1 线性表
1.1 循环链表
1.1.1 循环链表的概念
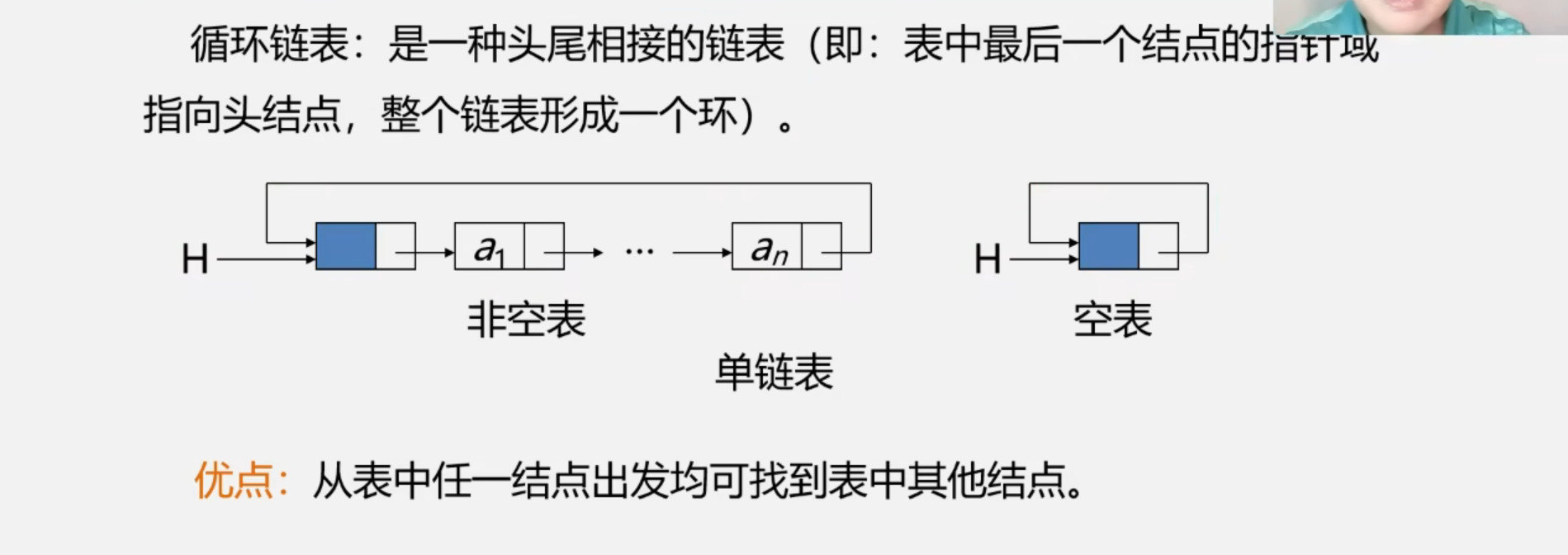
如何判断已经到了最后一个结点?

1.1.2 循环链表的时间复杂度
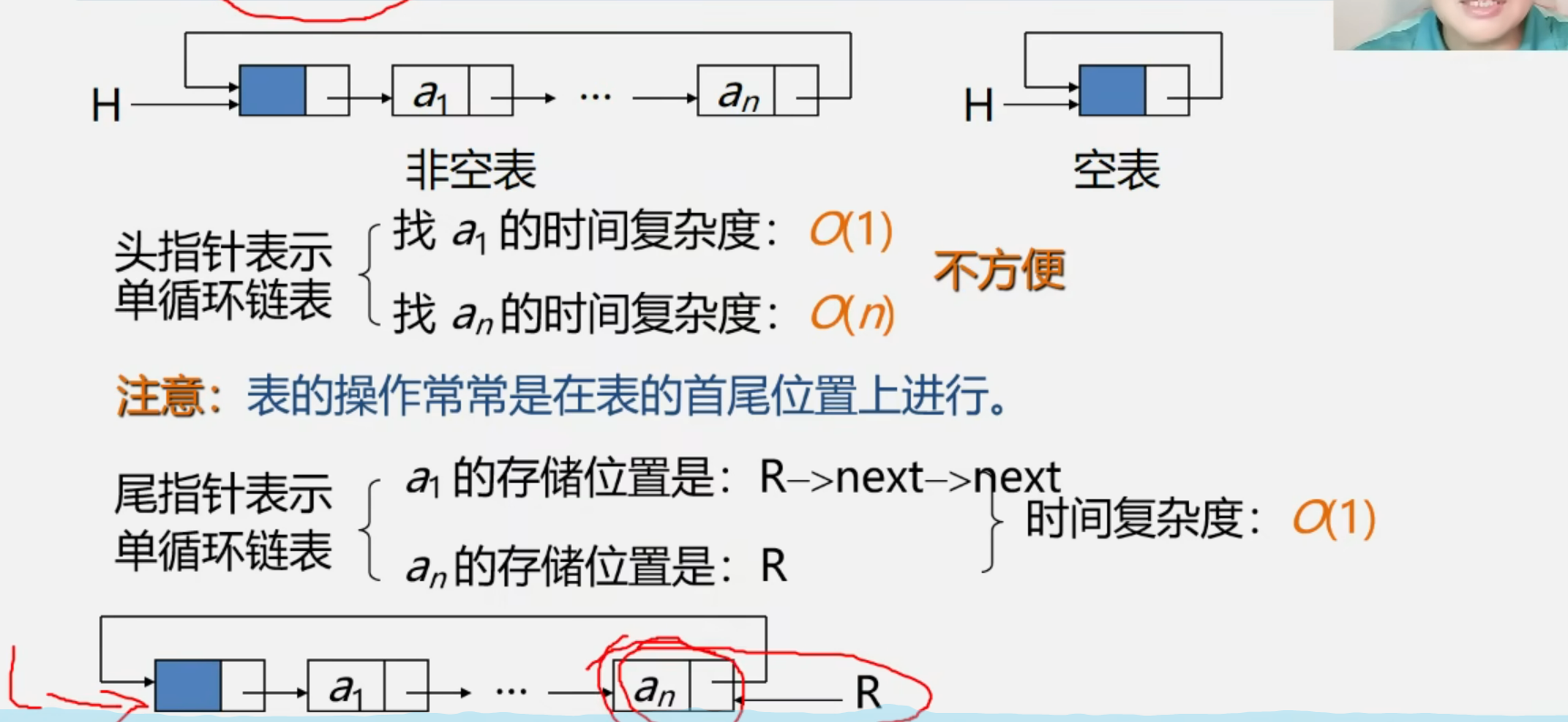
(1)头指针找 a_1 的时间复杂度:O(1)
头指针 head 本身就存储了 a_1 的地址,不需要遍历任何结点,直接就能访问到 a_1。
-
操作: head 就是 a_1 的指针,一步就能拿到。
-
时间复杂度:常数级,记为 O(1)。
(2)头指针找 a_n 的时间复杂度:O(n)
a_n 是尾结点,它的 next 指针指向 a_1(也就是 head )。
要找到 a_n,必须从 head 出发,逐个遍历链表的每个结点,直到某个结点的 next == head ,这个结点就是 a_n。
-
最坏情况:需要遍历链表中全部 n 个结点。
-
时间复杂度:线性级,记为 O(n)。
(3)尾指针找 a_n的时间复杂度
-
存储位置:R(尾指针本身就直接指向 a_n)
-
操作:一步就能访问到,不需要遍历
-
时间复杂度:{O(1)}(常数时间)
(2)尾指针找 a_1的时间复杂度
-
存储位置:R ---> next --->next
-
拆解:R --->next 是头结点(蓝色块),头结点的 next 就是首元结点 a_1
-
操作:只需要2次指针跳转,不需要遍历链表
-
时间复杂度:{O(1)}(常数时间)
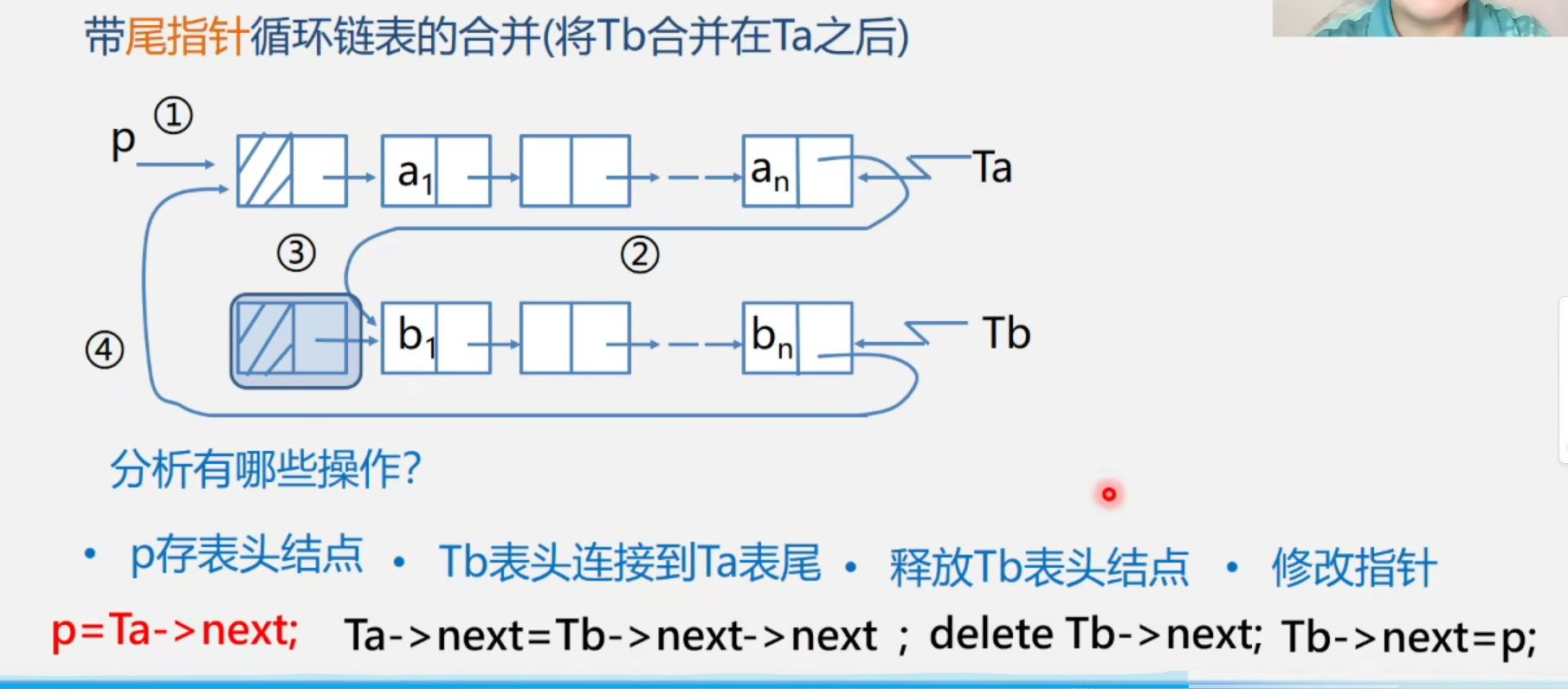
1.1.3 带尾指针循环链表的合并(将Tb合并在Ta后)

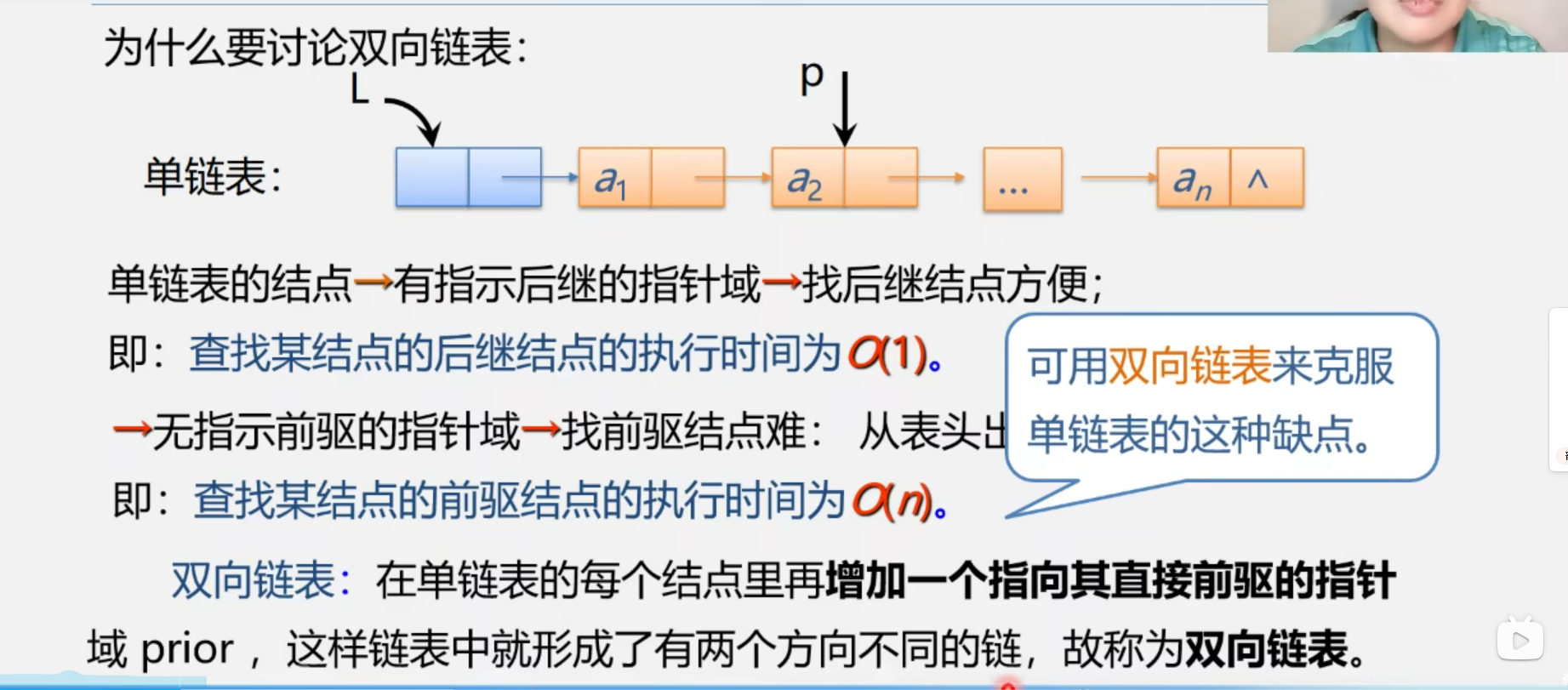
1.2 双向链表
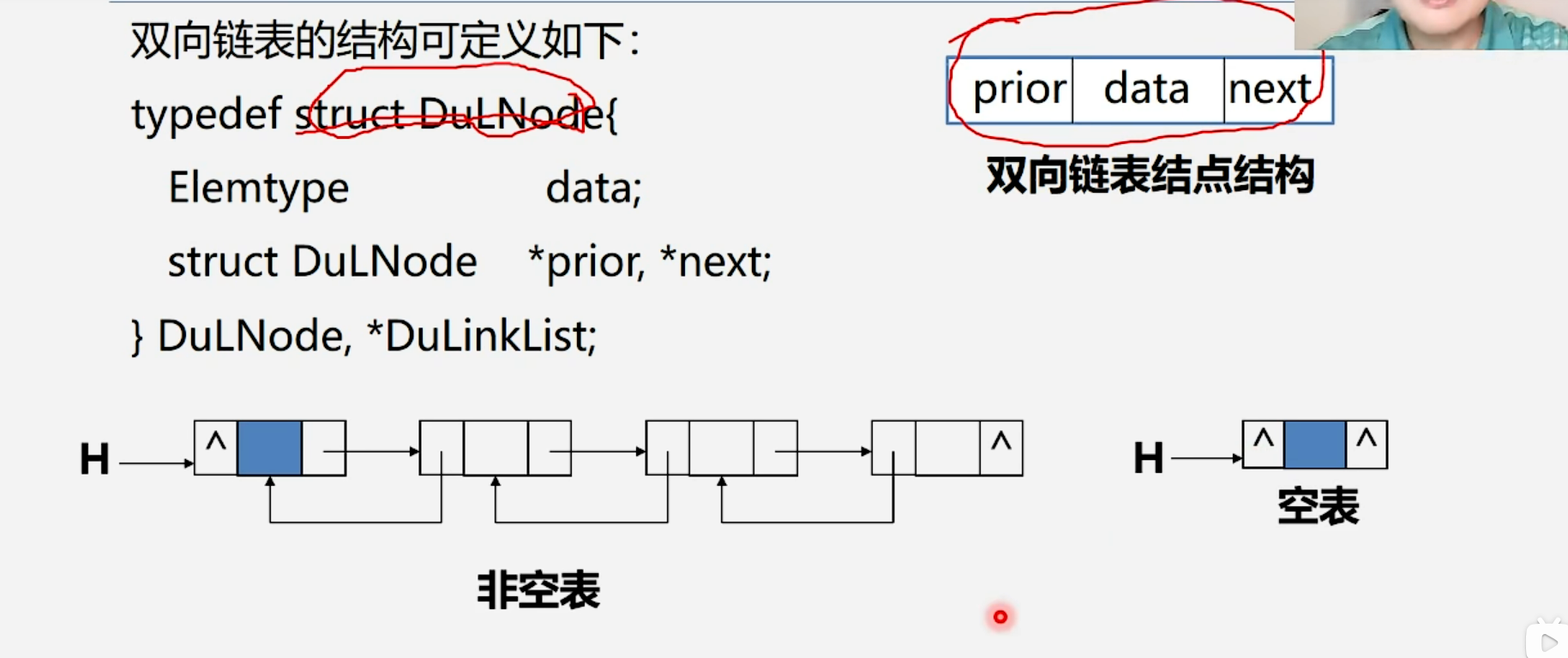
1.2.1 双向链表的概念
代码表示如下:
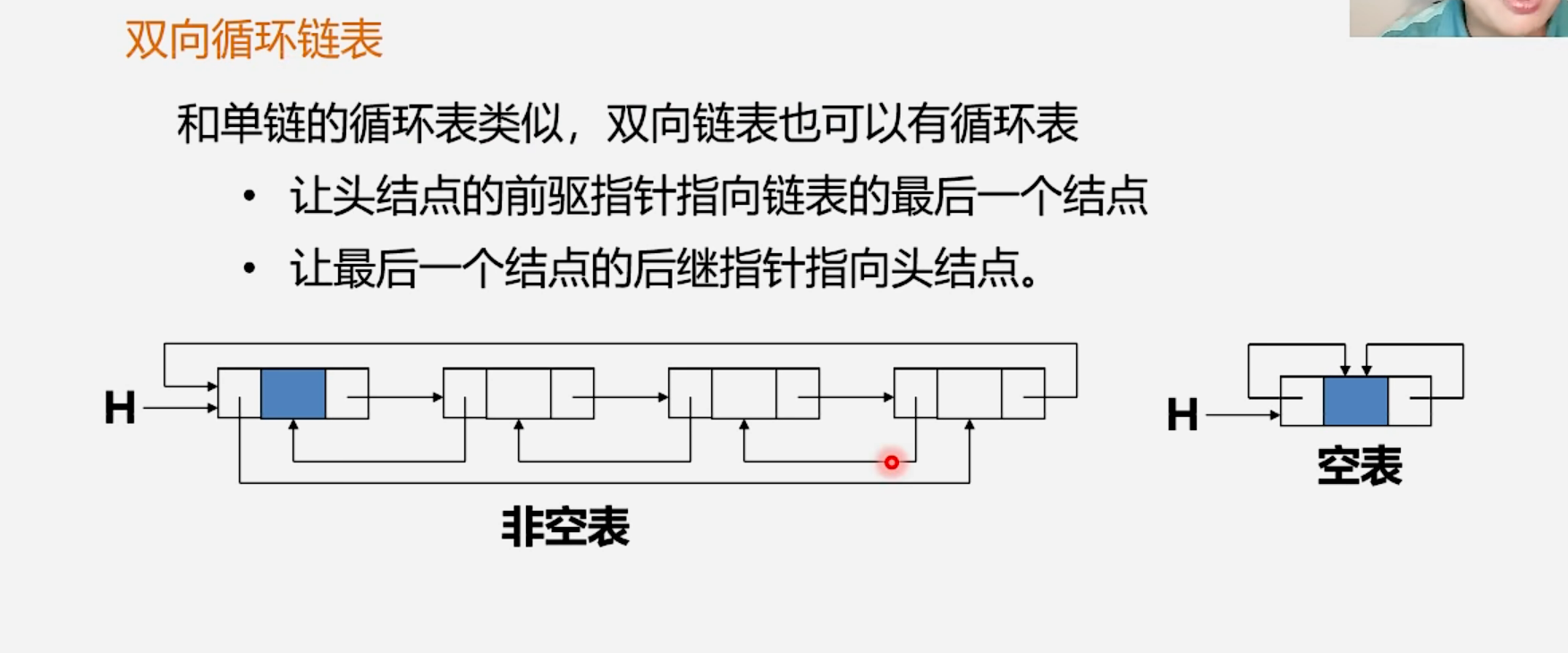
1.2.2 双向循环链表
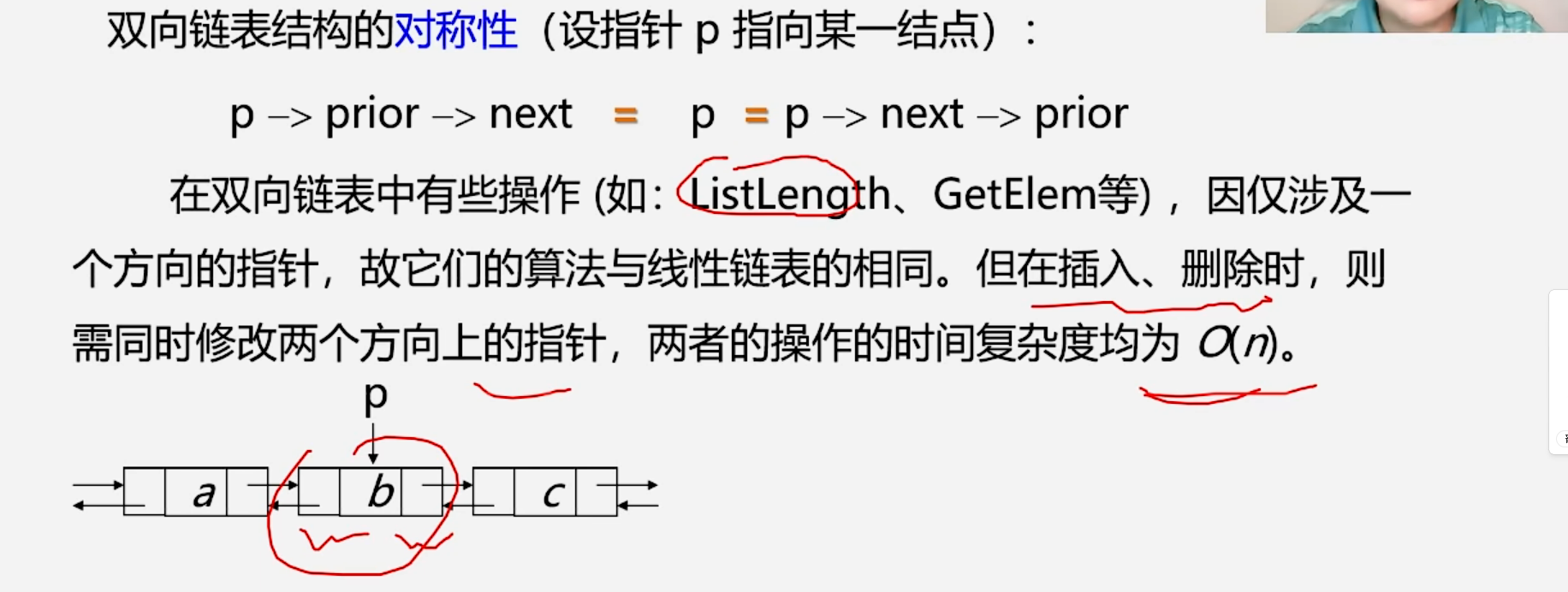
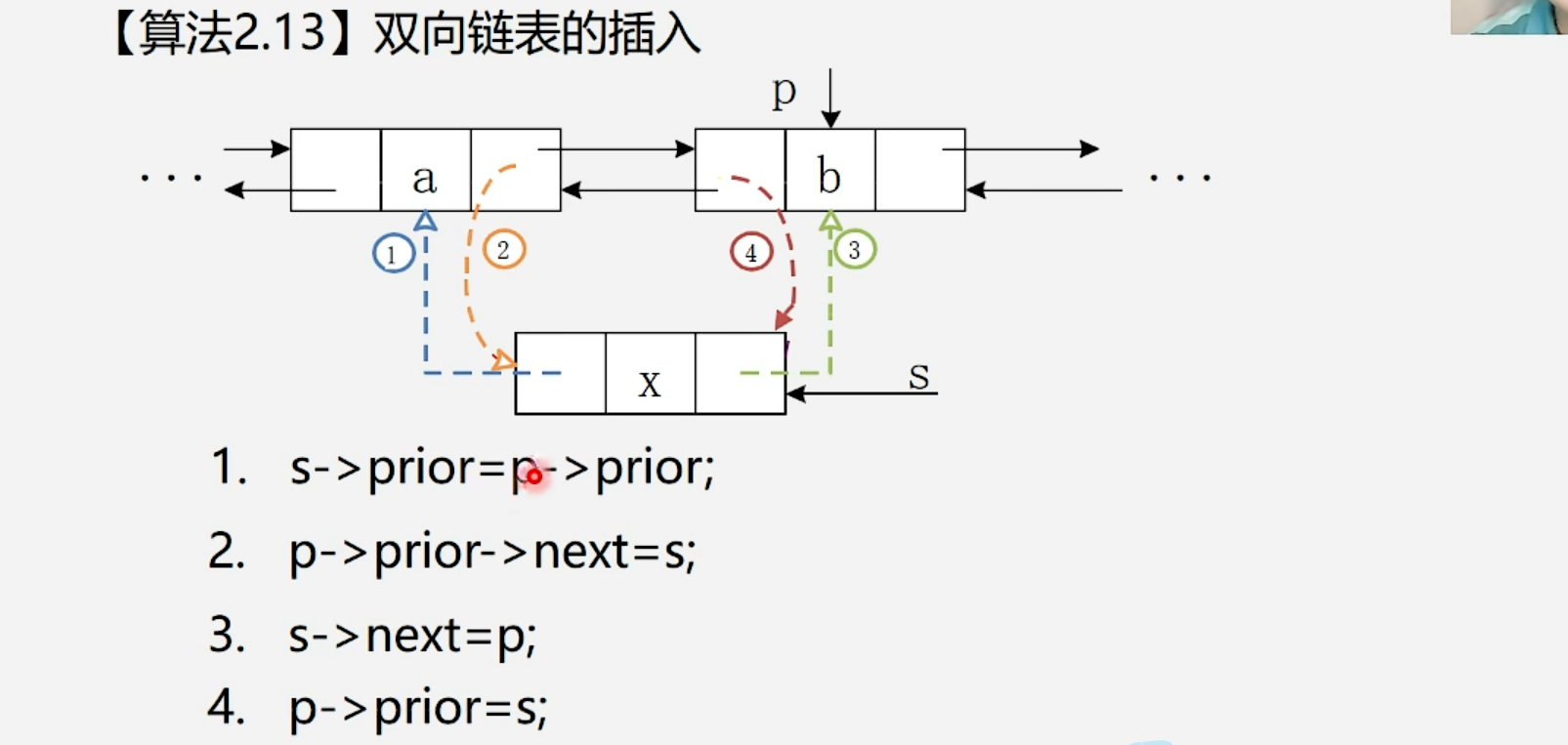
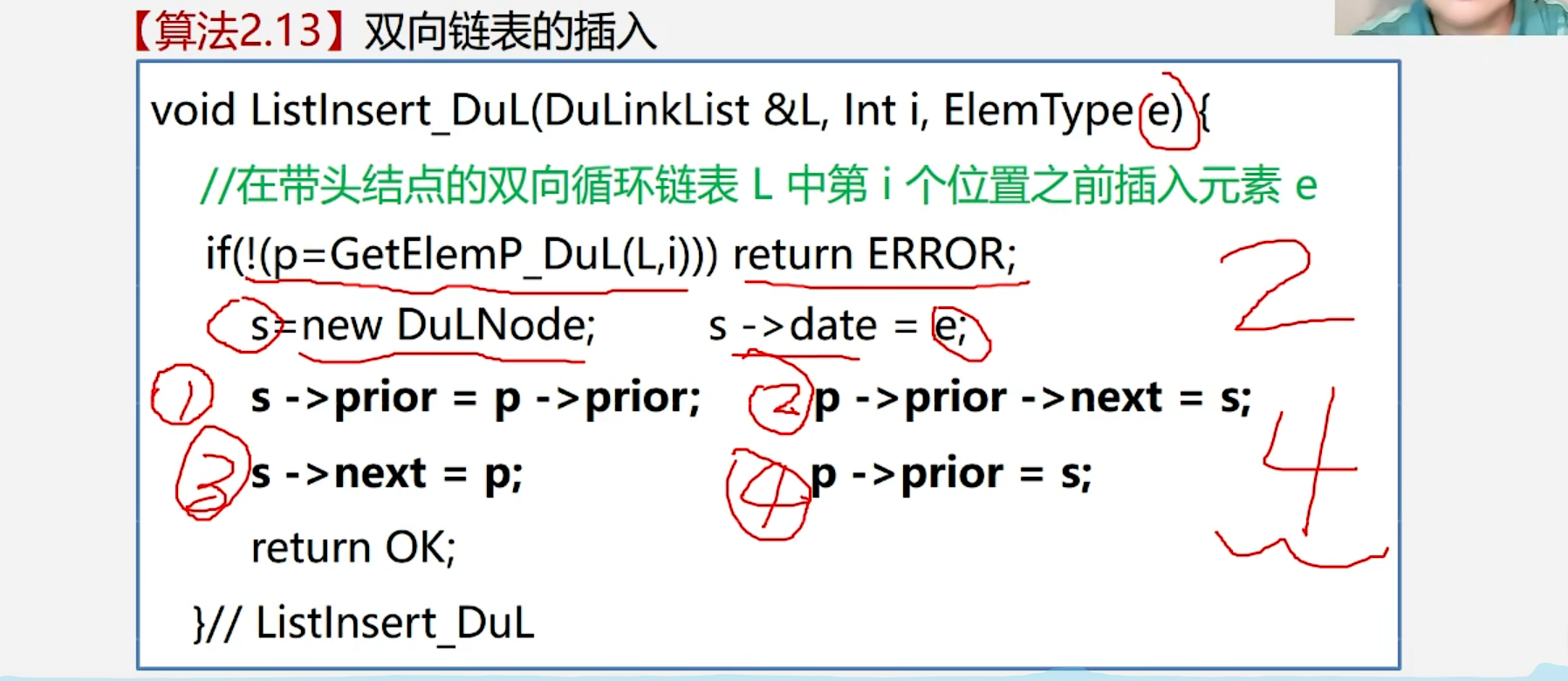
1.2.3 双向链表的插入
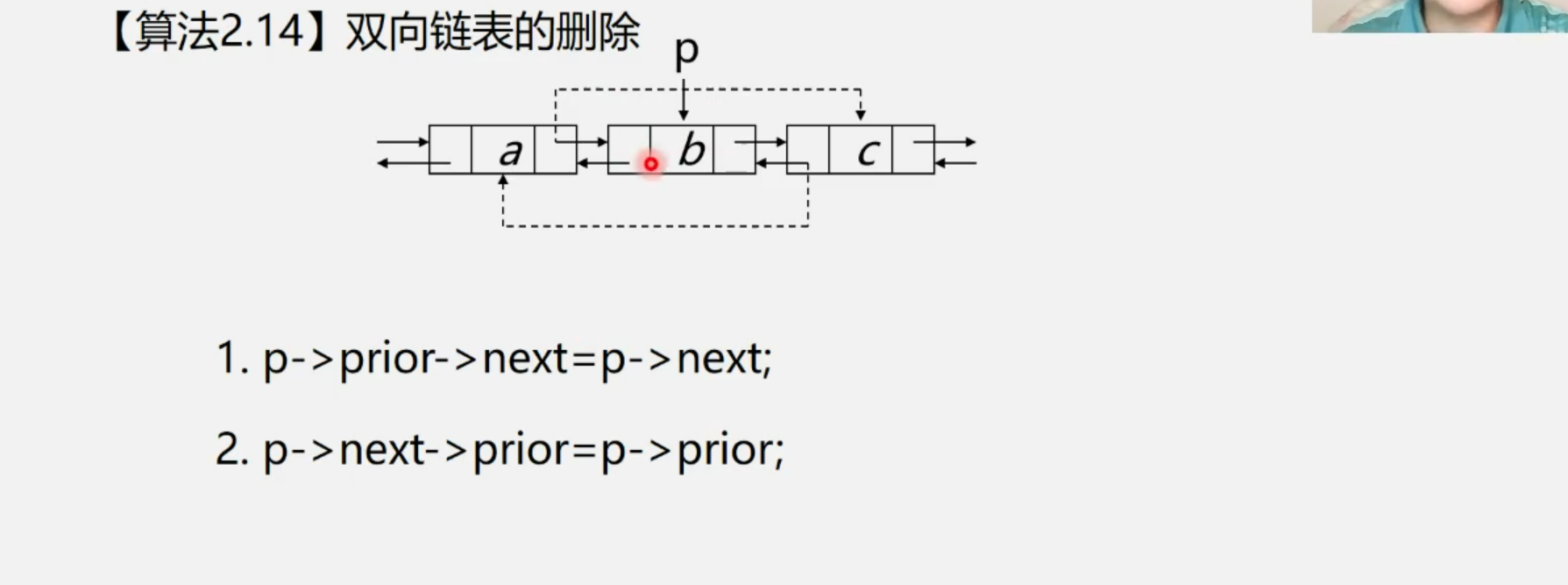
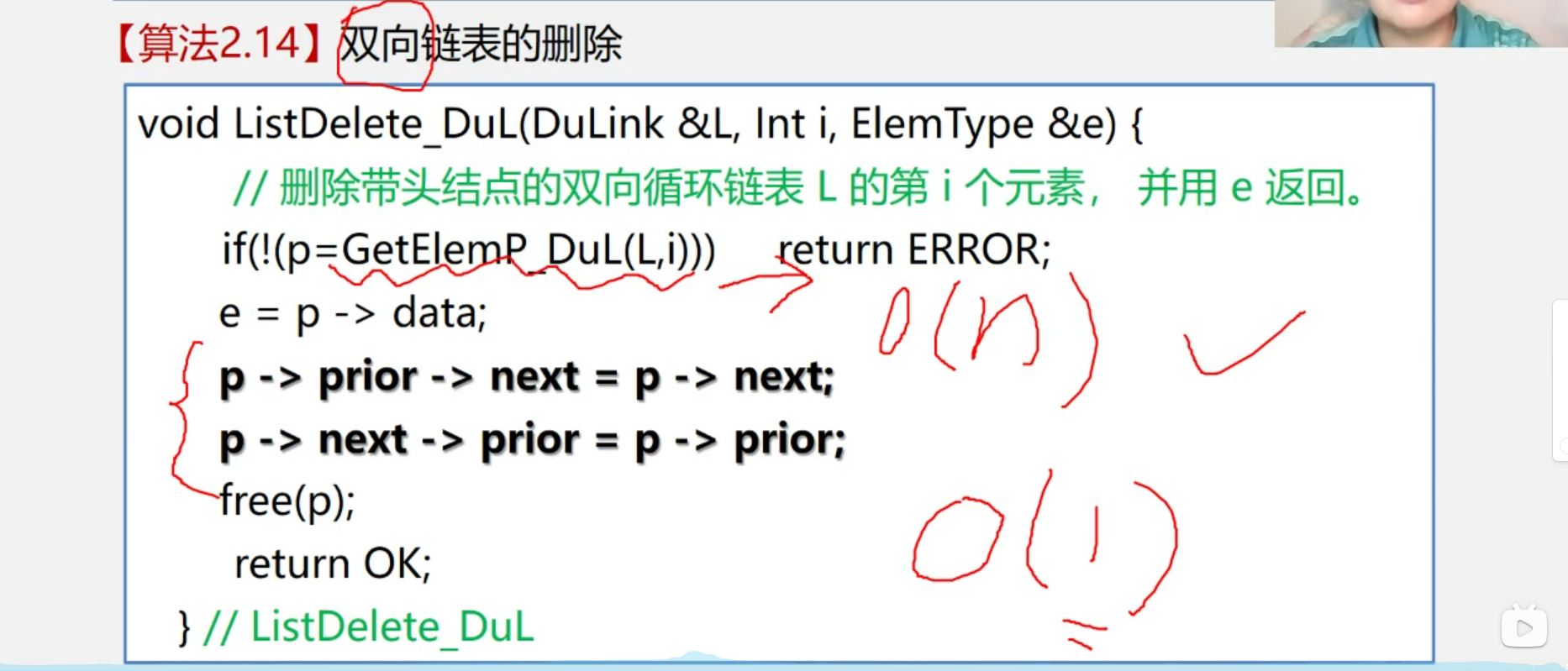
1.2.4 双向链表的删除
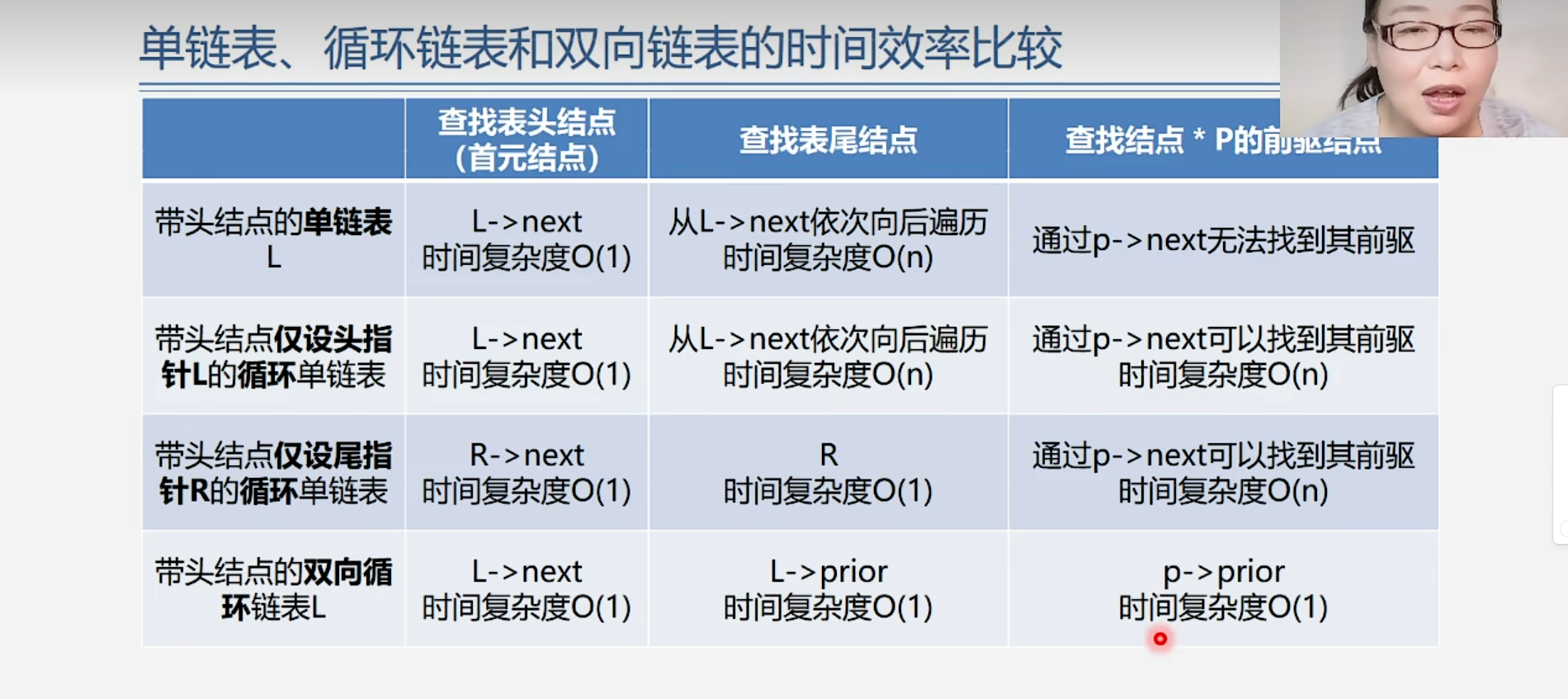
1.2.5 单链表、循环链表和双向链表的时间效率比较
1.3 顺序表和链表的比较
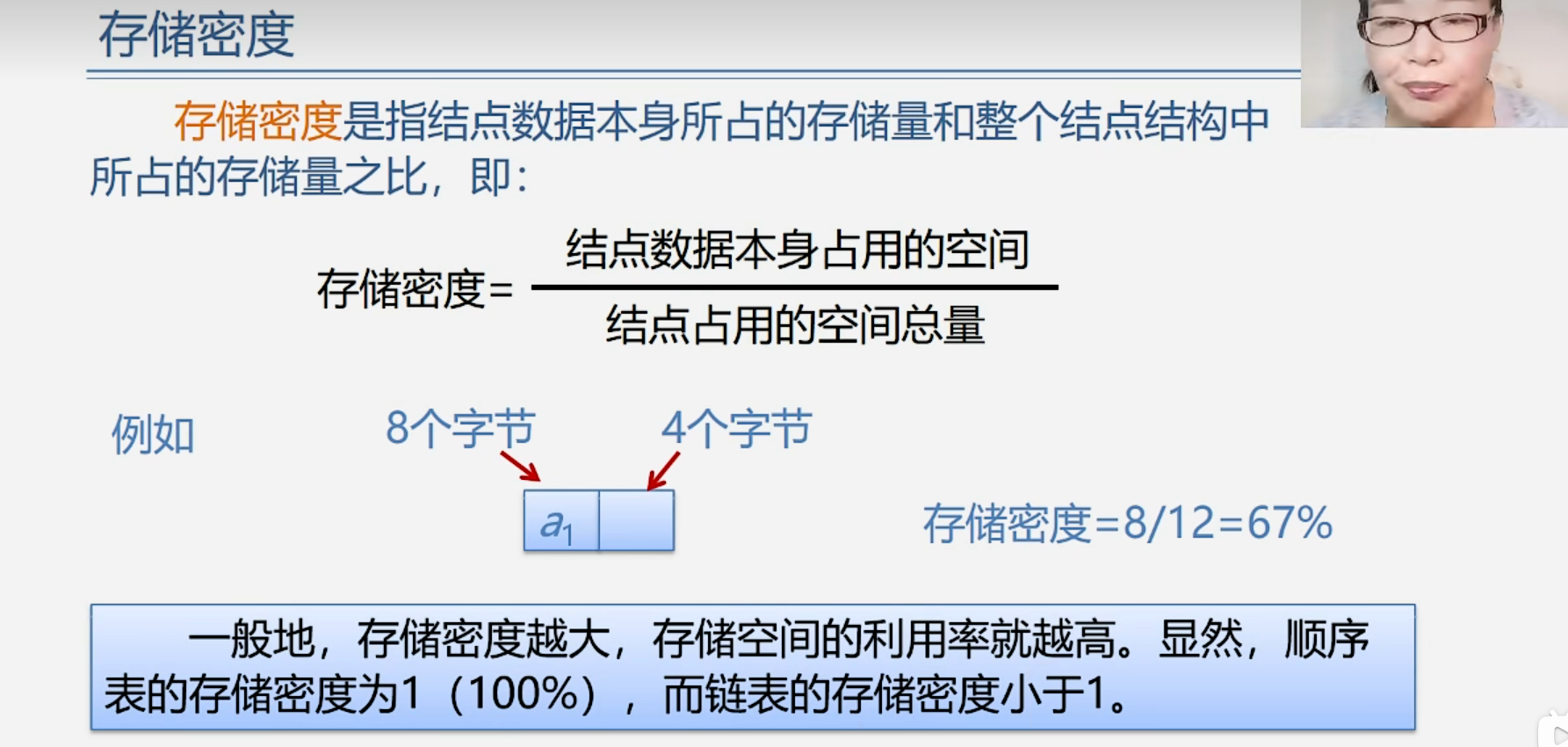
1.3.1 存储密度
1.3.2 链式存储结构的优缺点

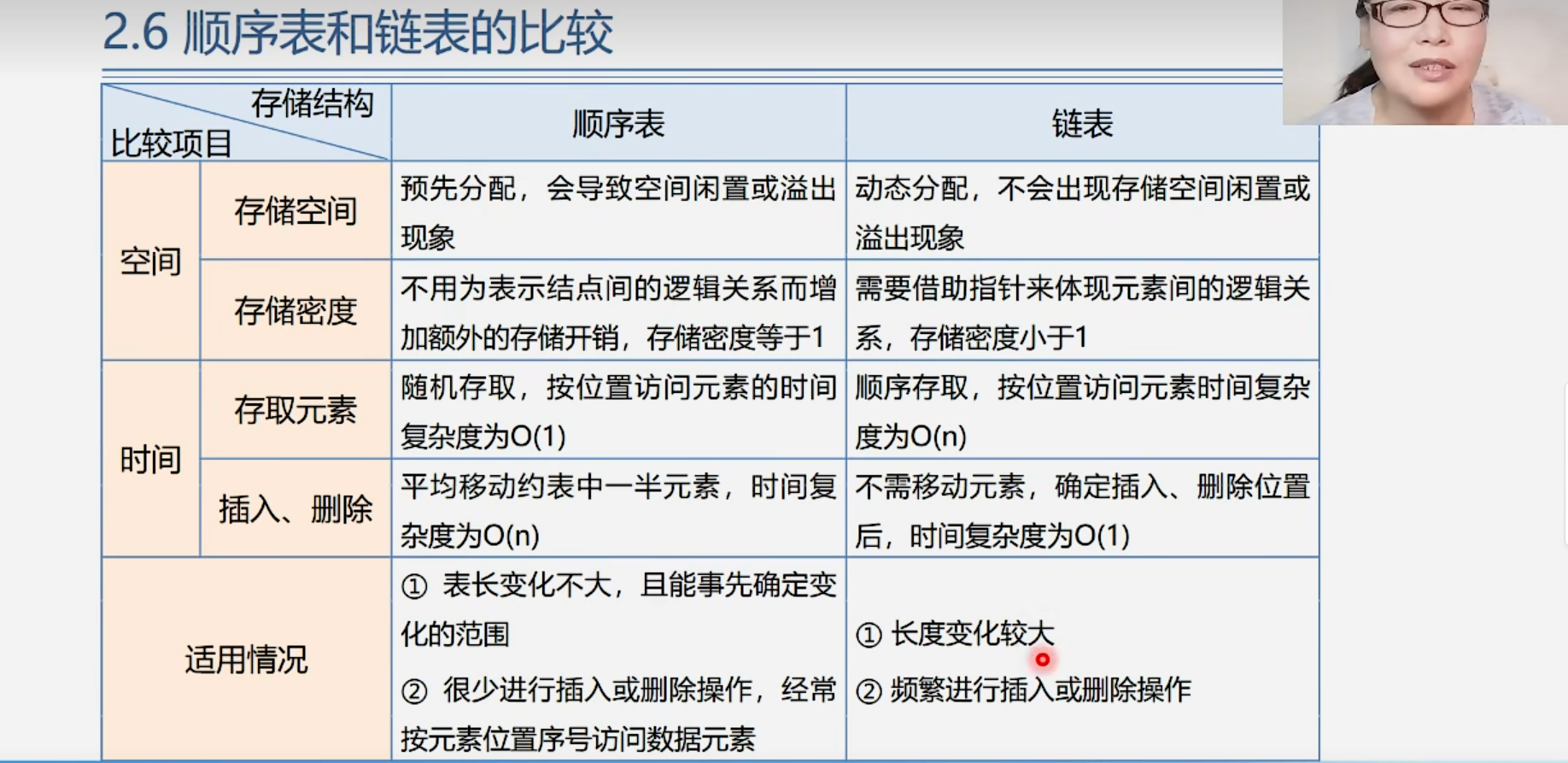
1.3.3 顺序表和链表的比较
1.4 线性表的应用
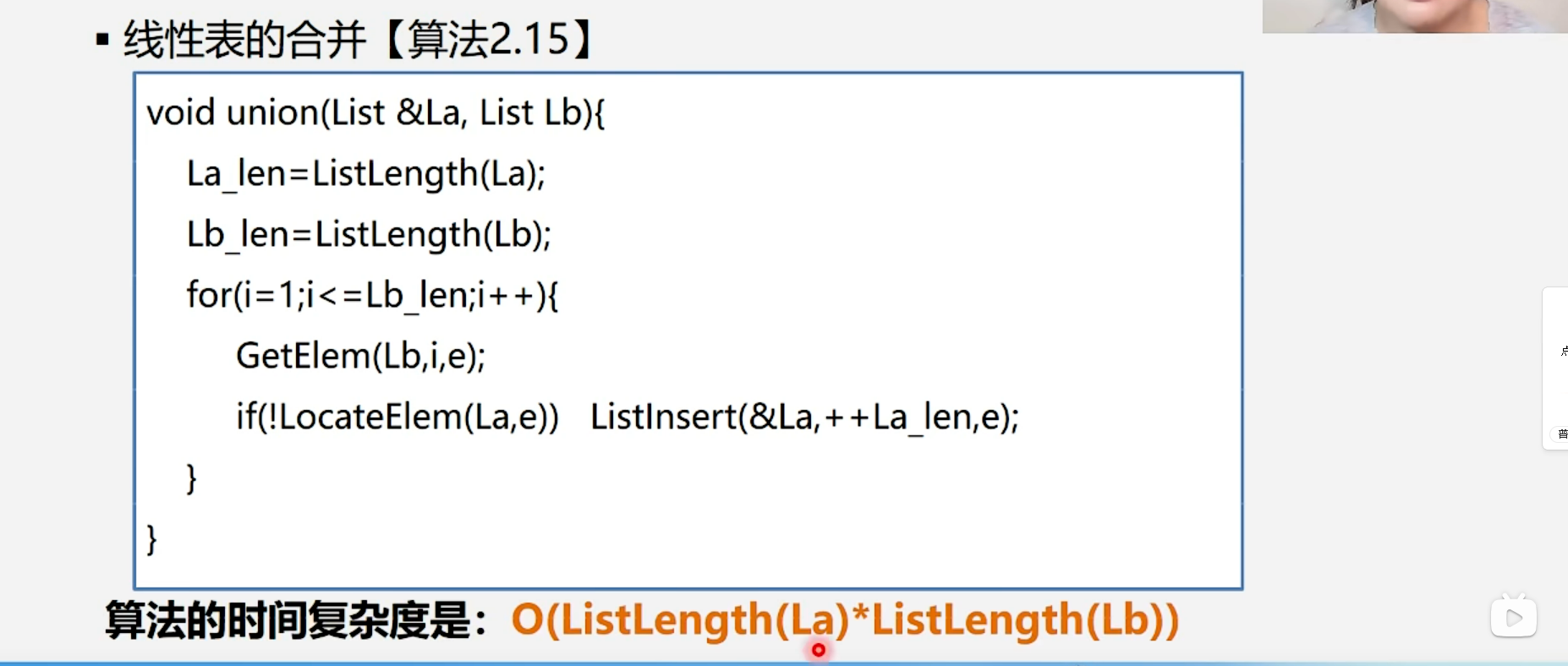
1.4.1 线性表的合并

算法步骤:
注意:
-
La要被修改(插入元素) → 必须传引用 &La ,才能让修改生效到原表。
-
Lb只被读取(查元素) → 传值 List Lb 就够了,原表不会被改动。
-
GetElem :拿元素(从Lb里把元素一个个取出来)
-
LocateElem :查元素(看看La里有没有这个元素)
-
ListInsert :插元素(如果没有,就把元素加到La的最后)
1.4.2 有序表的合并------用顺序表实现

算法思路:
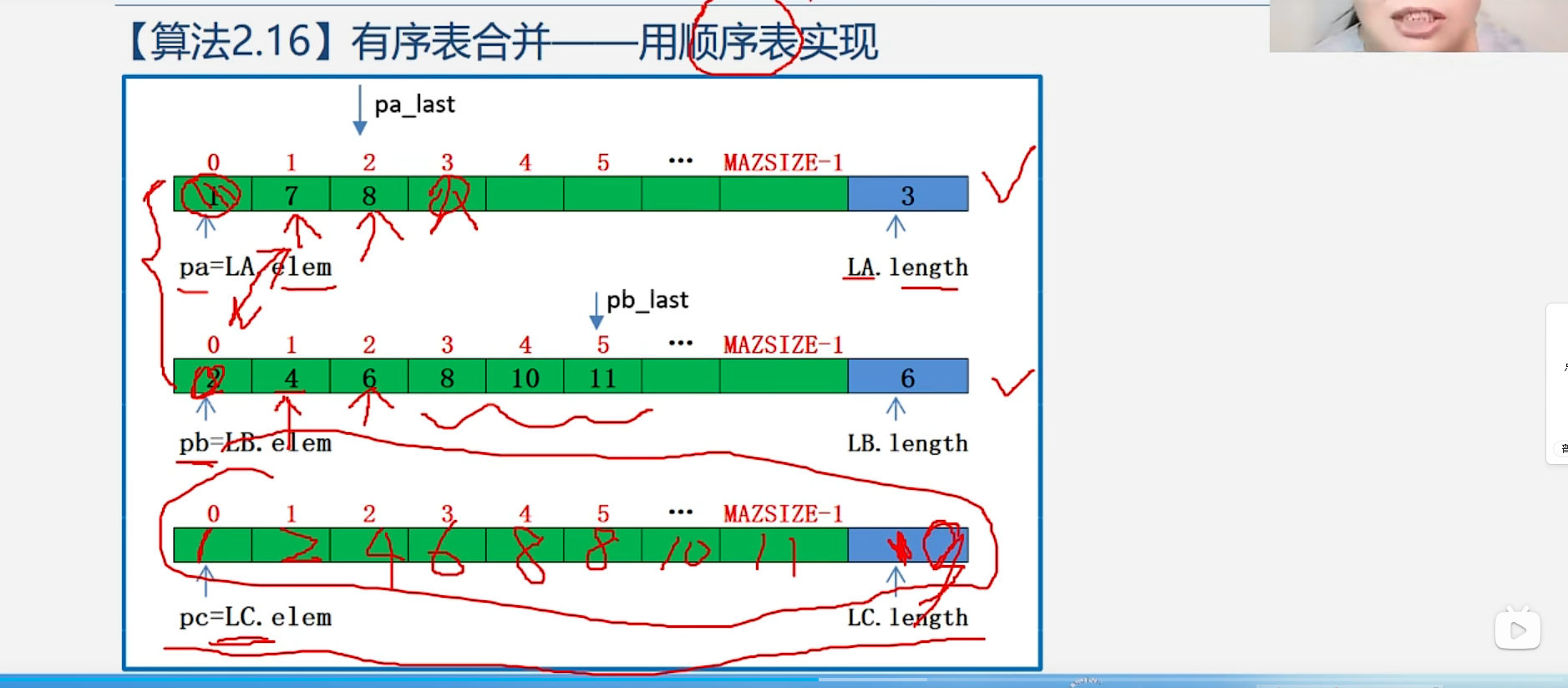
算法步骤:
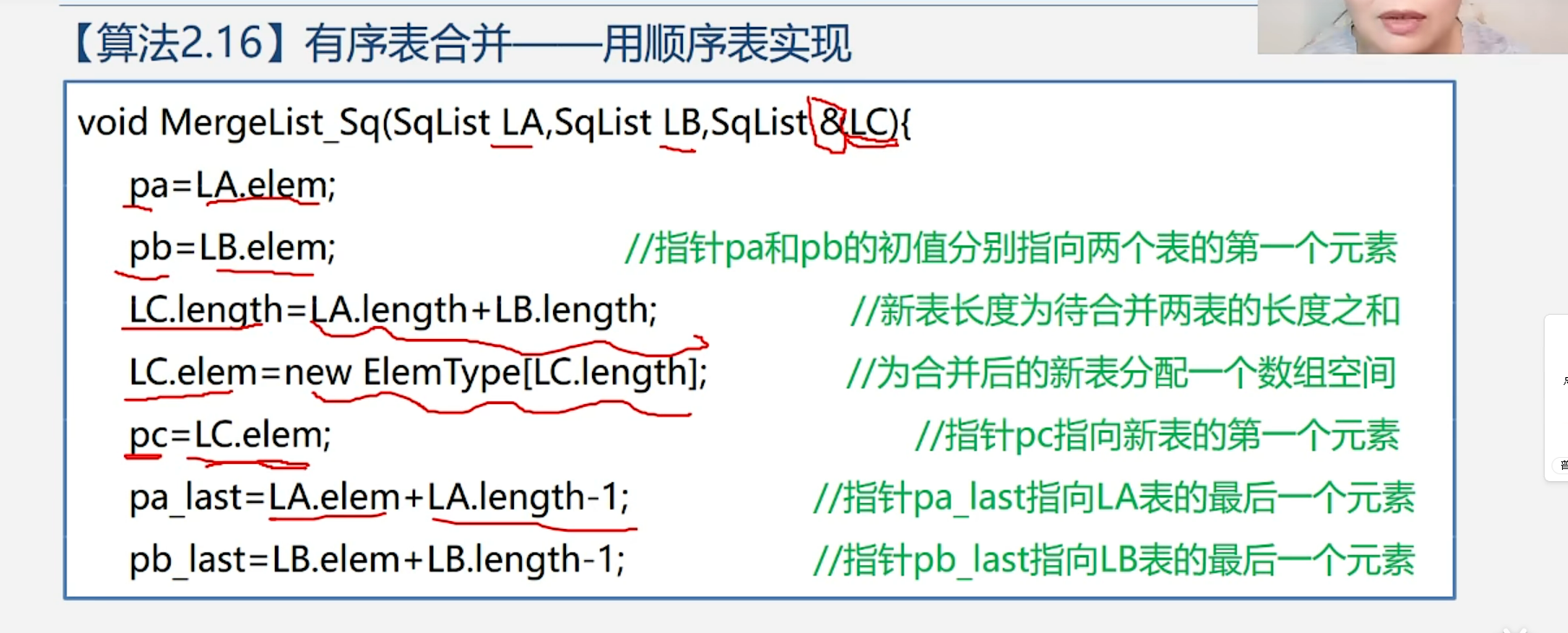

注意:
-
pa / pb 就是顺序表的「头指针」
它们的初始值 pa = La.elem 、 pb = Lb.elem ,就是把顺序表的数组首地址(也就是第一个元素的内存地址)赋值给指针,所以 pa / pb 初始就指向两个有序表的第一个元素,完全符合「头指针」的定义:指向数据结构第一个元素的指针。
-
SqList Lb :明确创建一个顺序表(数组实现)的空表,是具体的实现类型
-
List Lb :创建一个抽象的线性表空表,底层可以是顺序表,也可以是链表
-
为什么是 La.elem + La.length - 1
因为这是数组指针运算,C 语言里规则是:
指针 + 1 = 向后跳 一个元素,不是跳一个字节
-
*pc++ = * pa++ :
把 pa 的数给 pc,然后两个指针都往后走一步,等价于:
*pc = *pa; // 把 pa 现在指的数,放到 pc 现在指的位置
pc = pc + 1; // pc 往后挪一步
pa = pa + 1; // pa 往后挪一步
-
循环条件为什么是 pa <= pa_last?
因为:pa 一开始指向 A 第一个元素,pa_last 指向 A 最后一个元素,只要 pa 还没超过最后一个元素,就说明 A 还有剩,要继续插。
1.4.3 有序表的合并--用链表实现
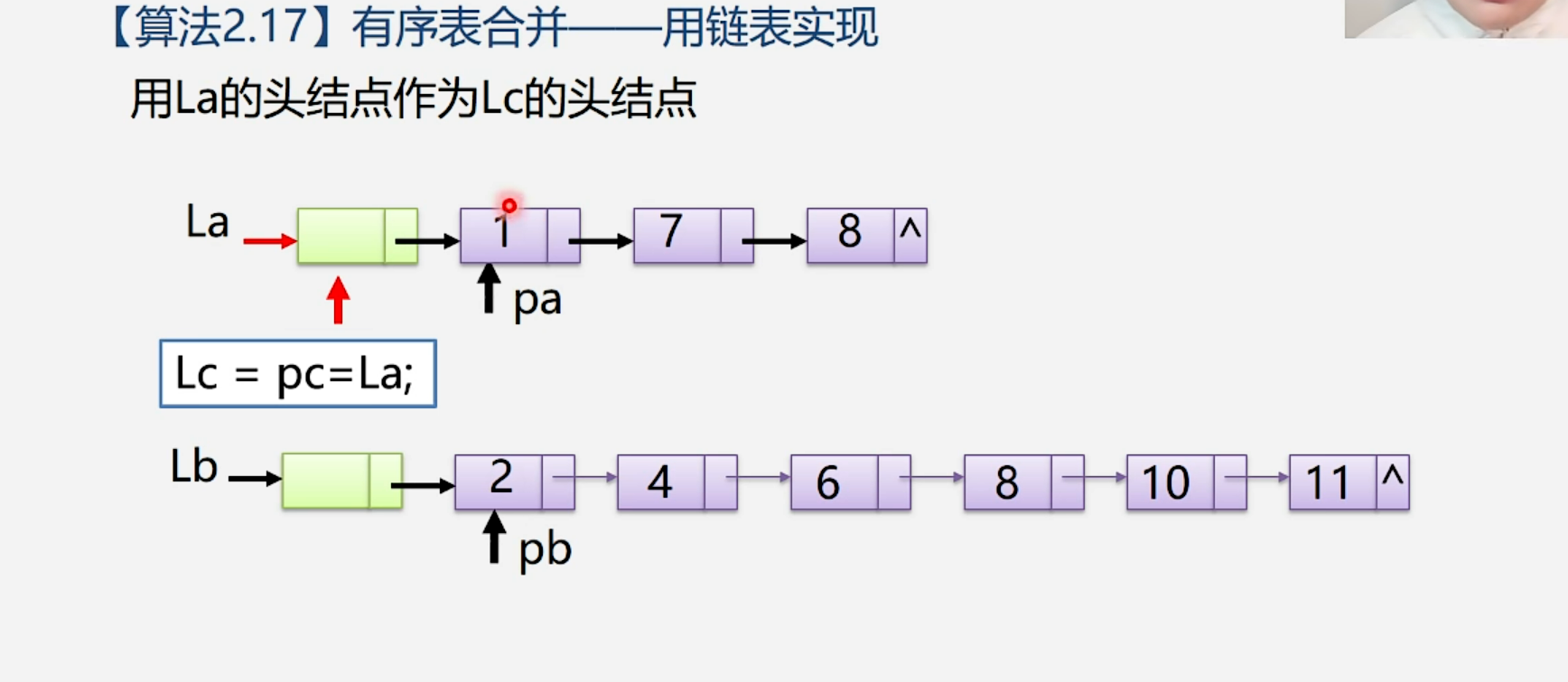
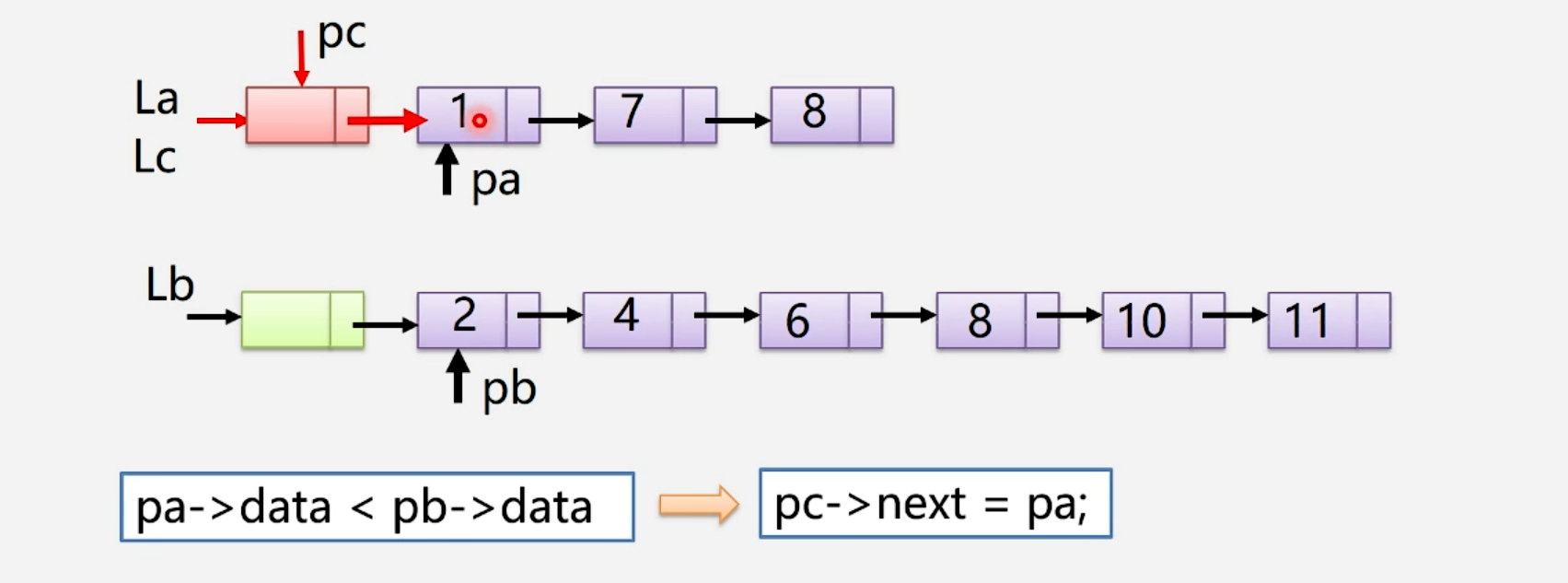
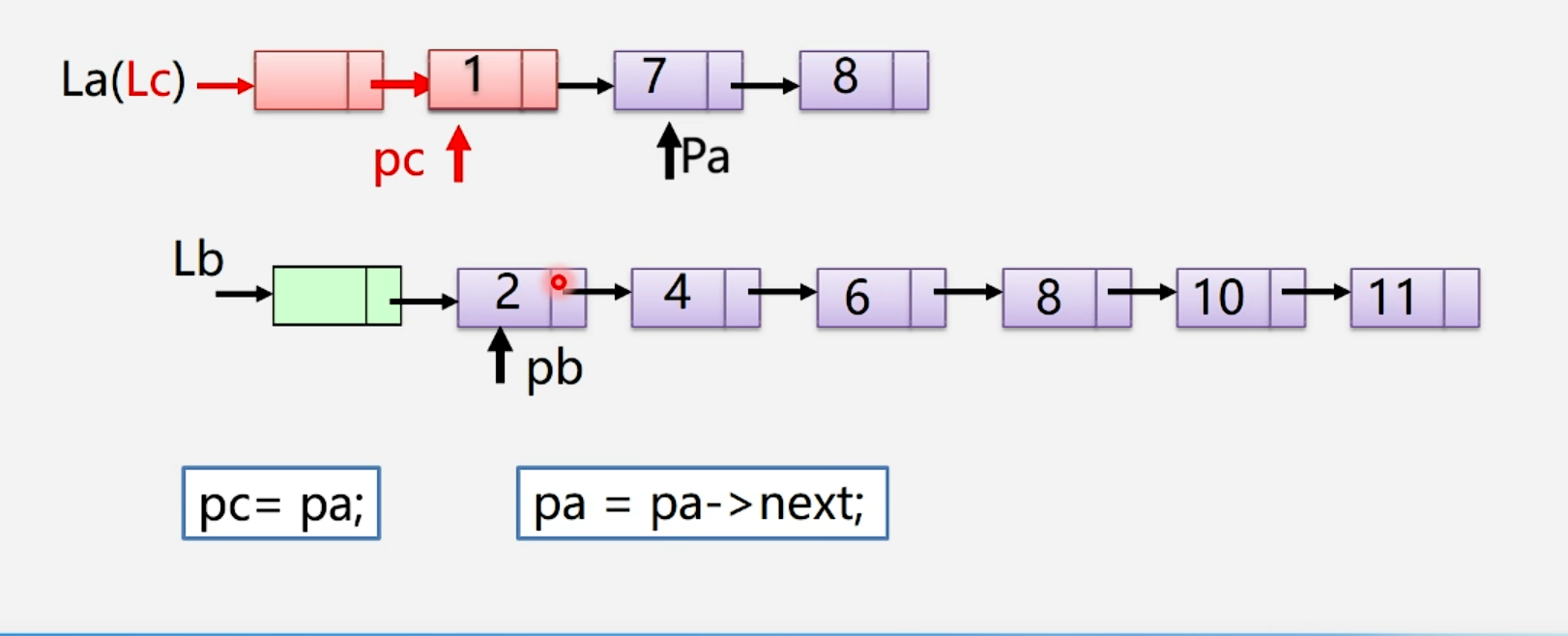
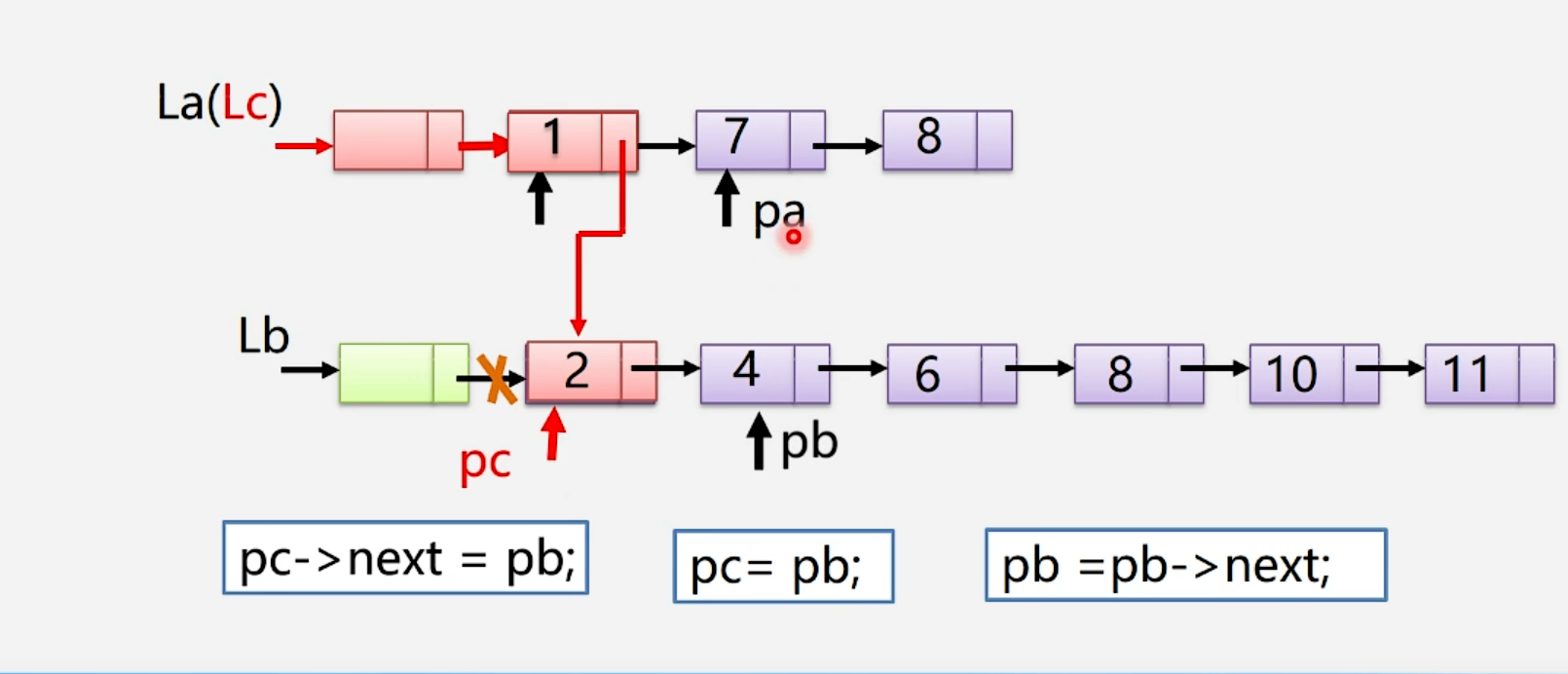
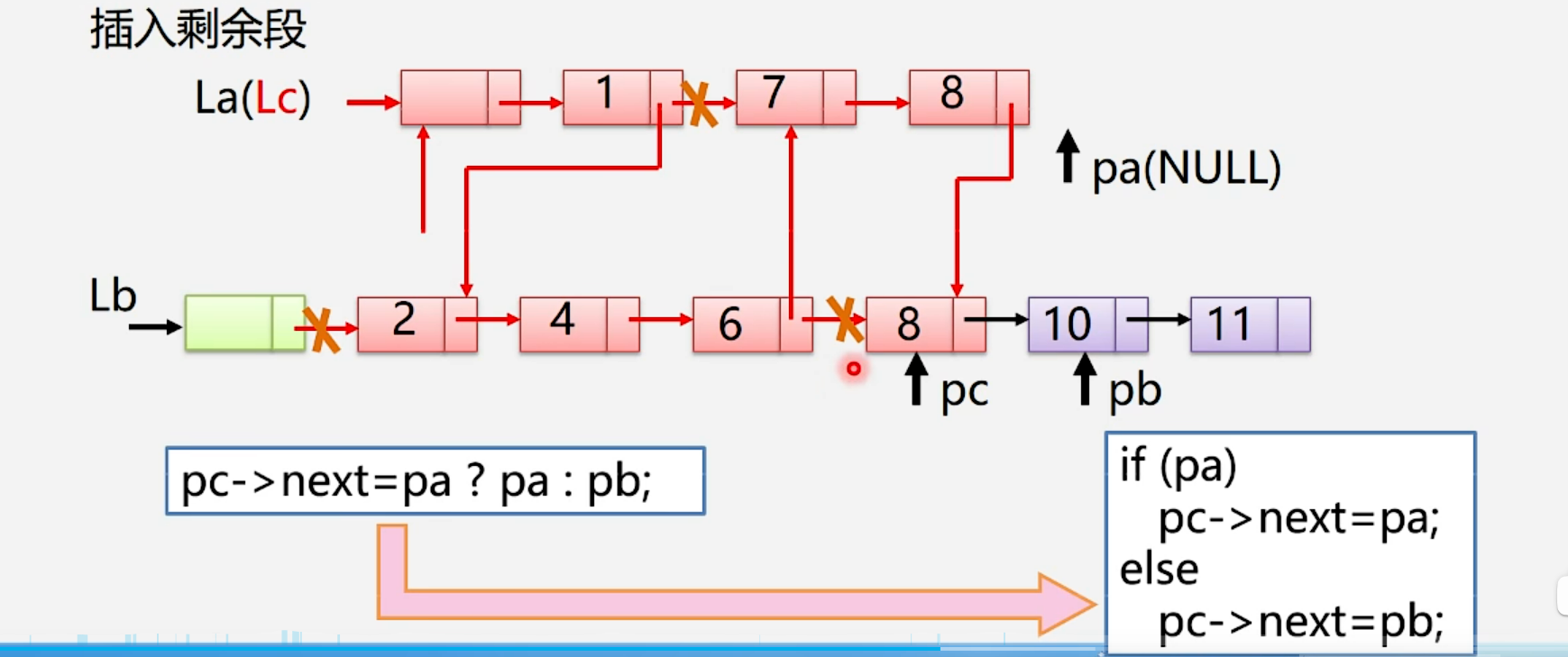
算法步骤:
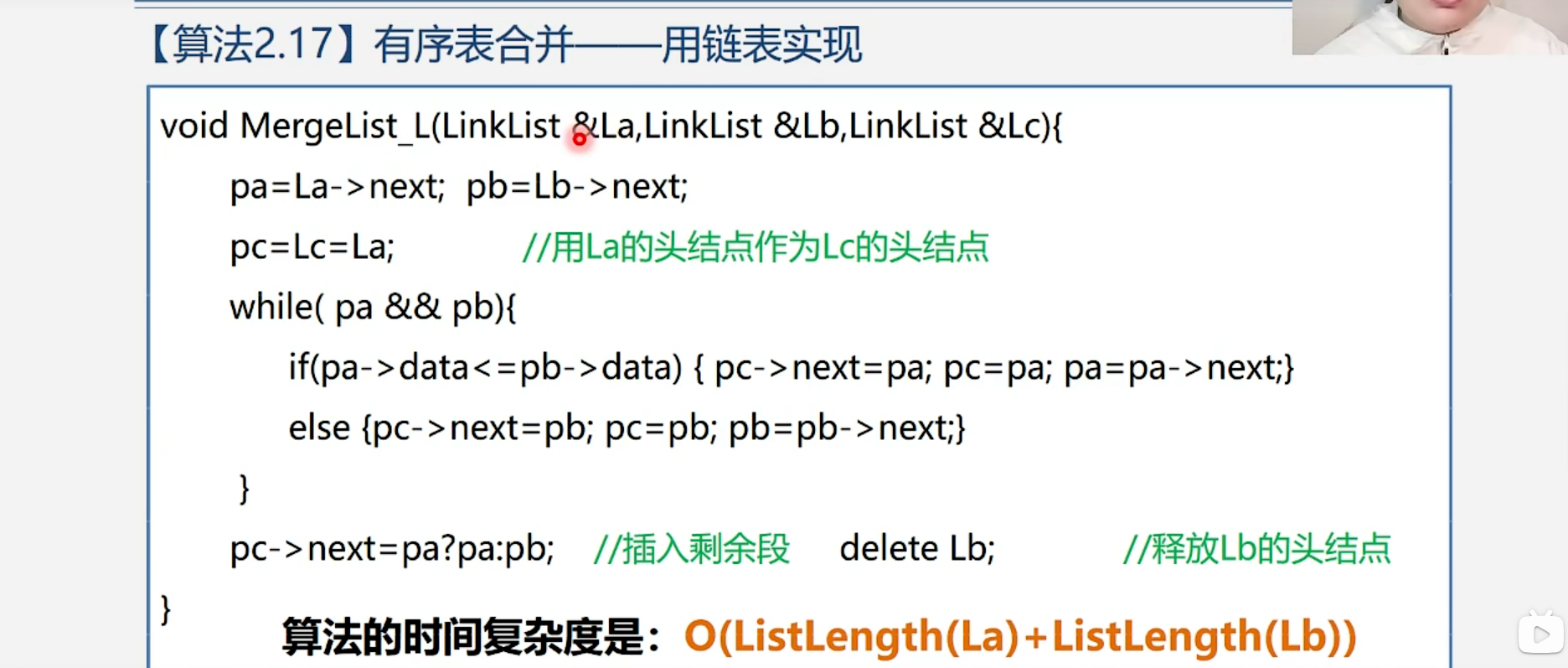
注意:
- 这个算法的空间复杂度是O(1),因为这个算法不需要额外的空间,只需要在原来的链表上修改指针就可以实现它们的合并。
1.5 线性表的分析与实现
1.5.1 多项式运算
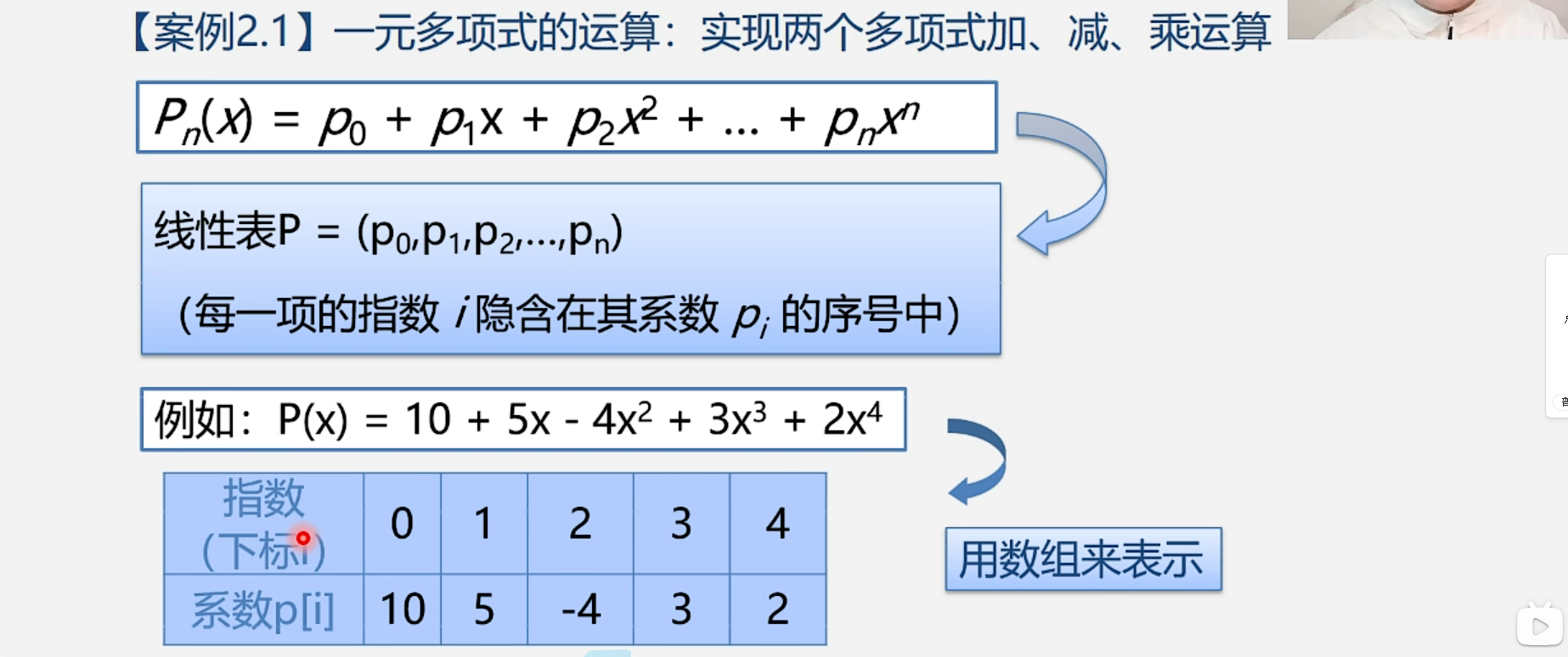
例题:
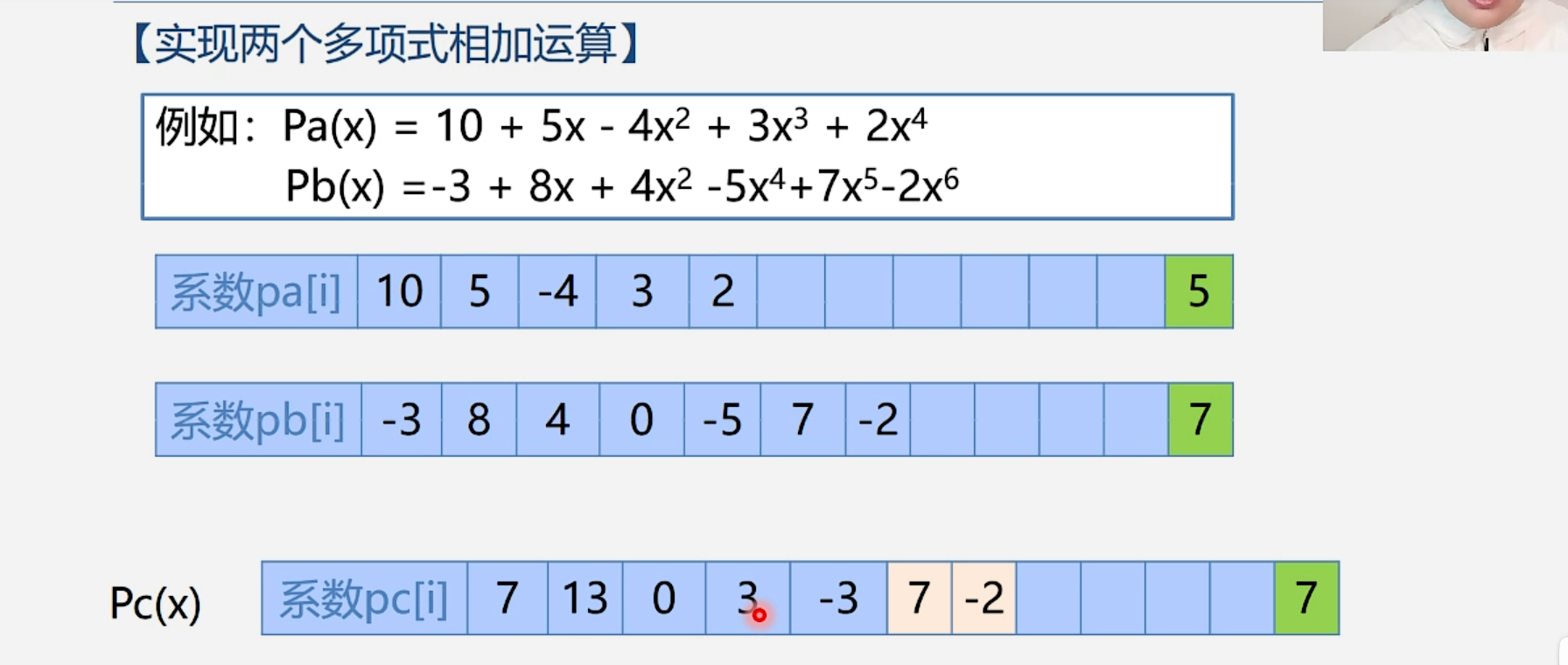
C++
// 多项式加法:La、Lb是两个有序(按指数升序)的多项式链表,合并结果存入Lc
void AddPolyn_L(LinkList &La, LinkList &Lb, LinkList &Lc) {
// 1. 初始化指针:pa指向La的首元结点,pb指向Lb的首元结点
LNode *pa = La->next;
LNode *pb = Lb->next;
LNode *pc; // 结果链表的尾指针
// 2. 用La的头结点作为Lc的头结点
Lc = La;
pc = Lc;
// 3. 双指针遍历两个链表,按指数合并(对应有序表合并的逻辑)
while (pa && pb) {
if (pa->exp < pb->exp) {
// La的当前项指数更小,直接接入结果链表
pc->next = pa;
pc = pa;
pa = pa->next;
} else if (pa->exp > pb->exp) {
// Lb的当前项指数更小,直接接入结果链表
pc->next = pb;
pc = pb;
pb = pb->next;
} else {
// 指数相等:系数相加
pa->coef += pb->coef;
if (pa->coef != 0) {
// 系数不为0,接入结果链表
pc->next = pa;
pc = pa;
} else {
// 系数为0,删除该结点
LNode *q = pa;
La->next = pa->next; // 从La中移除
}
// 释放pb的当前结点,pa后移
LNode *q = pb;
pb = pb->next;
delete q;
pa = pa->next;
}
}
// 4. 插入剩余段
if (pa) pc->next = pa;
else pc->next = pb;
// 5. 释放Lb的头结点
delete Lb;
}1.5.2 稀疏多项式的运算

算法思路:
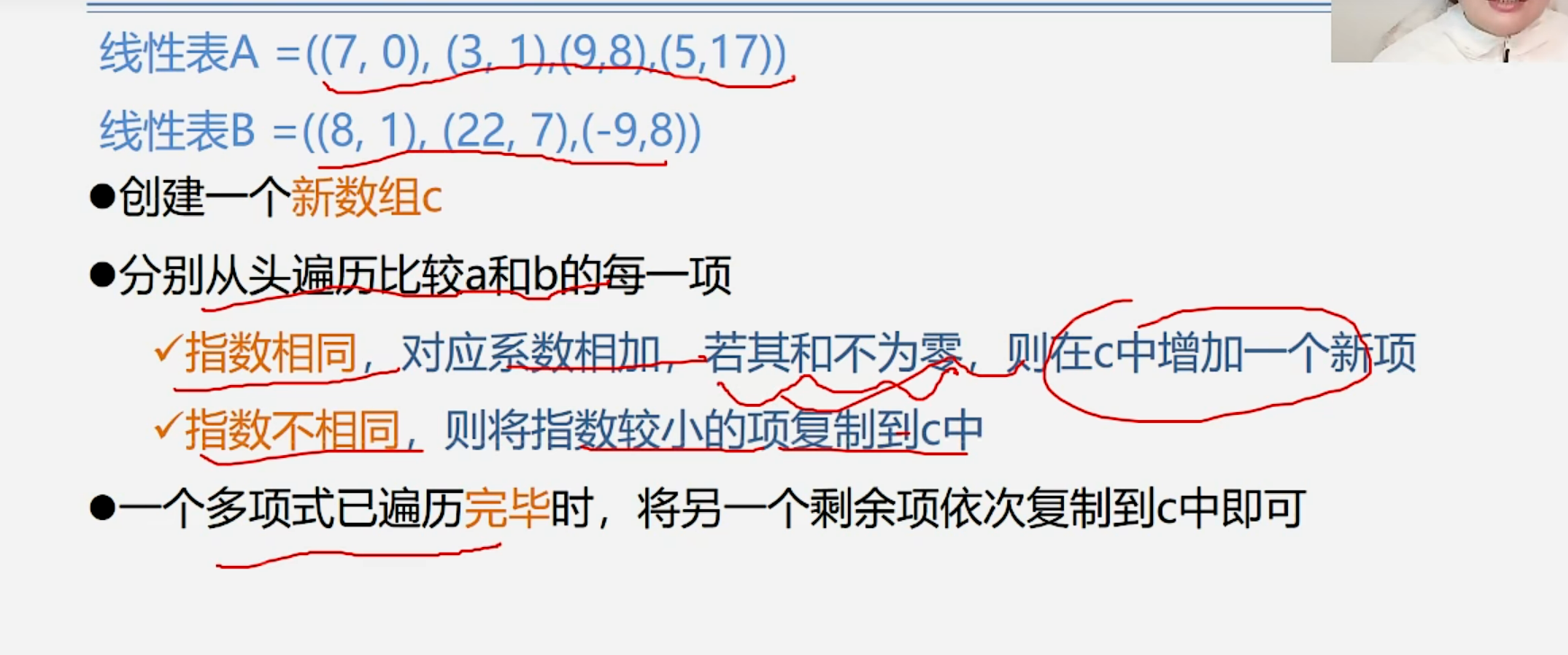
- 由于这个新的链表需要重新创建一个新的数组c存放数据,所以它的空间复杂度比较高。
算法分析:
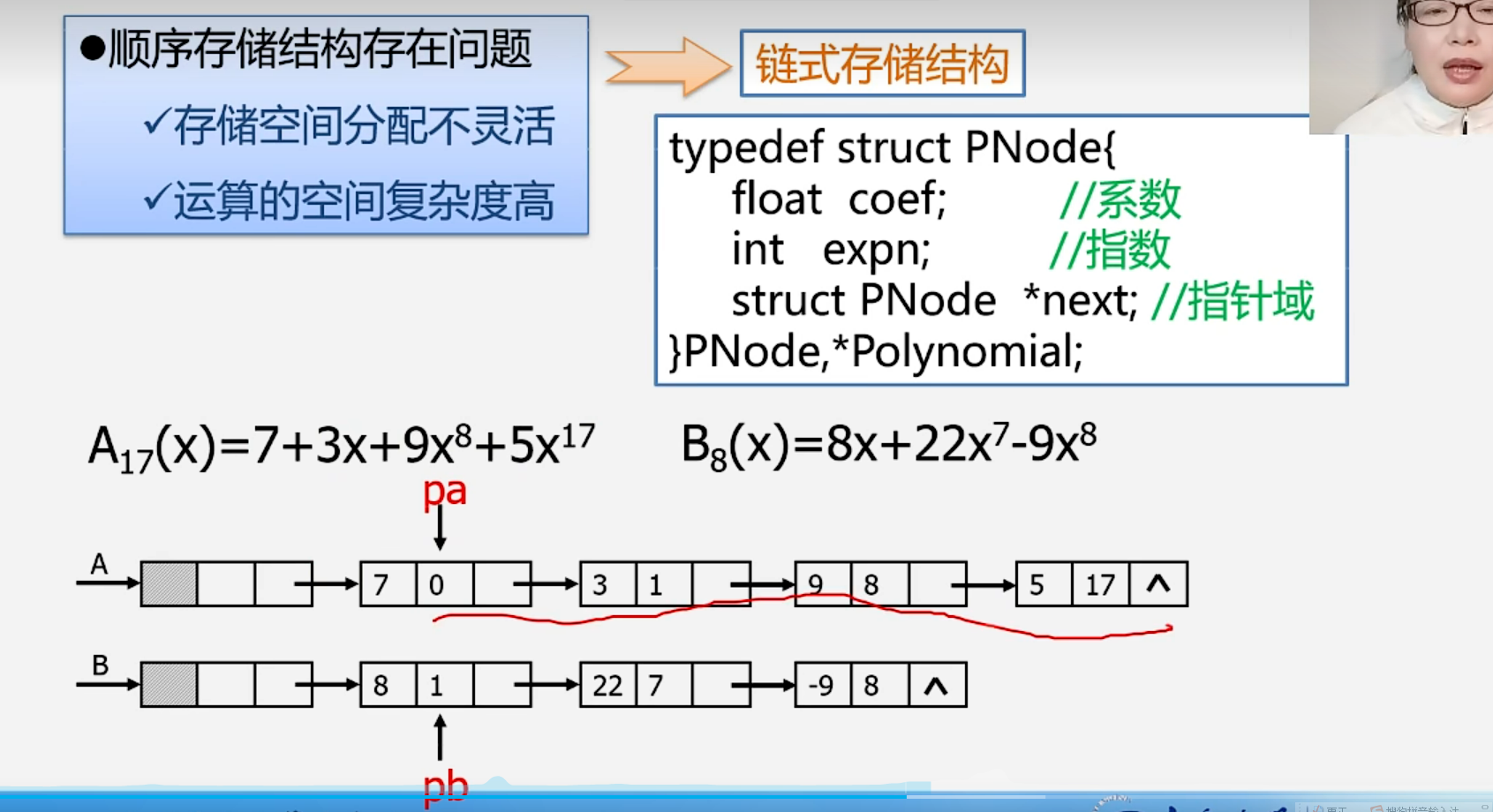
多项式创建------算法步骤:


多项式相加------算法步骤:
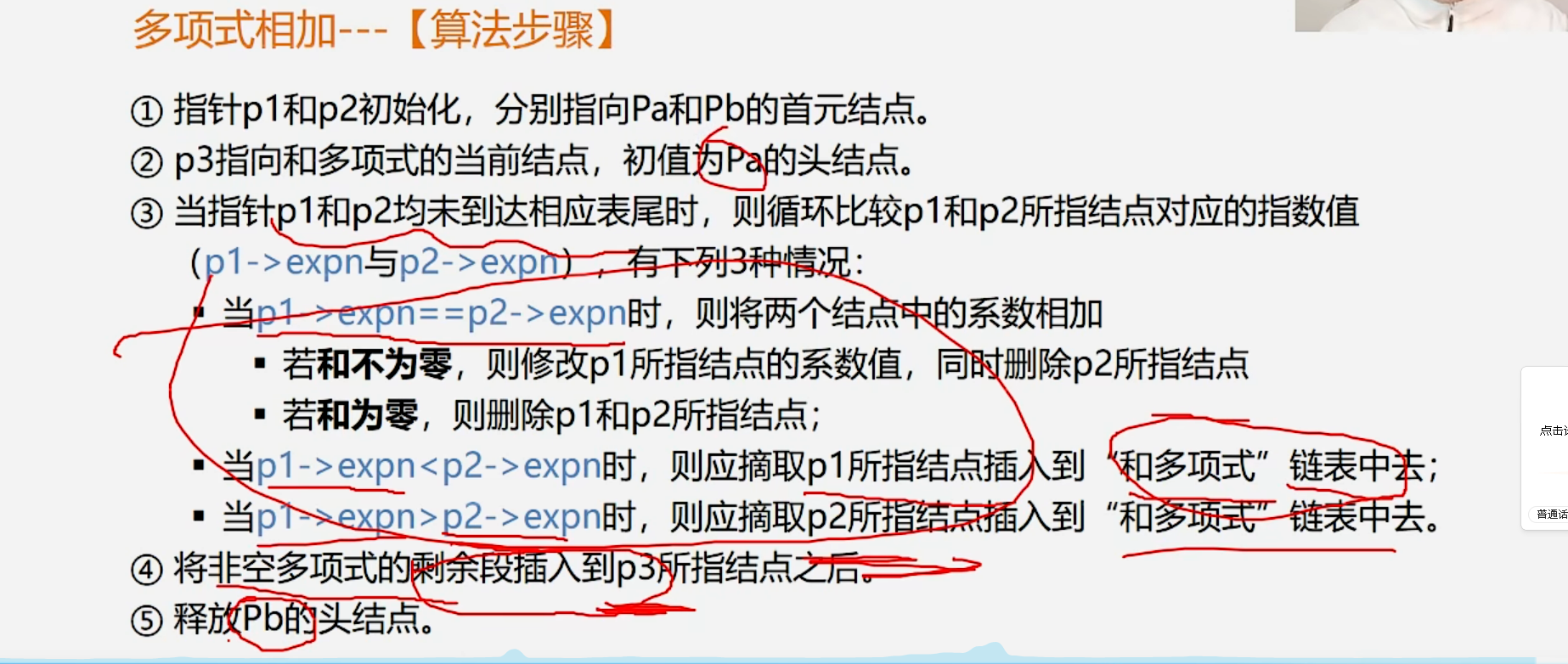
C++
void AddPolyn_L(LinkList &Pa, LinkList &Pb, LinkList &Pc) {
// 步骤①:指针p1和p2初始化,分别指向Pa和Pb的首元结点
LNode *p1 = Pa->next;
LNode *p2 = Pb->next;
// 步骤②:p3指向和多项式的当前结点,初值为Pa的头结点
LNode *p3 = Pa;
LNode *q; // 辅助指针,用于删除结点
while (p1 && p2) { // 步骤③:当p1和p2都未到表尾时,循环比较
if (p1->expn == p2->expn) {
// 情况1:指数相等,系数相加
p1->coef += p2->coef;
if (p1->coef != 0) {
// 子情况1:和不为零,修改p1的系数,删除p2的结点
p3->next = p1;
p3 = p1;
p1 = p1->next;
// 删除p2的当前结点
q = p2;
p2 = p2->next;
delete q;
} else {
// 子情况2:和为零,删除p1和p2的结点
// 先删p1
q = p1;
p1 = p1->next;
p3->next = p1;
delete q;
// 再删p2
q = p2;
p2 = p2->next;
delete q;
}
}
else if (p1->expn < p2->expn) {
// 情况2:p1的指数更小,摘取p1插入和多项式
p3->next = p1;
p3 = p1;
p1 = p1->next;
}
else {
// 情况3:p2的指数更小,摘取p2插入和多项式
p3->next = p2;
p3 = p2;
p2 = p2->next;
}
}
// 步骤④:将非空多项式的剩余段插入到p3之后
p3->next = p1 ? p1 : p2;
// 步骤⑤:释放Pb的头结点
delete Pb;
// 用Pa的头结点作为和多项式Pc的头结点
Pc = Pa;
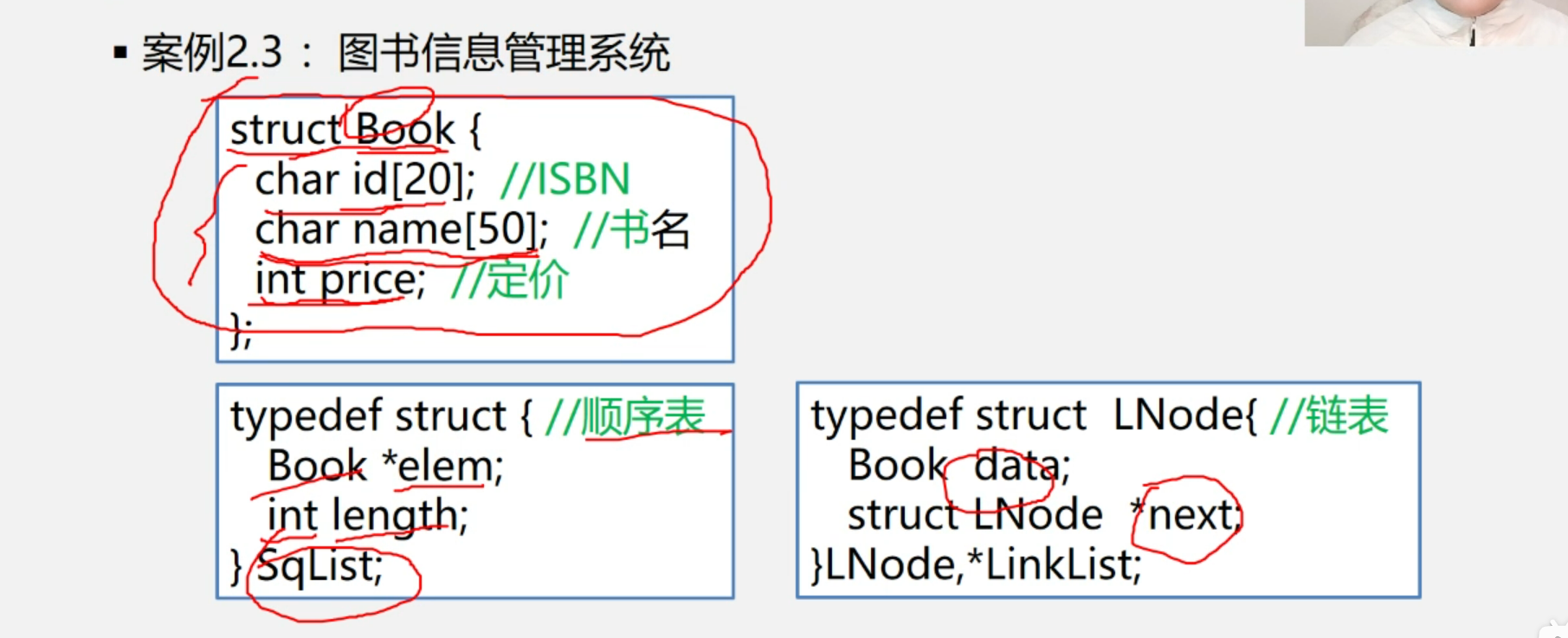
}1.5.3 图书信息管理系统
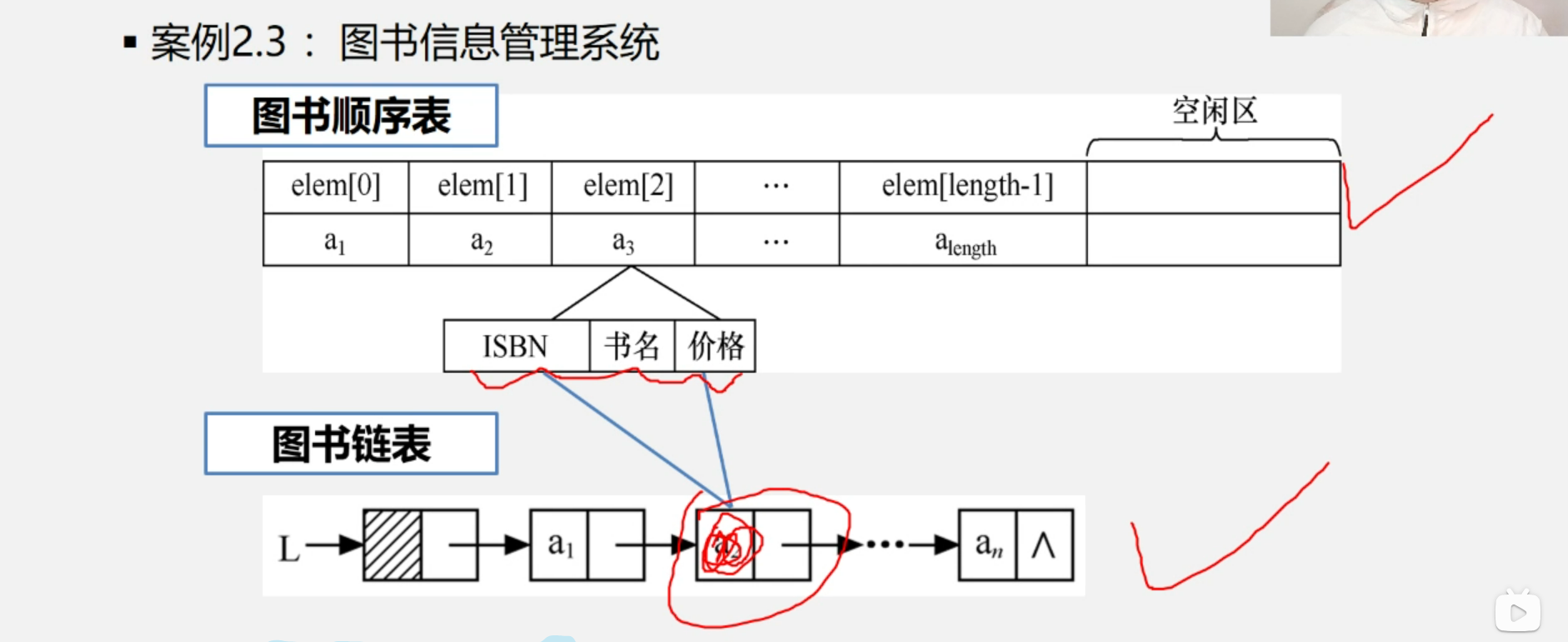
分析: