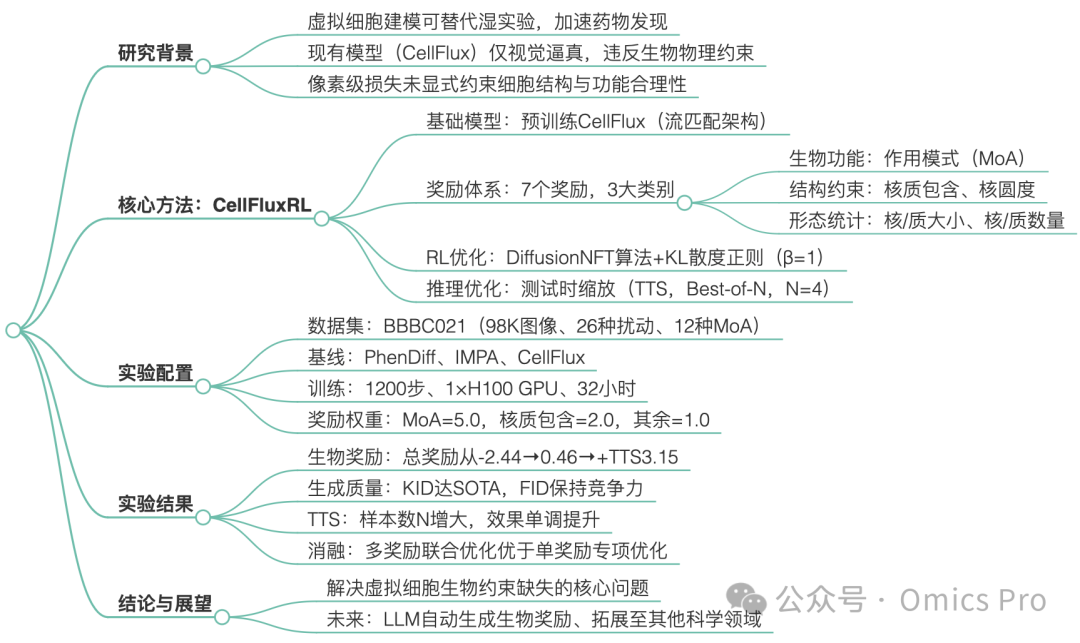
摘要
利用生成模型构建虚拟细胞以在硅基平台模拟细胞行为,正成为加速药物研发的新兴范式。但现有基于图像的生成方法易生成违背基础物理与生物约束的不合理细胞图像。针对该问题,本文提出采用强化学习(RL)对虚拟细胞模型进行后训练,将具有生物学意义的评估器作为奖励函数。本文设计了涵盖生物功能、结构有效性、形态正确性3大类的7项奖励,对当前最优的CellFlux模型斯坦福+哈佛医学院:虚拟细胞图像生成基础模型进行优化,得到CellFluxRL。在所有奖励指标上,CellFluxRL均优于原始CellFlux,结合测试时缩放策略可进一步提升性能。总体而言,本文提出的虚拟细胞建模框架通过强化学习施加基于物理的约束,将细胞生成从「视觉逼真」推进至「生物学有意义」的层面。
#虚拟细胞建模 #强化学习 #生物约束 #流匹配 #生成模型 #细胞形态模拟 #药物发现
引言
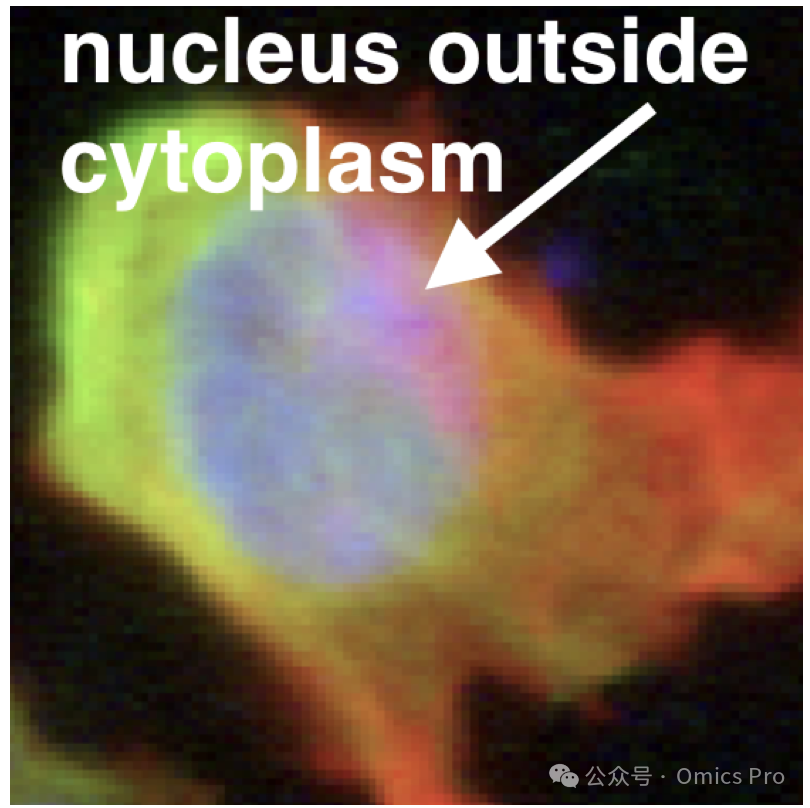
图 1 细胞生成失效案例
细胞生成模型的失效示例。例如生成的细胞核出现在细胞质外部。
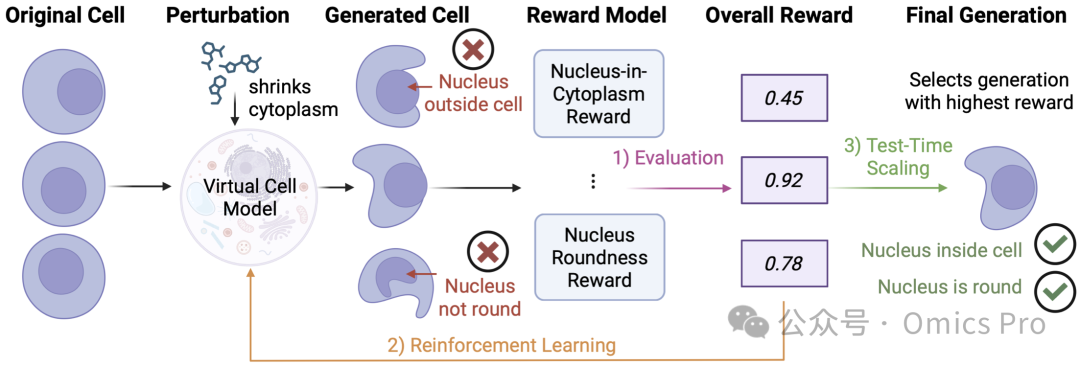
图 2 研究动机
现有用于模拟细胞扰动的生成模型无法生成物理合理的细胞图像。例如细胞核可能出现在细胞膜外。本文设计1套具有生物学意义的验证器,承担3种角色:
(1) 作为评估器,评判生成图像的生物合理性;
(2) 作为奖励信号,通过强化学习优化生成效果;
(3) 作为验证模块,通过测试时缩放提升样本质量。
方法
基于生物奖励的强化学习
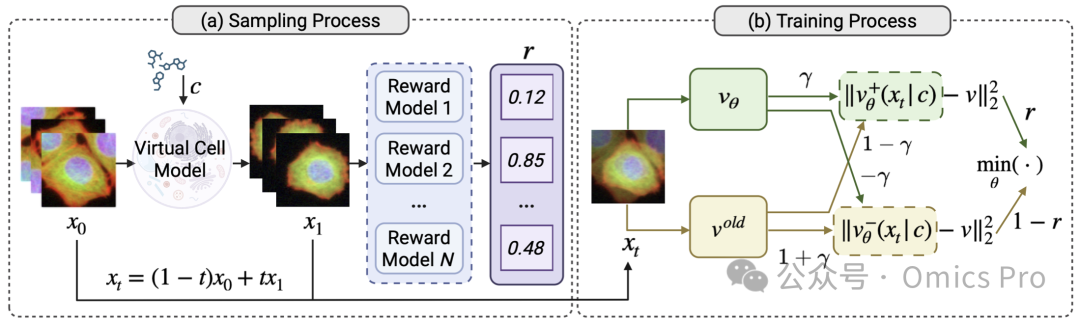
图 3 CellFluxRL算法流程
CellFluxRL算法。强化学习后训练旨在提升高奖励样本的生成概率,降低低奖励样本的生成概率。因此,CellFluxRL的核心训练循环由采样与训练交替阶段构成。
(a) 采样阶段:从固定的对照细胞图像与扰动条件生成多个rollout样本,并用奖励模型打分;
(b) 训练阶段:由于流匹配的精确似然难以求解,本文从1批rollout样本中构建正向与反向速度场,通过对比优化实现目标,方法遵循DiffusionNFT。
结果
实验细节
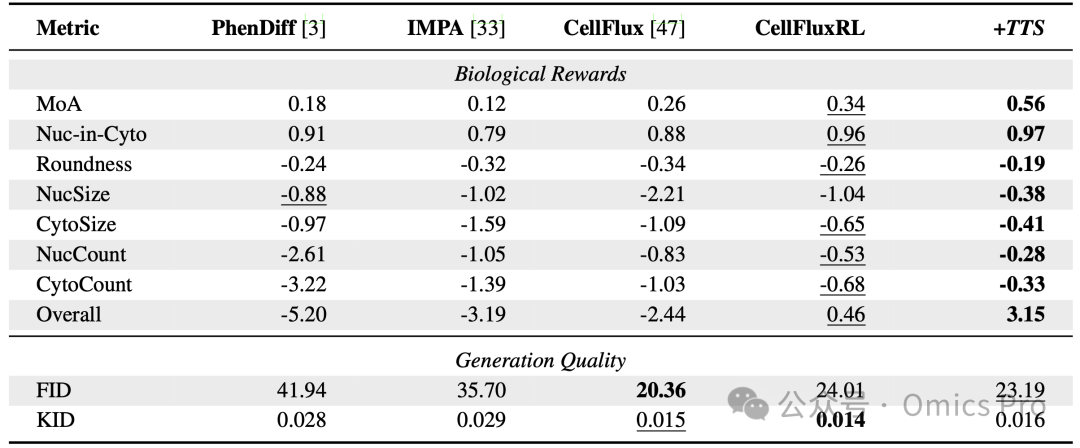
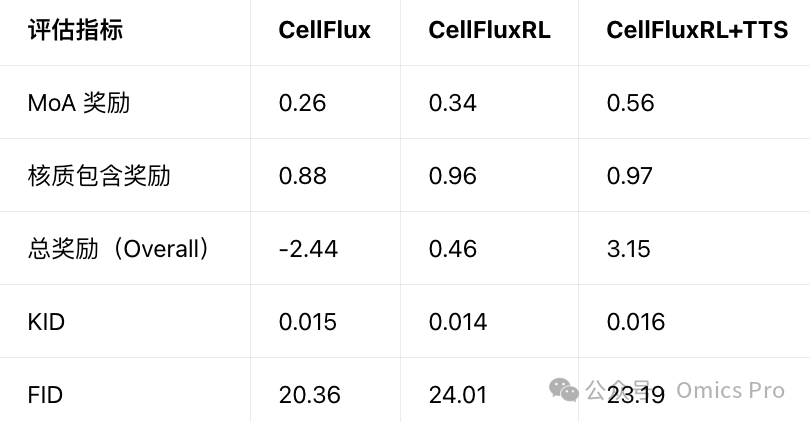
表1 生物奖励与生成质量指标的定量对比
每行代表不同评估指标,每列代表不同方法。TTS指采用N=4的最优样本选择策略进行测试时缩放的CellFluxRL,按加权总奖励选择最优样本。加粗值为最优性能,下划线值为次优性能。
强化学习带来性能提升
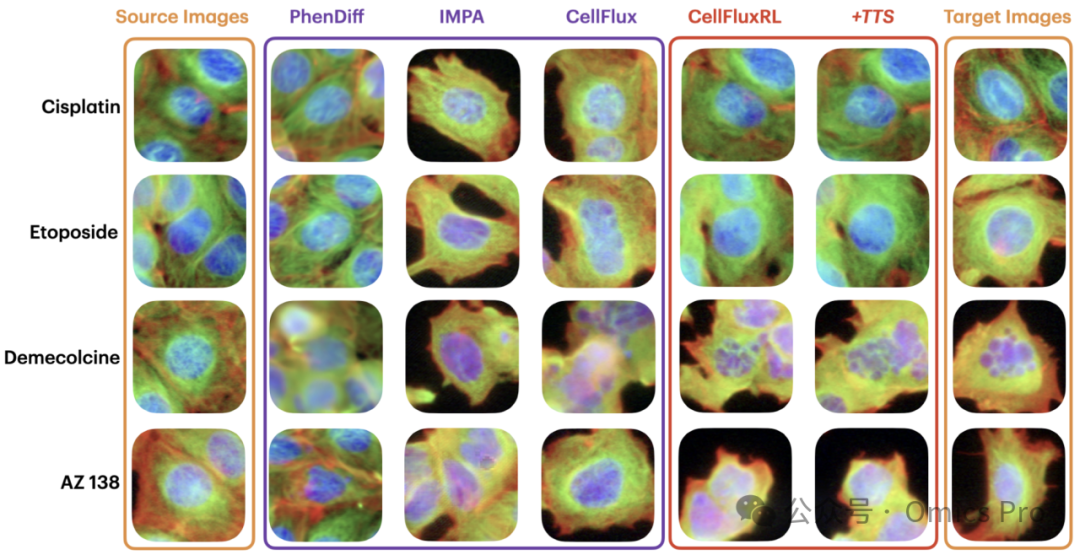
图 4 定性对比
CellFluxRL生成更贴合生物规律的图像,能更精准地复现药物诱导的形态变化。在这些示例中,依托泊苷诱导的细胞圆化、秋水仙胺介导的微管解聚、AZ138相关的细胞收缩均被更真实地还原,顺铂处理后的细胞密度也与真实情况更匹配。测试时缩放(+TTS)进一步将生成结果向真实目标图像优化。
测试时缩放进一步提升效果
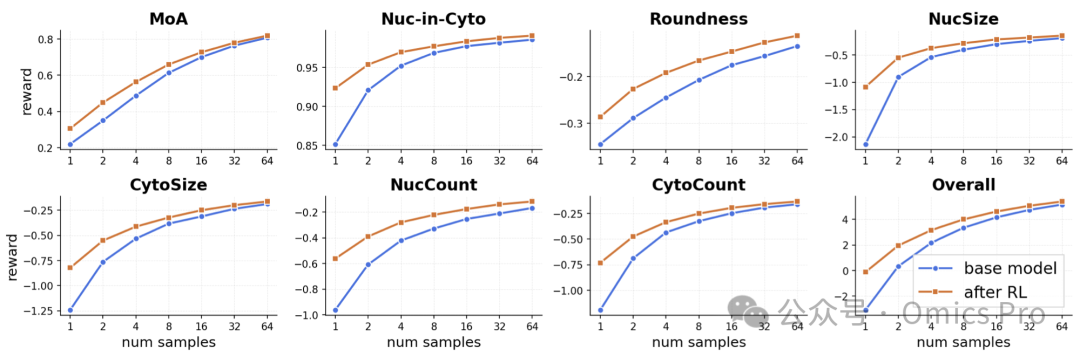
图 5 基于最优N样本选择的测试时缩放效果
从N个rollout样本中选择总奖励(加权组合)最高的样本,绘制各单项奖励结果。在所有奖励指标上,强化学习后模型(橙色)的缩放效果始终优于基础模型(蓝色)。
KL散度权重的敏感性分析
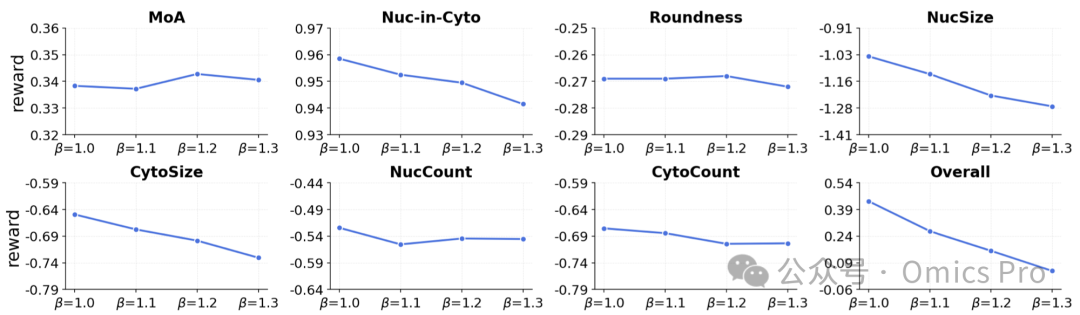
图 6 KL权重β的敏感性分析
每个子图展示强化学习后训练的模型奖励随β值的变化趋势。
单奖励优化消融实验
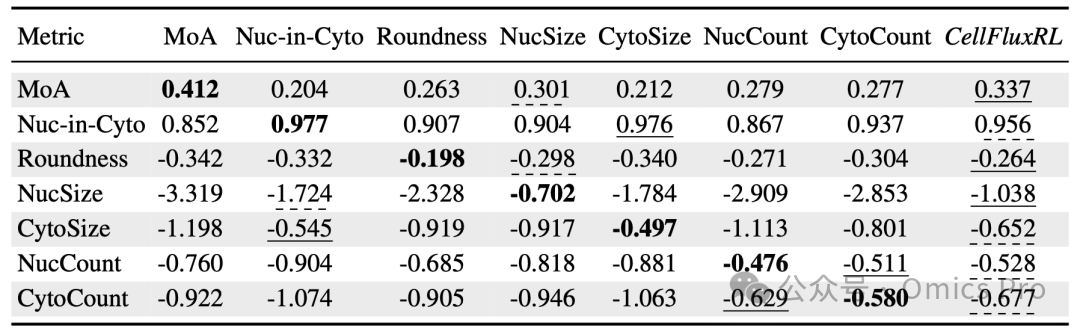
表2 基于强化学习的单奖励优化
每列代表仅优化单项奖励的模型或优化全部奖励的CellFluxRL,每行代表不同评估指标。加粗值为最优性能,下划线值为次优性能,虚下划线值为第3优性能。
详细总结
思维导图
生物有效性全面超越基线
参考
CellFluxRL: Biologically-Constrained Virtual Cell Modeling via Reinforcement Learning
https://doi.org/10.48550/arXiv.2603.21743
注:AI辅助创作,如有错误欢迎指出。内容仅供参考,不构成任何建议。