目录

1.摘要
针对UAV自主导航中反应式方法缺乏远见及传统规划方法动作空间维度过高的局限,本文提出了一种基于深度强化学习的分层自适应导航规划方法(HAP),其利用3D贝塞尔控制点简化路径规划的动作空间,并结合分布软角色-评论家(DSAC)算法与针对性的稠密奖励函数,使无人机在无需地图且传感器精度要求较低的情况下,实现了兼顾长远视觉与实时避障的自适应重规划能力。
2.问题表述
任务在 600 m × 500 m × 500 m 600\mathbf{m}\times500\mathbf{m}\times500\mathbf{m} 600m×500m×500m的 3D 空间内展开,目标是在规避随机障碍物的前提下,以最短路径从起点 p 0 \mathbf{p}_{0} p0到达终点 p T \mathbf{p}_T pT。最小化轨迹长度:
min ∑ t = 0 T ∥ p t + 1 − p t ∥ 2 \min\sum_{t=0}^T\|\mathbf{p}_{t+1}-\mathbf{p}_t\|_2 mint=0∑T∥pt+1−pt∥2
其中,需满足安全距离约束 o m i n > o ˉ o_{min}>\bar{o} omin>oˉ 及起止点边界条件。
无人机状态由selfinfo(自身信息)和obsinfo(障碍物信息)组成:
- 自身信息:包含绝对位置 ( x , y , z ) (x, y, z) (x,y,z)、相对目标位移、航向角 ω \omega ω及前向矢量与目标方向的夹角 μ \mu μ:
s e l f I n f o = x , y , z , x t a r g e t − x , y t a r g e t − y , z t a r g e t − z , ω , μ selfInfo = x, y, z, x_{target} - x, y_{target} - y, z_{target} - z, \\omega, \\mu selfInfo=x,y,z,xtarget−x,ytarget−y,ztarget−z,ω,μ - 感知信息:采用高密度的LiDAR系统,由18个平面、每个平面36条射线构成648束感知系统,记录各方向的障碍物距离 o i , j , c o_{i,j,c} oi,j,c
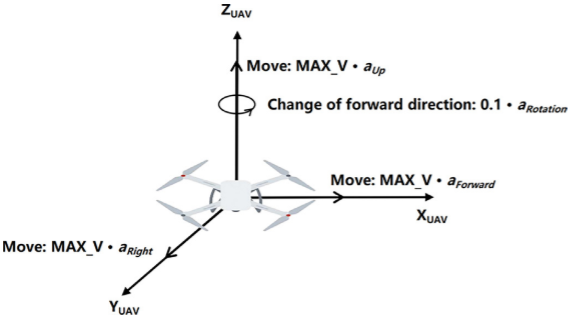
无人机动作空间定义为四个轴向的控制量 A U A V = a F o r w a r d , a R i g h t , a U p , a R o t a t i o n A_{UAV}=a_{Forward},a_{Right},a_{Up},a_{Rotation} AUAV=aForward,aRight,aUp,aRotation,其运动学状态转移公式:
{ ω t + 1 = ( ω t − 0.1 ⋅ a rotation ) ( m o d 2 π ) x t + 1 = x t + TIME_STEP ⋅ MAX_V ⋅ κ ⋅ ( a forward ⋅ cos ω t + 1 − a right ⋅ sin ω t + 1 ) y t + 1 = y t + TIME_STEP ⋅ MAX_V ⋅ κ ⋅ ( a forward ⋅ sin ω t + 1 + a right ⋅ cos ω t + 1 ) z t + 1 = z t + TIME_STEP ⋅ MAX_V ⋅ κ ⋅ a up \begin{cases} \omega_{t+1} = (\omega_t - 0.1 \cdot a_{\text{rotation}}) \pmod{2\pi} \\ x_{t+1} = x_t + \text{TIME\STEP} \cdot \text{MAX\V} \cdot \kappa \cdot (a{\text{forward}} \cdot \cos \omega{t+1} - a_{\text{right}} \cdot \sin \omega_{t+1}) \\ y_{t+1} = y_t + \text{TIME\STEP} \cdot \text{MAX\V} \cdot \kappa \cdot (a{\text{forward}} \cdot \sin \omega{t+1} + a_{\text{right}} \cdot \cos \omega_{t+1}) \\ z_{t+1} = z_t + \text{TIME\_STEP} \cdot \text{MAX\V} \cdot \kappa \cdot a{\text{up}} \end{cases} ⎩ ⎨ ⎧ωt+1=(ωt−0.1⋅arotation)(mod2π)xt+1=xt+TIME_STEP⋅MAX_V⋅κ⋅(aforward⋅cosωt+1−aright⋅sinωt+1)yt+1=yt+TIME_STEP⋅MAX_V⋅κ⋅(aforward⋅sinωt+1+aright⋅cosωt+1)zt+1=zt+TIME_STEP⋅MAX_V⋅κ⋅aup
3.分层自适应导航规划
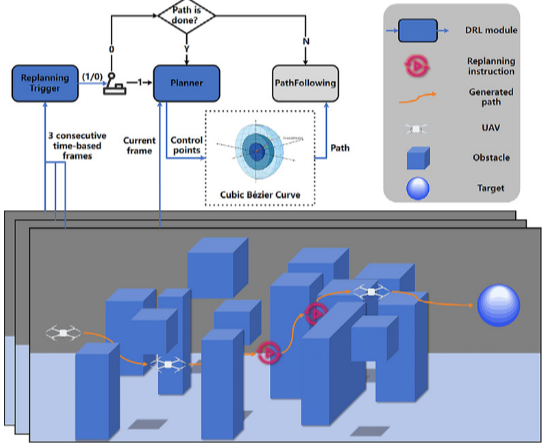
Planner:长远路径规划
Planner 负责在 3D 空间中生成平滑且避障的路径。为降低动作空间维度,它不直接输出轨迹,而是输出 3D 贝塞尔曲线的 3 个控制点 P 1 , P 2 , P 3 P_1, P_2, P_3 P1,P2,P3。
动作空间 A Planner = θ 1 , ϕ 1 , θ 2 , ϕ 2 , θ 3 , ϕ 3 A_{\text{Planner}} = \\theta_1, \\phi_1, \\theta_2, \\phi_2, \\theta_3, \\phi_3 APlanner=θ1,ϕ1,θ2,ϕ2,θ3,ϕ3,通过极角和方位角在三个等半径球上确定控制点坐标:
KaTeX parse error: Expected 'EOF', got '_' at position 32: ...\cdot \text{INF_̲R}}{3} (\sin \t...
奖励函数包含稀疏奖励(到达、碰撞、超时)和稠密奖励,重点是通过曲率惩罚实现平滑性:
r curvature t = σ 1 N ∑ i = 0 N − 1 ∣ B ′ ( p i t ) × B ′ ′ ( p i t ) ∣ ∣ B ′ ( p i t ) ∣ 3 r_{\text{curvature}}^t = \frac{\sigma_1}{N} \sum_{i=0}^{N-1} \frac{|\mathbf{B}'(\mathbf{p}_i^t) \times \mathbf{B}''(\mathbf{p}_i^t)|}{|\mathbf{B}'(\mathbf{p}_i^t)|^3} rcurvaturet=Nσ1i=0∑N−1∣B′(pit)∣3∣B′(pit)×B′′(pit)∣
算法采用 DSAC(Distributional Soft Actor-Critic)算法,通过建模 Q 值的概率分布 Z ( s , a ) ∼ N ( μ θ , σ θ 2 ) Z(s, a) \sim \mathcal{N}(\mu_\theta, \sigma_\theta^2) Z(s,a)∼N(μθ,σθ2) 来应对复杂随机环境中的不确定性。
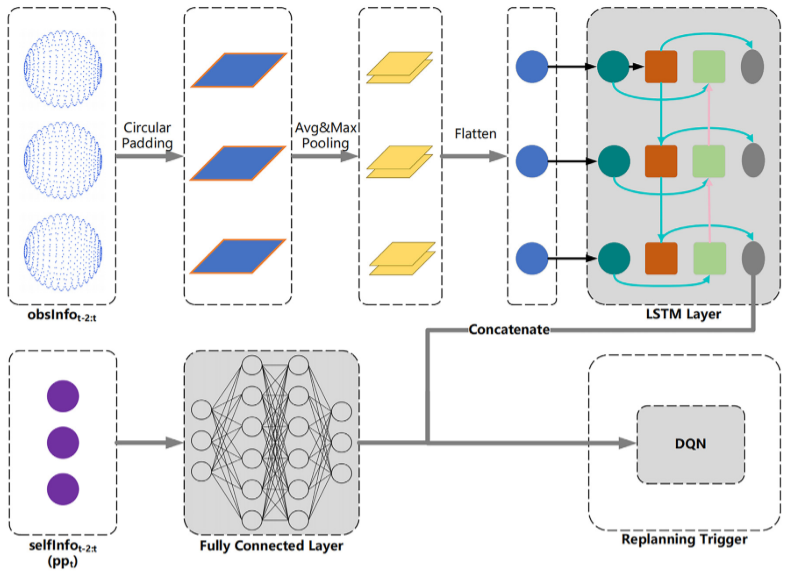
Replanning Trigger:自适应触发
模块监控环境决定何时调用 Planner 更新路径,实现自适应平衡。状态空间包含连续三帧的自身与环境信息,以及当前路径进度 p p t pp_t ppt:
s Trigger t = selfInfo t − 2 : t , obsInfo t − 2 : t , p p t s^t_{\text{Trigger}} = \\text{selfInfo}_{t-2:t}, \\text{obsInfo}_{t-2:t}, pp_t sTriggert=selfInfot−2:t,obsInfot−2:t,ppt
动作空间二值决策 a Trigger t ∈ { 0 , 1 } a^t_{\text{Trigger}} \in \{0,1\} aTriggert∈{0,1},决定是否触发发规划。
重规划奖励 ( r replan r_{\text{replan}} rreplan)评估重规划后的新路径是否比原路径更安全:
r replan t = σ 6 ( min i = 0 N − 1 − I d ( p new , i ) − min j = I N − 1 d ( p old , j ) ) r^t_{\text{replan}} = \sigma_6\left(\min_{i=0}^{N-1-I} d(p_{\text{new},i}) - \min_{j=I}^{N-1} d(p_{\text{old},j})\right) rreplant=σ6(i=0minN−1−Id(pnew,i)−j=IminN−1d(pold,j))
算法采用集成 DQN 算法处理离散决策。

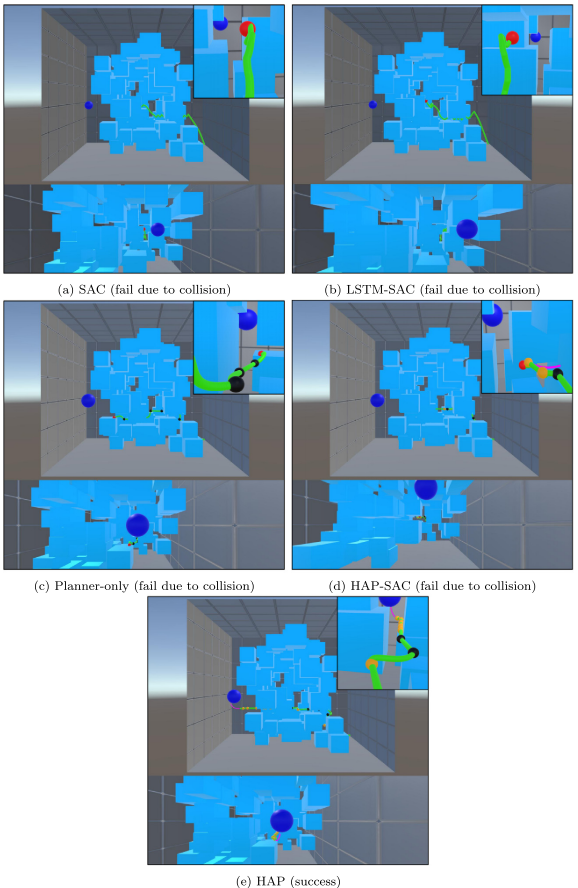
4.结果展示
5.参考文献
Liu S, Zhang Y, Li G, et al. A hierarchical adaptive navigation planner for UAVs in 3D complex environments based on deep reinforcement learningJ. Applied Soft Computing, 2026: 114614.
6.代码获取
xx
7.算法辅导·应用定制·读者交流
xx