📖标题:ProRL Agent: Rollout-as-a-Service for RL Training of Multi-Turn LLM Agents
🌐来源:arXiv, 2603.18815v1
🛎️文章简介
🔸研究问题:现有的多轮大模型智能体强化学习框架中,轨迹生成(Rollout)与策略训练紧密耦合,导致资源利用冲突且系统难以迁移维护,如何解决这一瓶颈?
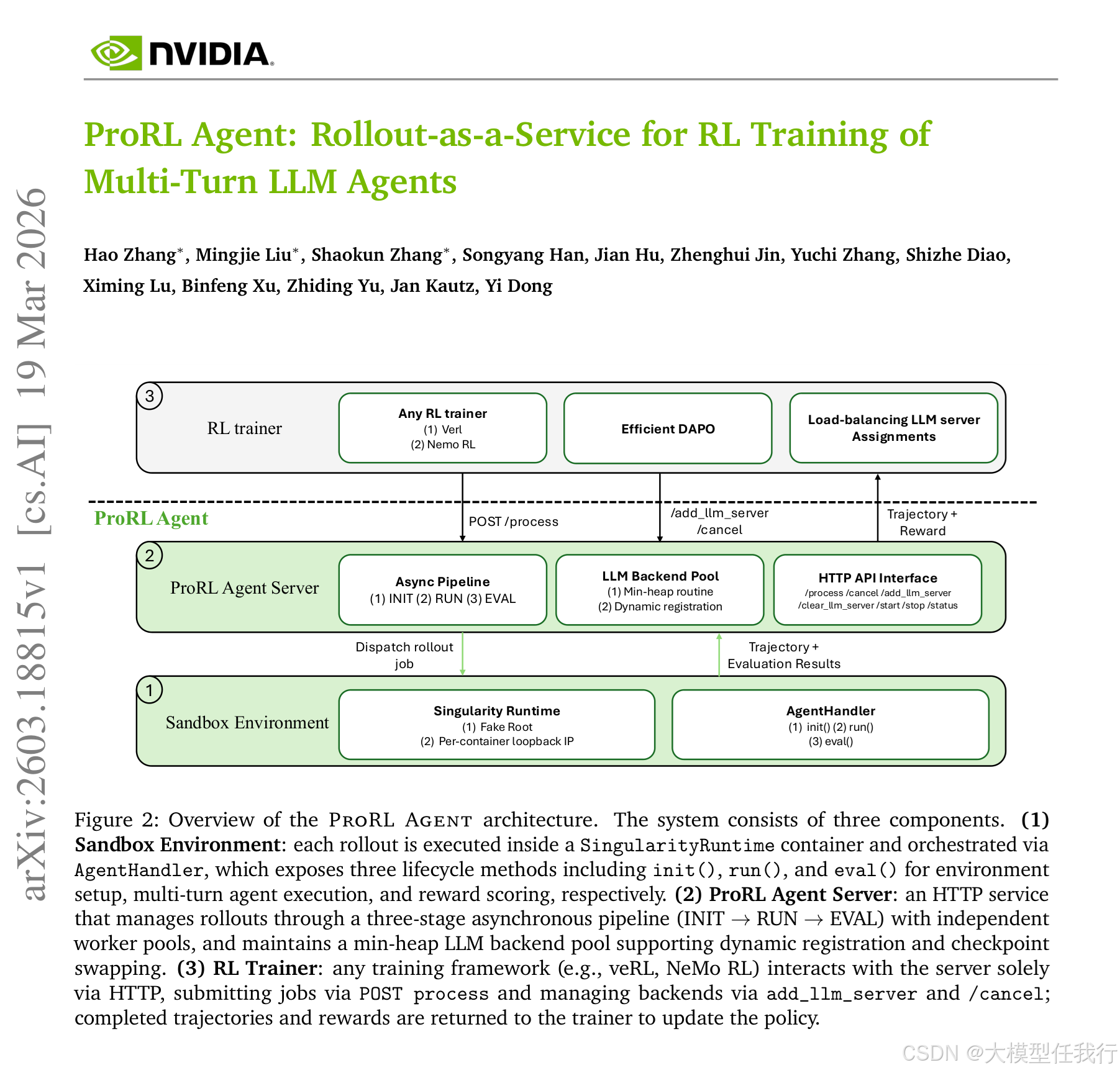
🔸主要贡献:提出了 ProRL Agent,一种基于"推演即服务"理念的可扩展基础设施,通过 HTTP API 将完整的智能体推演生命周期与训练循环彻底解耦。
📝重点思路
🔸采用推演即服务架构,将环境初始化、工具执行、结果评估等推演逻辑封装为独立的 HTTP 服务,使训练器仅需提交任务并接收轨迹,实现计算资源的物理隔离。
🔸设计基于 Singularity 的无根沙箱环境,支持在共享的高性能计算集群中以非特权用户身份运行,解决了传统 Docker 方案在 HPC 环境中的权限限制问题。
🔸实施三阶段异步流水线(初始化、运行、评估),为每个阶段分配独立的工作线程池,避免慢速阶段阻塞整体流程,最大化并发吞吐量。
🔸引入 Token-in/Token-out 通信机制,直接在训练管线中传递 Token ID 而非文本,消除了重新分词带来的分布漂移,确保训练数据的精确性。
🔸优化底层工具后端,利用伪终端替代 tmux 执行 Bash 命令,通过进程内 API 连接 IPython 内核,并使用 Unix 域套接字进行通信,显著降低单步动作延迟。
🔎分析总结
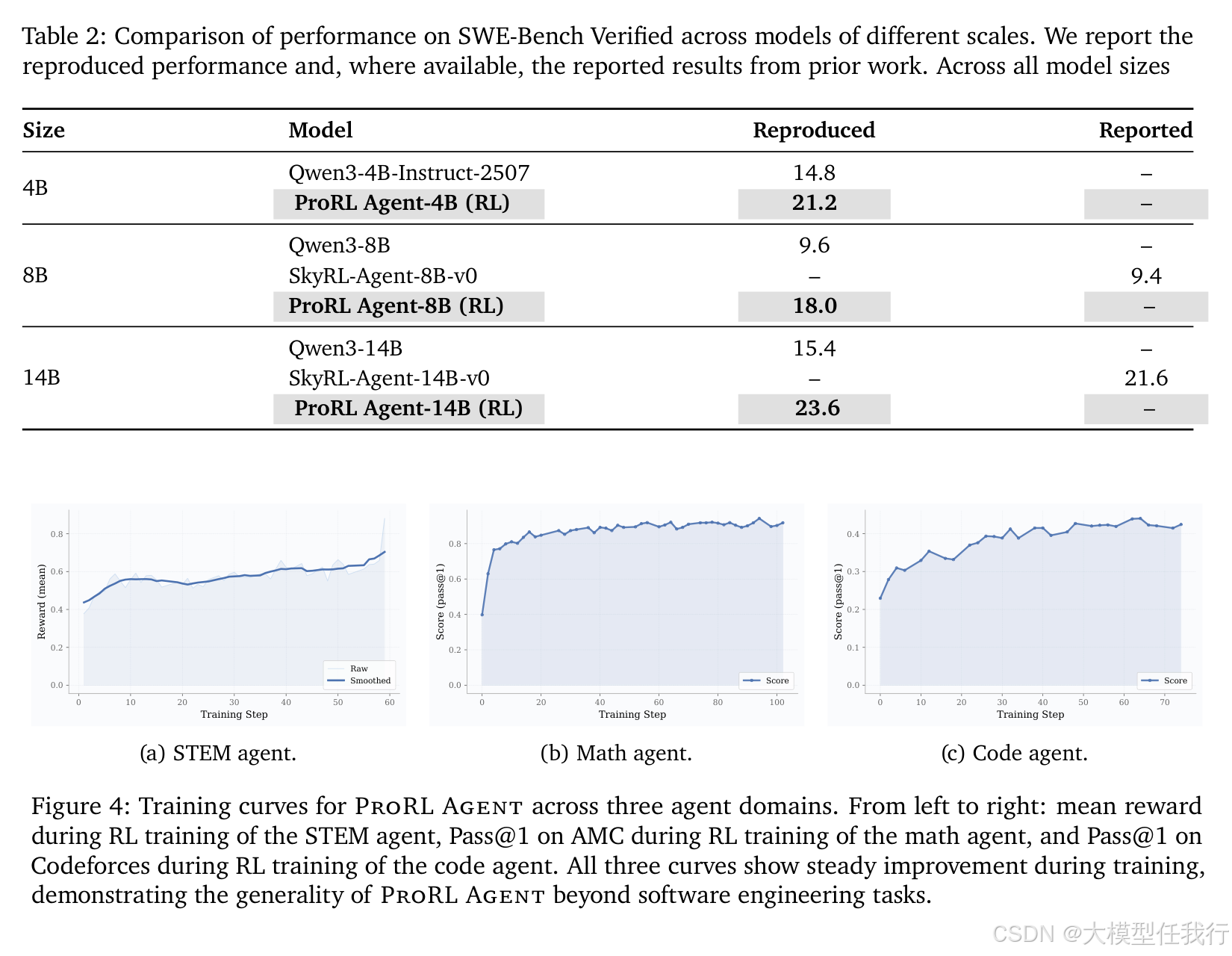
🔸在软件工程任务上的实验表明,ProRL Agent 在不同规模模型(4B 至 14B)上均显著优于现有框架,特别是在 8B 模型上实现了近两倍的性能提升。
🔸该系统具有良好的通用性,不仅在代码任务中表现优异,在需要网页搜索的 STEM 任务、依赖数学计算的 Math 任务以及代码生成的 Code 任务中均展现出稳定的训练收益。
🔸可扩展性测试显示,随着计算节点数量的增加,系统的推演吞吐量呈近乎线性的增长,证明其能有效利用大规模集群资源。
🔸消融实验证实,负载均衡策略、高效的 Bash 执行优化以及陈旧任务清理机制是提升 GPU 利用率和减少动作执行时间的关键因素。
💡个人观点
论文将高 I/O 消耗的推演过程独立化为微服务,解决了异构资源争抢的痛点。
🧩附录