
🔥草莓熊Lotso: 个人主页
❄️个人专栏: 《C++知识分享》 《Linux 入门到实践:零基础也能懂》
✨生活是默默的坚持,毅力是永久的享受!
🎬 博主简介:

文章目录
- 前言:
- [一. 你真的懂pthread_t吗?揭开线程 ID 的本质](#一. 你真的懂pthread_t吗?揭开线程 ID 的本质)
-
- [1.1 两个线程 ID:用户态pthread_t vs 内核态 LWP](#1.1 两个线程 ID:用户态pthread_t vs 内核态 LWP)
- [1.2 pthread_t的本质:TCB 控制块的指针](#1.2 pthread_t的本质:TCB 控制块的指针)
- [二. 线程与进程地址空间的完整布局(可以先结合上面的图再来理解)](#二. 线程与进程地址空间的完整布局(可以先结合上面的图再来理解))
-
- [2.1 先搞懂:动态库的加载映射](#2.1 先搞懂:动态库的加载映射)
- [2.2 线程在地址空间中的完整布局](#2.2 线程在地址空间中的完整布局)
- [2.3 主线程栈 vs 子线程栈的核心区别](#2.3 主线程栈 vs 子线程栈的核心区别)
- [三. pthread_create源码级全解析:线程创建的完整流程](#三. pthread_create源码级全解析:线程创建的完整流程)
-
- [3.1 步骤 1:函数入口与参数校验](#3.1 步骤 1:函数入口与参数校验)
- [3.2 步骤 2:分配线程栈与 TCB 控制块](#3.2 步骤 2:分配线程栈与 TCB 控制块)
- [3.3 步骤 3:TCB 控制块完整初始化](#3.3 步骤 3:TCB 控制块完整初始化)
- [3.4 步骤 4:返回用户态线程 ID](#3.4 步骤 4:返回用户态线程 ID)
- [3.5 步骤 5:调用 clone 系统调用,创建内核轻量级进程](#3.5 步骤 5:调用 clone 系统调用,创建内核轻量级进程)
- [3.6 步骤 6:线程启动,执行用户函数](#3.6 步骤 6:线程启动,执行用户函数)
- [四. 线程栈的底层实现与关键细节(补充了解)](#四. 线程栈的底层实现与关键细节(补充了解))
-
- [4.1 线程栈的内存布局](#4.1 线程栈的内存布局)
- [4.2 线程栈的大小设置](#4.2 线程栈的大小设置)
- [4.3 线程栈的共享性风险](#4.3 线程栈的共享性风险)
- [4.4 线程局部存储是什么?(图示代码和解析)](#4.4 线程局部存储是什么?(图示代码和解析))
- [五. 从 0 到 1:基于 clone 系统调用手动实现线程](#五. 从 0 到 1:基于 clone 系统调用手动实现线程)
-
- [5.1 clone 与 fork 的核心区别](#5.1 clone 与 fork 的核心区别)
- [5.2 手动实现线程的完整代码](#5.2 手动实现线程的完整代码)
- [六. C++ 线程封装实战:面向对象的线程类设计](#六. C++ 线程封装实战:面向对象的线程类设计)
- [七. 面试高频考点与全文总结](#七. 面试高频考点与全文总结)
-
- [7.1 面试高频考点(必背)](#7.1 面试高频考点(必背))
- [7.2 全文总结](#7.2 全文总结)
- 结尾:
前言:
大家好,我是深耕 Linux 内核与系统编程的博主。在 Linux 后端开发中,多线程编程是高性能服务的基石,但绝大多数开发者对线程的理解,只停留在
pthread_create /pthread_join的 API 调用层面。面试中一旦被问到:pthread_t到底是什么?和ps -aL看到的 LWP 有什么区别?线程在进程的虚拟地址空间中,到底是如何布局的?主线程栈和子线程栈有什么本质区别?pthread_create底层到底做了什么?很多同学就会一知半解。本文将完整参考 pthread 线程库源码、Linux 内核机制,结合 glibc-2.4 源码逐行解读,从用户态到内核态,完整拆解 Linux 线程的实现细节,带你彻底吃透 Linux 线程。
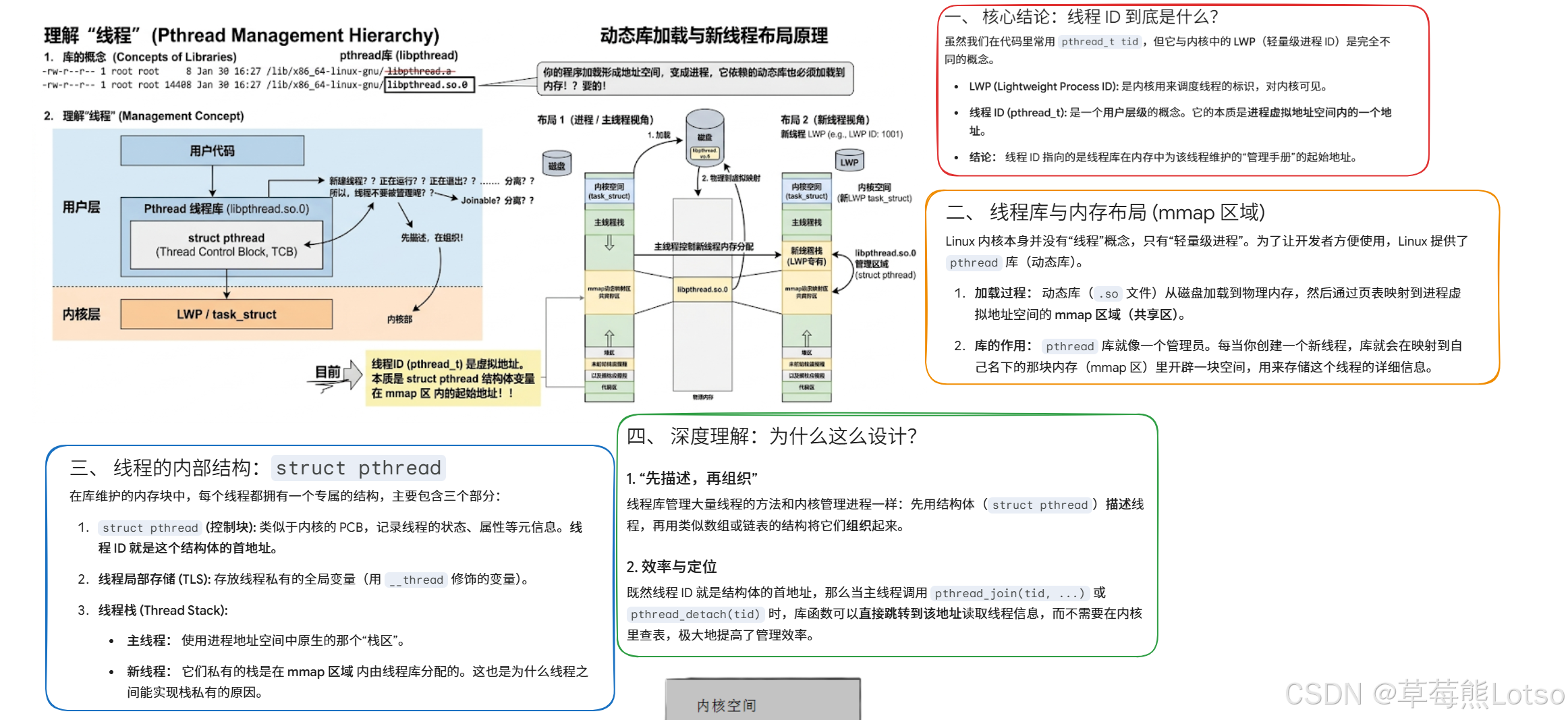
一. 你真的懂pthread_t吗?揭开线程 ID 的本质
我们日常使用pthread_create创建线程时,会得到一个pthread_t类型的线程 ID,通过pthread_self()也能获取当前线程的 ID。但 90% 的开发者都误解了这个 ID 的本质,先看一个最核心的结论:
pthread_t不是内核中的线程 LWP 号,其本质是进程虚拟地址空间中的一个内存地址,指向线程的用户态控制块 TCB!
1.1 两个线程 ID:用户态pthread_t vs 内核态 LWP
Linux 中,线程的实现采用**「用户态线程库 + 内核态轻量级进程 (LWP)」**的组合方案,因此存在两个完全不同的线程 ID,我们先通过代码直观感受:
cpp
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <unistd.h>
#include <sys/syscall.h>
// 获取内核态LWP号
#define gettid() syscall(SYS_gettid)
void *thread_routine(void *arg)
{
const char *thread_name = (const char *)arg;
printf("[%s] 用户态pthread_t: 0x%lx\n", thread_name, pthread_self());
printf("[%s] 内核态LWP号: %d\n", thread_name, gettid());
pthread_detach(pthread_self());
printf("%s exit...\n", thread_name);
return NULL;
}
int main()
{
pthread_t tid;
pthread_create(&tid, NULL, thread_routine, "sub-thread");
printf("[main-thread] 用户态pthread_t: 0x%lx\n", pthread_self());
printf("[main-thread] 内核态LWP号: %d\n", gettid());
printf("[main-thread] 新线程返回的pthread_t: 0x%lx\n", tid);
sleep(1);
return 0;
}编译运行命令:gcc thread_id.c -o thread_id -lpthread
运行结果示例:
bash
[main-thread] 用户态pthread_t: 0x7f8a1c920740
[main-thread] 内核态LWP号: 12345
[main-thread] 新线程返回的pthread_t: 0x7f8a1c000700
[sub-thread] 用户态pthread_t: 0x7f8a1c000700
[sub-thread] 内核态LWP号: 12346
sub-thread exit...这里我们能清晰看到两个核心区别:
- 内核态
LWP号 :通过gettid()获取(以前其实是需要自己去实现调系统调用的,这个后面我会在封装线程中用到),对应ps -aL命令看到的 LWP 列,是内核轻量级进程的唯一标识,是操作系统调度的最小单位,全局唯一。 - 用户态
pthread_t:通过pthread_self()获取,是 NPTL 线程库维护的进程内唯一标识,本质是一个虚拟地址,作用域仅限当前进程,内核不认识这个值。
1.2 pthread_t的本质:TCB 控制块的指针
为什么说pthread_t是一个地址?我们直接从 glibc 源码中找答案,源码路径:nptl/pthread_create.c中的核心函数__pthread_create_2_1(这是pthread_create的真正实现)。
源码中最关键的一行:
cpp
// 重点5:把pd(就是线程控制块地址)作为ID,传递出去,所以上层拿到的就是一个虚拟地址
*newthread = (pthread_t)pd;这里的pd是struct pthread *类型的指针,也就是线程控制块 TCB (Thread Control Block) 的起始地址。pthread库直接把 TCB 在进程虚拟地址空间中的地址,强制类型转换为pthread_t返回给用户,这就是pthread_t的本质。
后续我们调用pthread_join/pthread_detach/pthread_cancel等函数时,传入的pthread_t,本质就是告诉线程库:去操作这个地址对应的 TCB 控制块。
二. 线程与进程地址空间的完整布局(可以先结合上面的图再来理解)
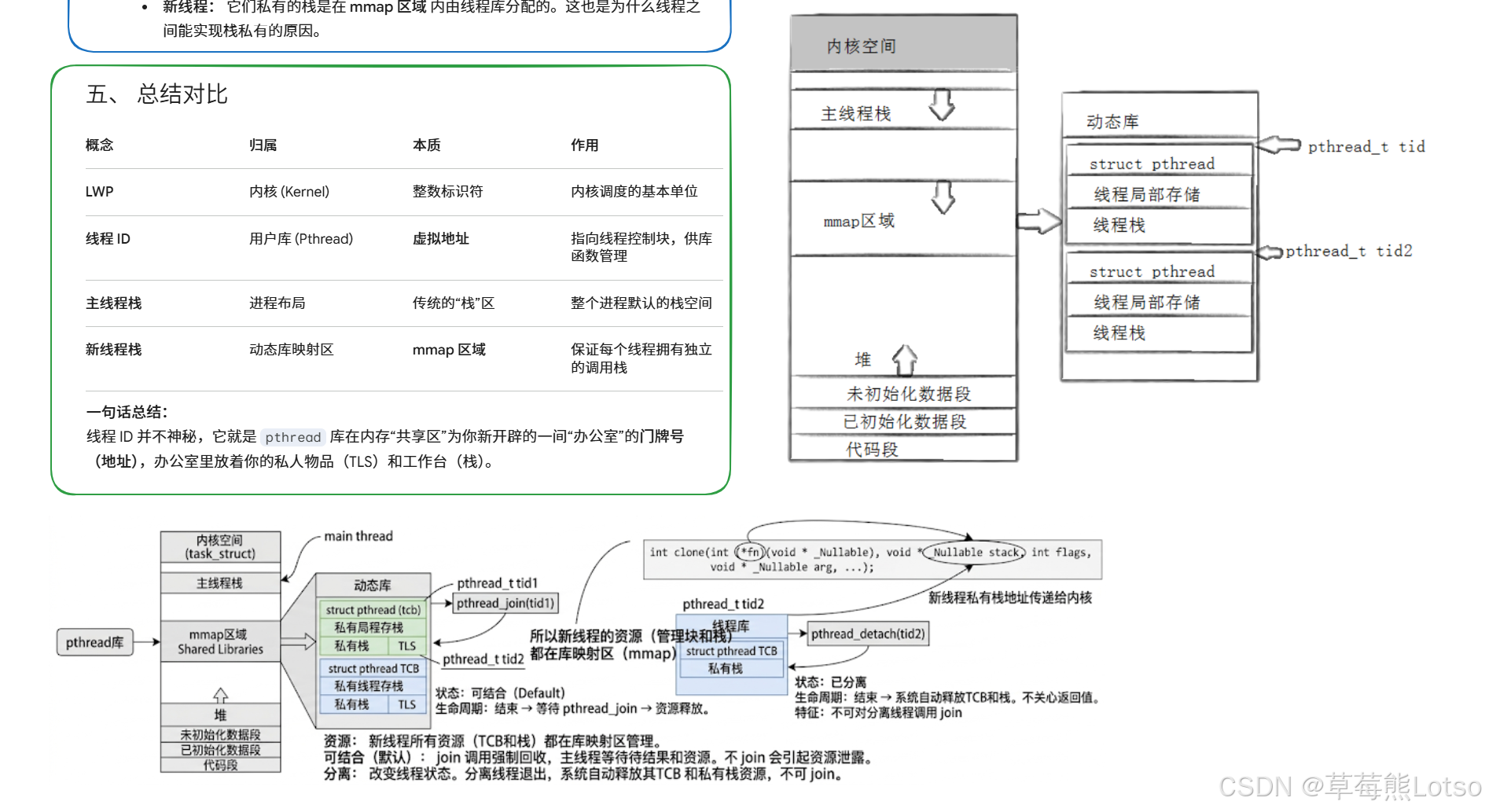
理解了线程 ID 的本质,我们再看一个核心问题:进程的虚拟地址空间,是如何容纳多个线程的? 这是理解 Linux 线程实现的核心。
2.1 先搞懂:动态库的加载映射
我们使用的pthread系列函数,都来自libpthread.so动态库。而动态库在程序运行时,会被加载到进程虚拟地址空间的共享区(mmap 映射区),也就是栈区和堆区之间的内存区域,整个过程如下:
- 程序启动时,内核加载可执行文件到代码段;
- 动态链接器将依赖的
libpthread.so加载到共享区,完成函数地址动态重定位; - 我们调用
pthread_create时,CPU 直接跳转到共享区的库函数代码执行。
这也是为什么同一个进程的所有线程,都能调用pthread库函数 ------ 它们共享同一个地址空间,共享区的库代码对所有线程可见。
2.2 线程在地址空间中的完整布局
以 32 位 Linux 系统为例,进程虚拟地址空间范围是 0~4GB,其中内核空间占 1GB,用户空间占 3GB。多线程进程的地址空间完整布局如下(从上到下):
| 地址空间区域 | 线程相关内容 | 共享 / 私有 |
|---|---|---|
| 内核空间(1GB) | 内核代码、数据、页表,所有线程共享同一份内核映射 | 全线程共享 |
| 用户栈区 | 主线程的栈空间,向下生长,支持动态扩容 | 主线程私有 |
| 共享区(mmap 映射区) | 1. libpthread.so等动态库的代码和数据 2. 每个子线程的 TCB 控制块(struct pthread) 3. 每个子线程的独立栈空间 4. 线程局部存储 TLS 区域 |
库代码全共享,每个子线程私有自己的 TCB、栈、TLS |
| 堆区 | malloc/new分配的内存,所有线程均可访问 |
全线程共享 |
| 未初始化数据段(BSS) | 全局变量、静态变量,所有线程共享 | 全线程共享 |
| 已初始化数据段 | 初始化的全局变量、静态常量,所有线程共享 | 全线程共享 |
| 代码段 | 程序的可执行机器指令,所有线程共享 | 全线程共享 |
这里有两个最核心的结论:
- 进程是资源分配的基本单位(基本实体),线程是调度的基本单位:同一个进程的所有线程,共享绝大多数进程资源,只私有自己的 TCB、栈、寄存器上下文等最小调度资源。
- 子线程的栈和 TCB,都在共享区通过 mmap 分配:这是和主线程最核心的区别,也是我们后面要重点讲解的内容。
2.3 主线程栈 vs 子线程栈的核心区别
很多同学会疑惑:都是线程栈,为什么主线程栈和子线程栈差异这么大?我们结合源码和内核机制,做一个完整的对比,这也是面试高频考点:
| 特性 | 主线程栈 | 子线程栈 |
|---|---|---|
| 内存位置 | 进程地址空间的栈区 | 共享区(mmap 映射区) |
| 分配方式 | 进程创建时由内核自动分配 | pthread库通过mmap系统调用手动分配 |
| 大小特性 | 支持动态向下增长,默认上限 8MB,超出后内核自动扩容 | 固定大小,默认 8MB,创建时确定,无法动态增长 |
| 栈溢出保护 | 内核自动处理,超出上限触发段错误 | 通过guardsize保护页实现,溢出访问保护页触发段错误 |
| 生命周期 | 随进程的生命周期存在,进程退出才释放 | 线程退出后,join/detach 时由pthread库释放,未处理会造成内存泄漏 |
| 地址生长 | 标准向下生长,内核维护栈边界 | 固定地址范围,无动态生长能力 |
这里重点讲两个底层细节:(第二个在之前的博客中讲过)
- 子线程栈为什么不能动态增长? 子线程栈是
mmap分配的连续固定内存块,前后都是其他线程的栈或动态库内存,没有连续的地址空间供其扩容,一旦栈使用超出分配的大小,就会直接访问到保护页,触发段错误。 - 线程切换为什么比进程快得多? 进程切换时,内核会修改 CR3 寄存器,指向新进程的页目录,导致 CPU 的 TLB(快表)全部失效,内存访问效率骤降;而同一个进程的线程切换,CR3 寄存器值不变,页表完全共享,TLB 不会失效,只需要切换线程的寄存器上下文,开销只有进程切换的 1/10 不到。
- 我们再往下继续深入看看源码,来全面的理解一下
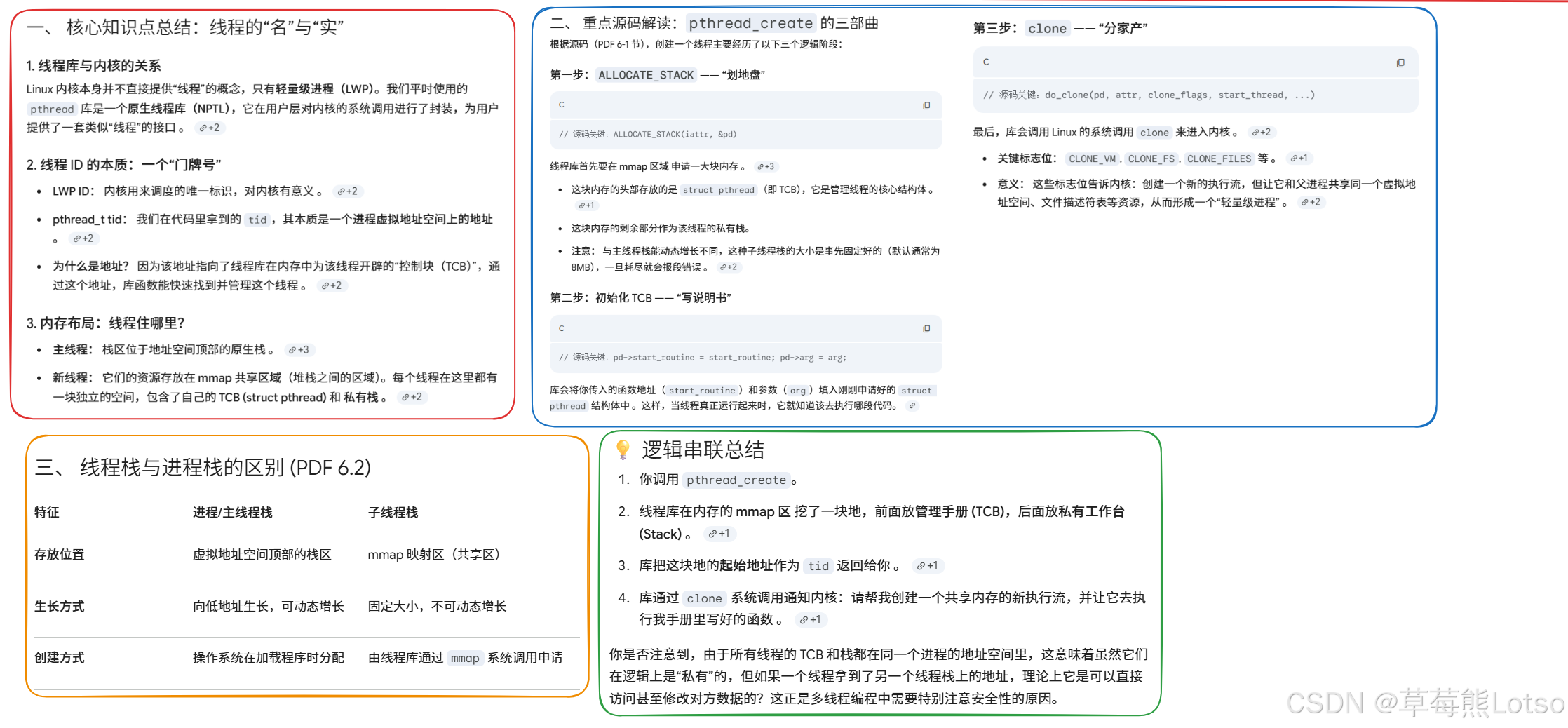
三. pthread_create源码级全解析:线程创建的完整流程
理解了地址空间布局,我们再深入pthread库源码,逐行拆解pthread_create的执行全流程。源码基于 glibc-2.4,路径nptl/pthread_create.c,核心函数__pthread_create_2_1。
整个线程创建流程,分为6 个核心步骤,我们逐一拆解:
3.1 步骤 1:函数入口与参数校验
cpp
int __pthread_create_2_1(pthread_t *newthread, const pthread_attr_t *attr,
void *(*start_routine)(void*), void *arg)
{
STACK_VARIABLES;
// 重点1: 处理线程属性,用户传NULL则使用默认属性
const struct pthread_attr *iattr = (struct pthread_attr *)attr;
if (iattr == NULL)
iattr = &default_attr;
// 重点2: 定义线程TCB指针,后续会分配内存
struct pthread *pd = NULL;- 入参
newthread:用于返回创建后的pthread_t; attr:线程属性,包括栈大小、分离状态、调度优先级等,NULL 则使用默认属性;start_routine:线程入口函数地址;arg:传递给线程入口函数的参数。
3.2 步骤 2:分配线程栈与 TCB 控制块
这是整个函数最核心的步骤,通过ALLOCATE_STACK宏完成线程栈和 TCB 的内存分配,宏对应nptl/allocatestack.c中的allocate_stack函数。
cpp
// 重点3: 分配栈内存 + 线程TCB结构体
int err = ALLOCATE_STACK(iattr, &pd);
if (__builtin_expect(err != 0, 0))
return err;我们深入allocate_stack函数,看它到底做了什么:
- 获取栈大小:用户在属性中设置了栈大小则使用用户值,否则使用系统默认值(通常 8MB);
- 缓存尝试:先从线程库的栈缓存中获取空闲的栈内存,避免频繁 mmap/munmap,提升性能;
- mmap 分配内存 :缓存未命中则调用
mmap分配匿名私有内存(不了解的可以看看我之前写的那篇mmap的加餐博客,里面的讲解比较详细):
cpp
mem = mmap(NULL, size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);-
MAP_PRIVATE:私有映射,内存修改不会同步到任何文件;
-
MAP_ANONYMOUS:匿名映射,不关联任何磁盘文件,仅用于分配内存;
- TCB 位置计算 :将
struct pthread控制块放在分配的栈内存的末尾,保证栈向下生长时不会破坏 TCB:
cpp
pd = (struct pthread *)((char *)mem + size - coloring) - 1;- 栈保护页设置 :在栈的底部分配
guardsize(默认 4KB,1 页)的内存,通过mprotect设置为PROT_NONE(不可访问),一旦栈溢出访问到该页,直接触发段错误,防止破坏其他内存; - TCB 基础字段初始化 :初始化
stackblock(栈起始地址)、stackblock_size(栈大小)、guardsize(保护页大小)等核心字段。
3.3 步骤 3:TCB 控制块完整初始化
分配好 TCB 和栈后,线程库会对 TCB 做完整的初始化,把用户传入的参数、线程属性全部写入 TCB,这是线程能正常运行的基础:
cpp
#ifdef TLS_TCB_AT_TP
// 初始化TLS线程局部存储
pd->header.self = pd;
pd->header.tcb = pd;
#endif
// 重点4: 向TCB写入线程入口函数和参数,后续线程启动会从这里取
pd->start_routine = start_routine;
pd->arg = arg;
// 拷贝线程属性、调度策略、调度参数
pd->flags = ((iattr->flags & ~(ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET))
| (self->flags & (ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET)));
// 处理分离状态:如果是分离线程,joinid指向自己
pd->joinid = iattr->flags & ATTR_FLAG_DETACHSTATE ? pd : NULL;
// 拷贝栈溢出保护canary、调度优先级、信号处理等参数
// ... 省略大量初始化代码这里的struct pthread就是线程的用户态 TCB,里面包含了线程运行需要的所有信息,我们列出核心字段:
cpp
struct pthread
{
pid_t tid; // 内核LWP号
pid_t pid; // 所属进程的PID
void *(*start_routine)(void *); // 用户传入的线程入口函数
void *arg; // 入口函数的参数
void *result; // 线程退出的返回值,pthread_join从这里取
struct pthread *joinid; // 等待该线程的线程TCB,用于join机制
void *stackblock; // 线程栈的起始地址
size_t stackblock_size; // 线程栈的总大小
size_t guardsize; // 栈保护页大小
int schedpolicy; // 调度策略
struct sched_param schedparam; // 调度优先级
// ... 省略TLS、信号、锁、清理函数等上百个字段
};3.4 步骤 4:返回用户态线程 ID
初始化完成后,线程库直接把 TCB 的地址作为pthread_t返回给用户,这就是我们前面讲的线程 ID 本质:
cpp
// 重点5: 把TCB的地址强制转换为pthread_t,返回给用户
*newthread = (pthread_t)pd;3.5 步骤 5:调用 clone 系统调用,创建内核轻量级进程
用户态的 TCB 和栈都准备好后,就需要让内核创建对应的轻量级进程,完成线程的最终创建。这里通过create_thread函数,最终调用clone系统调用:
cpp
// 检测线程是否为分离状态
bool is_detached = IS_DETACHED(pd);
// 重点6: 创建内核轻量级进程,启动线程执行
err = create_thread(pd, iattr, STACK_VARIABLES_ARGS);
if (err != 0)
{
// 创建失败,释放已分配的栈和TCB
if (!is_detached)
__deallocate_stack(pd);
return err;
}
return 0;
}
// 版本绑定,pthread_create最终指向该函数
versioned_symbol(libpthread, __pthread_create_2_1, pthread_create, GLIBC_2_1);我们看create_thread中最核心的clone_flags标志位,这是 Linux 线程和进程的核心区别:
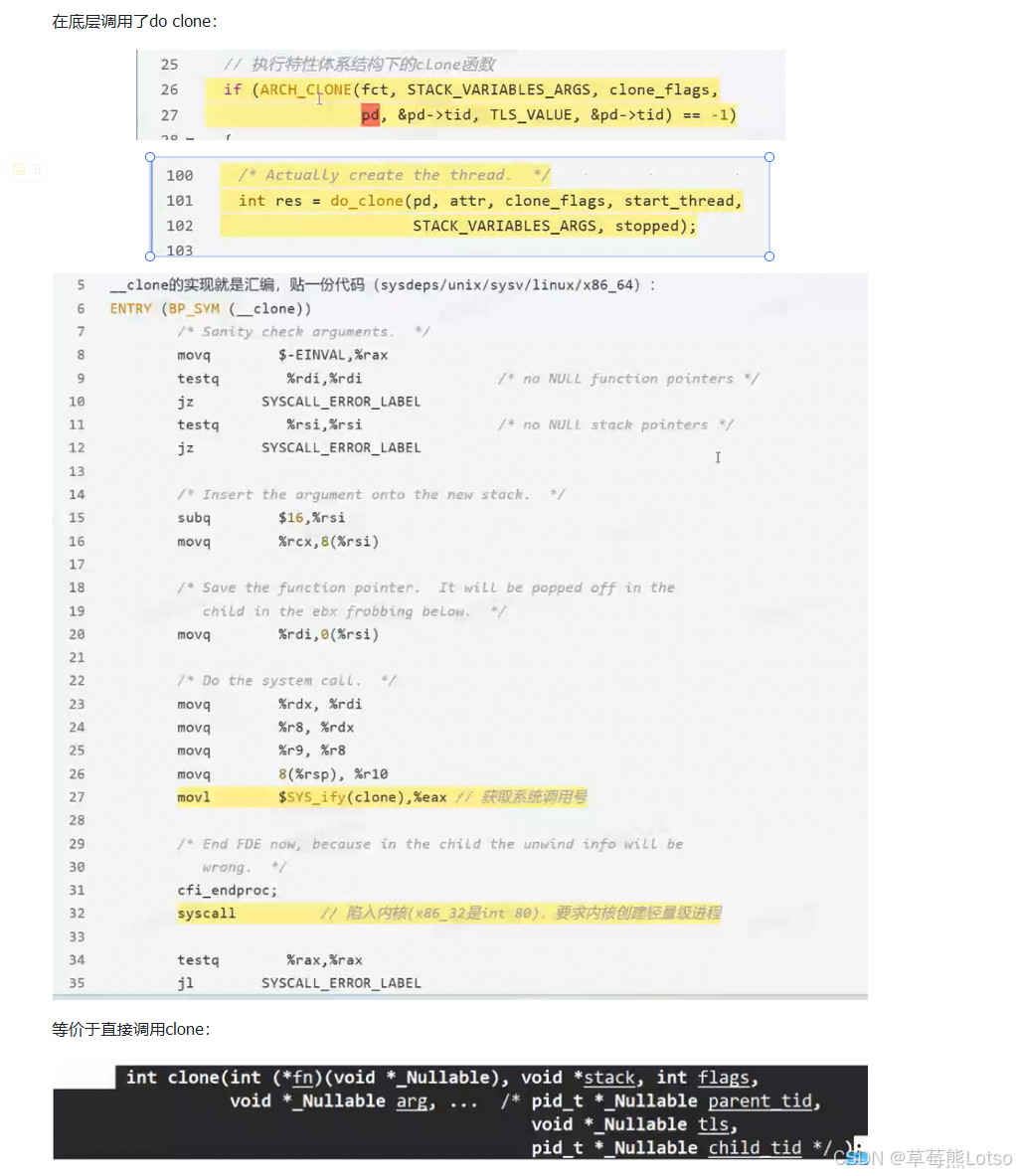
cpp
int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGNAL
| CLONE_SETTLS | CLONE_PARENT_SETTID
| CLONE_CHILD_CLEARTID | CLONE_SYSVSEM | 0);每个标志位的含义,决定了线程和父进程共享哪些资源:
| 标志位 | 核心作用 |
|---|---|
CLONE_VM |
共享虚拟地址空间,父子进程使用同一个页表,这是线程和进程最核心的区别 |
CLONE_FS |
共享文件系统信息,包括工作目录、umask 等 |
CLONE_FILES |
共享文件描述符表,一个线程打开的文件,其他线程可以直接使用 |
CLONE_SIGNAL |
共享信号处理函数表,信号的处理方式对所有线程生效 |
CLONE_SETTLS |
为新线程设置 TLS 线程局部存储区域 |
CLONE_PARENT_SETTID |
内核将新线程的 LWP 号写入父进程指定的地址 |
CLONE_CHILD_CLEARTID |
线程退出时,内核清空该地址,并触发 futex 唤醒等待的线程(join 机制的核心) |
最终,create_thread会调用do_clone,再通过汇编封装的__clone函数陷入内核,执行 clone 系统调用。内核会创建新的task_struct,共享父进程的mm_struct(地址空间)、文件表、信号表等资源,然后将新线程的入口设置为线程库的封装函数,等待调度器调度执行。
3.6 步骤 6:线程启动,执行用户函数
内核的轻量级进程被调度后,不会直接执行用户传入的start_routine,而是先执行线程库的封装函数,做一些初始化工作,再调用用户函数,执行完成后自动调用pthread_exit退出。
四. 线程栈的底层实现与关键细节(补充了解)
线程栈是线程私有资源的核心,也是多线程编程中最容易出问题的地方,我们结合源码,讲透线程栈的关键细节。
4.1 线程栈的内存布局
每个子线程的栈,都是mmap分配的一块连续内存,整体布局如下(从低地址到高地址):
bash
低地址 → 保护页(guardsize, PROT_NONE) → 线程栈可用空间 → TCB控制块 → 高地址- 保护页在栈的底部,防止栈向下溢出破坏其他内存;
- 栈可用空间从高地址向低地址生长,符合 Linux 栈的生长规则;
- TCB 放在栈内存的最高地址处,避免被栈生长破坏。
4.2 线程栈的大小设置
默认情况下,Linux 线程栈的大小是 8MB,我们可以通过两种方式修改:
- 全局修改 :通过
ulimit -s 10240修改系统默认栈大小为 10MB,仅对当前终端生效; - 代码中精准修改:通过线程属性设置,示例如下:
cpp
#include <stdio.h>
#include <pthread.h>
void *routine(void *arg)
{
printf("thread is running\n");
return NULL;
}
int main()
{
pthread_t tid;
pthread_attr_t attr;
// 初始化属性
pthread_attr_init(&attr);
// 设置栈大小为1MB
pthread_attr_setstacksize(&attr, 1024 * 1024);
// 用自定义属性创建线程
pthread_create(&tid, &attr, routine, NULL);
pthread_join(tid, NULL);
// 销毁属性
pthread_attr_destroy(&attr);
return 0;
}注意 :线程栈大小不能小于系统最小值
PTHREAD_STACK_MIN(通常 16KB),否则会创建失败。
4.3 线程栈的共享性风险
虽然每个线程的栈是私有的,但这只是逻辑上的私有。因为所有线程共享同一个地址空间,只要一个线程拿到了另一个线程栈变量的地址,就可以随意修改该变量 ,这是多线程编程中非常隐蔽的风险点。
我们看一个反面示例:
cpp
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>
int *shared_stack_var = NULL;
void *thread1_routine(void *arg)
{
int a = 100; // 线程1的栈变量
shared_stack_var = &a; // 把栈变量地址暴露给全局
printf("thread1 set a = %d\n", a);
sleep(2); // 等待线程2修改
printf("thread1 a is changed to %d\n", a);
return NULL;
}
void *thread2_routine(void *arg)
{
sleep(1);
*shared_stack_var = 200; // 直接修改线程1的栈变量
printf("thread2 modify a to 200\n");
return NULL;
}
int main()
{
pthread_t t1, t2;
pthread_create(&t1, NULL, thread1_routine, NULL);
pthread_create(&t2, NULL, thread2_routine, NULL);
pthread_join(t1, NULL);
pthread_join(t2, NULL);
return 0;
}运行结果:
cpp
thread1 set a = 100
thread2 modify a to 200
thread1 a is changed to 200可以看到,线程 2 成功修改了线程 1 的栈变量,这会导致极其隐蔽的 bug,开发中绝对不要把局部栈变量的地址传递给其他线程。
4.4 线程局部存储是什么?(图示代码和解析)
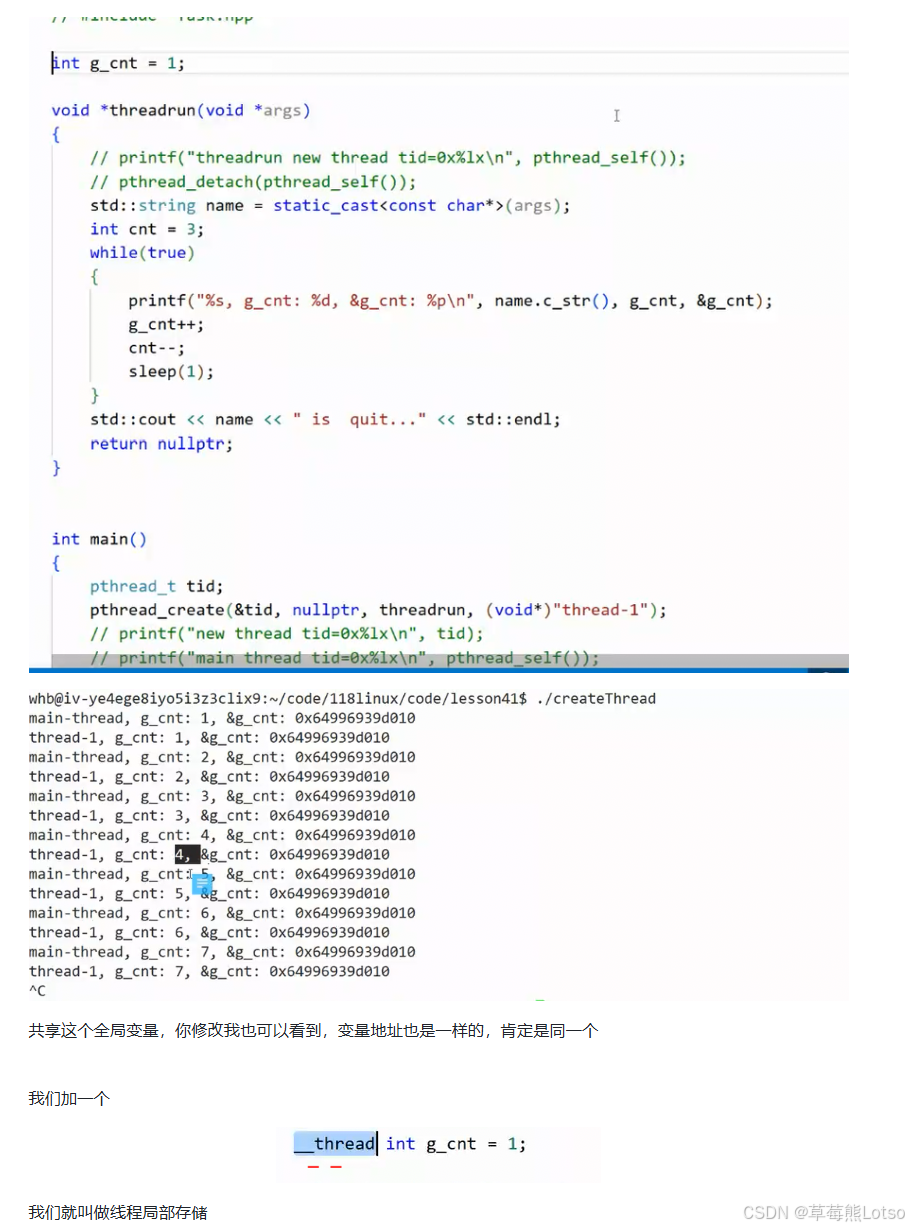
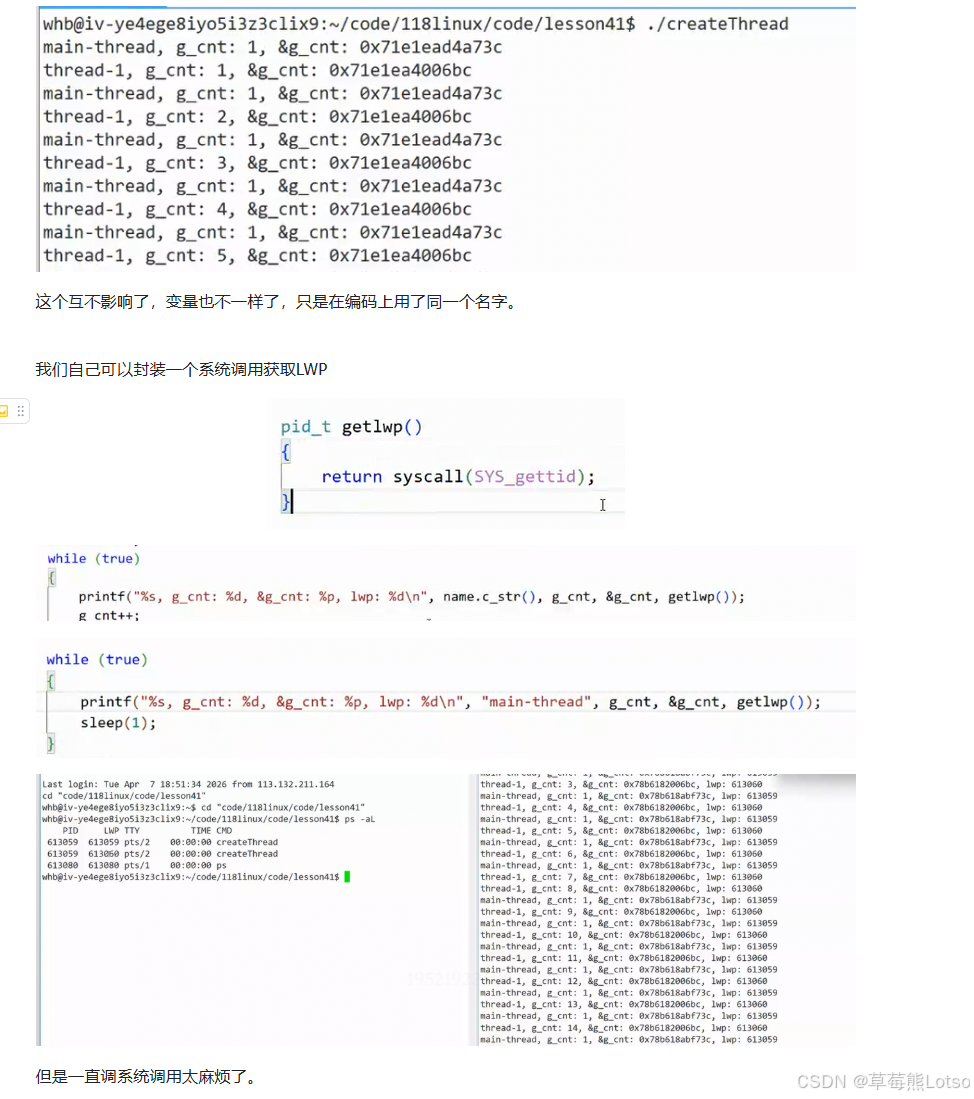
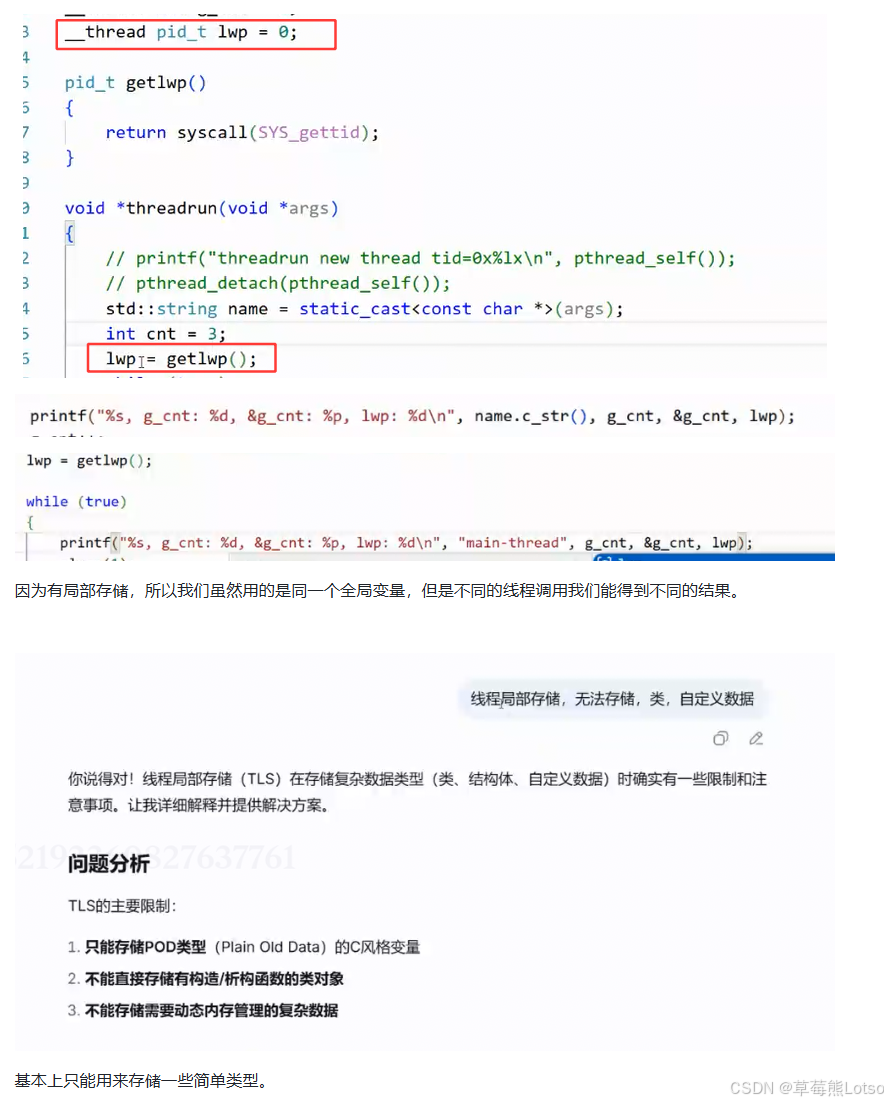

五. 从 0 到 1:基于 clone 系统调用手动实现线程
理解了pthread_create的底层是 clone 系统调用,我们可以直接基于 clone 手动实现一个极简的线程,直观感受 Linux 线程的底层实现。
5.1 clone 与 fork 的核心区别
fork():创建子进程时,复制父进程的所有资源,采用写时拷贝,父子进程拥有独立的地址空间;clone():可以通过参数精准控制父子进程共享哪些资源,传入CLONE_VM就可以共享地址空间,实现线程。
5.2 手动实现线程的完整代码
cpp
#define _GNU_SOURCE
#include <sched.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
#include <unistd.h>
// 定义线程栈大小 1MB
#define STACK_SIZE (1024 * 1024)
// 子线程执行的函数
static int child_thread_func(void *arg)
{
char *thread_name = (char *)arg;
printf("[%s] 进程PID: %d, 线程LWP: %d\n", thread_name, getpid(), gettid());
printf("[%s] 线程正在执行...\n", thread_name);
for (int i = 0; i < 3; i++)
{
printf("[%s] 计数: %d\n", thread_name, i);
sleep(1);
}
printf("[%s] 线程退出\n", thread_name);
return 0;
}
int main()
{
printf("[main] 主进程PID: %d, 主线程LWP: %d\n", getpid(), gettid());
// 1. 为子线程分配栈空间
char *stack = (char *)malloc(STACK_SIZE);
if (stack == NULL)
{
perror("malloc stack failed");
exit(EXIT_FAILURE);
}
// 2. 创建线程:共享地址空间,栈从高地址向低地址生长,所以传入栈的末尾
pid_t tid = clone(child_thread_func,
stack + STACK_SIZE,
CLONE_VM | CLONE_FS | CLONE_FILES | SIGCHLD,
"my-thread");
if (tid == -1)
{
perror("clone failed");
free(stack);
exit(EXIT_FAILURE);
}
printf("[main] 成功创建线程,LWP号: %d\n", tid);
// 3. 等待子线程结束
if (waitpid(tid, NULL, 0) == -1)
{
perror("waitpid failed");
free(stack);
exit(EXIT_FAILURE);
}
printf("[main] 线程已退出,程序结束\n");
free(stack);
return 0;
}编译运行命令:gcc clone_thread.c -o clone_thread,运行结果:
bash
[main] 主进程PID: 12500, 主线程LWP: 12500
[main] 成功创建线程,LWP号: 12501
[my-thread] 进程PID: 12500, 线程LWP: 12501
[my-thread] 线程正在执行...
[my-thread] 计数: 0
[my-thread] 计数: 1
[my-thread] 计数: 2
[my-thread] 线程退出
[main] 线程已退出,程序结束可以看到,我们通过 clone 创建的轻量级进程,和主线程拥有相同的 PID,不同的 LWP,共享同一个地址空间,这就是 Linux 线程的本质。
六. C++ 线程封装实战:面向对象的线程类设计
在 C++ 开发中,我们通常会对原生的 pthread 接口做面向对象的封装,屏蔽底层 C 接口的细节,让线程使用更便捷。我们参考文档中的封装 demo,实现一个功能完整的 C++ 线程类,支持任意可调用对象、参数传递、join/detach、线程命名等功能。
6.1 Makefile文件
bash
CXX = g++
CXXFLAGS = -std=c++11 -Wall -g
TARGET = testThread
SRCS = Main.cc
OBJS = $(SRCS:.cc=.o)
$(TARGET): $(OBJS)
$(CXX) $(CXXFLAGS) -o $@ $^
%.o: %.cc Thread.hpp
$(CXX) $(CXXFLAGS) -c -o $@ $<
clean:
rm -f $(OBJS) $(TARGET)
.PHONY: clean6.2 线程类头文件 Thread.hpp
cpp
#ifndef __THREAD_HPP
#define __THREAD_HPP
#include <iostream>
#include <string>
#include <functional>
#include <pthread.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/syscall.h>
using func_t = std::function<void()>;
enum class TSTAYUS
{
THREAD_NEW,
THREAD_RUNNING,
THREAD_STOPPED,
};
// 这个是有点bug的
static int gunm = 1;
class Thread
{
private:
void get_pid()
{
_pid = getpid();
}
void get_lwid()
{
_lwid = syscall(SYS_gettid);
}
static void* routine(void* args)
{
Thread* ts = static_cast<Thread*>(args);
ts->get_pid();
ts->get_lwid();
pthread_setname_np(pthread_self(), ts->Name().c_str());
ts->_func();
return nullptr;
}
public:
Thread(func_t f) : _func(f), _joinable(true), _status(TSTAYUS::THREAD_NEW)
{
_name = "thread-" + std::to_string(gunm++);
}
void start()
{
if(_status == TSTAYUS::THREAD_RUNNING)
{
std::cerr << "thread is already running" << std::endl;
return;
}
int n = pthread_create(&_tid, nullptr, routine, this);
if(n != 0)
{
std::cerr << "pthread_create failed" << std::endl;
}
_status = TSTAYUS::THREAD_RUNNING;
}
void stop()
{
if(_status == TSTAYUS::THREAD_RUNNING)
{
int n = pthread_cancel(_tid);
if(n != 0)
{
std::cerr << "pthread_cancel failed" << std::endl;
}
_status = TSTAYUS::THREAD_STOPPED;
}
else
{
std::cerr << "thread status is : THREAD_STOPPED or THREAD_NEW" << std::endl;
return;
}
}
void join()
{
if(_joinable)
{
int n = pthread_join(_tid, nullptr);
if(n != 0)
{
std::cerr << "pthread_join failed" << std::endl;
}
printf("lwp: %d, name: %s, join success\n", _lwid, _name.c_str());
}
else {
printf("lwp: %d, name: %s, join failed, because thread is detached\n", _lwid, _name.c_str());
}
}
void detach()
{
if(_joinable && _status == TSTAYUS::THREAD_RUNNING)
{
_joinable = false;
int n = pthread_detach(_tid);
if(n != 0)
{
std::cerr << "pthread_detach failed" << std::endl;
}
}
}
std::string Name()
{
return _name;
}
~Thread()
{}
private:
pthread_t _tid;
pid_t _pid;
pid_t _lwid;
std::string _name;
func_t _func;
bool _joinable;
TSTAYUS _status;
};
#endif6.2 测试主程序 main.cc
cpp
#include <iostream>
#include <unistd.h>
#include <vector>
#include "Thread.hpp"
void hello()
{
char name[64];
pthread_getname_np(pthread_self(), name, sizeof(name));
int count = 0;
while(count < 5) // 执行5次后退出
{
std::cout << "hello thread: " << name << std::endl;
sleep(1);
count++;
}
}
int main()
{
std::vector<Thread> threads;
for(int i = 0; i < 10; i++)
{
threads.emplace_back(hello);
}
for(auto& t : threads)
{
t.start();
}
for(auto& t : threads)
{
t.join();
}
return 0;
}编译运行命令:直接make就行了,运行后可以通过ps -aL看到子线程,完美实现了面向对象的线程封装。

七. 面试高频考点与全文总结
7.1 面试高频考点(必背)
pthread_t和 LWP 的区别是什么?pthread_t是用户态线程库维护的线程 ID,本质是进程虚拟地址空间中 TCB 控制块的地址,进程内唯一;- LWP 是内核轻量级进程的 ID,是操作系统调度的最小单位,全局唯一。
- 线程在进程地址空间中是如何布局的?
- 主线程栈在地址空间的栈区,子线程的栈和 TCB 控制块都在共享区(mmap 区),通过 mmap 分配;
- 所有线程共享代码段、数据段、堆区、文件描述符表、信号处理函数等进程资源,仅私有栈、TCB、寄存器上下文。
pthread_create底层做了哪些事情?- 校验线程属性,使用默认属性填充;
- 通过 mmap 分配线程栈和 TCB 控制块内存;
- 初始化 TCB,写入线程入口函数、参数、属性等信息;
- 将 TCB 地址作为
pthread_t返回给用户; - 调用 clone 系统调用,创建内核轻量级进程,设置共享资源标志位;
- 内核创建 task_struct,共享进程地址空间,等待调度执行。
- 主线程栈和子线程栈的核心区别?
- 位置不同:主线程栈在栈区,子线程栈在共享区;
- 分配方式不同:主线程栈由内核分配,子线程栈由 pthread 库 mmap 分配;
- 生长特性不同:主线程栈支持动态增长,子线程栈固定大小,无法扩容。
- 为什么线程切换比进程切换快?
- 线程切换无需修改 CR3 寄存器,页表共享,CPU 的 TLB 不会失效,内存访问效率不受影响;
- 进程切换需要切换 CR3 寄存器,TLB 全部刷新,内存访问效率骤降;
- 线程切换仅需保存和恢复寄存器上下文,进程切换还需要切换地址空间、文件表等大量资源。
7.2 全文总结
Linux 下的线程实现,是用户态 NPTL 线程库 + 内核态轻量级进程的完美结合:
- 用户态线程库负责 TCB 管理、栈内存分配、TLS 管理、线程生命周期控制;
- 内核负责线程的调度,通过 clone 系统调用实现资源共享,让多个轻量级进程共享同一个进程的地址空间;
pthread_t的本质是 TCB 控制块的虚拟地址,这是理解整个线程实现的核心钥匙。
结尾:
html
🍓 我是草莓熊 Lotso!若这篇技术干货帮你打通了学习中的卡点:
👀 【关注】跟我一起深耕技术领域,从基础到进阶,见证每一次成长
❤️ 【点赞】让优质内容被更多人看见,让知识传递更有力量
⭐ 【收藏】把核心知识点、实战技巧存好,需要时直接查、随时用
💬 【评论】分享你的经验或疑问(比如曾踩过的技术坑?),一起交流避坑
🗳️ 【投票】用你的选择助力社区内容方向,告诉大家哪个技术点最该重点拆解
技术之路难免有困惑,但同行的人会让前进更有方向~愿我们都能在自己专注的领域里,一步步靠近心中的技术目标!结语:多线程编程的难点,从来都不是 API 的调用,而是对底层实现的理解。只有搞懂了线程在地址空间中的布局、底层的创建流程,才能写出高效、安全的多线程代码,从容应对面试和线上问题。如果本文对你有帮助,欢迎点赞、收藏、关注,后续会持续分享 Linux 系统编程、网络编程、后端开发的硬核内容!
✨把这些内容吃透超牛的!放松下吧✨ ʕ˘ᴥ˘ʔ づきらど
