文章目录
- 摘要
- Abstract
- [一、《Filter, Correlate, Compress:Training-Free Token Reduction for MLLM Acceleration》](#一、《Filter, Correlate, Compress:Training-Free Token Reduction for MLLM Acceleration》)
-
- 1、摘要
- 2、主要贡献
- 3、相关工作
-
- 多模态大模型(MLLMs)
- [Token 缩减方法](#Token 缩减方法)
- 4、方法
-
- [4.1 第一步:筛选 ------ 哪些 token 应该被丢掉?](#4.1 第一步:筛选 —— 哪些 token 应该被丢掉?)
-
- [4.1.1 :在 FiCoCo‑V(视觉编码器)中](#4.1.1 :在 FiCoCo‑V(视觉编码器)中)
- [4.1.2 :在 FiCoCo‑L(语言模型)中](#4.1.2 :在 FiCoCo‑L(语言模型)中)
- [4.2 第二步:关联 ------ 被丢掉的 token 该把信息给谁?](#4.2 第二步:关联 —— 被丢掉的 token 该把信息给谁?)
- [4.3 第三步:压缩 ------ 如何融合信息而不稀释自身?](#4.3 第三步:压缩 —— 如何融合信息而不稀释自身?)
- 5、实验
-
- [5.1 实验设置](#5.1 实验设置)
- [5.2 主要结果(挑几个亮眼的)](#5.2 主要结果(挑几个亮眼的))
- [5.3 消融实验(验证每个设计的必要性)](#5.3 消融实验(验证每个设计的必要性))
- [5.4 可视化:直观感受信息回收](#5.4 可视化:直观感受信息回收)
- [5.5 效率分析](#5.5 效率分析)
- 6、总结
摘要
本周完成Glyph项目的复现,同时阅读论文《Filter, Correlate, Compress:
Training-Free Token Reduction for MLLM Acceleration》
Abstract
This week, I completed the reproduction of the Glyph project and read the paper Filter, Correlate, Compress: Training-Free Token Reduction for MLLM Acceleration.
一、《Filter, Correlate, Compress:Training-Free Token Reduction for MLLM Acceleration》
1、摘要
多模态大模型(MLLMs)在处理图片或视频时,会把图像切成很多小块(称为"视觉 token"),这些 token 的数量常常是文字 token 的几十倍甚至上百倍。模型在处理这么多 token 时,计算量会呈平方级增长,导致响应很慢,尤其是一开始"预填充"阶段特别耗时。
为了解决这个问题,论文设计了一个 "筛选 --- 关联 --- 压缩" 的三步框架,分为两个版本:
- FiCoCo‑V:在视觉编码器里做 token 缩减(只看图片内容,不管问题)
- FiCoCo‑L:在语言模型里做 token 缩减(结合问题来智能筛选)
实验证明,这套方法可以减少最高 14.7 倍的计算量 ,同时保留原来 93% 以上的回答准确率,而且不需要重新训练,拿来就能用。
2、主要贡献
- 首次提出"筛选---关联---压缩"三步走框架:系统性地、一步步地缩减视觉 token,而不是简单粗暴地丢弃。
- 设计了更聪明的冗余判断指标:同时考虑"视觉相似性"(容易被其他 token 预测的 token 就是冗余的)和"语义重要性"(跟图片整体含义关系不大的 token 就是冗余的)。
- 发明了信息回收机制 :被丢弃的 token 不是白白扔掉,而是把它携带的信息按相关性强弱转交给多个保留的 token,避免信息丢失。
- 自适应分配接收者数量:不再固定每个丢弃 token 合并到几个保留 token,而是根据相关性分布动态决定,更灵活。
- 两种版本适应不同场景:FiCoCo‑V 只看图片,适用于视频等冗余度高的任务;FiCoCo‑L 借助问题文本,更精准地保留任务相关信息。
- 效果惊人:在多个流行模型(LLaVA、Qwen2-VL、Video-LLaVA)上,大幅降低计算量,吞吐量提升 2 倍以上,准确率几乎不变。
3、相关工作
多模态大模型(MLLMs)
这类模型通常用一个视觉编码器(比如 CLIP 的 ViT)把图片变成一堆 token,再投影到语言模型里,和用户的文字指令一起生成回答。为了看得更清楚,新模型(如 LLaVA-NeXT)会使用更高分辨率的图片,导致视觉 token 数量暴涨,计算负担很重。
Token 缩减方法
之前的方法大致分两类:
- 需要训练的方法:训练一个模块来决定哪些 token 可以丢掉,效果好但成本高。
- 无需训练的方法(如 FastV、SparseVLM):直接在推理时根据注意力分数裁剪 token,简单但容易丢信息。
本文的方法属于无需训练,但比前人更细致:不只裁剪,还会回收信息;不只用一个指标,而是结合视觉和语义双重冗余度;不只固定合并数量,而是动态适应。
4、方法
4.1 第一步:筛选 ------ 哪些 token 应该被丢掉?
4.1.1 :在 FiCoCo‑V(视觉编码器)中
每个 token 会得到一个冗余分数,分数越高越容易被丢掉。这个分数由两部分组成:
-
视觉感知冗余
看一个 token 被其他视觉 token 关注的程度。如果大家都关注它(平均注意力高),说明它容易被其他 token 预测,信息是重复的,冗余度高。
通俗理解:大家都盯着你,说明你是"大众脸",丢掉你别人也能猜出你长啥样。
-
语义感知冗余
看图片的 CLS token(代表整体含义)对这个 token 的关注度。如果关注度很低,说明这个 token 跟图片整体语义关系不大,冗余度高。
通俗理解:图片整体在说"一只猫",但你是个"板凳",那你就不重要。
最后把这两个分数按一定比例(λ)加权相减,得到总冗余分。
另外还加了一个局部惩罚:把图片划成小窗口,不让所有高冗余 token 都挤在同一个窗口里被丢掉,避免关键区域的信息被一锅端。
4.1.2 :在 FiCoCo‑L(语言模型)中
除了上面两个指标,还引入 任务感知冗余:看每个视觉 token 被**文字 token(即用户的问题)**关注的多少。如果问题几乎不看它,那它对回答这个问题就没啥用,冗余度高。
通俗理解:你问"猫在哪儿",模型就会多关注猫所在的 token,那些无关的沙发、桌子自然就被筛掉了。
4.2 第二步:关联 ------ 被丢掉的 token 该把信息给谁?
筛选出一批要丢弃的 token(称为源集S)和保留的 token(目标集T )。现在问题来了:丢弃的 token 身上还有信息,不能直接扔,应该把它们"托付"给哪些保留的 token?
做法是构建一个相关性矩阵 C,大小为 源集S×目标集T。矩阵中第 i 行第 j 列的值表示:第 i 个丢弃 token 与第 j 个保留 token 的关联程度。
- 在 FiCoCo‑V 中,直接用自注意力权重作为相关性。
- 在 FiCoCo‑L 中,相关性由两部分组合:直接注意力 + 通过文本 token 的间接关系(比如两个视觉 token 都与同一个"猫"字有关,那它们之间也间接相关)。
补充:K 值是什么?为什么要自适应?
K 值表示每个丢弃 token 要分给几个保留 token 。以前的方法(如 ToMe)用固定的 K(比如 K=1 表示只给最相关的一个)。但论文发现不同情况下需要的 K 差别很大:有的丢弃 token 只有一个"铁哥们"保留 token,有的则有多个差不多的"好朋友"。
所以 FiCoCo 采用自适应 K :对每个丢弃 token,计算它那一行相关性分数的 ε 分位数(比如 ε=0.998),凡是大于这个阈值的保留 token 都会接收信息。K 就动态变成了 1、2 或更多。
4.3 第三步:压缩 ------ 如何融合信息而不稀释自身?
拿到了每个丢弃 token 要分发给哪些保留 token,以及各自的相关性权重,现在进行特征更新。
论文提出 "自保持压缩" 公式:
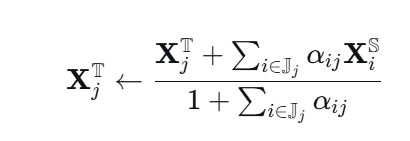
- 分子:保留 token 的原特征 + 所有关联丢弃 token 的加权特征
- 分母:1(代表自身权重) + 所有外来权重之和
这样保证了保留 token 自身的权重至少占 50%,不会被一堆外来信息"稀释"成四不像。同时,相关性越高的丢弃 token,贡献越大。
通俗理解:保留 token 就像一个小组长,它自己的意见占一半以上,再听取几个相关成员的附加意见,既吸收了大家的信息,又保持了自己的主导地位。
5、实验
5.1 实验设置
- 模型:LLaVA-1.5 (7B/13B)、LLaVA-NeXT-7B、Qwen2-VL-7B、Video-LLaVA
- 任务:图像问答(VQA、GQA、MMBench、POPE 等)、视频问答(TGIF、MSVD、ActivityNet)
- 对比方法:ToMe、FastV、SparseVLM、PDrop、PruMerge
- 硬件:单张 A800 80GB GPU
5.2 主要结果(挑几个亮眼的)
| 模型 | 压缩程度 | 准确率保留 | 速度提升 |
|---|---|---|---|
| LLaVA-1.5-7B | 计算量 ↓82.4% | 92.8% | 吞吐量 ↑43.5% |
| LLaVA-NeXT-7B | 计算量 ↓93.2% | 93.6% | 吞吐量 ↑107.9% |
| Qwen2-VL-7B | 视觉 token ↓54.5% | >98% | 超过 SparseVLM |
| Video-LLaVA | token ↓93.4% | >90% | 超过 FastV |
结论:FiCoCo 在几乎所有任务和模型上都优于现有的无需训练的方法,尤其在极端压缩下优势更明显。
5.3 消融实验(验证每个设计的必要性)
- 双重冗余:两个指标缺一不可,语义冗余贡献更大。
- 局部惩罚:能提升 FiCoCo‑V 的效果,但在 FiCoCo‑L 中会干扰任务先验,所以去掉。
- 自适应 K:比固定 K=0/1/2 都好,甚至比 K=0(即直接剪枝)还好。
- 自保持压缩:比简单平均效果更好,证明权重调节有效。
5.4 可视化:直观感受信息回收
论文展示了两个例子:
- 一个存放"2"这个答案的 token 被标记为红色(将要丢弃),它的信息根据相关性被分散到了多个绿色 token 中。这些绿色 token 最终帮助模型正确回答"有几个物体?"
- 另一个例子中,"GAMES"这个答案的信息也类似地被回收。
5.5 效率分析
- 理论计算:FiCoCo 引入的额外计算量是线性 增长,而节省的注意力计算是平方级下降,所以净收益巨大。
- 实际测试:LLaVA-NeXT 的 TFLOPs 从 42.7 降到 2.9(下降 93%),吞吐量从 3.8 img/s 升到 7.9 img/s(提升 108%)。
6、总结
这篇论文提出了一套优雅的、无需训练的 token 缩减框架,通过 筛选(谁该丢)--- 关联(丢给谁)--- 压缩(怎么融合) 三个步骤,在不重新训练模型的前提下,显著加速多模态大模型的推理,同时通过信息回收机制保证了生成质量。方法在多种模型和任务上表现出色,具有很强的实用价值。