在人工智能与计算机视觉技术飞速发展的当下,文字识别(OCR)作为信息提取的核心技术,已广泛应用于文档数字化、智能监控、自动驾驶、跨境电商等众多领域。百度开源的 PaddleOCR 凭借其轻量级、高精度、多语言支持等特性,成为开发者实现 OCR 功能的首选工具之一。本文将从实战角度出发,结合具体代码案例,详细讲解 PaddleOCR 的核心用法,包括静态图片多语言识别、静态图片文字标注展示、摄像头实时文字检测与中文显示等场景,帮助开发者快速上手并灵活运用 PaddleOCR 解决实际问题。
一、PaddleOCR 基础认知
1.1 PaddleOCR 简介
PaddleOCR 是基于飞桨(PaddlePaddle)深度学习框架开发的一套端到端的 OCR 工具库,具备超轻量级、高精度、多语言、易部署等优势。它集成了文本检测、文本识别、角度分类等核心功能,支持中文、英文、日语、韩语等多种语言的识别,同时提供了丰富的预训练模型,开发者无需从零训练,即可快速实现 OCR 功能。
1.2 核心特性
- 多语言支持:覆盖中、英、日、韩、法、德等数十种语言,满足跨境场景需求;
- 角度自适应:内置角度分类器,可识别旋转(如 90°、180°)的文字,提升识别鲁棒性;
- 轻量化部署:提供超轻量级模型,可部署于移动端、嵌入式设备等资源受限场景;
- 高精度识别:基于海量标注数据训练,在通用场景下识别准确率远超传统 OCR 方案;
- 易用性强:API 设计简洁,配套完善的文档和示例,降低开发门槛。
1.3 环境准备
在开始实战前,需完成基础环境搭建:
建议使用虚拟环境,安装PaddlePaddle,PaddleOCR避免版本冲突
- 安装 Python 环境(推荐 3.7-3.9 版本)
在E盘新建一个文件夹huanjing,在这个文件夹中创建名为为src(名字任意取)文件夹,
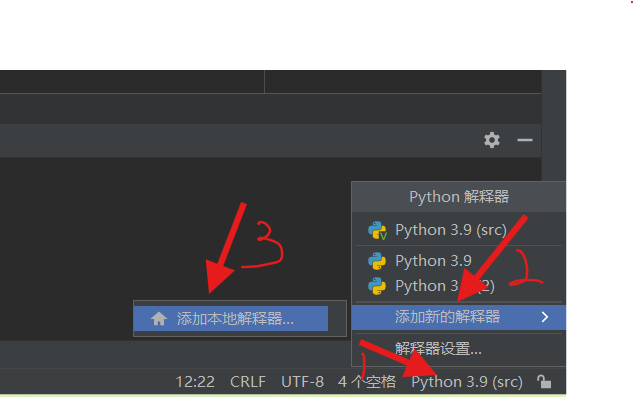
回到pyCharm按照以下步骤操作:
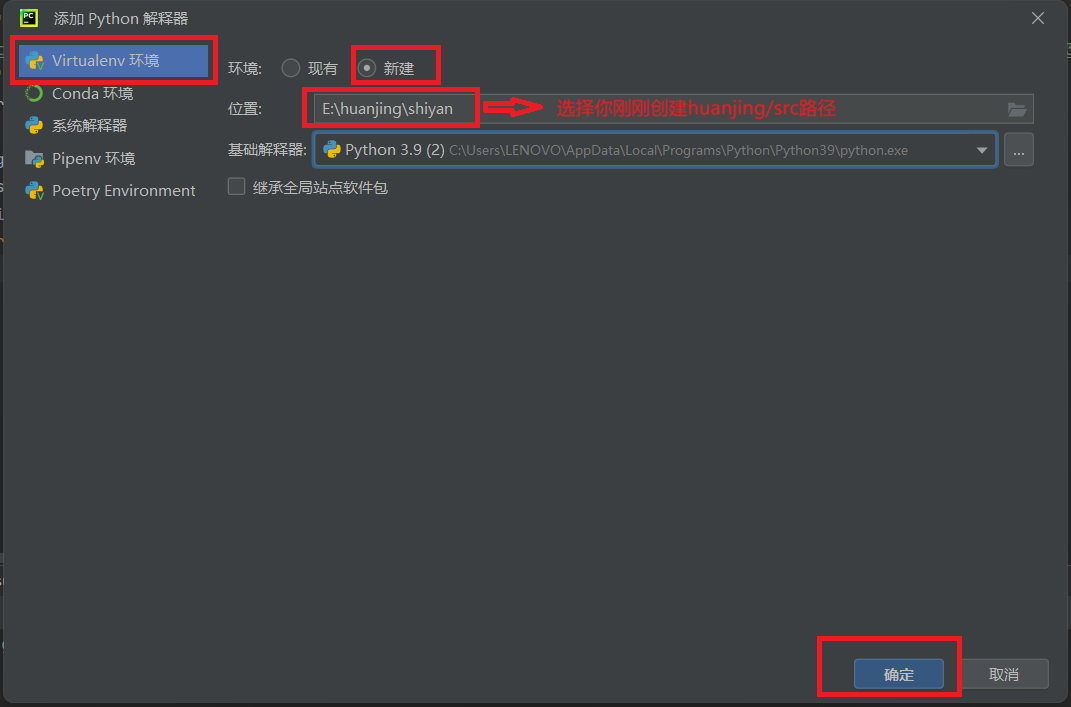
接着找到你刚刚创建的文件夹路径,点开Scripts
在文件目录输入cmd,进入命令提示符
输入activate,回车就可以安装PaddlePaddle,PaddleOCR
二、静态图片多语言文字识别:从基础到实战
2.1 核心原理
静态图片 OCR 识别的核心流程为:加载图片→调用 PaddleOCR 的 ocr 接口→解析识别结果。PaddleOCR 的ocr()方法会先对图片进行文本检测(定位文字区域),再对每个区域进行文字识别,最终返回包含文字区域坐标、识别文本、置信度的结构化结果。
2.2 代码实现:日语文字识别
以日语图片识别为例,编写基础识别代码(对应示例中 "文字识别.py"):
python
from paddleocr import PaddleOCR
# 初始化PaddleOCR对象
# use_angle_cls:是否启用角度分类(处理旋转文字)
# use_gpu:是否使用GPU(False为CPU模式)
# show_log:是否显示日志(False关闭冗余日志)
# lang:指定识别语言(japan为日语,ch为中文,en为英文)
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, show_log=False, lang='japan')
# 图片路径(建议使用绝对路径,避免路径问题)
img_path = r'img_2.png'
# 执行OCR识别,cls=True表示启用角度分类
result = ocr.ocr(img_path, cls=True)
# 解析识别结果
print("完整识别结果:")
print(result)
print("\n提取的文字内容:")
# result[0]为识别的文本行列表,每行包含坐标和文字信息
for line in result[0]:
# line[1][0]为识别出的文字内容,line[1][1]为置信度
print(line[1][0])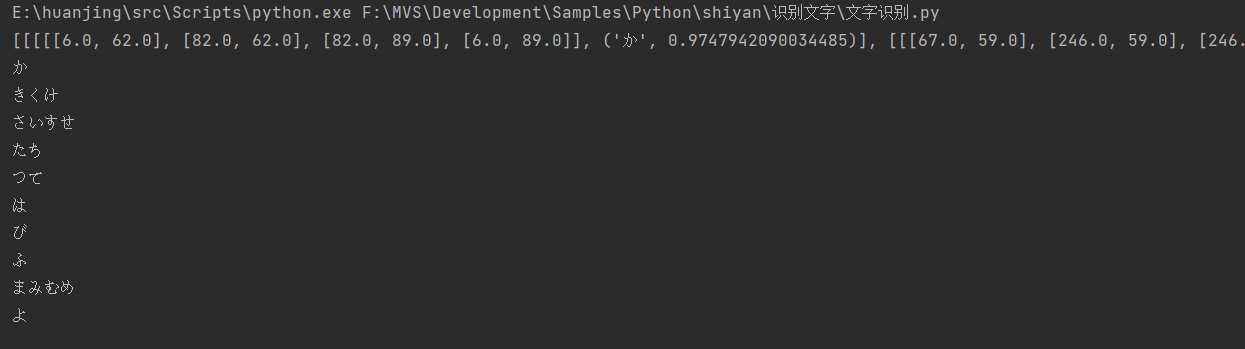
2.3 代码解析
- 初始化参数:
use_angle_cls=True是关键参数,尤其适用于拍摄角度倾斜的图片,能自动校正文字角度,提升识别准确率;lang参数需根据识别语言调整,如识别中文设为ch,英文设为en; - 结果解析:
ocr()方法返回的result是一个嵌套列表,第一层对应图片(批量识别时可传入多张),第二层为每一行文字的信息,其中line[0]是文字区域的四个顶点坐标(左上、右上、右下、左下),line[1]是一个元组,包含识别文本和置信度(0-1,越接近 1 准确率越高)。
2.4 多语言适配技巧
只需修改lang参数即可切换识别语言:
- 英文识别:
lang='en',适用于英文文档、商品标签等场景; - 中文识别:
lang='ch',支持简体、繁体中文,是最常用的场景; - 多语言混合:若图片包含多种语言(如中英文混合),优先选择
lang='ch'(中文模型对中英混合场景适配更好)。
三、静态图片文字识别与可视化标注
3.1 应用场景
在很多场景下,仅输出文字内容不够直观,需要将识别出的文字区域用框标注,并将文字内容显示在图片上,便于验证识别效果(如文档审核、图片标注等场景)。
3.2 代码实现:英文图片标注展示
以英文图片为例,实现文字区域标注和文字显示(对应示例中 "图片编号展示.py"):
python
from paddleocr import PaddleOCR
import cv2
import numpy as np
# 初始化OCR对象,指定语言为英文
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, show_log=False, lang='en')
# 读取图片(OpenCV默认以BGR格式读取)
frame = cv2.imread('img_3.png')
# 执行OCR识别
result = ocr.ocr(frame, cls=True)
# 解析结果并绘制标注
if not None in result: # 确保识别结果非空
for line in result[0]:
# 提取文字区域坐标并转换为整数类型
pts_int = np.array(line[0], dtype=np.int32)
# 调整坐标格式,适配cv2.polylines要求(形状为(-1,1,2))
pts = pts_int.reshape((-1, 1, 2))
# 绘制文字区域多边形框(紫色,线宽2)
cv2.polylines(frame, [pts], isClosed=True, color=(147, 20, 255), thickness=2)
# 在文字区域左上角绘制识别的文字(红色,字体大小1,线宽3)
cv2.putText(frame, line[1][0], (pts_int[0]), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 3)
# 显示标注后的图片
cv2.imshow('OCR Result', frame)
# 等待按键输入后关闭窗口(0表示无限等待)
cv2.waitKey(0)
# 释放窗口资源
cv2.destroyAllWindows()
3.3 核心知识点解析
3.3.1 OpenCV 图像处理基础
cv2.imread():读取图片,返回 NumPy 数组(BGR 格式);cv2.polylines():绘制多边形,参数说明:img:待绘制的图片数组;pts:多边形顶点坐标,需满足形状要求;isClosed=True:闭合多边形(连接最后一个点和第一个点);color:颜色值(BGR 格式,如 (147,20,255) 为紫色);thickness:线宽。
cv2.putText():绘制文字,参数说明:text:要显示的文字内容;org:文字起始坐标(左下角);fontFace:字体类型(如cv2.FONT_HERSHEY_SIMPLEX为默认字体);fontScale:字体缩放比例;color:文字颜色(BGR 格式);thickness:文字线条宽度。
3.3.2 坐标格式转换
PaddleOCR 返回的坐标是浮点数类型,而 OpenCV 绘制图形需要整数坐标,因此需通过np.array(line[0], dtype=np.int32)转换类型;同时,cv2.polylines()要求坐标形状为(-1,1,2),需通过reshape调整。
3.3.3 结果非空判断
if not None in result用于避免因图片无文字导致的result[0]索引报错,提升代码鲁棒性。
四、摄像头实时文字检测与中文显示
4.1 应用场景
实时文字检测适用于智能监控、扫码识别、现场信息提取等场景,例如超市收银台实时识别商品价格、地铁站识别乘客健康码文字信息等。由于 OpenCV 默认不支持中文显示,需结合 Pillow 库实现中文文字绘制。
4.2 代码实现:摄像头实时中文识别
(对应示例中 "摄像头识别文字.py"):
python
from paddleocr import PaddleOCR
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
# 定义中文绘制函数:解决OpenCV无法显示中文的问题
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
# 判断图片类型:若为NumPy数组(OpenCV格式),转换为Pillow的Image对象
if (isinstance(img, np.ndarray)):
# OpenCV默认BGR格式,转换为RGB格式(Pillow使用RGB)
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建绘制对象
draw = ImageDraw.Draw(img)
# 加载中文字体(需确保系统有该字体文件,simsun.ttc为宋体)
fontStyle = ImageFont.truetype('simsun.ttc', textSize, encoding='utf-8')
# 绘制中文文字
draw.text(position, text, textColor, font=fontStyle)
# 转换回OpenCV格式(BGR)并返回
return cv2.cvtColor(np.asarray(img), cv2.COLOR_RGB2BGR)
# 初始化OCR对象,指定语言为中文
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, show_log=False, lang='ch')
# 打开摄像头(0为默认摄像头,若有多个摄像头可改为1、2等)
cap = cv2.VideoCapture(0)
# 实时读取摄像头帧并处理
while True:
# 读取一帧画面(ret为是否读取成功,frame为帧数据)
ret, frame = cap.read()
if not ret: # 若读取失败,退出循环
break
# 执行OCR识别
result = ocr.ocr(frame, cls=True)
# 解析并标注结果
if not None in result:
for line in result[0]:
# 提取文字区域坐标
pts_int = np.array(line[0], dtype=np.int32)
pts = pts_int.reshape((-1, 1, 2))
# 提取识别的文字内容
zi = line[1][0]
# 获取文字区域左上角坐标
x, y = pts_int[0]
# 绘制文字区域框
cv2.polylines(frame, [pts], isClosed=True, color=(147, 20, 255), thickness=2)
# 绘制中文文字(文字位置上移30像素,避免与框重叠)
frame = cv2AddChineseText(frame, zi, (x, y-30))
# 显示实时处理结果
cv2.imshow('Real-Time OCR', frame)
# 按下ESC键(ASCII码27)退出循环
if cv2.waitKey(1) == 27:
break
# 释放摄像头资源
cap.release()
# 关闭所有窗口
cv2.destroyAllWindows()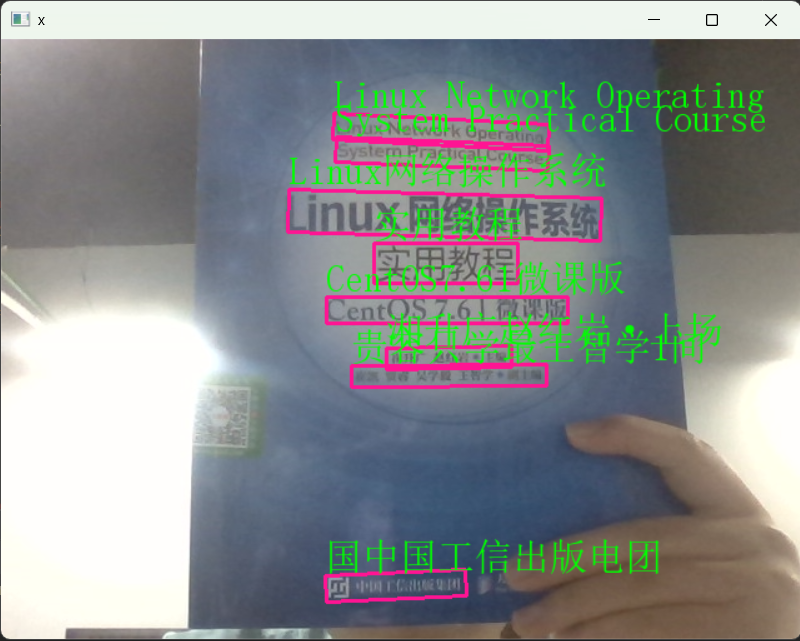
4.3 关键技术点解析
4.3.1 中文显示解决方案
OpenCV 的cv2.putText()仅支持 ASCII 字符,无法显示中文,因此需借助 Pillow 库:
- 将 OpenCV 的 BGR 格式图片转换为 Pillow 的 RGB 格式;
- 使用
ImageFont.truetype()加载中文字体(需确保系统存在对应的字体文件,如 Windows 的simsun.ttc、Linux 的/usr/share/fonts/truetype/liberation/LiberationSans-Regular.ttf); - 用
ImageDraw.Draw.text()绘制中文; - 转换回 OpenCV 格式,完成中文显示。
4.3.2 摄像头实时处理逻辑
cv2.VideoCapture(0):打开默认摄像头,返回视频捕获对象;- 无限循环读取帧:
while True持续读取摄像头画面,ret判断帧是否读取成功; cv2.waitKey(1):等待 1 毫秒,检测按键输入,返回按键的 ASCII 码,按下 ESC 键(27)退出循环;- 资源释放:循环结束后需调用
cap.release()释放摄像头,cv2.destroyAllWindows()关闭窗口,避免资源泄漏。
4.3.3 优化体验:文字位置调整
将文字绘制位置设为(x, y-30),使文字显示在识别框上方,避免文字与框重叠,提升视觉效果。
五、PaddleOCR 应用场景拓展
- 文档数字化:批量识别扫描件、PDF 中的文字,转换为可编辑的文本文件;
- 智能物流:识别快递面单上的收件人、地址、电话等信息,自动录入系统;
- 跨境电商:识别海外商品标签、说明书的多语言文字,实现自动翻译;
- 教育领域:识别试卷、作业中的文字,辅助自动批改;
- 车载场景:识别道路标识、车牌等信息,辅助自动驾驶。
六、总结与展望
PaddleOCR 作为一款高性能、易上手的 OCR 工具库,极大降低了文字识别技术的使用门槛。本文通过静态图片多语言识别、静态图片可视化标注、摄像头实时中文检测三个核心案例,详细讲解了 PaddleOCR 的基础用法、参数配置、OpenCV 可视化、中文显示等关键技术点,并分享了准确率优化、性能提升、异常处理等进阶技巧。
随着深度学习技术的发展,PaddleOCR 还在持续迭代,未来将支持更多语言、更高精度的模型,以及更轻量化的部署方案。开发者可结合自身业务场景,基于本文的案例进行拓展,例如集成到 Web 应用、移动端 APP、嵌入式设备中,实现更多实用的 OCR 功能。