迷思与现实:为什么我们需要 Harness Engineering?

生活化引子:那个"啥都会"但"啥都干不好"的朋友
想象你有一个朋友,智商高达 180,读过世界上所有的书(大模型的预训练)。你让他帮你"筹备一次生日派对"。
-
第一阶段(纯对话) :他滔滔不绝地给出建议:买气球、订蛋糕、邀请朋友。听起来很棒,但你发现你依然要自己去打电话、去淘宝下单。他只是个"动嘴皮子"的军师。
-
第二阶段(赋予工具):你给了他一部手机和一张信用卡(工具调用)。他开始帮你操作,但问题来了:他可能会在淘宝上同时买 10 种不同款式的气球(超支/冗余),或者在打电话邀请时,因为记不住上一个电话说了什么,导致重复邀请同一个人(上下文溢出/幻觉)。
-
第三阶段(失控):你发现他确实在干活,但他把厨房弄得一团糟,订的蛋糕是你不喜欢的榴莲味,而且因为同时处理太多事,他 CPU(上下文窗口)过载了,开始胡言乱语。
这个朋友就是现在的 AI Agent。 而 Harness Engineering ,就是我们为这位高智商但缺乏"社会规范"和"执行纪律"的朋友,设计的一套包含工作流程、反馈机制、奖惩制度和安全围栏的"现代企业管理制度"。
演进之路:从"问路"到"修路"
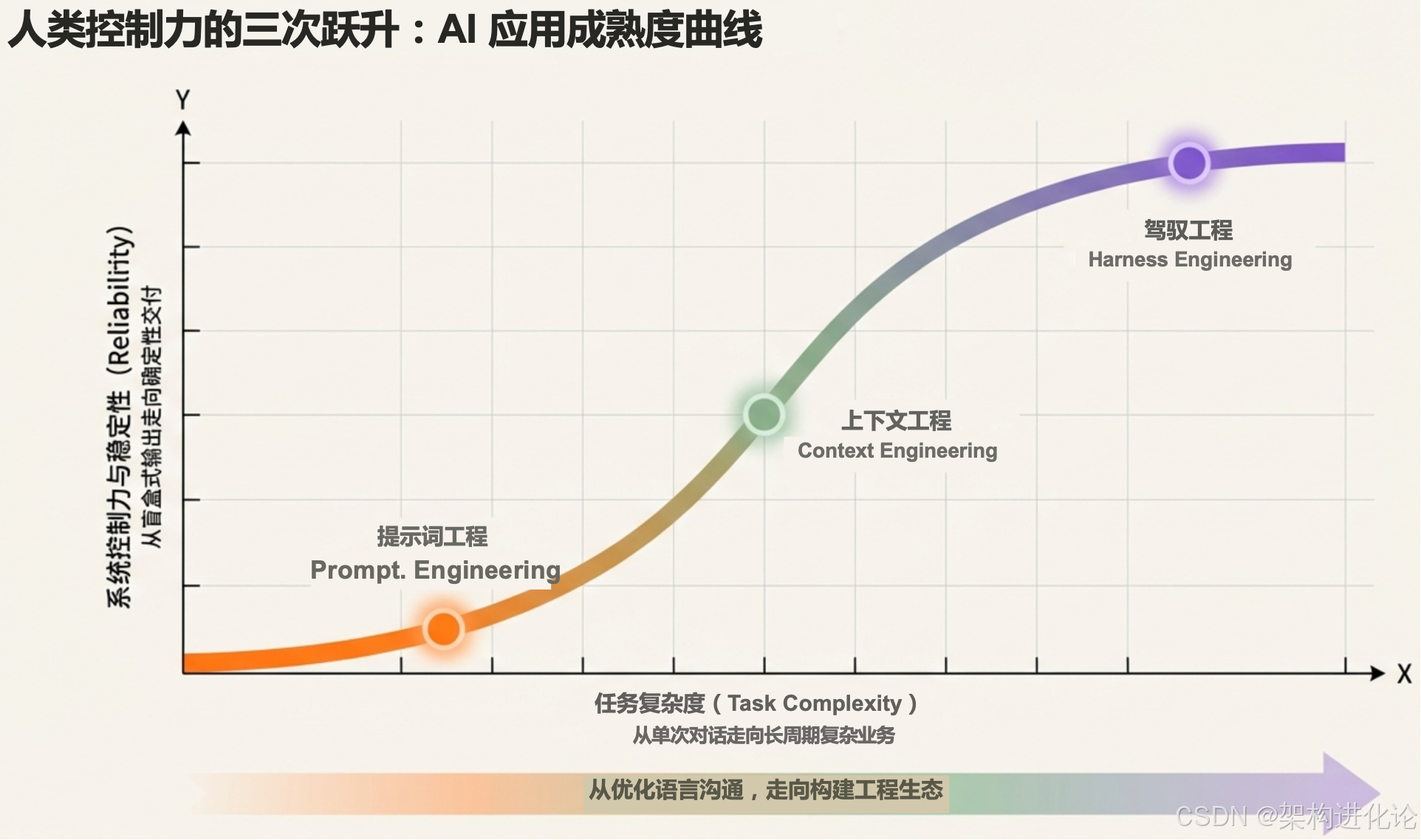
AI 应用开发范式的演进,本质上是一场关于"控制权"与"自主性"的博弈。
阶段一:Prompt Engineering(提示词工程)--- "教 AI 说话"
在 LLM 早期,模型就像一只通晓事理但极度懒散的高材生。你需要极其精确地告诉他"1+1=2",他才会点头。
-
技术焦点:Few-shot Learning, Chain-of-Thought (CoT)。
-
痛点 :脆弱且非结构化 。换一个说法,答案可能天差地别。它无法处理复杂、多步骤的任务,一旦任务超过 3 步,模型就会"迷路"。(扩展阅读:思维链(CoT)的演进与创新:Few-Shot与Zero-Shot架构设计深度解析)

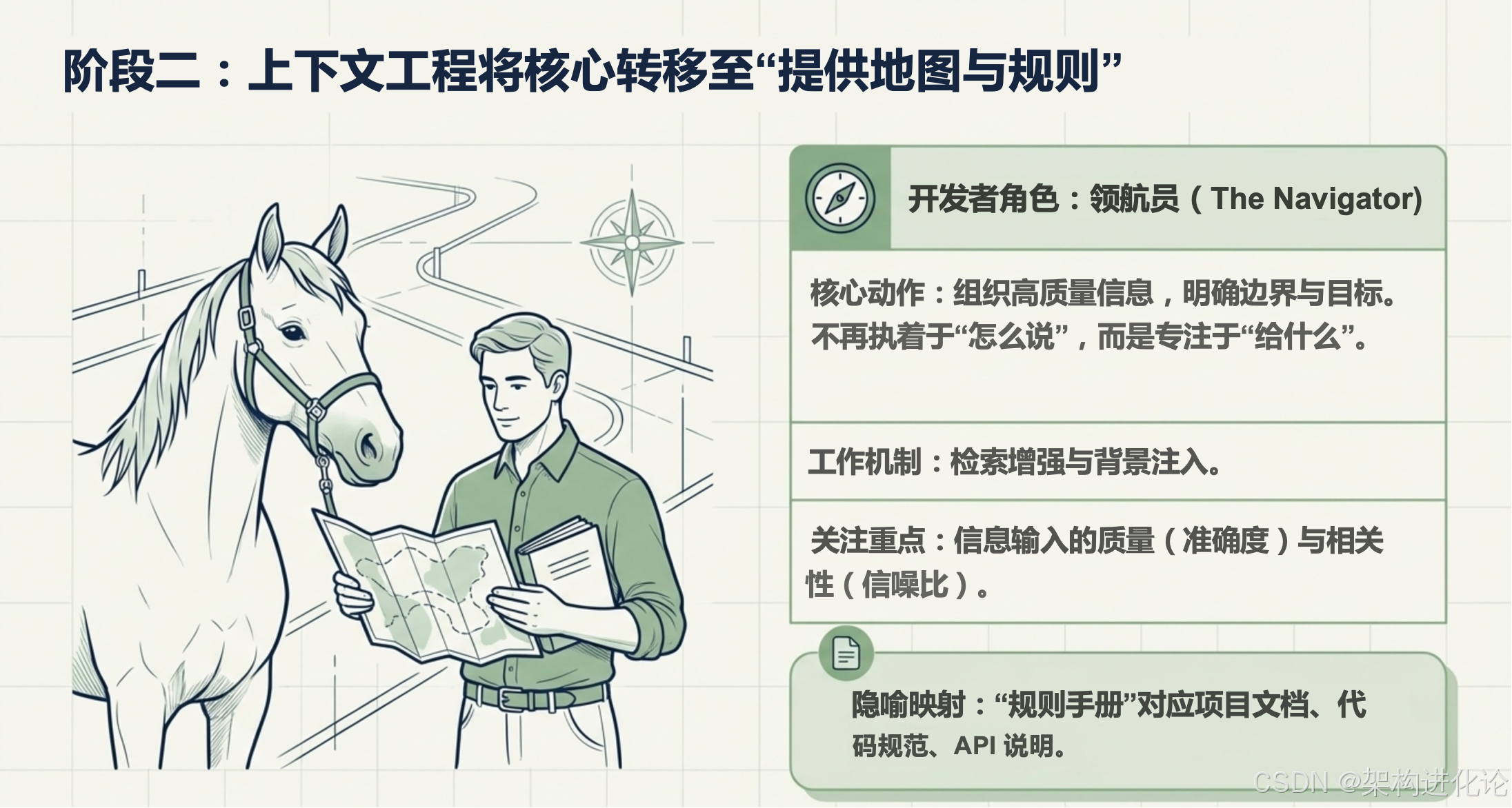
阶段二:Context Engineering(上下文工程)--- "给 AI 配副眼镜"
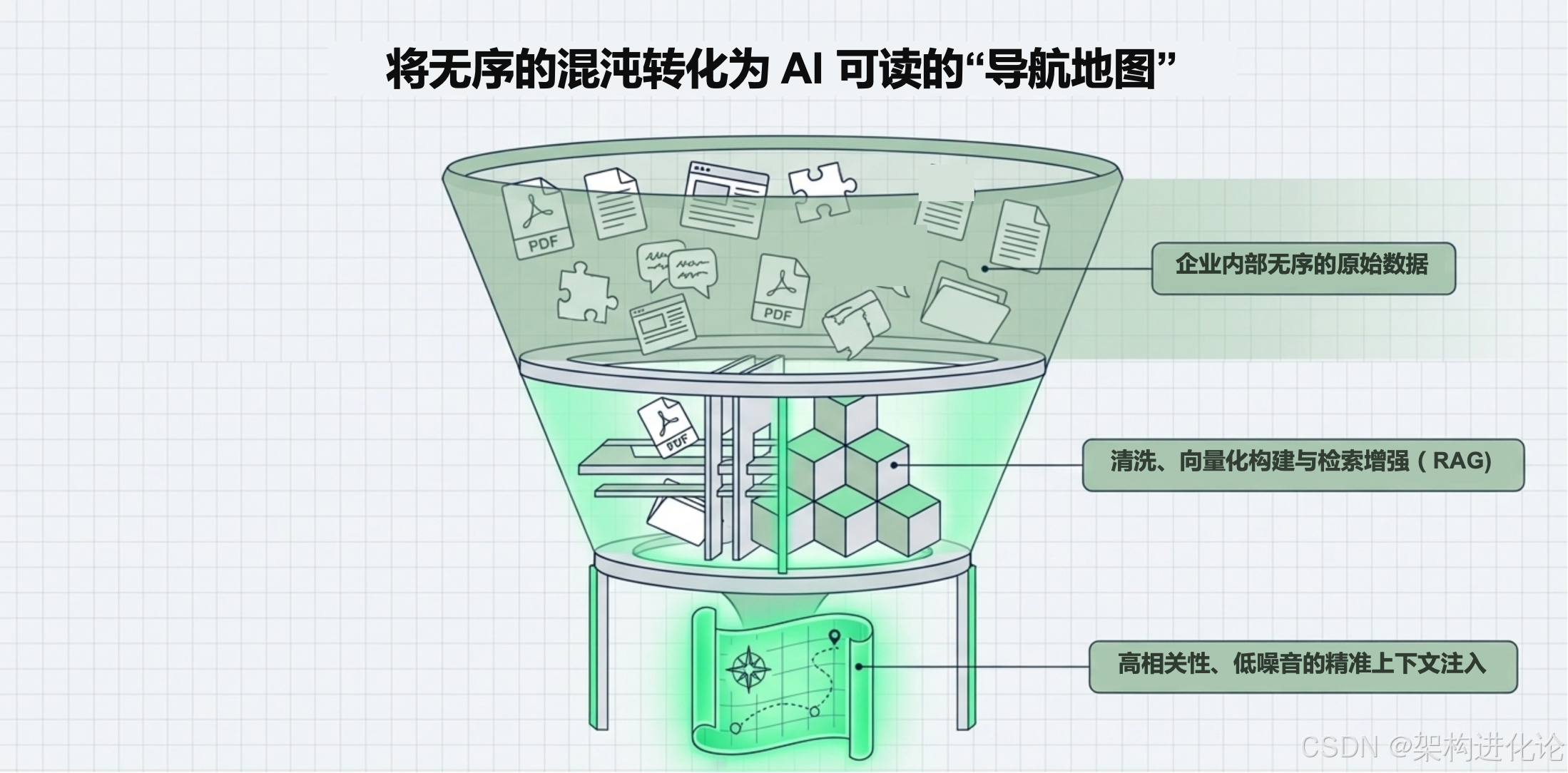
随着 RAG 和长上下文的出现,我们意识到模型并不缺知识,它缺的是此时此刻相关的信息。
-
技术焦点:向量数据库、嵌入、记忆检索。
-
痛点 :被动反应式 。它依然是在"回答问题",而非"完成任务"。它能从海量文档中找到答案,但它不会主动去执行
git commit或者关闭服务器上的一个端口。它像一个完美的顾问,但不是执行者。(扩展阅读:MoE meets In-Context Reinforcement Learning:混合专家模型与上下文强化学习的融合创新、专业级RAG系统设计与实现:高召回可溯源的多文档知识库解决方案、海马体启发的长期记忆革命:HippoRAG架构设计与多跳推理突破、检索增强生成(RAG)与微调(Fine-tuning)的架构创新设计:技术演进、适用场景与实战指南、大模型知识库开发中的向量数据库选型指南:从理论到实践、Redis 8.0向量库 vs 传统向量数据库:大模型知识库开发选型全指南)
阶段三:Harness Engineering(驾驭工程)--- "给 AI 立法"
直到 2026 年初,行业终于达成共识:我们需要的是执行者。Harness Engineering 应运而生。
-
定义 :Harness Engineering 是一套为 AI Agent 设计的运行时(Runtime)环境与治理框架。它不提升模型的智商,但通过架构约束、沙箱隔离、工具标准化和反馈闭环,极大幅度地提升模型在长周期任务中的成功率与可靠性。
-
核心理念 :Mitchell Hashimoto 给出了一个经典定义:"每当 AI 犯错,就工程化一个方案,让它永远不再犯同样的错。"
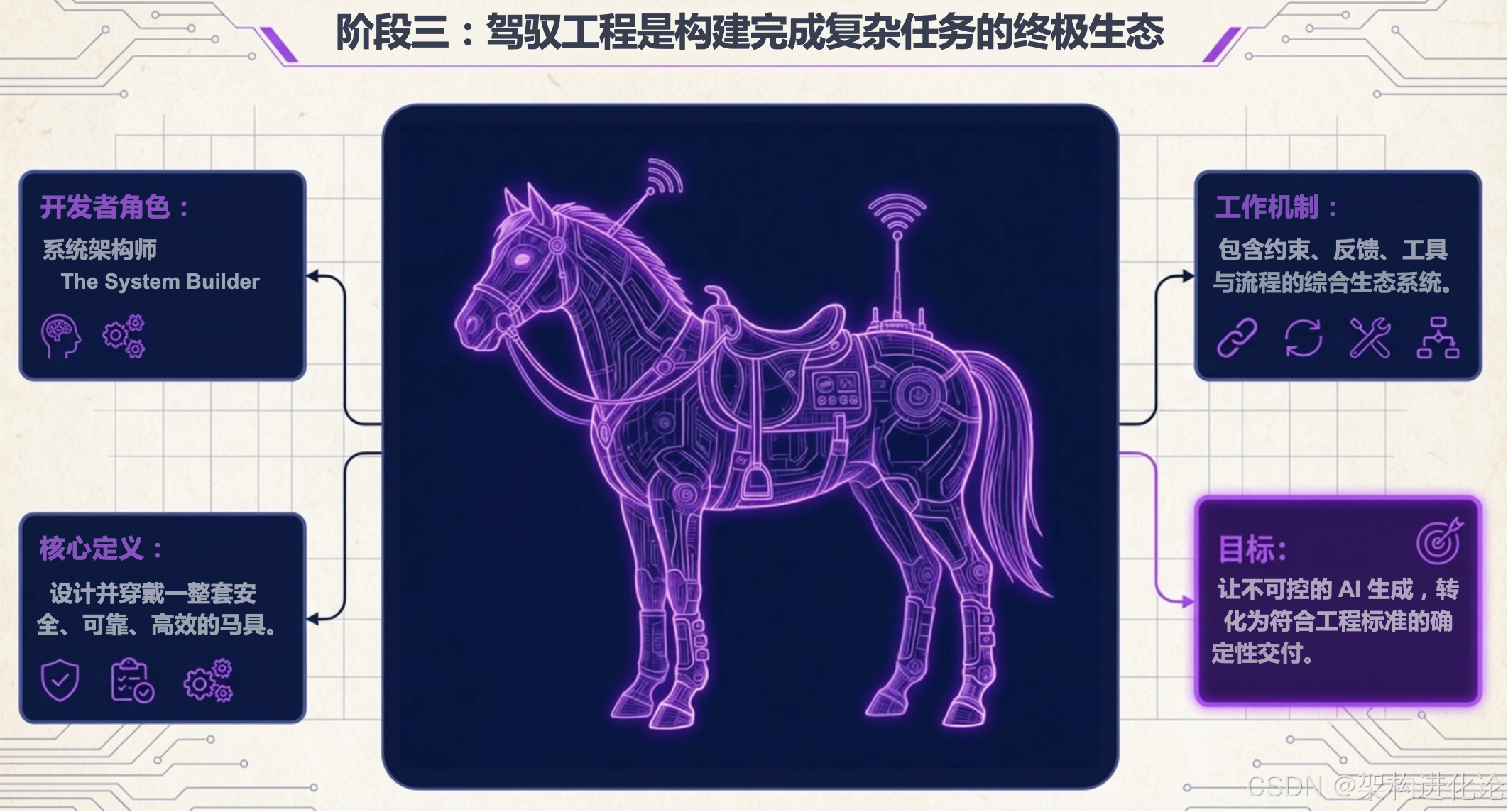
解构 Harness:三大技术支柱
Harness 不仅仅是一个"工作流编排"工具,它是一套系统性的架构方法论。我们可以将其拆解为三个核心层级,对应架构图中的不同区块。
架构全景图
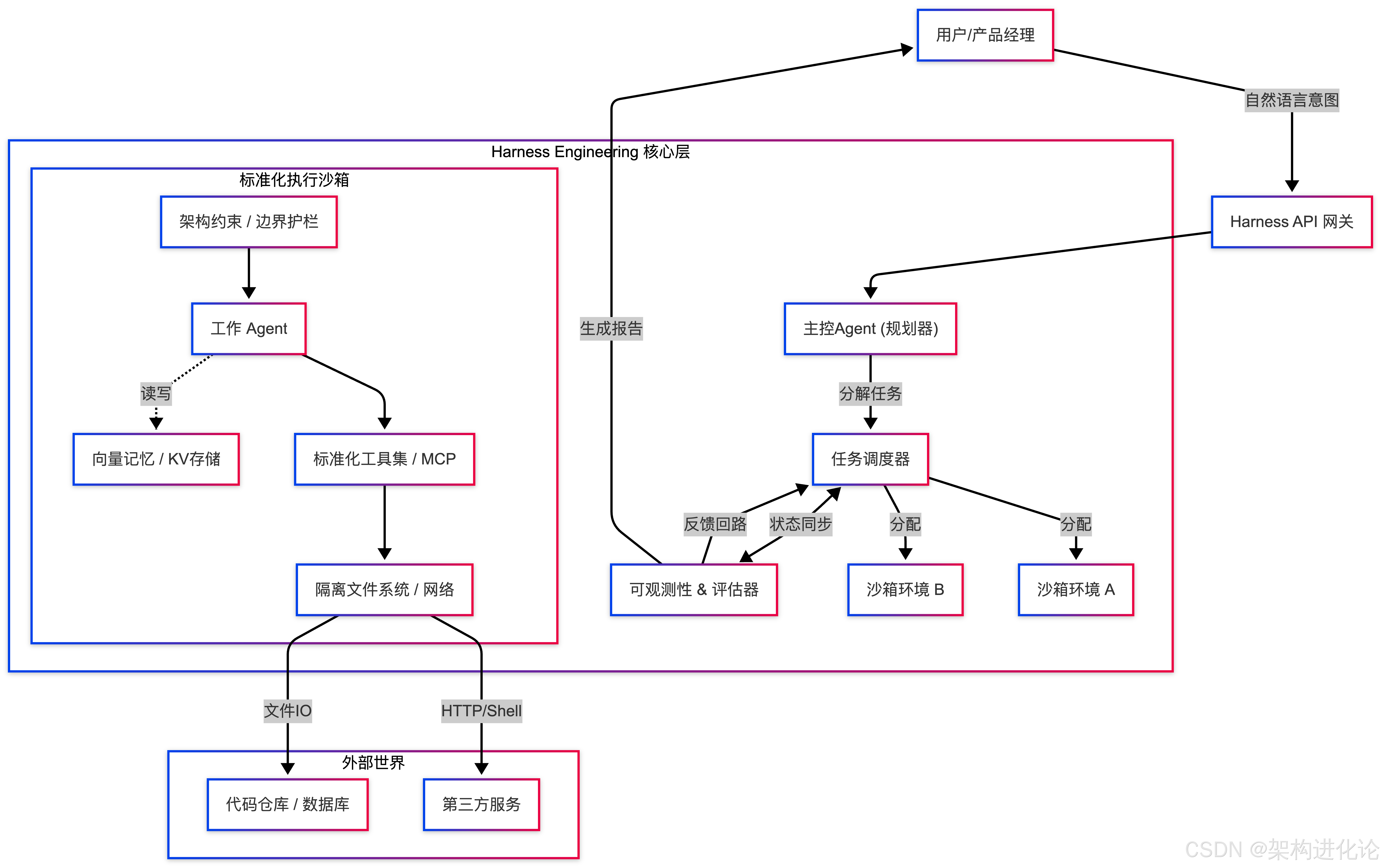
缰绳与马鞍:架构即上下文
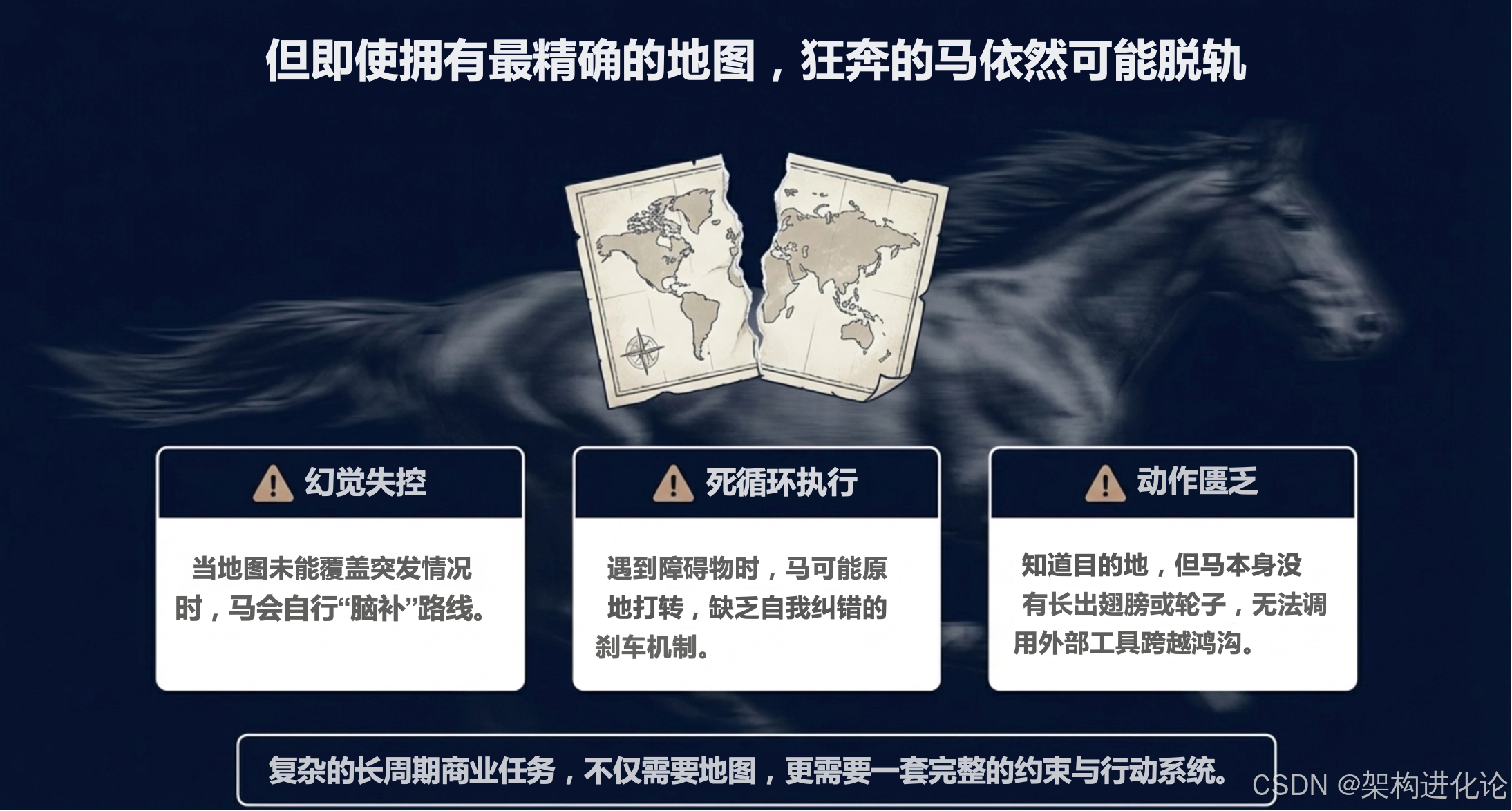
问题 :裸奔的 Agent 如同脱缰野马。给它一个"重构代码"的任务,它可能会重写整个架构,破坏掉原有的分层设计(DDD),或者引入严重的安全漏洞。
解决方案 :将架构约束编码为机器可读的规则。
在传统的 DevOps 中,我们依赖"文档"或"口头约定"来维护架构规范。在 Harness 中,这些规范是强制执行 的。
例如,OpenAI 在利用 Codex 开发百万行代码时,强制规定了依赖层级:Types → Config → Repo → Service → Runtime → UI。Agent 生成的代码如果违反了这一层级(例如在 UI 层直接调用了 Repo 层的函数),CI 流水线会直接拒绝合并。
生活化案例 :
这就像给一个新手司机开车。不给他 Harness,他可能会把油门当刹车,或者逆行。Harness 是什么呢?是车道线 (约束范围)、是红绿灯 (规则检查)、是导航仪(目标导向)。车道线并没有限制车的动力,但它确保了车在正确的方向上行驶。
马厩与围栏:沙箱化执行环境
问题 :Agent 操作实体世界具有巨大风险。如果 Agent 执行 rm -rf / 或者陷入死循环无限调用 API,后果不堪设想。
解决方案 :隔离与权限最小化。
Agent 不应直接操作宿主机。Harness 要求所有 Agent 的动作必须在一个受限的沙箱中执行。
-
代码执行:Python/JS 代码在安全的 Docker 容器中运行,限制 CPU/内存,切断不必要的网络访问。
-
文件访问:Agent 只能访问当前工作区(Workspace)的文件,无法读取系统密码文件。
-
工具调用 :高危操作(如删除数据库、发布生产环境)需要人工二次确认 或MFA 授权。百度云将其称为"高危拦截"机制。
驯马师的鞭子:多层反馈闭环
问题 :Agent 的自我评估(Self-Critique)往往非常不准。模型倾向于过度自信,即使代码跑不通,它也会告诉你"快好了"。
解决方案 :通过外部客观世界提供反馈,而非依赖模型的主观感受。
这是 Harness 区别于普通 Workflow 的核心。反馈回路必须快且客观。
-
编译期反馈:强类型语言(如 Go, Rust)是第一道防线。Agent 生成类型不匹配的代码,编译器立即报错。
-
单元测试:自动化运行单元测试。测试失败 = 任务未完成。
-
Linter 与静态检查:自动检查代码风格、复杂度,甚至检查是否符合预定义的架构边界。
-
E2E 与验收:在隔离环境中运行端到端测试,验证业务逻辑是否符合预期。
实战演练:从"对话"到"发版"
理论讲完了,我们来写代码。假设我们要构建一个 Harness 核心调度器的简化原型。
场景定义
我们需要一个系统,用户输入"计算 10 的阶乘并写入 result.txt",系统必须:
-
生成 Python 代码。
-
在沙箱中执行。
-
如果执行失败,分析错误并重试(最多 3 次)。
-
成功后读取文件内容返回。
代码实现:简易 Harness 核心
python
import subprocess
import tempfile
import os
from typing import Dict, Any
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, AIMessage
class HarnessAgent:
"""
Harness 核心执行器。
它的职责不是写代码,而是管理 Agent 写代码和运行代码的过程。
"""
def __init__(self, model_name: str = "gpt-4o"):
self.llm = ChatOpenAI(model=model_name)
# 定义系统级的"缰绳":不可违背的硬规则
self.system_constraints = """
你是一个代码生成器。你必须只输出 Python 代码,不要输出解释。
代码必须包含一个 solve() 函数,输入参数为原始需求变量。
你必须捕获所有异常并打印标准错误。
"""
# 工作空间(沙箱根目录)
self.workspace = tempfile.mkdtemp(prefix="harness_sandbox_")
print(f"初始化 Harness 沙箱环境: {self.workspace}")
def _generate_code(self, task: str, error_feedback: str = "") -> str:
"""利用 LLM 生成代码,如果出错则传入错误反馈进行修正"""
messages = [
{"role": "system", "content": self.system_constraints},
{"role": "user", "content": f"任务: {task}"}
]
if error_feedback:
# 反馈闭环:告诉 Agent 上一次为什么挂了
messages.append({"role": "user", "content": f"上一次执行失败了,错误信息:{error_feedback}。请修正代码。"})
response = self.llm.invoke(messages)
# 极其简陋的解析,生产环境需要用 AST 或正则提取
code = response.content.replace("```python", "").replace("```", "").strip()
return code
def _execute_in_sandbox(self, code: str) -> Dict[str, Any]:
"""在隔离的进程中执行代码(沙箱模拟)"""
code_path = os.path.join(self.workspace, "script.py")
with open(code_path, "w", encoding="utf-8") as f:
f.write(code)
# 关键点:Harness 控制执行边界。设置 timeout 防止死循环,限制资源。
try:
result = subprocess.run(
["python", code_path],
capture_output=True,
text=True,
timeout=5, # 硬性超时限制
cwd=self.workspace # 限制在沙箱目录内
)
return {
"success": result.returncode == 0,
"stdout": result.stdout,
"stderr": result.stderr
}
except subprocess.TimeoutExpired:
return {"success": False, "error": "Execution Timeout"}
def run(self, user_task: str) -> str:
"""
Harness 的主循环:规划 -> 执行 -> 观察 -> 纠偏
这其实就是 ReAct (Reasoning + Acting) 模式的工程化封装。
"""
feedback = ""
for attempt in range(3): # 重试机制
print(f"[Harness] 第 {attempt + 1} 次尝试...")
# 1. 生成代码(或修正代码)
code = self._generate_code(user_task, feedback)
# 2. 执行并观察结果
result = self._execute_in_sandbox(code)
# 3. 评估结果
if result["success"]:
print(f"[Harness] 执行成功。输出: {result['stdout']}")
# 验证输出是否符合预期(例如文件是否生成)
output_file = os.path.join(self.workspace, "result.txt")
if os.path.exists(output_file):
with open(output_file, "r") as f:
return f"最终结果: {f.read()}"
elif result['stdout']:
return f"最终结果: {result['stdout']}"
else:
# 特殊情况:代码执行了但没有产生任何输出
feedback = "代码执行成功但没有产生任何标准输出,且未找到 result.txt。请确保打印结果或写入文件。"
continue
else:
# 4. 构造负反馈,进入下一次循环
error_msg = result.get("stderr") or result.get("error", "Unknown Error")
print(f"[Harness] 执行失败: {error_msg}")
feedback = error_msg
raise Exception(f"Harness 重试 3 次后仍然失败。最后错误: {feedback}")
# 使用示例
if __name__ == "__main__":
harness = HarnessAgent()
# 注意:这里的任务是模糊的、高阶的
try:
final_output = harness.run("计算 10 的阶乘,并将结果写入 result.txt 文件。")
print(final_output)
except Exception as e:
print(f"Harness 任务崩溃: {e}")代码解析 :
这个不到 100 行的例子揭示了 Harness 的本质:
-
分离关注点 :
HarnessAgent类不关心模型怎么算阶乘,只关心流程控制(重试、超时)。 -
环境抽象 :
_execute_in_sandbox模拟了隔离环境。真正的生产系统会在这里挂载 Docker API,启动临时容器。 -
闭环反馈 :
error_feedback变量是 Harness 的灵魂。它不是让 Agent "下次注意",而是把编译器的报错信息 、Linter 的警告 、测试用例的失败详情原封不动地喂回给 LLM,让它进行"反思"和"修正"。
巅峰案例:当 Harness 驱动代码大军
OpenAI 的"工厂模式"
OpenAI 的内部实验是 Harness Engineering 的封神之战。他们用 Codex Agent 在 5 个月内产出了 100 万行代码,零人工代码。
他们是怎么做到的?秘密在于他们将工程师的角色从"程序员"转变为了"首席架构师 & 测试经理"。
-
架构即提示词 :他们没有告诉 Agent "写一个登录功能"。而是定义了
interface(Go) 或Protocol(Python)。Agent 的任务是实现这个接口。 -
测试即验收:工程师编写测试用例(Test Harness)。只要测试没通过,Agent 的任务状态就是"进行中"。Agent 能看到测试日志,不断修正代码直到变绿。
-
结果:效率提升 10 倍。布鲁克斯法则(给延期项目加人会使项目更延期)在这里失效了,因为"沟通成本"在 Agent 之间几乎为零,只有"编译成本"。
Anthropic 的"创意飞跃"
如果说 OpenAI 的例子展示了 Harness 的纪律性 ,Anthropic 的例子则展示了 Harness 的启发性 。
在一次前端开发实验中,Claude Agent 被要求设计一个博物馆网站。在第十次迭代时,它没有在原来的框架上修修补补,而是推翻重来,设计了一个带有 3D 透视效果的沉浸式画廊------这超出了人类的预期。
为什么没有 Harness 的普通聊天做不到这一点?
因为普通聊天没有 "长期记忆" 和 "迭代评估机制" 。Harness 给了 Agent 一个"沙盒游乐场",在这个环境里,试错成本极低。Agent 可以大胆尝试,只要最终评分(Resilience Score)提高了,Harness 就会保留这个"变异"特性。这本质上是一种工程化的进化算法。
架构师的行动指南
作为架构师,引入 Harness Engineering 意味着推翻现有的 AI 开发流程。

重新定义"完成"
在 Harness 模式下,"写代码"不是完成,"让 Agent 写完并通过所有检查"才是完成。你需要投资建设:
-
确定性测试集:一个包含 100+ 个典型场景的评估数据集(Golden Dataset)。每次 Agent 迭代,必须跑通这个集合并计算通过率。
-
混沌工程集成:Harness 不仅仅是"功能"测试,还要做"韧性"测试。例如,当我们在 Agent 执行任务期间,模拟网络延迟或 Kill 掉一个子进程,看它能否自动恢复。
设计"失败模式"
传统软件工程设计"成功路径",Harness 要求你设计"失败路径"。
你需要问自己:如果 Agent 陷入了死循环,Harness 怎么杀掉它?如果 Agent 花了 10 美元 API 费用还没搞定问题,Harness 怎么止损?
**超时(Timeout)、预算限制(Budget Limit)、回滚(Rollback)**是 Harness 的三大安全阀门。
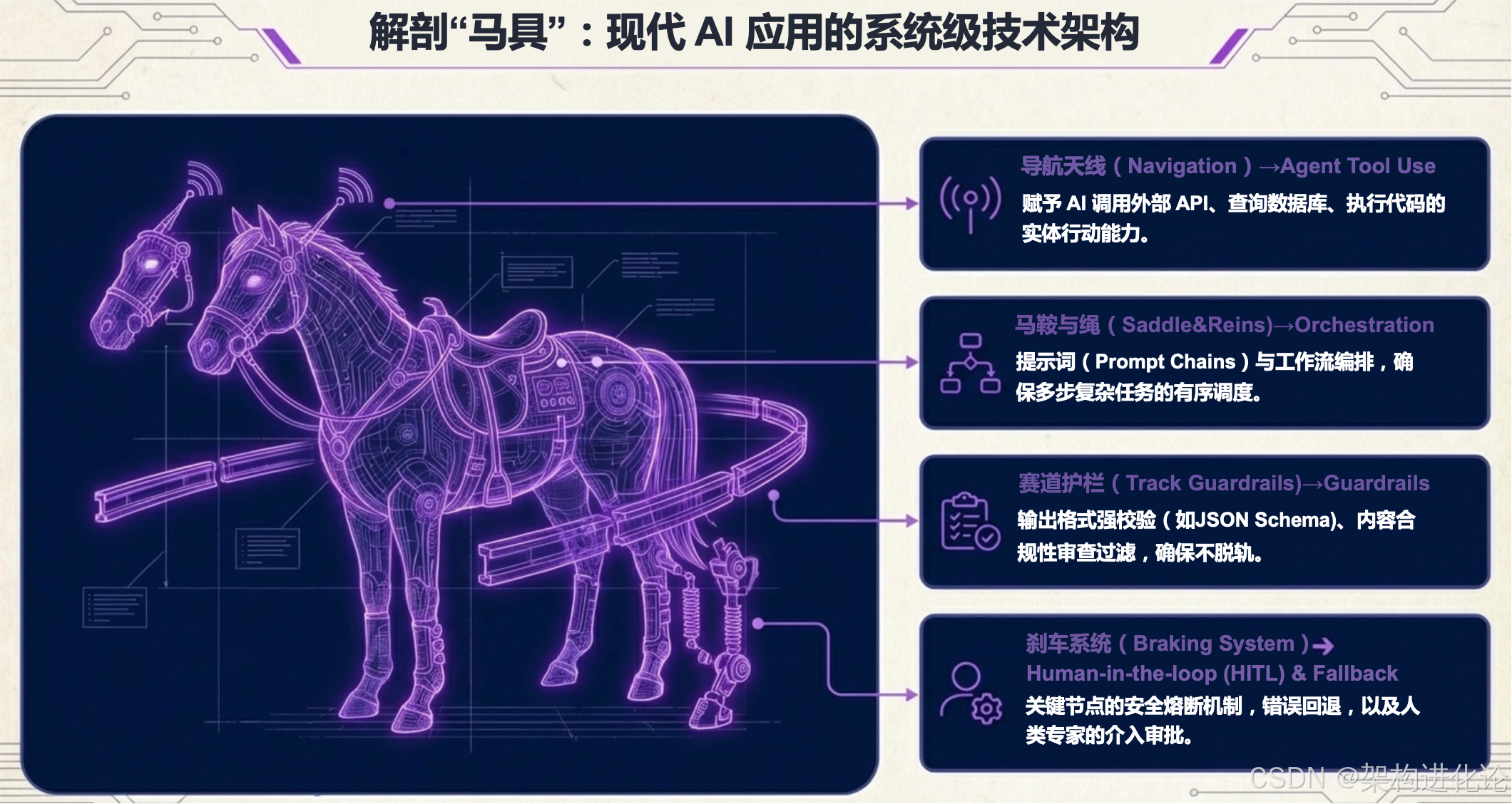
工具标准化:拥抱 MCP
不要让 Agent 适配五花八门的 API。引入 Model Context Protocol (MCP) 作为统一标准。
MCP 就像是 AI 界的 USB-C 接口。无论你是数据库、Slack 还是本地文件,只要封装成 MCP Server,Agent 就能即插即用。Harness 的职责变成了管理这些 MCP 插件的注册、发现和鉴权。(扩展阅读:9个革命性MCP工具概览:从本地客户端到智能研究助手、MCP Server深度评估报告:效能差异、优化策略与未来演进路径、MCP架构:大模型时代的分布式训练革命、MCP架构:模型上下文协议的革命性创新设计、MCP架构:AI时代的标准化上下文交互协议、A2A vs MCP:智能体通信协议的框架选择与最佳实践、MCP vs Function Calling:重构AI工具交互范式的技术真相、MCP、Function Calling与Agent:构建AI协作生态的三层架构体系、MCP与Skills:AI架构的进化,从连接协议到认知框架的演进、Skills vs MCP:谁才是大模型的"HTTP时刻"?)
结语
Harness Engineering 的出现,标志着 AI 开发从"炼丹术 "(Prompt 调参)正式迈入"工程学"(系统架构)。
它不再痴迷于"模型会不会变得更聪明",因为它知道模型一定会变得更聪明。它关注的是:当模型变聪明后,我们如何构建一套系统,让这种智能能够安全、高效、可控地流经我们的业务流程,最终转化为实实在在的产品价值。
正如汤道生所言:"AI 落地不只是一道算法题,更是一道工程题。" 在未来,决定 AI 产品成败的,将不再是那零点几个百分点的模型评分差异,而是包裹在模型外层的这套 Harness 是否足够精良。
作为架构师,我们的使命已经改变:不要试图去训练那匹马,去建造那条让它纵横驰骋的赛道。