从失败中学习:在微调大型语言模型作为智能体时整合负例
目录
文章目录
- 从失败中学习:在微调大型语言模型作为智能体时整合负例
📌 文章信息
- 论文原始标题: Learning From Failure: Integrating Negative Examples when Fine-tuning Large Language Models as Agents
- 论文标题翻译 : 从失败中学习:在微调大型语言模型作为智能体时整合负例

0. 📄 摘要信息
大型语言模型在作为智能体与外部环境(如搜索引擎等工具)交互方面已取得成功。然而,LLMs 在预训练或对齐阶段主要是针对语言生成而非工具使用进行优化的,这限制了它们作为智能体的有效性。为了解决这个问题,先前的工作通常先收集 LLM 与环境之间的交互轨迹,但仅使用那些成功完成任务的轨迹来微调较小的模型。这种做法使得微调数据变得稀缺,且获取数据既困难又昂贵。丢弃失败的轨迹也导致了数据和资源的大量浪费,并限制了微调过程中的潜在优化路径。
本文认为,不成功的轨迹蕴含着宝贵的经验教训,通过适当的质量控制和微调策略,LLMs 可以从这些轨迹中学习。通过在训练期间简单地添加一个前缀或后缀来告知模型应生成成功还是失败的轨迹,我们在数学推理、多跳问答和策略性问答任务上大幅提升了模型性能。我们进一步分析了推理结果,发现我们的方法在不成功轨迹中,于有价值信息和错误之间提供了更好的权衡。据我们所知,我们是第一个证明负例轨迹的价值及其在智能体微调场景中应用的团队。我们的研究结果为开发更好的智能体微调方法和低资源数据使用技术提供了指导。
1. 🔍 研究背景
-
LLM 智能体的兴起与局限:基于 LLM 的智能体(Agent)能够执行复杂的任务,如使用工具(搜索、计算)进行多步推理。然而,主流的强大模型(如 GPT-4)通常通过付费 API 访问,存在成本高、延迟大、结果不可复现等问题。同时,这些通用 LLM 并非为"智能体"场景(如生成特定格式的动作、调用工具函数)而优化,导致其原生能力不足。
-
微调 LLM 成为智能体的主流范式:为解决上述问题,研究界探索出"数据收集-微调-推理"的三阶段范式。通常使用一个强大的教师模型(如 GPT-4)与特定环境交互,生成大量的"思考-行动-观察"轨迹。然后,用这些轨迹数据去微调一个更小、更经济的模型(如 LLaMA-7B),使其具备智能体能力。这种方法取得了显著成效,甚至能让小模型在某些任务上超越教师模型。
-
传统微调方法的数据效率问题 :在上述范式中,一个根深蒂固的做法是:只保留成功完成任务的"正例"轨迹,而将未能成功的"负例"轨迹全部丢弃。这种做法的初衷是避免模型学习到错误的动作或推理。然而,这导致了两个严重问题:一是数据利用率极低(论文指出,在复杂任务中,丢弃的负例比例可高达60%以上),使得高质量数据的获取成本极高;二是模型可能错过了从错误中学习的机会,这与人类通过试错来学习的过程背道而驰。因此,如何有效利用这些数量庞大、成本低廉但包含错误的"负例"轨迹,成为一个亟待解决的关键问题。
2.❗问题与挑战
本论文旨在解决的核心问题及其面临的挑战可以归纳如下:
-
负例是否有价值?
- 问题描述:传统观点认为,用错误的数据(负例)微调模型会"污染"模型,导致模型学习到错误的动作或推理模式。因此,一个根本性的疑问是:LLM 是否能像人类一样,从失败中提取有价值的教训(例如,哪种推理路径是死胡同,哪种工具调用是无效的),而不是简单地记住错误?
- 挑战:需要设计实验来验证负例的潜在价值,证明将其加入训练集(即使不加特殊处理)也能对最终模型性能产生正面影响,而非负面作用。这挑战了领域内的一个普遍假设。
-
如何安全有效地整合负例?
- 问题描述:简单地混合正例和负例进行训练(论文中称为 NUT,Negative-Unaware Training)可能带来风险。模型会不加区分地学习两种轨迹,可能会将负例中的错误动作或错误推理也作为"正确知识"吸收,导致性能下降。因此,核心问题是如何设计一种训练机制,让模型既能从负例中学习其"不该做什么"的教训,又能抑制其学习具体错误行为。
- 挑战:需要一种细粒度控制的方法,在训练过程中明确区分正例和负例的身份。这种方法必须足够简单,不显著增加计算复杂度,但又足够有效,能够引导模型进行"有意识"的学习。
-
负例的质量如何影响学习效果?
- 问题描述:并非所有负例都同等有用。有些负例可能只是在最后一步答错了,但前面的推理过程完全正确(接近成功);而有些负例可能从一开始就偏离了方向,充满了无效的动作和错误的逻辑(完全失败)。模型如何从这些不同"质量"的负例中学习?是否需要对其进行分级?
- 挑战:需要建立一个框架来量化负例的质量(例如,通过预测答案与标准答案的相似度),并研究不同质量的负例对模型微调效果的影响。此外,还要探索更精细的策略,以最大化高质量负例的价值,并最小化低质量负例的潜在危害。
-
模型从负例中到底学到了什么?
- 问题描述:如果负例确实提升了性能,我们需要进行机制性分析,而不仅仅是看最终的准确率数字。提升来自于更好的推理("思考"步骤)?还是更少的动作错误("行动"步骤)?还是两者皆有?负例是否让模型学会了更长的规划或更早地终止无效路径?
- 挑战:需要对模型的输出进行深入的定性和定量分析。例如,计算不同动作的错误率、分析推理文本的困惑度(Perplexity),以及观察任务解决所需的平均交互轮数,从而揭示负例影响的深层机制。
3. ⚙️ 算法模型
针对上述挑战,论文提出了一个简洁而有效的解决方案:负例感知训练 (Negative-Aware Training, NAT) 。NAT 的核心思想是在训练阶段通过修改输入格式,明确告知模型当前样本是"正确示范"还是"错误示范",从而引导模型进行区分性学习。其完整流程如下:
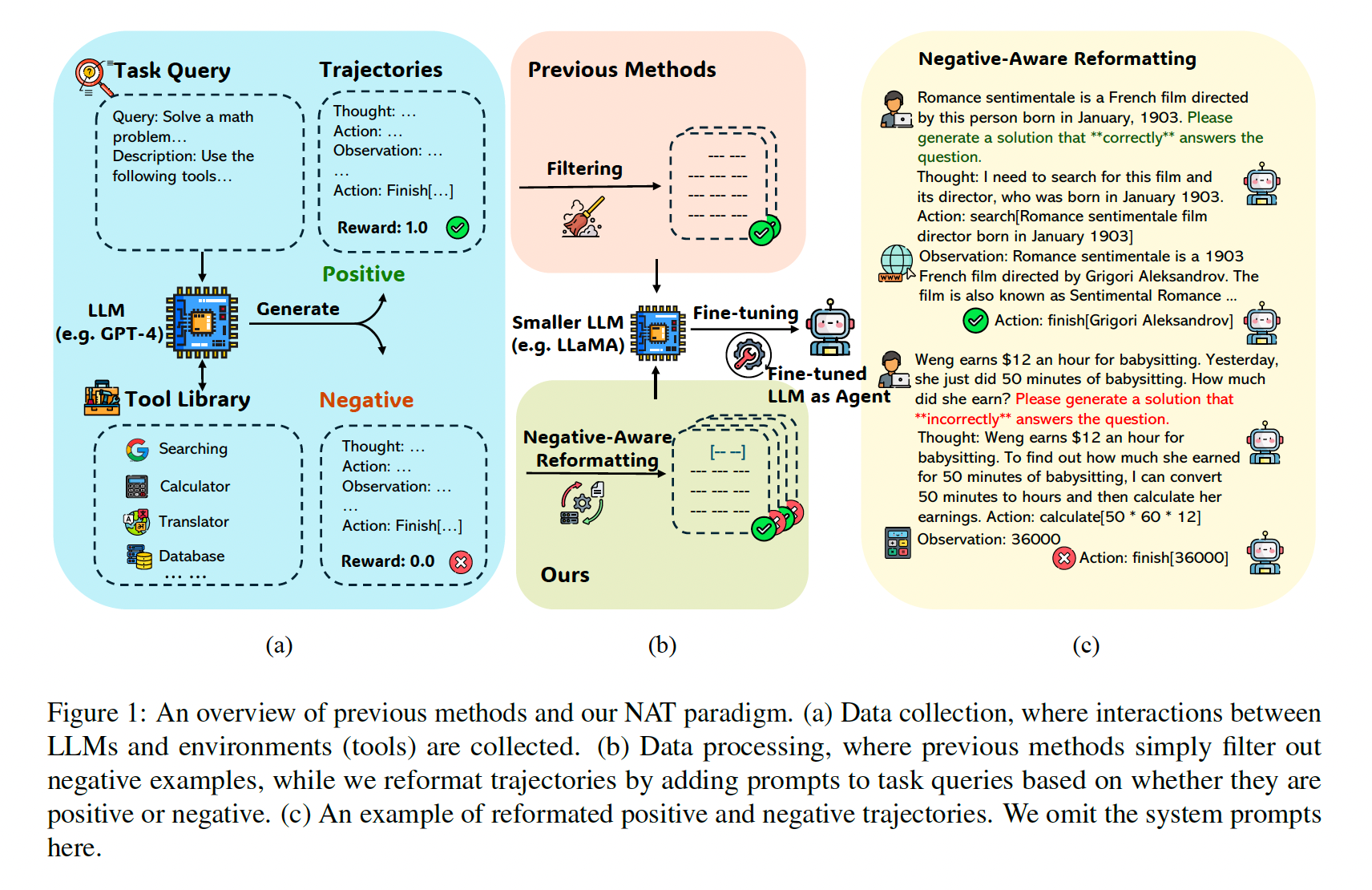
-
数据收集阶段:
- 使用一个强大的教师模型(如 GPT-3.5)对种子数据集(如 GSM8K 问题)进行推理。
- 为每个问题生成多条轨迹(例如,使用不同的温度参数 0.2, 0.5, 0.7 生成3次)。
- 根据每条轨迹的最终输出与标准答案进行比较,将轨迹标记为"正例"(成功)或"负例"(失败)。这一步与之前的工作相同。
-
负例感知重格式化 (Negative-Aware Reformatting) ------ 核心创新:
- 这是 NAT 区别于所有先前方法的关键步骤。
- 对于正例 轨迹,在其原始用户查询(Query)后添加一个特定的后缀 。论文中使用的提示是:"Please generate a solution that \\correctly\\ answers the question." (请生成一个正确回答该问题的解决方案。)
- 对于负例 轨迹,同样在其原始用户查询后添加一个不同的后缀 :"Please generate a solution that \\incorrectly\\ answers the question." (请生成一个错误回答该问题的解决方案。)
- 目的 :这个简单的改动在训练数据中为模型创建了一个清晰的上下文信号。模型不再被动地接收一个"问题-轨迹"对,而是接收一个带有指令的"目标(正确/错误)-问题-轨迹"三元组。这使得模型能够根据提示的目标来理解和学习后续轨迹。
-
微调阶段:
- 使用经过重格式化的所有数据(正例+负例)来微调目标模型(如 LLaMA-2-7B/13B)。
- 采用标准的因果语言建模(Causal Language Modeling)损失函数。重要的是,损失仅在模型生成的文本部分(即轨迹中的"思考"和"行动")计算,而不包括输入的用户查询和系统提示。这保证了模型学习的是生成有效轨迹的能力。
- 模型通过这种训练,学会了根据前缀指令来调节自己的生成行为:当看到"correctly"指令时,它应生成通往正确答案的轨迹;当看到"incorrectly"指令时,它应生成导致错误的轨迹。
-
推理阶段:
- 在微调完成后,将模型作为智能体进行推理时,我们只使用正例的提示 。即,对于每一个新的测试问题,我们在用户查询后固定加上"Please generate a solution that \\correctly\\ answers the question."。
- 通过这种方式,模型被激活到"正确模式",利用它在训练期间从正例和负例中学到的所有知识(哪些路径正确,哪些路径错误),来生成一个成功的解决方案。
NUT (Negative-Unaware Training) 对比 :论文中的基线方法 NUT 与 NAT 的唯一区别在于,它在微调负例时不添加任何区分性的前缀或后缀。模型直接看到的是"问题-错误轨迹"对,因此会错误地将错误轨迹中的行为也当成标准答案来学习。
4. 💡 创新点
本论文的主要创新点可以概括为以下几点:
-
首个在LLM智能体微调中系统性地证明负例价值的工作:这是最大的创新。论文通过大量实验,强有力地反驳了"负例无用论",证明了即使是在微调范式中,模型也能从失败中学习,这为未来的数据高效利用研究开辟了新方向。
-
提出简单、有效、通用的负例感知训练(NAT)范式:NAT 的核心在于通过一个极简的提示修改(添加区分性前缀/后缀),就巧妙地解决了"如何安全地整合负例"这一核心挑战。该方法无需改变模型架构、损失函数或复杂的多阶段训练流程,具有极高的实用性和可推广性。
-
揭示了负例学习的内部机制 :论文不仅仅展示了性能提升,还通过深入的分析实验(如动作错误率、困惑度分析)揭示了 NAT 成功的奥秘:它主要帮助模型学习更好的推理(Thought) ,同时通过上下文区分有效抑制了从负例中学习动作错误(Action Error)。这种"权衡"分析是理解该方法的点睛之笔。
-
提出了细粒度 NAT (Fine-grained NAT):论文进一步扩展了 NAT 的思想,证明了不仅区分正/负例有用,对负例本身按其"错误程度"(例如,根据 F1 分数)进行分级并赋予不同的提示,可以带来更进一步的性能提升。这展示了 NAT 框架的灵活性和巨大潜力。
-
验证了方法的广泛适用性:论文在数学推理(GSM8K等)、多跳问答(HotpotQA)、策略问答(StrategyQA)等多个任务,以及 ReAct 和 Chain-of-Thought 两种不同的推理策略上,均验证了 NAT 的有效性,证明了其是一种与任务和策略无关的通用技术。
5. 📊 实验效果(重要数据与结论)
实验设置
- 模型:LLaMA-2-Chat (7B 和 13B)。
- 任务:数学推理 (GSM8K, ASDiv, SVAMP, MultiArith),多跳问答 (HotpotQA),策略问答 (StrategyQA)。
- 基线 :
- Vanilla:仅使用正例微调(代表之前所有工作的做法)。
- NUT (Negative-Unaware Training):混合正例和负例微调,但不加区分性提示。
- 评估指标:准确率(数学)、精确匹配(EM)和 F1 分数(HotpotQA)、准确率(StrategyQA)。
核心实验结果与结论
-
NAT 显著且一致地优于基线 (Table 2, 3, 4):
- 数学任务 :在 LLaMA-2-7B 上,NAT 相比 Vanilla 平均提升高达 8.74%(2k正例时)。在 13B 模型上也有一致提升。NAT 在所有设置下都优于 NUT,证明区分性提示至关重要。
- 问答任务 (HotpotQA) :NAT 相比 Vanilla,在 7B 模型上 EM 提升 1.36% ,F1 提升 4.96% 。其变体 NAT-2 效果更佳,EM 提升 2.32% ,F1 提升 6.1%。
- 问答任务 (StrategyQA) :NAT 相比 Vanilla 提升超过 10%(7B: 55.4→65.8)。
-
数据稀缺场景下受益更大:当正例数量有限时(例如只有2k),NAT 带来的性能提升远大于正例充足时(例如5k)。这表明 NAT 是一种极其有效的低资源数据增强技术。
-
负例数量与质量的平衡 (Figure 2, Table 5):
- 数量:在一定范围内,增加负例数量能持续提升性能,直至饱和(~11k)。
- 质量:高质量负例(来自 GPT-3.5)能大幅提升性能,而低质量负例(来自弱模型)甚至会损害性能(Table 5,2k正例时性能下降 3.16%)。这说明负例的"价值"是关键,而非简单地越多越好。
-
NAT 的学习机制:更好的推理 vs. 更少的动作错误 (Table 6):
- 直接使用负例(NUT)虽然提高了准确率,但动作错误率也显著上升(从 4.01% 升至 15.33%),说明模型学到了一些错误的动作。
- NAT 成功地在提升准确率的同时,将动作错误率控制在一个较低的水平 (相比 NUT 显著降低)。论文由此得出结论:NAT 主要帮助模型学习更优的推理(Thought) ,同时通过区分性提示抑制了动作错误(Action) 的学习。
-
区分性是关键,而非语义内容 (Table 7) :无论使用有意义的提示("correct/incorrect")还是无意义的随机字符串("A/B"),NAT 都能取得类似性能提升。这证明了 NAT 成功的核心是为模型提供了区分正负例的上下文信号,而不是提示本身的语义指导模型"应该做什么"。
📈 推荐阅读指数
⭐⭐⭐⭐⭐(强烈推荐)
✅ 推荐理由
-
问题导向性强,切中当前痛点:LLM 智能体是前沿热点,但高昂的数据成本和低下的数据利用率是阻碍其发展的关键瓶颈。该论文直面这一问题,并给出了一个极其巧妙的解决方案。
-
方法简洁优雅,效果显著:NAT 的实现只需在数据预处理时修改一下输入文本,无需改动模型结构和训练流程。这种"四两拨千斤"的简洁性,使其具有极高的实用价值和落地潜力。实验证明,它能在多种任务和模型上稳定、显著地提升性能,尤其是在数据稀缺场景下。
-
理论分析深入,富有启发性:论文不止于展示结果,而是通过精妙设计的分析实验(动作错误率、困惑度、负例质量控制等),深刻揭示了模型从正/负例中到底学到了什么。特别是关于 NAT 如何在"更好的推理"和"更少的动作错误"之间取得平衡的分析,对理解 LLM 的训练动力学非常有启发。
-
挑战并修正了领域内的一个常见误区:长期以来,"只用高质量正例"是微调中的金科玉律。该论文用扎实的证据挑战了这一观点,证明"垃圾"(负例)经过合理处理也可以变成"宝藏"。这种颠覆性的认识,对于整个 AI 领域的数据使用观念都具有冲击和启发意义。
-
具有广泛的应用前景:NAT 的思想可以轻松扩展到智能体微调之外的其他领域,如指令微调、偏好学习,甚至是多模态模型训练。任何需要从正反例子中学习的场景,都可以借鉴其"区分性上下文标记"的核心思想。
总结:这是一篇兼具创新性、简洁性、有效性和深刻洞察力的优秀工作。它不仅提供了一个立即可用的高效微调工具,更重要的是,它启发我们重新审视那些被普遍丢弃的"失败"数据的潜在价值。因此,我给予其五星级的强烈推荐评级。
后记
- 如果您对我的博客内容感兴趣,欢迎三连击(点赞, 关注和评论) !!!
- 本博客将持续为您带来计算机人工智能前沿技术研究进展分享,助您更快了解 AI前沿技术。