SCNP:一种很巧妙的分割训练技巧(CVPR206)
最近看到一个很有意思的工作:SCNP。https://jmlipman.github.io/SCNP-SameClassNeighborPenalization/
它不是去改网络结构,也不是设计一个很重的拓扑损失,而是直接在 logits 和 loss 之间 做一个很巧妙的操作,让模型优先去修复局部最脆弱的位置,从而改善断裂、空洞、孤立误检等问题。
这篇文章适合这样理解:
如果一个局部区域里存在"短板像素",那这一片区域的训练误差,就先算在这个短板身上。
这篇博客用简单的方式整理一下它的核心思想。
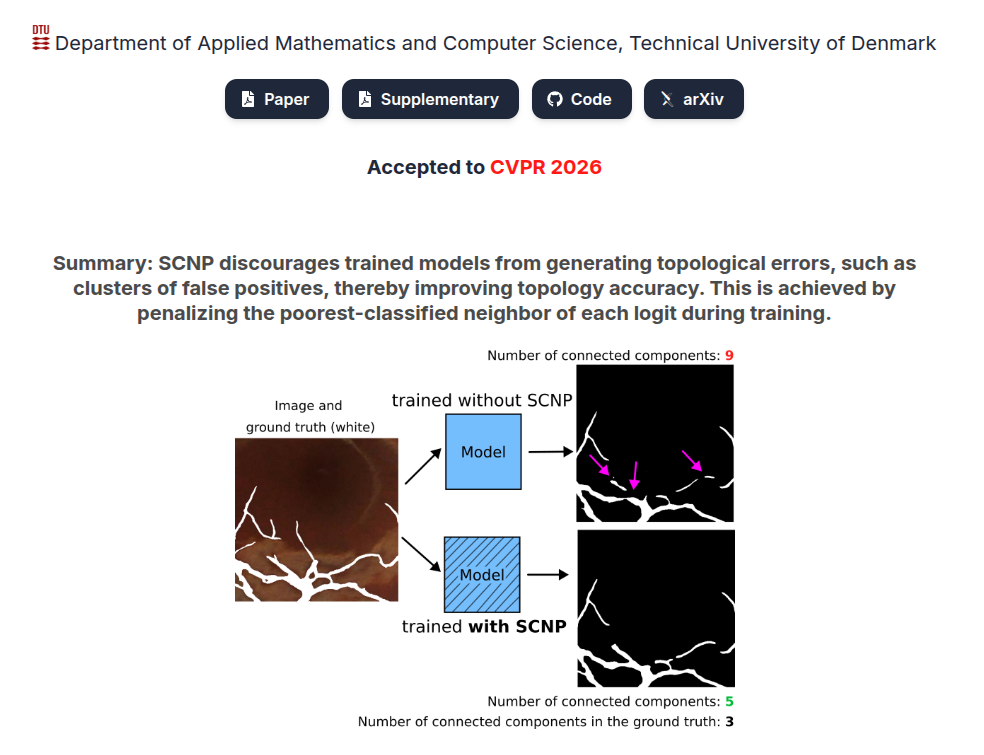
1. 先回顾:logits、loss 和梯度
1.1 什么是 logits
在分类或分割任务中,网络最后输出的通常不是概率,而是 logits,也就是每个类别的原始分数。
例如某个像素是三分类任务时,网络输出:
z=2.1, 0.3, −1.2 \mathbf z = 2.1,\\ 0.3,\\ -1.2 z=2.1, 0.3, −1.2
这表示该像素对三个类别的"偏好分数",但它们还不是概率。
如果要变成概率,一般再经过 softmax:
pi=ezi∑jezj p_i = \frac{e^{z_i}}{\sum_j e^{z_j}} pi=∑jezjezi
1.2 loss 是怎么和 logits 连起来的
训练时不会直接对 argmax 结果算损失,因为 argmax 是离散操作,不可导。
真正做的是:
- 网络输出 logits
- logits 经过 softmax / sigmoid
- 与标签比较,计算 loss
- loss 反向传播,更新参数
最常见的是交叉熵损失。
1.3 一个最重要的结论:梯度如何作用在 logits 上
对于多分类交叉熵,设某个像素的 softmax 概率为 pip_ipi,标签为 one-hot 向量 yiy_iyi,则有:
L=−∑iyilogpi L = -\sum_i y_i \log p_i L=−i∑yilogpi
对每个 logit 的梯度是:
∂L∂zi=pi−yi \frac{\partial L}{\partial z_i} = p_i - y_i ∂zi∂L=pi−yi
这条公式非常重要,它说明:
- 真类别的 logit 会被往上拉
- 错类别的 logit 会被往下压
所以可以把训练理解为:
loss 通过梯度不断调整 logits,让正确类别更大,错误类别更小。
2. 一个关键问题:梯度是不是只和当前像素自己有关?
在普通逐像素损失里,直觉上确实是这样的。
假设某个位置 ppp 的 loss 是:
Lp=ℓ(zp,yp) L_p = \ell(z_p, y_p) Lp=ℓ(zp,yp)
那么它主要依赖当前位置的输出 zpz_pzp。
但如果我们在算 loss 之前,先把它改成:
z~p=min(zp,zq) \tilde z_p = \min(z_p, z_q) z~p=min(zp,zq)
然后再算:
Lp=ℓ(z~p,yp) L_p = \ell(\tilde z_p, y_p) Lp=ℓ(z~p,yp)
那就不一样了。
这时 LpL_pLp 不仅依赖 zpz_pzp,也依赖邻居 zqz_qzq。
也就是说:
只要前向里用了邻居的值,反向时梯度就能流向邻居。
这正是 SCNP 能成立的基础。
3. max 和 min 为什么也能参与反向传播?
很多人第一次看到这里都会疑惑:
max / min 这种东西居然也能求导?
答案是:可以。
3.1 max / min 不是没有解析式,它们是分段函数
先看最简单的二元 max:
f(x,y)=max(x,y) f(x,y)=\max(x,y) f(x,y)=max(x,y)
它其实可以写成:
f(x,y)={x,x>yy,y>x f(x,y)= \begin{cases} x, & x > y \\ y, & y > x \end{cases} f(x,y)={x,y,x>yy>x
所以只要最大值是唯一的,它在局部就等于某个变量本身。
例如当 x>yx > yx>y 时:
∂f∂x=1,∂f∂y=0 \frac{\partial f}{\partial x}=1,\qquad \frac{\partial f}{\partial y}=0 ∂x∂f=1,∂y∂f=0
因为这时候 f=xf=xf=x。
同理,min 也是一样:
g(x,y)=min(x,y) g(x,y)=\min(x,y) g(x,y)=min(x,y)
如果 x<yx < yx<y,那么:
∂g∂x=1,∂g∂y=0 \frac{\partial g}{\partial x}=1,\qquad \frac{\partial g}{\partial y}=0 ∂x∂g=1,∂y∂g=0
3.2 多变量时也是一样
如果有多个变量:
m(x1,x2,...,xn)=max(x1,x2,...,xn) m(x_1, x_2, \dots, x_n)=\max(x_1, x_2, \dots, x_n) m(x1,x2,...,xn)=max(x1,x2,...,xn)
若第 kkk 个最大,且最大值唯一,则:
m=xk m = x_k m=xk
因此:
∂m∂xk=1,∂m∂xj=0(j≠k) \frac{\partial m}{\partial x_k}=1,\qquad \frac{\partial m}{\partial x_j}=0\quad (j\neq k) ∂xk∂m=1,∂xj∂m=0(j=k)
也就是说:
谁在前向里被选中,梯度就传给谁。
这和 max pooling 的反向传播本质是一样的。
3.3 那不可导点怎么办?
例如:
max(x,y) \max(x,y) max(x,y)
在 x=yx=yx=y 时确实严格不可导,因为这时不知道该选哪个。
但这通常不是问题,因为:
- 神经网络里两个浮点数完全相等并不常见
- 框架可以使用合法的次梯度或固定规则处理
所以实际训练完全可行。
4. SCNP 的核心思想
现在进入正题。
SCNP 的出发点很简单:
在分割中,很多拓扑错误并不是整块区域都预测很差,而是因为某个局部最弱点出了问题,例如:
- 一条细路中间某个像素太弱,导致整条路断开
- 某个背景点异常高,导致冒出一个孤立伪目标
- 某个边界点预测不稳,导致局部连通性破坏
所以它想做的事情是:
训练时不要平均优化每个像素,而是优先修复局部邻域里的"最差像素"。

5. SCNP 是怎么做的?
SCNP 作用在 logits 和 loss 之间。
它不是推理后处理,而是一个训练时操作。
5.1 它不靠预测类别,而是靠标签定义"同类邻域"
这是一个非常关键的点。
SCNP 里的"同类"不是根据预测结果,也不是根据 argmax,而是根据 真值标签 来定义。
也就是说:
- 训练时我们有 GT 标签
- 对每个类别通道,标签可以写成 one-hot 掩码 YYY
- 在某个类别通道里:
- Y=1Y=1Y=1 表示这个位置在 GT 中属于该类
- Y=0Y=0Y=0 表示这个位置在 GT 中不属于该类
于是 SCNP 就可以在每个类别通道上做"同标签邻域"的 min/max 操作。
5.2 前景和背景分别怎么处理?
对于某个类别通道,设原始 logits 为 zzz,标签掩码为 YYY。
SCNP 做两件事:
(1)对前景区域:传播最小值
对于 Y=1Y=1Y=1 的位置,在它的 3×3 邻域里,只看那些同样 Y=1Y=1Y=1 的位置,然后取其中最小的 logit。
因为对前景来说,logit 小 表示这个前景像素不够像前景,是薄弱点。
(2)对背景区域:传播最大值
对于 Y=0Y=0Y=0 的位置,在 3×3 邻域里,只看那些同样 Y=0Y=0Y=0 的位置,然后取其中最大的 logit。
因为对背景来说,logit 大 表示这个背景像素太像前景,是危险点。
5.3 最终得到新的 logits
经过这一步之后,原始 logits zzz 被变成新的 tildeztilde ztildez:
z→z~ z \rightarrow \tilde z z→z~
然后不改 loss 公式,仍然正常计算:
L=ℓ(z~,Y) L = \ell(\tilde z, Y) L=ℓ(z~,Y)
也就是说,SCNP 不是额外加一个复杂 loss,而是:
先改 logits,再用原本的 loss 去训练。
6. 为什么"复制最差邻居"的值会有用?
这一步是 SCNP 最巧妙的地方。
它不是说"这一片都错了",而是在说:
这一片的训练误差,先按最差那个位置来结算。
举一个简单的一维例子。
假设某个前景区域的 logits 是:
2.8, 2.6, 0.4, 2.7, 2.9\] \[2.8,\\ 2.6,\\ 0.4,\\ 2.7,\\ 2.9\] \[2.8, 2.6, 0.4, 2.7, 2.9
中间那个 0.40.40.4 明显是短板,很容易导致这条结构断裂。
如果直接逐像素算 loss,那么这个 0.40.40.4 只会收到自己那一个位置的梯度。
但如果做 SCNP 的最小值传播,邻域中多个位置都可能引用这个 0.40.40.4,于是 loss 会变成类似:
L=ℓ(0.4)+ℓ(0.4)+ℓ(0.4)+⋯ L = \ell(0.4) + \ell(0.4) + \ell(0.4) + \cdots L=ℓ(0.4)+ℓ(0.4)+ℓ(0.4)+⋯
注意,这些项虽然来自不同位置,但它们前向时都引用了同一个原始 logit。
于是反向传播时,这些梯度会叠加到同一个短板像素上。
所以 SCNP 的本质不是简单"复制数值",而是:
通过前向的值替换,让多个位置的梯度汇聚到最差点上。
7. 梯度为什么真的会流向最差邻居?
这个地方可以更正式一点看。
设某个位置的 SCNP 输出是:
z~p=min(zp,zq) \tilde z_p = \min(z_p, z_q) z~p=min(zp,zq)
如果当前 zq<zpz_q < z_pzq<zp,那么前向时实际上有:
z~p=zq \tilde z_p = z_q z~p=zq
于是:
Lp=ℓ(z~p,yp)=ℓ(zq,yp) L_p = \ell(\tilde z_p, y_p) = \ell(z_q, y_p) Lp=ℓ(z~p,yp)=ℓ(zq,yp)
根据链式法则:
$$
\frac{\partial L_p}{\partial z_q}
\frac{\partial L_p}{\partial \tilde z_p}
\cdot
\frac{\partial \tilde z_p}{\partial z_q}
\frac{\partial L_p}{\partial \tilde z_p}\cdot 1
$$
而:
∂Lp∂zp=0 \frac{\partial L_p}{\partial z_p}=0 ∂zp∂Lp=0
因为这一路前向里真正被选中的是 zqz_qzq,不是 zpz_pzp。
所以梯度不是"神奇地跳过去",而是:
前向里谁被用了,反向梯度就回给谁。
这和 max/min 的导数规则完全一致。
8. 用一句话概括 SCNP 的训练逻辑
SCNP 的核心逻辑可以概括为:
不要让局部好像素各自变得更好,而是先把局部最差像素修好。
它特别适合处理这些问题:
- 细长结构断裂
- 小孔洞
- 孤立误检
- 局部拓扑不连续
- 边界细节不稳
9. 一个非常简洁的伪代码理解
下面给一个简化理解版本:
python
# logits: [B, C, H, W]
# Y: one-hot GT mask, same shape
# 前景:在同标签前景邻域里取最小值
t1 = masked_min_pool(logits, mask=(Y == 1), kernel=3)
# 背景:在同标签背景邻域里取最大值
t2 = masked_max_pool(logits, mask=(Y == 0), kernel=3)
# 合成新的 logits
scnp_logits = t1 * Y + t2 * (1 - Y)
# 用新的 logits 继续算普通 loss
loss = LossFn(scnp_logits, Y)这里最关键的并不是代码本身,而是它背后的思想:
- GT 决定"同类邻域"
- min/max 决定"最差者是谁"
- 新 logits 决定"梯度重点打到谁"
10. 它和普通训练最大的区别
普通逐像素训练更像是:
每个像素管好自己。
而 SCNP 更像是:
一个局部区域里,如果还有一个短板没补好,那周围这些位置也先别轻松过关。
所以它不是普通意义上的"平滑",也不是后处理,而是一种局部短板优先优化机制。
11. 总结
SCNP 的思路非常巧妙,而且实现上并不复杂。
它的关键点可以总结成下面几条:
- logits 是 loss 的直接优化对象
- 梯度并不一定只流向当前位置,只要前向里用了邻居的值,梯度就能流向邻居
- max/min 是分段函数,在唯一最大/最小时是可导的
- SCNP 用 GT 标签定义"同类邻域"
- 前景传播最小值,背景传播最大值
- 多个位置如果都引用同一个最差 logit,那么这些位置的梯度会汇聚到这个最差点上
- 因此模型会优先修复局部薄弱点,从而改善拓扑结构
如果用一句最简单的话来概括 SCNP,那就是:
把一个局部区域的训练压力,集中施加到最脆弱的那个像素上。
这也是它最有意思、最巧妙的地方。