01
一.工具介绍
1.1 背景与问题
在软件开发的日常工作中,代码审查是保障代码质量、规避潜在风险、促进团队协同的核心环节。然而,纯人工审查通常会面临以下几个问题:
效率瓶颈:资深开发者需耗费大量时间检查基础性问题,重复劳动突出;新人开发者因经验不足,往往导致审查周期延长,进而影响整体交付进度。
标准不一致:不同审查者对代码质量的评判标准存在主观差异,相同问题在不同MR(Merge Request)中可能得到不同处理结果,大幅降低团队协作效率。
漏检风险:人工审查易因疲劳、疏忽遗漏关键安全漏洞或逻辑缺陷,此类问题一旦进入生产环境,可能引发严重系统故障,造成不必要的损失。
基于上述问题,我们实现了一套基于 GitLab Merge Request 的自动化代码审查系统。系统在 MR 提交后自动触发,解析代码变更内容,调用大语言模型完成审查,并将审查结果回写到 MR 评论区。该系统的目标并非替代人工审查,而是将其中重复性强、规则性强、容易遗漏的部分前置为自动化处理能力,具体包括:
自动识别语法错误、基础漏洞和常见缺陷;
在团队内形成相对统一的基础审查标准;
在不改变现有研发流程的前提下,将审查结果直接落到 MR 上。
02
二.整体架构设计
2.1 系统能力
围绕 GitLab Merge Request 的审查流程,系统主要提供以下能力:
-
监听GitLab Merge Request事件并自动触发审查;
-
解析代码 Diff,并建立准确的行号映射关系;
-
调用大语言模型识别代码缺陷、安全问题和性能风险;
-
自动创建与清理 MR 评论;
-
通过限流、并发控制与重试机制保证系统稳定性;
-
记录完整日志,便于问题定位与执行追踪。
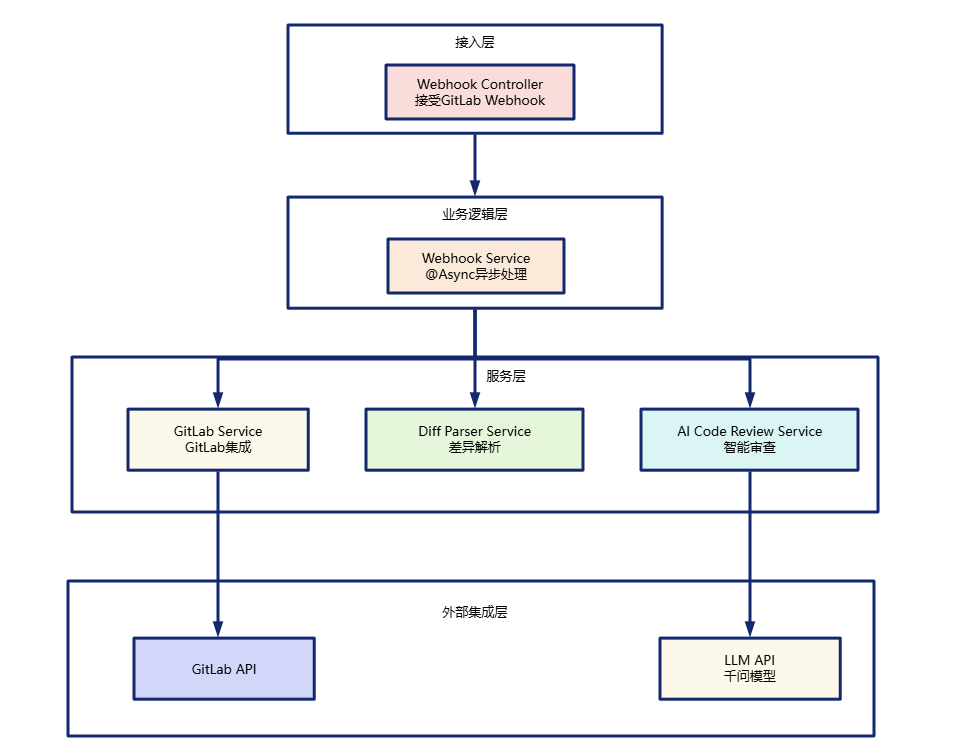
2.2 分层设计
为便于维护与扩展,系统整体采用分层设计,划分为接入层、业务逻辑层、服务层和外部集成层。
| 层次 | 核心职责 |
|---|---|
| 接入层 | 接收 GitLab Webhook 请求,完成请求校验、参数提取和事件过滤。 |
| 业务逻辑层 | 串联完整审查流程,包括事件处理、Diff 解析、AI 审查和评论发布。 |
| 服务层 | 封装核心能力,例如 Diff 解析、AI 审查、GitLab 评论管理等。 |
| 外部集成层 | 对接 GitLab API 与 LLM API,负责获取 MR 信息、提交评论和调用模型。 |
系统整体架构示意图:
03
三.核心模块设计
下文按照实际处理链路,对系统中的几个关键模块进行拆解说明。
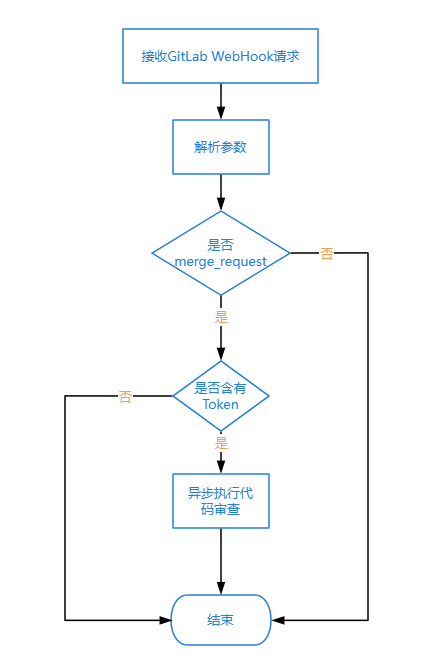
3.1 Webhook 事件处理与请求验证
Webhook 是整套系统的入口,其职责主要包括两部分:
一是识别并过滤需要处理的事件;二是将后续审查任务交由后台异步执行。
GitLab 会推送多类事件,但系统只处理 merge_request 类型,其他事件直接忽略,以减少无效请求对系统资源的占用。
异步执行这一设计背后有一个明确的工程约束:GitLab Webhook 接口存在 10 秒超时限制,而一次完整的 AI 审查通常包括 Diff 解析、Prompt 组装、模型调用、结果清洗以及评论回写等步骤,很难在 10 秒内稳定完成。
因此,系统将处理流程拆分为两段:
Webhook 接口层:只负责校验、过滤、参数提取和任务投递,并尽快返回成功响应;
后台异步任务:负责执行完整的审查流程。
这种拆分方式主要解决两个问题:
第一,避免 GitLab 因接口超时触发重试,造成重复审查;
第二,将耗时操作从入口线程中剥离,降低高并发场景下的阻塞风险。
流程如下:
3.2 Diff 解析与行号映射
在整条处理链路中,Diff 解析并非普通的文本预处理步骤,而是代码审查结果能否准确落地的关键。
对于 AI 审查而言,模型能够理解代码语义,并不意味着它能够稳定地给出正确的评论位置。在 MR 场景中,审查结果不仅要"识别出问题",还必须"定位到正确的代码行"。如果问题判断本身是正确的,但评论落点错误,那么这一结果在研发流程中仍然无法使用。
从这个角度看,Diff 解析所要解决的问题,并不是简单地将 Git Diff 交给模型,而是要完成一次中间层转换:将 GitLab 返回的非结构化变更文本,转换为同时满足模型理解、系统计算和平台校验要求的结构化审查上下文。如果这一层没有处理好,那么后续模型能力再强,最终输出仍然难以稳定回写到 MR 页面。
在方案初期,我们尝试直接将原始 Diff 文件传递给大模型,由模型自行理解上下文并返回评论位置。该方案实现成本较低,但在真实场景中很快暴露出两个典型问题:模型虽然能够识别代码风险,但无法稳定处理 Diff 内部的新旧行号关系,导致评论定位结果不可靠。
问题 1:行号与代码实际位置错位
模型返回的行号在表面上看通常是合理的,但与 GitLab MR 页面中的真实新文件行号并不一致。
根本原因在于,原始 Diff 本质上是一种面向人阅读的补丁格式,它包含 Hunk 头、上下文行、删除行和新增行,却没有将"评论应挂载到哪一条新文件代码行上"以显式结构表达出来。模型可以理解代码含义,但并不擅长稳定推导这类位置语义。
因此,虽然模型能够发现问题,但评论无法准确挂载到对应代码位置,实际可用性较差。

问题 2:生成无效行号
比行号偏移更严重的是,模型有时会生成一个根本不存在于当前变更集中的行号。
这类结果在语义上可能看似合理,但在 GitLab 评论接口校验时会被直接判定为无效位置,最终导致评论创建失败。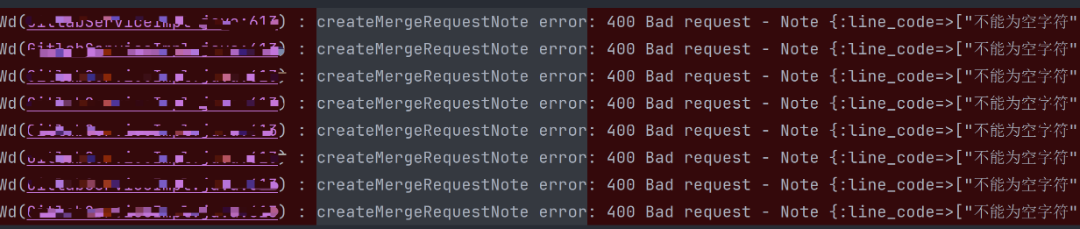
针对上述两类问题,我们从两个层面进行优化:
数据层:先对原始 Diff 进行结构化处理,建立明确的行号映射关系;
模型层:通过 Prompt 约束,限制模型只能从指定结构中提取新行号。
3.2.1 Diff 标准化与行号映射
原始 Diff 虽然包含完整变更信息,但其组织方式遵循补丁格式,更适合人工阅读,不适合作为模型输入或评论定位的直接依据。
因此,我们在服务端增加了一个 Diff 标准化步骤,其目标是:在保留代码变更语义的同时,为每一行补充明确的位置语义。
核心处理流程如下:
1.按 Hunk 分割 Diff
通过匹配 Hunk 头,提取每个变更块对应的新旧文件起始行号及区间信息。Hunk 头格式如下:
@@ -old_start,old_count +new_start,new_count @@
这一步的作用,是为后续行号推进建立准确的起点。
2.逐行扫描并建立映射关系
对 Hunk 内的每一行,根据前缀判断其类型:
+:新增行,仅推进新文件行号;
-:删除行,仅推进旧文件行号;
空格:上下文行,同时推进新旧文件行号。
通过这套规则,可以将原本隐含在 Diff 中的位置关系恢复为显式的新旧行号映射。
3.输出标准化 Diff *
在交给模型之前,为每一行补充旧行号和新行号信息,使其从原始文本差异转化为带位置标签的代码上下文。
经过这一步处理之后,Diff 不再只是供模型阅读的文本,而成为一份统一的中间表示:
它既保留了变更上下文,也提供了明确的位置约束,后续无论是模型分析、结果校验还是评论回写,都可以基于这份标准化结果完成。
从工程视角看,这一步真正解决的是:
将不可直接消费的原始变更数据,转换为系统各环节都可以稳定使用的统一输入。
Hunk 分割结果
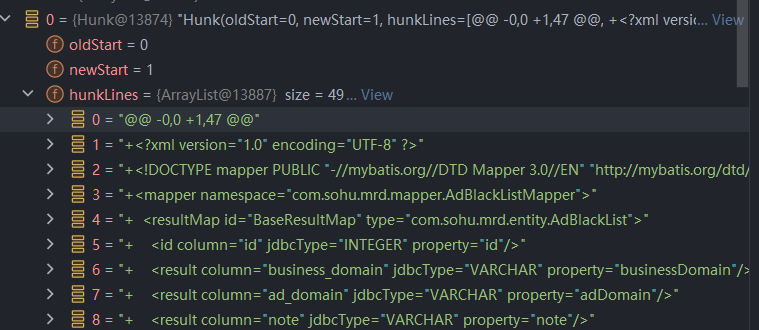 解析 Hunk 后,可以先得到每个变更块对应的新旧文件起始行号及区间信息。
解析 Hunk 后,可以先得到每个变更块对应的新旧文件起始行号及区间信息。
处理后的 Diff 格式
标准化之后,Diff 中的每一行都会显式标出旧行号和新行号,模型不再需要自行推导。
3.2.2 行号提取 Prompt 精细化设计
仅完成结构化 Diff 仍然不够。如果 Prompt 约束不足,模型仍然可能从删除行、上下文行,甚至错误推理结果中提取行号。也就是说,结构化输入解决了"可计算"的问题,但尚未完全解决"可控制"的问题。因此,我们在模型输出层增加了一层明确约束,其原则是:模型只负责识别问题,不负责自由决定评论位置;评论位置必须从预定义结构中提取。
Prompt 新增规则
go
**Diff 格式示例**:
```text
@@ -1,16 +1,13 @@
(3, ) - const oldVar = "delete"; <-- 删除行(忽略)
( , 15) + const newVar = "add"; <-- 新增行(重点关注,新行号为15)
(16, 16) funcCall(newVar); <-- 上下文行(用于理解逻辑)
```
**行号提取绝对规则(Crucial):**
* 我们只针对 **`+` (新增行)** 提出 Issue。
* 输出的 `startLine` 和 `endLine` 必须取自括号内的 **第二个数字(新行号)**。
* 例如:看到 `( , 15) + code`,则 `startLine` 为 15。通过这一步,模型的职责边界被进一步收紧: 它不再负责"生成一个可能正确的位置",而是仅在系统预先提供的合法位置集合中做选择。
这意味着,原本的概率性问题------模型自由生成行号------被收敛为确定性问题------模型从结构化输入中提取合法行号。前者容易漂移,后者可以校验;前者难以定位问题来源,后者则可以直接回溯到具体 Hunk 和具体代码行。
最终,整套方案形成了清晰的职责划分:
• 服务端负责位置计算与数据约束;
• 模型负责代码理解与问题识别;
• GitLab 负责最终位置合法性校验。
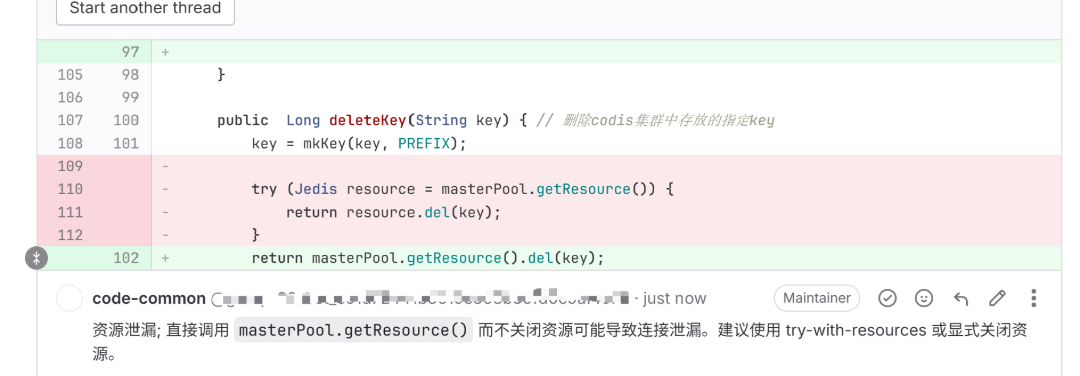
通过这种方式,评论定位从依赖模型发挥的过程,转变为一条可计算、可验证、可调试的工程链路。优化之后,评论行号与实际代码位置的对齐率显著提升,整套审查流程也具备了稳定接入研发流程的条件。
优化后的效果如下:
3.3 审查结果收敛:从开放式生成到规则化审查
行号问题解决之后,系统暴露出的下一个问题,是审查结果本身的质量不稳定。
最典型的表现包括:
• 输出大量缺乏依据的风格建议;
• 对代码作出猜测式评价;
• 评论数量较多,但真正有价值的问题较少。
换言之,系统已经解决了"评论能否发出"的问题,但尚未解决"评论是否值得阅读"的问题。 对于代码审查系统而言,真正重要的并不是评论数量,而是评论的信噪比。如果低价值建议过多,开发者很快就会对自动审查结果失去信任。
下图中的评论,便属于信息密度较低的输出:


3.3.1 问题原因
其根本原因在于,大模型默认更擅长生成"看起来合理"的内容,而不是克制地只输出高价值问题。 如果缺乏约束,模型很容易将代码审查理解为开放式点评任务,从而自然生成大量风格建议、经验性提醒甚至上下文不足的推测。但在真实研发流程中,自动审查并不需要"面面俱到"的评论,而需要在有限阅读成本内,优先暴露那些真正影响正确性、安全性和稳定性的问题。因此,这里需要解决的并不是简单的 Prompt 文案问题,而是重新定义模型在审查链路中的职责边界:
模型不是用来做泛化点评的,而是用来做有边界约束的问题识别。
3.3.2 解决方式
针对这一问题,我们没有继续通过温度参数或多轮试错去调节输出风格,而是直接将开放式生成改为规则化审查。
具体做法是,在 Prompt 中明确规定:
• 哪些问题属于有效审查范围;
• 哪些问题优先级更高;
• 哪些建议不应占用评论资源。
核心规则如下:
go
**识别以下类型的问题**:
- 逻辑漏洞或边界条件缺失
- 安全隐患(如SQL注入、XSS、反序列化风险)
- 性能低效或资源泄漏
- 结构设计不合理
- 类型不安全/缺错误处理/违反框架最佳实践
- 潜在业务逻辑偏差
**严重度判定**:
- **高**:编译错误/运行时崩溃/安全漏洞/内存泄漏/资源泄漏/数据破坏
- **中**:性能问题/类型不安全/缺错误处理/违反框架最佳实践
- **低**:代码风格/命名/可读性建议这套规则的意义不在于提升模型能力本身,而在于降低输出的不确定性。它将原本开放式的主观点评,收敛为一套边界明确的缺陷识别过程。
3.3.3 优化效果
在规则约束生效后,审查结果出现了较明显的变化:
风格类建议显著减少;输出更聚焦于影响运行与质量的实际问题;评论数量有所下降,但单条评论的信息密度明显提高;
开发者在 MR 页面上看到的,不再是大段泛化建议,而是更接近可直接处理的问题项。从工程效果上看,这一步并不是为了"让模型报出更多问题",而是为了"让模型减少低价值输出"。对于代码审查系统而言,后者通常更加关键。
优化后的效果如下:


3.4 代码行级评论管理
模型返回结果之后,还需要将这些结果准确写回 GitLab MR。这一层的核心不在于"发送评论"本身,而在于构建正确的 Position 对象,使评论能够挂载到具体代码行上。从整体链路来看,这一模块承担的是"审查结果落地"的职责。前面的 Diff 解析与模型审查,解决的是"发现问题";而评论管理解决的是"将问题稳定地挂载到研发同学真正会查看的位置"。
这部分主要完成以下工作:
1.过滤无效结果
对没有问题描述、没有行号、路径不合法的结果直接丢弃,避免产生无效请求。
2.构建 Position 对象
将项目 ID、MR IID、文件路径、提交 SHA、新行号等信息组装为 GitLab 所要求的评论定位对象。
3.异步提交评论
每条评论单独异步提交,以提升整体处理效率。
4.失败隔离
某一条评论创建失败时,仅记录日志,不影响其他评论继续提交。
核心代码如下:
go
// 1. 收集所有有效任务
List<ReviewNoteTask> validTasks = filterValidTasks(webHookParams, mrVersionDetails, codeReviewResults);
CountDownLatch taskLatch = new CountDownLatch(validTasks.size());
// 2. 异步创建评论
for (ReviewNoteTask task : validTasks) {
noteExecutor.submit(() -> {
try {
discussionsApi.createMergeRequestDiscussion(
task.projectId,
task.mergeRequestIid,
task.commentContent,
new Date(),
null,
task.position
);
} catch (Exception e) {
log.error("创建评论失败: projectId={}, iid={}, newPath={}",
webHookParams.getProjectId(),
webHookParams.getIid(),
task.getNewPath(), e);
} finally {
taskLatch.countDown();
}
});
}
// 3. 等待全部完成
taskLatch.await();这种实现方式的优势在于:
评论定位与评论写入职责分离,便于问题排查;单条评论失败不会导致整批任务中断,整体容错性更好;在评论数量较多的场景下,能够通过异步执行维持较好的处理效率。
3.5 限流、并发控制与重试机制
在系统接入真实团队之后,一个更具工程性的约束逐步显现出来:
当多个 MR 在短时间内同时触发时,模型调用量会迅速上升。如果不进行限制,很容易触发大模型平台的限流策略。一旦限流发生,请求会在短时间内集中失败,后台任务开始堆积,整条链路的稳定性随之下降。因此,这一部分所要解决的,已经不是单个请求是否成功,而是系统在高并发场景下能否保持整体可控。
限流触发时的异常如下:

针对这一问题,我们主要从三个方面进行了处理:
1.对模型调用做速率限制;
2.拆分线程池,控制不同类型任务的并发执行方式;
3.调整重试策略,避免请求长时间阻塞并放大故障。
3.5.1 使用 Guava RateLimiter 控制调用速率
首先,在全局引入基于令牌桶的限流机制,以平滑模型请求速率,避免瞬时流量直接打满接口。
go
// 限流配置类
@Configuration
public class RateLimiterConfig {
@Bean
public RateLimiter rateLimiter() {
// 每秒最多允许60个请求,平滑限流
return RateLimiter.create(60.0);
}
}这一层的作用主要是抑制瞬时并发峰值。
它并不保证所有请求都成功,但能够显著降低因请求突发集中而触发平台限流的概率。
3.5.2 线程池拆分
系统中的不同任务并不适合放在同一个线程池中执行。如果将模型调用、Diff 处理和评论回写全部混在一起,那么一旦某一类任务变慢,就可能拖住整条处理链路。因此,我们将任务拆分为两类线程池:
MR 审查主流程线程池:负责 Webhook 之后的整体任务处理;
评论创建线程池:专门负责评论回写。
这种方式的核心价值在于资源隔离。评论写入变慢时,不会阻塞前面的模型分析;某一类任务出现堆积时,也不会直接影响另一类任务的调度。在线程池参数设计上,除核心线程数、最大线程数和队列容量之外,还采用了 CallerRunsPolicy 作为拒绝策略,以尽量避免任务被直接丢弃。
3.5.3 自定义 Spring Retry 策略
Spring AI 底层依赖 Spring Retry。默认重试策略在一般场景下可以工作,但在模型限流场景中会带来明显问题:单次请求阻塞时间过长。
默认模板如下:
go
public static final RetryTemplate DEFAULT_RETRY_TEMPLATE = RetryTemplate.builder()
.maxAttempts(10)
.retryOn(TransientAiException.class)
.retryOn(ResourceAccessException.class)
.exponentialBackoff(Duration.ofMillis(2000), 5, Duration.ofMillis(3 * 60000))
.withListener(new RetryListener() {
@Override
public <T extends Object, E extends Throwable> void onError(RetryContext context,
RetryCallback<T, E> callback, Throwable throwable) {
logger.warn("Retry error. Retry count:" + context.getRetryCount(), throwable);
}
}).build();该策略的问题主要体现在以下几个方面:
最多重试 10 次;
指数退避倍数较大;
在限流持续存在时,请求可能被长时间拖住。
对于并发系统而言,长时间阻塞往往比一次快速失败更危险。原因在于线程会被持续占用,排队任务逐渐累积,最终可能将局部限流问题放大为整条链路的拥塞问题。
基于这一判断,我们将重试策略调整为更保守的实现:
go
public RetryTemplate retryTemplate() {
RetryTemplate template = new RetryTemplate();
// 重试策略 最大重试次数
SimpleRetryPolicy policy = new SimpleRetryPolicy(3);
template.setRetryPolicy(policy);
// 重试间隔
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(60000); //首次重试的等待时间
backOffPolicy.setMultiplier(2.0); //指数递增的乘数,每次重试的间隔时间 = 上一次间隔 × 乘每次重试的间隔时间
backOffPolicy.setMaxInterval(180000); //最大等待时间上限
template.setBackOffPolicy(backOffPolicy);
return template;
}这一版本的设计思路并不是尽可能提高单次请求的成功率,而是优先保证系统整体行为可控,不让个别失败请求长时间占用线程资源。
3.5.4 优化效果
通过限流、线程池拆分和重试策略调整之后,系统在高并发场景下的稳定性有了明显提升。即使多个项目同时提交 MR,模型调用也能够被压制在可控范围内,从而降低因瞬时限流导致整批任务失败的风险,同时减少因长时间重试造成的线程池堆积问题。
这一部分优化真正解决的是:当系统从"能够运行"进入"可供多人持续使用"的阶段之后,如何确保其在高负载条件下仍然保持可预期的行为,而不是偶发成功、偶发雪崩。
04
四.总结
这套 AI 代码审查系统,本质上是将原本分散在人工审查中的一部分重复性工作,迁移为一条自动化处理链路。从实现过程来看,真正困难的部分并不是"接入一个模型",而是将其放入真实研发流程之后,逐步解决一系列工程化问题,例如:Webhook 超时;Diff 行号与评论位置不一致;模型输出过于发散;高并发场景下的限流与重试失控。
从最终效果看,AI 审查并不能替代所有人工判断,但非常适合承担基础性、重复性和规则性较强的检查工作。只要对输入格式、输出约束以及系统稳定性进行充分处理,它就能够在现有研发流程中发挥较为稳定的作用。从工程价值上看,这套系统的意义并不只在于"引入 AI 参与代码审查",而在于它将部分原本依赖个人经验的审查能力,逐步沉淀为一条可复用、可扩展、可持续优化的工程链路。
