代码的移植和具体架构在实践篇可见:程序流监控 ------ AUTOSAR CP 功能安全在裸机 MCU 上的实现:实践篇-CSDN博客
引言
功能安全标准 ISO 26262 Part 6(软件层面)明确提出了多种用于错误探测的安全机制,其中程序流监控(Program Flow Monitoring)是检测软件运行时逻辑错误、时序错误和死锁的关键手段。
本文主要探讨在 AUTOSAR CP(Classic Platform)以及 AP(Adaptive Platform)两种典型架构下,如何实现程序流监控。由于 CP 平台广泛用于安全等级要求高、资源受限的 MCU 环境(如底盘、动力域),本文将以 CP 场景为重点,深入剖析其软件栈、监控原理、状态机及接口设计。
本项目旨在理论结合实践,将程序流监控的核心思想移植到一个低成本的裸机MCU平台上,构建一个轻量级但可靠的运行时监控框架。本文将分为两大部分:
-
理论篇:梳理程序流监控的核心概念、AUTOSAR WdgM架构及三种监督维度。
-
实战篇:介绍项目的背景、目标、难点及在裸机环境下的代码移植与架构设计。
第一部分:理论篇 - 程序流监控核心概念
1.1 总体工作栈
在 AUTOSAR CP 场景中,程序流监控依赖于软件与硬件的协同工作。从整体上看,其工作栈可分为硬件层和软件层两部分。
硬件部分:即通常所说的硬件看门狗(Hardware Watchdog)。它本质上是一个独立运行的定时器,初始化时被设置一个超时值(timeout)。使能后,看门狗开始倒计时。如果软件在超时前未执行"喂狗"(重置定时器),硬件将触发 MCU 复位,使系统进入安全状态。
软件部分:遵循 AUTOSAR CP 架构,从上至下包括:
-
应用/BSW层:被监控对象,通过调用WdgM_CheckpointReached()上报执行到某个"检查点"。
-
WdgM(Watchdog Manager):软件裁判-核心模块,收集各监督实体(SE)的检查点信息,执行负责监控软件运行状态,并根据结果决定是否喂狗。
-
WdgIf(Watchdog Interface):接口适配,为WdgM提供统一的喂狗接口,屏蔽底层硬件差异。
-
Wdg Driver:真正操作硬件看门狗寄存器的底层驱动。
正常流程:应用/BSW 上报运行信息(检查点)→ WdgM 判断程序流正确 → WdgM 调用 WdgIf → WdgIf 调用 Wdg Driver → 驱动执行喂狗。
异常流程:WdgM 检测到错误 → 停止喂狗或强制 timeout=0 → 硬件看门狗超时复位;也可通过 RTE 通知其他模块(如 DEM)记录故障。
1.2 核心软件模块详解
1.2.1 WdgM 模块(Watchdog Manager)
WdgM 是整个程序流监控的"裁判"。它的职责包括:
-
收集证据:接收各个被监控实体上报的"检查点"。
-
执行监督:根据配置对每个实体进行 Alive、Deadline、Logical 三种维度的判断。
-
状态管理:维护每个监督实体的本地状态,并汇总生成全局状态。
-
动作触发:若全局状态为 OK,则通过 WdgIf 喂狗;否则执行错误处理(通知 DEM、停止喂狗、立即复位等)。
关键术语:
-
SE(Supervised Entity,监督实体):被 WdgM 监控的一个软件实体,拥有唯一标识符。一个 SE 可以代表一个 SW-C(软件组件)、一个 BSW 模块、一个 CDD(复杂设备驱动)中的一个可运行实体,或者一组检查点的集合。 注:SE 与 AUTOSAR 架构模块之间无固定映射关系,完全取决于设计需要。
-
CP(Checkpoint,检查点):位于被监控实体内的一个特定位置,当程序执行到该位置时,会主动向 WdgM 报告"我已到达此处"。报告动作通过调用 WdgM_CheckpointReached(SE_ID, CP_ID) 实现。
1.2.2 三种监督维度
WdgM 通过三种互补的机制来探测程序流异常:
-
阻塞 (Alive Supervision):任务不再运行或陷入死循环。监控程序是否周期运行。
-
调度超时 (Deadline Supervision):任务运行了,但未在规定时间内完成。监控程序运行时间是否正确。
-
流程错误 (Logical Supervision):任务的执行顺序或状态机跳转非法。监控程序执行逻辑是否正确。
每种监督可独立配置于某个 SE,也可组合使用。
1.2.3 本地状态(Local Status)与全局状态(Global Status)
WdgM 的状态管理分为两个层级:
-
本地状态 --- 描述单个 SE 的程序运行状况,包含四种状态:

-
全局状态 --- 描述所有使能 SE 的整体状况,用于最终决策是否喂狗
1.3 核心工作流与状态机
1.3.1 正常程序流监控的工作流程
程序流监控的正常运行遵循一个闭环的"上报-评估-决策-动作"流程,具体步骤如下:
(1)检查点上报
被监控的软件实体(SE)在执行到预定义的检查点(CP)时,主动向 WdgM 报告"我已到达此处"。这一上报动作携带两个关键信息:哪个 SE(标识符)以及哪个 CP(标识符)。
(2)证据收集与更新
WdgM 收到上报后,根据该 SE 配置的监督类型,更新对应的运行证据:
-
若使能了 Alive 监督,则累加该 SE 在当前监控周期内的检查点出现次数。
-
若使能了 Deadline 监督,则根据上报的 CP 是"起点"还是"终点",记录时间戳或计算时间差。
-
若使能了 Logical 监督,则检查本次 CP 与上一次 CP 的转移是否在合法转移表中。
注意:此阶段仅更新证据,不立即判定错误,以避免因短时抖动导致误判。
(3)周期性评估
WdgM 由一个独立的周期时钟(例如每隔 1ms 或 5ms)触发评估任务。在每个评估周期内,WdgM 遍历所有已激活的 SE:
对于每个 SE,根据当前累积的证据,按照配置的监督规则计算其本地状态(OK / FAILED / EXPIRED / DEACTIVATED)。
具体判定逻辑:
-
Alive:比较本周期内检查点实际出现次数与期望的最小/最大次数。若在容忍范围内则 OK,否则根据缺失次数决定 FAILED 或 EXPIRED。
-
Deadline:若起点与终点之间的时间差超过了配置的最大允许值,则直接置为 EXPIRED。
-
Logical:若检查点转移非法,则直接置为 EXPIRED。
-
若某个 SE 未使能任何监督,则其本地状态为 DEACTIVATED。
(4)全局状态汇总
在完成所有 SE 的本地状态评估后,WdgM 按照以下规则汇总全局状态:
-
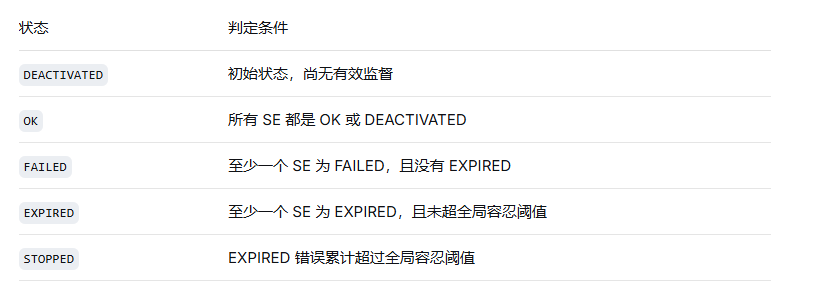
若所有 SE 均为 OK 或 DEACTIVATED → 全局状态为 OK。
-
若至少一个 SE 为 FAILED,且没有 EXPIRED → 全局状态为 FAILED。
-
若至少一个 SE 为 EXPIRED,且该 SE 的错误次数未超过全局容忍值 → 全局状态为 EXPIRED。
-
若至少一个 SE 为 EXPIRED,且错误次数超过容忍值 → 全局状态为 STOPPED。
初始状态为 DEACTIVATED。
(5)决策与动作
根据全局状态,WdgM 执行相应的动作:
-
若全局状态为 OK:则允许喂狗(通过 WdgIf 触发硬件看门狗刷新)。
-
若全局状态为 FAILED:通常仍允许喂狗,但需记录故障信息(例如通知 DEM),因为 FAILED 表示存在可容忍的 Alive 缺失,系统尚未进入危险状态。
-
若全局状态为 EXPIRED 或 STOPPED:则停止喂狗,或者强制将硬件看门狗的超时值设为 0,导致看门狗立即超时复位 MCU;同时可通过 RTE 通知其他模块执行恢复或记录故障。
1.3.2 状态机描述
(1)本地状态机(单个 SE)
每个 SE 的本地状态在评估周期内根据监督结果进行转换。标准转换规则如下:
-
DEACTIVATED → OK:当 SE 被使能且首次评估无任何错误时。
-
OK → FAILED:当出现 Alive 监督的计数缺失,但缺失次数仍在配置的容忍值以内。
-
FAILED → OK:当后续评估周期中 Alive 计数恢复正常(例如缺失次数归零)。
-
FAILED → EXPIRED:当 Alive 缺失次数累积超过容忍值,或者出现 Deadline/Logical 错误。
-
OK → EXPIRED:直接出现 Deadline 或 Logical 错误。
-
任何状态 → DEACTIVATED:当 SE 被动态去使能。
(2)全局状态机(系统级)
全局状态由所有 SE 的本地状态汇总决定,其转换规则如下:
-
DEACTIVATED → OK:至少一个 SE 被使能且其本地状态为 OK,其余为 DEACTIVATED。
-
OK → FAILED:至少一个 SE 进入 FAILED 状态,且没有 SE 为 EXPIRED。
-
FAILED → OK:所有 FAILED 的 SE 恢复为 OK。
-
FAILED → EXPIRED:至少一个 SE 进入 EXPIRED 状态,且错误次数未超限。
-
EXPIRED → STOPPED:某个 SE 的 EXPIRED 错误累积次数超过全局容忍值。
-
STOPPED → (复位):系统通常触发硬件复位,或进入安全状态后不再恢复。
第二部分:AP 场景下的程序流监控(简述)
AP 场景(Adaptive Platform)通常运行在 POSIX/Linux 类系统上,面向高性能计算(如自动驾驶)。其程序流监控架构如图 9 所示。
软件模块:主要由 PHM(Platform Health Management)执行监控,SM(State Management)管理状态,EM(Execution Management)负责进程/平台重启。
故障处理链路:
-
链路一:PHM 检测错误 → 报告 SM → SM 执行注册的处理程序(停止/重启应用)。
-
链路二:若 SM 超时无响应 → PHM 直接通知 EM → EM 执行停止/重启/平台复位。
-
链路三:若 EM 也出错 → PHM 触发硬件看门狗复位整个平台。
AP 场景中的监控术语(SE、Checkpoint)和状态机(本地/全局状态)与 CP 基本一致,故不再赘述。
第三部分:程序流监控总结
程序流监控的核心目标是在运行时及时发现软件执行的非预期行为(逻辑错、时序错、死锁),并通过硬件看门狗这一安全可靠的最后防线,将系统引导至安全状态。
-
CP 场景:依赖 WdgM、WdgIf、WdgDriver 三层结构,适合资源受限、实时性要求高的 MCU。
-
AP 场景:依赖 PHM、SM、EM 模块,适合复杂操作系统环境下的进程级健康管理。
但需要注意的是,仅仅理解软件模块和硬件看门狗是不够的。实际工程中必须结合系统设计参数(如故障处理时间间隔 FHTI,Fault Handling Time Interval)来正确配置:
-
看门狗的超时时间(应大于最大正常执行时间,小于 FHTI)
-
监督周期与任务周期的匹配
-
Alive 的容忍次数与 Deadline 的裕量
只有软硬件参数协同优化,才能达到最优的程序流监控效果。