哈喽,我是我不是小upper~
在时间序列短期预测任务中,很多同学容易陷入一个误区:一味追求复杂模型、盲目拉长历史依赖窗口,反而导致预测效果大打折扣。
正如导师常说的:短期预测别瞎搞!AR 模型为啥只看最近几步? 其实答案很朴素:时序数据中,越近的历史信息对未来的影响越强、参考价值越高,也就是 "记忆越近越有用"。
今天就带大家从最基础、最经典的时间序列模型入手,系统讲解基于自回归模型(AR)的短期预测技术,从核心原理到完整代码实现一次性讲透,这个基础课题也是后续进阶时序模型的重要前提,非常值得前期重点掌握。
先直接给出核心结论:自回归(Autoregression, AR)是专门适配短期预测 的经典时序模型,它的核心逻辑可以用一句话概括:利用时间序列过去若干步的观测值,通过线性组合直接预测下一步数值。
可以把它理解成一本 "精准记账本":只记住最近发生的关键状态,基于历史惯性线性外推,就能大概率推断出下一步的趋势。这里强调 "短期",本质是在界定有效记忆范围 ------ 超出短期窗口后,历史信息的相关性会快速衰减,外加外部干扰因素增多,长期预测精度会急剧下降。
接下来,我会从 AR 模型基础原理讲起,一步步带大家完成完整的模型实现与预测案例。
(一) 核心逻辑:自回归模型的核心原理与适配性
自回归模型(AR)的核心逻辑其实非常直观,本质就是通过历史数据的线性关联,预测下一个时刻的数值------简单来说,就是将未来某一时刻的值,拆解为过去若干步历史值的加权组合,再叠加常数项和随机误差项,用简洁的线性关系捕捉时序数据的"惯性"。
我们可以用一个贴近生活的例子快速理解:比如预测当天的气温,最具参考价值的从来不是几天前的遥远数据,而是近期的气温变化趋势。具体可表示为:
今天的温度 ≈ 0.7 × 昨天温度 + 0.2 × 前天温度 + 0.1 × 大前天温度 + 少量随机波动
这个简单的线性关系,正是AR模型的核心思想------时序数据的"惯性"特征,最近发生的状态,对下一步的影响最直接、参考意义也最强,这也是它能适配短期预测的核心前提。
从数学角度来看,自回归模型的标准形式为AR(p)模型,其中p代表"记忆长度",即用于预测未来的历史步数,其严格数学公式如下:
结合公式,我们能更清晰地理解AR模型的工作逻辑:第t时刻的预测值X_t,由常数项c、前p个时刻的历史观测值()及其对应的权重系数(
),再加上随机误差项
构成。
而AR模型之所以天生适合短期预测,核心原因的在于时序数据的信息衰减特性:
一方面,最近几步的历史观测值,能精准捕捉当前时序数据的运行节奏和真实状态,干扰因素少、与当前时刻的相关性极强,能为预测提供最可靠的支撑;另一方面,随着预测步数的不断增加,历史信息的相关性会快速减弱,同时外界噪声、突发事件、趋势变动等不可控因素会不断叠加,而AR模型的线性结构无法适配这种复杂的非线性变化,预测精度会急剧下降。
基于这一逻辑,AR模型应用过程中,有三个核心关键问题必须掌握,也是后续模型落地的基础:
-
记忆长度p的确定:p作为AR模型的核心超参数,决定了用过去多少步的历史数据进行预测。p设置过小,会遗漏关键历史信息,导致模型欠拟合;p设置过大,会引入无关的历史噪声,引发过拟合。
-
权重系数
的求解:核心目标是找到一组最优权重,使模型预测值与实际观测值的误差最小,常用方法有两种------最小二乘法(OLS),通过最小化残差平方和求解最优系数;正则化方法(Ridge/Lasso),通过给系数添加惩罚项,避免过拟合,提升模型泛化能力。
-
多步预测的实现:AR模型的多步预测采用"递推滚动"模式,先通过历史观测值预测出下一步的值,再将该预测值作为新的历史数据,结合此前的历史观测值,继续预测下下一步,以此类推,逐步实现多步预测。
这里需要重点说明正则化的作用:当滞后阶数p设置过大时,模型容易过度拟合历史数据中的偶然噪声(如异常值),出现"训练时精准、实战时失真"的问题------训练集上的预测误差很小,但遇到新的时序数据时,误差会急剧增大。而Ridge(L2正则化)、Lasso(L1正则化)通过给权重系数添加惩罚项(Ridge惩罚系数平方和,Lasso惩罚系数绝对值和),限制系数取值不过分极端,从而有效避免过拟合,让模型在新数据上的泛化能力更稳定。
针对短期预测,还有两个实用小诀窍,能进一步提升预测精度:
一是短期多步预测优先采用递推模式,这种方式更贴合时序数据的"惯性"特征,预测结果更贴合实际趋势;若直接一次性预测多步,会不断放大误差,精度远低于递推模式。
二是数据切分必须遵循时间顺序,时序数据的核心价值在于"时间关联性",训练集与测试集的切分需按时间先后划分(如前80%为训练集、后20%为测试集),绝对不能随机打乱,否则会出现"数据泄露"(用未来数据训练模型),导致模型失去实际预测价值。
总的来说,AR模型用于短期预测,是一种"常识+线性"的高效解决方案:核心是抓住"最近的历史信息",不盲目追求过长的记忆长度和复杂的模型结构;既充分利用了时序数据的线性惯性,又凭借简洁的结构实现高效执行,是时间序列短期预测的入门首选。
自回归模型(AR)的核心思路非常朴素,本质是利用时间序列的"惯性"------用过去一段时间的观测值,通过线性组合的方式,预测未来的下一个值。
通俗来讲,它就像我们根据近期的状态推断下一步走向:比如预测今天的温度,最有参考价值的不是一周前的温度,而是昨天、前天的温度,我们可以用这样的逻辑近似描述:
今天的温度 ≈ 0.7 × 昨天温度 + 0.2 × 前天温度 + 0.1 × 大前天温度 + 少量随机波动
这种"用过去推未来"的线性关系,就是AR模型的核心,也是它适配短期预测的关键------越近的历史信息,对当前状态的反映越真实,参考价值越高。
02 为什么AR模型天生适合短期预测?
核心原因在于时间序列的"信息衰减特性":
-
近期信息的及时性:最近几步的观测值,能精准反映当前时序的运行节奏和状态,干扰因素少、相关性强;
-
长期信息的不确定性:随着预测步数的增加,历史信息的相关性会快速衰减,同时外界噪声、突发事件、趋势变动等不可控因素会不断叠加,而AR模型的线性结构,无法适配这种复杂的非线性变化,此时预测精度会急剧下降。
03 AR模型的数学表达:AR(p)模型
从数学角度,自回归模型被定义为AR(p)模型,其中p代表"记忆长度",即用来预测未来的"过去步数",其标准公式如下:
公式各参数含义详解:
-
-
c:模型的常数项(偏移量);
-
-
-
04 AR模型应用的3个关键问题(必掌握)
1. 记忆长度p如何确定?
p是AR模型的核心超参数,代表"用过去多少步的历史数据来预测未来"。p太小,会遗漏关键的历史信息,导致模型欠拟合;p太大,会引入过多无关的历史噪声,导致模型过拟合。
常用确定方法:结合AIC、BIC准则(信息准则越小越好),或通过自相关函数(ACF)、偏自相关函数(PACF)的截尾特性判断。
2. 权重系数如何求解?
核心目标是找到一组最优的权重系数,让模型预测值与实际观测值的误差最小,常用方法有两种:
-
最小二乘法(OLS):最基础的求解方法,通过最小化预测值与实际值的残差平方和,求解系数的最优解;
-
正则化方法(Ridge/Lasso):针对p较大时的过拟合问题,通过给系数添加惩罚项,限制系数的绝对值,提升模型的泛化能力。
3. 多步预测如何实现?
AR模型的多步预测采用"递推滚动"的方式,核心逻辑的:
-
先用历史观测值
-
再将预测出的
-
以此类推,逐步递推,实现多步预测。
05 为什么需要正则化?
当我们将滞后阶数p设置得过大时,模型会过度拟合历史数据中的噪声(比如偶然的异常值),导致"短期看似精准,长期预测失真"------比如训练时预测误差很小,但遇到新的时序数据时,误差会急剧增大。
而Ridge(L2正则化)、Lasso(L1正则化)等方法,通过给权重系数添加惩罚项(Ridge惩罚系数的平方和,Lasso惩罚系数的绝对值和),可以限制系数的取值不过分极端,从而避免过拟合,让模型在新数据上的泛化能力更稳定。
06 短期预测的2个实用小诀窍
-
多步预测优先用递推:对于短期预测,递推滚动的方式更贴合时序数据的"惯性",预测结果更贴合实际趋势;如果直接一次性预测多步,会放大误差,精度远不如递推。
-
数据切分必须按时间顺序:时序数据的核心是"时间关联性",切分训练集和测试集时,必须按时间先后划分(比如前80%为训练集,后20%为测试集),绝对不能随机打乱------否则会导致"数据泄露"(用未来的数据训练模型),让模型失去实际预测价值。
总的来说,自回归短期预测是个常识 + 线性的办法------抓住最近,别贪太远;模型简洁,执行高效。
(二) 一个通俗例子:直观理解AR模型的工作方式
用一个日常场景就能轻松搞懂AR模型的核心,无需复杂推导:假设你每天固定往杯子里倒水,杯子水位虽有小幅波动,但整体变化平缓、有明显惯性。
通过观察,你发现一个规律:今天的水位,大致是昨天水位的80%,再叠加一个微小的随机误差(比如±0.5,模拟外界轻微干扰)。
若设昨天的水位为,则今天的水位可表示为:
其中为随机误差项(取值±0.5),代入数值可得:
。
如果要预测明天的水位,就用今天的预测值(或实际值)继续沿用这个规律:
预测后天的水位,则继续递推:
这就是AR(1)模型的核心逻辑------仅用前1步(p=1)的历史数据,通过线性惯性预测下一步,式中的0.8就是惯性系数(模型参数),可通过历史水位数据拟合得到。
若觉得只看前1步不够精准,可增加历史步数,比如同时参考昨天和前天的水位,这就变成了AR(2)模型,形式如下:
本质上,AR模型的核心就是:给定一串历史数据,找到一组最优权重系数(如0.8、、
),让线性加权后的预测值,尽可能贴近历史实际值,本质就是学习时序数据的"惯性"。
(三) 核心逻辑:AR(p)模型细节与实操要点
一、模型形式(AR(p))
AR(p)模型的标准数学形式的为:
其中:c为常数项,为滞后项权重系数,p为滞后阶数(记忆长度),
为随机误差项。
二、模型训练目标
训练的核心是最小化预测值与实际值的平方误差和,公式如下:
若需避免过拟合(如p设置过大),可加入Ridge正则化,目标函数变为:
其中为正则化惩罚系数,用于限制系数取值过大。
三、递推预测(多步预测方法)
AR模型多步预测采用递推滚动方式,核心是用预测结果作为新的历史数据,逐步推导:
- 一步预测:直接用历史观测值计算,公式为:
- 两步预测:将一步预测结果
后续多步预测以此类推,所有需要的未来滞后项,均采用前一步的预测结果替代。
四、模型评估指标
常用两个核心指标评估预测精度,避免除零问题需加入微小常数\\epsilon(如\\epsilon=1e-8):
- 均方根误差(RMSE):衡量预测值与实际值的平均偏差,值越小精度越高:
- 平均绝对百分比误差(MAPE):衡量相对误差,更直观反映预测偏差比例:
五、滞后阶数p的选择方法
p的取值直接影响模型效果,常用两种简单高效的方法:
方法A:观察自相关函数(ACF),看滞后到第几阶时,自相关系数仍有明显相关性(未落入置信区间),该阶数可作为p的参考值。
方法B:结合时间序列折叠交叉验证(TimeSeriesSplit)做网格搜索,选取多个候选p值(如6、12、24),选择验证集误差(RMSE/MAPE)最小的p作为最优值。
六、数据准备要点(关键避坑)
-
切分规则:按时间顺序切分为训练集、验证集、测试集,严禁随机打乱,避免数据泄露。
-
归一化/标准化:仅在训练集上拟合归一化/标准化参数(如均值、标准差),再用该参数变换验证集和测试集,避免引入未来信息。
-
滞后特征构造:严格按时间顺序对齐滞后项,确保构造特征时不引入未来时刻的数据。
七、残差检验要点
残差即实际值与预测值的差值(),理想情况下残差需满足白噪声特性:均值接近0、无明显时间相关性。
若残差仍存在明显结构性模式(如周期性、趋势性),说明模型未捕捉到数据的全部规律(如季节性、节假日效应),需进一步优化模型。
**(四)**完整案例
这里,我们专门生成一个合成数据集:既有趋势、又有季节性,还有 AR 的惯性。然后用滞后特征 + Ridge 回归来拟合,做短期预测。
步骤:
-
构造数据,趋势 + 周期 + 惯性 + 噪声
-
画出数据和分解图
-
计算并画自相关(ACF)
-
构造滞后特征矩阵
-
用时间序列交叉验证选择滞后阶数 p 和正则强度 α
-
训练最终模型
-
递推预测未来 N 步
-
评估误差、画预测对比图、画残差诊断图
-
画系数-滞后阶数图看模型在用哪些记忆
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import Ridge
from sklearn.model_selection import TimeSeriesSplit
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
np.random.seed(42)
sns.set_theme(style="whitegrid", font_scale=1.1)
palette = ['#e41a1c','#377eb8','#4daf4a','#984ea3', '#ff7f00',
'#ffff33', '#a65628', '#f781bf', '#999999']
sns.set_palette(palette)
# 1) 数据集
T = 1000
t = np.arange(T)
# 设定周期:例如日内 24、周内 168;用其中一个,叠加一些谐波
period = 24
seasonal = 1.5*np.sin(2*np.pi*t/period) + 0.8*np.sin(2*np.pi*t/(period/2))
# 趋势项(缓慢上升)
trend = 0.002 * t
# AR(2) 惯性生成:x_t = 0.6*x_{t-1} - 0.3*x_{t-2} + seasonal + trend + noise
x = np.zeros(T)
noise = 0.8 * np.random.randn(T)
x[0] = 0.0
x[1] = 0.5
for i in range(2, T):
x[i] = 0.6*x[i-1] - 0.3*x[i-2] + seasonal[i] + trend[i] + noise[i]
data = pd.DataFrame({
't': t,
'y': x,
'seasonal_true': seasonal,
'trend_true': trend
})
# 简单"分解":移动平均近似趋势,按周期平均近似季节成分
win = 2*period # 窗口
data['trend_ma'] = pd.Series(x).rolling(win, center=True, min_periods=1).mean()
detrended = data['y'] - data['trend_ma']
# 估季节:对相位分组取均值
seasonal_idx = t % period
seasonal_est = pd.Series(detrended).groupby(seasonal_idx).transform('mean')
data['seasonal_est'] = seasonal_est
data['resid_est'] = data['y'] - data['trend_ma'] - data['seasonal_est']
# 2) 图1:原始序列 + 趋势 + 季节 + 残差(多图组合)
fig, axes = plt.subplots(4, 1, figsize=(12, 12), sharex=True)
axes[0].plot(data['t'], data['y'], color=palette[0], lw=1.8, label='y (observed)')
axes[0].set_title('Figure 1: Time series and decomposition (observations)')
axes[0].legend()
axes[1].plot(data['t'], data['trend_ma'], color=palette[1], lw=2.0, label='trend (MA)')
axes[1].plot(data['t'], data['trend_true'], color=palette[3], lw=1.0, alpha=0.8, label='trend (true)', linestyle='--')
axes[1].set_title('Trend (Moving Average vs. True Value)')
axes[1].legend()
axes[2].plot(data['t'], data['seasonal_est'], color=palette[2], lw=1.8, label='seasonal (est)')
axes[2].plot(data['t'], data['seasonal_true'], color=palette[4], lw=1.0, alpha=0.8, label='seasonal (true)', linestyle='--')
axes[2].set_title('Seasonality (estimated vs. true value)')
axes[2].legend()
axes[3].plot(data['t'], data['resid_est'], color=palette[5], lw=1.5, label='residual (est)')
axes[3].axhline(0, color='#666666', lw=1.0, alpha=0.6)
axes[3].set_title('Residual (estimation)')
axes[3].legend()
plt.tight_layout()
# 3) 自相关函数(ACF)计算与可视化(到 48 阶)
def acf(x, nlags=48):
x = np.asarray(x)
x = x - x.mean()
corr = np.correlate(x, x, mode='full')
corr = corr[corr.size//2:]
corr = corr / corr[0]
return corr[:nlags+1]
nlags = 48
acf_vals = acf(data['y'].values, nlags=nlags)
# 图2:ACF 条形 + 置信带
fig, ax = plt.subplots(figsize=(12, 4))
lags = np.arange(nlags+1)
colors = [palette[(i % (len(palette)-1))+1] for i in lags]
ax.bar(lags, acf_vals, color=colors, edgecolor='black', alpha=0.9)
ax.axhline(0, color='#222222', lw=1.0)
# 近似置信区间(大样本近似 ±1.96/sqrt(N))
N = len(data)
conf = 1.96/np.sqrt(N)
ax.fill_between(lags, conf, -conf, color='#cccccc', alpha=0.4, label='approx 95% CI')
ax.set_title('Figure 2: Autocorrelation function ACF (orders 0-48)')
ax.set_xlabel('lag')
ax.set_ylabel('ACF')
ax.legend()
plt.tight_layout()
# 4) 构造滞后特征
def make_lag_matrix(y, max_lag):
# 返回特征矩阵 X (N - max_lag, max_lag),和目标 y_trim
Y = np.asarray(y)
N = len(Y)
X = []
for t in range(max_lag, N):
X.append(Y[t-max_lag:t][::-1]) # [y_{t-1}, y_{t-2}, ...]
X = np.array(X)
y_trim = Y[max_lag:]
return X, y_trim
# 划分训练、验证、测试
train_ratio, val_ratio = 0.7, 0.2
train_end = int(T*train_ratio)
val_end = int(T*(train_ratio + val_ratio))
# 5) 用时间序列交叉验证选择 p 和 α
candidate_p = [6, 12, 18, 24, 30, 36]
candidate_alpha = [0.0, 0.1, 1.0, 3.0, 10.0] # 0.0 近似无正则
best_cfg = None
best_score = np.inf
def smape(y_true, y_pred, eps=1e-6):
num = np.abs(y_pred - y_true)
den = (np.abs(y_true) + np.abs(y_pred) + eps) / 2.0
return 100.0*np.mean(num/den)
tscv = TimeSeriesSplit(n_splits=4)
y_trainval = data['y'].values[:val_end]
for p in candidate_p:
X_p, y_p = make_lag_matrix(y_trainval, max_lag=p)
# 对应的时间索引(从 p 到 val_end-1)
idx = np.arange(p, val_end)
for alpha in candidate_alpha:
fold_scores = []
for train_idx, test_idx in tscv.split(idx):
tr_ids = idx[train_idx]
te_ids = idx[test_idx]
# 按索引映射到 X_p,y_p 的行
X_tr = X_p[train_idx]
y_tr = y_p[train_idx]
X_te = X_p[test_idx]
y_te = y_p[test_idx]
# 标准化(只用训练集拟合)
scaler = StandardScaler()
X_trs = scaler.fit_transform(X_tr)
X_tes = scaler.transform(X_te)
model = Ridge(alpha=alpha, fit_intercept=True, random_state=42)
model.fit(X_trs, y_tr)
y_pred = model.predict(X_tes)
fold_scores.append(smape(y_te, y_pred))
cfg_score = np.mean(fold_scores)
if cfg_score < best_score:
best_score = cfg_score
best_cfg = (p, alpha)
print("Best (p, alpha):", best_cfg, "CV sMAPE:", round(best_score, 3))
# 6) 用最优 p、α 在训练+验证集上拟合,测试集上评估
p_opt, alpha_opt = best_cfg
X_all, y_all = make_lag_matrix(data['y'].values[:val_end], max_lag=p_opt)
# 训练集:从 p_opt 到 train_end-1;验证集:train_end 到 val_end-1
idx_all = np.arange(p_opt, val_end)
train_mask = idx_all < train_end
val_mask = ~train_mask
X_tr = X_all[train_mask]
y_tr = y_all[train_mask]
X_v = X_all[val_mask]
y_v = y_all[val_mask]
scaler = StandardScaler()
X_trs = scaler.fit_transform(X_tr)
X_vs = scaler.transform(X_v)
final_model = Ridge(alpha=alpha_opt, fit_intercept=True, random_state=42)
final_model.fit(X_trs, y_tr)
# 训练+验证上看一下拟合误差
y_v_pred = final_model.predict(X_vs)
rmse_val = np.sqrt(mean_squared_error(y_v, y_v_pred))
mape_val = smape(y_v, y_v_pred)
print("Validation RMSE:", round(rmse_val, 3), "sMAPE:", round(mape_val, 2), "%")
# 7) 递推预测:对测试集做多步滚动
test_y = data['y'].values[val_end:]
H = len(test_y)
# 初始化历史缓冲:取验证集末尾的 p_opt 个真实值
history = data['y'].values[val_end - p_opt:val_end].tolist()
preds = []
for h in range(H):
# 构造当前滞后特征
x_feat = np.array(history[-p_opt:][::-1]).reshape(1, -1)
x_feat_s = scaler.transform(x_feat)
y_hat = final_model.predict(x_feat_s)[0]
preds.append(y_hat)
# 递推:把预测当作下一步历史
history.append(y_hat)
test_pred = np.array(preds)
test_true = test_y
rmse_test = np.sqrt(mean_squared_error(test_true, test_pred))
mape_test = smape(test_true, test_pred)
print("Test RMSE:", round(rmse_test, 3), "sMAPE:", round(mape_test, 2), "%")
# 8) 图3:测试集预测 vs 真实
fig, ax = plt.subplots(figsize=(12, 4))
time_test = np.arange(val_end, T)
ax.plot(time_test, test_true, color=palette[0], lw=2.0, label='真实')
ax.plot(time_test, test_pred, color=palette[2], lw=2.0, linestyle='--', label='预测')
# 同时打点突出关键段
ax.scatter(time_test[::5], test_true[::5], color=palette[6], s=30, alpha=0.9)
ax.scatter(time_test[::5], test_pred[::5], color=palette[4], s=30, alpha=0.9)
ax.set_title('Figure 3: Test Set - Real vs. Predicted (Multi-Step Recursive)')
ax.set_xlabel('t')
ax.legend()
plt.tight_layout()
# 9) 图4:模型系数 vs 滞后阶(看"记忆强度")
coefs = final_model.coef_
lags = np.arange(1, p_opt+1)
fig, ax = plt.subplots(figsize=(12, 4))
ax.bar(lags, coefs, color=palette[1], edgecolor='black', alpha=0.9)
ax.axhline(0, color='#222222', lw=1.0)
ax.set_title('Figure 4: Coefficients vary with lag order (Ridge)')
ax.set_xlabel('lag')
ax.set_ylabel('coefficient')
plt.tight_layout()
# 10) 图5:残差诊断(时间域 + 分布)
residuals = test_true - test_pred
fig, axes = plt.subplots(1, 2, figsize=(14, 4))
axes[0].plot(time_test, residuals, color=palette[5], lw=1.5)
axes[0].axhline(0, color='#333333', lw=1.0)
axes[0].set_title('Figure 5a: Residual timing diagram (test set)')
# 直方图 + KDE
axes[1].hist(residuals, bins=30, color=palette[7], alpha=0.8, density=True, edgecolor='black')
# 自己简单估个KDE
from scipy.stats import gaussian_kde
kde = gaussian_kde(residuals)
xs = np.linspace(residuals.min(), residuals.max(), 200)
axes[1].plot(xs, kde(xs), color=palette[3], lw=2.0, label='KDE')
axes[1].set_title('Figure 5b: Residual distribution (test set)')
axes[1].legend()
plt.tight_layout()
# 11) 附加图6:残差的 ACF(看是否还有结构)
res_acf = acf(residuals, nlags=36)
fig, ax = plt.subplots(figsize=(12, 4))
lags_r = np.arange(37)
ax.bar(lags_r, res_acf, color=palette[8], edgecolor='black', alpha=0.9)
ax.axhline(0, color='#222222', lw=1.0)
conf_r = 1.96/np.sqrt(len(residuals))
ax.fill_between(lags_r, conf_r, -conf_r, color='#cccccc', alpha=0.4, label='approx 95% CI')
ax.set_title('Figure 6: Residual ACF (Is there any related structure?)')
ax.set_xlabel('lag')
ax.set_ylabel('ACF')
ax.legend()
plt.tight_layout()
plt.show()时间序列与分解(观察值、趋势、季节、残差):
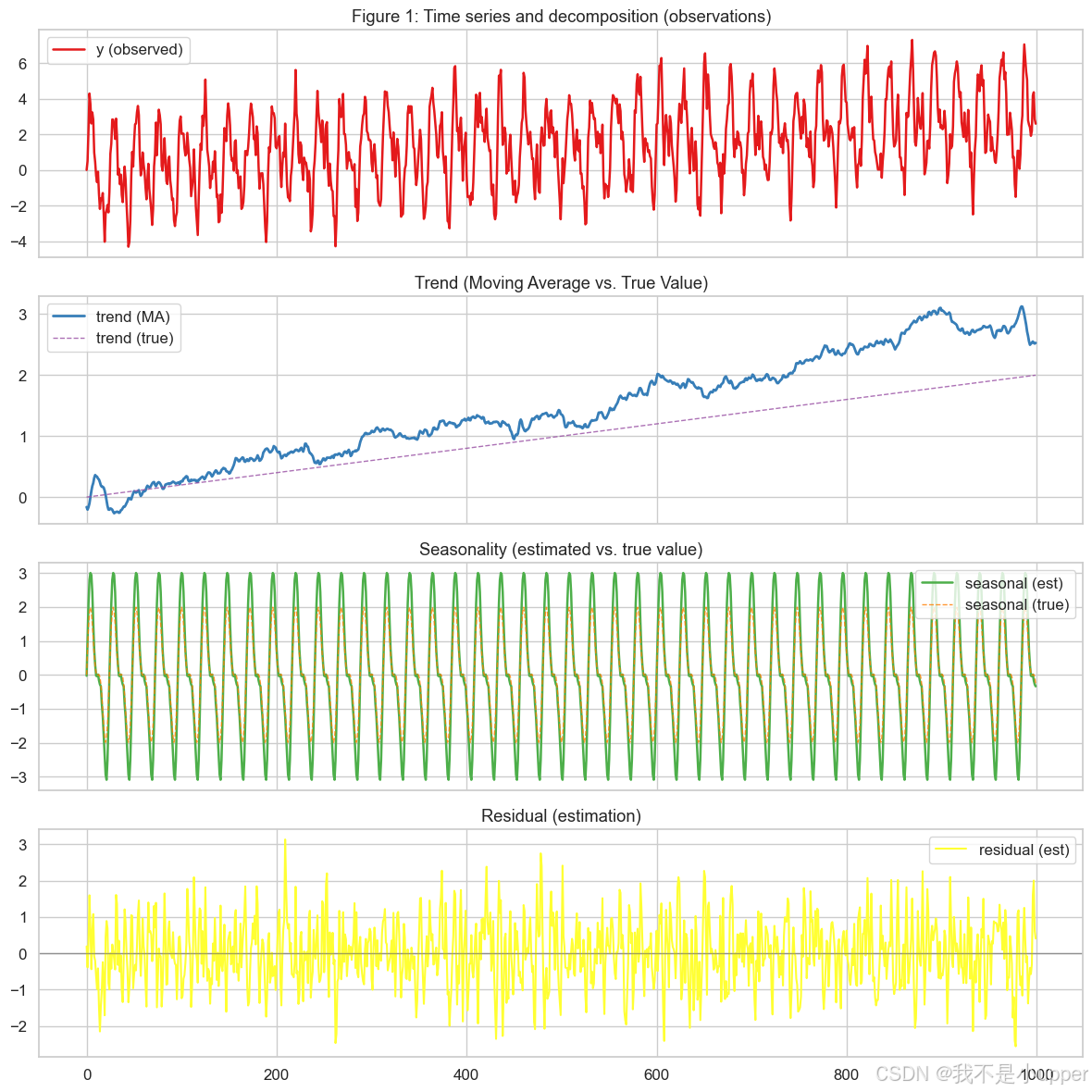
这张图帮助你确认数据里同时存在缓慢上升趋势和明显的周期振荡。移动平均估的趋势和真实趋势线形相近,说明平滑后取近似趋势可用;季节性估计的波形大体贴近真实季节波形。残差图应该在 0 附近波动,没有强烈的系统性结构。
自相关****函数 ACF(0-48 阶):
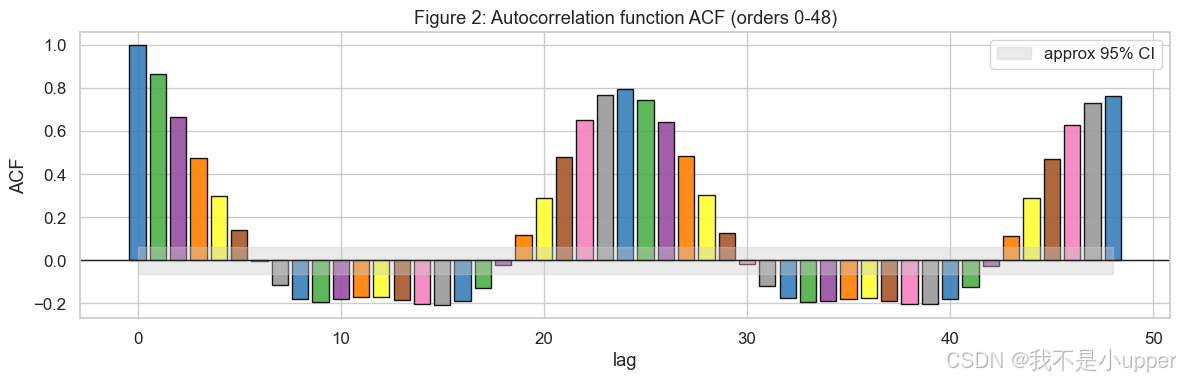
高的自相关峰值说明记忆存在,多数时间序列在季节周期附近(比如第 24 阶)会有显著峰,表明选择 p 至少要覆盖到这个周期的一部分。若 ACF 快速衰减,说明短记忆足够;若缓慢衰减,可考虑更大的 p 或更丰富的结构。
测试集真实 vs 预测(递推多步):
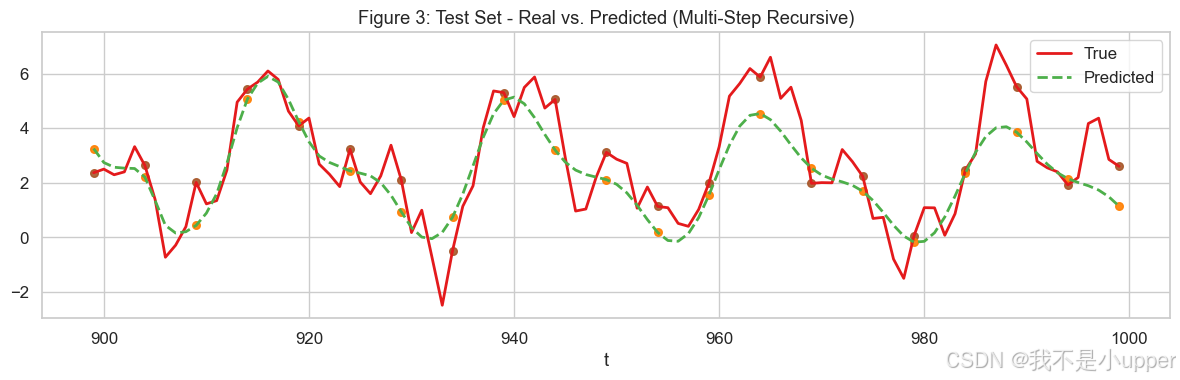
是最核心的成效图。观察整体趋势和主要起伏是否跟得上。若预测线和真实线整体同向、相位吻合,短期预测基本合格。偏差大、滞后严重,则模型需要改进(比如增加滞后阶、加强正则、引入季节性特征等)。
系数随滞后阶变化(Ridge):
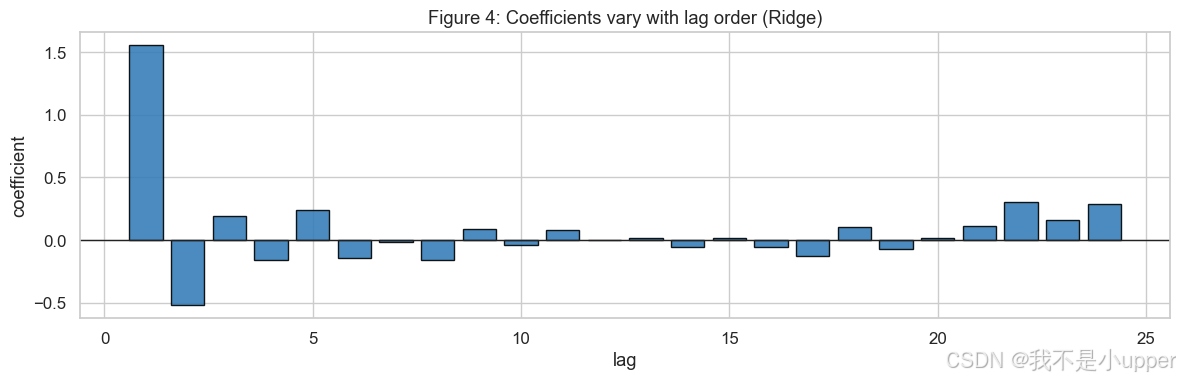
它告诉你模型最信哪几阶的过去。常见现象:前1-2阶系数较大,表示最近行为最重要;若在周期相关的lag(如 24)也出现显著系数,说明模型抓住了季节记忆。
残差诊断(时间域 + 分布):
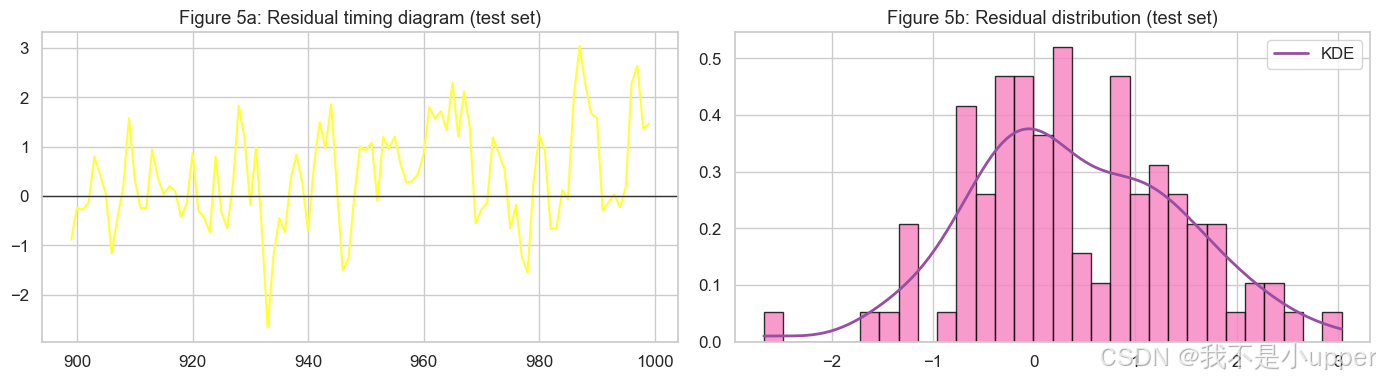
时间域残差若围绕 0 小幅震荡、没有长时间偏正/偏负,说明模型没有明显系统偏差。分布图看是否近似对称、尖峭程度如何;若偏重尾,可能异常点多或噪声非高斯。
残差的 ACF:
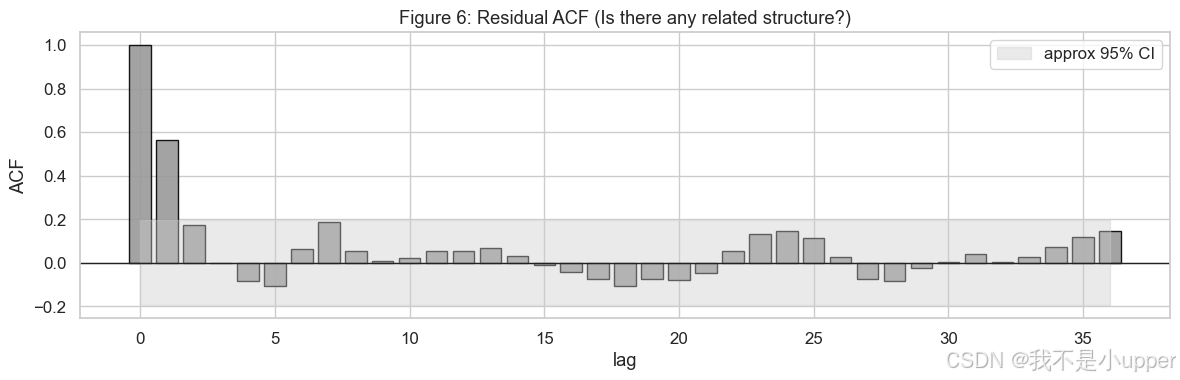
理想状况是各阶残差自相关都落在置信带内(不显著),说明剩下的误差像白噪声。如果某些 lag 明显越界,说明还有未建模的结构,可以考虑加特征或改模型。
核心步骤
数据生成: 我们构造了趋势 + 多谐波季节 + AR(2) 惯性 + 高斯噪声的序列,模拟现实里既有长期变化,又有周期波动,还存在惯性的情况。
简易分解: 用移动平均近似趋势,按相位分组均值近似季节。这不是严格意义上的 STL 分解,但直观、易实现。
**自相关分析:**用 ACF 看记忆长度,帮助决定滞后阶范围,避免盲选。
特征构造: 把当作特征, 当标签。
**时序交叉验证:**用 TimeSeriesSplit 折叠,随时间前进,不允许打乱,评估候选 p、α 的泛化能力。
标准化: 只在训练折上拟合 scaler,把验证/测试映射到同一标准。避免穿越。
**模型:**Ridge 回归,拟合 AR 系数;Ridge 在滞后特征较多时更稳健,能抗过拟合。
**递推预测:**一步步滚动,用上一时刻的预测作为下一时刻的输入,持续 H 步。短期效果往往最佳,中长期误差会积累。