文章目录
- 论文信息
- 核心方法
-
- [训练时统一(domain feature unifying,DFU)](#训练时统一(domain feature unifying,DFU))
-
- DFU模块代码解读
-
- 初始化
- 重参数化函数
- 标准差计算函数
- 核心前向传播
-
- 测试模式直接返回
- [自适应计算特征均值 / 标准差](#自适应计算特征均值 / 标准差)
- 滑动平均更新全局统计量
- 概率控制是否执行扰动
- 计算全局分布的标准差
- 重参数化采样
- [特征归一化 + 扰动重构](#特征归一化 + 扰动重构)
- [测试时自适应(uncertainty-guided test-time adaptation,UTTA)](#测试时自适应(uncertainty-guided test-time adaptation,UTTA))
论文信息
名称:
UniAda: Domain Unifying and Adapting Network for Generalizable Medical Image Segmentation
期刊:
IEEE TRANSACTIONS ON MEDICAL IMAGING
年份:
2025.5
作者:
Zhongzhou Zhang, Yingyu Chen, Hui Yu, Zhiwen Wang, Shanshan Wang, Fenglei Fan, Hongming Shan, Yi Zhang
图:
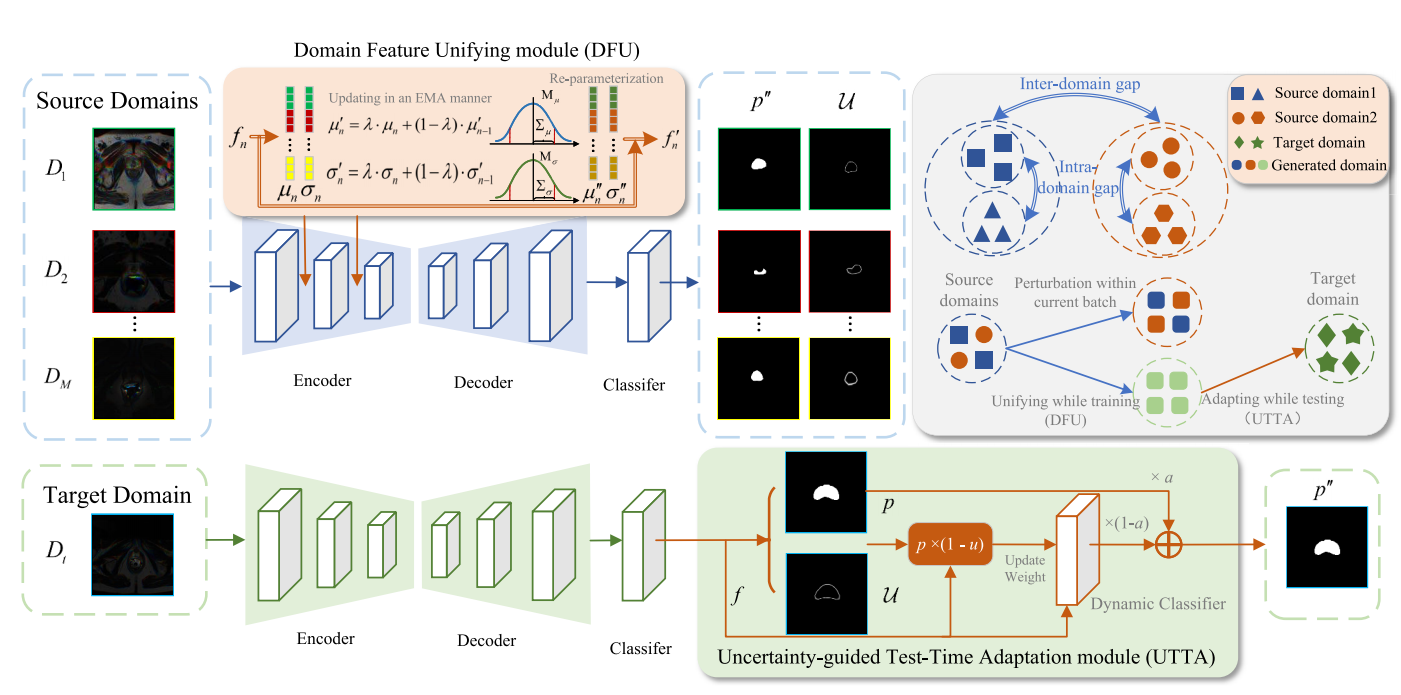
核心方法
训练时统一(domain feature unifying,DFU)
DFU模块代码解读
初始化
python
# 初始化函数:p=启用概率,lambda_=滑动平均系数,eps=防止除0的极小值
def __init__(self, p=0.5, lambda_=0.1, eps=1e-6):
# 调用父类nn.Module的初始化方法(必须写)
super(DFU, self).__init__()
# 极小值,防止计算标准差时分母为0
self.eps = eps
# 训练时执行特征扰动的概率(默认50%)
self.p = p
# 滑动平均系数,用于更新全局统计量(均值/标准差)
self.lambda_ = lambda_
# 重参数化的缩放因子,固定为1.0
self.factor = 1.0
# 全局滑动平均均值(初始为空)
self.bag_mean = None
# 全局滑动平均标准差(初始为空)
self.bag_std = None| 参数 | 作用 |
|---|---|
| p | 触发DFU的概率 |
| lambda_ | 滑动平均更新权重 |
| eps | 数学安全值,避免 std=0 导致除 0 错误 |
| bag_mean/std | 缓存全局特征均值 / 标准差,跨批次累积 |
重参数化函数
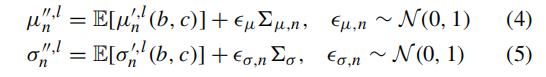
python
# 重参数化技巧:从正态分布 N(mu, std) 采样
def _reparameterize(self, mu, std):
# 生成和std形状相同的标准正态噪声 N(0,1),乘以缩放因子
epsilon = torch.randn_like(std) * self.factor
# 核心公式:z = μ + ε·σ
return mu + epsilon * std数学形式:z=μ+ϵ⋅σ,类比论文公式(4)和公式(5)
作用:
-
给 mean / std 加噪声
-
生成"新域分布参数"
标准差计算函数
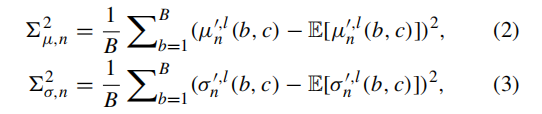
python
# 输入:特征张量 → 输出:特征维度的标准差(广播到原形状)
def sqrtvar(self, x):
# 计算维度0的方差 + eps → 开平方得到标准差
t = (x.var(dim=0, keepdim=True) + self.eps).sqrt()
# 将标准差复制到和输入x相同的行数(广播)
t = t.repeat(x.shape[0], 1)
return t- 输入:
[batch, dim]的均值 / 标准差张量 - 输出:每个维度的全局标准差,用于后续分布采样,类比公式(2)和公式(3)的开方
核心前向传播
若输入为x ∈ B, C, H, W(以下讲解以4维为例)
测试模式直接返回
python
def forward(self, x):
# 【关键】如果是测试/评估模式,直接返回原始特征,不做任何修改
if not self.training:
return x- PyTorch 中
model.eval()会设置self.training=False - 推理时无任何扰动,保证预测稳定
自适应计算特征均值 / 标准差
python
# 判断输入形状:3维 → 序列特征;4维 → 图像/卷积特征
if len(x.shape) == 3:
# 3维输入 [batch, seq_len, dim]:在序列维度求均值/标准差
mean = x.mean(dim=[1], keepdim=False)
std = (x.var(dim=[1], keepdim=False) + self.eps).sqrt()
else:
# 4维输入 [batch, channel, H, W]:在空间维度(H,W)求均值/标准差
mean = x.mean(dim=[2, 3], keepdim=False)
std = (x.var(dim=[2, 3], keepdim=False) + self.eps).sqrt()- 自动兼容序列特征(3 维)和卷积特征(4 维)
- 输出:
mean / std形状均为[B, C]
滑动平均更新全局统计量
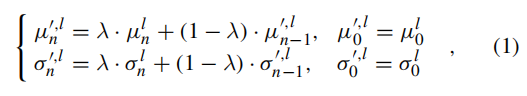
python
# 首次运行:初始化全局均值/标准差
if self.bag_mean is None:
self.bag_mean = mean.detach() # detach():截断梯度,不参与训练
self.bag_std = std.detach()
else:
# 形状匹配时:EMA滑动平均更新(平滑累积)
if self.bag_mean.shape == mean.shape:
self.bag_mean = self.lambda_ * self.bag_mean + (1-self.lambda_) * mean.detach()
self.bag_std = self.lambda_ * self.bag_std + (1 - self.lambda_) * std.detach()
# 形状不匹配时:重置全局统计量
else:
self.bag_mean = mean.detach()
self.bag_std = std.detach()- 滑动平均(EMA):
新值 = λ×旧值 + (1-λ)×当前值,类比公式(1) detach():全局统计量是运行时统计值,不计算梯度- 形状不匹配时直接重置,避免维度错误
self.bag_mean和self.bag_std形状均为[B, C]
概率控制是否执行扰动
python
# 随机概率:大于p则不扰动,直接返回原特征
if (not self.training) or (np.random.random()) > self.p:
return x- 训练时,只有
1-p的概率执行扰动 - 等价于:随机开启 / 关闭特征增强,增强泛化性
计算全局分布的标准差
python
# 计算全局均值的标准差(用于采样beta)
sqrtvar_mu = self.sqrtvar(self.bag_mean)
# 计算全局标准差的标准差(用于采样gamma)
sqrtvar_std = self.sqrtvar(self.bag_std)- 基于累积的全局统计量,计算分布的不确定性
sqrtvar_mu和sqrtvar_std的形状均为[B, C]
重参数化采样
python
# 采样:beta ~ N(当前均值, 全局均值分布)
beta = self._reparameterize(mean, sqrtvar_mu)
# 采样:gamma ~ N(当前标准差, 全局标准差分布)
gamma = self._reparameterize(std, sqrtvar_std)- 用重参数化生成随机化的缩放 / 偏移参数
- beta对应论文中的
μ'',gamma对应论文中的σ'' beta和gamma的形状均为[B, C]
特征归一化 + 扰动重构

python
# 3维序列特征:归一化 → 缩放偏移
if len(x.shape) == 3:
# 特征归一化:(x - 均值) / 标准差
x = (x - mean.reshape(x.shape[0], 1, x.shape[2])) / std.reshape(x.shape[0], 1, x.shape[2])
# 特征扰动:x = x * gamma + beta
x = x * gamma.reshape(x.shape[0], 1, x.shape[2]) + beta.reshape(x.shape[0], 1, x.shape[2])
# 4维卷积特征
else:
x = (x - mean.reshape(x.shape[0], x.shape[1], 1, 1)) / std.reshape(x.shape[0], x.shape[1], 1, 1)
x = x * gamma.reshape(x.shape[0], x.shape[1], 1, 1) + beta.reshape(x.shape[0], x.shape[1], 1, 1)
# 返回扰动后的特征
return x- 核心操作:特征标准化 + 随机仿射变换
- 理解:用原均值
μ和标准差σ归一化,再用全局信息扰动后的均值μ''和标准差σ''反归一化 reshape作用:把[B, C]广播到和原特征相同的形状(从[B, C]到[B, C, 1, 1]再广播到[B, C, H, W])- x的形状为
[B, C, H, W]
测试时自适应(uncertainty-guided test-time adaptation,UTTA)
UTTA模块代码解读
测试时自适应核心函数
python
def adjust_conv(output, uncertainty, feat, num_class):输入参数:
output:模型原始预测概率图(维度D1x2xHxW,D1 是切片数,2 是类别数)uncertainty:模型预测的不确定性图(维度D1x1xHxW,值越小越置信)feat:编码器输出的深度特征图(维度D1x256x(H/16)x(W/16),256 是特征通道数)num_class:分类类别数(这里是 2:背景 / 前列腺)
python
uncertainty = (uncertainty<0.2) * uncertainty- 置信度掩码:只保留不确定性 < 0.2 的高置信度区域,其余区域置 0
- 逻辑:
(uncertainty<0.2)生成布尔矩阵,和原值相乘后,只保留低不确定性区域
python
temp_pred = torch.argmax(output, dim=1, keepdim=True) # D1x1xHxWargmax:取概率最大的类别作为硬预测- 维度变化:
D1x2xHxW→D1x1xHxW(去掉了类别维度,每个像素是 0 或 1) keepdim=True:保持维度不变,方便后续广播计算
python
weight_volume = []初始化列表,用于存储每个类别的动态卷积核权重
python
for c in range(num_class):遍历每个类别(c=0 是背景,c=1 是前列腺),分别计算每个类别的卷积核
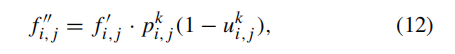
python
uncertainty_temp = F.interpolate((temp_pred == c) * (1 - uncertainty), size=feat.size()[2:], mode="bilinear", align_corners=True)核心:
(temp_pred == c):生成布尔矩阵,只有预测为类别c的像素是True* (1 - uncertainty):乘以置信度(1 - 不确定性),高置信度区域值接近 1,类比公式(12)F.interpolate(..., size=feat.size()[2:])- 把置信度图下采样到和特征图
feat一样的大小(H/16 x W/16) mode="bilinear":双线性插值align_corners=True:对齐角落像素,避免偏移
- 把置信度图下采样到和特征图
- 维度变化:
D1x1xHxW→D1x1x(H/16)x(W/16)
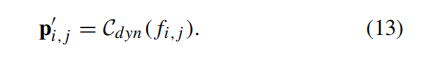
python
weight_volume_temp = F.normalize(torch.mean(uncertainty_temp * feat, dim=(0, 2, 3), keepdim=True), dim=1)这一行计算类别特征中心:
uncertainty_temp * feat,类比公式(12)- 用置信度图对特征图加权(高置信度区域特征权重高)
- 维度:
D1x256x(H/16)x(W/16)
torch.mean(..., dim=(0, 2, 3), keepdim=True)- 在切片维度 (dim0)、高度维度 (dim2)、宽度维度 (dim3)上取平均,类比公式(13)
- 得到全局类别特征中心
- 维度变化:
D1x256x(H/16)x(W/16)→1x256x1x1
F.normalize(..., dim=1):对特征通道维度做 L2 归一化,稳定训练
python
weight_volume.append(weight_volume_temp)把当前类别的权重加入列表
python
weight_volume = torch.cat(weight_volume, dim=0)- 在类别维度 (dim0)拼接所有类别的权重
- 维度变化:
[1x256x1x1, 1x256x1x1]→2x256x1x1 - 这就是动态生成的新卷积核权重
python
return weight_volume返回动态卷积核
主测试流程函数
基础环境配置
python
def main_test(args):
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpu)设置环境变量,指定使用哪块 GPU
python
model_file = args.model_file
output_path = args.save_path读取预训练模型路径、结果保存路径
测试数据集加载
python
composed_transforms_test = transforms.Compose([
tr.ToTensor_3d()
])定义测试集预处理:只做3D 图像转 PyTorch 张量,不做数据增强
python
db_test = DL.ProstateSegmentation_val(args, base_dir=args.data_dir, phase='test', splitid=args.datasetTest, transform=composed_transforms_test)实例化测试数据集:
base_dir:数据根目录phase='test':测试模式splitid:测试集折 ID(比如交叉验证的第 1 折)
python
batch_size = 1
test_loader = DataLoader(db_test, batch_size=batch_size, shuffle=False, num_workers=1)测试数据加载器:
batch_size=1:必须是 1,因为要处理单个 3D 体积shuffle=False:测试集不打乱顺序num_workers=1:单线程加载
模型构建与权重加载
python
model = DeepLab(num_classes=2, backbone='mobilenet', output_stride=args.out_stride, sync_bn=args.sync_bn, freeze_bn=args.freeze_bn).cuda()构建 DeepLabv3 + 分割模型:
num_classes=2:二分类(背景 / 前列腺)backbone='mobilenet':轻量级骨干网络(速度快)output_stride=16:输出步长(决定特征图分辨率).cuda():模型搬到 GPU
python
if torch.cuda.is_available():
model = model.cuda()双重保险:如果 GPU 可用,再次把模型搬到 GPU
python
print('==> Loading %s model file: %s' % (model.__class__.__name__, model_file))打印日志:提示正在加载模型
python
checkpoint = torch.load(model_file)加载预训练模型文件(.pth 或 .tar),包含模型权重、优化器状态等
python
pretrained_dict = checkpoint['model_state_dict']从 checkpoint 中提取模型权重字典
python
model_dict = model.state_dict()获取当前模型的空权重字典(结构匹配)
python
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}- 权重过滤:只保留预训练模型中和当前模型结构匹配的权重键值对
- 避免因结构不一致导致的加载错误
python
model_dict.update(pretrained_dict)用预训练权重覆盖当前模型的空权重
python
model.load_state_dict(model_dict)把合并后的权重加载到模型中
模型模式设置
python
if args.movingbn:
model.train()
else:
model.eval()设置模型模式:
model.eval():推理模式(关闭 Dropout、固定 BatchNorm 统计量)- 如果
args.movingbn=True,则设为train()模式(用测试样本更新 BatchNorm,特殊技巧)
初始化评估指标与变量
python
val_dice = []
val_asd = []
val_hd95 = []
timestamp_start = datetime.now(pytz.timezone('Asia/Hong_Kong'))-
初始化列表,用于存储每个测试样本的:Dice 系数(重叠度),ASD(平均表面距离)和HD95(95% 豪斯多夫距离)
-
记录测试开始时间(带时区,避免时间混乱)
python
weight = F.normalize(model.state_dict()["decoder.last_conv.weight"], dim=1)- 提取模型原始分类器卷积核权重 (
decoder.last_conv.weight) - 做 L2 归一化,作为初始权重
- 维度:
2x256x1x1(2 类别,256 输入通道,1x1 卷积核)
测试循环核心
python
for batch_idx, (sample) in tqdm.tqdm(enumerate(test_loader), total=len(test_loader), ncols=80, leave=False):遍历测试集:
tqdm.tqdm(...):显示进度条batch_idx:当前样本索引sample:当前样本的数据字典
python
data = sample['image'] # 1x1x(D1+2)xHxW
target = sample['label'] # 1x2x(D0+2)xHxW
img_name = sample['img_name']从样本字典中提取:
data:3D 输入图像(维度解释:1是 batch,1是通道,D1+2是切片数 + 上下 padding,H/W是高宽)target:3D 金标准标签(2是 one-hot 编码的背景 / 前景)img_name:图像文件名
python
if torch.cuda.is_available():
data, target = data.cuda(), target.cuda()把数据和标签搬到 GPU
python
pred_3d = torch.zeros_like(target).cuda() # 1x2x(D0+2)xHxW初始化 3D 预测结果张量(和标签同维度,全 0)
python
pred_3d[:, 0, ...] = 1 # background把背景通道(第0通道)初始化为1(默认所有像素都是背景)
3D转2.5D切片处理
python
data_slice = []初始化列表,存储2.5D切片
python
for s in range(0, data.shape[2]-2):遍历 3D 图像的有效切片(去掉上下各 1 层 padding,所以 data.shape[2]-2)
python
slic = data[:, 0, s:s+3, ...] # 1x3xHxW2.5D核心操作:
-
取连续 3 张切片(
s:s+3)作为输入 -
模拟层间上下文信息,比纯2D效果好
-
维度变化:
1x1x3xHxW→1x3xHxW(把3个切片当作3个通道)
python
data_slice.append(slic)把当前2.5D切片加入列表
python
data_slice = torch.cat(data_slice, dim=0) # Dx3xHxW-
在batch 维度(dim0)拼接所有 2.5D 切片
-
维度变化:
D1个1x3xHxW→D1x3xHxW(D1 是有效切片数) -
现在可以一次性送入模型推理(并行计算,速度快)
模型推理(前向传播)
python
with torch.no_grad():
output, feat = model(data_slice, None) # Dx2xHxW-
with torch.no_grad():推理核心,关闭梯度计算(省显存、提速) -
模型输出:
output:分割预测 logits(维度D1x2xHxW)feat:编码器输出的深度特征图(维度D1x256x(H/16)x(W/16))
证据推理与不确定性计算
python
output = torch.tanh(output) # D1x2xHxW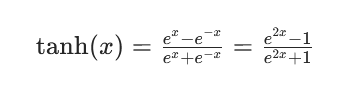
用 tanh 把 logits 压缩到 [-1, 1],为证据推理做准备
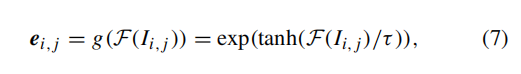
python
evidence = torch.exp(output / 0.25) # D1x2xHxW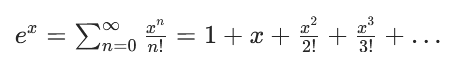
证据计算:
- 指数化得到证据(正数)
0.25是温度系数,控制证据的尖锐程度- 证据越大,模型对预测越有把握
- 类比公式(7)
python
alpha = evidence + 1 # D1x2xHxW计算狄利克雷分布的参数 alpha(证据 + 1)
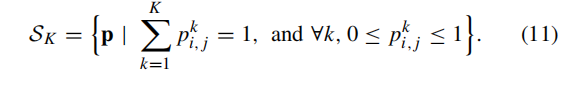
python
S = torch.sum(alpha, dim=1, keepdim=True) # D1x1xHxW计算 S(所有类别 alpha 的和),代表总证据量,类比公式(11)
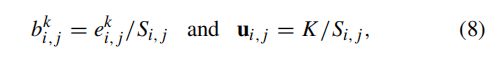
python
uncertainty = 2 / S # D1x1xHxW不确定性计算:
-
总证据量
S越大,不确定性越小 -
维度:
D1x1xHxW(每个像素一个不确定性值) -
类比公式(8)
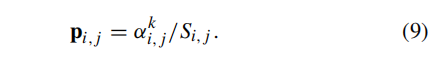
python
output1 = alpha / S # D1x2xHxW-
计算归一化概率(狄利克雷分布的均值)
-
这是模型的原始预测概率
-
类比公式(9)
测试时自适应(TTA)优化
python
alpha = 0.5
beta = 0.5超参数:
alpha:原始预测output1和自适应预测output2的融合权重beta:原始权重weight和动态权重weight_volume的滑动平均权重
python
feat = F.normalize(feat, dim=1) # D1x256x(H/16)x(W/16)对深度特征图做L2归一化(稳定动态权重计算)
python
weight_volume = adjust_conv(output1, uncertainty, feat, 2)-
调用前面讲的
adjust_conv函数,计算动态卷积核权重 -
输入:原始预测、不确定性、特征图
-
输出:动态卷积核(
2x256x1x1)
python
weight = beta * weight + (1 - beta) * weight_volume if batch_idx > 0 else weight_volume滑动平均更新权重:
- 如果是第 1 个样本(
batch_idx=0),直接用动态权重 - 否则,用
beta加权平均历史权重和当前动态权重 - 目的:平滑权重更新,避免单个样本的噪声影响
python
output2 = F.conv2d(feat, weight, stride=1, padding=0) # D1x2x(H/16)x(W/16)-
用动态卷积核 对特征图做卷积,得到自适应预测
-
维度:
D1x256x(H/16)x(W/16)→D1x2x(H/16)x(W/16)
python
output2 = F.interpolate(output2, size=output1.size()[2:], mode="bilinear", align_corners=True) # D1x2xHxW-
把自适应预测上采样 回原始图像分辨率(
HxW) -
双线性插值,对齐角落
python
output1 = torch.sigmoid(output1)
output2 = torch.sigmoid(output2)对原始预测和自适应预测都做 sigmoid,得到 0~1 的概率值
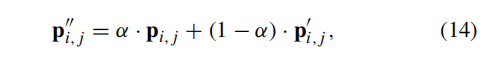
python
output = alpha * output1 + (1 - alpha) * output2融合预测:
alpha=0.5:原始预测和自适应预测各占一半- 得到最终的融合概率图
- 类比公式(14)
3D预测结果拼接
python
# =========================================================================
# 将2.5D切片的预测结果填充回3D体积的有效区域
# output.permute(1, 0, 2, 3): 调整维度顺序 [D1, 2, H, W] -> [2, D1, H, W](类别前置)
# .unsqueeze(0): 增加batch维度 [2, D1, H, W] -> [1, 2, D1, H, W]
# sample['non_zero_idx']: 有效切片在3D体积中的起始/结束索引,只填充有效区域避开padding
# =========================================================================
pred_3d[:, :, sample['non_zero_idx'][0]:sample['non_zero_idx'][1], ...] = output.permute(1, 0, 2, 3).unsqueeze(0) # 1x2x(D0+2)xHxW
# 去除3D预测结果上下各1层的padding切片(只保留核心有效区域)
pred_3d = pred_3d[:, :, 1:-1, ...] # 1x2xD0xHxW
# 同步去除金标准标签的padding切片,保持与预测结果维度一致
target = target[:, :, 1:-1, ...] # 1x2xD0xHxW
# 提取金标准标签的numpy数组(用于后续指标计算)
# target[0]: 去掉batch维度 [1, 2, D0, H, W] -> [2, D0, H, W]
# [1]: 取前景通道(第1通道,背景是第0通道)[2, D0, H, W] -> [D0, H, W]
# .data.cpu().numpy(): 从GPU显存搬运到CPU内存,并转为numpy格式
target_numpy = target[0][1].data.cpu().numpy() # D0xHxW
# 得到硬分割预测结果(0/1二值图)
# torch.argmax(pred_3d, dim=1): 在类别维度取最大值索引,得到0/1预测 [1, 2, D0, H, W] -> [1, D0, H, W]
# [0]: 去掉batch维度 [1, D0, H, W] -> [D0, H, W]
# .data.cpu().numpy(): 转为CPU numpy数组
prediction = torch.argmax(pred_3d, dim=1)[0].data.cpu().numpy() # D0xHxW
# 连通域分析后处理:去除小的孤立噪点,只保留最大的连通域(医学分割常用优化)
prediction = _connectivity_region_analysis(prediction)
# 计算Dice系数(分割重叠度指标,范围0-1,越高越好)
dice = binary.dc(prediction, target_numpy)
# 计算95%豪斯多夫距离(边界距离指标,越小越好)
# 特殊处理:若预测全是背景(无前景),给惩罚值100避免计算错误
hd95 = binary.hd95(prediction, target_numpy) if np.sum(prediction) > 1e-4 else 100
# 计算平均表面距离(边界距离指标,越小越好)
# 同样做空预测惩罚处理
asd = binary.asd(prediction, target_numpy) if np.sum(prediction) > 1e-4 else 100
# 将当前样本的指标存入列表(Dice乘以100转为百分比形式)
val_dice.append(dice*100)
val_hd95.append(hd95)
val_asd.append(asd)
# =========================================================================
# 保存3D分割结果(.nii/.nii.gz等医学图像格式)
# =========================================================================
volume_path = osp.join(output_path, "3d")
# 若3D结果文件夹不存在则创建
if not osp.exists(volume_path):
os.makedirs(volume_path)
# 将numpy预测数组转为SimpleITK医学图像格式
out = sitk.GetImageFromArray(prediction)
# 保存3D图像,文件名从原图像名提取(处理Windows路径的反斜杠)
sitk.WriteImage(out, osp.join(output_path, "3d", img_name[0].split("\\")[-1]))保存2D切片可视化
python
# =========================================================================
# 遍历每个切片,保存2D可视化结果(含原图、预测轮廓、金标准轮廓)
# =========================================================================
for s in range(0, data.shape[0]-2):
# 提取当前切片的原始图像
# data[s+1, ...]: 取中间切片(避开padding)
# [None]: 增加batch维度 [H, W] -> [1, H, W]
img = data[s+1, ...][None]
# 单通道转3通道(重复3次),方便后续彩色可视化
img = torch.cat([img, img, img], dim=0)
# 提取当前切片的金标准标签(索引对齐有效区域)
lt = target_numpy[s + sample['non_zero_idx'][0]-1, ...]
# 提取当前切片的预测标签(索引对齐有效区域)
lp = prediction[s + sample['non_zero_idx'][0]-1, ...]
# 反归一化:将图像从预处理后的张量范围转回原始像素范围(0-255)
img, lt = utils.untransform(img, lt)
# 生成2D可视化图的文件名:原图像名_切片号
save_img_name = img_name[0].split('.')[0] + "_"+str(s)
# 保存可视化结果(叠加原图、预测轮廓、金标准轮廓)
save_per_img_prostate(img.numpy().transpose(1, 2, 0),
output_path,
save_img_name,
lp, lt, mask_path=None, ext="bmp")打印平均指标与保存日志
python
# =========================================================================
# 测试结束,打印所有样本的平均指标±标准差(论文常用结果展示格式)
# =========================================================================
print('\n==>val_avg_dice : {:.4f} + {:.4f}'.format(np.mean(val_dice), np.std(val_dice)))
print('==>val_avg_hd95 : {:.4f} + {:.4f}'.format(np.mean(val_hd95), np.std(val_hd95)))
print('==>val_avg_asd : {:.4f} + {:.4f}'.format(np.mean(val_asd), np.std(val_asd)))
# =========================================================================
# 将测试结果写入CSV日志文件(方便后续Excel分析)
# =========================================================================
with open(osp.join(output_path, 'log.csv'), 'a') as f:
# 计算测试总耗时(秒)
elapsed_time = (
datetime.now(pytz.timezone('Asia/Hong_Kong')) -
timestamp_start).total_seconds()
# 整理日志内容:batch size、模型路径、所有样本的Dice/HD95/ASD、总耗时
log = ['batch-size: '] + [batch_size] + [args.model_file] + \
['val_dice: '] + val_dice + \
['val_hd95: '] + val_hd95 + \
['val_asd: '] + val_asd + [elapsed_time]
# 将所有日志内容转为字符串
log = map(str, log)
# 用逗号分隔,追加写入CSV文件(一行记录一次完整测试)
f.write(','.join(log) + '\n')