yolo介绍
YOLO(You Only Look Once)是单阶段实时目标检测的里程碑框架,核心特点是 "一次遍历图像就完成检测",区别于 Faster R-CNN 等两阶段模型,兼顾速度与精度,是工业界实时检测的首选方案。
yolo主要解决有问题有:目标定位,分类,姿态估计,旋转目标定位(obb),目标分割。当前yolo的主流框架是yolov8,它由 Ultralytics 公司维护(https://github.com/ultralytics/ultralytics/),目前最新的有yolov26。
它有预训练的模型,我们可以直接使用,我们也可以根据我们实际的需要自训练模型。预训练模型有5个级别,分别为n( Nano ),s(Small),m(Medium),l(large),x( X-Large ),从n到x,处理速度越来越慢,准确率越来越高,需要根据实际情况选择模型,下面以目标定位任务为例,来看对比这几种预训练模型。
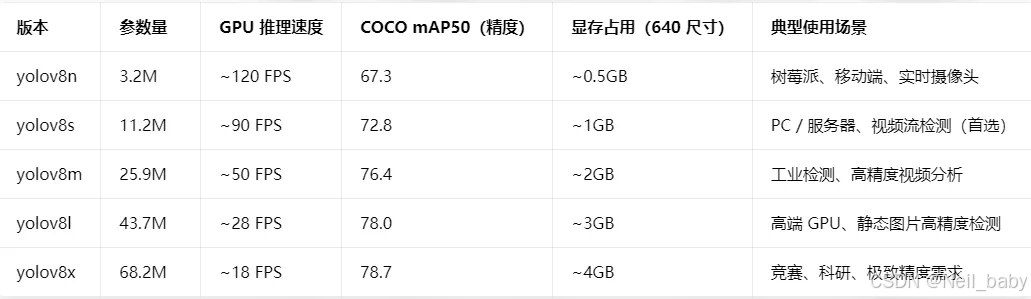
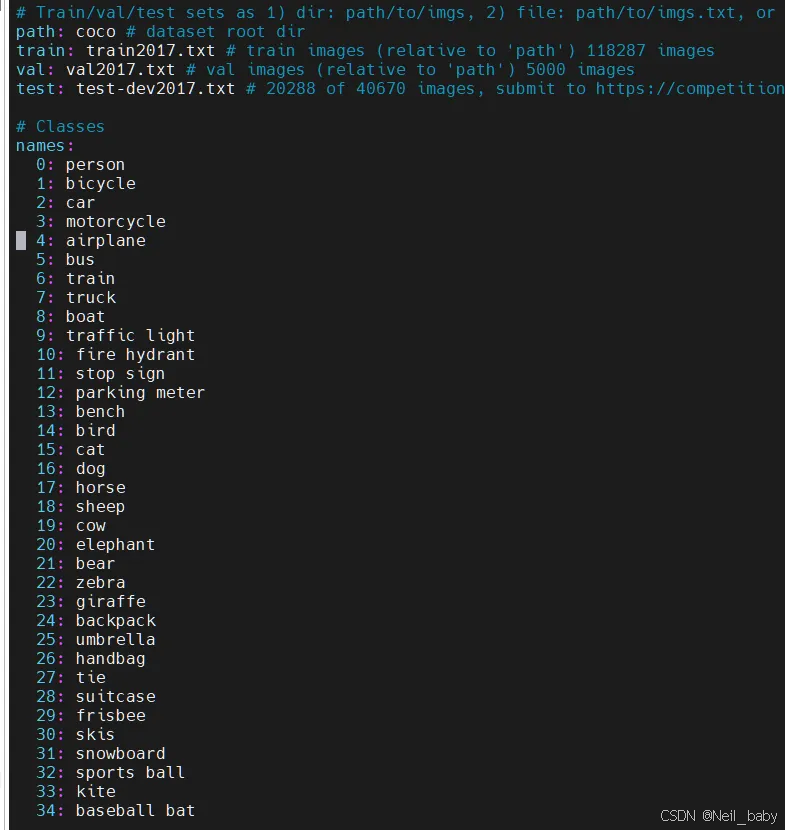
yolov8的预训练模型,obb对象检测支持15种类别,其它支持80种类别(COCO数据集训练),可以通过 ultralytics/cfg/datasets/coco.yaml路径查看:
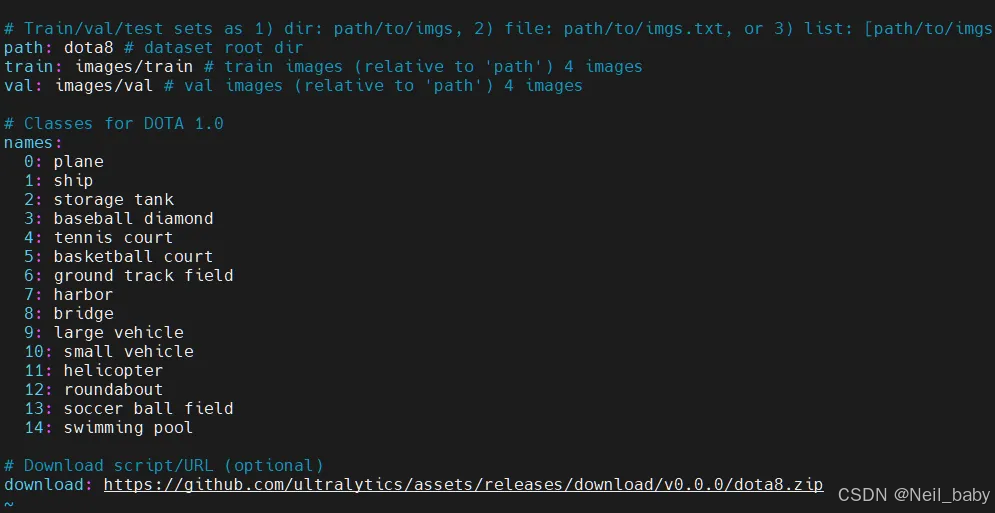
ultralytics/cfg/datasets/dota.yaml
也可通过如下代码,打印出各模型支持的类别
python
from ultralytics import YOLO
# 加载YOLOv8检测模型(自动下载预训练权重)
model = YOLO("yolov8n.pt")
# 打印COCO 80类名称(按ID排序)
print("YOLOv8检测模型支持的80类目标:")
for cls_id, cls_name in model.names.items():
print(f"{cls_id}: {cls_name}")
# 若查看OBB模型的DOTA类别(需加载obb模型)
model_obb = YOLO("yolov8n-obb.pt")
print("\nYOLOv8 OBB模型支持的DOTA类别:")
for cls_id, cls_name in model_obb.names.items():
print(f"{cls_id}: {cls_name}")yolo推理
下面以yolov8为例,初步看下yolo处理实际推理问题的效果。(假设环境已经搭建好),运行也很简单,一句命令即可。
目标定位
bash
yolo predict model=yolov8n.pt source='bus.jpg' save=True
目标分割
bash
yolo predict model=yolov8n-seg.pt source='bus.jpg' save=True
姿态估计
bash
yolo predict model=yolov8n-pose.pt source=test.mp4 save=True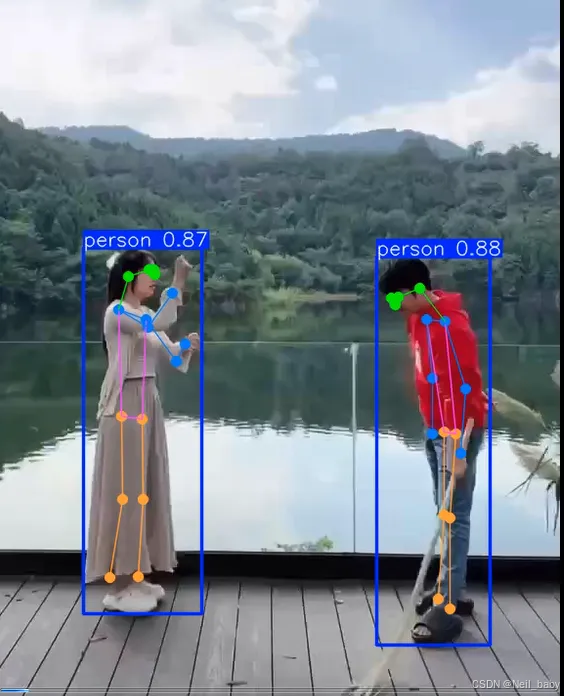
分类
这里用yolv8s-cls.pt模型,分类的结果只输出类别,无位置信息。
bash
yolo predict model=yolov8s-cls.pt source=test.mp4 save=True
旋转目标定位
bash
yolo predict model=yolov8n-obb.pt source=tennis_court.jpg save=True conf=0.4输出显示的边框不太明显,我们这里用OpenCV画出边框,代码如下:
python
from ultralytics import YOLO
import cv2
import numpy as np
# 1. 加载模型+检测
model = YOLO("yolov8n-obb.pt")
results = model.predict(source="test.jpg", conf=0.1)
# 2. 初始化参数(红色+BGR格式,框线粗细3)
RED = (0, 0, 255)
THICKNESS = 3
FONT = cv2.FONT_HERSHEY_SIMPLEX
FONT_SCALE = 0.6
# 3. 获取原始图片(避免修改原图)
img = results[0].orig_img.copy()
# 4. 遍历所有旋转框,手动画红色框
for obb in results[0].obb:
# 获取4个顶点坐标(转为整数,适配OpenCV)
pts = obb.xyxyxyxy.cpu().numpy().astype(np.int32).reshape((-1, 1, 2))
# 画红色旋转框(闭合多边形)
cv2.polylines(img, [pts], isClosed=True, color=RED, thickness=THICKNESS)
# 可选:画类别+置信度标签(红色背景+白色文字)
cls = int(obb.cls)
conf = float(obb.conf)
label = f"{model.names[cls]} {conf:.2f}"
# 标签位置(旋转框左上角)
label_pos = (pts[0][0][0], pts[0][0][1] - 10)
# 绘制标签背景
(w, h), _ = cv2.getTextSize(label, FONT, FONT_SCALE, 2)
cv2.rectangle(img,
(label_pos[0], label_pos[1] - h - 5),
(label_pos[0] + w, label_pos[1]),
RED, -1) # -1=填充背景
# 绘制白色文字
cv2.putText(img, label, label_pos, FONT, FONT_SCALE, (255,255,255), 2)
# 5. 保存+显示结果
cv2.imwrite("red_obb_box.jpg", img)
yolo的模型文件
pt模型文件
pt文件是 PyTorch 原生的权重序列化文件,是pytorch的专属格式,存储了 YOLO 模型(如 YOLOv5/v6/v7/v8/v9/v10 等)训练后学习到的所有可学习参数:
- 包含卷积层、归一化层、注意力层等的权重值、偏置值、均值 / 方差;
- 仅存储参数,不包含模型结构代码(需配合 YOLO 对应的网络定义代码加载);
- 区别于 ONNX/TensorRT/TFLite 等部署格式:
.pt是 PyTorch 专属格式,适合训练 / 本地推理,部署需先转换格式。
模型文件下载地址:https://github.com/ultralytics/assets/releases/tag/v8.1.0
如前面我们用到的都是pt模型文件。
ONNX模型文件
ONNX (Open Neural Network Exchange)是跨框架、跨平台的开放式神经网络交换格式 ,核心解决「模型格式不兼容」问题。例如pt文件是pytorch的专属文件,无法直接在 C++/ 嵌入式 / 移动端 / 工控机运行,而转换为 ONNX 后,可适配 TensorRT、OpenVINO、MNN、TFLite 等几乎所有部署框架,是 YOLO 模型从「训练(.pt)」到「落地部署」的核心中间格式。
bash
yolo export model=yolov8n.pt format=onnx # 导出ONNX会生成yolov8n.onnx文件,我们再用yolov8n.onnx模型文件进行推理,可以得到和pt模型文件一样的结果。
bash
yolo predict model=yolov8n.onnx source='bus.jpg' save=TrueTensorRT模型文件
TensorRT(NVIDIA TensorRT)是 NVIDIA 专为 GPU 打造的高性能推理优化引擎 ,核心作用是对深度学习模型(如 YOLOv8)进行极致优化(层融合、精度校准、显存重排等),相比 PyTorch(.pt)、ONNX Runtime 推理,TensorRT 可将 YOLOv8 推理速度提升 5~20 倍(FP16/INT8 量化后更明显),是 NVIDIA GPU 部署 YOLO 模型的首选方案,仅支持 NVIDIA GPU(T4/V100/A100/RTX 系列)。
bash
yolo export model=best.pt format=engine # 导出TensorRT引擎TFLite
TFLite(TensorFlow Lite)是 Google 专为移动端、嵌入式设备、边缘 MCU 设计的轻量级推理框架,核心优势是「极致轻量化、低功耗、快速推理」,适配安卓 /iOS 手机、树莓派、NVIDIA Jetson Nano、单片机(如 ESP32)等资源受限设备。YOLOv8 转换为 TFLite 后,可脱离 PyTorch/TensorFlow 完整框架,仅用几 MB 大小的推理库运行,是移动端部署 YOLO 的首选方案。
bash
yolo export model=yolov8n.pt format=tflite imgsz=480 half=True device=0