序
在看 PCIe Controller、iATU、eDMA 这些概念时,很多人都会遇到一种"每个点单独都认识,但一连起来就糊了"的感觉。
最常见的困惑通常长这样:
- inbound 和 outbound 到底是相对于谁定义的
- iATU 到底管的是所有数据,还是只管地址翻译
- RC 从设备读数据到 DDR,为什么有人说只看 outbound
- EP 主动 DMA 写主机内存,为什么又说这是 RC inbound
- eDMA 的地址到底该填本地域地址,还是 PCIe 域地址
这些问题之所以容易把人绕晕,并不是因为它们特别难,而是因为讨论时常常把几层不同的东西混在了一起:
- PCIe 事务层里的 request 和 completion
- PCIe Controller 内部的数据路径
- iATU 的地址匹配/翻译
- eDMA 的搬运路径和地址语义
所以这篇文章不打算一上来就把 eDMA 拉进来。更好的办法,是先从最简单的场景开始,把最基础的参考系和边界理清楚,然后再往后引入 eDMA。这样整条逻辑会顺得多。
1、最简单的场景开始:CPU/RC 主动访问 PCIe 设备
- CPU 运行在 SoC 本地侧
- SoC 里的 PCIe Controller 当前工作在 RC 模式
- CPU 想主动访问某个 PCIe 设备
这个"主动访问"可以是两种最基础的情况:
1.1 RC 主动发起一次 Memory Read
也就是:
- RC 侧发出一笔
MemRd - PCIe 设备返回
Completion Data
1.2 RC 主动发起一次 Memory Write
也就是:
- RC 侧发出一笔
MemWr - 数据直接被写到 PCIe 设备
此时最容易看清的,就是 谁发起 request,request 相对于 controller 是往外走,还是往里走。
2、inbound/outbound 的参考系
很多人第一次看文档时,会下意识把 inbound/outbound 理解成"相对于 CPU 或 DDR 来说的进和出"。这种感觉并不奇怪,因为 PCIe Controller 的本地侧通常确实连着 AXI、DDR、寄存器空间,以及 CPU 所在的系统地址域。
但如果要说得严谨,参考系并不是 CPU,而是 PCIe Controller 本身。
更准确地说:
- outbound:从 controller 的本地侧发往 PCIe 链路侧
- inbound:从 PCIe 链路侧进入 controller 的本地侧
这里的"本地侧"并不只指 CPU,而是 controller 所连接的整个本地地址域,包括 AXI fabric、DDR、寄存器空间,以及其他本地可达资源。
所以,当 RC 主动去访问 PCIe 设备时,不管是发 MemRd 还是 MemWr,只要这笔 request 是从 controller 本地侧发到 PCIe 链路上,那么它在方向语义上都属于 outbound。
反过来,如果是 PCIe 对端主动发一笔 request 进来,例如 EP 主动发 MemWr 到主机内存,那么对 RC 来说,这才属于 inbound。
到这里,其实可以先记一句最短的话:
inbound/outbound 的判断依据,不是"最终数据写到了哪里",而是"这笔 PCIe request 相对于当前 controller 是往外还是往里"。
3、iATU 监管的范围
把参考系统一之后,第二个最容易混的点就是 iATU。
很多人脑子里会有一句模糊但很顺口的话:
"只要数据经过了 PCIe,那应该就要过 iATU。"
这句话不准确。iATU 真正处理的是 PCIe request 的地址匹配和翻译,不是所有经过 PCIe 的数据都要统一"过一遍 iATU"。
也就是说:
- outbound iATU 关注的是"本地侧准备发到 PCIe 链路上的 request 地址"
- inbound iATU 关注的是"从 PCIe 链路进入本地侧的 request 地址"
这里最关键的词是 request。
在 PCIe 事务层里,下面几种东西是不同语义:
MemRd:新的读请求MemWr:新的写请求Completion with Data:对前面那笔MemRd的响应
这也是为什么很多问题的关键,不在于"数据有没有回来",而在于"回来的到底是一个新的 request,还是前面 request 的 completion"。
4、两个基础场景
如果只讲抽象定义,读起来还是容易飘。更好的办法,是把两个最基础的场景摆在一起看。
4.1 场景 A:RC 主动访问设备
例如:
- RC 主动发
MemRd去读设备 - 或者 RC 主动发
MemWr去写设备
在这个场景里,请求的发起者是 RC,所以对 RC 来说,这些 request 都属于 outbound。
4.2 场景 B:EP 主动访问主机
例如:
- EP 主动发
MemWr写主机内存 - 或者 EP 主动发
MemRd读主机内存
在这个场景里,请求是从 PCIe 链路进入 RC,所以对 RC 来说,这类 request 属于 inbound。
把这两个场景并排之后,方向判断就会清楚很多:
- 我主动发 request 去访问对端,先看 outbound
- 对端主动发 request 来访问我,再看 inbound
真正决定 in/out 的,是 request 的方向,而不是"最终数据要落到哪里"。
5、关于 PCIe 控制器 eDMA
eDMA 当然也是 DMA,但它不是那种"全 SoC 通用 DMA 控制器"的语义。它更准确的定位,是:
嵌在 PCIe IP 内部、负责在本地地址域和 PCIe 地址域之间搬运数据的 DMA 引擎。
如果简单做个对比:
- 通用 DMA:两端通常都在 SoC 内部总线体系里
- PCIe eDMA:一端连本地 AXI/DDR,另一端连 PCIe 事务层
也正因为如此,eDMA 场景里往往会同时出现两种不同的地址语义:
- 本地 AXI / DDR 物理地址
- PCIe 总线侧地址
这也是为什么很多人在看 eDMA 时,会自然把"本地 DDR 写入"、"PCIe request 发出"、"iATU 地址翻译"这几件事混在一起。
5.1 eDMA read 为例
- RC 侧使用 PCIe Controller 内部的 eDMA
- RC 想从某个 PCIe 设备读取一段数据
- 最终把数据写入本地 DDR
把整个过程拆开看,实际发生的是:
- RC 侧 eDMA 先向 PCIe 设备发起一笔
MemRd - 设备返回
Completion Data - RC 侧 eDMA 收到 completion 数据
- eDMA 再把这批数据通过本地 AXI 路径写入本地 DDR
所以这个场景里要分清三件事:
MemRd是 RC 主动发起的 request,对 RC 来说属于 outboundCompletion Data是响应,不是新的 request- 写入本地 DDR 属于 controller 内部数据路径
5.2 eDMA 传输时与 iATU 有关的地址
本地 AXI 侧地址
例如:
- RC eDMA read 时写入 DDR 的目标地址
- RC eDMA write 时从 DDR 读取的源地址
这类地址本质上属于 controller 内部访问本地 AXI/DDR 的地址语义。
PCIe 侧 request 地址
例如:
- eDMA 发
MemRd时要去访问设备的地址 - eDMA 发
MemWr时要写向设备的地址
这类地址才是 outbound 路径真正关注的对象,因为它对应的是"要上 PCIe 链路的那一侧地址"。
从 PCIe 对端主动打进来的 request 地址
例如:
- EP 主动发
MemWr到主机内存 - 主机主动访问 EP 的 BAR 空间
这类地址才和 inbound 语义直接相关。
所以更准确的说法不是"读写都必须经过 iATU",而是:
跨 PCIe 链路发起 request 的那一侧,要关注 outbound 路径;从 PCIe 链路主动进入本地的 request,才属于 inbound 路径。
5.3 关于 eDMA 读写是否需要经过地址转换单元 iATU
上一小节讲的是,理论上需要经过 inbound/outbound 路径。很多时候,eDMA 虽然理论上经过 inbound/outbound 路径,但是硬件设计上可不一定如此。我们看几个实例:
案例 1:Intel 官方 DMA 文档直接写明了地址域归属
Intel 的 Avalon-MM DMA/Descriptor Controller 文档把读写方向和地址域写得非常直白。
以 Read DMA 为例,官方文档明确说明:
- Read DMA 是把数据从
PCIe address space搬到Avalon-MM address space(cpu 地址域) - 它发出的是
Memory Read TLP - 返回的 completion 数据会被写到本地 Avalon-MM 内存
这和前面讲的"RC 发 MemRd,completion 回来后再落到本地内存"的思路,其实是完全一致的。
同样,Intel 在描述符格式里也明确区分了地址域:
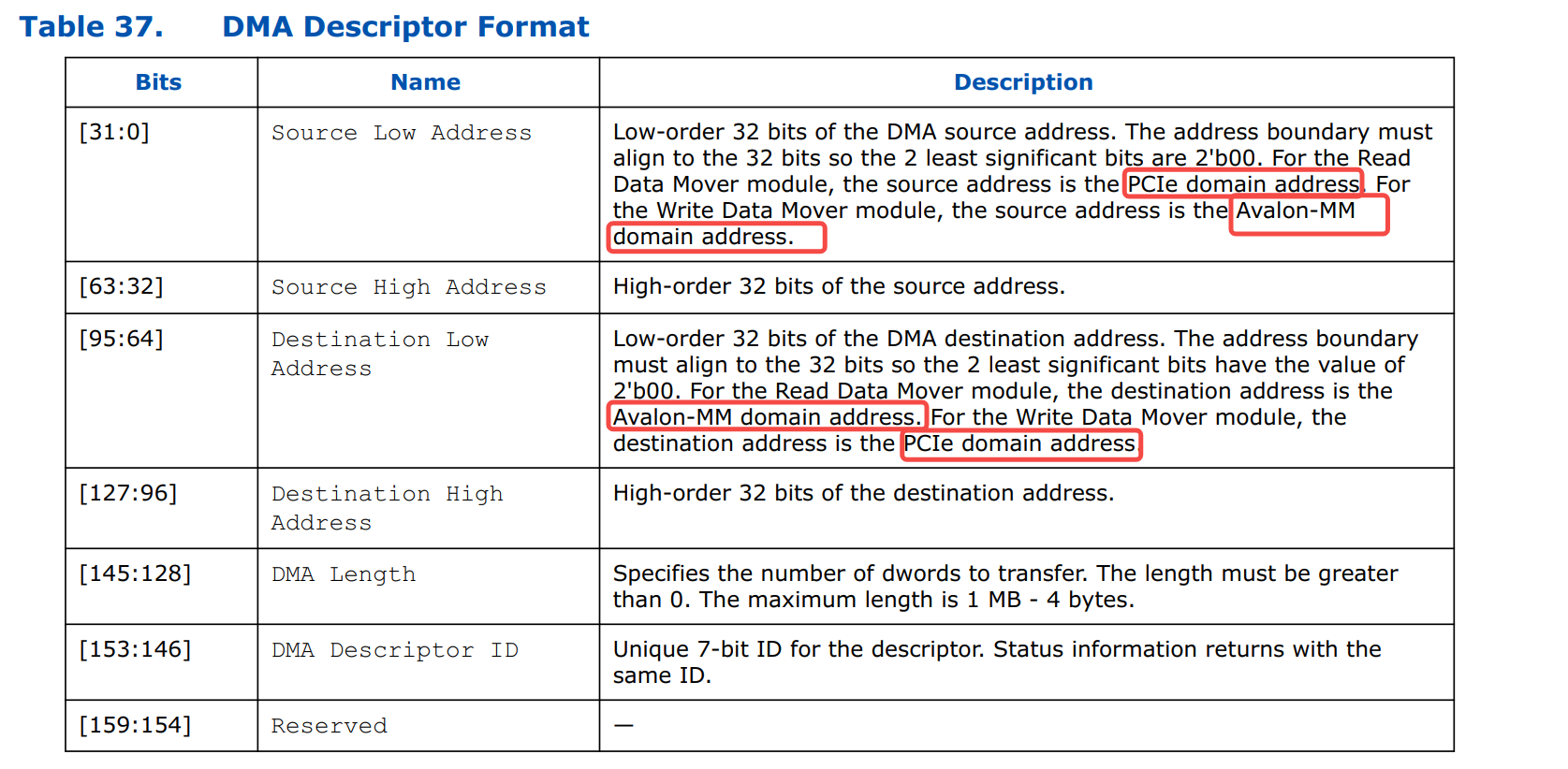
其实,从这里的描述就可以猜测出,eDMA 发出的 MemRd ,
虽然理论上走的是 outbound 路径,但是实际上没有经过 iATU 单元的转换。
因为如果要经过 iATU 单元的转换,MemRd 的地址应该是 CPU 域的地址,而不是 PCIe 域的地址。其实,这就是和硬件设计有关。我们实际开发中也要注意。
案例 2:Linux 主线里的 Synopsys DW eDMA 代码
linux/drivers/dma/dw-edma/dw-edma-core.c:
c
u64 dw_edma_get_pci_address(struct dw_edma_chan *chan, phys_addr_t cpu_addr)
{
struct dw_edma_chip *chip = chan->dw->chip;
if (chip->ops->pci_address)
return chip->ops->pci_address(chip->dev, cpu_addr);
return cpu_addr;
}
static struct dma_async_tx_descriptor *
dw_edma_device_transfer(struct dw_edma_transfer *xfer)
{
......
if (xfer->type == EDMA_XFER_INTERLEAVED) {
src_addr = xfer->xfer.il->src_start;
dst_addr = xfer->xfer.il->dst_start;
} else {
src_addr = chan->config.src_addr;
dst_addr = chan->config.dst_addr;
}
if (dir == DMA_DEV_TO_MEM)
src_addr = dw_edma_get_pci_address(chan, (phys_addr_t)src_addr);
else
dst_addr = dw_edma_get_pci_address(chan, (phys_addr_t)dst_addr);
......
} 代码里,src_addr/dst_addr 先从 channel config 里取出来,然后在 DMA_DEV_TO_MEM 或 DMA_MEM_TO_DEV 场景下,对 PCIe 那一侧 地址调用 dw_edma_get_pci_address(),将上层传递下来的 CPU 域地址,转换成 PCIe 域地址。注意,只是转换一侧,另一侧还是 CPU 域地址。
从上述代码的分析来看,PCIe eDMA 从 PCIe 外设读数据时,使用的是 PCIe 域地址,可以理解为没有经过 iATU 地址翻译单元。而 PCIe eDMA 往 CPU DDR 写数据时,使用的是 CPU 域地址,可以理解为,也没有经过 iATU 地址翻译单元,直接连接到了 AXI 总线上。
PCIe 协议并没有规定,eDMA 一定要经过 iATU 地址翻译单元。只是说,理论上我们分析,是需要经过 outbound 或者 inbound 路径的。实际上,还是需要根据硬件设计来决定。
再比如说:我们注意看注释:
linux/include/linux/dma/edma.h:
c
/**
* struct dw_edma_core_ops - platform-specific eDMA methods
* @irq_vector: Get IRQ number of the passed eDMA channel. Note the
* method accepts the channel id in the end-to-end
* numbering with the eDMA write channels being placed
* first in the row.
* @pci_address: Get PCIe bus address corresponding to the passed CPU
* address. Note there is no need in specifying this
* function if the address translation is performed by
* the DW PCIe RP/EP controller with the DW eDMA device in
* subject and DMA_BYPASS isn't set for all the outbound
* iATU windows. That will be done by the controller
* automatically.
*/
struct dw_edma_plat_ops {
int (*irq_vector)(struct device *dev, unsigned int nr);
u64 (*pci_address)(struct device *dev, phys_addr_t cpu_addr);
}; 这里写得很关键:平台回调 pci_address() 的作用是"把 CPU address 转成 PCIe bus address";如果 DW PCIe RP/EP controller 自己已经做地址翻译,且没有开 DMA_BYPASS,那这个转换可以由 controller 自动完成,无需此函数。
- CPU 地址到 PCIe bus address 的转换既可能由软件回调完成,依赖 outbound iATU 单元去翻译
- 也可能由 DW PCIe controller 在未启用
DMA_BYPASS的 outbound iATU 路径上自动完成,无需手动转换 - 也可能是
DMA_BYPASS不去做地址转换,直通
6、关于 Inbound 路径
以 rk3568 为例,实际上,当 rk3568 作为 RC 时,只有一种情况会经过 RC 的 inbound 路径,就是 EP 主动发起 MemRd 或者 MemWr。
除开这种情况,Inbound 路径最常见的就是,rk3568 作为 EP 时。
当 rk3568 作为 EP,其他的 RC 主动给 EP 发出 MemRd 或者 MemWr,走的就是 rk3568 的 Inbound 路径。