
优化思想
之前我们提到过,这是神经网络的正向传播过程。但很明显,这并不是神经网络算法的全流程,这个流程虽然可以输出预测结果,但却无法保证神经网络的输出结果与真实值接近。
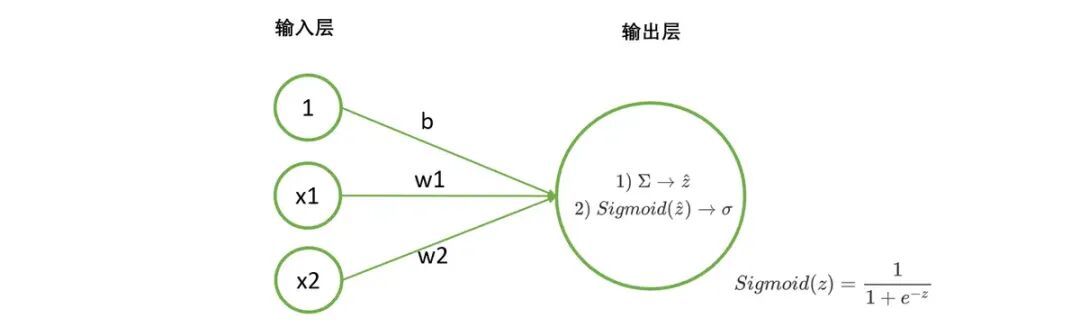
那我就来讲解一下模型训练的全过程。
(1)提出基本模型,明确目标 我们的基本模型就是我们自建的神经网络架构,我们需要求解的就是神经网络架构中的权重向量。 (2)确定损失函数/目标函数 我们需要定义某个评估指标,用以衡量模型权重为w的情况下,预测结果与真实结果的差异。当真实值与预测值差异越大时,我们就认为神经网络学习过程中丢失了许多信息,丢失的这部分被形象地称为"损失",因此评估真实值与预测值差异的函数被我们称为"损失函数"。 3)确定适合的优化算法 4)利用优化算法,最小化损失函数,求解最佳权重(训练)
回归优化算法:误差平方和SSE
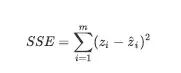
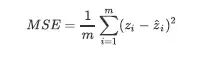
go
import torch
from torch.nn import MSELoss
yhat = torch.randn(size=(50,),dtype=torch.float32)
y = torch.randn(size=(50,),dtype=torch.float32)
criterion =MSELoss() #实例化
loss = criterion(yhat,y)
#在MSELoss中有重要的参数,reduction
#当reduction = "mean" (默认也是mean),则输出MSE
#当reduction = "sum",则输出SSE
criterion = MSELoss(reduction = "mean") #实例化
criterion(yhat,y)
criterion = MSELoss(reduction = "sum")
criterion(yhat,y)
print(loss)二分类交叉熵损失函数
推导过程大家自己学习。
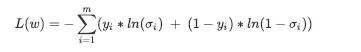
对于二分类交叉熵损失,nn提供了两个类:BCEWithLogitsLoss以及BCELoss。虽然PyTorch官方没有直接明确,但实际上两个函数所需要输入的参数不同。
BCEWithLogitsLoss内置了sigmoid函数与交叉熵函数,它会自动计算输入值的sigmoid值,因此需要输入zhat与真实标签,且顺序不能变化,zhat必须在前。
相对的,BCELoss中只有交叉熵函数,没有sigmoid层,因此需要输入sigma与真实标签,且顺序不能变化。
同时,这两个函数都要求预测值与真实标签的数据类型以及结构(shape)必须相同,否则运行就会报错。
go
import torch
import torch.nn as nn
X = torch.rand((500,4),dtype=torch.float32)
w = torch.rand((4,1),dtype=torch.float32,requires_grad=True)
y = torch.randint(low=0,high=2,size=(500,1),dtype=torch.float32)
zhat = torch.mm(X,w)
sigma = torch.sigmoid(zhat)
criterion1 = nn.BCELoss()
loss1 = criterion1(sigma, y)
criterion2 = nn.BCEWithLogitsLoss()
loss2 = criterion2(zhat, y)
print(loss1,loss2)
#tensor(0.8342, grad_fn=<BinaryCrossEntropyBackward0>) tensor(0.8342, grad_fn=<BinaryCrossEntropyWithLogitsBackward0>)与MSELoss相同,二分类交叉熵的类们也有参数reduction,默认是"mean",表示求解所有样本平均的损失,也可换为"sum",要求输出整体的损失。以及,还可以使用选项"none",表示不对损失结果做任何聚合运算,直接输出每个样本对应的损失矩阵。
多分类交叉熵损失函数
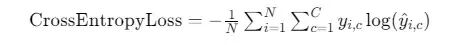
我们可以直接调用CrossEntropyLoss。
go
import torch
import torch.nn as nn
X = torch.rand((500,4),dtype=torch.float32)
w = torch.rand((4,3),dtype=torch.float32,requires_grad=True)
y = torch.randint(low=0,high=3,size=(500,),dtype=torch.long)
zhat = torch.mm(X,w)
criterion1 = nn.CrossEntropyLoss()
loss1 = criterion1(zhat, y)
print(loss1)
# tensor(1.1369, grad_fn=<NllLossBackward0>)这里我们需要注意两点,就是真实标签必须是1维tensor,同时类型必须是整数。这是因为交叉熵损失需要将标签转化为独热形式来进行计算。