论文地址:https://arxiv.org/pdf/2507.07957?
GitHub :https://github.com/Mirix-AI/MIRIX
pip install mirix==0.1.6安装的是一个 AI 多智能体记忆系统相关的 Python 包 ,简单说它不是常规工具库,而是一个 面向 LLM/Agent 的"长期记忆系统框架"。
目录
[2.1 研究背景](#2.1 研究背景)
[2.2 现有方案缺陷](#2.2 现有方案缺陷)
[3.应用与用例(Application & Use Cases)](#3.应用与用例(Application & Use Cases))
[3.1 MIRIX 桌面应用](#3.1 MIRIX 桌面应用)
[3.2 可穿戴设备记忆系统](#3.2 可穿戴设备记忆系统)
[3.3 智能体记忆市场](#3.3 智能体记忆市场)
[4 方法论(Methodology)](#4 方法论(Methodology))
[4.1 六大记忆组件](#4.1 六大记忆组件)
[Core Memory(核心记忆)](#Core Memory(核心记忆))
[Episodic Memory(情景记忆)](#Episodic Memory(情景记忆))
[Semantic Memory(语义记忆)](#Semantic Memory(语义记忆))
[Procedural Memory(过程记忆)](#Procedural Memory(过程记忆))
[Resource Memory(资源记忆)](#Resource Memory(资源记忆))
[Knowledge Vault(知识金库)](#Knowledge Vault(知识金库))
[5.2.LOCOMO 实验](#5.2.LOCOMO 实验)
[6.相关工作(Related Work)](#6.相关工作(Related Work))
1.摘要
尽管人工智能智能体的记忆能力正受到越来越多的关注,但现有解决方案仍存在根本性局限。大多数方案依赖于扁平、范围狭窄的记忆组件,这限制了它们随时间推移实现个性化、抽象化以及可靠回忆用户特定信息的能力。为此,我们推出了MIRIX,这是一个模块化的多智能体记忆系统,通过解决该领域最关键的挑战------让语言模型真正实现记忆,重新定义了人工智能记忆的未来。与以往的方法不同,MIRIX突破文本的局限,融入了丰富的视觉和多模态体验,使记忆在真实场景中真正发挥作用。MIRIX包含六种独特且结构严谨的记忆类型:核心记忆、情景记忆、语义记忆、程序记忆、资源记忆和知识库,同时搭配一个多智能体框架,可动态控制和协调记忆的更新与检索。这一设计使智能体能够大规模持久化、推理并准确检索多样化的长期用户数据。我们在两种高要求的场景中对MIRIX进行了验证。首先,在ScreenshotVQA这一具有挑战性的多模态基准测试中------该测试每个序列包含近2万张高分辨率电脑截图,需要深度的上下文理解能力,且现有记忆系统均无法适用------MIRIX的准确率比RAG基准模型高出35%,同时存储需求降低了99.9%。其次,在LOCOMO这一包含单模态文本输入的长对话基准测试中,MIRIX取得了85.4%的顶尖性能,远超现有基准模型。这些结果表明,MIRIX为增强记忆的大语言模型智能体树立了新的性能标杆。为了让用户体验我们的记忆系统,我们推出了一款基于MIRIX的集成应用。它可实时监控屏幕,构建个性化记忆库,并提供直观的可视化效果和安全的本地存储,以保障用户隐私。
- 标题:MIRIX: Multi-Agent Memory System for LLM-Based Agents
- 核心:模块化 + 多智能体 + 多模态的全能记忆系统
- 成绩:
- ScreenshotVQA 多模态基准:准确率第一,存储降 99.9%
- LOCOMO 长对话基准:85.38% SOTA,超第二名 8%+
- 落地:提供可安装的桌面应用,支持屏幕监控→自动建记忆→自然问答
2.引言(Introduction)
2.1 研究背景
LLM 智能体在任务执行(代码、浏览、工具调用)进步快,但记忆能力被严重忽略。人类依赖记忆实现连贯行为,AI 也需要:
- 记住用户长期信息
- 个性化交互
- 避免重复提问
- 从经验中学习
2.2 现有方案缺陷
主流方案:知识图谱 (Zep/Cognee)、扁平向量库(Letta/Mem0/ChatGPT Memory)
| 现有缺陷 | 具体表现 |
|---|---|
| 无组合化结构 | 所有信息塞一起,无情景 / 语义 / 过程分工,召回低效 |
| 多模态支持差 | 只处理文本,无法处理截图、界面、图像 |
| 无抽象与可扩展性 | 存原始数据,尤其图像,存储爆炸,无提炼 |
提出6 大记忆组件 + 多智能体架构 + 主动召回机制 ,实现结构化、多模态、可扩展记忆。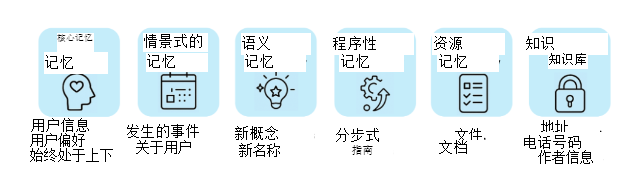
3.应用与用例(Application & Use Cases)
3.1 MIRIX 桌面应用
- 前端:React-Electron;后端:Uvicorn
- 屏幕监控:每 1.5s 截图,去重,20 张触发更新
- 流式上传:调用 Gemini,端到端时延从 50s → <5s
能力:对话查询、记忆可视化、本地安全存储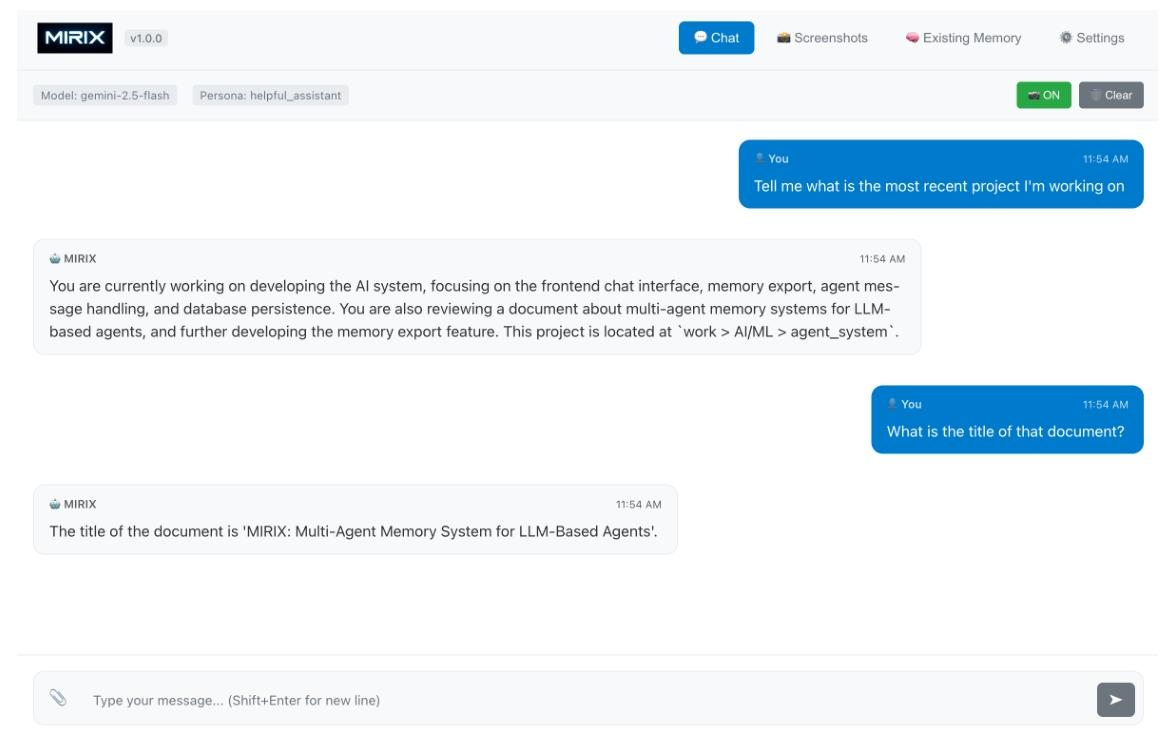
3.2 可穿戴设备记忆系统
适配 AI 眼镜、AI 胸针等轻硬件:
- 实时采集音视频、构建用户专属记忆
- 过程记忆:学习用户路线、会议结构
- 语义记忆:偏好、环境、习惯
- 情景记忆:带时间戳事件
- 混合存储:敏感信息本地存,大资源云端存
3.3 智能体记忆市场
将个人记忆变成数字资产,构建去中心化生态:
- AI 智能体基础设施(个人助手、可穿戴、多智能体协作)
- 隐私保护(端到端加密、细粒度权限、去中心化存储)
- 记忆交易 / 社交 / 粉丝经济 / 专家社区
| 应用场景 | 核心价值 | 技术特点 |
|---|---|---|
| 桌面个人助手 | 屏幕行为记忆、问答、可视化 | 低延迟、多模态、本地隐私 |
| 可穿戴 AI | lifelong 记忆、轻量化 | 端云混合、低算力 |
| 记忆市场 | 记忆资产化、交易共享 | 隐私安全、去中心化 |
4 方法论(Methodology)
4.1 六大记忆组件
MIRIX 最核心创新:6 类分工明确、结构化记忆。
| 记忆名称 | 存储内容 | 关键字段 | 核心作用 |
|---|---|---|---|
| Core Memory(核心记忆) | 智能体人设、用户基础信息、常驻偏好 | persona、human | 始终在上下文,保证基础认知 |
| Episodic Memory(情景记忆) | 带时间戳的事件、交互、行为 | 类型、摘要、详情、参与者、时间 | 时序推理、追踪行为、追溯事件 |
| Semantic Memory(语义记忆) | 概念、实体、关系、常识 | 名称、摘要、详情、来源 | 抽象知识、关联推理 |
| Procedural Memory(过程记忆) | 操作步骤、工作流、指南 | 类型、目标、步骤列表 | 任务执行、自动化、复现流程 |
| Resource Memory(资源记忆) | 文档、多模态文件、长内容 | 标题、摘要、类型、内容 | 长任务上下文、引用原文 |
| Knowledge Vault(知识金库) | 敏感明文:密码、电话、地址、密钥 | 类型、敏感度、密文 | 安全存储、权限管控 |
Core Memory(核心记忆)
最高优先级、永远在上下文里的基础记忆,是智能体 "不会忘" 的信息。
存储内容
-
智能体自身人设(性格、语气、身份、行为准则)
-
用户长期不变的基础信息(姓名、偏好、重要属性)
-
必须时刻可见的关键配置
分为两大块:
-
Persona(智能体人设)
- 身份、语气、行为模式、目标
-
Human(用户信息)
- 姓名、习惯、偏好、固定特征
管理机制
-
容量达到 90% 自动精简重写
-
只保留最关键信息,保证轻量、常驻
- 用户名叫 David
- 用户喜欢日料
- 智能体语气专业简洁
Episodic Memory(情景记忆)
带时间戳的事件日志 ,记录 "什么时候发生了什么",像智能体的人生日历 。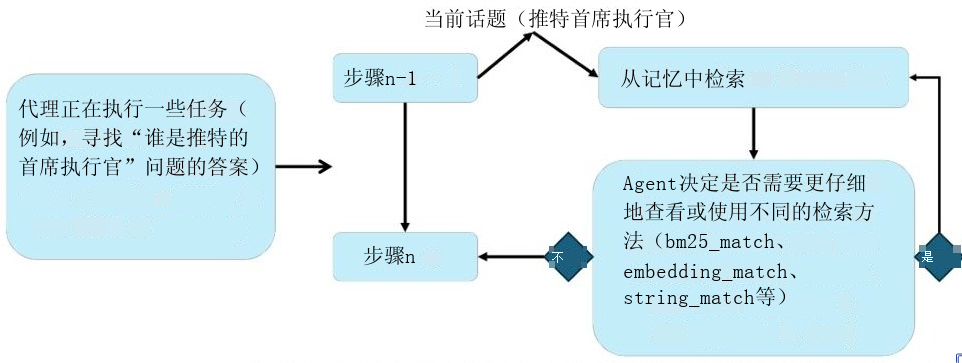
存储内容
- 用户所有时序化事件、操作、对话、行为
- 带时间、主体、上下文的完整经历
- 用于追踪习惯、追溯事件、时序推理
标准字段(论文原文)
- event_type:事件类型(用户消息 / 系统通知 / 推理结果)
- summary:事件精简摘要
- details:详细上下文(对话原文、推理过程)
- actor:发起者(用户 / 智能体)
- timestamp:时间戳(精确到分钟)
设计意图
- 支持时序推理:先做了什么、后做了什么
- 支持行为分析:用户习惯、最近任务
- 支持待办跟进:未完成事项追踪
典型示例
- 2025-04-14 10:15,用户查看 MIRIX 论文
- 2025-04-14 11:00,用户询问六大记忆组件
Semantic Memory(语义记忆)
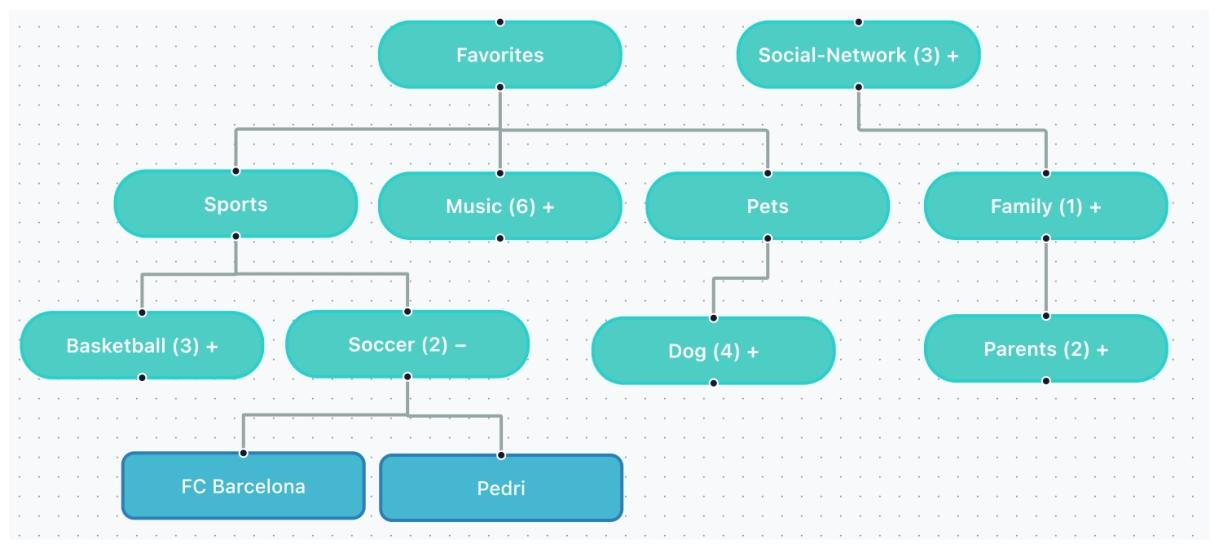
抽象知识与实体关系库,不依赖时间,记录 "世界是什么、谁是谁、什么是什么"。
存储内容
- 概念、名词、实体、人物、关系
- 用户的社交网络、偏好分类、常识
- 结构化树形知识(论文图示:社交、喜好、运动、宠物...)
标准字段
- name:实体 / 概念名
- summary:定义或关系简述
- details:背景、详情、解释
- source:来源(用户提供 / 推理 / 外部知识)
设计意图
- 脱离具体事件,做长期抽象推理
- 构建用户的知识图谱
- 支持关联问答、分类检索
典型示例
- 实体:Harry Potter
- 关系:作者 J.K. Rowling
- 人物:用户朋友 John,住旧金山,喜欢慢跑
Procedural Memory(过程记忆)
技能库 + 操作手册 ,记录 "怎么做某事",是智能体的肌肉记忆。
存储内容
- 步骤化指南、工作流、操作流程
- 可复现的任务脚本
- 用户教会智能体的所有 "技能"
标准字段
- entry_type:类型(workflow /guide/script)
- description:目标 / 功能描述
- steps:步骤列表(可结构化 JSON)
设计意图
- 让智能体学会技能、长期保留
- 支持任务自动化、分步执行
- 不用每次重新理解流程
典型示例
- Git 提交推送步骤
- 报销流程
- 预约餐厅步骤
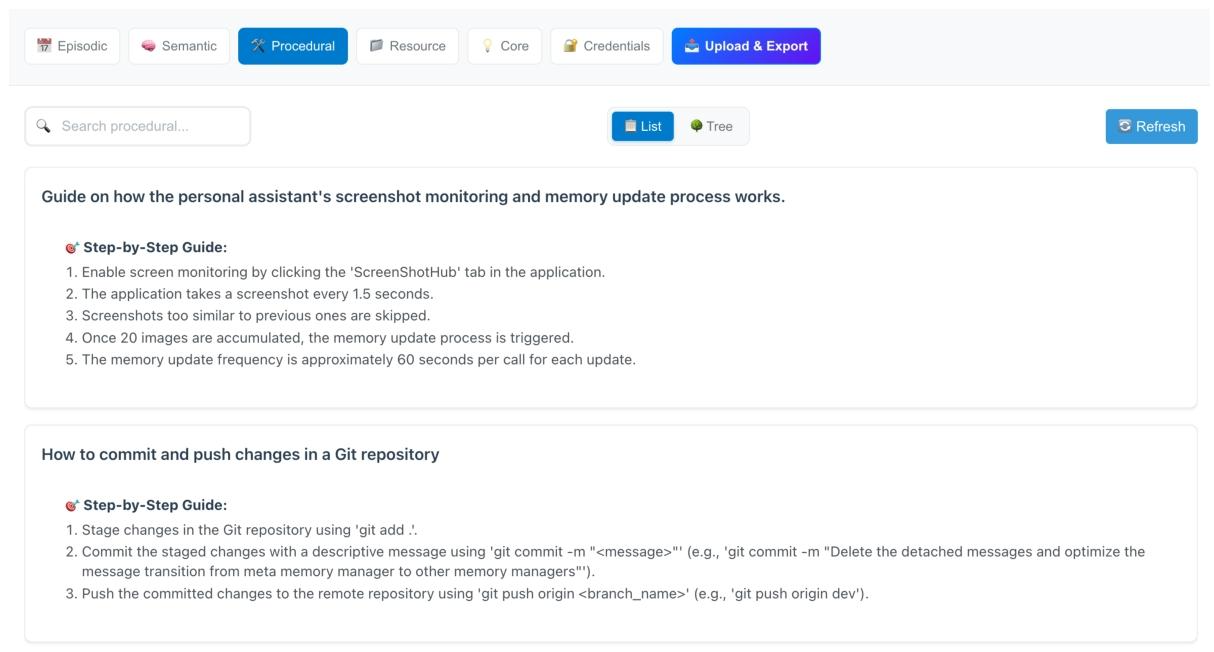
- 截图监控与记忆更新流程
Resource Memory(资源记忆)
用户正在使用的文档与多模态素材库,存 "完整原文 / 文件 / 素材"。
存储内容
- 文档、笔记、演讲稿、长文本
- 图片、音频转录、视频摘要等多模态资源
- 不属于其他 5 类,但需要完整保留的内容
标准字段
- title:资源标题
- summary:内容概述
- resource_type:类型(doc /pdf/image /voice)
- content:内容或片段
设计意图
- 保证长任务上下文不中断
- 支持原文引用、内容检索
- 多模态内容统一托管
典型示例
- 用户正在读的论文全文
- 项目计划书
- 活动方案
- 截图里的关键界面文本
Knowledge Vault(知识金库)
安全私密存储,专门存 "必须一字不差、高敏感" 的信息。
存储内容
- 密码、账号、API Key
- 电话、地址、邮箱、证件信息
- 任何需要原封不动保存的私密数据
标准字段
- entry_type:类型(凭证 / 联系人 / 地址 / 密钥)
- source:来源
- sensitivity:敏感度(低 / 中 / 高)
- secret_value:真实密文
设计意图
- 安全第一,高敏感信息独立隔离
- 不参与普通闲聊检索
- 权限控制、防止泄露
典型示例
- 用户手机号:138xxxxxxx
- 邮箱:xxx@xxx.com
- 家庭地址
- 服务器密钥
4.2.检索设计
主动召回机制(Active Retrieval)
解决传统 "不主动搜就忘" 的问题:
- 用户输入 → 先生成当前主题
- 按主题从 6 类记忆召回 Top-K
- 按来源标记(<semantic>...</semantic>)注入系统提示
- 支持多种召回:embedding /bm25 /string_match
优势:无需用户手动说 "搜索记忆",自动关联历史。
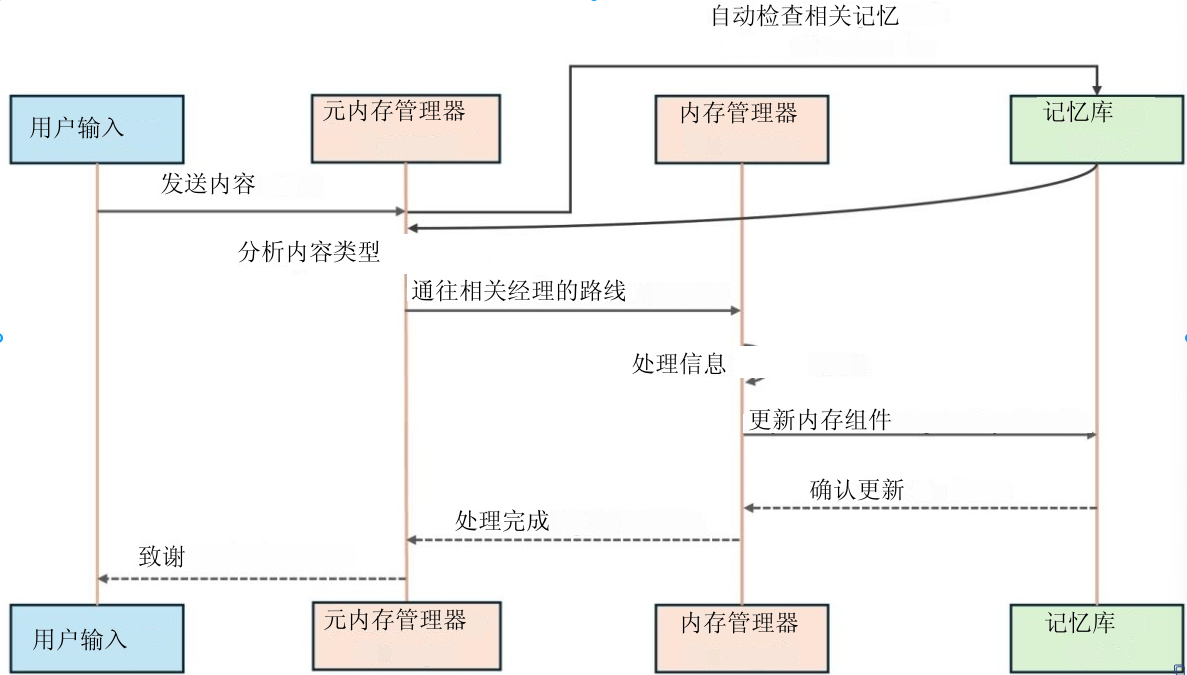
4.3.多智能体工作流
架构:1 个元记忆管理器 + 6 个记忆管理器 + 1 个对话智能体
(1)记忆更新流程
- 用户输入 → 自动检索已有记忆
- 元记忆管理器分析内容类型
- 路由到对应记忆管理器
- 并行更新、去重
- 返回确认
(2)对话应答流程
- 用户查询 → 全记忆库粗召回
- 对话智能体分析查询 → 精召回对应记忆
- 融合信息 → 生成回答
- 如需更新,直接调用对应记忆管理器
5.实验
| 基准 | 数据来源 | 任务特点 | 评估指标 |
|---|---|---|---|
| ScreenshotVQA | 3 位博士生 1 个月电脑截图(5k--2w 张) | 多模态、长时序、真实行为 | 精度、存储大小 |
| LOCOMO | 10 轮长对话,每轮 600 轮、26k token | 单跳 / 多跳 / 时序 / 开放域 | LLM-as-a-Judge 精度 |
模型配置
- ScreenshotVQA:gemini-2.5-flash
- LOCOMO:gpt-4.1-mini(强函数调用)
- 评判:GPT-4.1 作为裁判
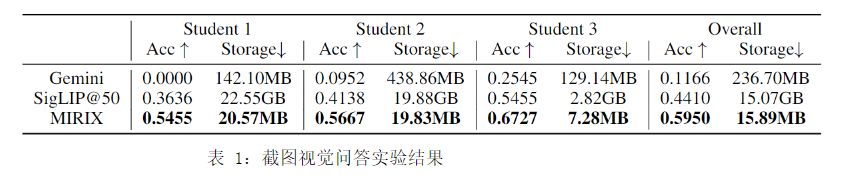
5.1.ScreenshotVQA实验
一、实验定位与目标
ScreenshotVQA 是全球第一个面向 LLM 智能体的「长时序、高分辨率、真实用户行为」多模态记忆基准。
- 目标:验证 MIRIX 能否从海量屏幕截图中构建记忆,并准确回答用户行为问题。
- 核心挑战:图片极多、分辨率极高、时间跨度长、现有记忆系统无法处理。
二、数据集构建全过程(论文完整步骤)
1. 数据采集对象
3 位真实用户:2 位计算机博士 + 1 位物理博士,正常使用电脑。
2. 采集工具与频率
- 自定义脚本:每秒自动截 1 张屏
- 去重策略:若与上一张相似度 > 0.99,丢弃当前图
- 采集时长:1 周~1 个月
- 分辨率:用户原生显示器分辨率 2K~4K
3. 最终数据规模
| 用户 | 使用强度 | 图片数量 | 时间跨度 |
|---|---|---|---|
| 用户 1 | 重度 | 5,886 张 | 1 天 |
| 用户 2 | 中度 | 18,178 张 | 20 天 |
| 用户 3 | 轻度 | 5,349 张 | 1 个多月 |
4. 问题构建
- 让用户根据自己的屏幕行为手动出题
- 题目必须只能通过记忆历史行为回答
- 总题目数:11 + 21 + 55 = 87 题
- 题型:用户做过什么项目、看过什么文档、打开过什么页面等。
三、MIRIX 在 ScreenshotVQA 上的具体实现流程
阶段 1:屏幕截图流式处理(论文 2.1 节)
- 每 1.5s 捕获 1 张截图,实时去重
- 收集 20 张不重复截图 触发一次记忆更新(约 60 秒)
- 流式上传:不等待 20 张攒齐,抓到一张传一张
- 调用 Gemini API 解析图片内容(文本、界面、操作、任务)
关键优化:用 Gemini Cloud URL 加载图片 → 端到端延迟从 50s → <5s
阶段 2:多模态信息抽取 → 写入六大记忆
MIRIX 从截图中提取信息,并自动路由到 6 大记忆组件:
- Core Memory用户身份、常用软件、长期偏好
- Episodic Memory什么时间、打开了什么、做了什么操作(时序事件)
- Semantic Memory项目名称、文档标题、软件功能、人物 / 概念
- Procedural Memory用户重复的操作流程(Git、部署、打开软件步骤)
- Resource Memory文档全文、界面关键内容、长文本
- Knowledge Vault邮箱、路径、密钥等敏感信息(若出现)
阶段 3:推理问答流程(用户提问 → 记忆召回 → 回答)
- 用户提出行为问题(如:我最近在做什么项目?)
- Active Retrieval 自动生成主题,并行检索 6 类记忆
- 召回相关事件、语义、资源记忆
- 融合信息,用自然语言给出答案
- 全程不依赖原始图片,只使用结构化记忆
基线 1:Gemini 长上下文模型(Long-Context Baseline)
- 把所有截图缩放到 256×256
- 一次性塞进 Prompt,最多塞约 3,600 张
- 直接让模型看图回答
- 存储:所有缩放后图片总大小
缺陷:图片太多、分辨率太低、模型记不住时序。
基线 2:SigLIP + Gemini(RAG 基线)
- 用 SigLIP 对所有截图做向量检索
- 用户问题 → 检索 Top 50 相关截图
- 把 50 张图给 Gemini 生成答案
- 存储:所有原始 2K~4K 高清图
缺陷:存储爆炸、检索不准、无记忆抽象。
五、评估指标与计算方式
1. 准确率(Accuracy)
- 用 GPT-4.1 作为裁判(LLM-as-a-Judge)
- 输入:问题 + 标准答案 + 模型回答
- 输出:是否正确(0/1)
- 最终:三人平均准确率
2. 存储占用(Storage)
- Gemini:缩放后图片总大小
- SigLIP:原始高清图总大小
- MIRIX:sqlite .db 文件大小(仅存结构化记忆)
5.2.LOCOMO 实验
LOCOMO = Long-term Conversational Memory
- 用途:专门评测 LLM Agent 长期对话记忆能力的权威基准
- 目标:验证 MIRIX 在纯文本长对话中,能否把关键信息蒸馏、路由、存储并精准召回
- 核心约束:只能用记忆回答,不能看原始对话
1. 基本统计
- 对话数量:10 轮长对话
- 每轮对话:约 600 轮交互 、平均 26k token(论文原文)
- 会话分布:跨多天、多段会话,模拟真实长期聊天
- 总问题数:约 2000 题,覆盖 4 类核心题型(排除对抗题)
2. 问题类型(MIRIX 实验用这 4 类)
| 题型 | 含义 | 例子 |
|---|---|---|
| Single-hop 单跳 | 单点事实查找 | 某人的家乡是哪里? |
| Multi-hop 多跳 | 跨会话信息融合 | 4 年前她从哪里搬来? |
| Temporal 时序 | 时间 / 先后推理 | 什么时候去露营? |
| Open-domain 开放域 | 常识 + 对话结合 | 如果去旅行会带什么? |
Adversarial(不可回答):MIRIX 实验按惯例排除不计分。
三、MIRIX LOCOMO 实验完整流程
阶段 1:统一实验设定(保证公平)
- 所有方法 ** backbone 统一为 gpt-4.1-mini**
- 理由:函数调用能力最强,Berkeley 榜单得分更高
- 严格约束:只能用记忆系统召回的信息答题,禁止访问原始对话
- 评估器:GPT-4.1 作为 LLM-as-a-Judge,输出 0/1 对错
阶段 2:对话→记忆写入流程
- 逐句读入 LOCOMO 长对话
- Meta Memory Manager 分析内容类型
- 自动路由到 6 大记忆组件:
- Core:人物身份、固定偏好
- Episodic:带时间戳的事件
- Semantic:人物关系、地点、概念
- Procedural:计划、流程
- Resource:长文本、关键段落
- Knowledge Vault:电话、地址等敏感信息
- 去重、结构化、持久化到数据库
阶段 3:问答→记忆召回流程
- 用户问题输入
- Active Retrieval:先提取主题
- 并行检索 6 大记忆,取 Top-K
- 按来源标记(<core>/<episodic>...)注入 Prompt
- 模型只基于召回的记忆生成答案
- GPT-4.1 打分
四、基线模型与实现方式(MIRIX 论文官方)
| 基线 | 类型 | 实现要点 |
|---|---|---|
| A-Mem | 知识图谱记忆 | Zettelkasten 笔记式图谱 |
| LangMem | LangChain 长记忆 | 事实抽取 + 向量检索 |
| Zep | 时序知识图谱 | 基于对话构建时序图 |
| Mem0 | 扁平压缩记忆 | 增量压缩、存储事实 |
| Memobase | 用户画像记忆 | 持久化属性偏好 |
| RAG-500 | 普通检索增强 | 分块、向量检索 Top 500 |
| Full-Context | 上限基线 | 直接把全部对话塞上下文 |
五、评分机制(LLM-as-a-Judge)
- 输入:Question + Ground Truth + Model Answer
- GPT-4.1 判断:完全正确 / 错误
- 计算每类题型正确率与整体平均
- MIRIX 运行 3 次取平均,保证稳定
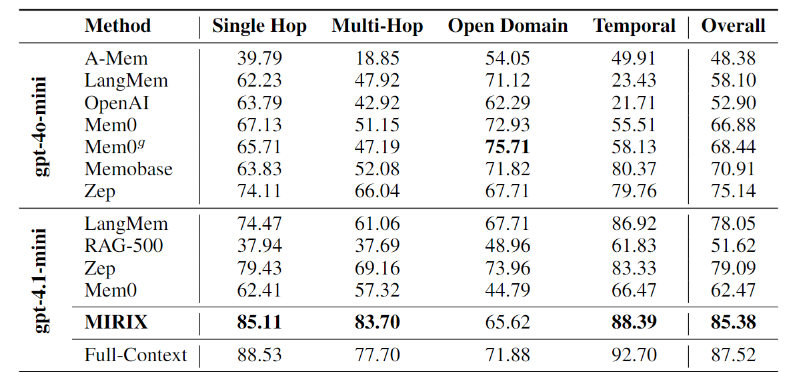
- 多跳提升最大:超基线 24%+,因 MIRIX 提前融合信息,无需实时拼接
- 时序 / 单跳极强:结构化存储带来精准召回
- 开放域略低:受 RAG 全局理解限制
- 存储效率:数量级下降
6.相关工作(Related Work)
| 研究方向 | 代表工作 | 核心局限 | MIRIX 优势 |
|---|---|---|---|
| 隐空间记忆 | Memory Transformer、M+ | 需重训、不兼容闭源模型 | 即插即用、无需训练 |
| 扁平文本记忆 | Mem0、MemGPT、Zep | 结构单一、模态单一 | 6 类记忆、多模态 |
| 单一认知记忆 | 情景 / 语义 / 过程记忆 | 不成完整系统 | 全认知架构 |
| 通用多智能体 | AutoGPT、MetaGPT | 无专用记忆协同 | 记忆专属多智能体 |