继上次Claude Code客户端代码泄露之后,这篇主要想带大家扒一扒编程智能体和 agent harnesses 的底层设计。核心就三点:这玩意儿是啥?咋工作的?各个部件怎么搭伙干活?
大家应该也感觉到了,智能体现在是大热门。但这波进展不光靠模型升级,更关键的是咱们怎么"调教"它们。落到实际应用上,工具、记忆这些外围设施,重要性一点都不输模型本身。
难怪像 Claude Code 这种系统,明明模型一样,却比在普通聊天框里用着顺手、强大得多,原因就在这儿。
编程智能体这事儿,我把它分成了 6 个大部件。下文我就按这 6 个部分,带大家过一遍它们是怎么跑起来的。
Claude Code、Codex CLI和其他编码代理
像 Claude Code、Codex 还有国内的 TRAE,想必你用过的。它们本质上是啥?其实就是"智能体驾驭系统"(agentic harnesses)。你可以理解为给大模型穿了件"应用层"的外衣,让它写代码时更好用、更效率。
这类编码智能体是专门针对软件开发设计的。这里有个重点:不仅仅要看模型选得好不好,周边系统也很重要。比如怎么理解代码库上下文、工具怎么设计、缓存稳不稳定,以及记忆和长对话能不能接得上。
为啥要强调这点?因为一谈到 LLM 的编码能力,很多人容易把模型、推理行为和产品本身混为一谈。所以,咱们先花点时间,把这几个基本概念的区别搞清楚。
LLM、推理模型和智能体
咱们先说LLM,它就是那个核心大脑,干的事儿主要是预测下一个 token 是啥。推理模型(reasoning model)呢,底子还是 LLM,但它是"强化版",更擅长思考中间步骤、验证对错或者找答案,比如用思维链就是典型例子。而智能体或者驾驭系统,它是站在最上层的。打个比方,它就像是围在模型外面的一层"控制循环"。你给它一个目标,它就负责指挥:下一步检查啥?调用啥工具?状态怎么变?什么时候算完事儿?
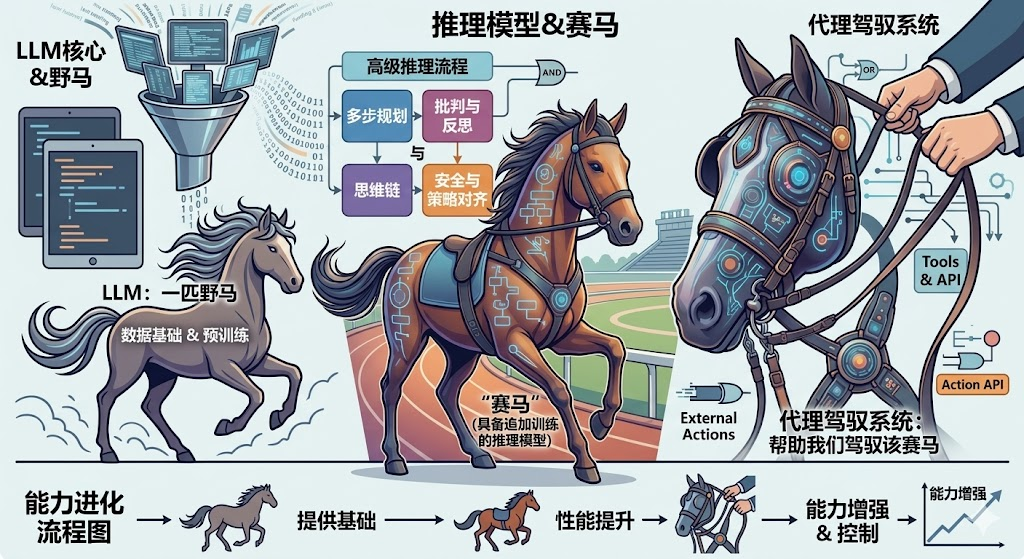
我们可以粗略的理解为LLM是一匹马;推理模型是一个特殊训练过的、懂得竞赛规则的赛马;而智能体驾驭系统则是帮助我们驾驭、驱使这匹赛马的马具。
LLM: 只会猜下一个要输出的词语的基础模型
推理模型: 一个经过优化的LLM,能够输出中间推理过程并进行自我验证
智能体: 一个循环架构/流程,该循环整合了模型、工具调用、记忆机制以及环境反馈
智能体驾驭系统: 智能体的外层软件支撑框架,用于统筹管理上下文、工具调用、提示工程、状态维护与控制流程。例如之前非常流行的小龙虾(OpenClaw)就属于这一类型
编程驾驭系统(Coding harness): 智能体驾驭系统的一种,专门针对编程场景设计。例如Codex, Claude Code, TRAE都属于这一类
在没有智能体驾驭系统的时候,推理模型依然可以工作,甚至可以通过按照猜测下一个要生成的词的方式来完成代码编写的工作,但它并不能非常出色的完成编程任务。原因在于软件工程师编程的时候,还会考虑目录结构、函数的调用关系、运行测试、检查编译和执行的错误,并收集汇总所有的这些有关信息,作为编写程序时的依据。(程序员们可能知道这是费力的脑力工作,这就是为什么我们不喜欢在编程时被打断)
说白了,只要这套系统搭得好,哪怕模型本身不会推理,用起来也比平常在聊天框里直接问要厉害得多哟。
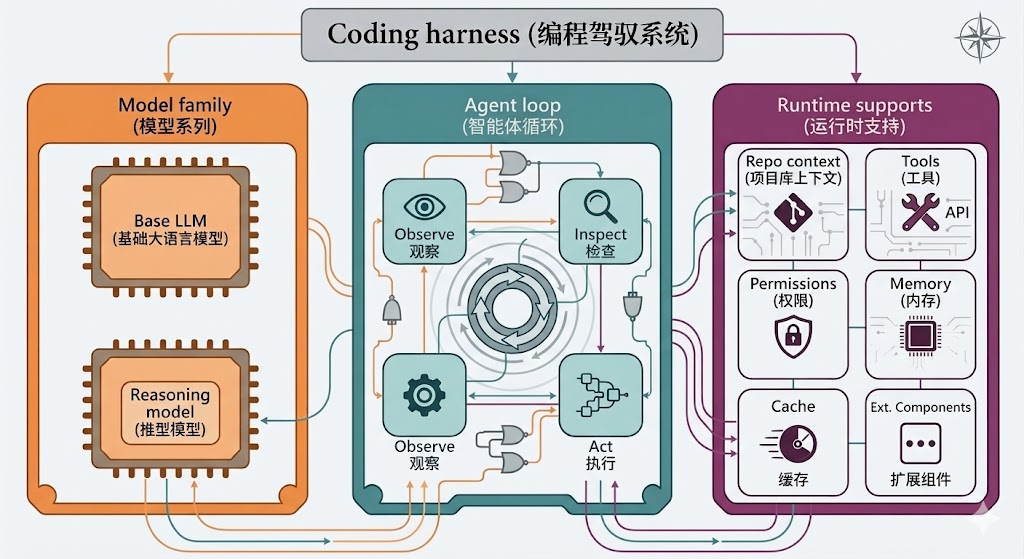
一个编程智能体驾驭系统结合了三层:模型、智能体循环和运行时支持。模型提供"引擎",智能体循环驱动迭代问题解决,运行时支持提供基础设施。
在循环中,"观察"从环境中收集信息,"检查"分析这些信息,"Inspect"选择下一步,"act"执行它。 (这让我想起了PDCA戴明环,是不是很类似 😄)
编程智能体驾驭系统
啥叫"驾驭系统"?其实就是模型外面包的那层软件。它管的事儿可杂了:怎么组合提示词、给你用什么工具、文件状态咋跟踪、怎么改文件、跑什么命令、权限怎么管,甚至连缓存和记忆都归它管。
说实话,现在用大模型,这层软件才决定了你大部分的使用体验。不像以前的网页聊天界面,无非就是上传个文件,然后对着文件内容聊两句。
如今那些基础模型(像什么 GPT-5.4、Opus 4.6、GLM-5)原生能力都差不多快持平了。所以啊,真正能让一个智能体比别人更厉害的,往往就是这个"编程智能体驾驭系统"做得好不好。
编程智能体驾驭系统的六个主要组件

1. 实时仓库上下文
这东西看着最显而易见,但其实特别关键。
你想啊,当用户说"修个测试"或者"加个功能"的时候,模型得心里有数:我现在在 Git 仓库里吗?在哪个分支?有没有文档能查?
因为这些细节直接决定了对错。比如说"修复测试",这话本身没头没尾的。要是代理能读到 AGENTS.md 或者 README,它就知道该跑啥命令。要是知道文件目录长啥样,它就能直接去对的地方找,不用瞎蒙。
再加上 Git 的分支、状态这些信息,能让代理知道现在正在改啥,重点该看哪儿。
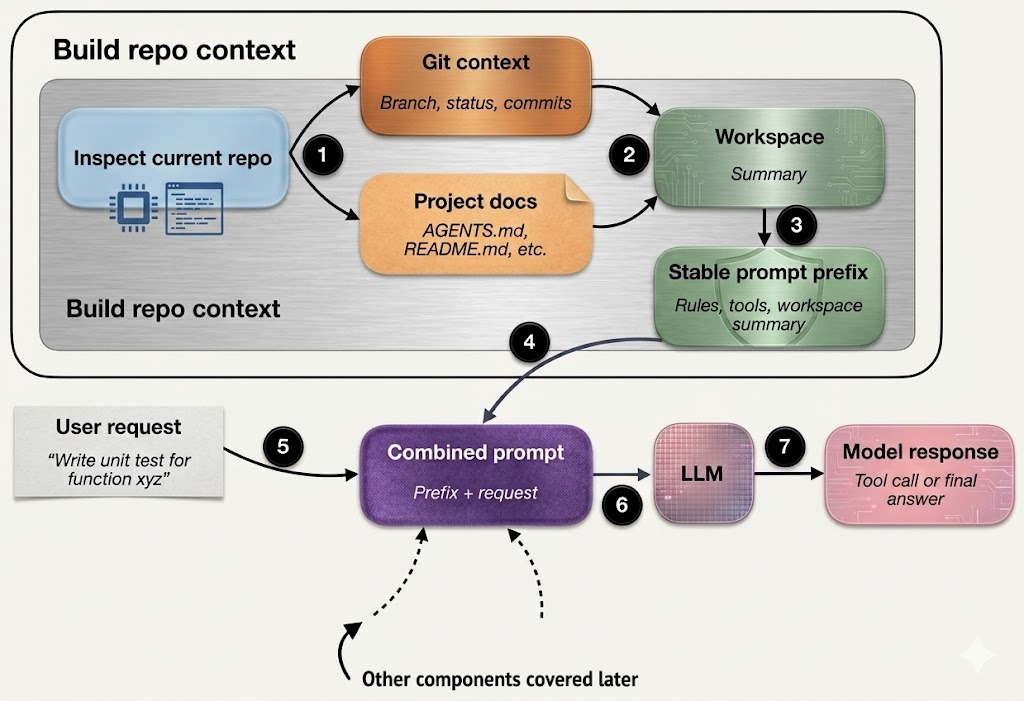
说白了,编码代理在动手之前,得先把信息收集好(就是把那些"稳定事实"整理成工作区摘要)。这样它每次干活都有上下文,不用每次都从零开始瞎忙活。
2. 提示词重塑和缓存复用
智能体搞清楚仓库情况后,下一步就是怎么把这些信息告诉模型。你看上图那个简化版("前缀 + 请求"),好像在现实中,每次用户问个问题都要把整个工作区摘要重新组合一遍,这也太浪费了吧。
其实啊,编码会话有很多重复的东西。智能体的规则变吗?不变。工具描述变吗?也不变。连工作区总结都基本稳得住。真正变的,其实就是用户最新的那句话、最近的聊天记录,还有那点短期记忆。
所以,聪明的系统不会像下图那样,每一轮都把所有内容重新搅和在一起,生成一个巨大的提示词。
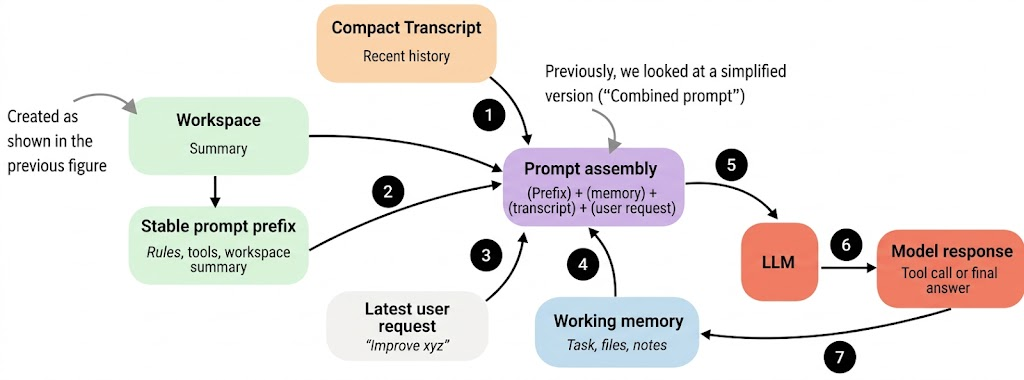
智能体框架构建一个稳定的提示前缀,添加变化中的会话状态,然后将合并后的提示发送给模型。
这和第 1 节有个主要区别:第 1 节讲的是怎么收集仓库信息,而这里我们关注的是怎么高效地封装和缓存这些信息,供模型重复调用。
所谓"稳定的提示词前缀",就是指里面包含的信息变化不多。它通常装着通用指令、工具描述和工作区摘要。如果没有重要变化,我们就不想在每次交互中都从头重建它,从而浪费计算资源。
其他组件更新得更频繁(通常每轮都会变)。这包括短期记忆、最近的对话记录和最新的用户请求。
3. 工具访问和使用
有了工具访问权,这才感觉不像是在聊天,而是真有个智能体在干活。
你想啊,普通模型只能动口不动手,给你推荐个命令就算了。但编码智能体里的 LLM 得能直接上手执行命令,拿到结果,不用咱们手动复制粘贴。
但是,框架可不能让它瞎发挥。它不能随便写语法,得在一个预定义的清单里选工具,输入和边界都得清清楚楚。流程大概是这样(如下图):模型得选一个驾驭系统认得的操作,比如列文件、读文件、搜东西、跑命令或者写文件。而且参数格式也得对,不然系统不认。
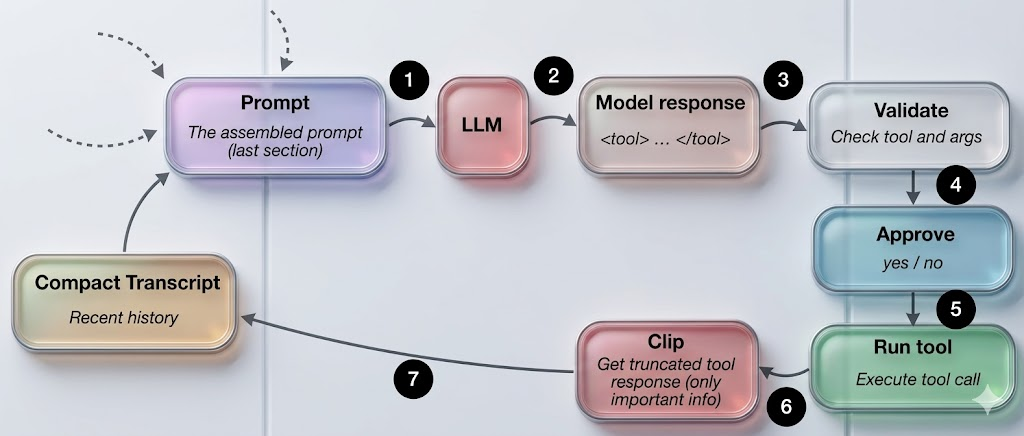
LLM发出一个动作,框架验证它,可选地请求批准,执行它,并将有限的结果反馈到循环中。*
所以,模型想干活的时候,运行时系统会先拦下来做个体检:
- "这工具你用过吗?"
- "参数填对了吗?"
- "这事儿需要用户点头吗?"
- "你要动的文件在安全范围内吗?"
只有全通过了,才真让它动手。
虽说跑编码智能体有点风险,但有了这些检查,可靠性高多了,毕竟模型不能随便乱跑命令。除了拦错别字和要审批,还能通过检查路径,把文件访问限制在仓库里,不让它乱跑。
说白了,驾驭系统虽然管得严,给了模型更少的自由,但也让它变得更靠谱、更好用了。
4. 上下文缩减
上下文变臃肿这事儿,不光是编码智能体头疼,所有 LLM 都头疼。虽说现在模型能吃的上下文越来越长,但这玩意儿贵啊,而且要是塞了一堆没用的信息,噪音太大,模型也容易晕。
特别是编码智能体,多轮聊下来,又是读文件、又是工具输出、还有日志,比普通聊天更容易把上下文撑爆。要是全保留,tokens分分钟用完。所以,一个好的编程驾驭系统在这块儿得比普通聊天界面复杂得多,不能简单粗暴地截断或者总结。
概念上咋做呢?你看下面这个图,大输出得裁剪,旧数据得去重,代码得压缩了再塞回提示词里。
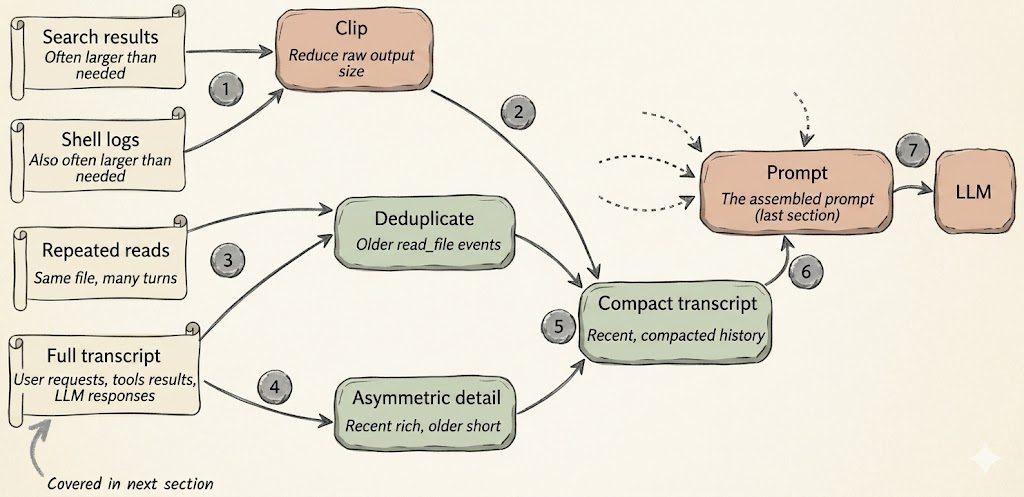
起码得用两招来管这事儿:
第一招叫裁剪(clipping)。就是不管你是文档片段、工具输出还是笔记,太长了就剪短点。别让某一段文字光因为长,就把整个 prompt 的预算占光了。
第二招叫对话记录缩减。就是把之前的聊天历史总结成个小摘要,能塞进 prompt 就行。
这里有个窍门:最近的事儿要记得细,因为跟当前步骤关系大;早前的事儿可以压缩狠点,因为可能没那么相关了(咋样,想起了神经网络LSTM吗 😄)。另外,之前读过的文件就别反复塞了,去重一下,免得模型老是看到重复内容。
说白了,这块儿设计看着挺无聊,经常被低估,但其实特别关键。很多时候你觉得是"模型不够聪明",其实是"上下文喂得不好"。
5. 结构化的会话记忆
其实啊,这 6 个核心概念都是缠在一起的,只是不同章节侧重点不一样。上一节咱们聊的是"prompt 时机"和怎么把对话记录变紧凑。那时候核心问题是:上一轮聊过的内容,有多少要塞给下一轮模型? 所以重点是怎么压缩、裁剪、去重,还有讲究个时效性。
而这一节讲的结构化会话内存,是说历史数据怎么存。核心问题变成了:智能体长期该记住什么? 所以重点是系统得存一份完整的对话记录当备份,同时还得有个更轻量级的"记忆层"。这个记忆层更小,而且是可以修改、压缩的,不是光往里添内容。
说白了,编码智能体把状态分成了至少两层:
工作记忆:就是智能体特意保留的一小部分精华状态。
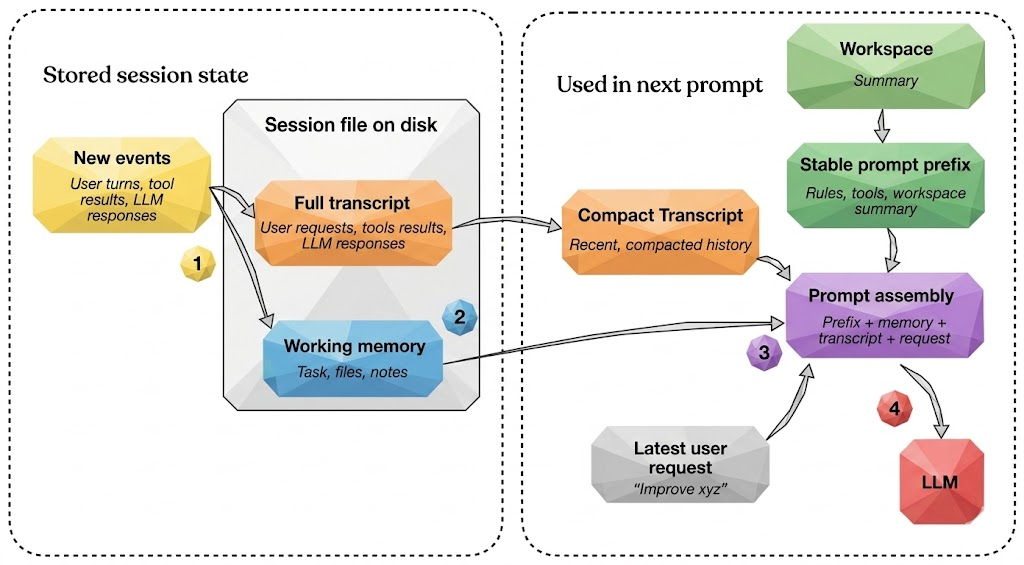
你看这张图,主要有两个会话文件------完整记录和工作记忆------通常都是存成 JSON 文件放在硬盘上。完整记录就是全量历史,就算代理关了,也能恢复。工作记忆就像是个精简版,只装当前最重要的信息,这跟"精简对话记录"有点关系,但又不完全一样。
它俩用途有啥区别呢?精简对话记录是用来重构提示词的,目的就是给模型提供一个压缩过的近期历史视图,不用每次都把完整记录翻一遍。工作记忆则是为了保证任务连续性,它存的是一个小型摘要,记着跨轮次的重要事儿,比如当前任务啥、关键文件是哪些、最近的笔记等等。
按图里步骤 4 说的,最新的用户请求、模型回答和工具输出,在下一轮都会当作"新事件",同时记到完整记录和工作记忆里去。
6. 使用(有边界的)子智能体进行委托
智能体有了工具和状态后,下一步能干啥?委托!
为啥需要委托?因为这样能让子智能体帮忙并行干活,主任务就能跑得更快。你想啊,主智能体正在忙一个大任务,突然需要查个小资料,比如"哪个文件定义了这个符号"、"配置文件咋写的"或者"测试为啥挂了"。把这些拆出去交给子智能体单独处理,比让主程序同时盯着所有线索要高效得多。
但子智能体得知道足够的背景信息(上下文)才能干活。可要是完全不管,好几个智能体一起跑,可能会重复劳动、抢着改同一个文件,甚至无限生成子智能体,那就乱套了。
所以,最难的设计点不光是怎么生成子智能体,还有怎么管住它。这跟编程里的进程和子进程挺像的:子进程能共享父进程的环境,还能并行跑。
这里的难点在于平衡:子智能体得继承足够的上下文才有用,但又得被约束住不然会出乱子(比如限制它只能读不能写,或者限制它不能再嵌套生成子智能体)。
目前,Claude Code 早就支持子智能体了,Codex 最近才加上。Codex 通常不会强制子智能体只能"只读"。相反,子智能体会继承主智能体的大部分沙箱和审批设置。所以,它的边界更多地是控制在任务范围、上下文多少和嵌套深度上。
与 OpenClaw 是什么关系
说到 OpenClaw,可能大家会觉得有点像,但其实它跟咱们刚才聊的编码智能体不是一回事儿。
OpenClaw 更像是一个本地的"通用代理平台",虽然也能写代码,但它不是专门的编程助手。不过呢,它跟编码工具确实有几处挺像的:比如
但是啊,核心重点不一样。编码智能体是专门为在代码仓库里干活的人设计的,你想查文件、改代码、跑工具,它最擅长。而 OpenClaw 则是为了在聊天、频道里跑那些长期存在的本地智能体而优化的,编程只是它能干的活儿之一,并不是全部。
