最小值等
#只能计算数值型,所以字符型都自动忽略
df2.T #将df2视为矩阵,进行转置
df2.sort_index(axis=0,ascending=False)
#排序函数此时用sort_index(),但与上文行索引index无关联
#axis=0,对行操作(行动),axis=1,对列操作(列动)
#ascending=False表示倒序
df2.sort_values(by='E') #根据表格中的值进行排序,根据'E'列的值进行排序 A B C D E F
0 1 2020-03-19 1.0 3 test fool
1 1 2020-03-19 1.0 3 train fool
2 1 2020-03-19 1.0 3 test fool
3 1 2020-03-19 1.0 3 train fool
A int64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
Int64Index([0, 1, 2, 3], dtype='int64')
Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object')
[[1 Timestamp('2020-03-19 00:00:00') 1.0 3 'test' 'fool']
[1 Timestamp('2020-03-19 00:00:00') 1.0 3 'train' 'fool']
[1 Timestamp('2020-03-19 00:00:00') 1.0 3 'test' 'fool']
[1 Timestamp('2020-03-19 00:00:00') 1.0 3 'train' 'fool']]| | A | B | C | D | E | F |
| 0 | 1 | 2020-03-19 | 1.0 | 3 | test | fool |
| 2 | 1 | 2020-03-19 | 1.0 | 3 | test | fool |
| 1 | 1 | 2020-03-19 | 1.0 | 3 | train | fool |
| 3 | 1 | 2020-03-19 | 1.0 | 3 | train | fool |
|---|
2.2 pandas选择数据
python
import pandas as pd
import numpy as np
dates=pd.date_range('20200319',periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
print(df)
#选择特定的某一列
print(df['A'])
print(df.A)
#按照切片进行选择
print(df[0:3]) #选取0到3行
print(df['20200320':'20200323']) #选取'20200320'到'20200323'列
#更高级的方法select by label:loc根据标签(行名和列名)进行选择
print(df.loc['20200322'])
print(df.loc[:,['A','B']]) #保留所有行,列选取'A'和'B'
print(df.loc['20200322',['A','B']]) A B C D
2020-03-19 0 1 2 3
2020-03-20 4 5 6 7
2020-03-21 8 9 10 11
2020-03-22 12 13 14 15
2020-03-23 16 17 18 19
2020-03-24 20 21 22 23
2020-03-19 0
2020-03-20 4
2020-03-21 8
2020-03-22 12
2020-03-23 16
2020-03-24 20
Freq: D, Name: A, dtype: int32
2020-03-19 0
2020-03-20 4
2020-03-21 8
2020-03-22 12
2020-03-23 16
2020-03-24 20
Freq: D, Name: A, dtype: int32
A B C D
2020-03-19 0 1 2 3
2020-03-20 4 5 6 7
2020-03-21 8 9 10 11
A B C D
2020-03-20 4 5 6 7
2020-03-21 8 9 10 11
2020-03-22 12 13 14 15
2020-03-23 16 17 18 19
A 12
B 13
C 14
D 15
Name: 2020-03-22 00:00:00, dtype: int32
A B
2020-03-19 0 1
2020-03-20 4 5
2020-03-21 8 9
2020-03-22 12 13
2020-03-23 16 17
2020-03-24 20 21
A 12
B 13
Name: 2020-03-22 00:00:00, dtype: int32
python
#select by position:iloc根据位置(第几行第几列)进行选择
print(df.iloc[3]) #选择第四行的数据
print(df.iloc[3,1]) #第4行,第2列
print(df.iloc[2:4,1:3]) #第3行到第4行,第2列到第3列
#!!!x:y,起始值是x,但终点值是y-1
print(df.iloc[[1,3,5],1:3]) #不连续的选取A 12
B 13
C 14
D 15
Name: 2020-03-22 00:00:00, dtype: int32
13
B C
2020-03-21 9 10
2020-03-22 13 14
B C
2020-03-20 5 6
2020-03-22 13 14
2020-03-24 21 22
python
#Boolean indexing
print(df)
print(df[df.A<8]) #列名为A的列中,<8的数被输出来
print(df[df.A<8][df.B>4]) A B C D
2020-03-19 0 1 2 3
2020-03-20 4 5 6 7
2020-03-21 8 9 10 11
2020-03-22 12 13 14 15
2020-03-23 16 17 18 19
2020-03-24 20 21 22 23
A B C D
2020-03-19 0 1 2 3
2020-03-20 4 5 6 7
A B C D
2020-03-20 4 5 6 72.3 pandas设置值
python
import pandas as pd
import numpy as np
dates=pd.date_range('20200319',periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
df.iloc[2,2]=111 #根据iloc(位置) 将第3行第3列的数改为111
df.loc['20200322','B']=3435 #根据loc(名称label)
df[df.A>4]=1 #A列大于4的元素所在的行,值都改为1
print(df) A B C D
2020-03-19 0 1 2 3
2020-03-20 4 5 6 7
2020-03-21 1 1 1 1
2020-03-22 1 1 1 1
2020-03-23 1 1 1 1
2020-03-24 1 1 1 1
python
df.A[df.A<4]=2 #找到A列中小于4的元素所在的行,A列里元素都改为2(.A表示只修改A,其他地方不动)
print(df) A B C D
2020-03-19 2 1 2 3
2020-03-20 4 5 6 7
2020-03-21 2 1 1 1
2020-03-22 2 1 1 1
2020-03-23 2 1 1 1
2020-03-24 2 1 1 1
python
df.B[df.A<4]=3 #找到A列中小于4的元素所在的行,B列里元素都改为3(.B表示只修改A,其他地方不动)
print(df) A B C D
2020-03-19 2 3 2 3
2020-03-20 4 5 6 7
2020-03-21 2 3 1 1
2020-03-22 2 3 1 1
2020-03-23 2 3 1 1
2020-03-24 2 3 1 1
python
df['F']=np.nan
#新添加了F列,所有值都是NaN
#之后再根据某行某列等方法,将F列的值一个一个输入
print(df) A B C D F
2020-03-19 2 3 2 3 NaN
2020-03-20 4 5 6 7 NaN
2020-03-21 2 3 1 1 NaN
2020-03-22 2 3 1 1 NaN
2020-03-23 2 3 1 1 NaN
2020-03-24 2 3 1 1 NaN
python
#和原有的序列纵坐标相同
df['E']=pd.Series([1,2,3,4,5,6],index=pd.date_range('20200319',periods=6))
#添加列的同时指定值
print(df) A B C D F E
2020-03-19 2 3 2 3 NaN 1
2020-03-20 4 5 6 7 NaN 2
2020-03-21 2 3 1 1 NaN 3
2020-03-22 2 3 1 1 NaN 4
2020-03-23 2 3 1 1 NaN 5
2020-03-24 2 3 1 1 NaN 62.4处理丢失数据
python
import pandas as pd
import numpy as np
dates=pd.date_range('20200319',periods=6)
df=pd.DataFrame(np.arange(24).reshape((6,4)),index=dates,columns=['A','B','C','D'])
df.iloc[0,1]=np.nan #假设丢失掉的数据
df.iloc[1,2]=np.nan
print(df)
#丢弃 drop
print(df.dropna(axis=0,how='any')) #任何一行有NaN都被丢弃
#axis=0丢掉行,axis=1丢掉列
#how={'any'(默认),'all'} all表示一行(列)所有数据都是NaN时,才会被丢弃
A B C D 2020-03-19 0 NaN 2.0 3 2020-03-20 4 5.0 NaN 7 2020-03-21 8 9.0 10.0 11 2020-03-22 12 13.0 14.0 15 2020-03-23 16 17.0 18.0 19 2020-03-24 20 21.0 22.0 23 A B C D 2020-03-21 8 9.0 10.0 11 2020-03-22 12 13.0 14.0 15 2020-03-23 16 17.0 18.0 19 2020-03-24 20 21.0 22.0 23
python
#填充 fill
print(df.fillna(value=0)) #NaN用0填入
A B C D 2020-03-19 0 0.0 2.0 3 2020-03-20 4 5.0 0.0 7 2020-03-21 8 9.0 10.0 11 2020-03-22 12 13.0 14.0 15 2020-03-23 16 17.0 18.0 19 2020-03-24 20 21.0 22.0 23
python
#判断数据有没有缺失
print(df.isnull()) #缺失返回True
#当表格很大,很难找到哪里有True时
print(np.any(df.isnull())==True) #,返回False表示没有丢失,返回True表示该表格中至少有一个数据丢失
A B C D 2020-03-19 False True False False 2020-03-20 False False True False 2020-03-21 False False False False 2020-03-22 False False False False 2020-03-23 False False False False 2020-03-24 False False False False True
2.5导入导出数据.
python
import pandas as pd
#读取excel文件
data=pd.read_csv('student.csv',encoding='UTF-8')
print(data)
#存储文件
data.to_pickle('student.pickle')2.6合并concat.
python
import pandas as pd
import numpy as np
#concatenating
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['a','b','c','d'])
df3=pd.DataFrame(np.ones((3,4))*2,columns=['a','b','c','d'])
print(df1)
print(df2)
print(df3)
a b c d 0 0.0 0.0 0.0 0.0 1 0.0 0.0 0.0 0.0 2 0.0 0.0 0.0 0.0 a b c d 0 1.0 1.0 1.0 1.0 1 1.0 1.0 1.0 1.0 2 1.0 1.0 1.0 1.0 a b c d 0 2.0 2.0 2.0 2.0 1 2.0 2.0 2.0 2.0 2 2.0 2.0 2.0 2.0
python
#用shape去记忆axis,要改变shape中哪一维的大小,axis就选几,numpy和pandas都一样
#如原shape为(3,4),合并后为(6,4),改变第一个位置的值,所以axis=0
#合并
result=pd.concat([df1,df2,df3],axis=0) #合并,axis=0对行操作,行变多
print(result) #行索引还是原来的没有变化
result=pd.concat([df1,df2,df3],axis=0,ignore_index=True)
print(result) #生成新的有序索引
a b c d 0 0.0 0.0 0.0 0.0 1 0.0 0.0 0.0 0.0 2 0.0 0.0 0.0 0.0 0 1.0 1.0 1.0 1.0 1 1.0 1.0 1.0 1.0 2 1.0 1.0 1.0 1.0 0 2.0 2.0 2.0 2.0 1 2.0 2.0 2.0 2.0 2 2.0 2.0 2.0 2.0 a b c d 0 0.0 0.0 0.0 0.0 1 0.0 0.0 0.0 0.0 2 0.0 0.0 0.0 0.0 3 1.0 1.0 1.0 1.0 4 1.0 1.0 1.0 1.0 5 1.0 1.0 1.0 1.0 6 2.0 2.0 2.0 2.0 7 2.0 2.0 2.0 2.0 8 2.0 2.0 2.0 2.0
python
#concat()的一个参数,join,有两种形式,['inner','outer']
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['c','d','e','f'],index=[2,3,4])
#df1和df2的行和列不完全一致,合并时用join可以很好的处理
print(df1)
print(df2)
result1=pd.concat([df1,df2],join='outer') #合并后保留所有不重复的行和列,不存在的元素用NaN填充
print(result1) #类似于并集
result2=pd.concat([df1,df2],join='inner',ignore_index=True) #合并后保留共同的部分
print(result2) #类似于交集
#处理序号仍然可以用ignore_index=True
a b c d 1 0.0 0.0 0.0 0.0 2 0.0 0.0 0.0 0.0 3 0.0 0.0 0.0 0.0 c d e f 2 1.0 1.0 1.0 1.0 3 1.0 1.0 1.0 1.0 4 1.0 1.0 1.0 1.0 a b c d e f 1 0.0 0.0 0.0 0.0 NaN NaN 2 0.0 0.0 0.0 0.0 NaN NaN 3 0.0 0.0 0.0 0.0 NaN NaN 2 NaN NaN 1.0 1.0 1.0 1.0 3 NaN NaN 1.0 1.0 1.0 1.0 4 NaN NaN 1.0 1.0 1.0 1.0 c d 0 0.0 0.0 1 0.0 0.0 2 0.0 0.0 3 1.0 1.0 4 1.0 1.0 5 1.0 1.0
python
#append 添加一行(列)数据
df1=pd.DataFrame(np.ones((3,4))*0,columns=['a','b','c','d'],index=[1,2,3])
df2=pd.DataFrame(np.ones((3,4))*1,columns=['c','d','e','f'],index=[2,3,4])
result1=df1.append([df2,df2],ignore_index=True) #将两个df2接到df1后,竖着接
print(result1)
s=pd.Series([1,2,3,4],index=['a','b','c','d'])
result=df1.append(s,ignore_index=True) #追加一行,而不是一个表
print(result)
a b c d e f 0 0.0 0.0 0.0 0.0 NaN NaN 1 0.0 0.0 0.0 0.0 NaN NaN 2 0.0 0.0 0.0 0.0 NaN NaN 3 NaN NaN 1.0 1.0 1.0 1.0 4 NaN NaN 1.0 1.0 1.0 1.0 5 NaN NaN 1.0 1.0 1.0 1.0 6 NaN NaN 1.0 1.0 1.0 1.0 7 NaN NaN 1.0 1.0 1.0 1.0 8 NaN NaN 1.0 1.0 1.0 1.0 a b c d 0 0.0 0.0 0.0 0.0 1 0.0 0.0 0.0 0.0 2 0.0 0.0 0.0 0.0 3 1.0 2.0 3.0 4.0
2.7合并merge
python
#concat相对于merge,是一种比较简单的合并
#maerge在考虑索引或者key的对照下,实现DataFrame的合并
import pandas as pd
import numpy as np
#merge two df by key/keys(maybe used in database)
#simple example
left=pd.DataFrame({'key':['K0','K1','K2','K3'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right=pd.DataFrame({'key':['K0','K1','K2','K3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
print(left)
print(right)
res=pd.merge(left,right,on='key') #on='key'基于key列合并
print(res)
key A B 0 K0 A0 B0 1 K1 A1 B1 2 K2 A2 B2 3 K3 A3 B3 key C D 0 K0 C0 D0 1 K1 C1 D1 2 K2 C2 D2 3 K3 C3 D3 key A B C D 0 K0 A0 B0 C0 D0 1 K1 A1 B1 C1 D1 2 K2 A2 B2 C2 D2 3 K3 A3 B3 C3 D3
python
#merge two df by key/keys (maybe used in database)
#consider two keys
left=pd.DataFrame({'key1':['K0','K0','K1','K2'],
'key2':['K0','K1','K0','K1'],
'A':['A0','A1','A2','A3'],
'B':['B0','B1','B2','B3']})
right=pd.DataFrame({'key1':['K0','K1','K1','K2'],
'key2':['K0','K0','K0','K0'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
print(left)
print(right)
#how=['left','right','inner','outer']
res1=pd.merge(left,right,on=['key1','key2']) #how默认为inner,合并后保留相同的部分
#在left中'K1,K0'只有一组对应'A2,B2',但right有两组'K1,K0',所以'A2,B2'出现了两遍
res2=pd.merge(left,right,on=['key1','key2'],how='right') #基于right的keys合并(即right的keys全保留)
print(res2)
key1 key2 A B 0 K0 K0 A0 B0 1 K0 K1 A1 B1 2 K1 K0 A2 B2 3 K2 K1 A3 B3 key1 key2 C D 0 K0 K0 C0 D0 1 K1 K0 C1 D1 2 K1 K0 C2 D2 3 K2 K0 C3 D3 key1 key2 A B C D 0 K0 K0 A0 B0 C0 D0 1 K1 K0 A2 B2 C1 D1 2 K1 K0 A2 B2 C2 D2 3 K2 K0 NaN NaN C3 D3
python
#merge two df by key/keys (maybe used in database)
#indicator
df1=pd.DataFrame({'col1':[0,1],'col_left':['a','b']})
df2=pd.DataFrame({'col1':[1,2,2],'col_right':[2,2,2]})
print(df1)
print(df2)
res=pd.merge(df1,df2,on='col1',how='outer',indicator=True)
#indicator会显示每行merge的方式,indicator默认为False
print(res)
#显示结果多了label是'merge'的一列,其中为left_only表示只有左边有数据,右边没有数据
#merge(x,y),x是左边,y是右边
#将indicator默认的列名'merge',改为自定义的
res1=pd.merge(df1,df2,on='col1',how='outer',indicator='indicator_column')
print(res1)
col1 col_left 0 0 a 1 1 b col1 col_right 0 1 2 1 2 2 2 2 2 col1 col_left col_right _merge 0 0 a NaN left_only 1 1 b 2.0 both 2 2 NaN 2.0 right_only 3 2 NaN 2.0 right_only col1 col_left col_right indicator_column 0 0 a NaN left_only 1 1 b 2.0 both 2 2 NaN 2.0 right_only 3 2 NaN 2.0 right_only
python
#merge by index
left=pd.DataFrame({'A':['A0','A1','A2'],
'B':['B0','B1','B2']},
index=['K0','K1','K2'])
right=pd.DataFrame({ 'C':['C0','C1','C2'],
'D':['D0','D1','D2']},
index=['K0','K2','K3'])
print(left)
print(right)
#left_index和right_index,默认值都是False
#当把他们都设为True时,表示不再根据列中的'key'进行合并,而是调转方向,根据行名来merge
res1=pd.merge(left,right,left_index=True,right_index=True,how='outer')
print(res1)
A B K0 A0 B0 K1 A1 B1 K2 A2 B2 C D K0 C0 D0 K2 C1 D1 K3 C2 D2 A B C D K0 A0 B0 C0 D0 K1 A1 B1 NaN NaN K2 A2 B2 C1 D1 K3 NaN NaN C2 D2
python
#处理overlapping
boys=pd.DataFrame({'k':['K0','K1','K2'],'age':[1,2,3]})
girls=pd.DataFrame({'k':['K0','K0','K3'],'age':[4,5,6]})
print(boys)
print(girls)
#'age'该列名重复
res=pd.merge(boys,girls,on='k',suffixes=['_boy','_girl'],how='outer')
#suffixes修改列名(加后缀)
print(res)
k age 0 K0 1 1 K1 2 2 K2 3 k age 0 K0 4 1 K0 5 2 K3 6 k age_boy age_girl 0 K0 1.0 4.0 1 K0 1.0 5.0 2 K1 2.0 NaN 3 K2 3.0 NaN 4 K3 NaN 6.0
2.8plot画图
python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#plot data
#Series线性数据
data=pd.Series(np.random.randn(1000),index=np.arange(1000))
data=data.cumsum() #data中的数据累加
data.plot()
plt.show()
python
#DataFrame数据表
data=pd.DataFrame(np.random.randn(1000,4),
index=np.arange(1000),
columns=list('ABCD'))
data=data.cumsum()
print(data.head())
data.plot()
#data.plot()中有很多参数,线条形状颜色等等,自己google
plt.show()
A B C D 0 -1.407811 0.164888 -0.858803 -0.217948 1 -1.323665 -0.058319 -1.588471 0.542279 2 -2.152346 -0.327931 -0.698983 -0.541206 3 -1.357743 1.626128 1.190956 0.988664 4 -0.275740 1.231384 1.318562 0.986995
python
#plot methods:
#'bar','hist','box','kde','area','scatter','hexbin','pie'
#scatter只能有两个对象x和y,而不能像data.plot()一样可以同时画出很多列数据
ax=data.plot.scatter(x='A',y='B',color='DarkBlue',label='class1') #画散点图
data.plot.scatter(x='A',y='C',color='DarkGreen',label='class2',ax=ax)
plt.show()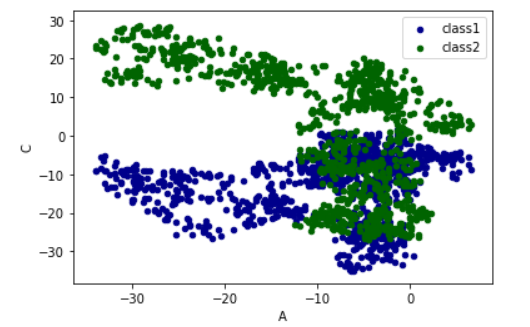
python
data.plot.hist()
plt.show()