
📝 前言
最近在学习大模型的基础知识,为了不让自己只停留在理论层面,决定在本地进行一次完整的实战部署。初衷是想搭建一个类似知识库的AI小助手,尝试将CSDN的文章切片形成RAG(检索增强生成)让模型读取。虽然在RAG环节遇到了不少报错并最终暂时搁置,转而测试了微调方案,但整个环境搭建的过程非常值得记录。
本次教程将手把手教你如何利用Docker、Ollama和Open WebUI,在本地部署属于你自己的AI聊天界面,并通过内网穿透实现公网访问。
🛠️ 准备阶段:环境搭建
1. 下载与安装 Docker
Docker 是容器化的核心工具。Mac用户可以直接通过命令行下载,或者前往官网获取安装包。
- 官网地址: https://www.docker.com
- Mac命令行安装:
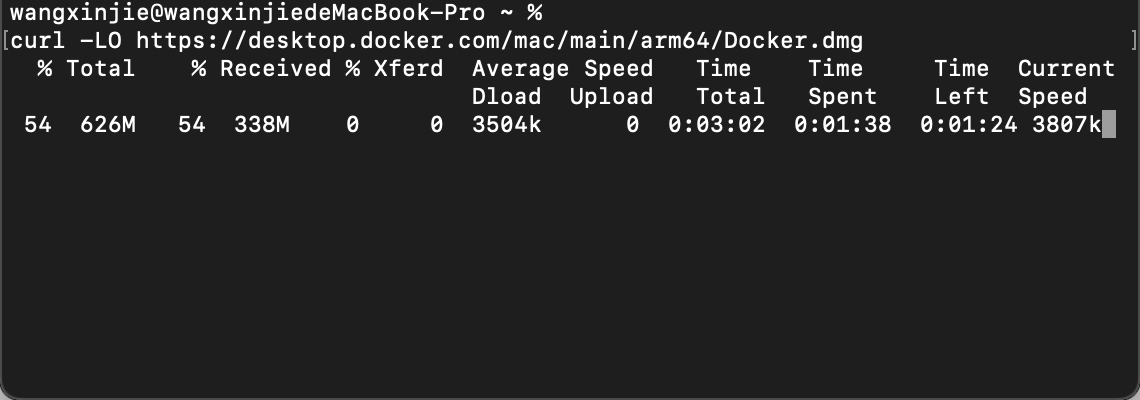 也可以去官网下载
也可以去官网下载
2. 下载 Ollama
Ollama 是一个方便本地运行大模型的工具。
- 下载地址: https://ollama.com/download
- 选择对应系统版本下载安装即可。
3. 安装 Open WebUI
Open WebUI 是一个用户友好的自托管AI平台,支持Ollama。
-
使用 Docker 拉取镜像并运行:
bashdocker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main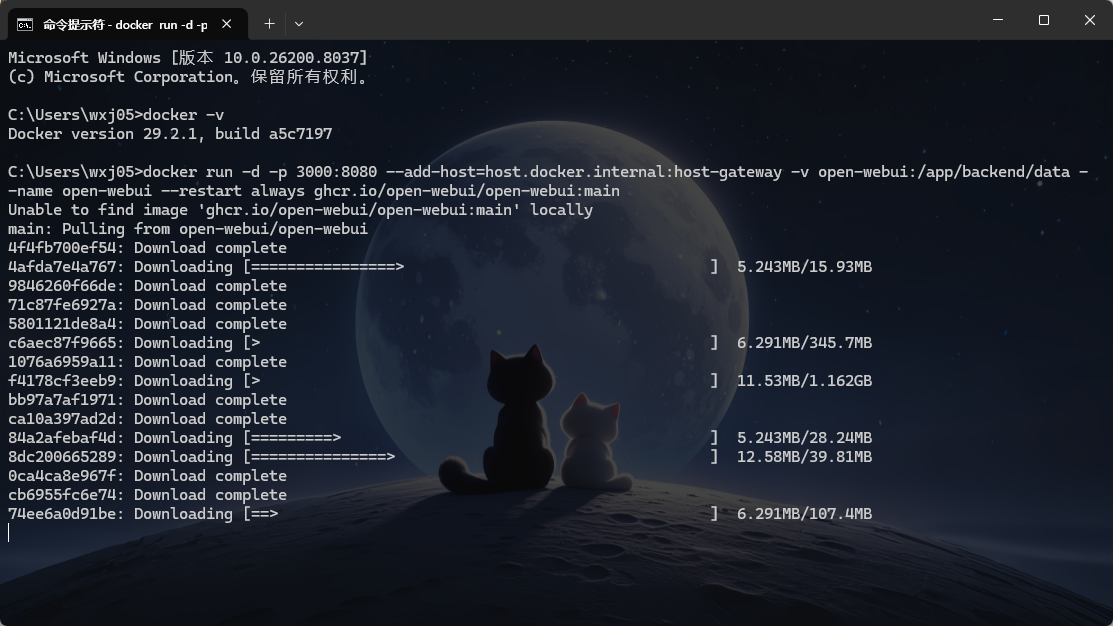
下载完成后,容器应该处于运行状态。
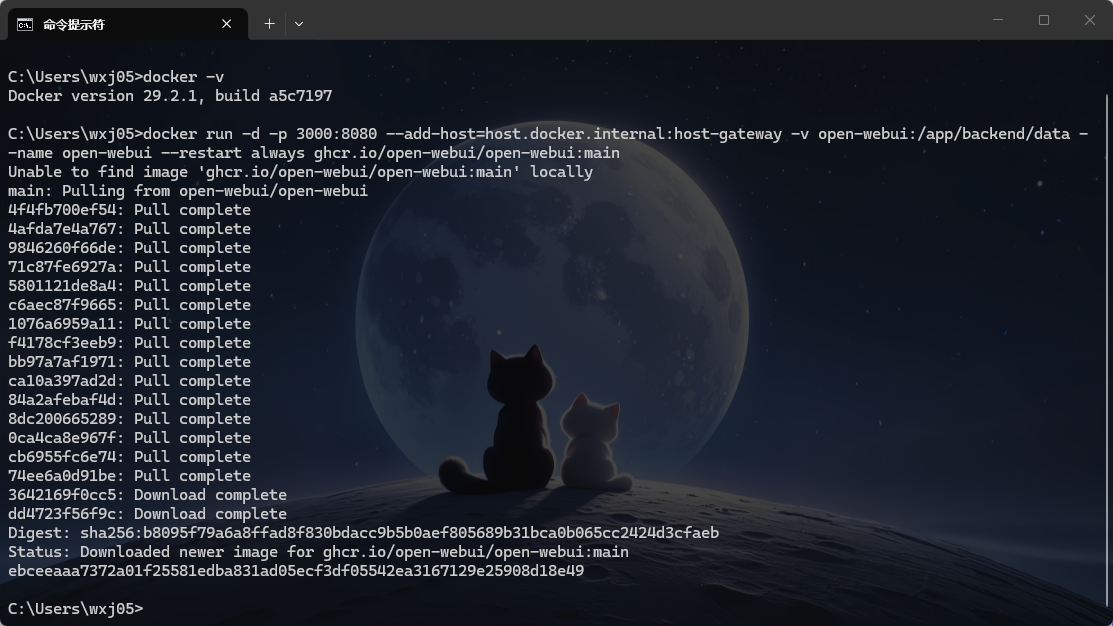
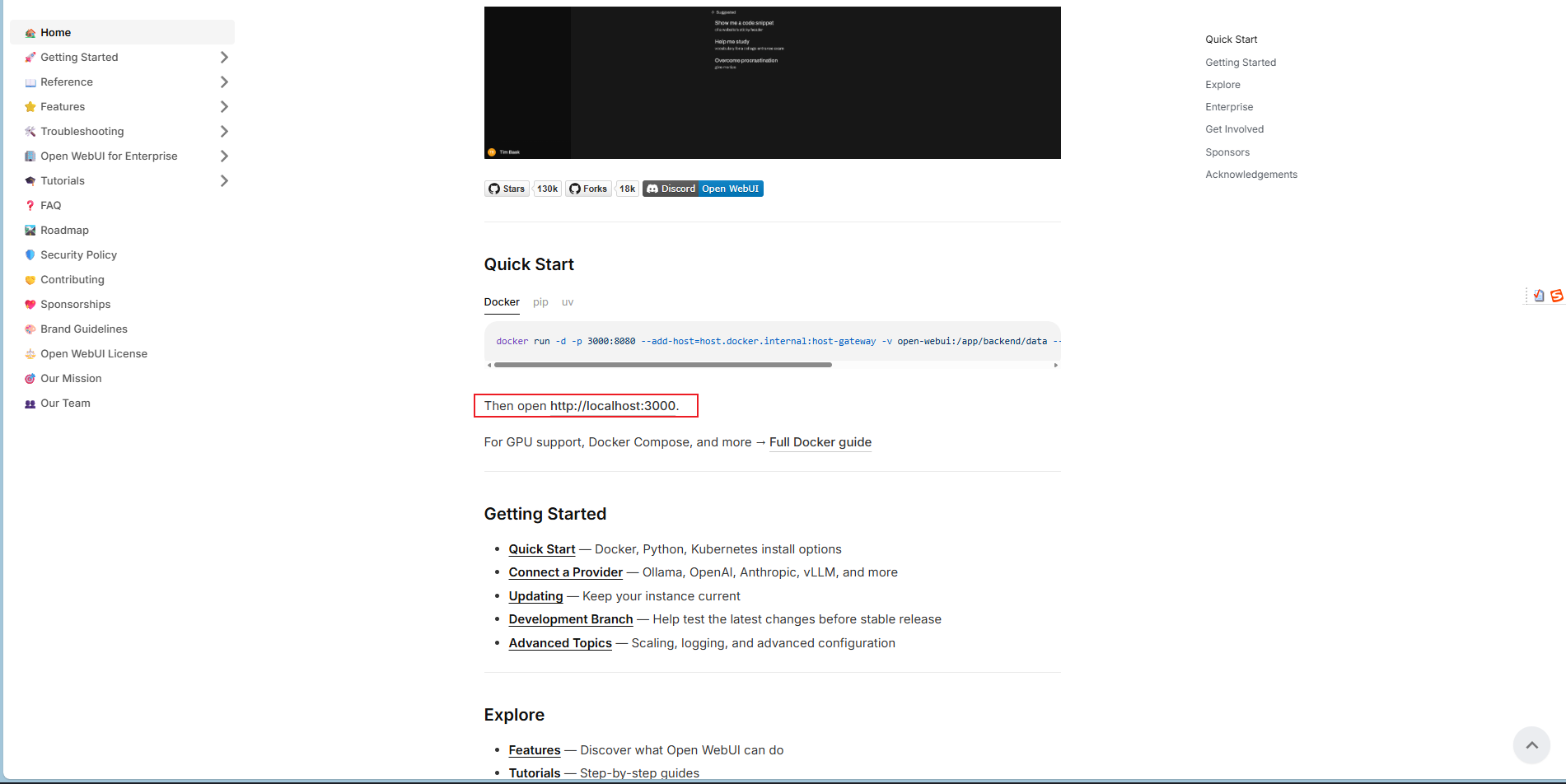
回到说明文档,Open WebUI 默认运行在本地3000端口。
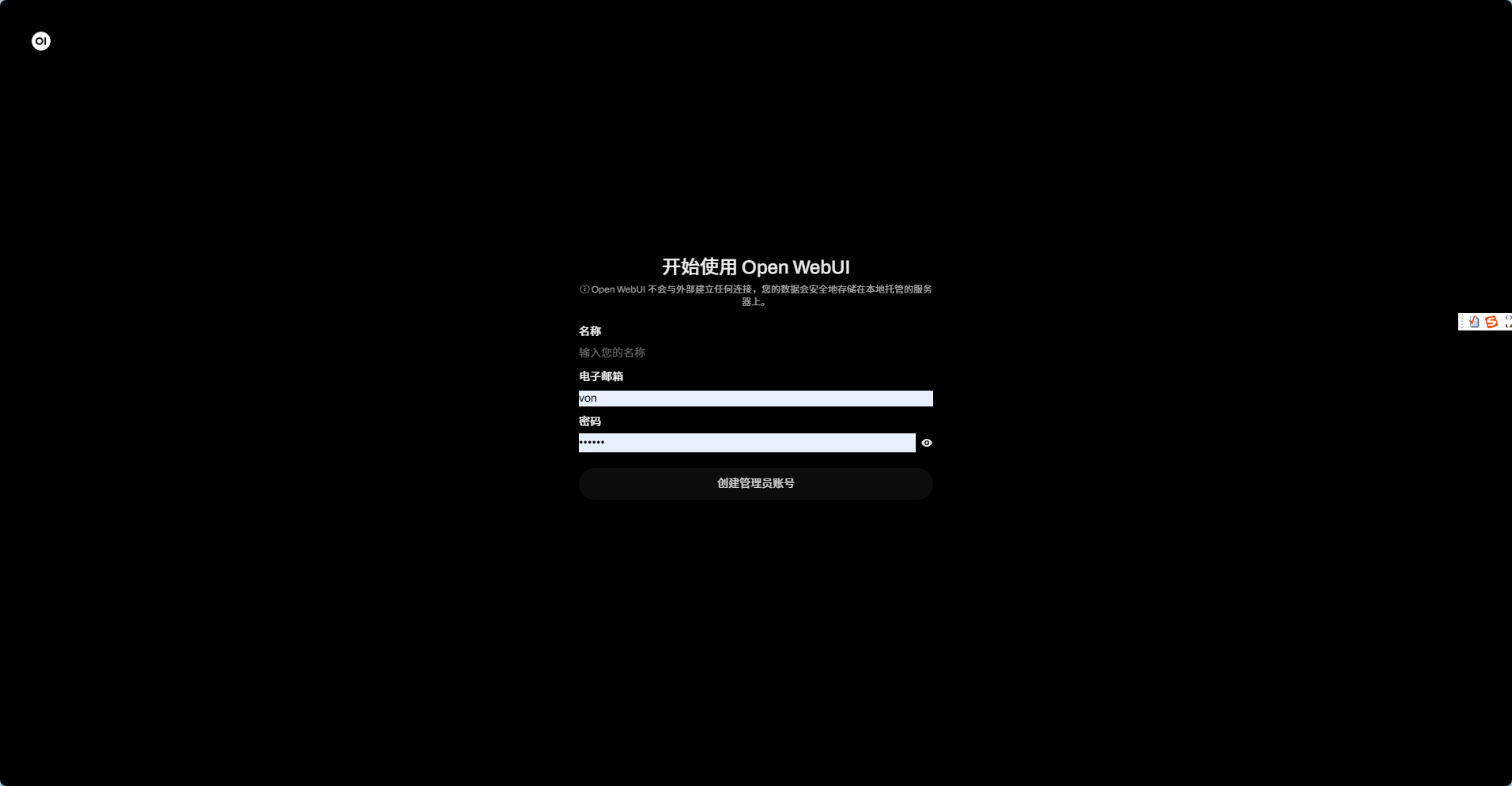
点击 http://localhost:3000 进去后,系统会提示你注册管理员账号。
注册成功后登录界面:
🧠 拉取模型并调试
这一步是核心。如果本地安装了Ollama,可以直接拉取;为了统一管理,我这里继续使用Docker命令。
1. 尝试拉取高性能模型(踩坑记录)
我最初尝试了Gemma4的e4b版本,这是一个性能不错的模型,但体积较大(约9.6G)。
bash
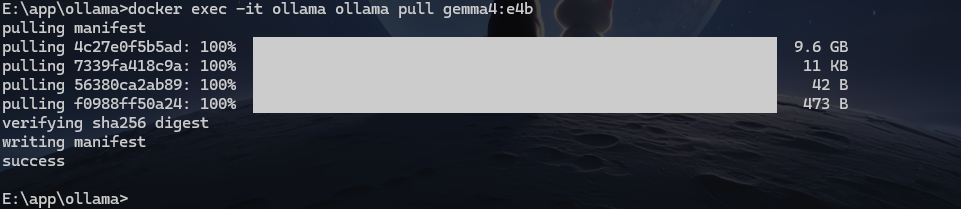
docker exec -it ollama ollama pull gemma4:e4b
⚠️ 警告: 下载这个模型花费了我几个小时,请确保网络环境良好。
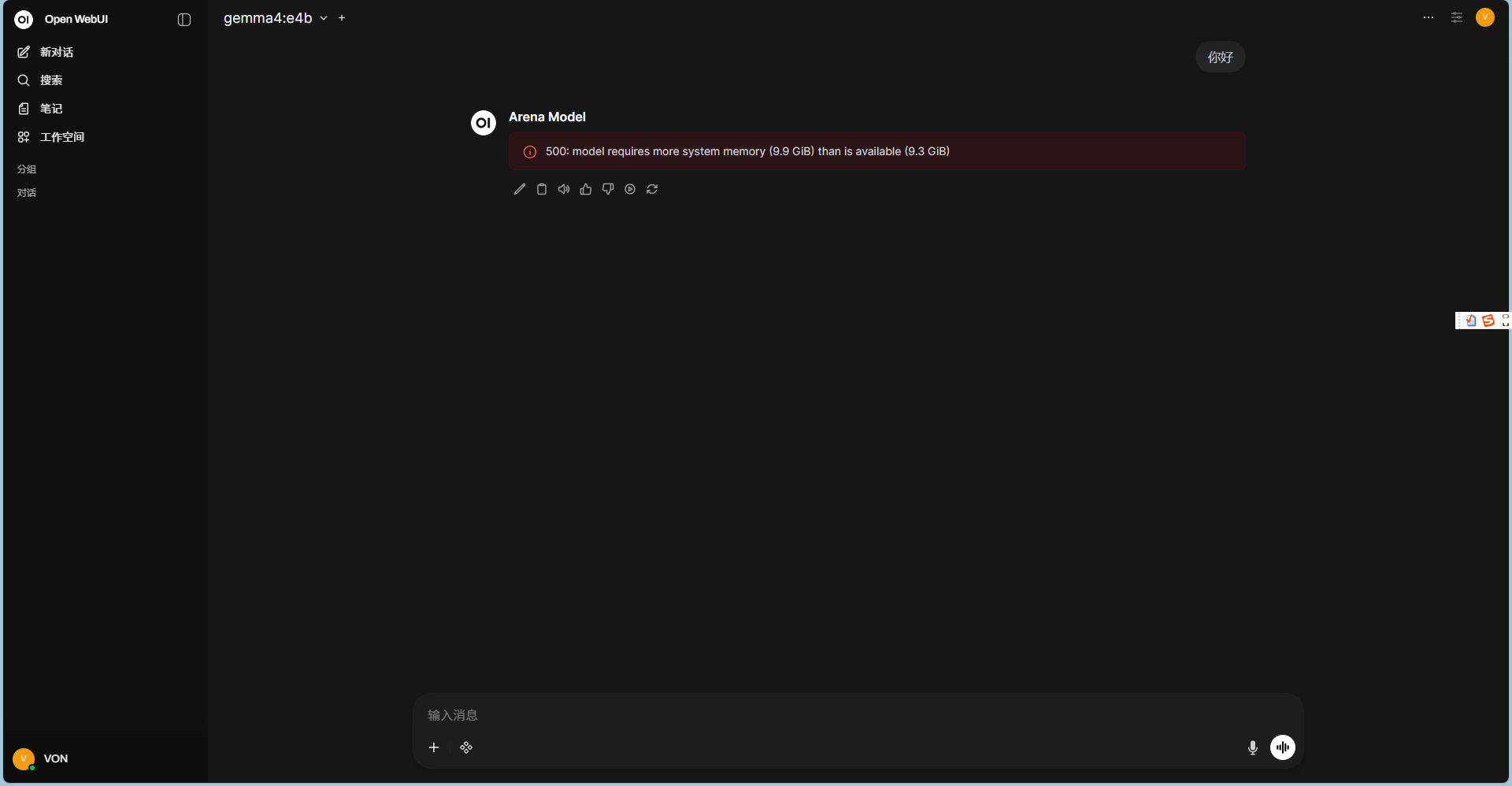
最终因为我的电脑内存不足(报错:model requires more system memory),不得不放弃这个大模型。

2. 改用轻量级模型(推荐方案)
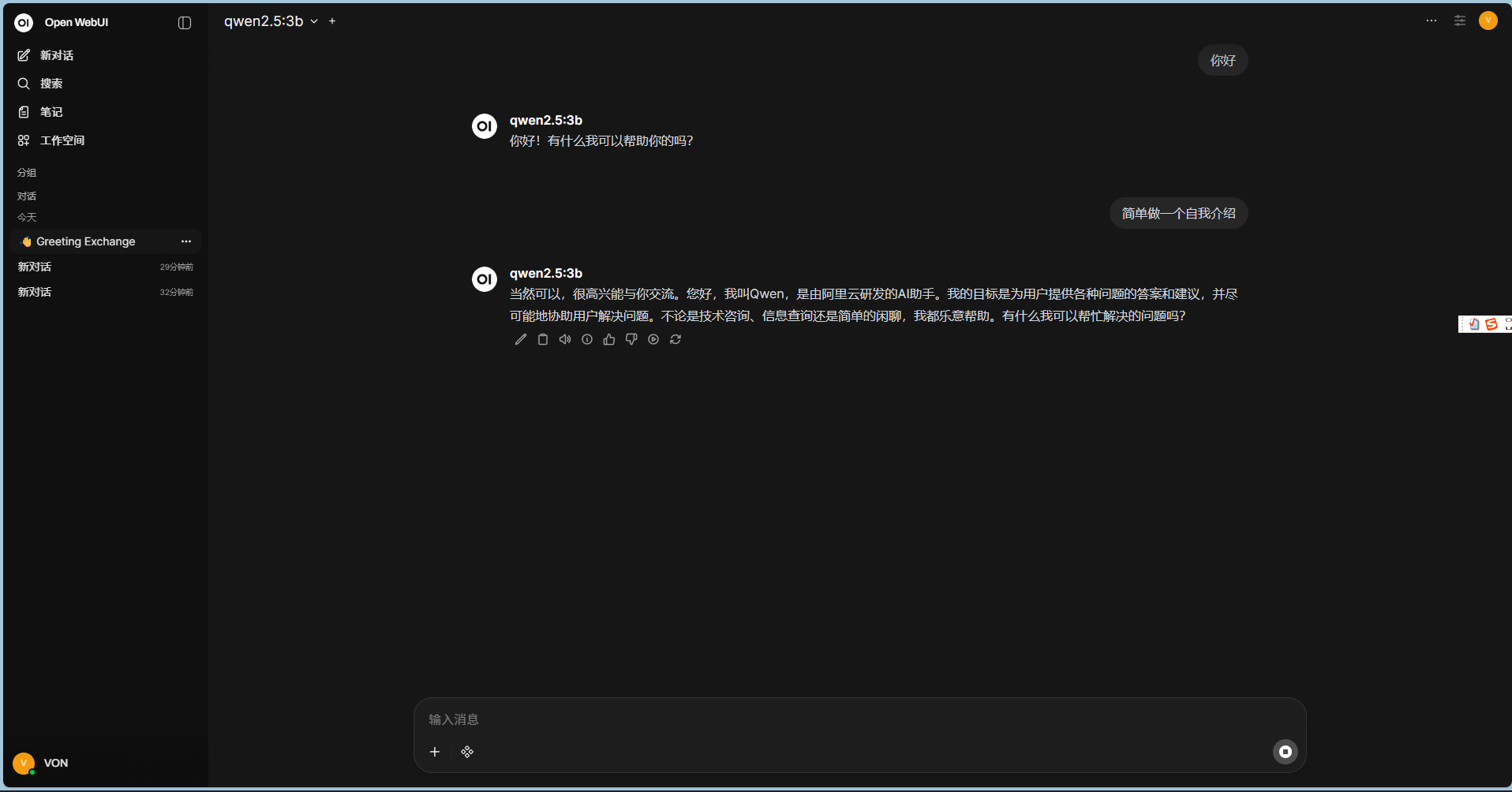
鉴于内存限制,我转而使用通义千问的轻量版 qwen2.5:3b,非常适合普通电脑部署。
bash
docker exec -it ollama ollama pull qwen2.5:3b下载过程:

下载成功:

回到 Open WebUI 测试一下,这下终于可以正常对话了!
🌐 内网穿透:让AI走出本地
为了让别人也能在公网访问你的AI,我们需要使用 cpolar 进行内网穿透。
1. 注册与安装
- 官网: https://www.cpolar.com/ (免费版足够测试使用)
- 下载 Windows 版并安装(无脑下一步即可)。
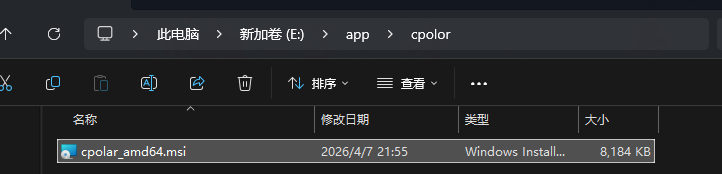
安装完成后修改安装路径(可选)。
2. 配置隧道
- 打开 cpolar 客户端,登录注册账号。
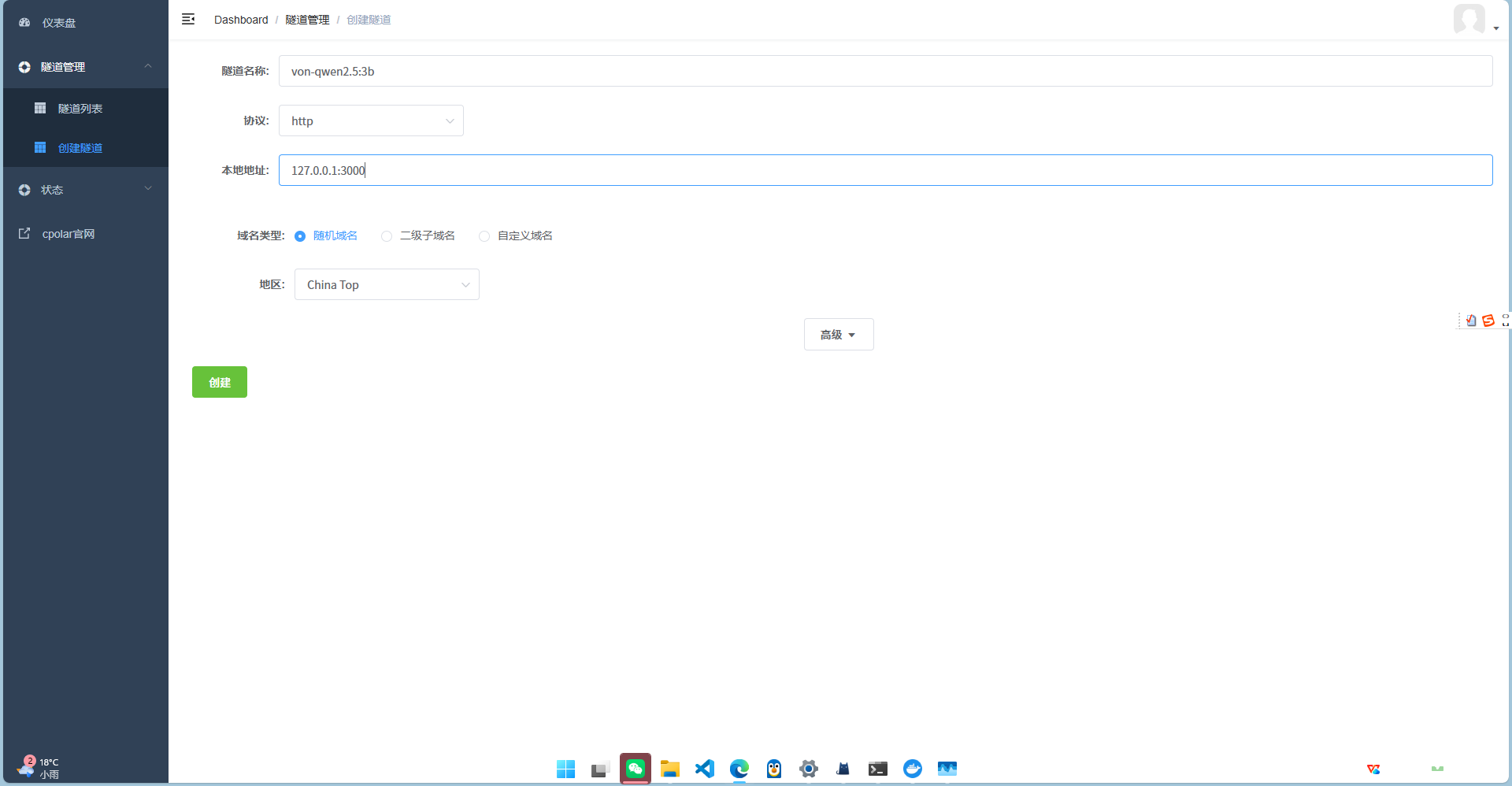
- 创建隧道(关键步骤):
- 隧道名称: ollama-webui (自定义)
- 协议: http
- 本地地址: 127.0.0.1:3000 (对应 Open WebUI 端口)
- 地区: 选 cn (国内节点)
- 启动隧道,你会获得一个公网地址。
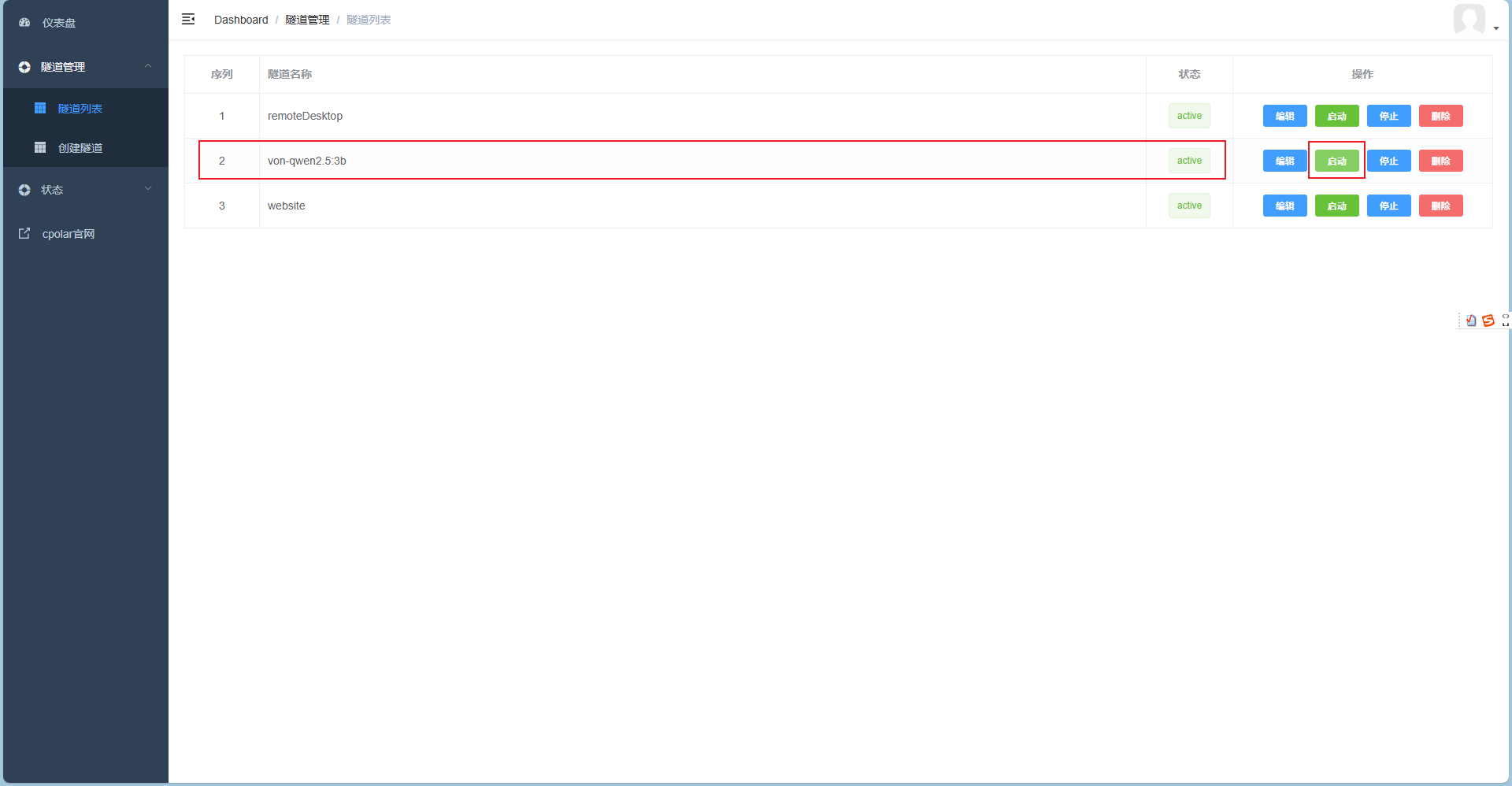
3. 公网访问
将生成的公网地址(例如 https://xxxx.cpolar.cn)发给别人。
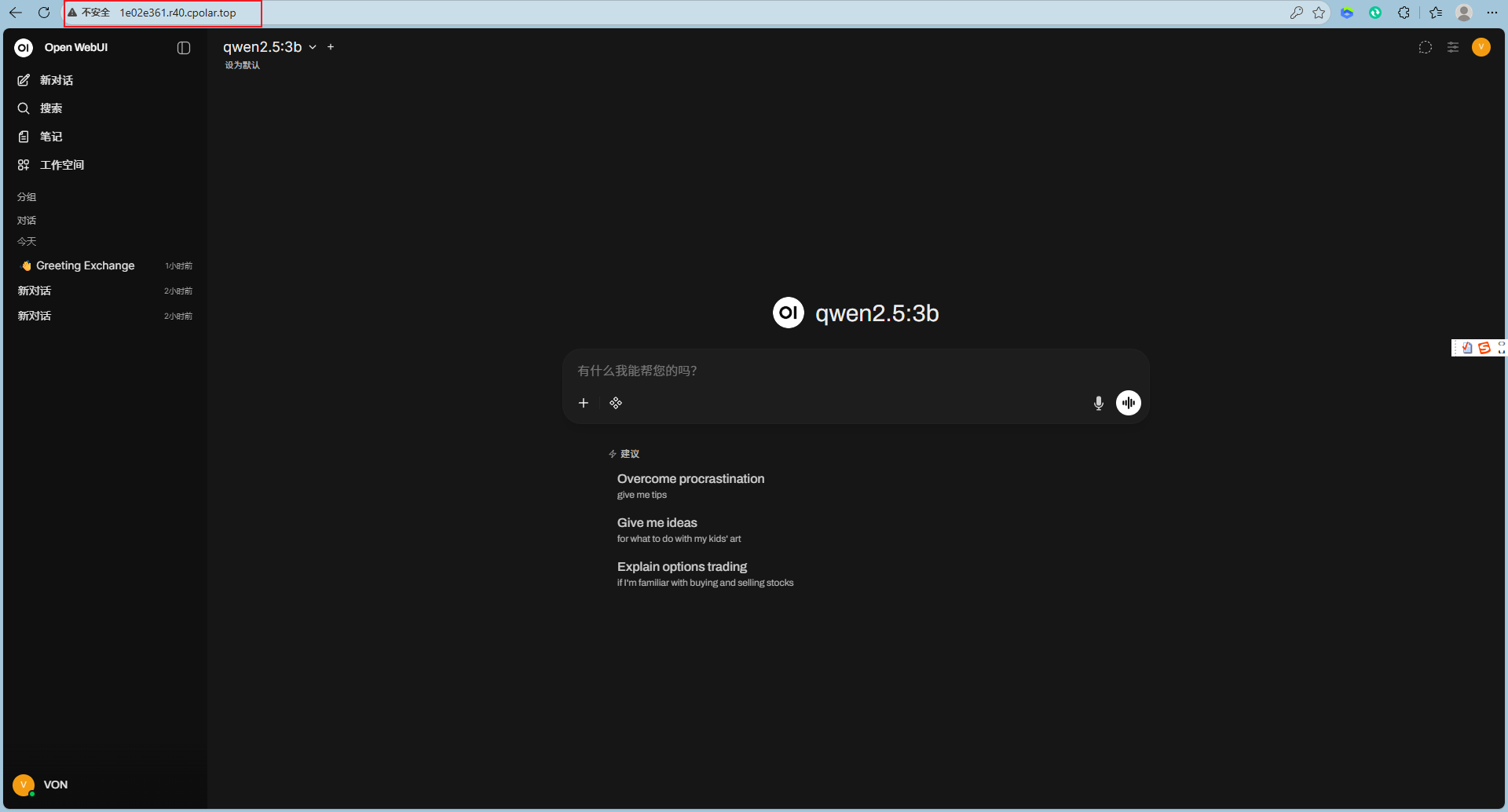
别人在任何网络环境下,打开浏览器访问该链接,就能直接使用你电脑上的 qwen2.5:3b 进行聊天了。
- 映射原理:
Forwarding https://xxxx.cpolar.cn -> http://localhost:3000 - 在线隧道列表查看:
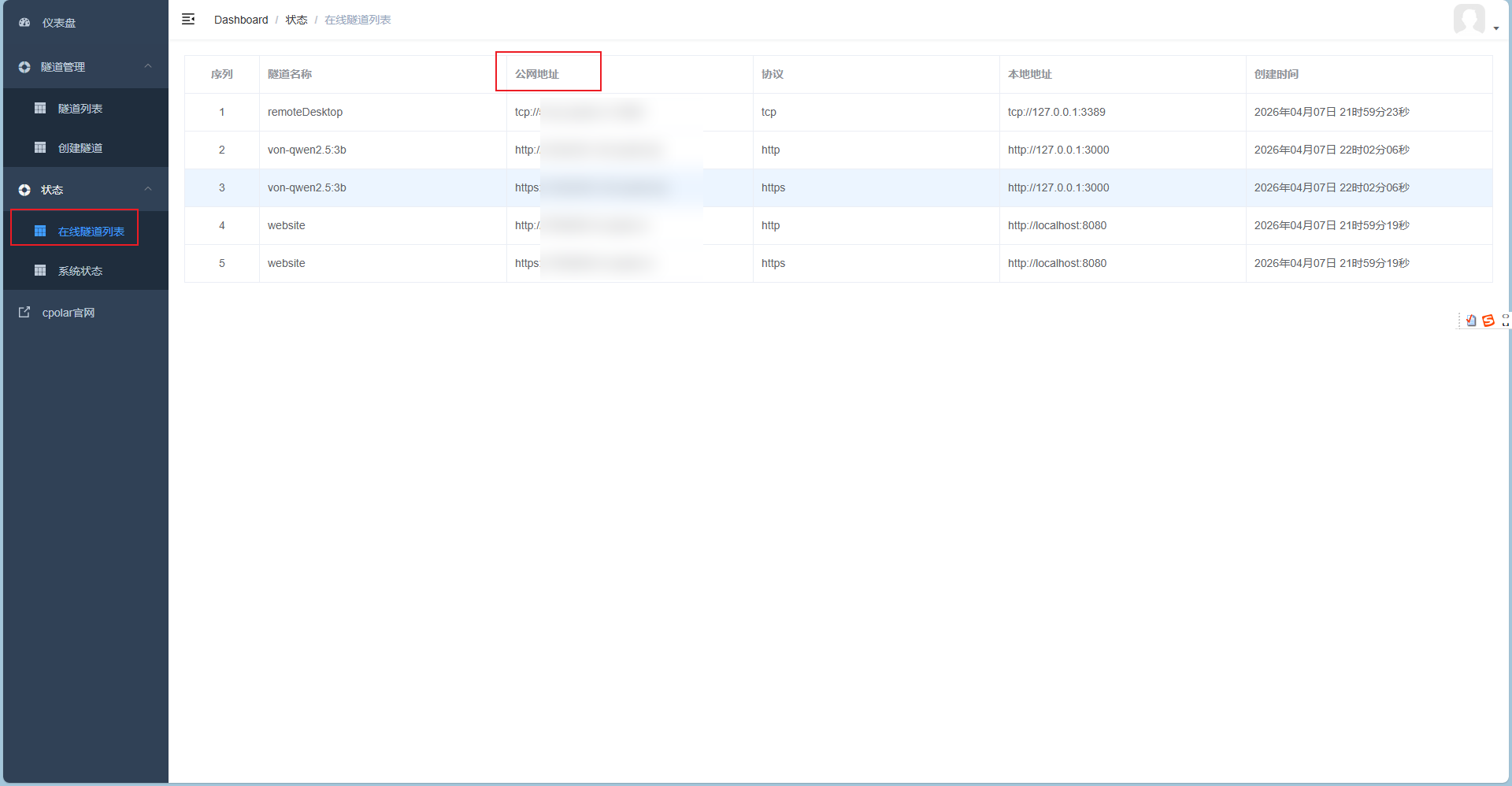
最终效果:
🛑 常见错误与解决方案
在部署过程中,我遇到了几个典型问题,记录下来供大家避坑。
1. Ollama 无法下载或拉取镜像
如果遇到网络问题导致无法下载 Ollama 或模型,可以使用 DaoCloud 的镜像源。
bash
# 拉取镜像(使用国内源)
docker pull docker.m.daocloud.io/ollama/ollama:latest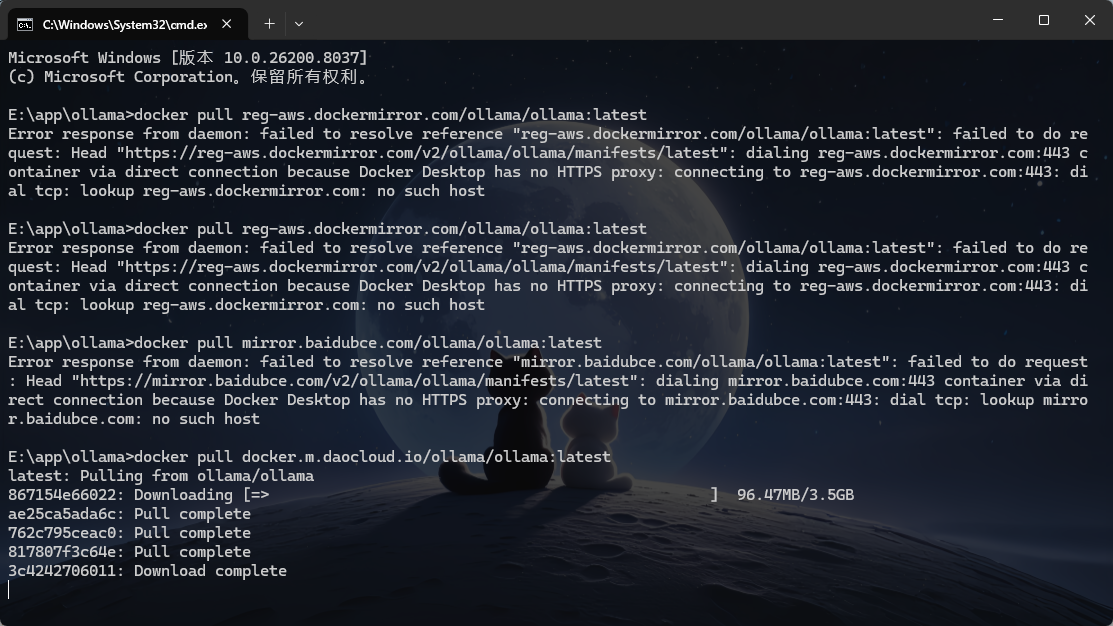
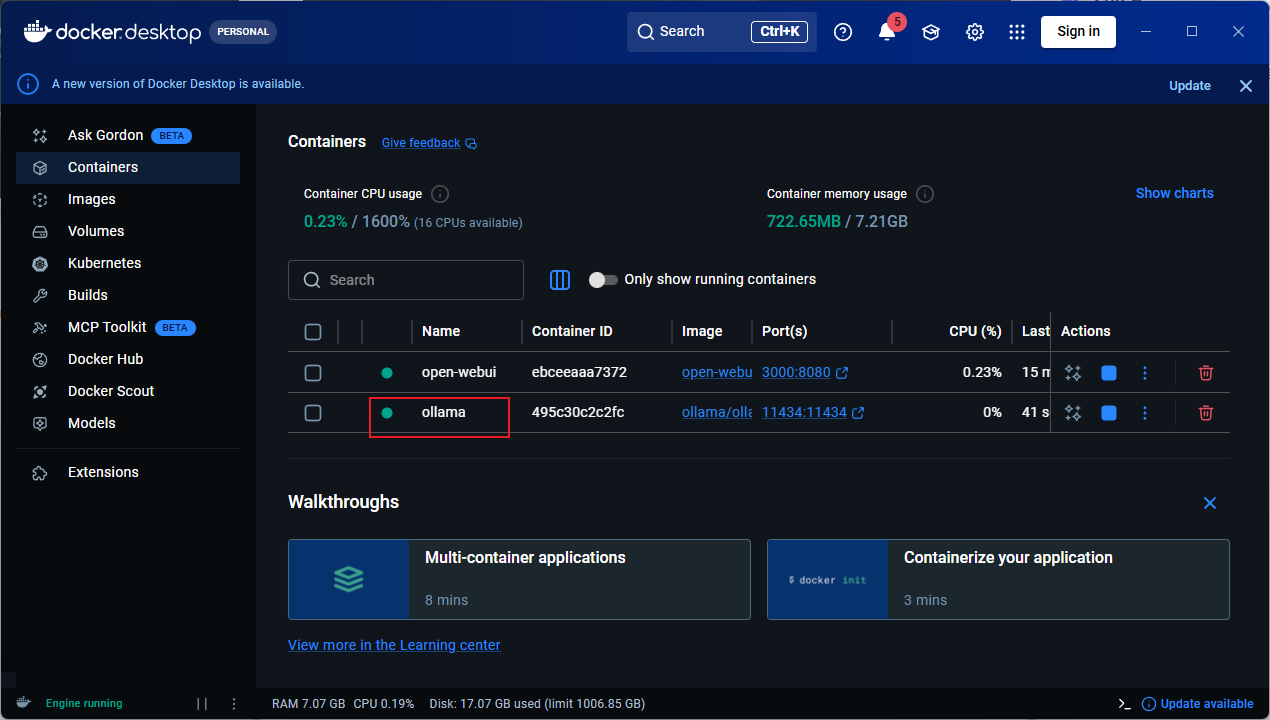
运行容器:
bash
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama --restart always docker.m.daocloud.io/ollama/ollama运行成功状态:
2. 主机版本不兼容
- 问题: Mac系统版本过低(如Mac 13)无法安装新版 Docker 或 Ollama。
- 解决方案: 确保 Mac 系统版本在 14 以上。
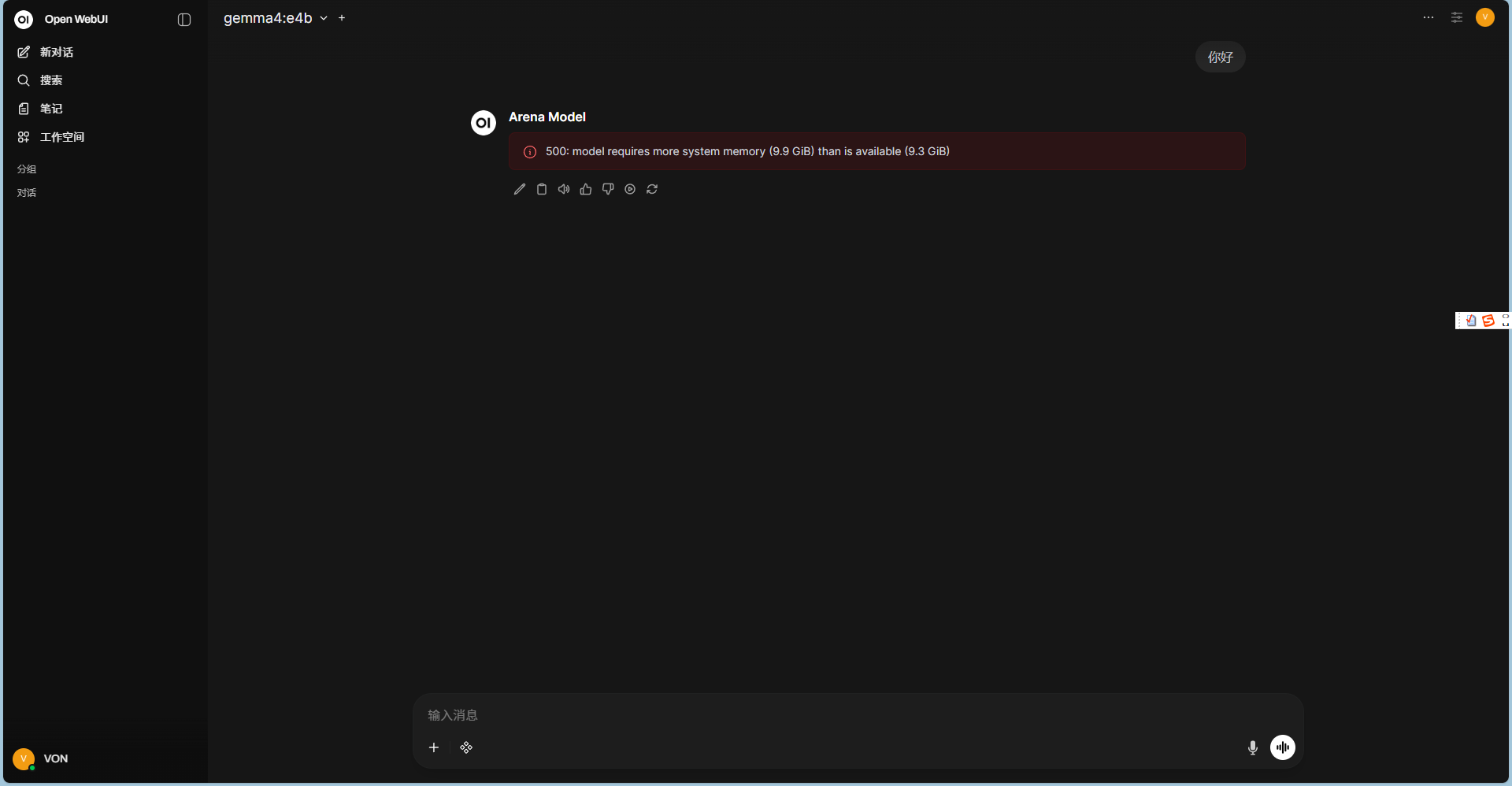
3. 内存不足报错
-
问题: 启动模型时报错
500: model requires more system memory...。 -
解决方案: 一定要根据自己的电脑配置选择低版本或轻量级模型(如
qwen:0.5b)。-
0.5b 版本命令:
bashdocker exec -it ollama ollama pull qwen:0.5b -
运行命令:
bashdocker exec -it ollama ollama run qwen:0.5b -
查看运行状态:
bashdocker ps
-
📌 结语
折腾了一整天,从课堂上的大模型理论,到宿舍里的实战部署,虽然中间遇到了RAG失败、内存溢出等各种报错,但通过不断将报错信息扔给AI寻求修改方案,最终还是成功跑通了流程。
这次实践让我明白:电脑内存最好是16G+,否则在面对动辄几G的大模型时会非常被动。虽然最终没有实现复杂的知识库RAG,但成功部署了Open WebUI并实现了公网访问,也算是迈出了本地大模型应用的重要一步。听说Gemma4昨天刚发布,虽然下载了一下午,但看到它能在普通电脑上跑起来,还是觉得未来可期!