零门槛揭开大模型训练的神秘面纱
摘要 :无需企业级算力,仅需一张消费级显卡(如RTX 3090)、3元成本与2小时,即可从零训练一个64M参数的轻量语言模型。本文以开源项目 MiniMind 为例,手把手带你体验大模型训练全流程。
一、环境准备:10分钟搞定基础配置
1. 硬件要求
- 显卡:NVIDIA GTX 3000及以上(显存≥8GB)
- 内存:16GB
- 存储:50GB可用空间(用于数据集与模型)
以上是建议硬件,我自己的笔记本是3050显卡,显存4g,训练64的会很慢,最终训练了一个更小的,主要是体验下整个过程。
2. 关键软件安装
如果你本机有其他很多依赖库,建议隔离安装,我是用的venv隔离环境
# 安装Python环境(推荐3.10+)
conda create -n minimind python=3.10
conda activate minimind
# 安装PyTorch与依赖
pip install torch==2.3.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install transformers datasets tiktoken wandb3. 克隆MiniMind源码
git clone https://github.com/jingyaogong/minimind
cd minimind二、数据准备:极简中文语料处理
1. 下载开源数据集
项目提供预清洗的100MB中文数据集(覆盖百科、新闻、论坛):
python scripts/download_data.py --dataset_name minimind-cn-100m输出示例:
Downloaded 102,437 samples (98.7MB) to ./data/minimind-cn-100m2. 训练分词器
python
python train_tokenizer.py \
--data_dir ./data/minimind-cn-100m \
--vocab_size 32768 \
--save_dir ./tokenizer关键参数解析:
vocab_size:词表大小(小模型建议≤32K)save_dir:输出分词器模型路径
生成文件:
tokenizer.model:分词器模型文件tokenizer.json:兼容Hugging Face的配置文件
三、预训练:2小时完成64M模型训练
1. 启动训练脚本
python
python train_pretrain.py \
--data_dir ./data/minimind-cn-100m \
--tokenizer_path ./tokenizer/tokenizer.model \
--model_size 64M \
--batch_size 32 \
--gradient_accumulation_steps 4 \
--max_steps 5000 \
--lr 1e-3核心技术解析:
- 梯度累积 (
gradient_accumulation_steps=4)- 显存不足时,用4个小批次(batch=8)模拟大批次(等效batch=32)
- 突破单卡显存限制
- 混合精度训练
- 前向计算用float16加速,梯度更新用float32防溢出
- 余弦退火学习率
- 前期快速收敛,后期精细调优(公式见代码)
2. 训练过程监控
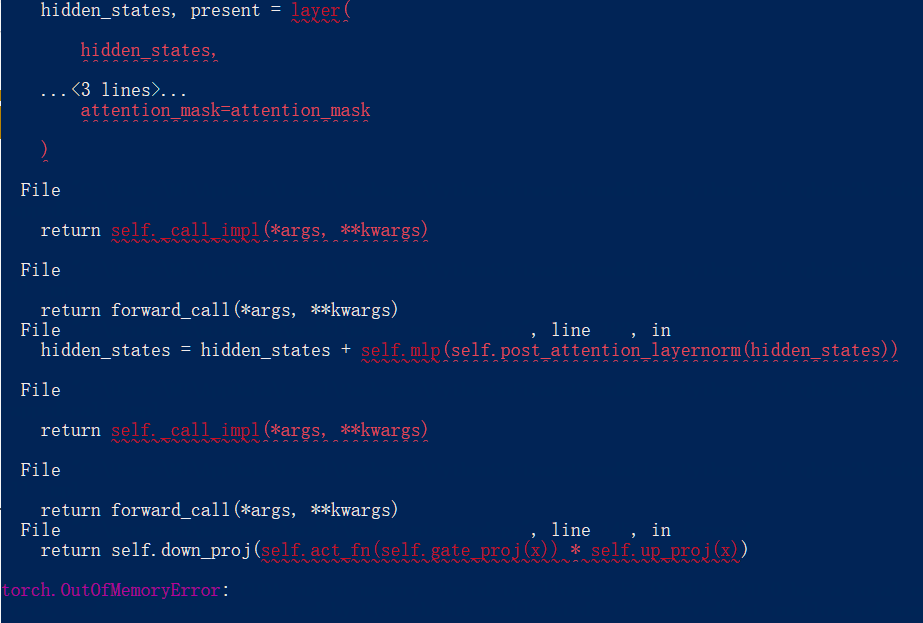
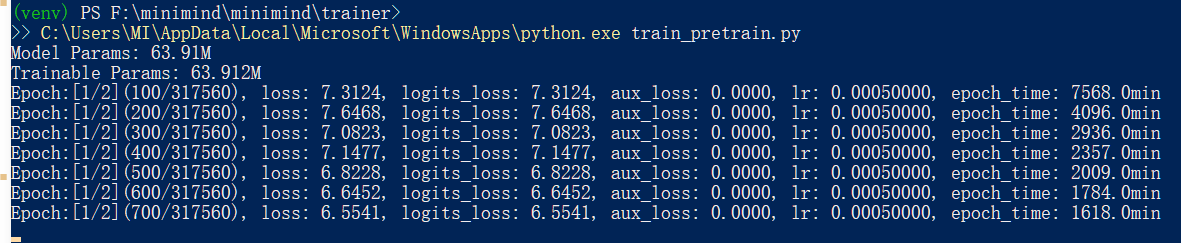
第一次爆显存了,调整参数后继续训练,将参数调小后可以了。

四、指令微调:让模型听懂人类指令
1. 准备指令数据集
python
from datasets import load_dataset
ds = load_dataset("minimind/minimind-cn-sft-5k")
print(ds[0])
# 输出: {"instruction": "写一首关于春天的诗", "output": "春风拂面百花开,燕子归来筑巢忙..."}2. 启动监督微调(SFT)
python
python train_sft.py \
--pretrained_model ./output/64M_pretrain \
--dataset minimind/minimind-cn-sft-5k \
--epochs 3 \
--batch_size 16五、模型部署:本地运行与API服务
1. 本地对话测试
python
from minimind.model import MiniMind
model = MiniMind.from_pretrained("./output/64M_sft")
response = model.chat("法国的首都是哪里?")
print(response) # 输出: 法国的首都是巴黎。2. 启动OpenAI兼容API
python
python api_server.py \
--model ./output/64M_sft \
--port 8000调用示例:
python
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"messages": [{"role": "user", "content": "解释牛顿定律"}]}'六、性能优化:小显卡的加速技巧
1. 技术对比(RTX 3050实测)
| 技术 | 显存占用 | 训练速度 | 适用场景 |
|---|---|---|---|
| 原始模式 | 4GB | 1.0x | 调试 |
| 梯度累积(step=4) | 3.6GB | 0.9x | 显存不足时 |
| 混合精度 | 3GB | 1.7x | 推荐默认开启 |
2. 高级技巧:LoRA微调
python
from peft import LoraConfig
lora_config = LoraConfig(
r=8, # 低秩矩阵秩
target_modules=["q_proj", "v_proj"] # 仅微调注意力层
)
model.enable_lora(lora_config) # 注入LoRA适配器优势:
- 显存占用降低70%
- 微调速度提升3倍
结语:为什么MiniMind值得尝试?
- 完全透明: 所有代码从零实现(包括RMSNorm、RoPE位置编码等),拒绝黑盒
- 全流程覆盖: 预训练→SFT→RLHF→工具调用→模型蒸馏,一站式学习 。
- 兼容主流生态: 模型可直接转换为GGUF格式运行于llama.cpp,或部署至ollama/vLLM 。
开发者说: "用乐高拼飞机,远比坐头等舱更让人兴奋。MiniMind 的目标是让每个人都能理解大模型的每一行代码。" ------ 项目作者 @jingyaogong
附录:扩展资源
- 项目地址:https://github.com/jingyaogong/minimind
- 预训练模型下载:
ollama run jingyaogong/minimind-3 - 进阶教程:《MoE稀疏激活原理与实战》
注:本文代码实测环境:RTX 3050 + Windows11操作系统,所有截图及日志来自真实运行记录。