Scrapy工作空间搭建与目录结构解析:从初始化到基础配置全流程
在Scrapy爬虫开发中,规范的工作空间搭建是高效开发、便于维护的基础。无论是个人数据采集项目,还是企业级大规模爬虫开发,清晰的项目结构、标准的操作流程,都能大幅降低后续开发成本,避免因目录混乱、配置缺失导致的开发效率低下。本文将详细阐述Scrapy工作空间的创建操作、目录结构拆解,以及开发前的基础配置,结合实际终端命令和项目结构示例,为爬虫开发提供标准化的操作指南。
Scrapy作为Python生态中最成熟的爬虫框架,其本身提供了完善的项目初始化工具,能够快速生成标准化的工作空间目录。不同于手动创建文件夹搭建项目,使用Scrapy自带的命令行工具,可直接生成符合框架规范的目录结构,省去手动配置包依赖、初始化文件的繁琐步骤,同时保证项目的可扩展性和可维护性。
一、Scrapy工作空间创建:标准化终端操作流程
Scrapy工作空间的创建核心依赖终端命令,全程无需手动创建任何文件夹,仅需两条核心命令,即可完成项目初始化和爬虫任务创建,操作简洁且规范。以下操作基于Windows系统PowerShell终端(Mac、Linux系统终端操作逻辑一致,仅路径表示略有差异),前提是已完成Scrapy的安装(可通过pip install scrapy命令安装,安装成功后即可执行以下操作)。
1. 项目初始化:创建Scrapy工作空间
首先需定位到目标项目的存放目录,可通过cd命令切换终端路径,例如将项目放置在D盘的scrapy_projects文件夹下,终端执行命令:cd D:\scrapy_projects。定位完成后,执行项目创建命令,生成完整的Scrapy工作空间。
核心命令:scrapy startproject 项目名
bash
scrapy startproject MyTest执行该命令后,Scrapy会自动在当前目录下生成一个名为MyTest的项目文件夹,这就是我们的Scrapy工作空间。需要特别注意的是,后续使用PyCharm打开该项目时,务必将MyTest设置为项目根目录,否则会出现包导入失败、路径异常等问题,影响爬虫正常运行。
2. 创建爬虫任务:生成具体爬虫文件
项目初始化完成后,需进入项目目录,再创建具体的爬虫任务。爬虫任务是Scrapy工作的核心,每个爬虫任务对应一个具体的爬取目标(如爬取豆瓣电影Top250、音乐网站评论等),每个爬虫任务会生成一个独立的.py文件,便于分类管理。
第一步:进入项目目录,终端执行命令:
bash
cd 项目名第二步:创建爬虫任务,核心命令:scrapy genspider 爬虫名 爬虫起始url
bash
scrapy genspider douban https://movie.douban.com/top250该命令中,"douban"是爬虫名(可自定义,建议贴合爬取目标,便于后续区分),"https://movie.douban.com/top250"是爬虫的起始url,即爬虫开始爬取的第一个网页地址。执行命令后,Scrapy会自动在项目的指定目录下生成对应的爬虫文件,无需手动创建。
若需创建多个爬虫任务,可重复执行该命令,例如再创建一个爬取音乐网站的爬虫:scrapy genspider music51 https://www.xxx.com/music,此时会生成对应的music51.py文件,实现多爬虫任务的分类管理。
二、Scrapy工作空间目录结构解析:读懂每个文件夹的作用
执行上述两条命令后,Scrapy工作空间的目录结构已自动生成,看似层级较多,但每个目录和文件都有明确的分工,理解其作用是后续编写爬虫代码、配置项目的关键。以下以MyTest项目为例,详细拆解每个目录和文件的核心功能,明确哪些文件需要修改、哪些文件可保持默认。
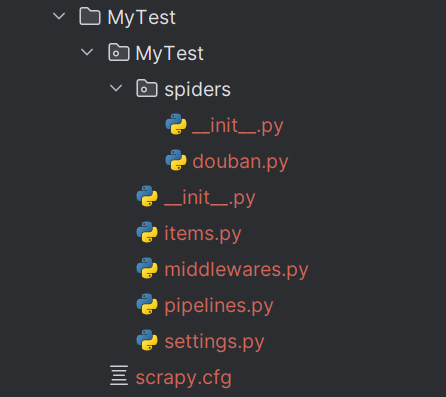
plain
MyTest/ - 项目文件夹(Scrapy工作空间根目录)
- MyTest/ -- 主目录,与项目同名,核心代码存放目录
- spiders/ --- 存储具体的爬虫任务文件,所有爬虫逻辑均在此编写
- __init__.py ---- 包标识文件,空文件即可,用于标识spiders为Python包
- douban.py ---- 单个爬虫任务文件,对应豆瓣电影Top250爬取任务
- music51.py ---- 单个爬虫任务文件,对应音乐网站爬取任务
- __init__.py --- 主目录包标识文件,空文件,标识MyTest为主包
- items.py --- 定义爬取的数据结构,提前声明需要爬取的字段(如标题、作者、评分等)
- middlewares.py --- 定义请求/响应中间件,用于在请求发送前、响应接收后执行额外逻辑(如代理切换、UA伪装),默认无需修改
- pipelines.py --- 数据处理管道,负责对爬取到的数据进行清洗、过滤、存储(如存为CSV、MySQL)
- settings.py --- 项目核心配置文件,所有全局设置均在此配置(如请求头、并发数、延迟等)
- scrapy.cfg -- 项目默认配置文件,用于指定项目部署、爬虫列表等,默认无需修改1. 根目录:MyTest/
这是整个Scrapy工作空间的根目录,也是PyCharm需要识别的项目根目录。该目录下包含两个核心部分:与项目同名的主目录(MyTest/)和项目默认配置文件(scrapy.cfg),主要作用是统一管理项目所有文件,便于后续项目部署和维护。
2. 主目录:MyTest/(与项目同名)
这是爬虫开发的核心目录,所有代码编写、配置修改均在此目录下进行,其内部包含5个核心文件/文件夹,分工明确、各司其职。
(1)spiders/ 文件夹
该文件夹是爬虫任务的核心存放位置,所有通过scrapy genspider命令创建的爬虫文件,都会自动生成在此目录下。每个爬虫文件对应一个独立的爬取任务,例如douban.py对应豆瓣电影Top250的爬取,music51.py对应音乐网站的爬取。
其中__init__.py是包标识文件,无需编写任何代码,仅用于告诉Python解释器,spiders文件夹是一个可导入的Python包。爬虫文件(如douban.py)是我们编写爬取逻辑的主要文件,后续的URL设置、XPath选择器、数据提取逻辑等,均在该文件中编写。
(2)items.py 文件
该文件用于定义爬取的数据结构,相当于数据模型。在爬取数据前,需提前在此文件中声明需要爬取的字段,例如爬取豆瓣电影时,需要爬取电影标题、导演、主演、评分、上映年份等字段,即可在items.py中定义对应的字段,规范数据格式,避免后续数据混乱。
items.py的核心作用是统一数据格式,便于后续在pipelines.py中进行数据处理和存储,同时提高代码的可读性和可维护性。若未提前定义字段,也可直接在爬虫文件中提取数据,但会导致数据格式不统一,不利于后续维护。
(3)middlewares.py 文件
该文件用于定义请求/响应中间件,中间件的核心作用是在请求发送前、响应接收后,执行额外的逻辑处理。例如,在请求发送前自动添加请求头、切换代理IP;在响应接收后,对响应内容进行预处理(如解码、去重)等。
Scrapy默认提供了基础的中间件实现,对于大多数爬虫场景,无需修改该文件,仅在需要实现复杂反爬(如动态代理、Cookie池)时,才需要在该文件中自定义中间件逻辑。
(4)pipelines.py 文件
该文件是数据处理管道,负责对爬虫爬取到的数据进行后续处理,包括数据清洗(去除空格、无用字符)、数据过滤(筛选符合条件的数据)、数据存储(存储到CSV、JSON文件或MySQL、MongoDB数据库)等。
爬虫文件中提取的数据,会通过yield语句传递到pipelines.py中,由该文件中的逻辑进行处理。例如,将爬取到的豆瓣电影数据清洗后,存储到douban_top250.csv文件中,即可在pipelines.py中编写对应的存储逻辑。
(5)settings.py 文件
该文件是Scrapy项目的核心配置文件,所有全局设置均在此配置,直接影响爬虫的运行效果和反爬能力。该文件中包含大量可配置项,后续开发中需要重点修改部分基础配置,其余配置可保持默认。
3. 配置文件:scrapy.cfg
该文件是Scrapy项目的默认配置文件,主要用于指定项目的部署相关设置、爬虫列表等,默认情况下无需任何修改。除非需要将爬虫部署到服务器,否则无需改动该文件,保持默认即可。
三、开发前基础配置:settings.py 核心设置
创建完工作空间和目录结构后,在编写爬虫代码前,需先对settings.py文件进行基础配置,主要目的是伪装浏览器、关闭robots协议,避免被目标网站识别为爬虫,导致爬取失败。以下是必须修改的两项基础配置,其余配置可根据实际需求调整。
1. 配置USER_AGENT:伪装浏览器请求
USER_AGENT是请求头中的核心字段,用于告诉目标网站当前请求的浏览器信息。默认情况下,Scrapy的USER_AGENT为Scrapy自带的标识,容易被网站识别为爬虫,从而被限制访问。因此,需将其修改为浏览器的真实USER_AGENT。
修改方式:打开settings.py文件,找到USER_AGENT配置项,将其修改为以下内容(可根据自己的浏览器版本调整,也可通过百度搜索"USER_AGENT"获取最新浏览器标识):
python
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36"2. 关闭ROBOTSTXT_OBEY:取消robots协议限制
ROBOTSTXT_OBEY是Scrapy的默认配置,默认值为True,表示遵循目标网站的robots协议。robots协议用于限制爬虫爬取网站的某些内容,若遵循该协议,可能会导致无法爬取到目标数据。因此,在开发爬虫时,通常将其设置为False,取消协议限制。
修改方式:打开settings.py文件,找到ROBOTSTXT_OBEY配置项,将其修改为:
python
ROBOTSTXT_OBEY = False除了上述两项基础配置外,settings.py中还可配置并发数(CONCURRENT_REQUESTS)、请求延迟(DOWNLOAD_DELAY)、Cookie设置等,后续可根据爬取场景和反爬需求逐步调整。
四、爬虫运行命令:两种常用运行方式
完成工作空间创建、目录结构解析和基础配置后,即可运行爬虫任务,获取目标数据。Scrapy提供了两种常用的运行方式,分别适用于不同的开发场景,可根据需求选择使用。
1. 带日志运行:查看爬虫运行详情
核心命令:scrapy crawl 爬虫名
bash
scrapy crawl douban执行该命令后,终端会输出爬虫的运行日志,包括请求的URL、响应状态码、提取的数据、爬取进度等信息。这种方式适合开发调试阶段,可通过日志快速定位爬取过程中的问题(如请求失败、数据提取错误等)。
2. 不带日志运行:简洁输出爬取结果
核心命令:scrapy crawl 爬虫名 --nolog
bash
scrapy crawl douban --nolog执行该命令后,终端不会输出任何运行日志,仅在爬取完成后,输出最终的爬取结果(若配置了数据存储,会直接将数据存储到指定位置)。这种方式适合爬虫调试完成后,批量爬取数据,避免日志占用终端空间,提高爬取效率。
五、总结
Scrapy工作空间的搭建是爬虫开发的基础,通过标准化的终端命令,可快速生成规范的目录结构,省去手动配置的繁琐步骤。本文详细阐述了项目初始化、爬虫任务创建的核心命令,拆解了工作空间的目录结构,明确了每个文件的作用,同时讲解了开发前的基础配置和爬虫运行方式,形成了一套完整的Scrapy工作空间搭建流程。
需要注意的是,务必将项目根目录设置为PyCharm的根目录,避免出现路径异常;settings.py的基础配置是爬虫正常运行的前提,不可遗漏;不同的爬虫任务需分类创建,便于后续代码维护。掌握这些基础操作,能够为后续的爬虫逻辑编写、反爬破解、数据存储奠定坚实基础,提高爬虫开发的效率和规范性。
后续将基于本次搭建的工作空间,结合具体的爬取场景,编写完整的爬虫代码,实现数据提取和存储,感兴趣的可持续关注。
关注我,了解更多爬虫知识和实战经验~~