做故障诊断、时间序列预测,你是不是还默认把 ResNet 当成第一选择?
这当然没错。ResNet 经典、稳定、好用,到今天依然是很多工业场景里的强基线。
但问题是:
如果你的模型认知还停留在 ResNet,那你看到的,只是视觉网络发展史中的一小段。
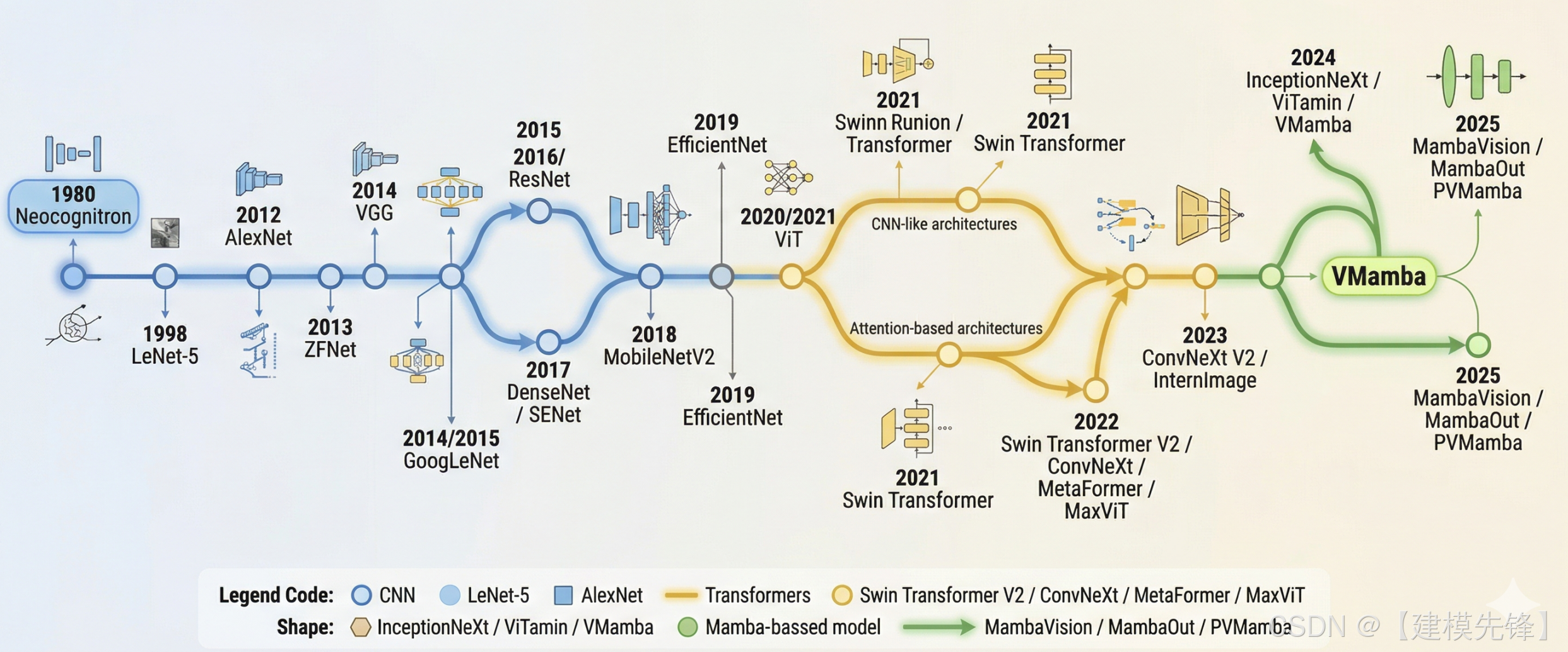
如果把现代计算机视觉的发展压缩成一条主线,那么最值得反复回看的,不是某一个单独模型,而是视觉主干网络(backbone)如何一步步演化:从早期卷积网络建立"局部感受野 + 参数共享 + 层级特征"的视觉归纳偏置,到 ImageNet 时代把 CNN 推上主舞台,再到 Transformer 打开新的视觉建模范式,最后进入卷积、注意力、状态空间模型并行发展的新阶段。
卷积网络的根本价值,不只是"能做图像分类",而是它把视觉任务中最核心的结构性先验直接写进了模型:局部感受野、参数共享、层级特征提取、一定程度的平移鲁棒性。这类归纳偏置让它在图像领域天然比纯全连接结构更高效。早期的 Neocognitron 已经体现了这种思想,而 LeNet-5 则把它真正落成了可通过反向传播训练的工程系统。
如果从历史演进看,视觉 backbone 大致经历了五个阶段:
思想原型期 (Neocognitron/LeNet)→ 深度学习复兴期 (AlexNet/ZFNet/VGG)→ 结构成熟期 (GoogLeNet/ResNet/DenseNet)→ 高效化与注意力增强期 (SENet/MobileNet/EfficientNet)→ Transformer 与后 Transformer 时期(ViT/Swin/ConvNeXt/VMamba 等)。这个脉络,基本就是过去二十多年视觉模型发展的主轴。
1 Neocognitron:卷积网络思想的源头
(1)论文题目:Neocognitron: A Self-Organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position(1980)
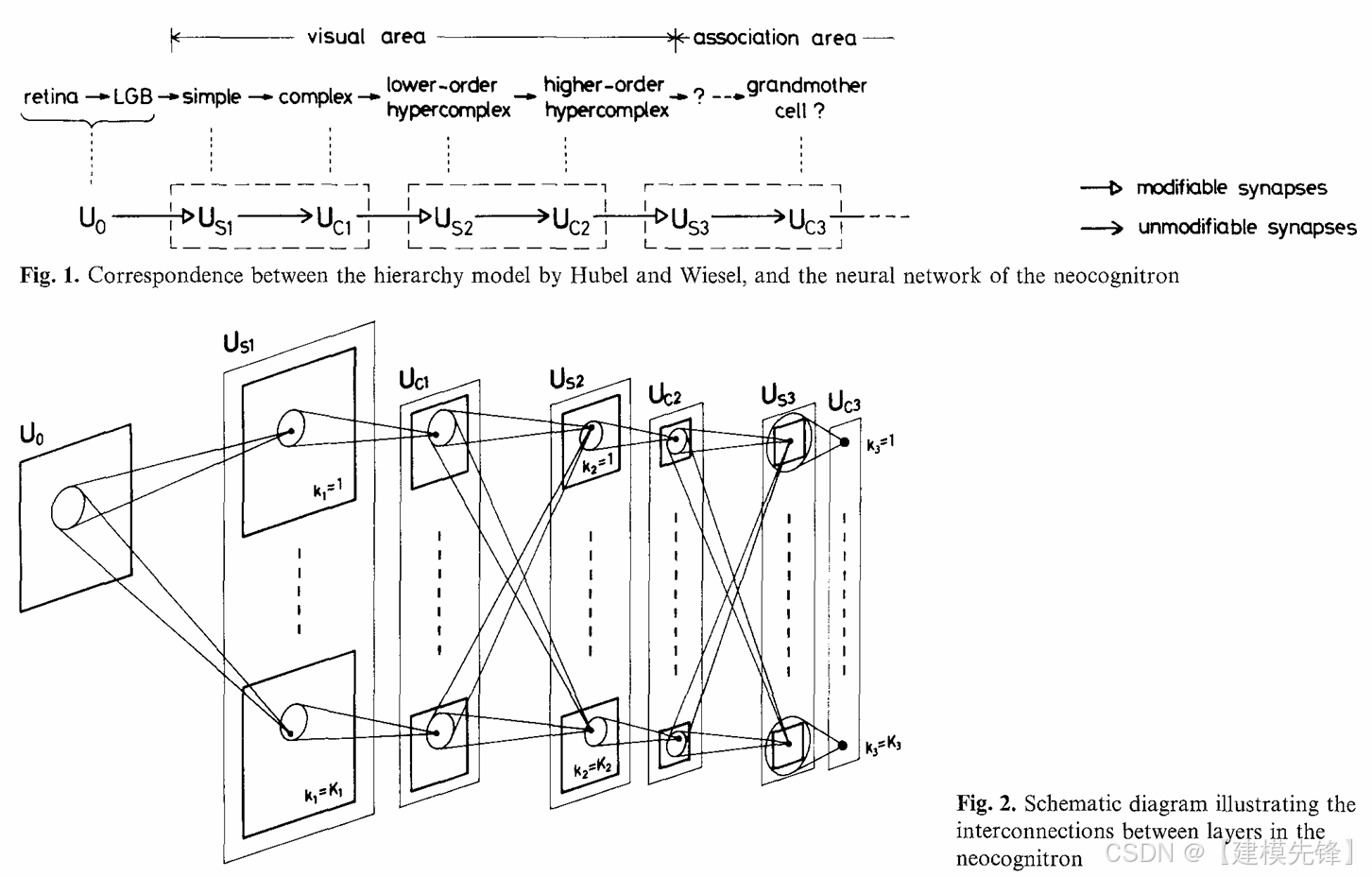
(2)模型简介:
Neocognitron 并不是现代深度学习框架下的 CNN,但它非常重要,因为它最早系统化地提出了分层感受野、局部连接、位置鲁棒性这类思想。后来的卷积网络很多基本设计,都能在这里找到原型。它更像是"卷积网络的思想起点",而不是今天工程意义上的可训练标准模型。
核心思想:用层级结构逐步抽取局部模式,并让模型对位移具有一定鲁棒性。
(3)论文链接:
https://link.springer.com/article/10.1007/BF00344251
开源代码:
https://github.com/lcpo/neocognitron
2 LeNet-5:现代 CNN 的工程起点
(1)论文题目:Gradient-Based Learning Applied to Document Recognition(1998)
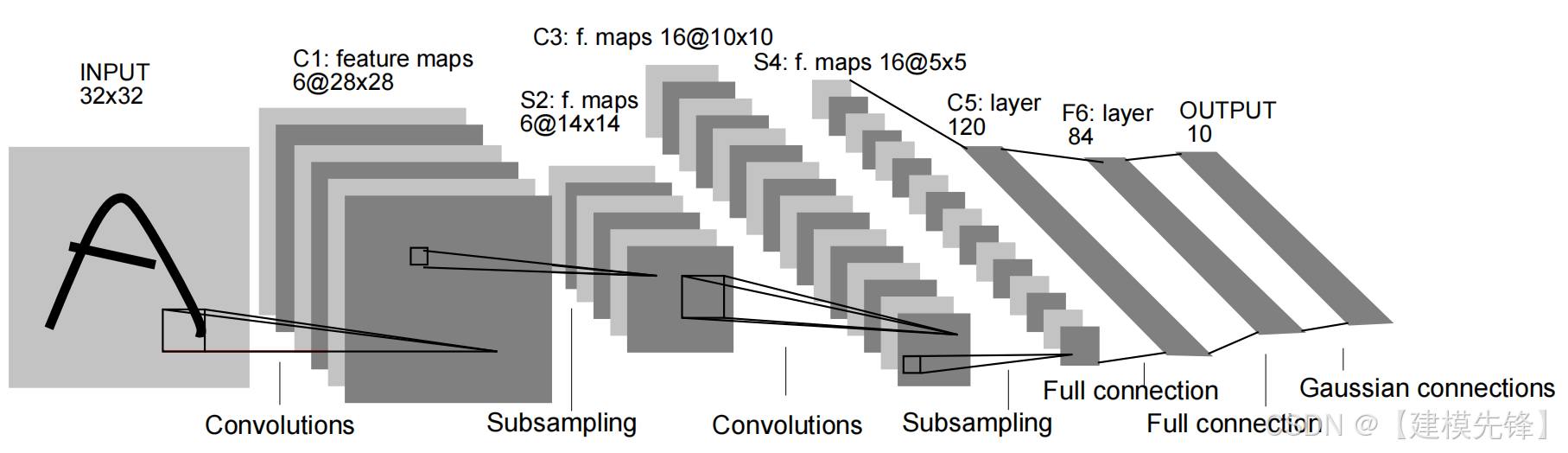
(2)模型简介:
LeNet-5 是现代卷积网络真正意义上的起点。它把卷积层、下采样层和全连接层组合成一个端到端可训练系统,主要用于手写数字识别。今天回看,LeNet 很小、很浅,但它定义了后来 CNN 的基本流水线。
核心思想:用卷积提取局部空间特征,用下采样减少分辨率和参数量,最后用全连接完成分类。
(3)论文链接:
https://ieeexplore.ieee.org/abstract/document/726791
开源代码:
https://github.com/0x7dc/LeNet-5
3 AlexNet:深度学习复兴的标志
(1)论文题目:ImageNet Classification with Deep Convolutional Neural Networks(2012)
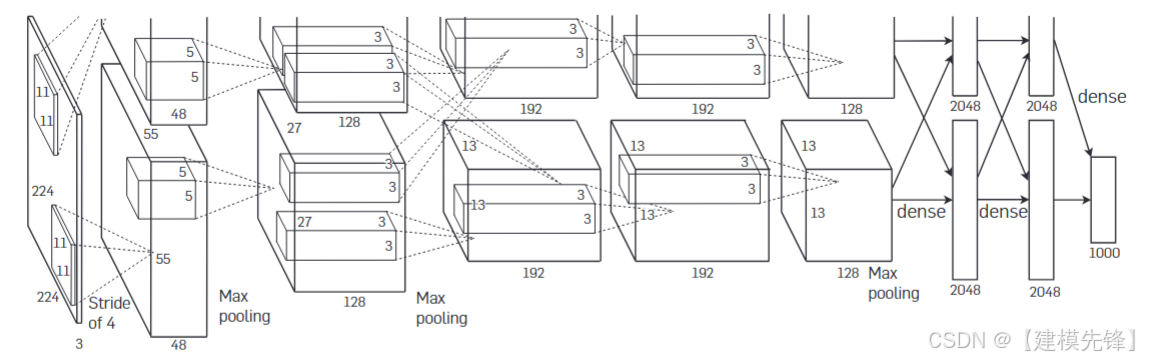
(2)模型简介:
AlexNet 的意义不在于"第一个 CNN",而在于它第一次在大规模 ImageNet 分类上,用深卷积网络显著拉开了与传统方法的差距。ReLU、Dropout、数据增强、GPU 训练,这些今天看来很常规的设计,在 AlexNet 这里被系统组合到一起,直接引爆了深度学习视觉时代。
核心思想:更深的卷积网络 + 大规模数据 + GPU 加速训练。
(3)论文链接:
https://dl.acm.org/doi/epdf/10.1145/3065386
开源代码:
https://github.com/computerhistory/AlexNet-Source-Code
4 ZFNet:第一次系统解释 CNN 在学什么
(1)论文题目:Visualizing and Understanding Convolutional Networks(2013)
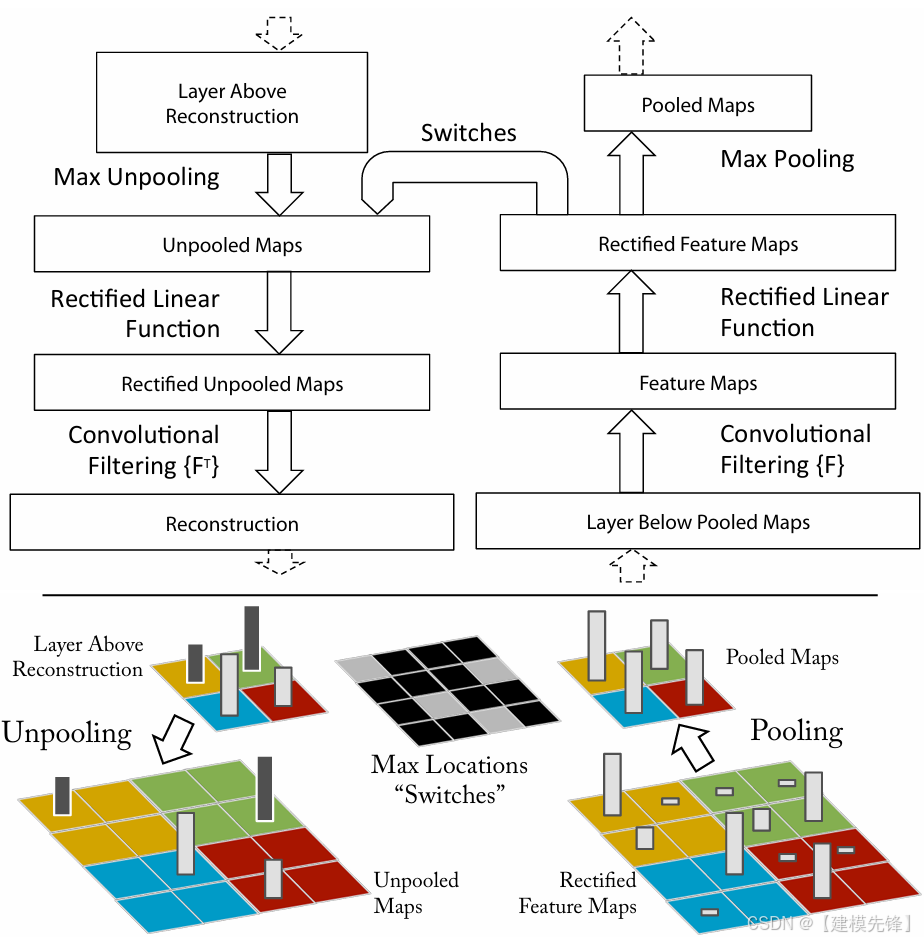
(2)模型简介:
ZFNet 可以看作 AlexNet 的一次结构微调,但它真正的贡献,是通过反卷积可视化解释了卷积网络各层到底在响应什么。这让研究者第一次比较系统地"看见"了 CNN 的中间特征,也推动了后续架构设计更加精细。
核心思想:通过 deconvnet 可视化中间层特征,同时改进 AlexNet 前层卷积核和步长设置。
(3)论文链接:
https://arxiv.org/abs/1311.2901
开源代码:
https://github.com/amir-saniyan/ZFNet
5 VGG:把"堆深"做得最整齐的一代网络
(1)论文题目:Very Deep Convolutional Networks for Large-Scale Image Recognition(2014)
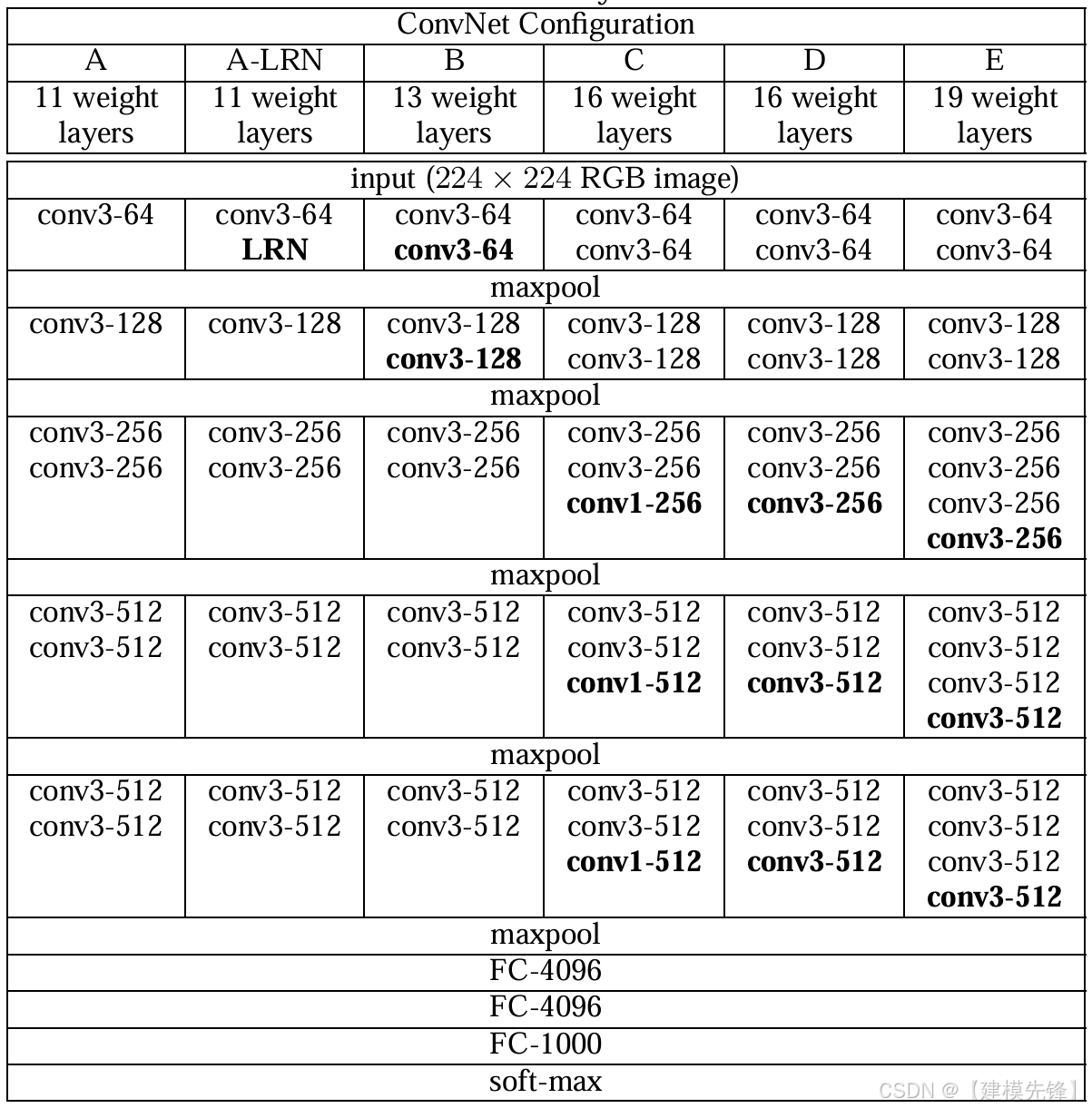
(2)模型简介:
VGG 的贡献非常纯粹:统一使用 3×3 小卷积核,不断加深网络。它没有 Inception 的复杂分支,也没有 ResNet 的捷径连接,但正因为结构规整,VGG 成了一个时代里最容易理解、最容易做迁移学习的 backbone。
核心思想:用多个 3×3 卷积堆叠来扩大感受野,同时保持架构统一。
(3)论文链接:
https://arxiv.org/abs/1409.1556
开源代码:
https://github.com/Prabhu204/Very-Deep-Convolutional-Networks-for-Large-Scale-Image-Recognition
6 GoogLeNet / Inception v1:多尺度分支的开始
(1)论文题目:Going Deeper with Convolutions(2015)
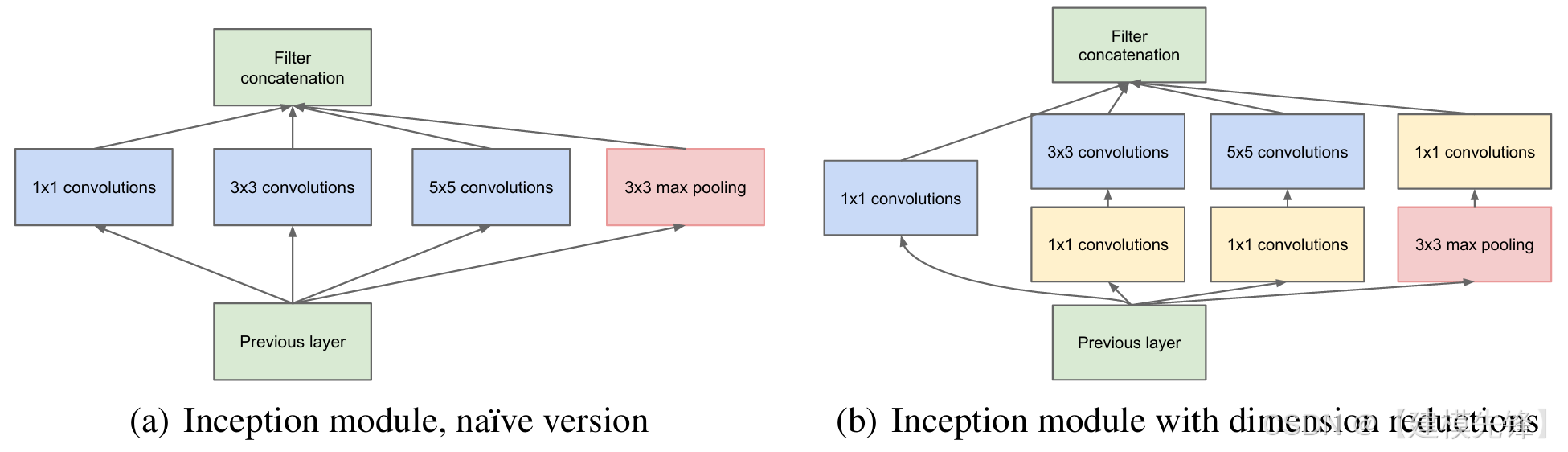
(2)模型简介:
GoogLeNet 的关键创新是 Inception 模块:在同一层中并行使用 1×1、3×3、5×5 卷积和池化,然后把结果拼接。这等于把"多尺度特征提取"显式写进网络结构中,同时通过 1×1 卷积控制参数量。它标志着 CNN 设计从"单一路径堆深"走向"结构化多分支设计"。
核心思想:多尺度并行卷积 + 1×1 降维。
(3)论文链接:
https://arxiv.org/abs/1409.4842
开源代码:
https://github.com/pytorch/vision
7 ResNet:解决"网络越深越难训练"的关键一跳
(1)论文题目:Deep Residual Learning for Image Recognition(2016)
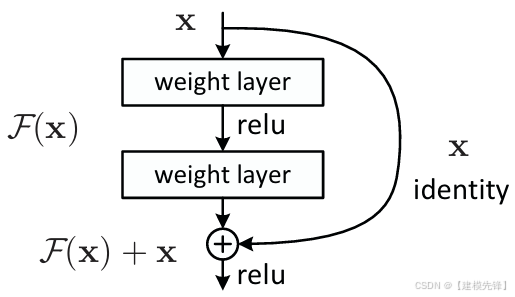
(2)模型简介:
ResNet 是视觉网络发展史上最重要的论文之一。它提出了残差连接,直接把深网络训练问题从"堆不动"变成"可以继续堆"。很多人记住的是 ResNet-50/101/152,但真正要记住的是这条公式:
y=F(x)+x
它让网络学习残差,而不是直接学习完整映射。这个简单改动,极大改善了优化难度。
核心思想:多shortcut / skip connection,使深层网络更容易优化。
(3)论文链接:
https://arxiv.org/pdf/1512.03385
开源代码:
https://github.com/KaimingHe/deep-residual-networks
8 DenseNet:把特征复用推到极致
(1)论文题目:Densely Connected Convolutional Networks(2017)
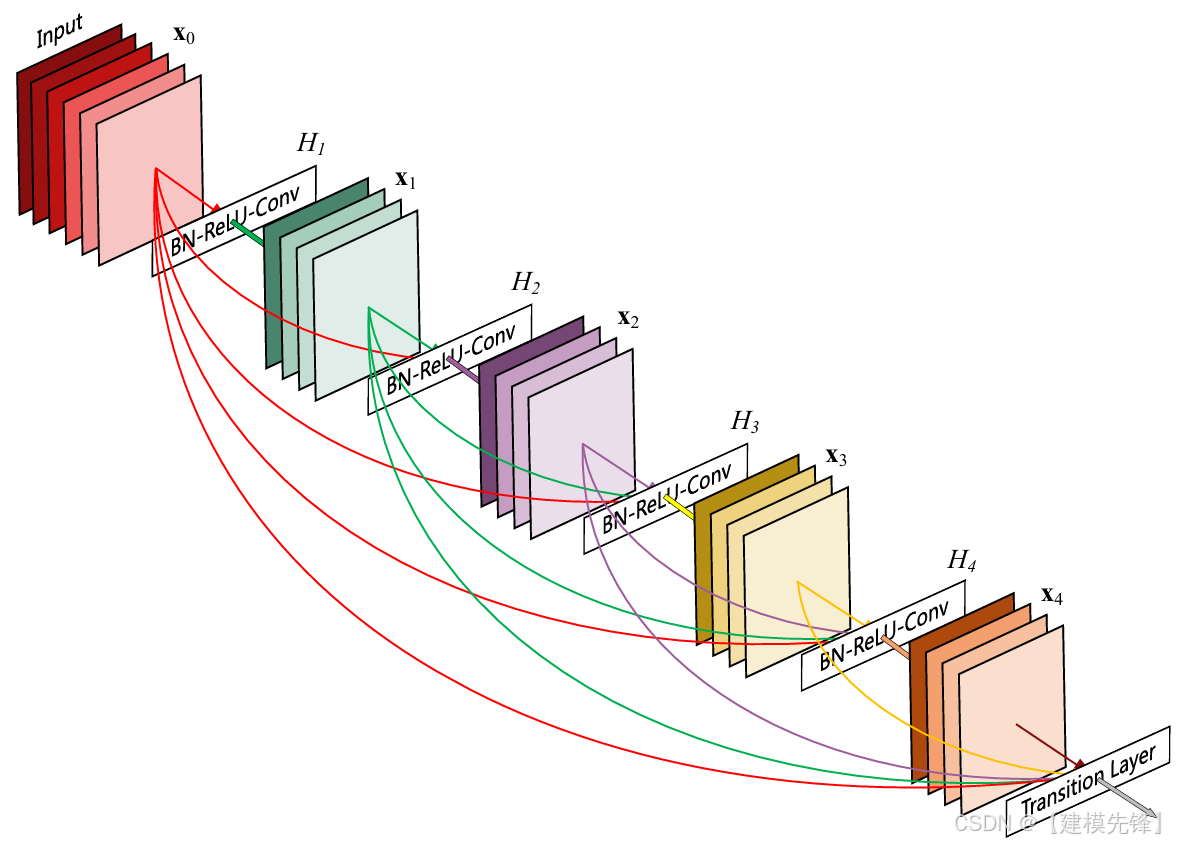
(2)模型简介:
DenseNet 的思路是:每一层都接收前面所有层的特征,形成密集连接。它的典型表达是:
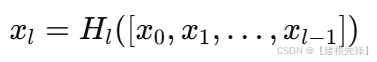
这里的 \[\] 表示特征拼接。相比 ResNet 的"相加",DenseNet 走的是"拼接与复用"。这样做能强化梯度传播和特征复用,也让模型在参数效率上很突出。
核心思想:层间密集连接,鼓励特征复用,缓解梯度消失。
(3)论文链接:
https://arxiv.org/abs/1608.06993
开源代码:
https://github.com/liuzhuang13/DenseNet
9 SENet:把"通道注意力"引入主流视觉网络
(1)论文题目:Squeeze-and-Excitation Networks(2018)
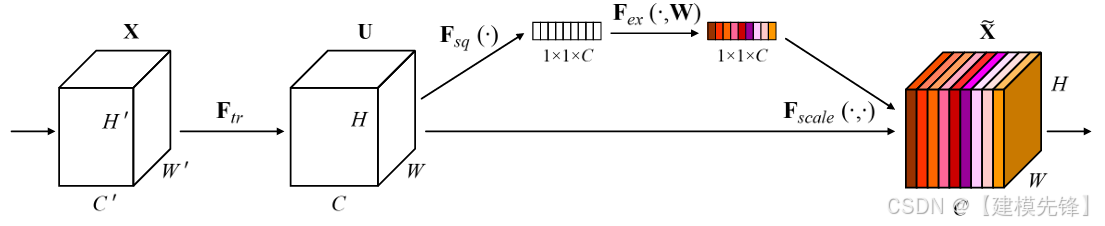
(2)模型简介:
SENet 的重要性在于,它提出了一个非常轻量但非常有效的模块:SE block。它先对空间维度做全局压缩,再学习通道间依赖关系,最后对通道权重进行重标定。换句话说,它解决的是"哪些通道更重要"这个问题。
核心思想:显式建模通道关系,进行特征重标定。
(3)论文链接:
https://arxiv.org/abs/1709.01507
开源代码:
https://github.com/hujie-frank/SENet
10 MobileNetV2:轻量化 CNN 的工程范式
(1)论文题目:MobileNetV2: Inverted Residuals and Linear Bottlenecks(2018)
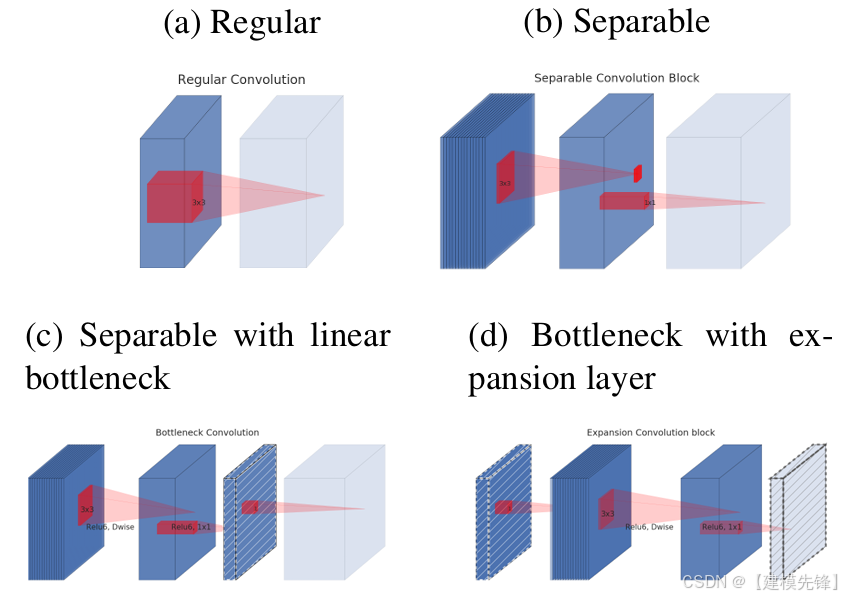
(2)模型简介:
MobileNetV2 面向的是移动端和边缘端部署。它最关键的设计是 depthwise separable convolution + inverted residual + linear bottleneck。这让模型在保持较好性能的同时,大幅减少参数量和计算量。对于工程落地,这类模型的意义非常大。
核心思想:轻量卷积、反残差结构、线性瓶颈。
11 EfficientNet:把网络缩放方法系统化
(1)论文题目:EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks(2019)
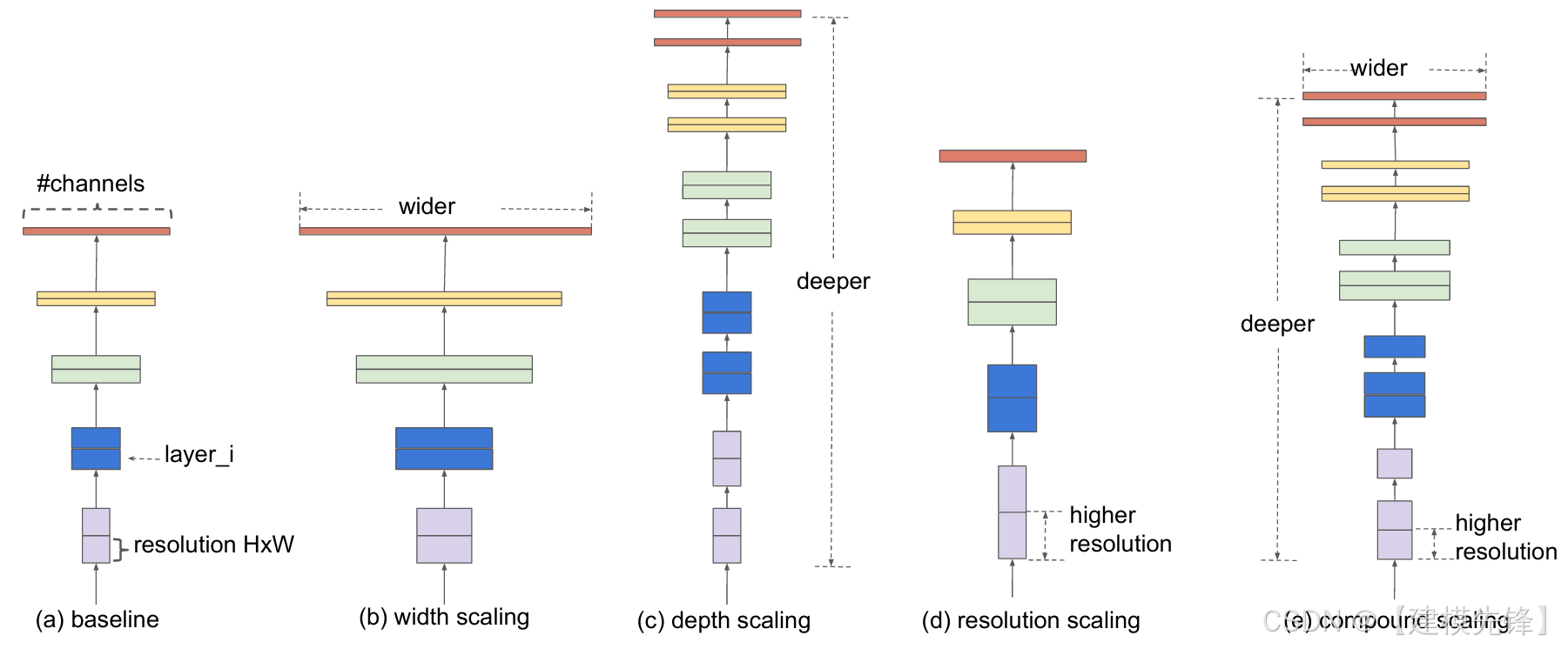
(2)模型简介:
在 EfficientNet 之前,大家通常是单独加深网络、加宽网络,或者提高输入分辨率。EfficientNet 的关键是提出了 compound scaling:统一协调深度、宽度和分辨率三者的缩放,而不是只调其中一个维度。它代表了 CNN 时代在"效率---精度权衡"上的一次系统化总结。
核心思想:复合缩放,而不是单维度粗暴扩张。
(3)论文链接:
https://arxiv.org/abs/1905.11946
开源代码:
https://github.com/sd2001/EfficientNet
12 ViT:视觉模型第一次大规模脱离卷积
(1)论文题目:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale(2021)
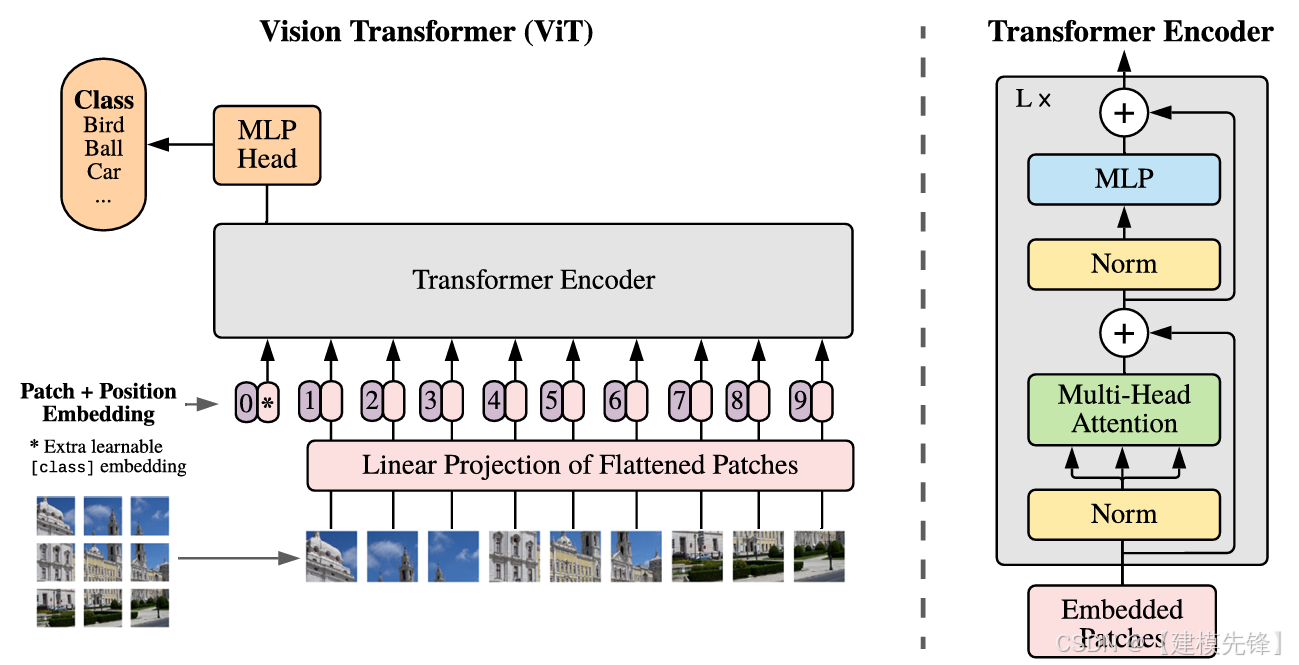
(2)模型简介:
ViT 的关键不是"引入注意力",而是直接把图像切成 patch,当作 token 输入纯 Transformer 编码器。这等于第一次明确提出:视觉分类并不一定需要卷积作为主干。它的出现标志着视觉 backbone 的范式发生了根本变化。
核心思想:Patchify 图像,把分类问题改写成 token 序列建模。
(3)论文链接:
https://arxiv.org/abs/2010.11929
开源代码:
https://github.com/gupta-abhay/pytorch-vit
13 Swin Transformer:真正可做通用视觉骨干的 Transformer
(1)论文题目:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(2021)
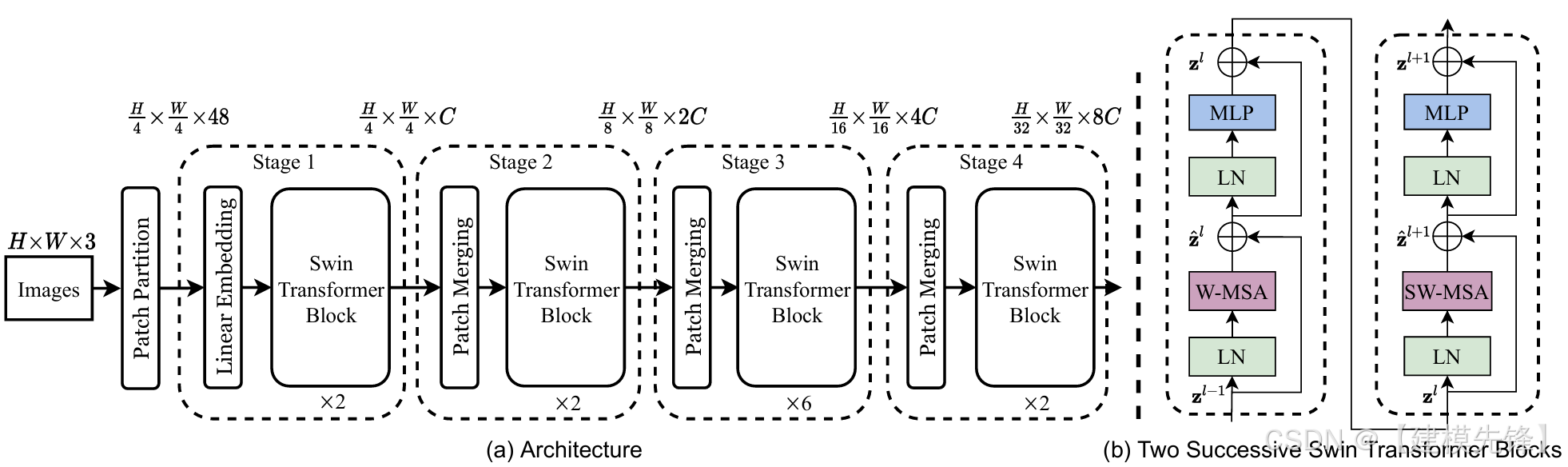
(2)模型简介:
ViT 在分类上很强,但直接迁移到检测和分割并不自然。Swin Transformer 通过层级特征图 + 窗口注意力 + shifted windows,重新引入了很多原本属于 CNN 的多尺度先验,使 Transformer 真正成为可泛化到检测、分割等任务的通用 backbone。
核心思想:层级化表示 + 局部窗口注意力 + 跨窗口交互。
(3)论文链接:
https://arxiv.org/abs/2103.14030
开源代码:
https://github.com/durongzheng/Swin
14 RepLKNet:大核卷积在 Transformer 时代的强势回归
(1)论文题目:Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs(2022)
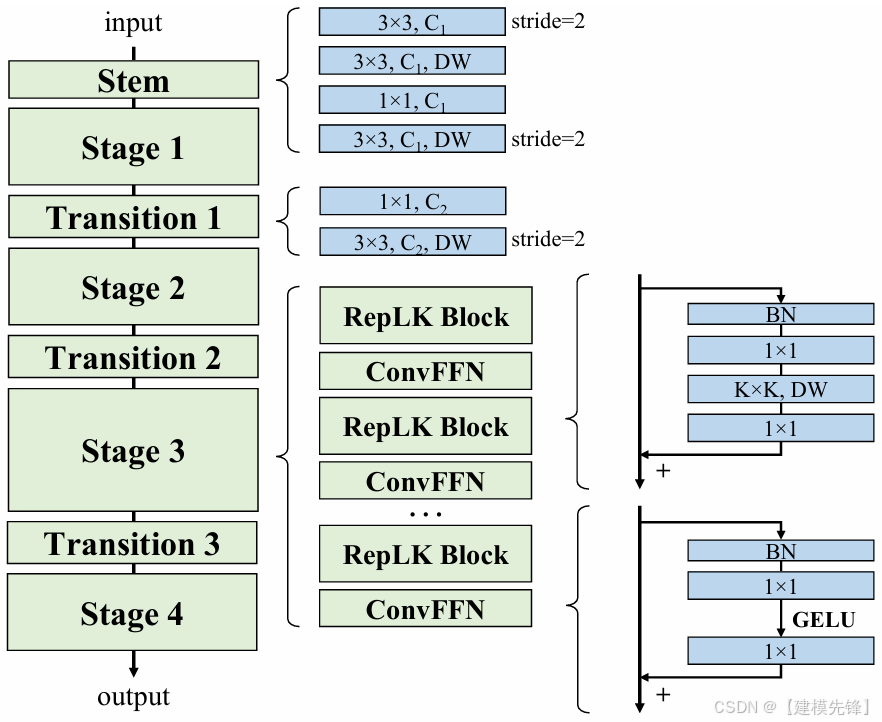
(2)模型简介:
RepLKNet 是 CVPR 2022 一篇非常值得单独写进发展史的论文。它重新讨论了一个看似"老问题"、但在 Transformer 时代又变得很关键的话题:卷积核到底能不能做大,而且做大以后是否真的有价值。 作者在论文中提出,少量大卷积核并不只是"小卷积核堆叠"的低效替代,相反,在现代 CNN 设计中,大核可能是一种更强的范式。基于这一判断,论文提出了 RepLKNet ,其核心特征是使用可重参数化的大型 depth-wise 卷积,并把卷积核尺度扩展到 31×31。
核心思想:RepLKNet 的关键不是单纯把卷积核变大,而是围绕"大核 CNN"提出了一套设计准则,并结合 re-parameterized large depth-wise convolution 构建纯 CNN 主干。
(3)论文链接:
https://arxiv.org/abs/2203.06717
开源代码:
https://github.com/MegEngine/RepLKNet
15 ConvNeXt:Transformer 时代下的卷积复兴代表作
(1)论文题目:A ConvNet for the 2020s(2022)
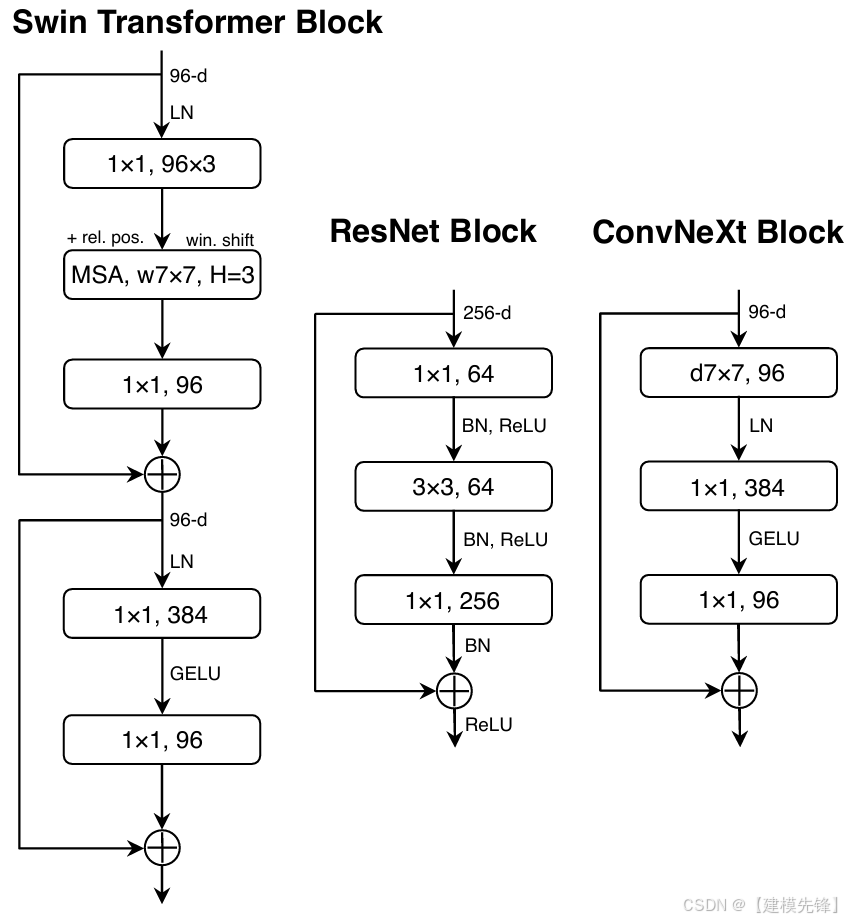
(2)模型简介:
ConvNeXt 的意义非常大。它不是发明一个全新的卷积算子,而是系统性地回答一个问题:如果把 ViT 时代有效的训练和设计经验重新用于纯卷积网络,会发生什么? 论文通过逐步"现代化"ResNet,最终得到 ConvNeXt,并证明纯 ConvNet 依然可以与强势 Transformer backbone 竞争。
核心思想:用 Transformer 时代的设计经验重构经典 ConvNet,使其在保持卷积先验的同时获得更强性能。
(3)论文链接:
https://arxiv.org/abs/2201.03545
开源代码:
https://github.com/facebookresearch/ConvNeXt
16 PoolFormer / MetaFormer:把视觉网络提升到"结构范式"层面
(1)论文题目:MetaFormer Is Actually What You Need for Vision(2022)
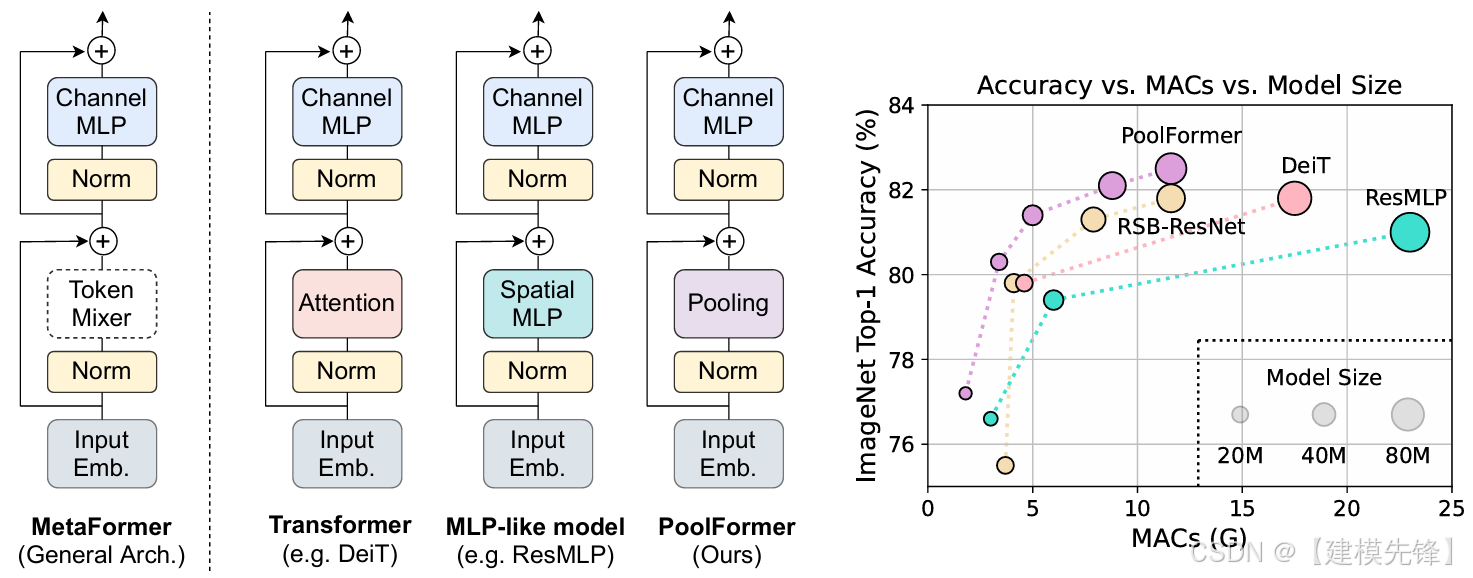
(2)模型简介:
这篇论文的重要性不在于 PoolFormer 本身有多强,而在于它提出了一个更抽象的判断:很多视觉模型成功的关键,可能不在于注意力这个具体 token mixer,而在于更高层的 MetaFormer 框架。论文用极其简单的 pooling 代替 attention,结果依然能得到很有竞争力的效果。
核心思想:真正重要的可能是"MetaFormer 骨架"本身,而不是某一种特定的 token mixing 算子。
(3)论文链接:
https://arxiv.org/abs/2111.11418
开源代码:
https://github.com/sail-sg/poolformer
17 MaxViT:局部与全局注意力的混合层级视觉骨干
(1)论文题目:MaxViT: Multi-Axis Vision Transformer(2022)
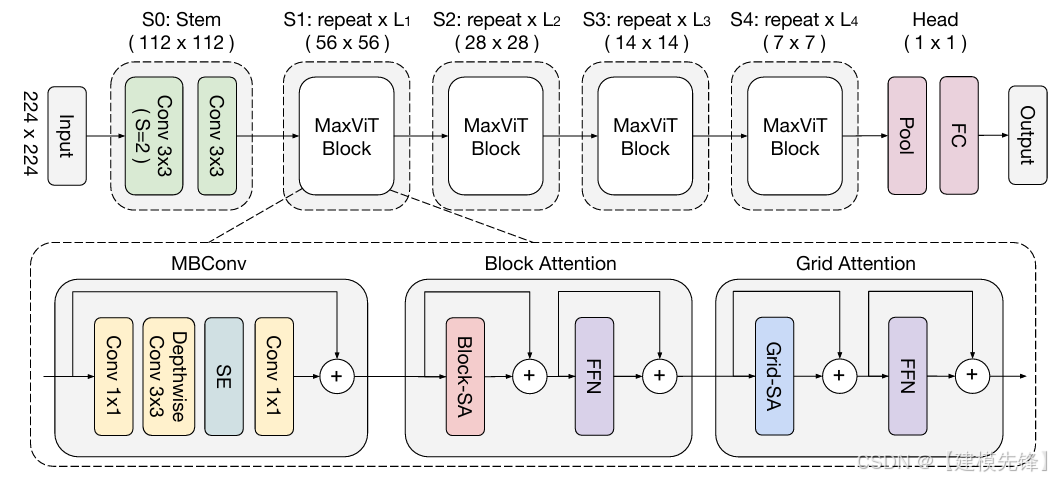
(2)模型简介:
MaxViT 是后 Swin 时代非常有代表性的层级 Transformer。它通过 blocked local attention + dilated global attention 在同一个 block 中同时建模局部和全局关系,并保持线性复杂度。相比"只做窗口注意力"的方案,MaxViT 更强调全局-局部交互的统一。
核心思想:将局部注意力和稀疏全局注意力结合,构建可扩展的层级视觉 Transformer。
(3)论文链接:
https://arxiv.org/abs/2204.01697
开源代码:
https://github.com/google-research/maxvit
18 InternImage:以可变形卷积为核心的大规模 CNN 骨干
(1)论文题目:InternImage: Exploring Large-Scale Vision Foundation Models With Deformable Convolutions(2023)
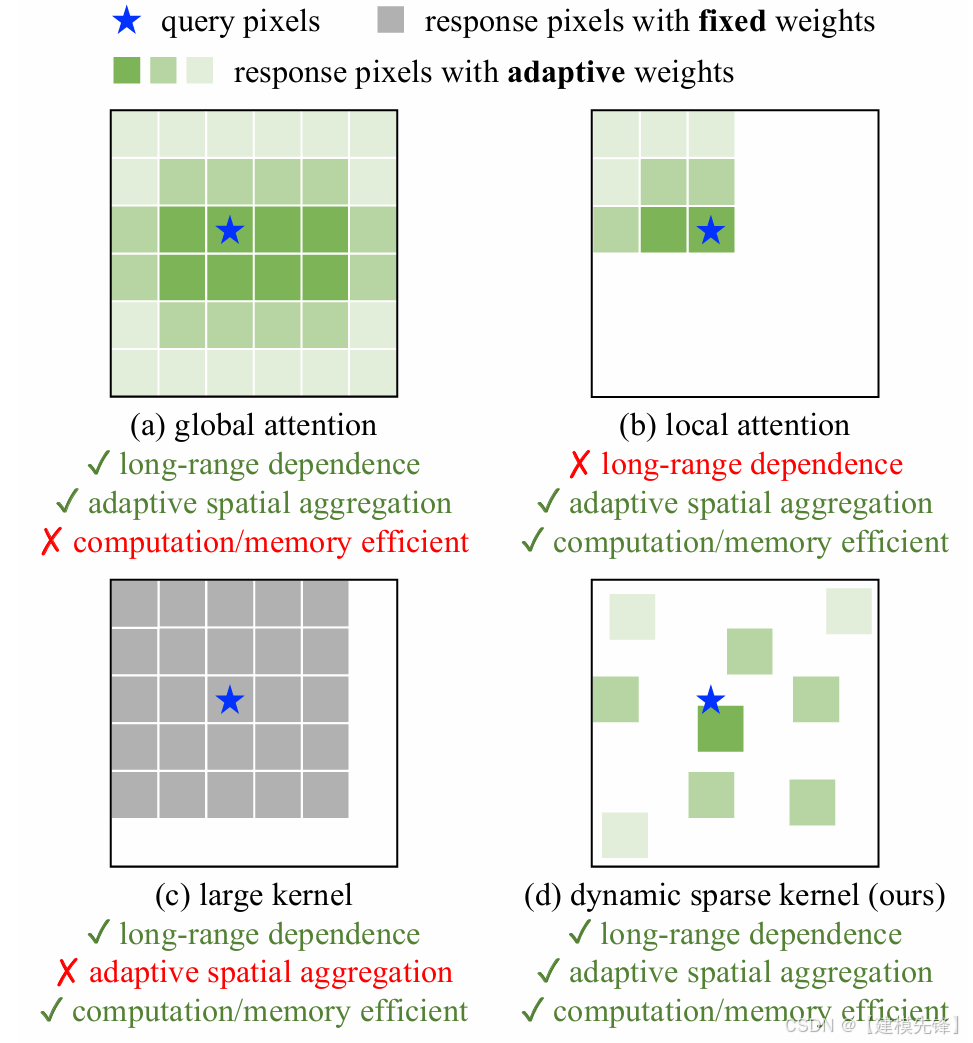
(2)模型简介:
InternImage 是卷积路线中非常值得单独写的一篇论文。它没有走大核卷积路线,而是把 deformable convolution 作为核心算子,试图让 CNN 也具备类似 ViT 的大感受野与输入自适应空间聚合能力,从而构建面向 foundation model 时代的大规模 CNN。
核心思想:利用可变形卷积提升 CNN 的空间自适应建模能力和有效感受野。
(3)论文链接:
https://arxiv.org/abs/2211.05778
开源代码:
https://github.com/OpenGVLab/InternImage
19 InceptionNeXt:经典 Inception 思想在现代 ConvNet 中的再生
(1)论文题目:InceptionNeXt: When Inception Meets ConvNeXt(2024)
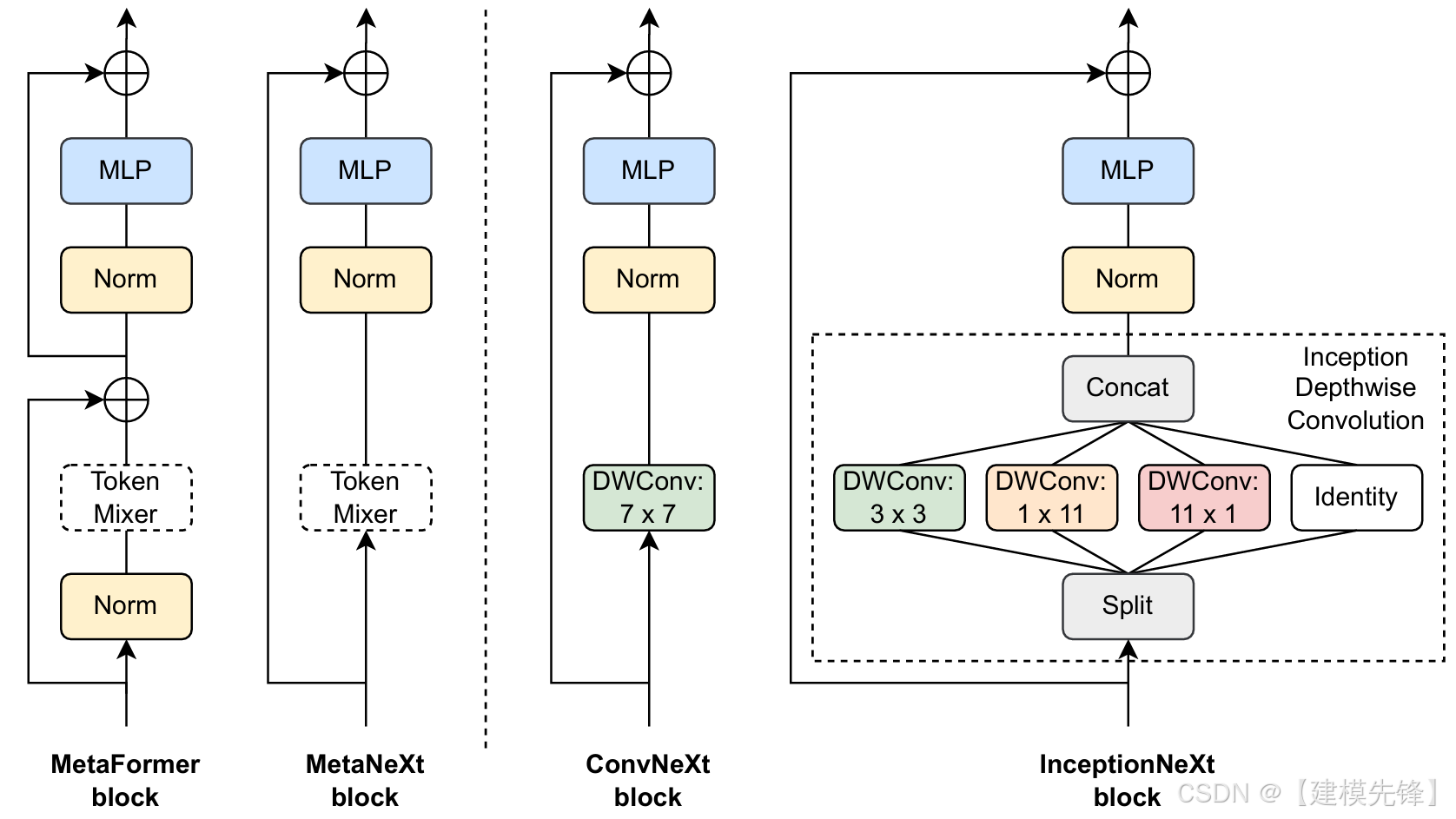
(2)模型简介:
InceptionNeXt 可以理解为"把 GoogLeNet/Inception 的多分支思想重新带回 ConvNeXt 时代"。论文从 ConvNeXt 出发,尝试改造其中较重的 depthwise convolution 模块,在兼顾精度的同时提高效率,是一种"经典结构思想现代化"的代表案例。
核心思想:将 Inception 风格的分支式局部建模思想与现代 ConvNeXt 设计结合起来。
(3)论文链接:
https://arxiv.org/abs/2303.16900
开源代码:
https://github.com/sail-sg/inceptionnext
20 ViTamin:视觉-语言时代的可扩展视觉编码器
(1)论文题目:ViTamin: Designing Scalable Vision Models in the Vision-Language Era(2024)
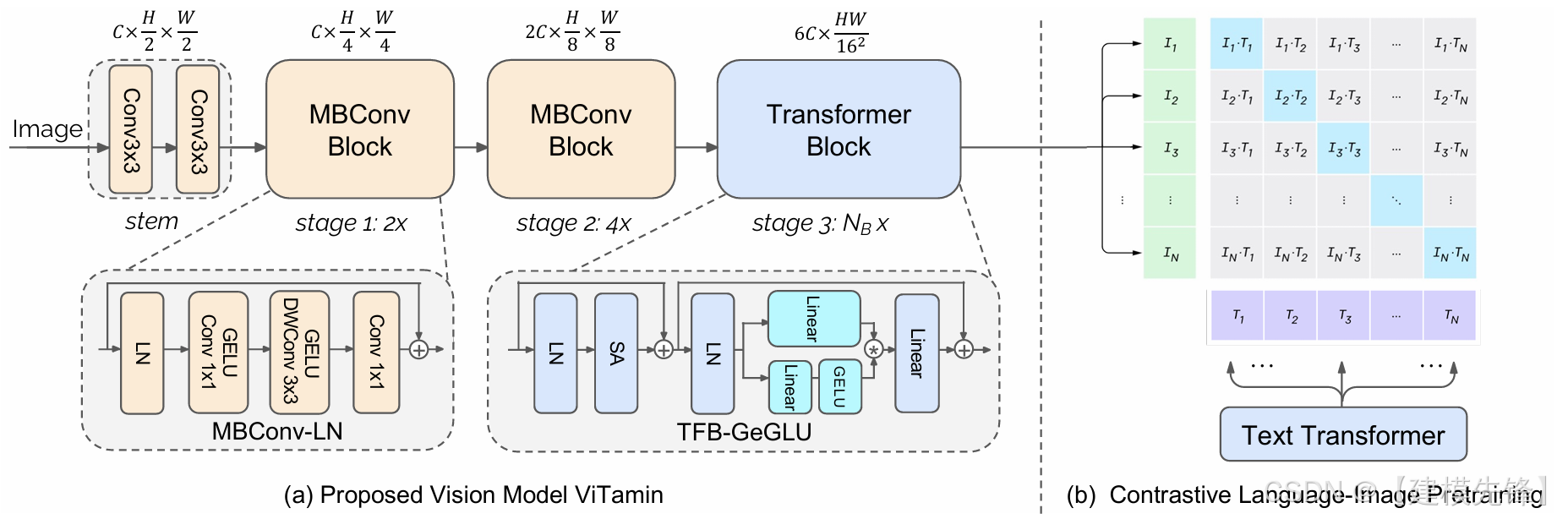
(2)模型简介:
ViTamin 的特殊性在于,它不再只面向传统 ImageNet 分类,而是把视觉 backbone 的设计问题放到 Vision-Language Model(VLM)时代 来重新讨论。它更关心的是:在大规模图文预训练和开放词汇任务背景下,视觉编码器应该如何扩展。
核心思想:面向视觉-语言预训练范式,设计可扩展、高迁移性的视觉编码器。
(3)论文链接:
https://arxiv.org/abs/2404.02132
开源代码:
https://beckschen.github.io/vitamin.html
21 VMamba:视觉主干开始进入状态空间模型时代
(1)论文题目:VMamba: Visual State Space Model(2024)
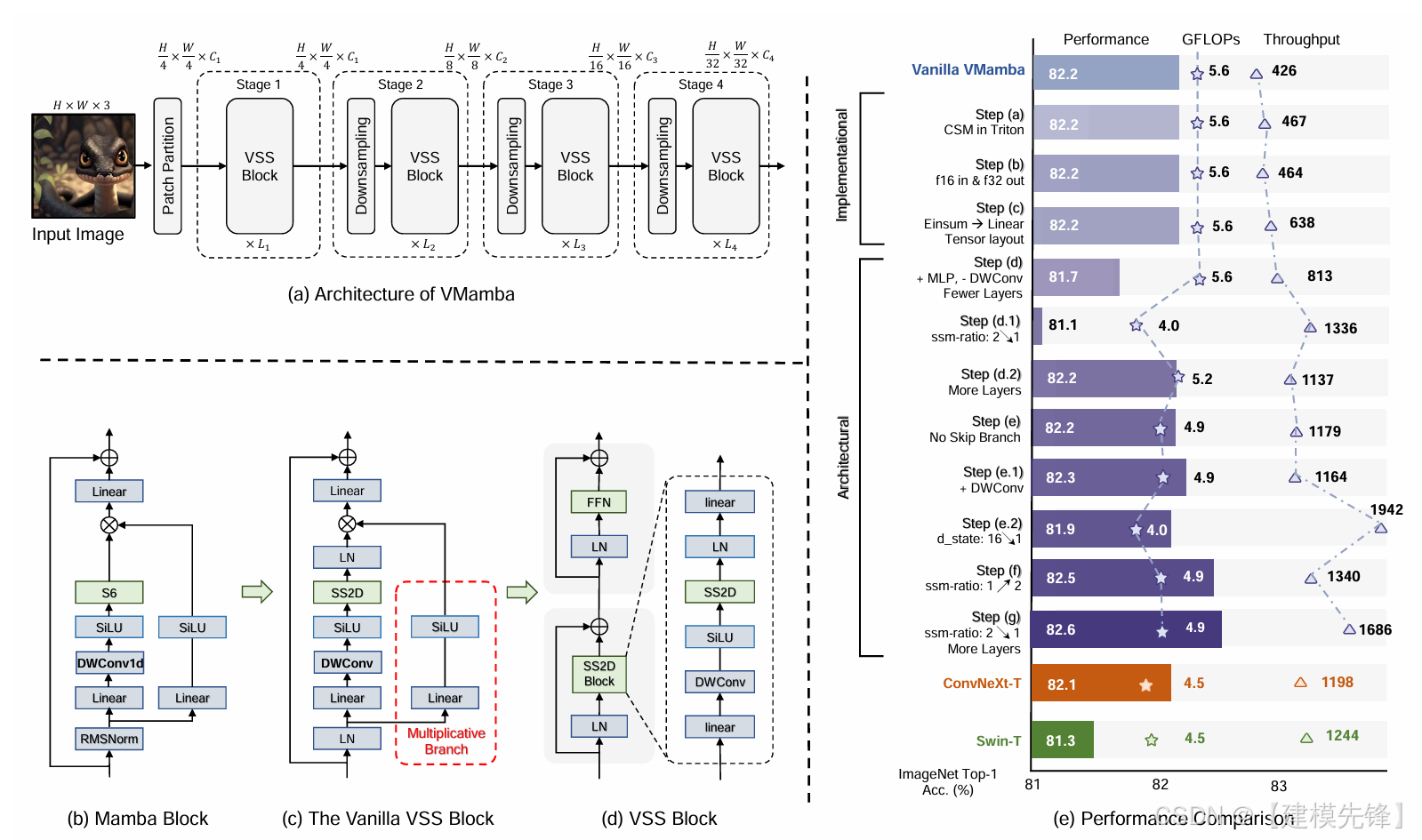
(2)模型简介:
VMamba 是后 Transformer 时代非常重要的一篇论文。它把语言领域的 Mamba/SSM 思路引入视觉 backbone,提出了 Visual State-Space(VSS)block 和 2D Selective Scan(SS2D) 模块,试图用线性复杂度方式处理视觉长序列建模问题。
核心思想:将状态空间模型从语言迁移到视觉,构建线性复杂度的视觉骨干。
(3)论文链接:
https://arxiv.org/abs/2401.10166
开源代码:
https://github.com/MzeroMiko/VMamba
22 MambaVision:Mamba 与 Transformer 的混合视觉骨干
(1)论文题目:MambaVision: A Hybrid Mamba-Transformer Vision Backbone(2025)
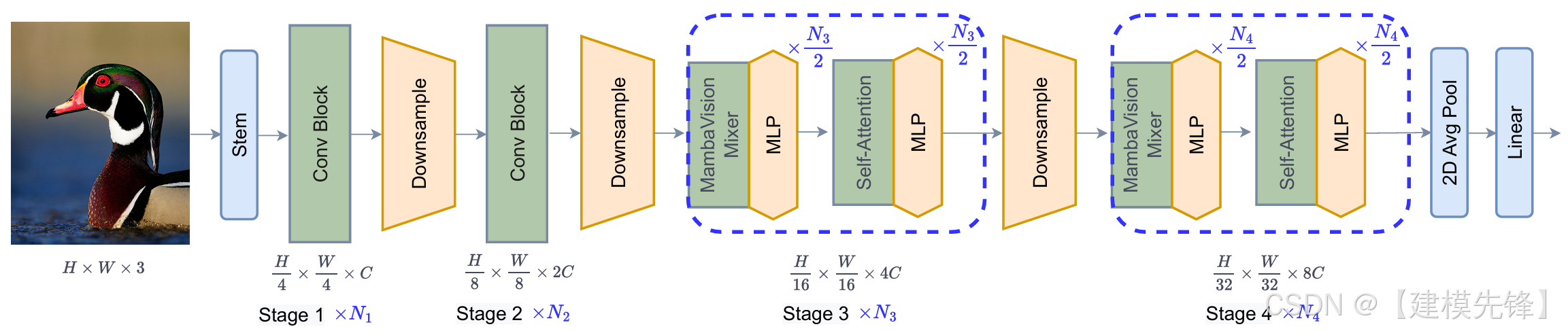
(2)模型简介:
MambaVision 的代表性在于,它没有走"纯 Mamba 替代 Transformer"的极端路线,而是采用 Mamba + Transformer 的混合架构。这反映出一个现实趋势:在视觉任务中,研究者更关注不同机制之间的互补,而不是简单押注单一范式。
核心思想:将 Mamba 的线性建模能力与 Transformer 的表达优势结合起来。
(3)论文链接:
https://arxiv.org/abs/2407.08083
开源代码:
https://github.com/NVlabs/MambaVision
23 PVMamba:尝试解决视觉 Mamba 的并行化瓶颈
(1)论文题目:PVMamba: Parallelizing Vision Mamba via Dynamic State Aggregation(2025)
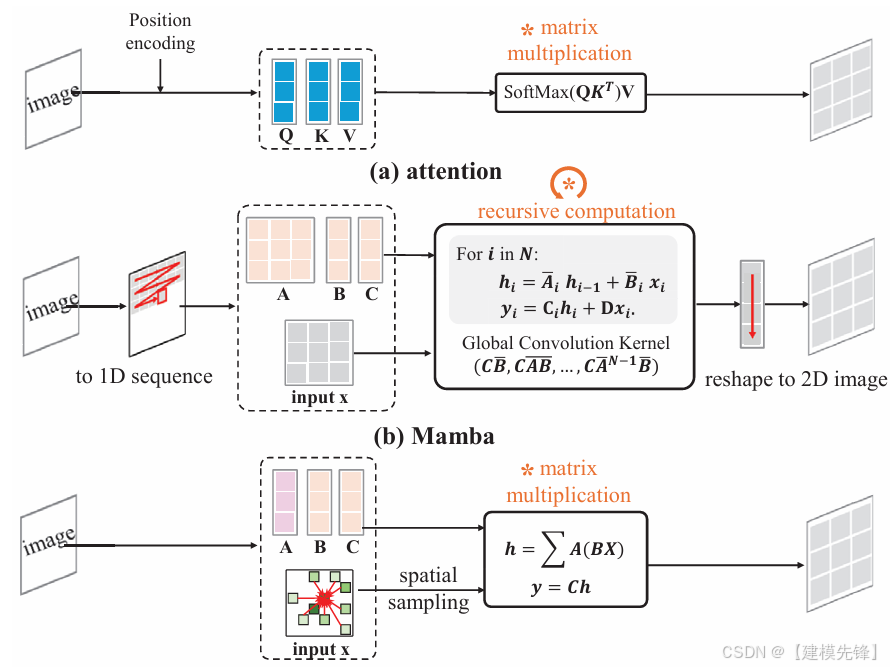
(2)模型简介:
PVMamba 是 ICCV 2025 的一个代表性工作。它关注的是视觉 Mamba 的一个现实问题:虽然 Mamba 具有线性复杂度优势,但其顺序扫描方式与 2D 图像并不天然匹配。PVMamba 通过 Dynamic State Aggregation 来提升并行性,是视觉 SSM 路线向更强工程可用性推进的一篇论文。
核心思想:针对视觉 Mamba 的顺序扫描瓶颈,提升并行化和 2D 数据适配能力。
(3)论文链接:
开源代码:
https: //github.com/VISION-SJTU/PVMamba
总结
卷积网络的发展史,本质上不是"模型名字越来越多"的历史,而是视觉建模思路不断演化的历史。Neocognitron 提出层级视觉思想,LeNet 建立 CNN 的工程范式,AlexNet 让深度学习重回视觉中心,VGG/GoogLeNet/ResNet/DenseNet 把结构设计推向成熟,SENet/MobileNet/EfficientNet 让视觉主干开始兼顾注意力、轻量化与效率。随后 ViT 和 Swin Transformer 改写了视觉主干的范式,而 ConvNeXt、InternImage、VMamba、MambaVision 则进一步说明:后 Swin 时代,视觉网络已经不再是"CNN 被 Transformer 取代"的单线叙事,而是卷积、注意力与状态空间模型持续重组、相互借鉴的多路线时代。