在人工智能技术飞速发展的今天,AI 助手已从 "文字框里的应答者" 进化为 "能听会说的智能伙伴"。无论是手机端的 Siri、小爱同学,还是 Web 端的智能客服、教育 AI 助手,语音交互都成为其核心竞争力 ------ 用户无需手动输入,只需开口提问,AI 助手就能用自然的语音回应。
这一转变的背后,离不开前端语音识别与 TTS(文本转语音)技术的支撑。本文将聚焦前端场景,从需求出发,拆解 TTS 基础知识、浏览器原生能力,深入解析微软认知服务 SDK 的优势,帮你一步步实现 "让 AI 助手开口说话" 的目标。
目录
[一、为什么 AI 助手需要语音识别与 TTS?](#一、为什么 AI 助手需要语音识别与 TTS?)
[二、前端 TTS 基础知识:AI 助手 "说话" 的底层逻辑](#二、前端 TTS 基础知识:AI 助手 “说话” 的底层逻辑)
[三、浏览器内置语音能力:快速实现 AI 助手的 "基础语音功能"](#三、浏览器内置语音能力:快速实现 AI 助手的 “基础语音功能”)
[四、Microsoft Cognitive Services Speech SDK:让 AI 助手 "说" 得更自然](#四、Microsoft Cognitive Services Speech SDK:让 AI 助手 “说” 得更自然)
一、为什么 AI 助手需要语音识别与 TTS?
提升用户体验是首要原因。
传统的文本输入方式需要用户手动键入,而语音输入更加自然高效。想象一下,用户可以直接通过语音与你的AI助手对话,而不必反复敲击键盘。
无障碍访问同样重要。
语音交互为视力障碍者、行动不便的用户提供了更加平等的访问机会。这是Web包容性设计的重要体现。
多场景适配价值显著。
在移动端场景中,语音输入比键盘输入更加便捷;在车载系统、智能家居等场景下,语音更是唯一的交互方式。
二、前端 TTS 基础知识:AI 助手 "说话" 的底层逻辑
要让 AI 助手 "开口说话",首先需理解前端 TTS 的核心原理:它并非简单地 "将文字转为声音",而是一套包含 "文本处理、语音合成、音频输出" 的完整流程。

1. TTS 的三大核心环节
AI 助手的语音输出,需经过以下三个关键步骤,每个环节都直接影响 "说话" 的质量:
🔹 文本预处理:为 AI 助手 "整理话术"
大模型返回给 AI 助手的文本,可能包含 HTML 标签(如 <br> <p>)、特殊符号(如 * #),或存在长句无停顿、语气不明确的问题。
文本预处理环节需做三件事:
▪ **清洗文本:**去除无关标签与符号,保留纯文字内容;
▪ **语义分析:**识别句子类型(疑问句、感叹句、陈述句),比如 "您需要生成报告吗?" 需调整为疑问语气,"报告已生成完成!" 需用感叹语气;
**▪ 断句优化:**在长句中插入合理停顿标记(如 "项目进度方面,停顿 设计模块已完成 80%,停顿 开发模块预计下周结束"),避免语音 "一口气读完" 的生硬感。
🔹 语音合成引擎:为 AI 助手 "定制音色"
这是 TTS 的核心,负责将处理后的文本转化为语音信号。目前主流的合成技术分为两类:
**▪ 规则合成:**基于语法规则与预制音素(如 "你" 对应 "nǐ" 的发音)拼接语音,成本低但音质机械,类似早期 "机器人说话";
**▪ 神经合成(Neural TTS):**基于深度学习模型,通过大量真人语音数据训练,能模拟真人的语调、节奏甚至情感,是当前 AI 助手的首选技术(如微软、百度的 TTS 均采用此方案)。
🔹 音频输出:让 AI 助手 "把话讲出来"
合成后的语音信号需通过浏览器音频 API 播放,前端需控制三个关键参数,优化用户听感:
**▪ 语速:**默认 1 倍速,可根据场景调整(如教育 AI 助手讲解知识点时用 0.8 倍速,办公 AI 助手播报通知时用 1.2 倍速);
**▪ 音量:**默认 100%,需支持用户手动调节,避免音量过大或过小;
**▪ 播放控制:**支持暂停、继续、停止功能(如用户听 AI 助手播报攻略时,可暂停查看地图,再继续听后续内容)。
2. AI 助手语音交互的完整流程
AI 助手的 "听" 与 "说" 是一个闭环:用户语音输入→AI 助手识别→大模型生成回答→AI 助手语音输出。
具体流程如下图所示,清晰呈现了 "用户开口" 到 "AI 助手回应" 的全链路
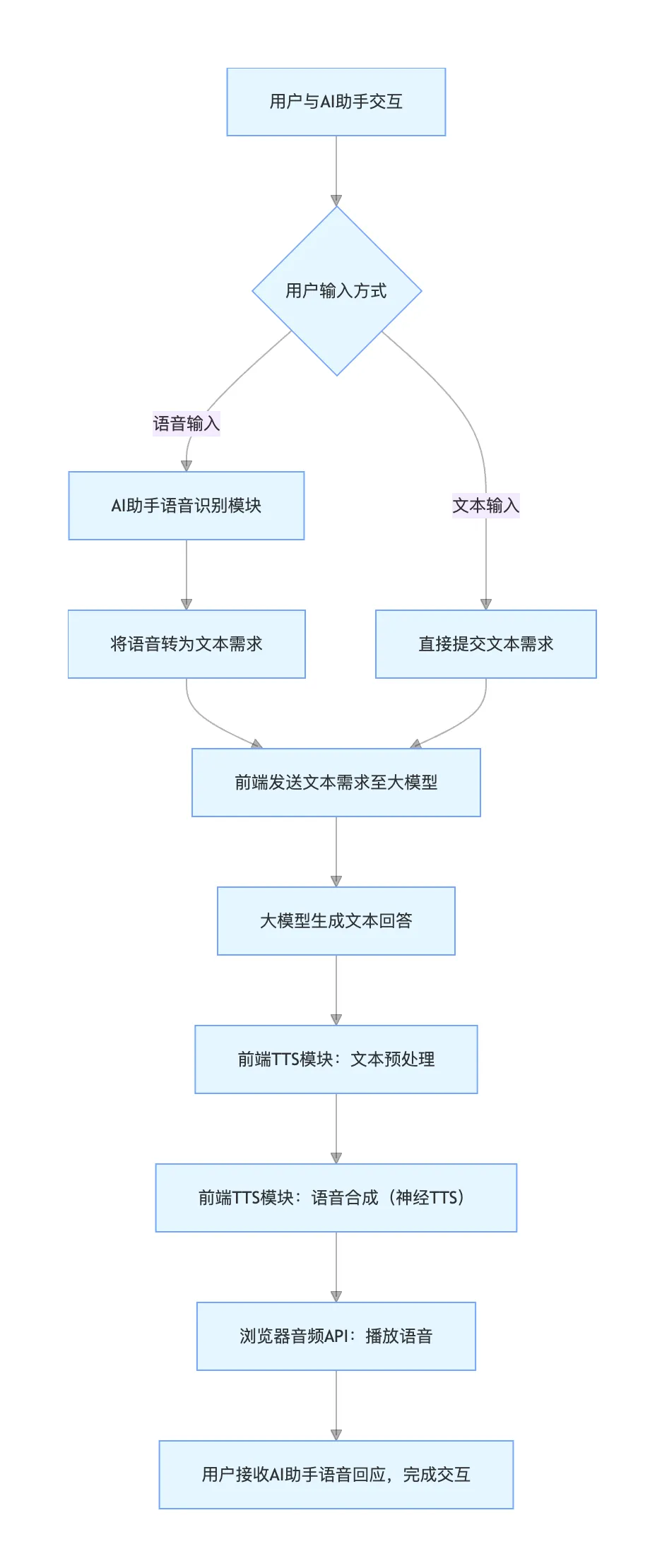
从流程图可见,TTS 是 AI 助手 "输出端" 的核心 ------ 大模型负责 "想答案",TTS 负责 "把答案说出来";而语音识别则是 "输入端" 的关键,让用户能轻松传递需求。
二者结合,才构成完整的语音交互体验。
三、浏览器内置语音能力:快速实现 AI 助手的 "基础语音功能"
若你想快速搭建一个 "能听会说" 的简易 AI 助手,无需依赖第三方工具 ------ 现代浏览器已内置语音识别与 TTS 模块,通过 Web Speech API 即可调用。但需注意,这类原生能力更适合 "轻量级场景",如个人小助手,无法满足企业级 AI 助手的高质量需求。
1. 浏览器内置 TTS:SpeechSynthesis 接口
浏览器通过 SpeechSynthesis 接口提供 TTS 能力,支持 Chrome、Edge、Safari(14.1+)等主流浏览器,能让 AI 助手实现 "基础说话功能"。
核心 API 与 AI 助手示例代码
▪**SpeechSynthesis.speak():**触发语音播放;
**▪ SpeechSynthesisUtterance:**创建语音实例,配置文本、语速、语调等参数。
以下是简易办公 AI 助手的 TTS 实现代码 ------ 当大模型生成 "会议待办清单" 后,AI 助手自动用语音播报:
javascript
// 检查浏览器是否支持原生TTS
if ('speechSynthesis'inwindow) {
// 模拟大模型返回的AI助手回答(会议待办清单)
const aiAnswer = "以下是今日会议待办清单:1. 确定项目上线时间,2. 分配测试任务,3. 同步客户反馈。请在下班前完成整理。";
// 创建语音实例
const utterance = new SpeechSynthesisUtterance(aiAnswer);
// 配置AI助手的语音参数
utterance.rate = 1.1; // 语速稍快,适合办公场景
utterance.pitch = 1.2; // 语调略高,传递清晰感
utterance.volume = 0.9; // 音量适中,避免干扰他人
// 选择语音(优先中文语音)
let voices = window.speechSynthesis.getVoices();
// 等待语音列表加载(部分浏览器需延迟获取)
window.speechSynthesis.onvoiceschanged = () => {
voices = window.speechSynthesis.getVoices();
// 筛选中文语音(如Chrome的"Microsoft 慧涛")
const chineseVoice = voices.find(voice =>
voice.lang.includes('zh-CN') || voice.name.includes('Chinese')
);
if (chineseVoice) utterance.voice = chineseVoice;
// AI助手开始"说话"
window.speechSynthesis.speak(utterance);
console.log("AI助手正在播报待办清单...");
};
} else {
alert("您的浏览器不支持语音功能,请升级后使用AI助手!");
}原生 TTS 的局限:不适合 "高质量 AI 助手"
虽然原生 TTS 能让 AI 助手 "开口",但存在明显短板,无法满足企业级需求:
**▪ 音色机械:**内置语音多为规则合成,比如 Chrome 的 "Microsoft 慧涛",语调平淡无情感,像 "机器人读稿",缺乏 AI 助手的 "亲切感";
**▪ 语音种类少:**仅支持浏览器预装的语音包,无法自定义音色(如办公 AI 助手需要的 "专业男声"、儿童教育助手需要的 "卡通女声");
**▪ 兼容性差:**Safari 不支持语音选择功能,在苹果浏览器中,AI 助手只能用默认语音,无法统一体验。
2. 浏览器内置语音识别:SpeechRecognition 接口
要让 AI 助手 "听懂" 用户的语音需求,可使用浏览器内置的 SpeechRecognition 接口(Chrome 中需加 webkit 前缀),将用户口语转为文本,再发送给大模型。
基础实现代码:AI 助手 "听需求"
以下代码实现了 "用户语音提问,AI 助手接收需求" 的功能,以办公 AI 助手为例:
javascript
// 处理浏览器兼容性
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
if (SpeechRecognition) {
const recognition = new SpeechRecognition();
recognition.lang = 'zh-CN'; // 识别中文
recognition.interimResults = false; // 不返回未完成的临时结果
recognition.maxAlternatives = 1; // 只返回最准确的识别结果
// 绑定"唤醒AI助手"按钮(用户点击后开始识别)
document.getElementById('wake-ai-btn').addEventListener('click', () => {
recognition.start();
console.log("AI助手已唤醒,正在听您说话...");
document.getElementById('ai-status').textContent = "正在聆听...";
});
// 识别成功:获取用户需求,发送给大模型
recognition.onresult = (event) => {
const userDemand = event.results\[0]\[0].transcript;
document.getElementById('ai-status').textContent = \`您的需求:\${userDemand}\`;
console.log("用户需求:", userDemand);
// 发送需求给大模型,获取AI助手回答(后续触发TTS播报)
getAiAnswer(userDemand);
};
// 识别结束/错误处理
recognition.onend = () => {
document.getElementById('ai-status').textContent = "等待唤醒...";
console.log("AI助手停止聆听");
};
recognition.onerror = (error) => {
document.getElementById('ai-status').textContent = "识别失败,请重试";
console.error("语音识别错误:", error);
};
} else {
alert("您的浏览器不支持语音识别,无法唤醒AI助手!");
}
// 模拟发送需求给大模型,获取AI助手回答
async function getAiAnswer(demand) {
const response = await fetch('/api/ai-assistant', {
method: 'POST',
body: JSON.stringify({ demand: demand }),
headers: { 'Content-Type': 'application/json' }
});
const data = await response.json();
// 后续调用TTS,让AI助手播报回答
speakAiAnswer(data.answer);
}原生语音识别的短板
▪ 与 TTS 类似,原生语音识别也无法满足 AI 助手的复杂需求:
**▪ 依赖外部服务:**Chrome 的语音识别需连接 Google 服务器,国内网络环境下常出现 "识别超时",导致 AI 助手 "听不见";
**▪ 准确率低:**在嘈杂环境(如办公室、咖啡厅)中,易误识别(比如用户说 "生成报告",可能识别为 "生成报纸");对带口音的口语(如四川话、粤语)支持差,无法覆盖广泛用户;
**▪ 功能单一:**不支持 "自定义词汇表"------ 比如办公 AI 助手常涉及 "CRM 系统""OKR 目标" 等专业术语,原生识别易识别错误,影响交互体验。
四、Microsoft Cognitive Services Speech SDK:让 AI 助手 "说" 得更自然
要打造企业级、高质量的 AI 助手(如教育平台的学习助手、电商平台的客服助手),浏览器原生能力远远不够。此时,第三方语音 SDK 成为首选,其中 Microsoft Cognitive Services Speech SDK(微软认知服务语音 SDK)凭借 "高音质、高准确率、强定制性" 的优势,成为众多 AI 助手的核心技术支撑。
1. 微软 SDK 让 AI 助手 "脱胎换骨" 的 4 大优势
相比浏览器原生能力,微软 SDK 从 "音色、识别、兼容性、功能" 四个维度,全面提升 AI 助手的语音交互体验:
(1)TTS 音色:让 AI 助手拥有 "专属声线"
微软 SDK 采用先进的 "神经 TTS" 技术,合成的语音自然度远超原生能力,且支持高度定制,能为不同场景的 AI 助手匹配专属音色:
**▪ 自然度高:**语音流畅度接近真人,可模拟呼吸声、停顿节奏,避免机械感;
**▪ 音色丰富:**提供数十种预定义音色(如中文的 "晓晨""晓燕",英文的 "Jenny""Guy"),覆盖不同年龄、性别、风格(正式、亲切、活泼);
**▪ 情感定制:**支持为语音添加情感(如喜悦、悲伤、愤怒),例如在智能客服回复 "很抱歉给您带来不便" 时,使用低沉、歉意的语气;
**▪ 自定义音色:**企业可上传真人语音样本,训练专属音色(如品牌代言人声音),增强品牌辨识度。
(2)语音识别:让 AI 助手 "听得更准"
微软 SDK 的语音识别模块(Speech-to-Text)通过大规模语料训练,具备更强的场景适配能力:
**▪ 噪音鲁棒性:**在嘈杂环境(如商场、街道)中,仍能保持高识别准确率;
**▪ 口音与方言支持:**支持中文各地方言(如粤语、四川话)、带口音的英文等,覆盖更广泛用户群体;
**▪ 行业术语优化:**可导入自定义词汇表(如医疗领域的 "核磁共振"、金融领域的 "量化宽松"),提升专业场景的识别准确率;
**▪ 实时流处理:**支持边说话边识别(实时转写),减少用户等待时间,适合长对话场景。
(3)跨平台兼容性强,简化前端集成
微软 SDK 提供专门的前端集成包(支持浏览器、Electron),解决了原生 API 的兼容性问题:
**▪多浏览器支持:**统一适配 Chrome、Edge、Safari、Firefox 等主流浏览器,无需额外处理兼容性差异;
**▪ 轻量级集成:**通过 CDN 引入 SDK(约 200KB),或使用 npm 安装,API 设计简洁,开发者无需关注底层语音引擎细节;
**▪ 离线支持:**部分场景下可部署本地语音引擎,实现离线语音识别与 TTS,适合对网络稳定性要求高的场景(如工业 Web 应用)。
(4)丰富的附加功能,满足复杂需求
除核心的 "识别" 与 "合成" 外,SDK 还提供一系列增值功能,降低前端开发复杂度:
**▪ 语音翻译:**支持实时将语音从一种语言转为另一种语言(如中文语音→英文文本 / 语音),适合跨国对话场景;
**▪ 语音标记:**支持在 TTS 中插入停顿、强调标记(如<break time="500ms"/>表示停顿 500 毫秒),优化语音节奏;
**▪ 错误重试与断点续播:**网络波动时自动重试,TTS 支持断点续播(如用户暂停后,从上次停止位置继续播放)。
2. 前端集成微软 Speech SDK 的示例代码
以下是一个简化的前端集成流程,包含 "语音识别(用户输入)" 与 "TTS(大模型回答输出)" 两个核心环节:
步骤 1:引入 SDK(通过 CDN)
javascript
<!-- 引入微软Speech SDK -->
<script src="https://cdn.jsdelivr.net/npm/microsoft-cognitiveservices-speech-sdk@latest/distrib/browser/microsoft.cognitiveservices.speech.sdk.bundle-min.js"></script>步骤 2:初始化 SDK(需先在微软 Azure 控制台创建资源,获取密钥与区域)
javascript
// 配置SDK参数(替换为你的Azure密钥与区域)
const speechConfig = sdk.SpeechConfig.fromSubscription("你的Azure密钥", "你的区域(如eastasia)");
// 设置TTS语音(选择中文音色"晓燕")
speechConfig.speechSynthesisVoiceName = "zh-CN-XiaoyanNeural";
// 设置语音识别语言(中文)
speechConfig.speechRecognitionLanguage = "zh-CN";步骤 3:实现语音识别(用户输入)
javascript
// 创建语音识别器(绑定麦克风输入)
const audioConfig = sdk.AudioConfig.fromDefaultMicrophoneInput();
const recognizer = new sdk.SpeechRecognizer(speechConfig, audioConfig);
// 开始识别(绑定按钮事件)
document.getElementById('start-recog').addEventListener('click', () => {
console.log("开始语音识别...");
recognizer.startContinuousRecognitionAsync(); // 连续识别(适合长对话)
});
// 识别结果处理(获取文本并发送给大模型)
recognizer.recognized = (s, e) => {
if (e.result.reason === sdk.ResultReason.RecognizedSpeech) {
const userText = e.result.text;
console.log("用户语音识别结果:", userText);
// 调用大模型API(此处以模拟为例)
callLLM(userText).then(llmText => {
// 大模型返回文本后,调用TTS播放
synthesizeSpeech(llmText);
});
}
};
// 停止识别
document.getElementById('stop-recog').addEventListener('click', () => {
recognizer.stopContinuousRecognitionAsync();
});步骤 4:实现 TTS(播放大模型回答)
javascript
// 创建TTS合成器(绑定默认音频输出)
const synthesizer = new sdk.SpeechSynthesizer(speechConfig);
// TTS合成与播放函数
function synthesizeSpeech(text) {
console.log("开始TTS合成:", text);
// 合成并播放语音
synthesizer.speakTextAsync(
text,
(result) => {
if (result.reason === sdk.ResultReason.SynthesizingAudioCompleted) {
console.log("TTS播放完成");
}
synthesizer.close(); // 关闭合成器
},
(error) => {
console.error("TTS错误:", error);
synthesizer.close();
}
);
}五、未来展望
语音交互技术正在向端到端模型发展,未来将朝着拟人化、低延时、多模态等方向发展,更贴近人类自然对话,提升用户体验。
同时,WebGPU等新技术将为直接在浏览器中运行复杂的语音模型提供可能。
作为前端开发者,掌握语音交互技术将为我们的应用开启新的可能性,创造更加自然、智能的用户体验。
参考资料:
1 https://platform.openai.com/docs/guides/realtime
2https://blogs.microsoft.com/blog/2024/10/01/an-ai-companion-for-everyone/
3https://blog.csdn.net/Jason_Lee155/article/details/137961667
4https://blog.csdn.net/weixin_48827824/article/details/132977459
5https://zhuanlan.zhihu.com/p/691709656
6https://github.com/openai/whisper
7https://github.com/RVC-Boss/GPT-SoVITS
8https://github.com/2noise/ChatTTS
9https://github.com/huggingface/speech-to-speech
10https://developer.mozilla.org/zh-CN/docs/Web/API/Web_Speech_API
11https://learn.microsoft.com/en-us/azure/ai-services/speech-service/speech-sdk