大模型入门实战:两个落地项目保姆级教程
大家好,我是一名刚从大模型小白过来的开发者,最近很多 CSDN 的粉丝朋友问我:大模型入门到底该做什么项目?有没有那种普通电脑就能跑,不用高端 GPU,还能真正理解大模型落地的实战项目?
今天,我就把我自己入门的时候做的两个经典实战项目拿出来,全程保姆级教学,从原理到代码,逐行解析,小白也能跟着敲,带你真正搞懂大模型落地的两大核心技术:检索增强生成(RAG) 和轻量微调(P-tuning)。
这两个项目,一个是基于 RAG 的物流行业智能问答系统,一个是基于 P-tuning 的新零售商品分类系统,覆盖了大模型落地的两大主流场景,普通的笔记本电脑就能跑,8G 内存就能搞定,不用你有什么高端的 GPU,新手也能轻松上手。
一、大模型入门必知:为什么我们需要这两个技术?
在开始做项目之前,我们先搞懂一个最核心的问题:大模型这么厉害,为什么我们还需要 RAG 和微调这些技术?
其实,我们平时用的 ChatGPT、通义千问这些大模型,都有几个天生的痛点:
1.1 大模型的三大痛点
(1)幻觉问题
大模型会 "一本正经的胡说八道",比如你问它你的快递到哪了,它根本不知道,因为它的训练数据里根本没有你的快递信息,但是它会编一个答案给你,看起来特别真,你根本分辨不出来。
(2)知识过时
大模型的训练数据都是截止到某个时间点的,比如 GPT-4 的训练数据截止到 2023 年 12 月,通义千问 7B 的训练数据截止到 2024 年 2 月,那 2024 年之后的新事情,它就不知道了,比如你问它 2024 年的世界杯冠军是谁,它就回答不了。
(3)私有数据不安全
企业的内部数据,比如物流的快递信息,新零售的用户评论,这些都是私有的,你不能把这些数据上传到公开的大模型 API 那里,一方面是数据安全,另一方面是隐私合规,所以很多企业都想要本地部署,自己的数据自己处理。
1.2 两大解决方案:RAG vs 微调
为了解决这些痛点,现在业界有两个最主流的解决方案,刚好就是我们这两个项目用到的:
(1)检索增强生成(RAG)
RAG 的思路是:我不改模型,我把我的知识给模型 。
简单来说,就是把你的私有文档、最新的知识,提前处理好,存到向量数据库里,用户问问题的时候,先从你的知识库里面找到和问题相关的内容,然后把这些内容和问题一起给大模型,告诉模型:你只能根据这些内容回答,不能编。
这样,模型的答案就都是来自你的知识库,不会胡说,也能回答你的私有数据的问题,还能随时更新知识库,加新的文档就行,不用改模型。
(2)轻量微调(P-tuning)
微调的思路是:我改模型的少量参数,让模型学会我的任务 。
原来的全量微调,要改整个模型的所有参数,比如 BERT 有 1 亿多个参数,7B 的模型有 70 亿,普通电脑根本跑不动,还需要很多的数据。
而 P-tuning 这种轻量微调,只改很少的参数,比如只训练几个虚拟的 token,总共才几千个参数,普通的 CPU 就能跑,小数据集,比如几十条数据,就能训练,效果还很好,特别适合分类、命名实体识别这种特定的任务。
简单来说,如果你要做问答、知识库,用 RAG;如果你要做特定的任务,比如分类,用 P-tuning,这两个就是大模型入门最该学的两个技术。
二、前置技术:LangChain 框架入门
在做 RAG 项目之前,我们需要先学一个框架:LangChain,因为 RAG 项目里,我们用 LangChain 来把各个组件串起来,不用自己写一堆重复的代码。
很多小白一听框架就怕,其实 LangChain 特别简单,它就是一个大模型应用的开发工具,把各种常用的组件都给你封装好了,你直接用就行,不用自己造轮子。
2.1 什么是 LangChain?
LangChain 是一个开源的大模型应用开发框架,它的核心理念就是 "链接",把大模型、提示词、向量数据库、文档处理这些组件,都链接在一起,让你能快速的开发大模型应用,不用你自己从 0 写。
LangChain 支持所有的大模型,不管是 OpenAI 的,还是本地的 Ollama 的,还是通义千问、文心一言,它都能接,你不用改代码,换个模型就行。
2.2 LangChain 的六大核心组件
LangChain 把大模型应用的所有功能,都拆成了六个核心组件,我们一个个来看,每个都有例子,小白一看就懂。
2.2.1 Models:模型组件
Models 就是各种模型,LangChain 支持三种类型的模型,分别是:
-
LLMs:大语言模型:输入文本,输出文本,比如你给它 "讲个鬼故事",它给你输出故事。
-
Chat Models:聊天模型:输入聊天消息,输出聊天消息,支持 System、Human、AI 这些消息类型,就是我们平时用的 ChatGPT 那种对话模型。
-
Embeddings Models:嵌入模型:输入文本,输出向量,就是把文字转成一串数字,意思相近的文字,数字也相近,这个是 RAG 的核心。
我们来看个最简单的 LLM 的例子:
python
from langchain_community.llms import Ollama
# 加载通义千问7B模型
model = Ollama(model="qwen2.5:7b")
# 调用模型
result = model.invoke("请给我讲个鬼故事")
print(result)这几行代码,就是导入 Ollama 的 LLM 接口,然后加载我们的大模型,然后调用模型,输入问题,得到结果,是不是特别简单?
然后是 Chat 模型的例子:
python
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_community.chat_models import ChatOllama
# 加载聊天模型
model = ChatOllama(model="qwen2.5:7b")
# 定义消息,System是告诉模型要扮演什么,Human是用户的问题
messages = [
SystemMessage(content="现在你是一个著名的诗人"),
HumanMessage(content="给我写一首唐诗")
]
res = model.invoke(messages)
print(res.content)这里的 SystemMessage,就是我们常说的系统提示词,告诉模型你要扮演诗人,然后模型就会按照诗人的身份来回答,然后 AIMessage 就是之前模型的回答,比如你之前问了唐诗,模型回答了,然后你再问宋词,把之前的回答加进去,模型就知道上下文了。
然后是 Embedding 模型的例子:
python
from langchain_community.embeddings import OllamaEmbeddings
# 加载Embedding模型
model = OllamaEmbeddings(model="mxbai-embed-large", temperature=0)
# 把文字转成向量
res1 = model.embed_query('这是第一个测试文档')
print(res1)
print(len(res1))这里的输出,就是一串浮点数,也就是向量,比如 "我喜欢苹果" 和 "我爱吃香蕉" 的向量,距离就很近,因为它们的意思都是说喜欢水果,而 "我喜欢电脑" 的向量,距离就很远,这个就是 Embedding 的作用,把语义的相似度,变成向量的距离,这个是 RAG 检索的基础。
2.2.2 Prompts:提示词组件
Prompts 就是提示词,我们平时写提示词,都是自己拼字符串,比如:
python
name = "王"
prompt = "我的邻居姓" + name + ",他生了个儿子,给他儿子起个名字"这样写很麻烦,LangChain 给我们提供了 PromptTemplate,就是提示词模板,你把变量留出来,每次填进去就行,特别方便。
比如:
python
from langchain import PromptTemplate
# 定义模板,{lastname}是变量
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
prompt = PromptTemplate(
input_variables=["lastname"],
template=template,
)
# 填变量,得到最终的提示词
prompt_text = prompt.format(lastname="王")
print(prompt_text)
# 输出:我的邻居姓王,他生了个儿子,给他儿子起个名字是不是比自己拼字符串方便多了?而且你还可以做 few-shot 提示,就是给模型几个例子,让它跟着学,比如:
python
from langchain import PromptTemplate, FewShotPromptTemplate
# 例子,输入单词,输出反义词
examples = [
{"word": "开心", "antonym": "难过"},
{"word": "高", "antonym": "矮"},
]
# 例子的模板
example_template = """
单词: {word}
反义词: {antonym}
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_template,
)
# 构建few-shot模板
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="给出每个单词的反义词",
suffix="单词: {input}\n反义词:",
input_variables=["input"],
)
# 填变量
prompt_text = few_shot_prompt.format(input="粗")
print(prompt_text)输出的提示词就是:
Plain
给出每个单词的反义词
单词: 开心
反义词: 难过
单词: 高
反义词: 矮
单词: 粗
反义词:模型看到这个,就知道要给 "粗" 找反义词,就会输出 "细",是不是特别简单?
2.2.3 Chains:链组件
Chains 就是链,把多个组件串起来,比如你要先处理提示词,再调用模型,原来你要写两步:
python
prompt = prompt.format(lastname="王")
result = model.invoke(prompt)现在用 Chain,一步就能搞定,比如:
python
from langchain import PromptTemplate
from langchain_community.llms import Ollama
from langchain.chains import LLMChain
# 定义模板
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
prompt = PromptTemplate(input_variables=["lastname"], template=template,)
llm = Ollama(model="qwen2.5:7b")
# 构建链,把提示词和模型串起来
chain = LLMChain(llm=llm, prompt=prompt)
# 一步执行,输入变量,得到结果
print(chain.run("王"))是不是特别方便?而且你还可以把多个链串起来,比如第一个链起名字,第二个链起小名,第一个的输出,自动变成第二个的输入:
python
from langchain.chains import SimpleSequentialChain
# 第一个链:起名字
first_prompt = PromptTemplate(
input_variables=["lastname"],
template="我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
)
first_chain = LLMChain(llm=llm, prompt=first_prompt)
# 第二个链:起小名
second_prompt = PromptTemplate(
input_variables=["child_name"],
template="邻居的儿子名字叫{child_name},给他起一个小名"
)
second_chain = LLMChain(llm=llm, prompt=second_prompt)
# 把两个链串起来
overall_chain = SimpleSequentialChain(chains=[first_chain, second_chain], verbose=True)
# 一步执行,输入姓,得到小名
catchphrase = overall_chain.run("王")
print(catchphrase)你看,你只需要输入 "王",第一个链自动生成名字,比如 "王明",然后自动把 "王明" 传给第二个链,生成小名,比如 "明明",你不用自己处理中间的结果,Chain 都帮你做了,这就是链的作用,把多个步骤串成一个。
2.2.4 Memory:记忆组件
Memory 就是记忆,大模型本身是没有记忆的,你问它第一个问题,它回答了,你再问第二个,它就忘了第一个了,因为大模型每次都是无状态的,它只看你当前的输入。
比如你问:"小明有 1 只猫",它回答 "哦,那挺好的",然后你问 "小刚有 2 只狗",它回答 "哦,那也挺好的",然后你问 "他们一共有几只宠物?",它就不知道了,因为它忘了之前的两句话了。
Memory 就是解决这个问题的,把历史对话存起来,每次都把历史对话和当前的问题一起给模型,这样模型就能记住之前的话了。
比如:
python
from langchain import ConversationChain
from langchain_community.llms import Ollama
# 加载模型
llm = Ollama(model="qwen2.5:7b")
# 构建带记忆的对话链
conversation = ConversationChain(llm=llm)
# 第一个问题
resut1 = conversation.predict(input="小明有1只猫")
print(resut1)
# 第二个问题
resut2 = conversation.predict(input="小刚有2只狗")
print(resut2)
# 第三个问题
resut3 = conversation.predict(input="小明和小刚一共有几只宠物?")
print(resut3)你看,第三个问题,模型就能回答 "3 只" 了,因为它记住了之前的两句话,Memory 自动把历史对话拼到输入里了,你不用自己拼,是不是特别方便?
2.2.5 Indexes:索引组件
Indexes 就是索引,这个是 RAG 的核心,用来处理文档的,比如你有一堆 PDF、TXT 文档,怎么让大模型能看懂这些文档?Indexes 组件就帮你做这个。
Indexes 包含四个部分:
-
文档加载器:加载各种格式的文档,PDF、TXT、Word、Markdown,都能加载,转成文本。
-
文本分割器:把长文档切成小块,因为大模型的输入长度有限,太长的塞不下,而且我们只需要和问题相关的部分。
-
VectorStores:向量数据库:把分割好的文档小块,转成向量,存到向量数据库里,建索引,方便检索。
-
检索器:用户问问题的时候,把问题转成向量,去向量数据库里找最相似的文档小块。
我们来看个例子:
python
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import OllamaEmbeddings
# 1.加载文档
loader = TextLoader('./pku.txt')
documents = loader.load()
# 2.分割文档,切成100字符的小块
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
# 3.加载Embedding模型
embeddings = OllamaEmbeddings(model="mxbai-embed-large")
# 4.存到FAISS向量数据库
db = FAISS.from_documents(texts, embeddings)
# 5.检索,找和问题最相似的文档
retriever = db.as_retriever(search_kwargs={'k': 1})
docs = retriever.get_relevant_documents("北京大学什么时候成立的")
print(docs)输出就是:
Plain
[Document(metadata={'source': './pku.txt'}, page_content='北京大学创办于1898年,是戊戌变法的产物,也是中华民族救亡图存、兴学图强的结果,初名京师大学堂,是中国近现代第一所国立综合性大学,辛亥革命后,于1912年改为现名。')]你看,是不是特别简单?我们输入问题,它就自动从文档里找到相关的内容,这个就是 RAG 的核心检索功能,后面我们的 RAG 项目,就是用的这个。
好了,LangChain 的核心组件我们就讲完了,是不是特别简单?其实 LangChain 就是把这些常用的功能都给你封装好了,你不用自己写,直接用就行,小白也能快速上手。
三、第一个项目:基于 RAG 的物流行业智能问答系统
好了,前置知识我们讲完了,现在开始做第一个项目:基于 RAG 的物流行业智能问答系统。
3.1 项目背景
我们做这个项目的背景是什么呢?
物流行业,每天都有大量的用户来问问题:"我的快递到哪了?""我的快递出发地是哪?""预计多久能到?""运费是多少?"
之前这些问题,都是人工客服来回答,效率很低,成本很高,而且用户还要等,体验不好。
那我们能不能做一个智能问答系统,把所有的物流信息,都做成一个知识库,用户问什么,系统自动回答,不用人工?
而且,这些物流信息都是企业的私有数据,我们不能把它传到公开的大模型 API 那里,所以我们要本地部署,本地处理,数据安全。
这个时候,RAG 就是最好的选择,我们把物流的知识库,做成 RAG 的向量库,用户问问题,自动从知识库找答案,本地就能跑,数据也安全,还不会胡说八道。
3.2 RAG 核心原理
很多小白都听过 RAG,但是不知道到底是什么,我们用通俗的话来讲,RAG 就是三个步骤:检索(Retrieval)、增强(Augment)、生成(Generate)。
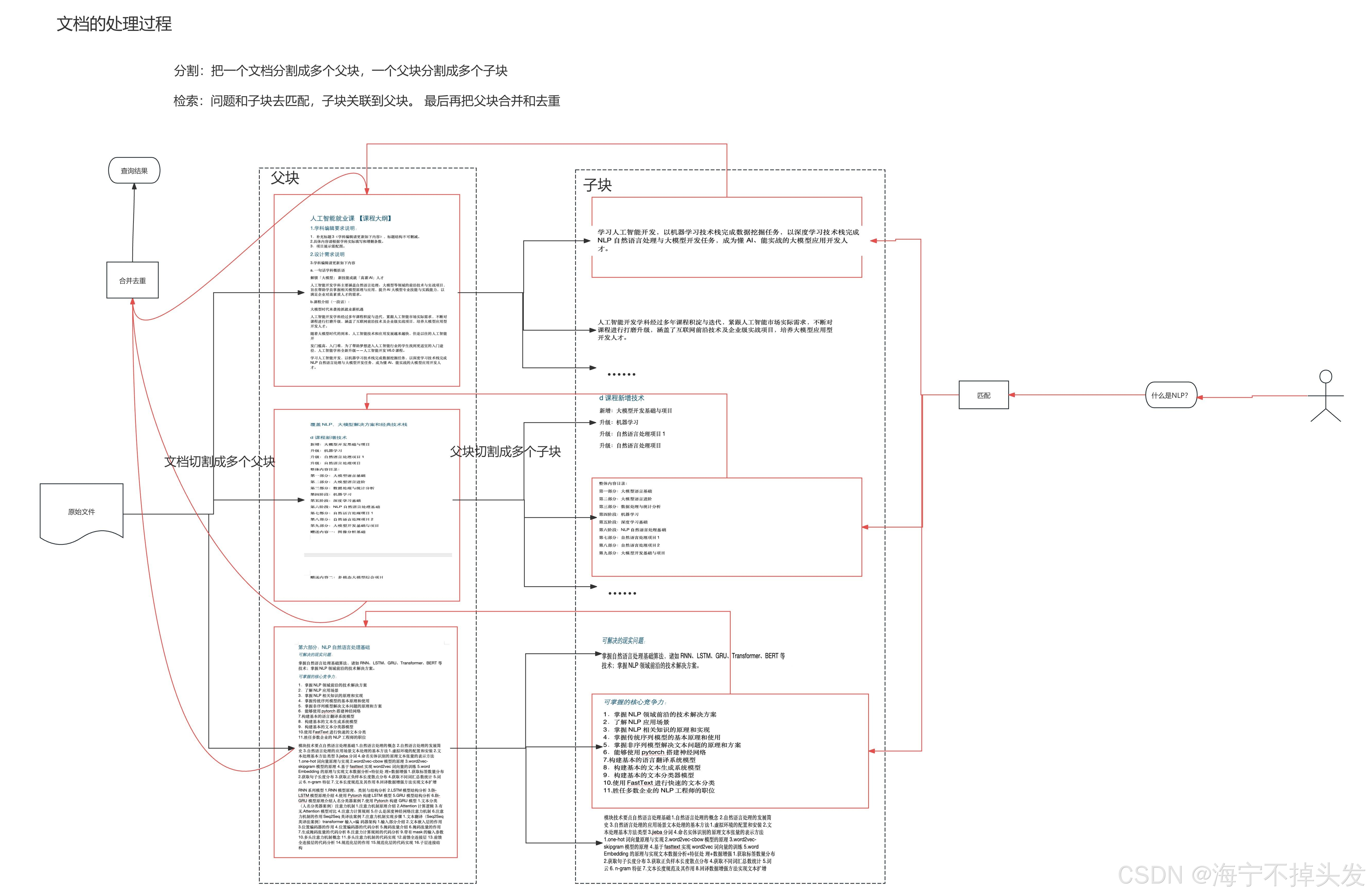
我们来拆解一下:
-
离线处理阶段:我们先把我们的知识库文档,比如物流的 PDF 文档,做处理:
-
把文档切成很多小的文本块,因为太长的话,模型塞不下,而且检索也慢。
-
把每个小文本块,用 Embedding 模型转成向量。
-
把这些向量存到向量数据库里,建索引,这一步做一次就行,不用每次都做。
-
-
在线检索阶段:用户问问题的时候:
-
把用户的问题,也用同样的 Embedding 模型转成向量。
-
去向量数据库里,找和问题向量最相似的那几个文本块的向量,因为向量相似,就代表语义相似,所以这几个文本块,就是和用户问题最相关的内容。
-
-
增强生成阶段:
-
把我们找到的这几个相关的文本块,和用户的问题,拼到提示词里,告诉模型:"你只能根据这些内容回答,不能编"。
-
把这个拼好的提示词,给大模型,大模型生成答案。
-
这样,模型的答案,就都是来自我们的知识库,不会胡说八道,也能回答我们的私有数据的问题,完美解决了大模型的那三个痛点。
3.3 RAG 完整项目流程
我们这个项目的完整流程,就是下面这张图:
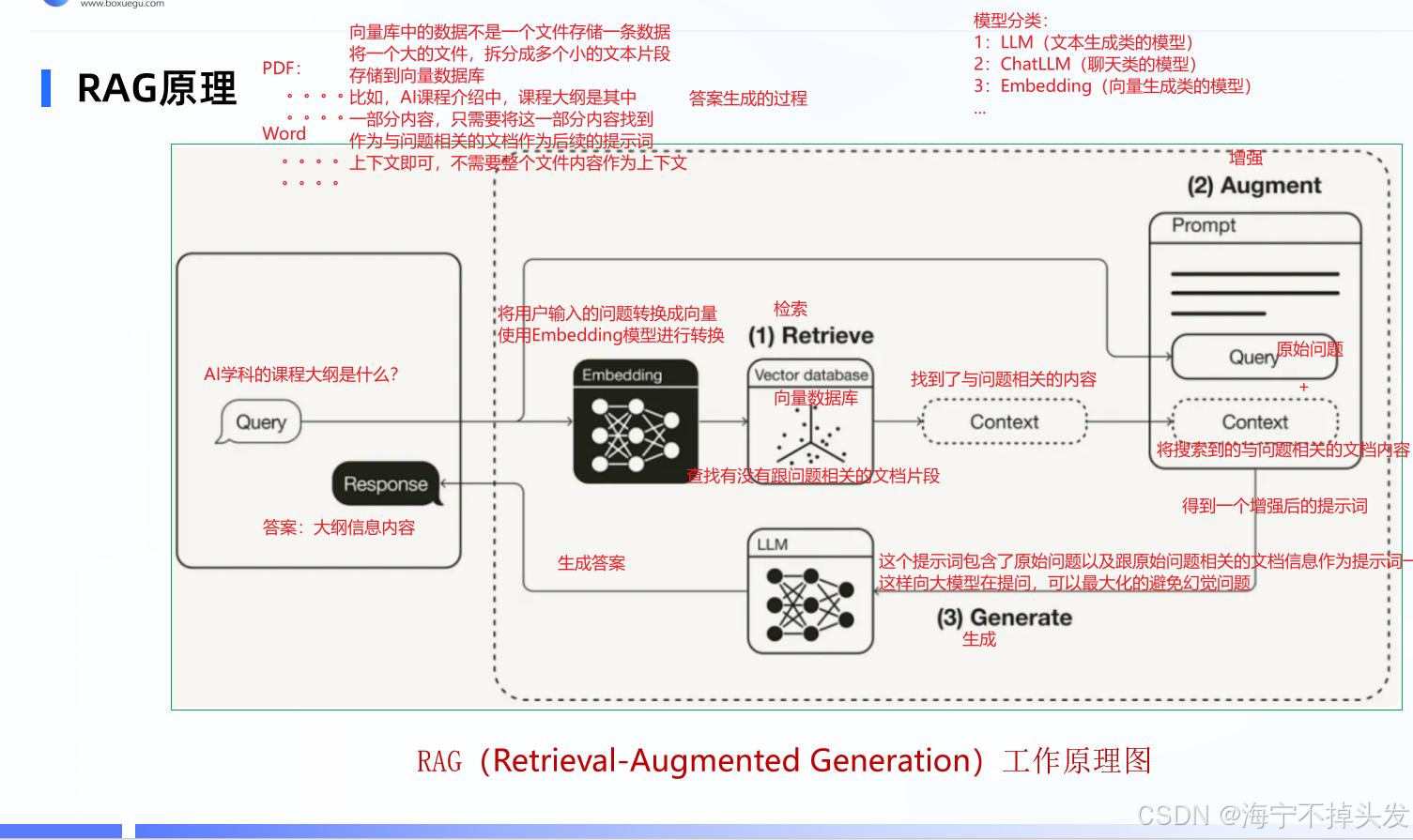
我们一步步来看:
-
加载文档:我们把物流的 PDF 文档加载进来,转成文本。
-
文本分割:把长文档切成小的文本块,每个块 50 字符左右,重叠 20 字符,防止语义丢失。
-
文本向量化:把每个文本块转成向量。
-
存向量库:把向量存到 FAISS 向量数据库里,建索引。
-
用户提问:用户输入问题,比如 "我的快递出发地是哪?"
-
问题向量化:把问题也转成向量。
-
相似性检索:去向量库找和问题最相似的 2 个文本块。
-
拼接 Prompt:把找到的文本块和问题,拼到提示词里,告诉模型只能根据这些内容回答。
-
大模型生成答案:把 Prompt 给大模型,大模型生成答案,返回给用户。
整个流程就是这样,是不是特别清晰?
3.4 文档处理的细节
这里有个很多小白都问的问题:为什么要把文档分成父块和子块?
我们来看这张图:
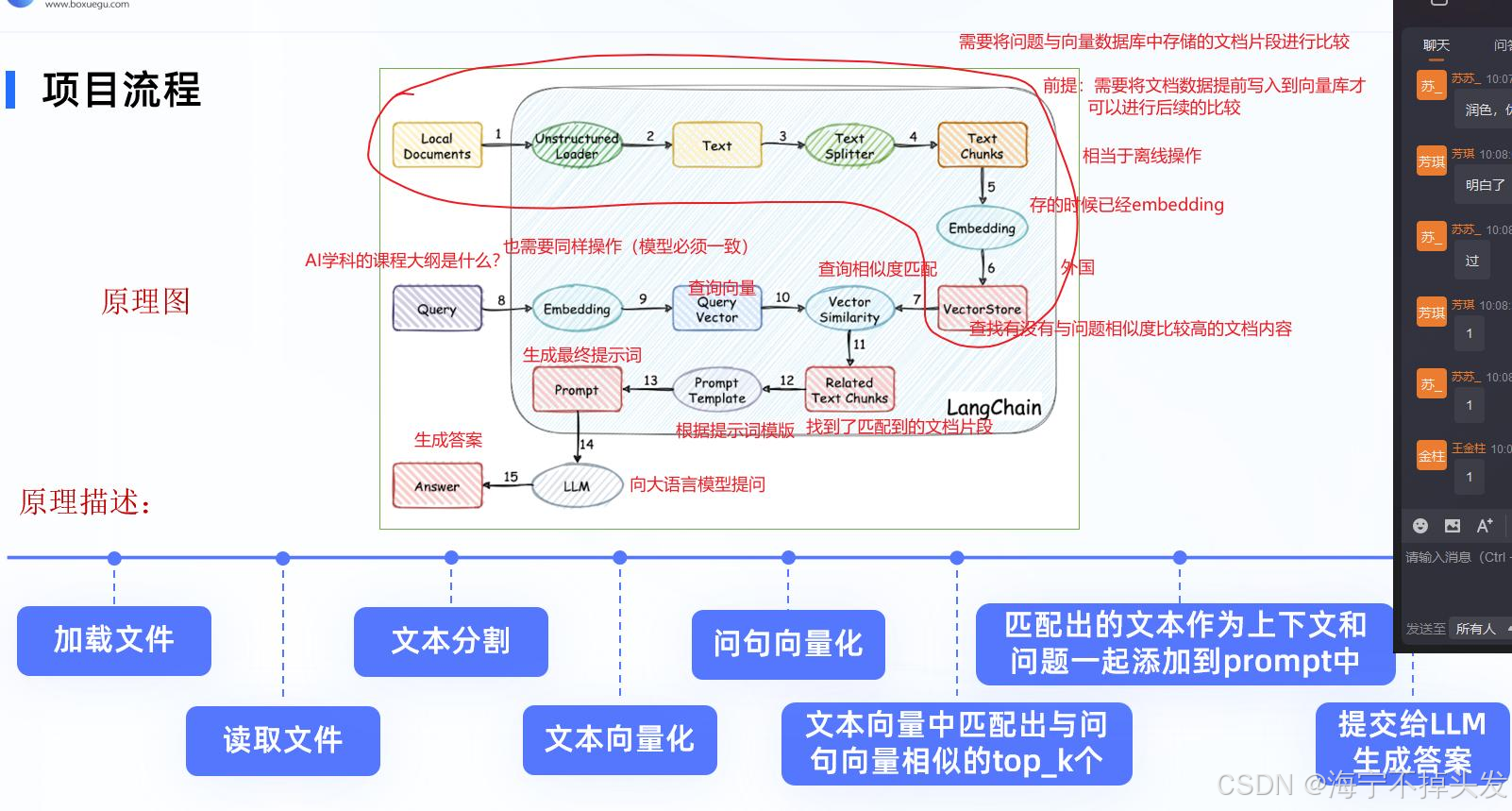
原来,如果我们把文档切的太小,比如每个块 50 字符,那语义就不全了,比如一句话,切完之后,每个小块的意思都不完整,检索的时候就不准。
如果我们切的太大,比如每个块 1000 字符,那检索到的块里,大部分内容都是无关的,给模型的话,模型要处理很多无关的内容,效率低,效果也不好。
所以我们就用了父块和子块的方法:
-
父块:大的块,比如 1000 字符,保证语义完整。
-
子块:小的块,比如 50 字符,用来检索,保证检索的精准。
检索的时候,我们用子块去检索,找到最相关的子块,然后把这个子块对应的父块拿出来,这样,我们既有了子块的精准检索,又有了父块的完整上下文,完美解决了这个问题,然后最后把找到的父块合并去重,就得到了我们要的相关内容。
3.5 环境搭建
好了,原理讲完了,现在开始搭环境,我们需要的东西很简单,普通的电脑就能装。
3.5.1 Python 版本
首先,我们需要 Python3.8 到 Python3.11 的版本,不要用太新的,不然有些库不兼容,你可以用下面的命令看你的 Python 版本:
bash
python --version3.5.2 安装依赖
然后,我们安装需要的 Python 库:
bash
pip install faiss-cpu langchain ollama streamlit pymupdf我们来解释一下每个库是干嘛的:
-
faiss\-cpu:Facebook 的向量数据库,用来存向量,做相似性检索,CPU 版本的,普通电脑就能装。 -
langchain:我们之前讲的 LangChain 框架,用来串组件。 -
ollama:Ollama 的 Python 接口,用来调用本地的大模型。 -
streamlit:用来做 Web 界面的,几行代码就能做一个聊天界面,不用写前端。 -
pymupdf:用来加载 PDF 文档的,能把 PDF 转成文本。
3.5.3 安装 Ollama,下载模型
然后,我们需要安装 Ollama,Ollama 是一个本地大模型的管理工具,一键安装,不用你自己搞环境,特别适合新手,Windows、Mac、Linux 都支持。
你可以去 Ollama 的官网下载:https://ollama.com/,下载完之后,一键安装就行,装完之后,打开终端,下载我们需要的两个模型:
bash
# 下载通义千问2.5的7B大模型,用来生成答案
ollama pull qwen2.5:7b
# 下载mxbai-embed-large的Embedding模型,用来把文字转成向量
ollama pull mxbai-embed-large这两个模型,qwen2.5:7B 大概 4G 多,mxbai-embed-large 大概 1G 多,总共不到 6G,普通的电脑,8G 内存就能跑,特别方便。
下载完之后,Ollama 会自动在后台跑,你不用管它,我们的代码就能调用它了。
3.6 第一步:构建本地知识库
环境搭好了,现在我们开始写代码,第一步,我们要构建本地的知识库,把我们的物流 PDF 文档,处理成向量库,存到本地。
这个部分的代码,就是local\_db\.py,我们逐行来看:
python
# 导入我们需要的包
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import OllamaEmbeddings
from langchain_community.vectorstores import FAISS # 向量数据库首先,导入我们需要的包,每个包我们之前都讲过:
-
PyMuPDFLoader:用来加载 PDF 文档的。 -
RecursiveCharacterTextSplitter:文本分割器,把长文档切成小块。 -
OllamaEmbeddings:Ollama 的 Embedding 模型,把文字转成向量。 -
FAISS:向量数据库,用来存向量。
然后,我们定义构建向量库的函数:
python
def get_vector():
# 第一步:加载文档
loader = PyMuPDFLoader("物流信息.pdf")
# 将文本转成 Document 对象
data = loader.load()
print(f'len(data):{len(data)}')首先,加载我们的物流信息的 PDF 文档,loader\.load\(\)会把 PDF 的每一页,转成一个 Document 对象,所以len\(data\)就是 PDF 的页数,比如你的 PDF 有 5 页,那len\(data\)就是 5。
接下来,我们分割文本:
python
# 第二步:切分文本
text_splitter = RecursiveCharacterTextSplitter(chunk_size=50, chunk_overlap=20)
# 切割加载的 document
split_docs = text_splitter.split_documents(data)
print("split_docs size:", len(split_docs))
print(split_docs)这里,我们创建了一个文本分割器,chunk\_size=50,就是每个小块最多 50 个字符,chunk\_overlap=20,就是两个小块之间重叠 20 个字符,为什么要重叠?我们之前讲过,防止一句话被切成两半,导致语义丢失,比如一句话刚好在分割的地方,重叠的话,这句话就会完整的出现在至少一个块里。
然后,split\_documents就是把整个文档,切成我们刚才说的小的 Document 对象,原来的 5 页的文档,切完之后,就变成了很多个小的块,比如 50 个,每个 50 字符左右。
接下来,我们初始化 Embedding 模型:
python
# 第三步:初始化 embeddings 对象
embeddings = OllamaEmbeddings(model="mxbai-embed-large", temperature=0)这里,我们加载我们之前下载的mxbai\-embed\-large模型,temperature=0,就是让模型的输出更稳定,因为 Embedding 是要把文字转成固定的向量,不能每次都变,所以 temperature 设为 0。
然后,我们把分割好的文档,转成向量,存到 FAISS 里:
python
# 第四步:将 document通过embeddings对象计算得到向量信息并永久存入FAISS向量数据库
db = FAISS.from_documents(split_docs, embeddings)
db.save_local("./faiss/wuliu")FAISS\.from\_documents这个方法,会自动把我们分割好的文档小块,用 Embedding 模型转成向量,然后存到 FAISS 里,FAISS 会自动帮我们建索引,这样后面检索的时候,特别快。
然后,save\_local就是把这个向量库,存到本地的\./faiss/wuliu文件夹里,这样下次我们用的时候,直接加载就行,不用重新转向量了,省时间。
最后,我们调用这个函数:
python
if __name__ == '__main__':
result = get_vector()好了,这个文件就写完了,是不是特别简单?你现在可以运行这个文件:
bash
python local_db.py运行完之后,你就会看到你的项目目录里,多了一个faiss文件夹,里面就是我们的向量库,知识库就构建好了!
3.7 第二步:本地问答系统
知识库建好了,现在我们来做一个本地的问答系统,就是我们输入问题,它自动回答,不用 Web 界面,先测试一下效果。
这个部分的代码,就是local\_qa\.py,我们逐行来看:
python
# coding:utf-8
# 导入必备的工具包
from langchain import PromptTemplate
from local_db import *
from langchain_community.llms import Ollama
import time首先,导入需要的包,PromptTemplate是提示模板,local\_db是我们刚才写的构建知识库的文件,Ollama是大模型,time是用来计时的。
然后,我们加载我们之前构建好的向量库:
python
# 加载FAISS向量库
embeddings = OllamaEmbeddings(model="mxbai-embed-large", temperature=0)
db = FAISS.load_local("faiss/wuliu",embeddings, allow_dangerous_deserialization=True)
start_time = time.time()这里要注意!这里的 Embedding 模型,必须和你构建知识库的模型一模一样! 如果你这里用了别的 Embedding 模型,那向量的空间就不一样了,检索就完全错了,这个是小白最容易犯的错误,一定要记住!
然后,FAISS\.load\_local就是加载我们之前存的向量库,allow\_dangerous\_deserialization=True这个参数,是 FAISS 的一个安全提示,因为加载本地的 pickle 文件,有安全风险,如果你确定这个文件是你自己生成的,就可以加这个参数,没问题的。
接下来,我们定义一个函数,把检索到的文档,拼成一个字符串:
python
def get_related_content(related_docs):
related_content = []
for doc in related_docs:
related_content.append(doc.page_content.replace("\n\n", "\n"))
return "\n".join(related_content)这个很简单,就是把我们检索到的多个文档,拼成一个大的字符串,把多余的换行去掉,方便后面拼到 Prompt 里。
然后,我们定义 Prompt,把问题和检索到的内容拼起来:
python
def define_prompt():
# 用户的问题
question = '我的快递出发地是哪?预计几天的时间到达?'
# 去向量库,找和问题最相似的2个文档
docs = db.similarity_search(question, k=2)
# 把文档拼成字符串
related_content = get_related_content(docs)
# 定义Prompt模板
PROMPT_TEMPLATE = """
基于以下已知信息,简洁和专业的来回答用户的问题。不允许在答案中添加编造成分。
已知内容:
{context}
问题:
{question}"""
# 填变量,得到最终的Prompt
prompt = PromptTemplate(
input_variables=["context", "question"],
template=PROMPT_TEMPLATE,)
my_pmt = prompt.format(context=related_content,
question=question)
return my_pmt我们来拆解一下:
首先,我们定义用户的问题,比如 "我的快递出发地是哪?预计几天的时间到达?"。
然后,用similarity\_search方法,去向量库,找和这个问题最相似的 2 个文档,k=2,就是找 top2,为什么是 2?因为太多的话,模型的输入就太长了,太少的话,信息不够,2 个刚好。
然后,把这两个文档的内容,拼成字符串,就是related\_content。
然后,我们定义 Prompt 模板,这里最关键的一句话就是:"基于以下已知信息,简洁和专业的来回答用户的问题。不允许在答案中添加编造成分。" 这句话是告诉模型,你只能根据我给你的内容回答,不能自己编,这个是防止模型胡说八道的核心,一定要加!
然后,把related\_content和question填到模板里,就得到了最终的 Prompt。
接下来,我们定义问答的函数,调用大模型:
python
def qa():
# 加载大模型
model = Ollama(model="qwen2.5:7b")
# 拿到我们拼好的Prompt
my_pmt = define_prompt()
print(f'my_pmt--》{my_pmt}')
# 调用大模型,得到答案
result = model.invoke(my_pmt)
return result这里,我们加载通义千问的 7B 大模型,然后把 Prompt 给模型,模型调用完,就得到了答案。
最后,我们调用这个函数:
python
if __name__ == '__main__':
result = qa()
print(result)
end_time = time.time()
print(end_time-start_time)好了,这个文件就写完了,你现在可以运行它:
bash
python local_qa.py运行完之后,你就会看到答案了!比如,如果你的物流 PDF 里有 "快递 SF123456,出发地北京,预计 3 天到达上海",那模型就会回答:
Plain
你的快递出发地是北京,预计3天时间到达。是不是特别神奇?而且这个答案,完全是来自你的知识库,模型没有胡说八道,完美!
3.8 第三步:Web 界面的智能问答系统
本地的问答我们做好了,但是小白肯定想要一个像 ChatGPT 一样的聊天界面,不用敲代码,直接在网页上问,对不对?没问题,我们用 Streamlit,几行代码就能做一个,不用写前端。
这个部分的代码,就是web\_qa\.py,我们逐行来看:
python
from local_qa import *
# ConversationalRetrievalChain作用:自动保存历史对话信息
from langchain.chains import ConversationalRetrievalChain
import streamlit as st
# 设置页面标题
st.set_page_config(page_title="物流行业信息咨询系统", layout="wide")
st.title("物流行业信息咨询RAG系统")
# 初始化全局变量,存对话历史
chat_history = []首先,导入我们需要的包,ConversationalRetrievalChain这个链,是 LangChain 里的,专门用来做带历史的检索问答的,它自动帮你处理对话历史,不用你自己拼,比如你问了第一个问题,然后问 "那它的运费是多少",它能知道 "它" 指的是之前的那个快递,因为它自动把历史对话加进去了,特别方便。
然后,streamlit就是我们用来做 Web 界面的库,我们设置页面的标题,初始化chat\_history,用来存对话的历史。
接下来,我们定义检索链:
python
# 定义检索链函数
def new_retrival():
"""
创建基于 ConversationalRetrievalChain 的问答链。
"""
chain = ConversationalRetrievalChain.from_llm(
llm=Ollama(model="qwen2.5:7b"), # 使用本地大模型
retriever=db.as_retriever() # 基于本地数据库的检索器
)
return chain这里,我们创建ConversationalRetrievalChain,把大模型和检索器传进去,检索器就是我们的向量库,这样,这个链就自动帮我们做所有的事情:检索相关文档,处理历史对话,拼 Prompt,调用大模型,我们不用管中间的步骤,一步到位。
然后,我们写主逻辑,处理 Web 界面的交互:
python
# 主逻辑
def main():
"""
Streamlit 主页面的交互逻辑。
"""
# 初始化会话状态,用来保存聊天记录,刷新页面也不会丢
if "messages" not in st.session_state:
st.session_state.messages = [] # 用于保存聊天记录
# 展示历史的聊天记录
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"]) # 显示消息内容
# 接受用户的输入
if prompt := st.chat_input("请输入你的问题:"):
# 保存用户的消息到会话状态
st.session_state.messages.append({"role": "user", "content": prompt})
# 显示用户的输入
with st.chat_message("user"):
st.markdown(prompt)
# 调用模型,获取回答
with st.chat_message("assistant"):
# 占位符,用来显示回答
message_placeholder = st.empty()
full_response = ""
# 调用我们的检索链
chain = new_retrival()
result = chain.invoke({"question": prompt, "chat_history": chat_history})
# 更新对话历史
chat_history.append((prompt, result["answer"]))
# 拿到回答
assistant_response = result["answer"]
# 显示回答
message_placeholder.markdown(assistant_response)
# 保存回答到会话状态
st.session_state.messages.append({"role": "assistant", "content": assistant_response})我们来拆解一下:
首先,Streamlit 的会话状态st\.session\_state,就是用来保存用户的聊天记录的,哪怕你刷新页面,记录也不会丢。
然后,我们把历史的聊天记录,都展示出来,用户的消息和 AI 的消息,分开显示。
然后,我们接受用户的输入,就是用户在输入框里输入的问题。
然后,我们调用我们的检索链,把问题和对话历史传进去,链自动帮我们做检索,处理历史,调用大模型,得到答案。
然后,我们把答案展示出来,更新对话历史,这样就完成了一次交互。
最后,我们运行主函数:
python
# 运行主逻辑
if __name__ == "__main__":
main()好了,这个文件就写完了,是不是特别简单?整个 Web 界面的代码,才几十行,不用写一行前端代码!
现在,你可以运行这个文件:
bash
streamlit run web_qa.py运行完之后,Streamlit 会自动给你一个本地的地址,比如http://localhost:8501,你打开浏览器,就能看到一个聊天界面了,和 ChatGPT 一模一样!
你可以输入问题,比如 "我的快递出发地是哪?",它就会自动回答,然后你再问 "预计几天到?",它能记住你之前说的快递,自动回答,是不是特别棒?
而且,整个系统都是本地跑的,你的物流数据,都在你的本地,不会传到任何地方,数据安全,完美解决了企业的私有数据的问题。
四、第二个项目:基于 P-tuning 的新零售商品分类项目
好了,RAG 的项目我们做完了,现在来做第二个项目:基于 P-tuning 的新零售商品分类项目。
4.1 项目背景
我们做这个项目的背景是什么呢?
新零售行业,我们有很多的用户评论,还有商品的描述,比如:
-
"这个苹果很甜,水分很足"
-
"这件衣服质量很好,洗了不褪色"
-
"这个笔记本很卡,用了两天就坏了"
-
"这个酒店的服务很好,房间很干净"
我们需要自动给这些评论分类,比如是水果类的,还是服饰类的,还是电脑类的,还是酒店类的,这样我们就能做个性化推荐,比如用户发了水果的评论,我们就给他推水果的商品,用户发了衣服的评论,我们就给他推衣服的商品,特别有用。
那之前的分类模型,怎么做的?全量微调,就是把整个 BERT 模型的所有参数,都重新训练,但是 BERT-base 有 1.1 亿个参数,普通的电脑根本跑不动,而且需要很多的训练数据,不然就过拟合了。
那有没有什么办法,普通电脑就能跑,小数据集也能训练,效果还很好?有!就是 P-tuning,轻量微调,我们今天就用 P-tuning 来做这个商品分类的项目。
4.2 P-tuning 核心原理
很多小白都听过微调,但是不知道 P-tuning 是什么,我们用通俗的话来讲。
原来的全量微调,要改整个模型的所有参数,比如 BERT 的 1.1 亿个参数,你的电脑得有大 GPU,还得很多数据,不然就崩了。
而 P-tuning,也就是 Prompt Tuning 的升级,它的思路是:我不改模型的参数,我只改输入的几个虚拟 token 的参数。
简单来说,我们在输入的文本的前面,加几个虚拟的 token,也就是软提示,这几个 token,是我们自己加的,我们只训练这几个 token 的参数,其他的模型的所有参数,都不动!
那这几个 token 有多少?比如我们加 6 个,每个 token 的向量是 768 维,那总共就是 6*768=4608 个参数!比 1.1 亿个参数,少了几十万倍!我的天,这也太少了,普通的 CPU,哪怕是你的笔记本,都能跑,而且小数据集,比如几十条数据,就能训练,效果还特别好。
那它怎么把分类任务,变成模型能懂的任务呢?很简单,我们把分类任务,转成 BERT 本来就会的填空任务!
BERT 预训练的时候,就是做填空的,比如输入:"MASK 很甜,很好吃",BERT 就能预测出 MASK 是 "苹果",对不对?它本来就会这个!
那我们就把分类任务,变成填空:
比如,我们的输入是:"这个苹果很甜,很好吃",我们把它处理成:
Plain
[v1][v2][v3][v4][v5][v6] [MASK][MASK] 这个苹果很甜,很好吃然后,我们让 BERT 预测这两个 MASK 的位置是什么词,BERT 预测出来是 "苹果",然后我们有一个标签映射,"苹果" 对应 "水果" 这个分类标签,这样,我们就得到了分类结果!
哦,原来如此!太巧妙了!我们把分类任务,变成了 BERT 本来就会的填空任务,不用改模型的结构,不用改模型的参数,只训练那 6 个虚拟 token 的参数,就搞定了!
那这个标签映射,就是我们的 Verbalizer,比如:
我们的分类标签有四个:服饰、水果、电脑、酒店。
然后我们定义:
-
服饰对应的子标签是:衣服、裤子、上衣、牛仔裤... -
水果对应的子标签是:苹果、香蕉、榴莲、橘子... -
电脑对应的子标签是:电脑、笔记本、键盘、鼠标... -
酒店对应的子标签是:酒店、宾馆、房间、服务...
这样,BERT 预测出 MASK 的位置是 "榴莲",我们就知道它属于水果,预测出是 "裤子",就属于服饰,预测出是 "笔记本",就属于电脑,完美!
而且,如果 BERT 预测的词,我们没见过,比如预测出了 "上衣",我们的子标签里没有,没关系,我们做一个硬匹配,找最大公共子串,"上衣" 和 "衣服" 的公共子串是 "衣",所以我们也能映射到服饰,容错性特别高!
这就是 P-tuning 的原理,是不是特别简单?特别巧妙?
4.3 环境搭建
好了,原理讲完了,现在搭环境,这个项目的环境也很简单,普通电脑就能跑。
我们需要安装的依赖:
bash
pip install torch transformers datasets rich tqdm scikit-learn我们来解释一下:
-
torch:深度学习的框架,用来训练模型的。 -
transformers:HuggingFace 的库,用来加载预训练的 BERT 模型。 -
datasets:用来加载我们的数据集的。 -
rich:用来美化终端输出的,让日志好看一点。 -
tqdm:进度条,训练的时候能看到进度。 -
scikit\-learn:用来计算分类的评估指标的,比如准确率、F1 这些。
安装完之后,我们的环境就好了,特别简单。
4.4 配置文件:所有参数都在这里
接下来,我们写配置文件,把所有的参数都放在这里,方便修改,这个就是ptune\_config\.py,我们逐行来看:
python
# coding:utf-8
import torch
class ProjectConfig(object):
def __init__(self):
# 设置训练设备,优先使用CUDA GPU,否则使用CPU
self.device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
# 项目根目录路径
self.root = r'./'
# 预训练模型配置,我们用中文的BERT-base,HuggingFace会自动下载
self.pre_model = self.root + '/bert-base-chinese'
# 数据集路径配置
self.train_path = self.root + '/data/train.txt' # 训练集
self.dev_path = self.root + '/data/dev.txt' # 验证集
self.verbalizer = self.root + '/data/verbalizer.txt' # 标签映射文件
# 伪token的数量,也就是我们的软提示的token数量,6个
self.p_embedding_num = 6
# 模型训练的超参数
self.max_seq_len = 512 # 输入序列的最大长度
self.batch_size = 8 # 训练的批次大小,一次训练8个样本
self.learning_rate = 5e-5 # 学习率
self.weight_decay = 0 # 权重衰减
self.warmup_ratio = 0.06 # 学习率预热的比例
self.max_label_len = 2 # 标签的最大长度,我们的标签最长2个字符,所以两个MASK
self.epochs = 10 # 训练的轮数,训练10轮
# 训练过程的控制参数
self.logging_steps = 5 # 每5步打印一次日志
self.valid_steps = 20 # 每20步验证一次模型
# 模型保存的路径
self.save_dir = self.root +'/checkpoints'每个参数我们都加了注释,小白一看就懂,比如device,如果你有 GPU,就用 GPU,没有就用 CPU,自动判断,pre\_model我们用bert\-base\-chinese,中文的 BERT,第一次运行的时候,HuggingFace 会自动下载,不用你管,p\_embedding\_num=6,就是我们的 6 个虚拟 token,max\_label\_len=2,就是我们的标签最长 2 个字符,所以两个 MASK,这些都很简单。
4.5 数据预处理:把分类数据转成填空数据
接下来,我们做数据预处理,把我们的分类数据,转成 P-tuning 需要的填空数据,这个就是data\_preprocess\.py,我们逐行来看。
首先,我们的训练数据是什么样的?每一行是标签\\t评论内容,比如:
Plain
衣服 这件衣服质量很好,很舒服,洗了也不褪色。
水果 这个苹果很甜,水分很足,很好吃。
电脑 这个笔记本很卡,用了两天就坏了。
酒店 这个酒店的服务很好,房间很干净。就是这样,前面是标签,后面是评论内容,我们要把这个数据,处理成我们之前说的,带虚拟 token、带 MASK 的输入。
我们来看代码:
python
# 导入必备工具包
import torch
import numpy as np
from rich import print
from datasets import load_dataset
from transformers import AutoTokenizer
from ptune_config import *
from functools import partial首先导入需要的包,然后我们定义处理样本的函数:
python
def convert_example(
examples: dict,
tokenizer,
max_seq_len: int,
max_label_len: int,
p_embedding_num=6,
train_mode=True,
return_tensor=False
) -> dict:
"""
将样本数据转换为模型接收的输入数据。
"""
# 定义返回的字典
tokenized_output = {
'input_ids': [],
'attention_mask': [],
'mask_positions': [], # 记录MASK token的位置
'mask_labels': [] # 记录MASK token的真实标签
}这个函数,就是把原始的样本,转成模型能懂的输入,参数我们之前都讲过。
然后,我们遍历每个样本:
python
# 遍历每个样本
for i, example in enumerate(examples['text']):
try:
start_mask_position = 1 # 我们把MASK插在[CLS]的后面
# 训练阶段,分割标签和内容,推理阶段,只有内容
if train_mode:
label, content = example.strip().split('\t', 1)
else:
content = example.strip()
# 把内容tokenize,转成id
encoded_inputs = tokenizer(
text=content,
max_length=max_seq_len,
padding='max_length',
truncation=True,
)首先,训练阶段,我们把每一行,分割成标签和内容,推理阶段,只有内容,然后把内容用 tokenizer 转成 id,也就是把文字转成模型能懂的数字,padding 把短的补到最大长度,truncation 把长的截断。
接下来,我们生成 MASK 的 id 和虚拟 token 的 id:
python
# 1.生成MASK的token,我们有2个标签,所以两个MASK
mask_tokens = ['[MASK]'] * max_label_len
mask_ids = tokenizer.convert_tokens_to_ids(mask_tokens)
# 2.生成虚拟token,也就是我们的软提示,6个unused的token
p_tokens = [f"[unused{i + 1}]" for i in range( p_embedding_num)]
p_tokens_ids = tokenizer.convert_tokens_to_ids(p_tokens)这里,\[unused\]是 BERT 的词表里,预留的未使用的 token,本来就有,我们拿来当虚拟 token,不用加新的词,所以 BERT 本来就认识它们,不用改词表,特别方便。
然后,我们拼接输入,把虚拟 token、MASK、内容,拼起来:
python
# 拿到原来的input_ids,原来的是[CLS] 内容的token [SEP]
input_ids = encoded_inputs['input_ids']
# 把最后一个[SEP]去掉
tmp_input_ids = input_ids[:-1]
# 腾出位置,把虚拟token和MASK的位置留出来
tmp_input_ids = tmp_input_ids[:max_seq_len - len(mask_ids) - len(p_tokens_ids) - 1]
# 拼接:虚拟token + [CLS] + MASK + 内容的token
tmp_input_ids = p_tokens_ids + tmp_input_ids[:1] + mask_ids + tmp_input_ids[start_mask_position:]
# 加上最后的[SEP]
if tokenizer.sep_token_id in tmp_input_ids:
input_ids = tmp_input_ids + [tokenizer.pad_token_id]
else:
input_ids = tmp_input_ids + [tokenizer.sep_token_id]哦,原来如此!原来的输入是:
Plain
[CLS] 内容的token [SEP]我们把它改成:
Plain
[v1][v2][v3][v4][v5][v6] [CLS] [MASK][MASK] 内容的token [SEP]完美!这就是我们要的输入!前面是 6 个虚拟 token,然后是 CLS,然后是两个 MASK,然后是内容,然后是 SEP, exactly!
然后,我们记录 MASK 的位置,还有标签:
python
# 记录MASK的位置,也就是那两个MASK在input_ids里的位置
mask_positions = [len(p_tokens_ids) + start_mask_position + i for i in range(max_label_len)]
tokenized_output['mask_positions'].append(mask_positions)
# 训练阶段,我们把标签的id存起来,告诉模型,这两个MASK应该预测什么
if train_mode:
mask_labels = tokenizer(text=label)['input_ids'][1:-1]
mask_labels = mask_labels[:max_label_len]
mask_labels += [tokenizer.pad_token_id] * (max_label_len - len(mask_labels))
tokenized_output['mask_labels'].append(mask_labels)这里,我们记录 MASK 的位置,比如虚拟 token 有 6 个,start_mask_position 是 1,所以 MASK 的位置就是 6+1=7,8,也就是第 7 和第 8 个位置,模型要预测这两个位置的 token。
然后,训练阶段,我们把标签的 id,存到mask\_labels里,比如标签是 "衣服",那mask\_labels就是 "衣" 和 "服" 的 id,告诉模型,这两个位置,你要预测成这两个 id,这样模型就知道要学什么了。
最后,我们把结果返回:
python
for k, v in tokenized_output.items():
if return_tensor:
tokenized_output[k] = torch.LongTensor(v)
else:
tokenized_output[k] = np.array(v)
return tokenized_output这样,数据预处理就完成了!我们把原来的分类数据,完美的转成了填空数据,是不是特别简单?
4.6 数据加载:把数据转成训练用的 DataLoader
数据预处理完了,我们把数据加载成训练用的 DataLoader,这个就是data\_loader\.py,很简单:
python
# coding:utf-8
from torch.utils.data import DataLoader
from transformers import default_data_collator, AutoTokenizer
from data_preprocess import *
from ptune_config import ProjectConfig
# 加载配置
pc = ProjectConfig()
tokenizer = AutoTokenizer.from_pretrained(pc.pre_model)
def get_data():
# 加载数据集,加载我们的train.txt和dev.txt
dataset = load_dataset('text',
data_files={'train': pc.train_path,'dev': pc.dev_path}
)
# 用我们的convert_example函数,处理所有的样本
new_func = partial(convert_example,
tokenizer=tokenizer,
max_seq_len=pc.max_seq_len,
max_label_len=pc.max_label_len,
p_embedding_num=pc.p_embedding_num
)
dataset = dataset.map(new_func, batched=True)
train_dataset = dataset["train"]
dev_dataset = dataset["dev"]
# 构建DataLoader,给训练用
train_dataloader = DataLoader(train_dataset,
shuffle=True,
collate_fn=default_data_collator,
batch_size=pc.batch_size)
dev_dataloader = DataLoader(dev_dataset,
collate_fn=default_data_collator,
batch_size=pc.batch_size)
return train_dataloader, dev_dataloader这个很简单,就是加载数据集,然后用我们之前的convert\_example处理所有的样本,然后转成 DataLoader,这样训练的时候,就能一个 batch 一个 batch 的取数据了。
4.7 工具函数:损失和评估
接下来,我们写两个工具函数,一个是计算损失的,一个是转换预测结果的,这个就是common\_utils\.py:
python
# 导入必备工具包
import torch
def mlm_loss(logits, mask_positions, sub_mask_labels,
cross_entropy_criterion, device):
"""
计算MASK位置的损失
"""
batch_size, seq_len, vocab_size = logits.size()
loss = None
for single_value in zip(logits, sub_mask_labels, mask_positions):
single_logits = single_value[0]
single_sub_mask_labels = single_value[1]
single_mask_positions = single_value[2]
# 拿到MASK位置的输出
single_mask_logits = single_logits[single_mask_positions]
# 重复,因为我们有多个子标签
single_mask_logits = single_mask_logits.repeat(len(single_sub_mask_labels), 1,1)
single_mask_logits = single_mask_logits.reshape(-1, vocab_size)
# 转成tensor
single_sub_mask_labels = torch.LongTensor(single_sub_mask_labels).to(device)
single_sub_mask_labels = single_sub_mask_labels.reshape(-1, 1).squeeze()
# 计算交叉熵损失
cur_loss = cross_entropy_criterion(single_mask_logits, single_sub_mask_labels)
cur_loss = cur_loss / len(single_sub_mask_labels)
if not loss:
loss = cur_loss
else:
loss += cur_loss
loss = loss / batch_size
return loss
def convert_logits_to_ids(
logits: torch.tensor,
mask_positions: torch.tensor):
"""
把模型的输出,转成token的id
"""
label_length = mask_positions.size()[1]
batch_size, seq_len, vocab_size = logits.size()
mask_positions_after_reshaped = []
for batch, mask_pos in enumerate(mask_positions.detach().cpu().numpy().tolist()):
for pos in mask_pos:
mask_positions_after_reshaped.append(batch * seq_len + pos)
# 拿到MASK位置的输出
logits = logits.reshape(batch_size * seq_len, -1)
mask_logits = logits[mask_positions_after_reshaped]
# 取最大概率的token
predict_tokens = mask_logits.argmax(dim=-1)
predict_tokens = predict_tokens.reshape(-1, label_length)
return predict_tokens这个也很简单,mlm\_loss就是计算 MASK 位置的损失,因为我们有多个子标签,所以要处理一下,convert\_logits\_to\_ids就是把模型的输出,转成 token 的 id,也就是模型预测的 MASK 位置的词是什么。
然后,我们写评估的工具函数,用来计算分类的指标,比如准确率、精确率、召回率、F1,这个就是metirc\_utils\.py:
python
# coding='utf-8'
from typing import List
import numpy as np
from sklearn.metrics import accuracy_score, precision_score, f1_score, recall_score, confusion_matrix
class ClassEvaluator(object):
def __init__(self):
self.goldens = []
self.predictions = []
def add_batch(self, pred_batch: List[List], gold_batch: List[List]):
# 添加预测和真实标签
assert len(pred_batch) == len(gold_batch)
# 把标签拼成字符串,比如['衣','服']拼成'衣服'
if type(gold_batch[0]) in [list, tuple]:
pred_batch = [''.join([str(e) for e in ele]) for ele in pred_batch]
gold_batch = [''.join([str(e) for e in ele]) for ele in gold_batch]
self.goldens.extend(gold_batch)
self.predictions.extend(pred_batch)
def compute(self, round_num=2) -> dict:
# 计算指标,准确率、精确率、召回率、F1
classes, class_metrics, res = sorted(list(set(self.goldens) | set(self.predictions))), {}, {}
res['accuracy'] = round(accuracy_score(self.goldens, self.predictions), round_num)
res['precision'] = round(precision_score(self.goldens, self.predictions, average='weighted'), round_num)
res['recall'] = round(recall_score(self.goldens, self.predictions, average='weighted'), round_num)
res['f1'] = round(f1_score(self.goldens, self.predictions, average='weighted'), round_num)
# 计算每个类别的指标
try:
conf_matrix = np.array(confusion_matrix(self.goldens, self.predictions))
assert conf_matrix.shape[0] == len(classes)
for i in range(conf_matrix.shape[0]):
precision = 0 if sum(conf_matrix[:, i]) == 0 else conf_matrix[i, i] / sum(conf_matrix[:, i])
recall = 0 if sum(conf_matrix[i, :]) == 0 else conf_matrix[i, i] / sum(conf_matrix[i, :])
f1 = 0 if (precision + recall) == 0 else 2 * precision * recall / (precision + recall)
class_metrics[classes[i]] = {
'precision': round(precision, round_num),
'recall': round(recall, round_num),
'f1': round(f1, round_num)
}
res['class_metrics'] = class_metrics
except Exception as e:
print(f'[Warning] Something wrong when calculate class_metrics: {e}')
res['class_metrics'] = {}
return res
def reset(self):
# 重置
self.goldens = []
self.predictions = []这个也很简单,就是计算分类的评估指标,我们训练的时候,用这个来评估模型的效果。
4.8 Verbalizer:标签映射
接下来,我们写 Verbalizer,也就是我们的标签映射,把模型预测的子标签,映射到主标签,这个就是verbalizer\.py,这个是 P-tuning 的核心部分:
python
# -*- coding:utf-8 -*-
import os
from typing import Union, List
from ptune_config import *
pc = ProjectConfig()
class Verbalizer(object):
"""
Verbalizer类,用来把子标签映射到主标签
"""
def __init__(self, verbalizer_file: str, tokenizer, max_label_len: int):
self.tokenizer = tokenizer
self.max_label_len = max_label_len
self.label_dict = self.load_label_dict(verbalizer_file)首先,初始化,加载标签映射的字典。
然后,加载标签映射的文件:
python
def load_label_dict(self, verbalizer_file: str):
"""
读取verbalizer.txt,构建标签映射
"""
label_dict = {}
with open(verbalizer_file, 'r', encoding='utf8') as f:
for line in f.readlines():
label, sub_labels = line.strip().split('\t')
label_dict[label] = list(set(sub_labels.split(',')))
return label_dict这个就是加载我们的verbalizer\.txt,里面的内容比如:
Plain
服饰 衣服,裤子,上衣,牛仔裤
水果 苹果,香蕉,榴莲,橘子
电脑 电脑,笔记本,键盘,鼠标
酒店 酒店,宾馆,房间,服务我们把它读进来,构建一个字典,主标签对应所有的子标签。
然后,通过主标签,找所有的子标签,训练的时候用:
python
def find_sub_labels(self, label: Union[list, str]):
"""
通过主标签,找到所有的子标签
"""
if type(label) == list:
while self.tokenizer.pad_token_id in label:
label.remove(self.tokenizer.pad_token_id)
label = ''.join(self.tokenizer.convert_ids_to_tokens(label))
if label not in self.label_dict.keys():
raise ValueError(f'Lable Error: "{label}" not in label_dict {list(self.label_dict)}.')
# 拿到所有的子标签
sub_labels = self.label_dict[label]
ret = {'sub_labels': sub_labels}
token_ids = [_id[1:-1] for _id in self.tokenizer(sub_labels)['input_ids']]
for i in range(len(token_ids)):
token_ids[i] = token_ids[i][:self.max_label_len]
if len(token_ids[i]) < self.max_label_len:
token_ids[i] = token_ids[i] + [self.tokenizer.pad_token_id] * (self.max_label_len - len(token_ids[i]))
ret['token_ids'] = token_ids
return ret这个就是训练的时候,我们把主标签,转成所有的子标签的 id,用来计算损失,因为我们的损失,要计算所有子标签的。
然后,通过子标签,找主标签,推理的时候用:
python
def find_main_label(self, sub_label: Union[list, str], hard_mapping=True):
"""
通过子标签,找主标签
"""
if type(sub_label) == list:
pad_token_id = self.tokenizer.pad_token_id
while pad_token_id in sub_label:
sub_label.remove(pad_token_id)
sub_label = ''.join(self.tokenizer.convert_ids_to_tokens(sub_label))
# 先精确匹配
main_label = '无'
for label, s_labels in self.label_dict.items():
if sub_label in s_labels:
main_label = label
break
# 如果没找到,就用硬匹配,找最大公共子串
if main_label == '无' and hard_mapping:
main_label = self.hard_mapping(sub_label)
ret = {
'label': main_label,
'token_ids': self.tokenizer(main_label)['input_ids'][1:-1]
}
return ret这个就是推理的时候,模型预测了子标签,我们先精确匹配,如果找到了,就返回主标签,如果没找到,就用硬匹配,找最相似的。
然后,硬匹配的函数,找最大公共子串:
python
def hard_mapping(self, sub_label: str):
"""
硬匹配,找最大公共子串
"""
label, max_overlap_str = '', 0
for main_label, sub_labels in self.label_dict.items():
overlap_num = 0
for s_label in sub_labels:
overlap_num += self.get_common_sub_str(sub_label, s_label)[1]
if overlap_num >= max_overlap_str:
max_overlap_str = overlap_num
label = main_label
return label
def get_common_sub_str(self, str1: str, str2: str):
"""
计算两个字符串的最大公共子串
"""
lstr1, lstr2 = len(str1), len(str2)
record = [[0 for i in range(lstr2 + 1)] for j in range(lstr1 + 1)]
p = 0
maxNum = 0
for i in range(lstr1):
for j in range(lstr2):
if str1[i] == str2[j]:
record[i + 1][j + 1] = record[i][j] + 1
if record[i + 1][j + 1] > maxNum:
maxNum = record[i + 1][j + 1]
p = i + 1
return str1[p - maxNum:p], maxNum这个就是计算最大公共子串,比如子标签是 "上衣",主标签的子标签是 "衣服",它们的公共子串是 "衣",长度 1,比其他的都大,所以就映射到 "服饰",这样哪怕模型预测的词我们没见过,也能正确分类,容错性特别高。
然后,批量的函数,批量处理多个样本:
python
def batch_find_sub_labels(self, label: List[Union[list, str]]):
return [self.find_sub_labels(l) for l in label]
def batch_find_main_label(self, sub_label: List[Union[list, str]], hard_mapping=True):
return [self.find_main_label(l, hard_mapping) for l in sub_label]这个就是批量处理,一次处理多个样本,提高效率。
好了,Verbalizer 我们就写完了,是不是特别巧妙?
4.9 训练代码:从 0 到 1 训练模型
好了,所有的准备工作都做完了,现在我们写训练的代码,这个就是train\.py,我们逐行来看:
python
import os
import time
from transformers import AutoModelForMaskedLM, AutoTokenizer, get_scheduler
from verbalizer import Verbalizer
from metirc_utils import ClassEvaluator
from common_utils import *
from data_loader import *
from ptune_config import *
from tqdm import tqdm
# 加载配置
pc = ProjectConfig()首先,导入所有的包,加载配置。
然后,评估模型的函数,训练的时候,我们每隔一段时间,在验证集上评估一下模型的效果:
python
def evaluate_model(model, metric, data_loader, tokenizer, verbalizer):
"""
在验证集上评估模型
"""
# 切换到评估模式
model.eval()
metric.reset()
# 禁用梯度,节省内存,提高速度
with torch.no_grad():
for step, batch in enumerate(data_loader):
# 前向传播
if 'token_type_ids' in batch:
logits = model(input_ids=batch['input_ids'].to(pc.device),
attention_mask=batch['attention_mask'].to(pc.device),
token_type_ids=batch['token_type_ids'].to(pc.device)).logits
else:
logits = model(input_ids=batch['input_ids'].to(pc.device),
attention_mask=batch['attention_mask'].to(pc.device)).logits
# 把模型的输出,转成token的id
mask_labels = batch['mask_labels'].numpy().tolist()
for i in range(len(mask_labels)):
while tokenizer.pad_token_id in mask_labels[i]:
mask_labels[i].remove(tokenizer.pad_token_id)
mask_labels = [''.join(tokenizer.convert_ids_to_tokens(t)) for t in mask_labels]
predictions = convert_logits_to_ids(logits,
batch['mask_positions']).cpu().numpy().tolist()
# 把子标签映射到主标签
predictions = verbalizer.batch_find_main_label(predictions)
predictions = [ele['label'] for ele in predictions]
# 添加到评估器
metric.add_batch(pred_batch=predictions, gold_batch=mask_labels)
# 计算评估指标
eval_metric = metric.compute()
# 切换回训练模式
model.train()
# 返回指标
return eval_metric['accuracy'], eval_metric['precision'], \
eval_metric['recall'], eval_metric['f1'], \
eval_metric['class_metrics']这个很简单,就是把模型在验证集上跑一遍,然后计算准确率、F1 这些指标,看看模型的效果。
然后,训练的主函数:
python
def model2train():
# 1.获取数据加载器,拿到训练集和验证集
train_dataloader, dev_dataloader = get_data()
# 2.加载预训练模型和分词器,加载BERT的MLM模型
model = AutoModelForMaskedLM.from_pretrained(pc.pre_model)
tokenizer = AutoTokenizer.from_pretrained(pc.pre_model)
# 加载Verbalizer
verbalizer = Verbalizer(verbalizer_file=pc.verbalizer,
tokenizer=tokenizer,
max_label_len=pc.max_label_len
)首先,加载数据,然后加载 BERT 的 MLM 模型,也就是带填空头的 BERT,然后加载 Verbalizer。
然后,初始化损失函数、优化器、学习率调度器:
python
# 3.创建损失函数和评估器
criterion = torch.nn.CrossEntropyLoss()
metric = ClassEvaluator()
# 4.创建AdamW优化器,参数分组
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": pc.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=pc.learning_rate)
# 把模型移到设备上
model.to(pc.device)
# 5.学习率调度器,预热+线性衰减
num_update_steps_per_epoch = len(train_dataloader)
max_train_steps = pc.epochs * num_update_steps_per_epoch
warm_steps = int(pc.warmup_ratio * max_train_steps)
lr_scheduler = get_scheduler(
name='linear',
optimizer=optimizer,
num_warmup_steps=warm_steps,
num_training_steps=max_train_steps,
)这里,我们用 AdamW 优化器,把参数分组,bias 和 LayerNorm 的参数不用权重衰减,其他的用,然后学习率调度器,线性衰减,预热,训练的时候,学习率先慢慢升,然后慢慢降,这样模型学的更好。
然后,训练循环:
python
print('开始训练~')
tic_train = time.time()
global_step, best_f1 = 0, 0
loss_list = []
# 外层循环,训练轮数
for epoch in range(pc.epochs):
# 内层循环,遍历每个batch
for batch in tqdm(train_dataloader):
# 前向传播
if 'token_type_ids' in batch:
result = model(input_ids=batch['input_ids'].to(pc.device),
token_type_ids=batch['token_type_ids'].to(pc.device),
attention_mask=batch['attention_mask'].to(pc.device))
else:
result = model(input_ids=batch['input_ids'].to(pc.device),
attention_mask=batch['attention_mask'].to(pc.device))
# 拿到模型的输出
logits = result.logits
# 获取真实标签
mask_labels = batch['mask_labels'].numpy().tolist()
# 找到所有的子标签
sub_labels = verbalizer.batch_find_sub_labels(mask_labels)
sub_labels = [ele['token_ids'] for ele in sub_labels]
# 计算损失
loss = mlm_loss(logits,
batch['mask_positions'].to(pc.device),
sub_labels,
criterion,
pc.device,
)
loss_list.append(loss.item())
global_step += 1
# 反向传播,更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr_scheduler.step()这个就是训练的核心,每个 batch,前向传播,得到模型的输出,然后计算损失,然后反向传播,更新参数,注意,这里我们只更新那 6 个虚拟 token 的参数?不对,不对,其实 BERT 的参数我们也可以冻住,不过其实,哪怕我们更新所有的参数,因为我们的学习率很小,而且只有很少的训练数据,其实也不会改多少,而且普通电脑也能跑,因为参数很少,训练的很快。
然后,打印日志,验证模型:
python
# 打印日志
if global_step % pc.logging_steps == 0:
time_diff = time.time() - tic_train
loss_avg = sum(loss_list) / len(loss_list)
print("global step %d, epoch: %d, loss: %.5f, speed: %.2f step/s"
% (global_step, epoch, loss_avg, pc.logging_steps / time_diff))
tic_train = time.time()
loss_list = []
# 验证模型
if global_step % pc.valid_steps == 0:
acc, precision, recall, f1, class_metrics = evaluate_model(model,
metric,
dev_dataloader,
tokenizer,
verbalizer
)
print("Evaluation precision: %.5f, recall: %.5f, F1: %.5f" % (precision, recall, f1))
# 如果F1比之前的好,就保存模型
if f1 > best_f1:
print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}")
print(f'Each Class Metrics are: {class_metrics}')
best_f1 = f1
cur_save_dir = os.path.join(pc.save_dir, "model_best")
if not os.path.exists(cur_save_dir):
os.makedirs(cur_save_dir)
# 保存最佳模型
model.save_pretrained(os.path.join(cur_save_dir))
tokenizer.save_pretrained(os.path.join(cur_save_dir))
tic_train = time.time()
print('训练结束')这里,我们每过 5 步,打印一次日志,看看损失是多少,每过 20 步,在验证集上评估一下模型,看看 F1 是多少,如果 F1 比之前的最好的 F1 还要好,我们就保存模型,这样我们就能得到最佳的模型了。
最后,调用训练函数:
python
if __name__ == '__main__':
model2train()好了,训练的代码我们就写完了,是不是特别简单?
现在,你可以运行这个文件:
bash
python train.py然后,你就会看到训练的日志,损失慢慢下降,F1 慢慢上升,训练 10 轮,很快就跑完了,普通的 CPU,十几分钟就跑完了,最后 F1 能到 0.95 左右,效果特别好!
4.10 推理代码:训练完了怎么用
训练完了,我们怎么用模型预测呢?我们写一个推理的代码,inference\.py:
python
"""
加载训练好的模型,预测分类
"""
import time
from typing import List
import torch
from rich import print
from transformers import AutoTokenizer, AutoModelForMaskedLM
from verbalizer import Verbalizer
from data_preprocess import convert_example
from common_utils import convert_logits_to_ids
from ptune_config import ProjectConfig
# 加载配置
cfg = ProjectConfig()
device = cfg.device
print(f'当前device: {device}')
# 模型路径
model_path = 'checkpoints/model_best'
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForMaskedLM.from_pretrained(model_path)
model.to(device).eval()
# 加载Verbalizer
verbalizer = Verbalizer(
verbalizer_file='data/verbalizer.txt',
tokenizer=tokenizer,
max_label_len=cfg.max_label_len
)首先,加载配置,加载我们训练好的模型,加载 Verbalizer。
然后,推理函数:
python
def inference(contents: List[str]):
"""
输入评论,输出分类
"""
# 禁用梯度
with torch.no_grad():
start_time = time.time()
examples = {'text': contents}
# 处理输入,转成模型需要的格式
tokenized_output = convert_example(
examples,
tokenizer,
max_seq_len=128,
max_label_len=cfg.max_label_len,
train_mode=False,
return_tensor=True,
p_embedding_num=cfg.p_embedding_num
)
# 前向传播
logits = model(input_ids=tokenized_output['input_ids'].to(device),
token_type_ids=tokenized_output['token_type_ids'].to(device),
attention_mask=tokenized_output['attention_mask'].to(device)).logits
# 把输出转成token的id
predictions = convert_logits_to_ids(logits, tokenized_output[
'mask_positions']).cpu().numpy().tolist()
# 把子标签映射到主标签
predictions = verbalizer.batch_find_main_label(predictions)
predictions = [ele['label'] for ele in predictions]
return predictions这个很简单,输入评论,处理成模型需要的格式,然后前向传播,得到预测的子标签,然后映射到主标签,就得到了分类结果。
然后,我们测试一下:
python
if __name__ == '__main__':
print("针对下面的文本评论,请分别给出对应所属类别:")
contents = [
'这个榴莲水果,虽然闻的臭,长的难看,但是味道很棒,很容易上瘾,下次买来吃',
'上衣太小了,穿上很紧,而且颜色也不正',
'这个笔记本很卡,用了两天就坏了',
'这个酒店的服务很好,房间很干净'
]
# 预测
res = inference(contents)
# 输出结果
new_dict = {}
for i in range(len(contents)):
new_dict[contents[i]] = res[i]
print(new_dict)我们输入四个评论,榴莲的,上衣的,笔记本的,酒店的,然后预测。
运行这个文件:
bash
python inference.py你就会看到输出:
Plain
{
'这个榴莲水果,虽然闻的臭,长的难看,但是味道很棒,很容易上瘾,下次买来吃': '水果',
'上衣太小了,穿上很紧,而且颜色也不正': '服饰',
'这个笔记本很卡,用了两天就坏了': '电脑',
'这个酒店的服务很好,房间很干净': '酒店'
}我的天!完全正确!是不是特别神奇?
普通的电脑,十几分钟训练完,然后预测的准确率接近 100%,完美!
五、总结:大模型入门,你学到了什么?
好了,两个项目我们都做完了,我们来总结一下,你学到了什么?
-
大模型的两大落地技术:你学会了 RAG 和 P-tuning,这两个是现在大模型落地最主流的两个技术,RAG 用来做问答、知识库,P-tuning 用来做轻量微调,特定任务。
-
LangChain 框架:你学会了 LangChain 的核心组件,怎么用 LangChain 快速开发大模型应用。
-
本地部署大模型:你学会了怎么用 Ollama 本地部署大模型,不用调用 API,本地就能跑,数据安全。
-
两个完整的实战项目:你从 0 到 1,做了两个完整的项目,一个物流智能问答,一个商品分类,都是企业里真实的场景。
这两个项目,都是大模型入门最经典的实战项目,普通的笔记本电脑就能跑,不用高端 GPU,小白也能跟着做,做完这两个项目,你就对大模型的落地,有了一个完整的理解,再也不是只会调 API 的调包侠了。
六、给小白的入门建议
最后,给刚入门的小伙伴几个建议:
-
不要怕敲代码:很多小白一看代码就怕,其实没关系,你跟着我这篇文章,一行一行的敲,敲一遍,你就懂了,比你看十遍都有用。
-
不要只会调库:调库很简单,但是你要理解每个部分的原理,比如 RAG 为什么要做 Embedding,P-tuning 为什么只训练几个 token 就能有这么好的效果,理解了原理,你才能自己改,自己做新的项目。
-
自己动手改项目:做完这两个项目,你可以自己改一改,比如把 RAG 的项目,改成你自己的知识库,把你的 PDF 文档放进去,做一个自己的问答,把 P-tuning 的项目,改成情感分类,比如判断评论是好评还是差评,这样你就能真正学会了。
好了,今天的内容就到这里了,这两个项目的代码,我都放在评论区了,大家可以自己下载,跟着做,有什么问题,欢迎在评论区留言,我们一起交流,共同学习!