目录
1.摘要
针对异构多机器人系统中伴随优先约束的大规模多目标任务分配问题,现有算法在求解的收敛性与解集多样性上面临挑战。为此,本文建立三目标优化模型提出一种协作式蚁群系统(CACS)以同时最小化最大完工时间、平均机器人移动时间及平均任务等待时间,该系统构建三个独立蚁群分别优化各项指标,采用任务-联盟序列编码以适配优先约束,并设计了结合动态启发式信息与双信息素矩阵新型构造策略以生成可行解。此外,算法引入基于融合的局部搜索机制,通过交互多蚁群信息进一步提升解集的质量。
2.问题陈述
多机器人任务分配(MRTA)由异构机器人集合 R R R与协作任务集合 T T T构成,每个任务具备多维的能力与资源需求及严格的优先约束,而每个机器人则拥有特定的移动速度及能力与资源配置。
为满足任务需求,多个机器人需组成联盟协同作业,且仅当联盟内所有成员均抵达指定位置后,任务方可启动。任务的实际执行时间由其基础属性及联盟综合能力共同决定;机器人的移动时间取决于其作业序列的路径距离与移动速度;任务的等待时间则受限于前置任务的完工时间与联盟成员的最晚到达时间。模型最小化最大完工时间、平均机器人移动时间以及平均任务等待时间
min F ( X ) = ( f 1 ( X ) , f 2 ( X ) , f 3 ( X ) ) T \min F(X)=(f_1(X),f_2(X),f_3(X))^T minF(X)=(f1(X),f2(X),f3(X))T
f 1 ( X ) = max t i ∈ T F T t i , f 2 ( X ) = ∑ r j ∈ R T T r j n , f 3 ( X ) = ∑ t i ∈ T W T t i m f_1(X)=\max_{t_i\in T}FT_{t_i},\quad f_2(X)=\frac{\sum_{r_j\in R}TT_{r_j}}n,\quad f_3(X)=\frac{\sum_{t_i\in T}WT_{t_i}}m f1(X)=ti∈TmaxFTti,f2(X)=n∑rj∈RTTrj,f3(X)=m∑ti∈TWTti
需严格遵循能力、资源及优先级三大约束:
∑ j ∈ A R a k r c r j z ≥ t c t i z , ∑ j ∈ A R a k r r r j d ≥ t r t i d \sum_{j\in AR_{a_k}}rc_{r_j}^z\geq tc_{t_i}^z,\quad\sum_{j\in AR_{a_k}}rr_{r_j}^d\geq tr_{t_i}^d j∈ARak∑rcrjz≥tctiz,j∈ARak∑rrrjd≥trtid
F T t o ≤ W T t i ∀ o ∈ P C t i FT_{t_o}\leq WT_{t_i}\quad\forall o\in PC_{t_i} FTto≤WTti∀o∈PCti
3.CACS算法
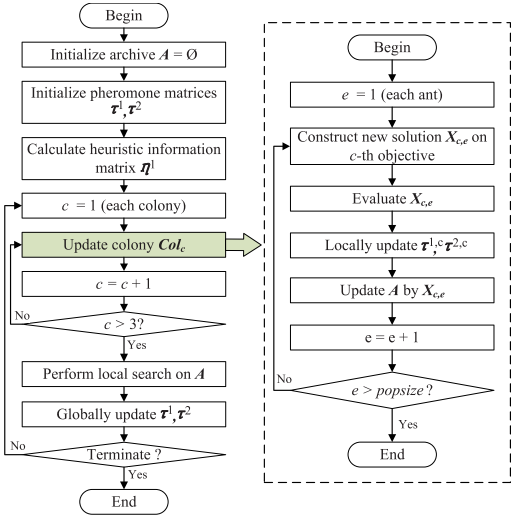
解表示方案与构造
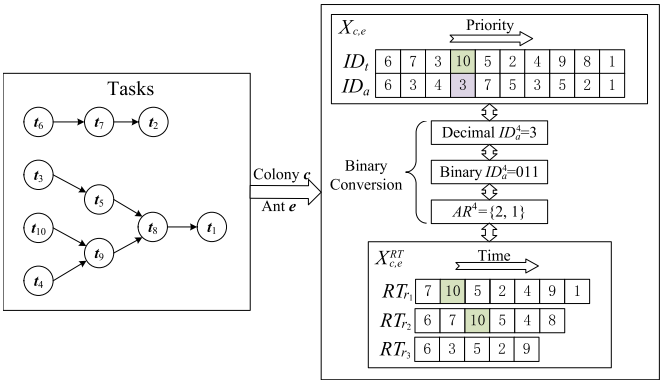
任务-联盟序列编码方案表示为 X c , e = ( X c , e , 1 , X c , e , 2 , ... , X c , e , m ) X_{c,e}=(X_{c,e,1},X_{c,e,2},\ldots,X_{c,e,m}) Xc,e=(Xc,e,1,Xc,e,2,...,Xc,e,m),其中 X c , e , z = ( I D t z , I D a z ) X_{c,e,z}=(ID_t^z,ID_a^z) Xc,e,z=(IDtz,IDaz)均通过二进制元组界定了任务标识及其分配的机器人联盟,其索引顺序直接决定了任务的执行优先级。通过对该序列进行二进制解码,可将其转化为针对 n n n个机器人的具体执行路径集 X c , e R T X_{c,e}^{RT} Xc,eRT。在协同蚁群算法(CACS)的构建过程中,解的生成遵循一种逐步启发式策略:首先基于任务间的信息素 τ 1 , c \tau_{1,c} τ1,c与启发式信息 η 1 \eta_1 η1,通过如下状态转移规则从候选集 T p T_p Tp中择定当前任务 t i t_i ti
t i = { argmax t o ∈ T p { τ 1 , c w , o α ⋅ η 1 w , o β } , if q ≤ q 0 J ∼ P 1 , c w , o , otherwise t_i=\begin{cases}\operatorname{argmax}{t_o\in T_p}\{\\tau_{1,c}\^{w,o}^\alpha\cdot\\eta_1\^{w,o}^\beta\},&\text{if}q\le q_0\\J\sim P{1,c}^{w,o},&\text{otherwise}\end{cases} ti={argmaxto∈Tp{τ1,cw,oα⋅η1w,oβ},J∼P1,cw,o,ifq≤q0otherwise
其中,概率分布 P 1 , c w , o P_{1,c}^{w,o} P1,cw,o
P 1 , c w , o = τ 1 , c w , o α ⋅ η 1 w , o β ∑ t b ∈ T p τ 1 , c w , b α ⋅ η 1 w , b β P_{1,c}^{w,o}=\frac{\\tau_{1,c}\^{w,o}^\alpha\cdot\\eta_1\^{w,o}^\beta}{\sum_{t_b\in T_p}\\tau_{1,c}\^{w,b}^\alpha\cdot\\eta_1\^{w,b}^\beta} P1,cw,o=∑tb∈Tpτ1,cw,bα⋅η1w,bβτ1,cw,oα⋅η1w,oβ
在确定任务后,算法通过逐一筛选可用机器人来动态构建联盟,而非采用全量枚举,从而显著压缩搜索空间。机器人 r j r_j rj的选择同样受信息素 τ 2 , c \tau_{2,c} τ2,c和动态启发项 η 2 , c \eta_{2,c} η2,c驱动:
P 2 , c i , u = τ 2 , c i , u α ⋅ η 2 , c i , u β ∑ r g ∈ R ′ τ 2 , c i , g α ⋅ η 2 , c i , g β P_{2,c}^{i,u}=\frac{\\tau_{2,c}\^{i,u}^\alpha\cdot\\eta_{2,c}\^{i,u}^\beta}{\sum_{r_g\in R^{\prime}}\\tau_{2,c}\^{i,g}^\alpha\cdot\\eta_{2,c}\^{i,g}^\beta} P2,ci,u=∑rg∈R′τ2,ci,gα⋅η2,ci,gβτ2,ci,uα⋅η2,ci,uβ

信息素管理
在信息素表示方面,算法为每个种群 c c c维护两个异质信息素矩阵 τ 1 , c \tau_{1,c} τ1,c为 ( m + 1 ) × ( m + 1 ) (m+1)\times(m+1) (m+1)×(m+1)阶任务邻接矩阵,用于记录任务执行顺序的历史轨迹; τ 2 , c \tau_{2,c} τ2,c为 ( m + 1 ) × ( n + 1 ) (m+1)\times(n+1) (m+1)×(n+1)阶任务-机器人关联矩阵,用于刻画特定任务对个体的偏好。在系统初始化阶段,由于大规模场景下贪婪搜索的时间复杂度极高,算法采用随机策略生成初始解 X r X_r Xr,并依此设定初始信息素浓度:
τ 0 , c = 1 m × f c ( X r ) \tau_{0,c}=\frac1{m\times f_c(X_r)} τ0,c=m×fc(Xr)1
为了抑制算法陷入局部最优,构建新解后需执行局部更新。对于解 X c , e X_{c,e} Xc,e中涉及的路径元素 ( i , j ) (i,j) (i,j),信息素浓度将通过如下规则进行适度挥发:
τ s , c i , j = ( 1 − ρ l ) × τ s , c i , j + ρ l × τ 0 , c \tau_{s,c}^{i,j}=(1-\rho_l)\times\tau_{s,c}^{i,j}+\rho_l\times\tau_{0,c} τs,ci,j=(1−ρl)×τs,ci,j+ρl×τ0,c
在迭代末期,算法引入基于排名的全局更新机制以实现种群间的信息通信。从存档集 A A A中选取
使第 c c c个目标函数最优的解 X c , b X_{c,b} Xc,b,强化其对应的路径信息
τ s , c i , j = ( 1 − ρ g ) × τ s , c i , j + ρ g × Δ τ c , Δ τ c = 1 f c ( X c , b ) \tau_{s,c}^{i,j}=(1-\rho_g)\times\tau_{s,c}^{i,j}+\rho_g\times\Delta\tau_c,\quad\Delta\tau_c=\frac{1}{f_c(X_{c,b})} τs,ci,j=(1−ρg)×τs,ci,j+ρg×Δτc,Δτc=fc(Xc,b)1
启发式设计
为了提升解的构建质量与种群的多样性,CACS算法引入了基于贪婪策略的启发式信息以及融合式的局部搜索机制。在启发表引导方面,任务选择倾向于降低空间跨度,其启发 η 1 w , o \eta_{1}^{w,o} η1w,o由任务间的欧几里得距离倒数定义:
η 1 w , o = 1 d i s t ( T P t w , T P t o ) \eta_{1}^{w,o} = \frac{1}{dist(TP_{t_w}, TP_{t_o})} η1w,o=dist(TPtw,TPto)1
在构建联盟时,针对不同优化目标 c c c,算法评估将机器人 r u r_u ru分配给任务 t i t_i ti所带来的目标值增量 Δ f c \Delta f_c Δfc,并取其倒数作为启发信息 η 2 , c i , u \eta_{2,c}^{i,u} η2,ci,u,以优先选择增量最小的机器人:
η 2 , c i , u = 1 Δ f c + 1 \eta_{2,c}^{i,u} = \frac{1}{\Delta f_c + 1} η2,ci,u=Δfc+11
其中, Δ f c \Delta f_c Δfc涵盖了完工时间偏差( c = 1 c=1 c=1)、移动距离增量( c = 2 c=2 c=2)以及等待时间代价( c = 3 c=3 c=3)等维度。
在迭代过程中,算法通过融合式局部搜索 进一步优化存档集 A A A,该机制基于目标归一化后的平均曼哈顿距离筛选出稀疏解。

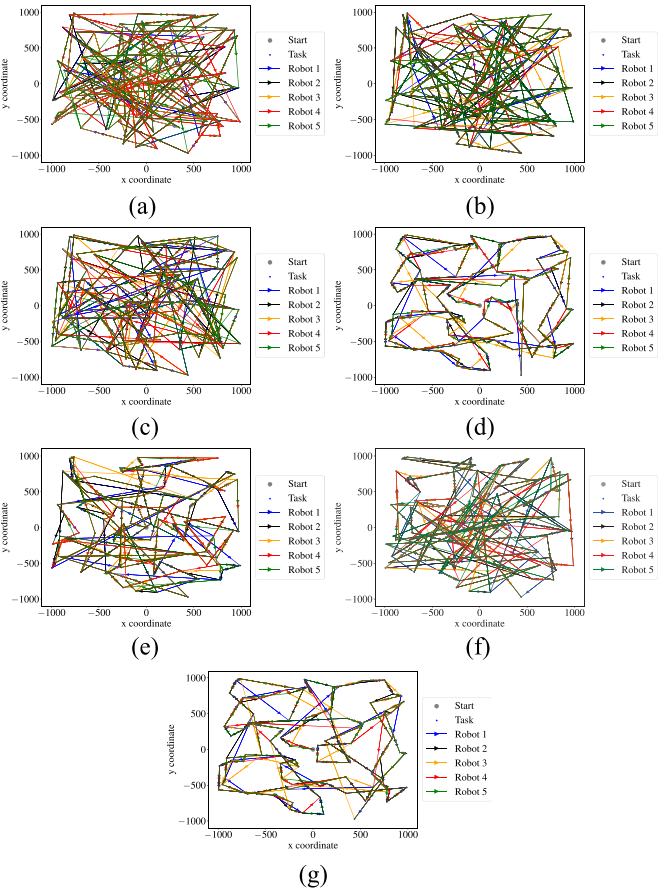
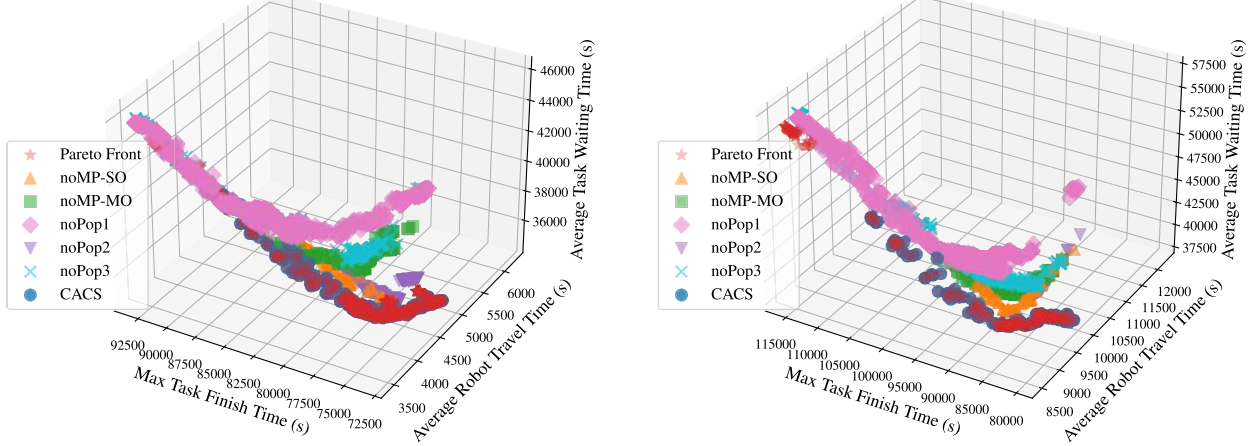
4.结果展示
5.参考文献
Qian T, Liu X F, Fang Y. A cooperative ant colony system for multiobjective multirobot task allocation with precedence constraintsJ. IEEE Transactions on Evolutionary Computation, 2024.
6.代码获取
xx
7.算法辅导·应用定制·读者交流
xx