引言:迷宫的魔力与算法的奥秘
迷宫,这个古老而迷人的智力游戏,从古希腊神话中的米诺陶洛斯迷宫到现代的电子游戏,一直吸引着人类的探索欲望。今天,我们将用Python的Pyglet框架打造一个可玩、可学、可AI化的迷宫游戏,并深入探索路径规划算法的奥秘。
但这不是一个普通的迷宫游戏------我们将实时可视化四种经典寻路算法,让您亲眼目睹AI是如何"思考"和"决策"的。从深度优先搜索的盲目探索,到A*算法的智能导航,您将看到算法思维在解决实际问题中的力量。
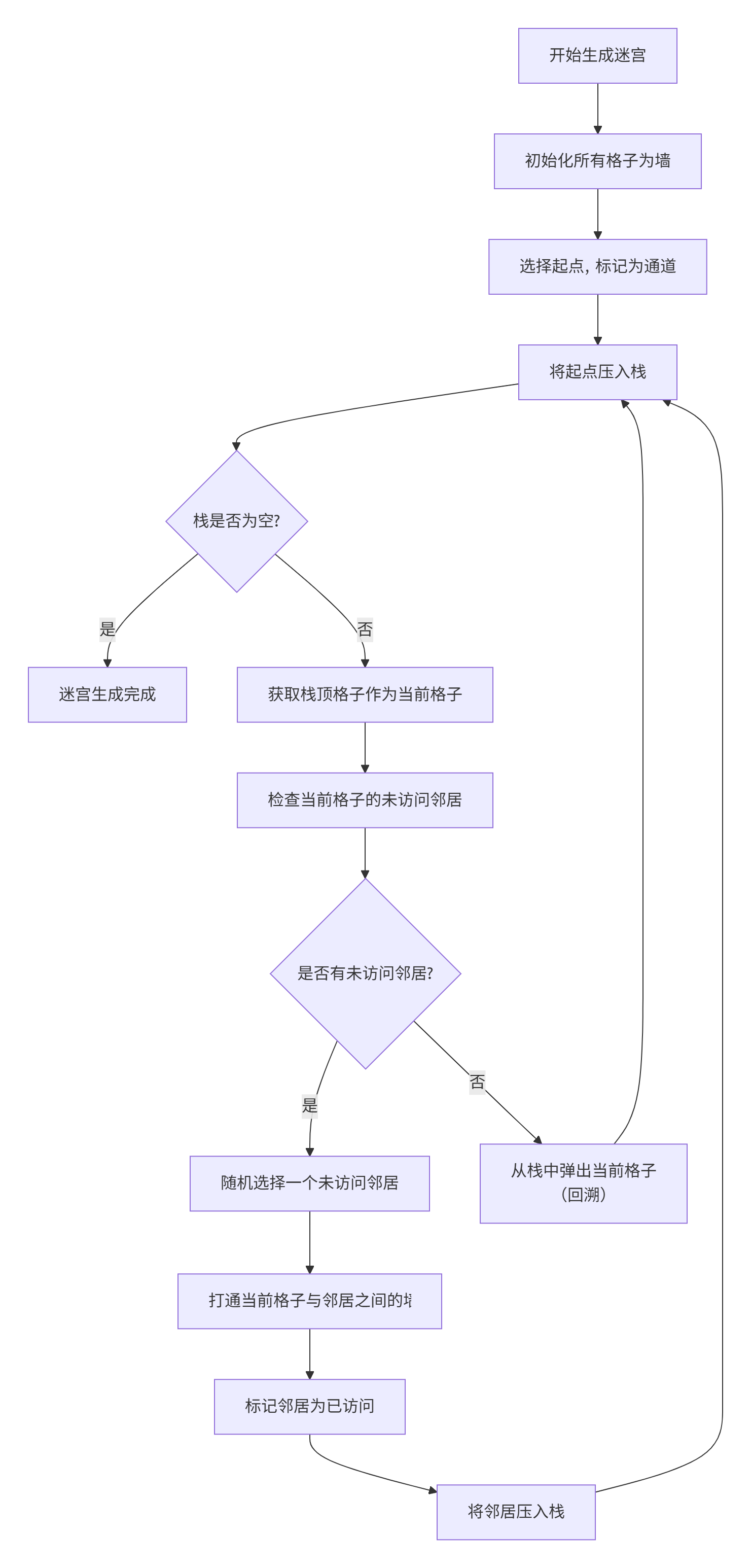
第一部分:迷宫生成的艺术
1.1 迷宫生成的两种哲学
迷宫的生成本身就是一种艺术。让我们先理解两种主流的迷宫生成算法:

1.2 递归回溯算法详解
让我们深入理解递归回溯算法的原理和实现:
1.3 代码实现:迷宫生成器
python
# maze_generator.py
import random
from typing import List, Tuple, Set
from enum import Enum
from dataclasses import dataclass
class Direction(Enum):
"""方向枚举,用于迷宫生成"""
UP = (0, 1)
DOWN = (0, -1)
LEFT = (-1, 0)
RIGHT = (1, 0)
@dataclass
class MazeCell:
"""迷宫格子数据类"""
x: int
y: int
is_wall: bool = True
visited: bool = False
is_start: bool = False
is_end: bool = False
in_path: bool = False
distance: float = float('inf') # 用于路径算法
def __str__(self):
return '#' if self.is_wall else ' '
def get_position(self) -> Tuple[int, int]:
return (self.x, self.y)
class MazeGenerator:
"""迷宫生成器类"""
def __init__(self, width: int = 15, height: int = 15):
"""
初始化迷宫生成器
Args:
width: 迷宫宽度(格子数)
height: 迷宫高度(格子数)
"""
self.width = width
self.height = height
# 确保迷宫尺寸为奇数,这样有明确的墙和通道
if self.width % 2 == 0:
self.width += 1
if self.height % 2 == 0:
self.height += 1
# 初始化迷宫网格
self.grid: List[List[MazeCell]] = []
self._initialize_grid()
# 起点和终点位置
self.start_pos = (1, 1) # 通常是左上角内部
self.end_pos = (self.width - 2, self.height - 2) # 右下角内部
def _initialize_grid(self):
"""初始化迷宫网格,所有格子都是墙"""
self.grid = []
for y in range(self.height):
row = []
for x in range(self.width):
cell = MazeCell(x=x, y=y, is_wall=True)
row.append(cell)
self.grid.append(row)
def generate_recursive_backtracking(self):
"""使用递归回溯算法生成迷宫"""
# 从起点开始
start_x, start_y = self.start_pos
self.grid[start_y][start_x].is_wall = False
self.grid[start_y][start_x].visited = True
self.grid[start_y][start_x].is_start = True
# 使用栈实现深度优先搜索
stack = [(start_x, start_y)]
while stack:
current_x, current_y = stack[-1]
# 获取未访问的邻居(距离为2的格子)
neighbors = self._get_unvisited_neighbors(current_x, current_y, distance=2)
if neighbors:
# 随机选择一个邻居
next_x, next_y, wall_x, wall_y = random.choice(neighbors)
# 打通当前格子和邻居之间的墙
self.grid[wall_y][wall_x].is_wall = False
self.grid[next_y][next_x].is_wall = False
self.grid[next_y][next_x].visited = True
# 将邻居加入栈
stack.append((next_x, next_y))
else:
# 回溯
stack.pop()
# 设置终点
end_x, end_y = self.end_pos
self.grid[end_y][end_x].is_wall = False
self.grid[end_y][end_x].is_end = True
# 重置访问标记
self._reset_visited()
def generate_randomized_prims(self):
"""使用随机Prim算法生成迷宫"""
# 从起点开始
start_x, start_y = self.start_pos
self.grid[start_y][start_x].is_wall = False
self.grid[start_y][start_x].is_start = True
# 维护墙的列表
walls = []
# 添加起点的所有墙邻居
for dx, dy in [(0, 2), (2, 0), (0, -2), (-2, 0)]:
nx, ny = start_x + dx, start_y + dy
if 0 <= nx < self.width and 0 <= ny < self.height:
walls.append((nx, ny, start_x + dx//2, start_y + dy//2))
while walls:
# 随机选择一堵墙
wall_x, wall_y, cell_x, cell_y = random.choice(walls)
walls.remove((wall_x, wall_y, cell_x, cell_y))
# 检查墙两边的格子
# 计算墙对面的格子
opposite_x = 2 * wall_x - cell_x
opposite_y = 2 * wall_y - cell_y
# 确保坐标在迷宫范围内
if 0 <= opposite_x < self.width and 0 <= opposite_y < self.height:
# 如果墙对面的格子是墙(未访问)
if self.grid[opposite_y][opposite_x].is_wall:
# 打通墙
self.grid[wall_y][wall_x].is_wall = False
self.grid[opposite_y][opposite_x].is_wall = False
# 添加新格子的墙邻居
for dx, dy in [(0, 2), (2, 0), (0, -2), (-2, 0)]:
nx, ny = opposite_x + dx, opposite_y + dy
if 0 <= nx < self.width and 0 <= ny < self.height and self.grid[ny][nx].is_wall:
walls.append((nx, ny, opposite_x + dx//2, opposite_y + dy//2))
# 设置终点
end_x, end_y = self.end_pos
self.grid[end_y][end_x].is_wall = False
self.grid[end_y][end_x].is_end = True
def _get_unvisited_neighbors(self, x: int, y: int, distance: int = 1) -> List[Tuple]:
"""
获取未访问的邻居格子
Args:
x: 当前格子的x坐标
y: 当前格子的y坐标
distance: 邻居距离(1为相邻,2为隔墙)
Returns:
邻居列表,每个元素为(邻居x, 邻居y, 墙x, 墙y)
"""
neighbors = []
directions = [(0, distance), (distance, 0), (0, -distance), (-distance, 0)]
for dx, dy in directions:
nx, ny = x + dx, y + dy
# 检查邻居是否在迷宫范围内且未被访问
if 0 <= nx < self.width and 0 <= ny < self.height:
if not self.grid[ny][nx].visited and self.grid[ny][nx].is_wall:
# 计算墙的位置
wall_x = x + dx//2
wall_y = y + dy//2
neighbors.append((nx, ny, wall_x, wall_y))
return neighbors
def _reset_visited(self):
"""重置所有格子的访问标记"""
for row in self.grid:
for cell in row:
cell.visited = False
def get_cell(self, x: int, y: int) -> MazeCell:
"""获取指定位置的格子"""
if 0 <= x < self.width and 0 <= y < self.height:
return self.grid[y][x]
return None
def is_walkable(self, x: int, y: int) -> bool:
"""检查指定位置是否可通行"""
if 0 <= x < self.width and 0 <= y < self.height:
return not self.grid[y][x].is_wall
return False
def get_walkable_neighbors(self, x: int, y: int) -> List[Tuple[int, int]]:
"""获取可通行的邻居格子"""
neighbors = []
directions = [(0, 1), (1, 0), (0, -1), (-1, 0)]
for dx, dy in directions:
nx, ny = x + dx, y + dy
if self.is_walkable(nx, ny):
neighbors.append((nx, ny))
return neighbors
def print_maze(self):
"""打印迷宫到控制台(用于调试)"""
for y in range(self.height):
row_str = ''
for x in range(self.width):
cell = self.grid[y][x]
if cell.is_start:
row_str += 'S'
elif cell.is_end:
row_str += 'E'
elif cell.is_wall:
row_str += '#'
else:
row_str += ' '
print(row_str)
def to_numpy_array(self):
"""将迷宫转换为numpy数组"""
import numpy as np
maze_array = np.zeros((self.height, self.width), dtype=int)
for y in range(self.height):
for x in range(self.width):
cell = self.grid[y][x]
if cell.is_wall:
maze_array[y, x] = 1
else:
maze_array[y, x] = 0
return maze_array
# 测试迷宫生成
if __name__ == "__main__":
print("测试递归回溯算法生成的迷宫:")
generator1 = MazeGenerator(15, 15)
generator1.generate_recursive_backtracking()
generator1.print_maze()
print("\n" + "="*30 + "\n")
print("测试随机Prim算法生成的迷宫:")
generator2 = MazeGenerator(15, 15)
generator2.generate_randomized_prims()
generator2.print_maze()第二部分:路径规划算法详解
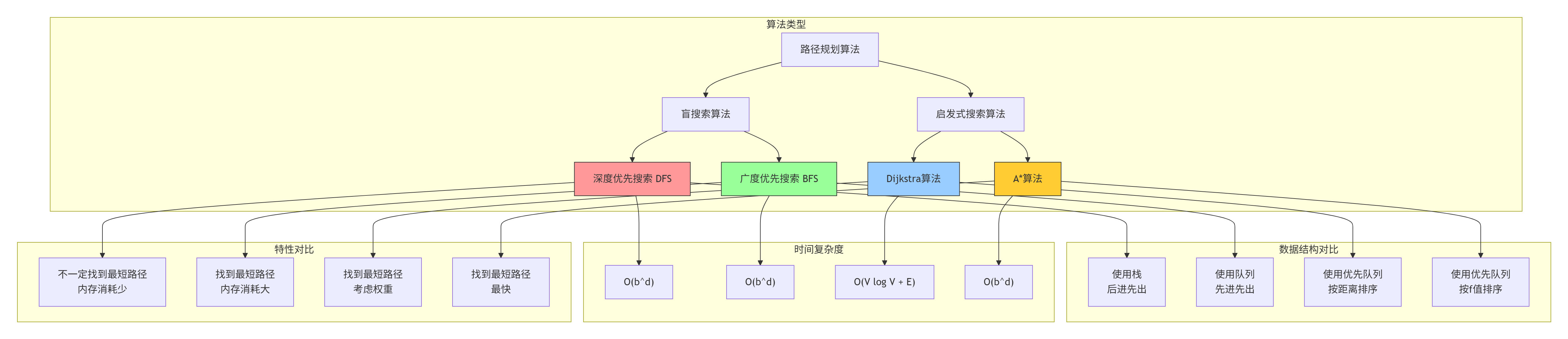
2.1 四大寻路算法对比
在迷宫寻路中,我们有四种经典的算法选择。让我们先理解它们的基本原理和差异:
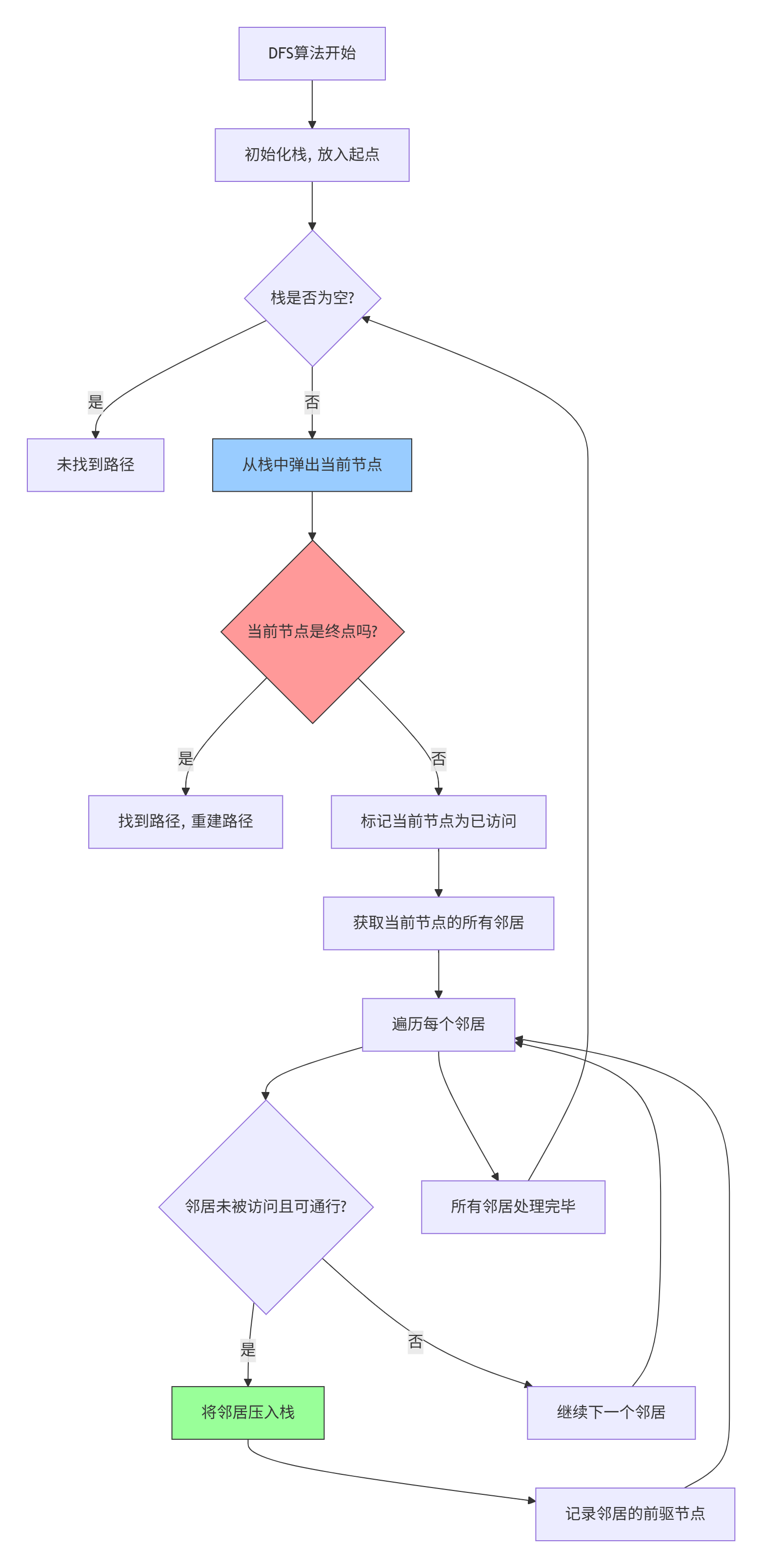
2.2 深度优先搜索(DFS)
深度优先搜索是最直观的搜索算法,它像一个人在迷宫中探索一样,一直向前走直到遇到死路,然后回溯:
2.3 广度优先搜索(BFS)
广度优先搜索像水波纹一样从起点向外扩散,确保找到最短路径:
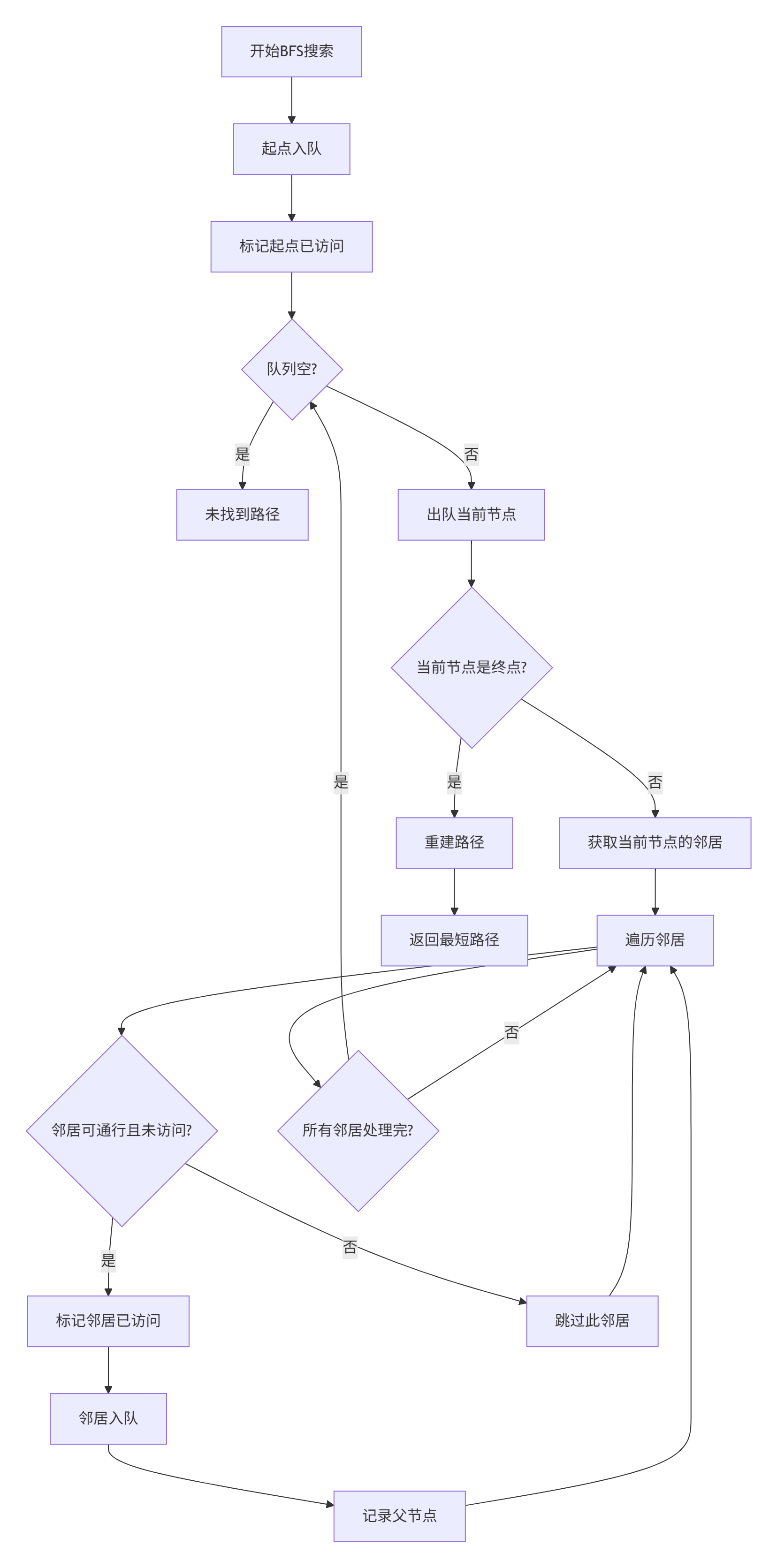
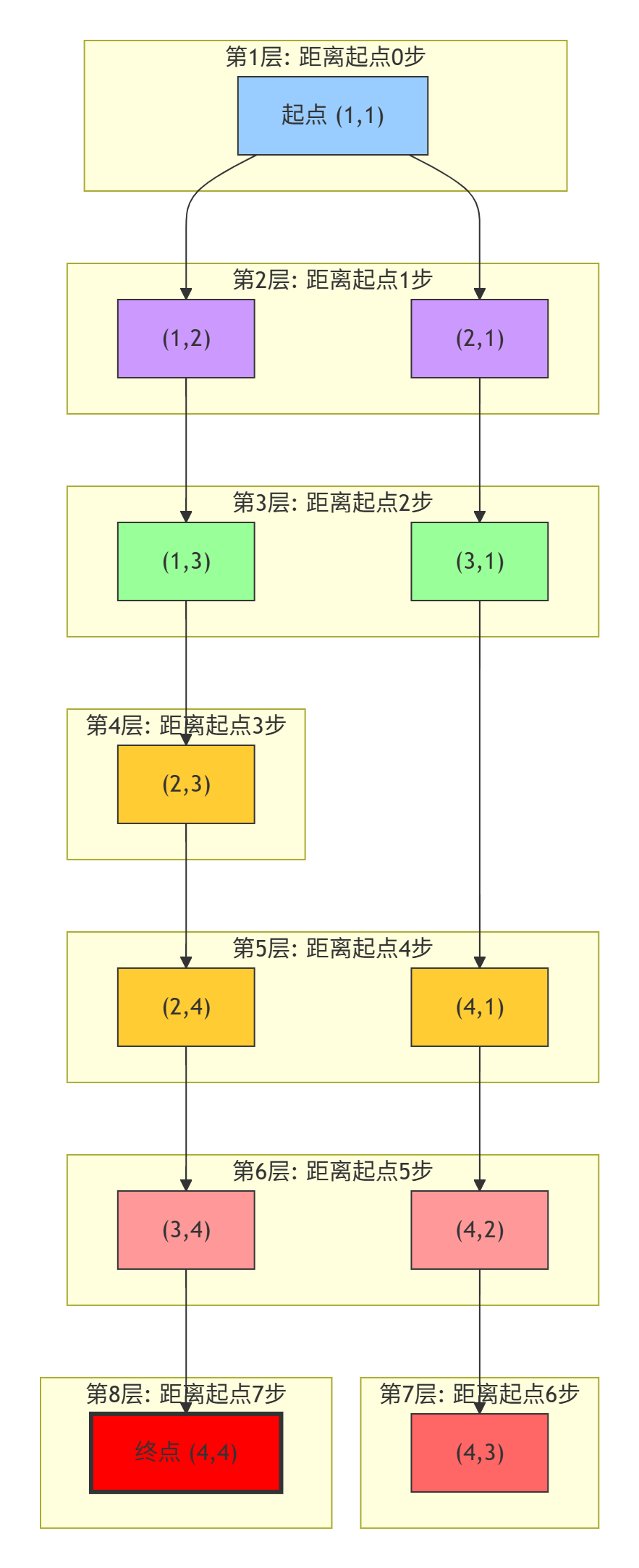
2.4 Dijkstra算法
Dijkstra算法考虑了移动成本,找到成本最低的路径:
python
# dijkstra_algorithm.py
import heapq
from typing import List, Tuple, Dict, Optional
from maze_generator import MazeGenerator, MazeCell
class DijkstraPathfinder:
"""Dijkstra路径规划算法"""
def __init__(self, maze: MazeGenerator):
self.maze = maze
self.width = maze.width
self.height = maze.height
def find_path(self, start: Tuple[int, int], end: Tuple[int, int]) -> List[Tuple[int, int]]:
"""
使用Dijkstra算法寻找最短路径
Args:
start: 起点坐标 (x, y)
end: 终点坐标 (x, y)
Returns:
路径坐标列表,从起点到终点
"""
# 验证起点和终点
if not self.maze.is_walkable(*start) or not self.maze.is_walkable(*end):
return []
# 初始化距离和前驱字典
distances = {}
predecessors = {}
for y in range(self.height):
for x in range(self.width):
if self.maze.is_walkable(x, y):
distances[(x, y)] = float('inf')
distances[start] = 0
predecessors[start] = None
# 使用优先队列(最小堆)
priority_queue = []
heapq.heappush(priority_queue, (0, start))
# 已访问集合
visited = set()
# 主循环
while priority_queue:
current_distance, current_node = heapq.heappop(priority_queue)
# 如果已经处理过这个节点,跳过
if current_node in visited:
continue
visited.add(current_node)
# 如果到达终点,提前结束
if current_node == end:
break
# 获取邻居节点
x, y = current_node
neighbors = self.maze.get_walkable_neighbors(x, y)
for neighbor in neighbors:
if neighbor in visited:
continue
# 计算新的距离(假设每个移动的成本为1)
new_distance = current_distance + 1
# 如果找到更短的路径,更新
if new_distance < distances[neighbor]:
distances[neighbor] = new_distance
predecessors[neighbor] = current_node
heapq.heappush(priority_queue, (new_distance, neighbor))
# 重建路径
return self._reconstruct_path(predecessors, start, end)
def _reconstruct_path(self, predecessors: Dict, start: Tuple, end: Tuple) -> List[Tuple]:
"""从前驱字典重建路径"""
if end not in predecessors:
return []
path = []
current = end
while current is not None:
path.append(current)
current = predecessors.get(current)
# 反转路径,使其从起点到终点
path.reverse()
# 确保路径从起点开始
if path and path[0] == start:
return path
else:
return []2.5 A*算法
A*算法是游戏AI中最常用的寻路算法,结合了BFS和启发式搜索的优点:
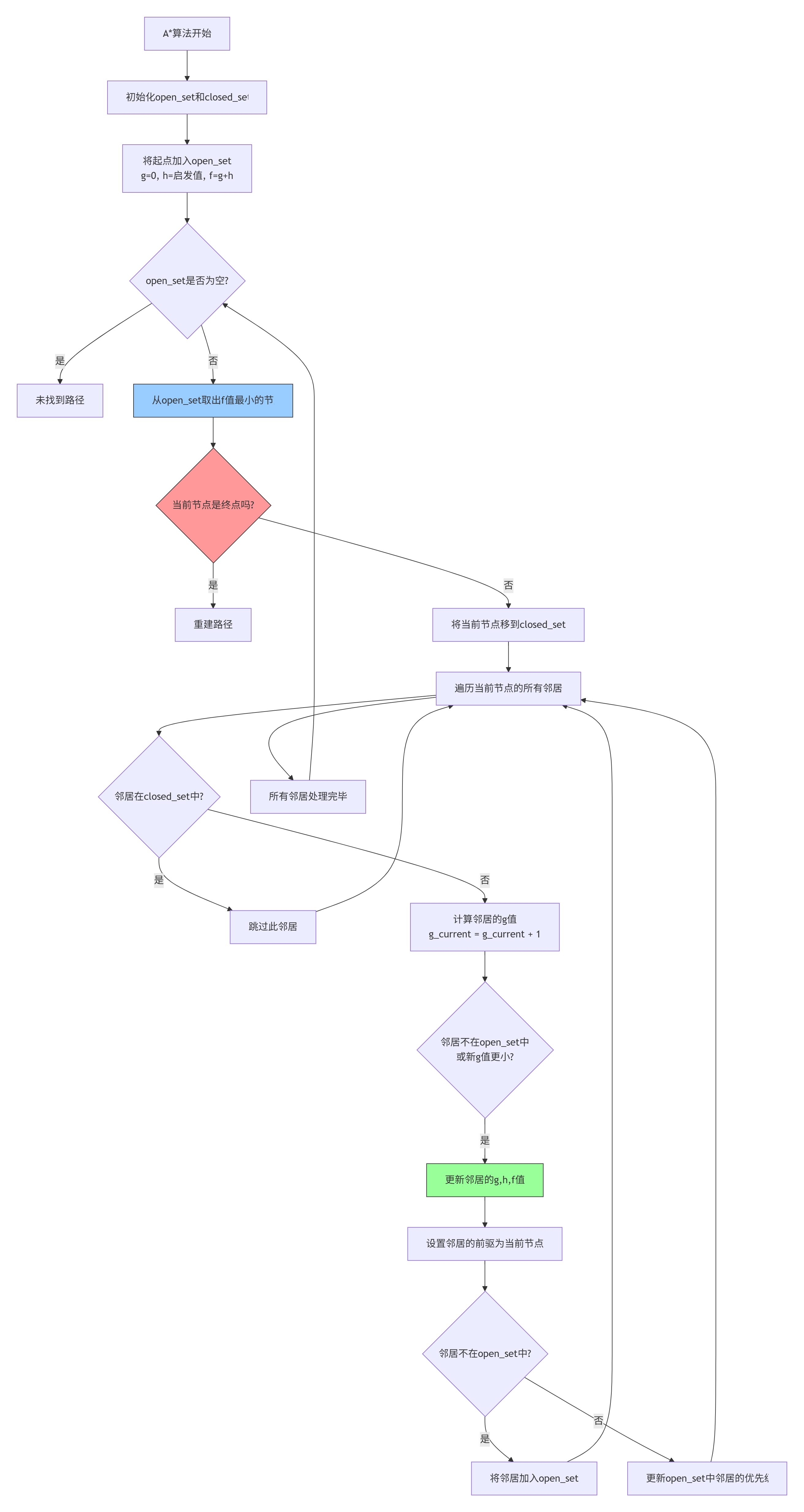
第三部分:Pyglet迷宫可视化实现
3.1 游戏架构设计
让我们设计一个完整的迷宫游戏,包含可视化寻路算法:
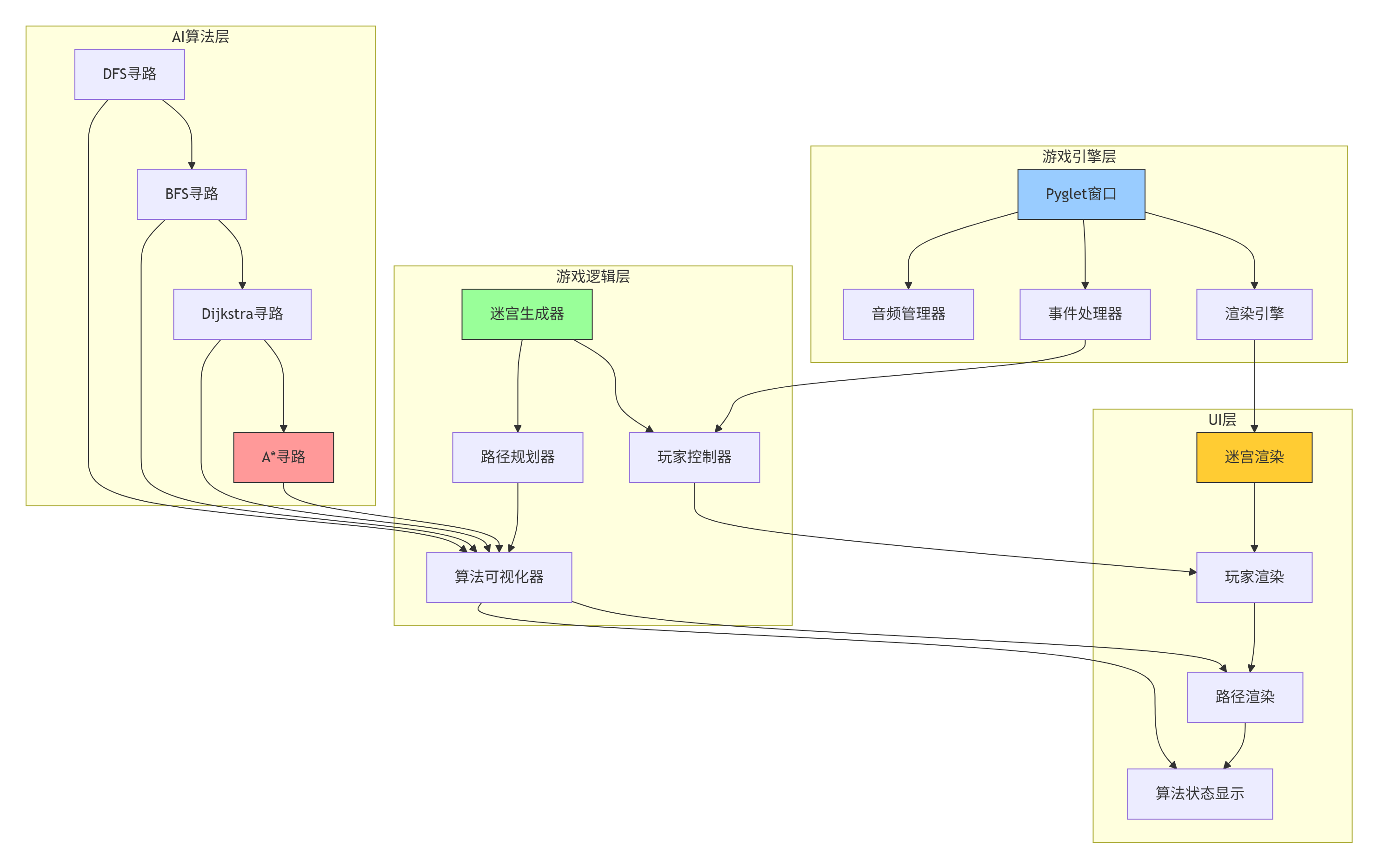
3.2 完整的迷宫游戏实现
python
# maze_game.py
import pyglet
import heapq
from typing import List, Tuple, Dict, Set, Optional
from enum import Enum
import random
import time
from dataclasses import dataclass
import math
class AlgorithmType(Enum):
"""算法类型枚举"""
DFS = "深度优先搜索"
BFS = "广度优先搜索"
DIJKSTRA = "Dijkstra算法"
ASTAR = "A*算法"
ALL = "全部算法对比"
@dataclass
class VisualStep:
"""算法可视化步骤"""
algorithm: AlgorithmType
current_cell: Tuple[int, int]
visited_cells: Set[Tuple[int, int]]
frontier_cells: List[Tuple[int, int]]
path_so_far: List[Tuple[int, int]]
class MazeGame:
"""迷宫游戏主类"""
def __init__(self, width: int = 800, height: int = 600, maze_size: int = 15):
# 初始化窗口
self.window = pyglet.window.Window(
width=width,
height=height,
caption="像素迷宫 - 路径规划算法可视化"
)
# 游戏参数
self.cell_size = 30
self.maze_size = maze_size
self.player_pos = (1, 1)
self.start_pos = (1, 1)
self.end_pos = (maze_size-2, maze_size-2)
# 游戏状态
self.maze = []
self.steps = 0
self.score = 0
self.time_limit = 60.0
self.time_remaining = self.time_limit
self.game_state = "WAITING" # WAITING, PLAYING, COMPLETE, FAILED
# 算法可视化
self.current_algorithm = AlgorithmType.ASTAR
self.showing_path = False
self.path = []
self.visualization_steps = []
self.current_step = 0
self.is_visualizing = False
self.visualization_speed = 0.1 # 秒
# 颜色配置
self.colors = {
'background': (25, 25, 35, 255),
'wall': (40, 40, 50, 255),
'path': (60, 60, 80, 255),
'start': (76, 175, 80, 255),
'end': (244, 67, 54, 255),
'player': (33, 150, 243, 255),
'visited': (255, 193, 7, 100),
'frontier': (255, 87, 34, 100),
'final_path': (0, 188, 212, 255),
'text': (240, 240, 240, 255),
'grid_line': (60, 60, 70, 255)
}
# 创建批处理渲染
self.batch = pyglet.graphics.Batch()
# 生成迷宫
self.generate_maze()
# 创建游戏元素
self.create_game_elements()
# 设置事件处理器
self.setup_event_handlers()
# 启动游戏循环
pyglet.clock.schedule_interval(self.update, 1/60.0)
def generate_maze(self):
"""生成迷宫"""
# 初始化所有格子为墙
self.maze = []
for y in range(self.maze_size):
row = []
for x in range(self.maze_size):
row.append({
'x': x,
'y': y,
'is_wall': True,
'visited': False,
'is_start': False,
'is_end': False,
'in_path': False,
'distance': float('inf')
})
self.maze.append(row)
# 递归回溯算法生成迷宫
stack = []
start_x, start_y = self.start_pos
self.maze[start_y][start_x]['is_wall'] = False
self.maze[start_y][start_x]['visited'] = True
self.maze[start_y][start_x]['is_start'] = True
stack.append((start_x, start_y))
while stack:
x, y = stack[-1]
# 获取未访问的邻居(距离为2)
neighbors = []
for dx, dy in [(0, 2), (2, 0), (0, -2), (-2, 0)]:
nx, ny = x + dx, y + dy
if (0 <= nx < self.maze_size and
0 <= ny < self.maze_size and
not self.maze[ny][nx]['visited']):
neighbors.append((nx, ny, x + dx//2, y + dy//2))
if neighbors:
# 随机选择一个邻居
nx, ny, wx, wy = random.choice(neighbors)
# 打通墙壁
self.maze[wy][wx]['is_wall'] = False
self.maze[ny][nx]['is_wall'] = False
self.maze[ny][nx]['visited'] = True
stack.append((nx, ny))
else:
# 回溯
stack.pop()
# 设置终点
end_x, end_y = self.end_pos
self.maze[end_y][end_x]['is_wall'] = False
self.maze[end_y][end_x]['is_end'] = True
# 重置访问状态
for y in range(self.maze_size):
for x in range(self.maze_size):
self.maze[y][x]['visited'] = False
def create_game_elements(self):
"""创建游戏图形元素"""
# 计算迷宫在屏幕上的位置
maze_width = self.maze_size * self.cell_size
self.maze_x = (self.window.width - maze_width) // 2
self.maze_y = (self.window.height - maze_width) // 2 + 50
# 创建迷宫格子
self.cell_shapes = []
for y in range(self.maze_size):
row_shapes = []
for x in range(self.maze_size):
cell = self.maze[y][x]
# 计算屏幕坐标
screen_x = self.maze_x + x * self.cell_size
screen_y = self.maze_y + y * self.cell_size
# 根据格子类型选择颜色
if cell['is_start']:
color = self.colors['start']
elif cell['is_end']:
color = self.colors['end']
elif cell['is_wall']:
color = self.colors['wall']
else:
color = self.colors['path']
# 创建矩形
rect = pyglet.shapes.Rectangle(
screen_x, screen_y,
self.cell_size, self.cell_size,
color=color,
batch=self.batch
)
row_shapes.append(rect)
self.cell_shapes.append(row_shapes)
# 创建玩家
px, py = self.player_pos
player_x = self.maze_x + px * self.cell_size + self.cell_size // 2
player_y = self.maze_y + py * self.cell_size + self.cell_size // 2
self.player = pyglet.shapes.Circle(
player_x, player_y,
self.cell_size // 3,
color=self.colors['player'],
batch=self.batch
)
# 创建信息标签
self.info_label = pyglet.text.Label(
"方向键移动 | 空格键: 显示路径 | R: 重新生成 | 1-4: 切换算法",
font_name="Arial",
font_size=12,
x=20, y=self.window.height - 30,
color=self.colors['text'],
batch=self.batch
)
self.stats_label = pyglet.text.Label(
f"步数: {self.steps} | 算法: {self.current_algorithm.value}",
font_name="Arial",
font_size=16,
x=self.window.width - 200, y=self.window.height - 30,
color=self.colors['text'],
batch=self.batch
)
self.algorithm_info = pyglet.text.Label(
"",
font_name="Arial",
font_size=14,
x=self.window.width // 2,
y=30,
anchor_x='center',
color=self.colors['text'],
batch=self.batch
)
# 创建算法可视化覆盖层
self.visited_overlays = []
self.frontier_overlays = []
self.path_overlays = []
def setup_event_handlers(self):
"""设置事件处理器"""
@self.window.event
def on_draw():
self.window.clear()
self.batch.draw()
@self.window.event
def on_key_press(symbol, modifiers):
if symbol == pyglet.window.key.UP:
self.move_player(0, 1)
elif symbol == pyglet.window.key.DOWN:
self.move_player(0, -1)
elif symbol == pyglet.window.key.LEFT:
self.move_player(-1, 0)
elif symbol == pyglet.window.key.RIGHT:
self.move_player(1, 0)
elif symbol == pyglet.window.key.SPACE:
self.toggle_path_display()
elif symbol == pyglet.window.key.R:
self.reset_game()
elif symbol == pyglet.window.key._1:
self.set_algorithm(AlgorithmType.DFS)
elif symbol == pyglet.window.key._2:
self.set_algorithm(AlgorithmType.BFS)
elif symbol == pyglet.window.key._3:
self.set_algorithm(AlgorithmType.DIJKSTRA)
elif symbol == pyglet.window.key._4:
self.set_algorithm(AlgorithmType.ASTAR)
elif symbol == pyglet.window.key.V:
self.start_visualization()
def move_player(self, dx: int, dy: int):
"""移动玩家"""
if self.game_state != "PLAYING":
return
px, py = self.player_pos
new_x, new_y = px + dx, py + dy
# 检查是否在迷宫范围内且不是墙
if (0 <= new_x < self.maze_size and
0 <= new_y < self.maze_size and
not self.maze[new_y][new_x]['is_wall']):
self.player_pos = (new_x, new_y)
self.steps += 1
# 更新玩家位置
player_x = self.maze_x + new_x * self.cell_size + self.cell_size // 2
player_y = self.maze_y + new_y * self.cell_size + self.cell_size // 2
self.player.x = player_x
self.player.y = player_y
# 检查是否到达终点
if (new_x, new_y) == self.end_pos:
self.game_state = "COMPLETE"
self.score = max(1000 - self.steps * 10, 100)
self.info_label.text = f"到达终点!得分: {self.score}"
def set_algorithm(self, algorithm: AlgorithmType):
"""设置当前算法"""
self.current_algorithm = algorithm
self.stats_label.text = f"步数: {self.steps} | 算法: {self.current_algorithm.value}"
if self.showing_path:
self.calculate_path()
def toggle_path_display(self):
"""切换路径显示"""
self.showing_path = not self.showing_path
if self.showing_path:
self.calculate_path()
else:
self.clear_path()
def calculate_path(self):
"""计算路径"""
# 清除之前的路径
self.clear_path()
# 根据当前算法计算路径
if self.current_algorithm == AlgorithmType.DFS:
self.path = self.depth_first_search()
elif self.current_algorithm == AlgorithmType.BFS:
self.path = self.breadth_first_search()
elif self.current_algorithm == AlgorithmType.DIJKSTRA:
self.path = self.dijkstra_search()
elif self.current_algorithm == AlgorithmType.ASTAR:
self.path = self.a_star_search()
# 显示路径
for x, y in self.path:
if not ((x, y) == self.start_pos or (x, y) == self.end_pos):
self.maze[y][x]['in_path'] = True
# 更新显示
self.update_graphics()
def clear_path(self):
"""清除路径显示"""
for y in range(self.maze_size):
for x in range(self.maze_size):
self.maze[y][x]['in_path'] = False
self.path = []
self.update_graphics()
def depth_first_search(self) -> List[Tuple[int, int]]:
"""深度优先搜索"""
start = self.start_pos
end = self.end_pos
stack = [(start, [start])]
visited = set()
while stack:
(x, y), path = stack.pop()
if (x, y) in visited:
continue
visited.add((x, y))
if (x, y) == end:
return path[1:] # 排除起点
# 探索邻居
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if (0 <= nx < self.maze_size and
0 <= ny < self.maze_size and
not self.maze[ny][nx]['is_wall'] and
(nx, ny) not in visited):
stack.append(((nx, ny), path + [(nx, ny)]))
return []
def breadth_first_search(self) -> List[Tuple[int, int]]:
"""广度优先搜索"""
from collections import deque
start = self.start_pos
end = self.end_pos
queue = deque([(start, [start])])
visited = set([start])
while queue:
(x, y), path = queue.popleft()
if (x, y) == end:
return path[1:] # 排除起点
# 探索邻居
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if (0 <= nx < self.maze_size and
0 <= ny < self.maze_size and
not self.maze[ny][nx]['is_wall'] and
(nx, ny) not in visited):
visited.add((nx, ny))
queue.append(((nx, ny), path + [(nx, ny)]))
return []
def dijkstra_search(self) -> List[Tuple[int, int]]:
"""Dijkstra算法"""
start = self.start_pos
end = self.end_pos
# 距离字典
distances = {start: 0}
# 前驱节点
previous = {}
# 未访问节点
unvisited = set()
# 初始化
for y in range(self.maze_size):
for x in range(self.maze_size):
if not self.maze[y][x]['is_wall']:
unvisited.add((x, y))
if (x, y) not in distances:
distances[(x, y)] = float('inf')
while unvisited:
# 找到距离最小的未访问节点
current = min(unvisited, key=lambda node: distances[node])
if current == end or distances[current] == float('inf'):
break
unvisited.remove(current)
x, y = current
# 更新邻居距离
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
neighbor = (nx, ny)
if (0 <= nx < self.maze_size and
0 <= ny < self.maze_size and
not self.maze[ny][nx]['is_wall'] and
neighbor in unvisited):
new_dist = distances[current] + 1
if new_dist < distances[neighbor]:
distances[neighbor] = new_dist
previous[neighbor] = current
# 重建路径
path = []
current = end
while current in previous:
path.append(current)
current = previous[current]
path.reverse()
return path if path and path[0] == start else []
def a_star_search(self) -> List[Tuple[int, int]]:
"""A*寻路算法"""
start = self.start_pos
end = self.end_pos
# 启发式函数(曼哈顿距离)
def heuristic(a, b):
return abs(a[0] - b[0]) + abs(a[1] - b[1])
# 优先队列
open_set = []
heapq.heappush(open_set, (0, start))
# 记录路径
came_from = {}
# 实际代价
g_score = {start: 0}
# 预估总代价
f_score = {start: heuristic(start, end)}
while open_set:
_, current = heapq.heappop(open_set)
if current == end:
# 重建路径
path = []
while current in came_from:
path.append(current)
current = came_from[current]
path.reverse()
return path
# 探索邻居
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
neighbor = (current[0] + dx, current[1] + dy)
# 检查是否是有效格子
if (0 <= neighbor[0] < self.maze_size and
0 <= neighbor[1] < self.maze_size and
not self.maze[neighbor[1]][neighbor[0]]['is_wall']):
# 计算新的g值
tentative_g_score = g_score[current] + 1
if neighbor not in g_score or tentative_g_score < g_score[neighbor]:
came_from[neighbor] = current
g_score[neighbor] = tentative_g_score
f_score[neighbor] = tentative_g_score + heuristic(neighbor, end)
if neighbor not in [i[1] for i in open_set]:
heapq.heappush(open_set, (f_score[neighbor], neighbor))
return [] # 无路径
def start_visualization(self):
"""开始算法可视化"""
self.is_visualizing = True
self.current_step = 0
self.visualization_steps = self.generate_visualization_steps()
self.info_label.text = "可视化进行中... 按ESC停止"
def generate_visualization_steps(self) -> List[VisualStep]:
"""生成算法可视化步骤"""
steps = []
# 这里实现算法执行过程的逐步记录
# 由于篇幅限制,这里简化实现
# 实际实现会记录算法每一步的状态
return steps
def update_graphics(self):
"""更新图形显示"""
for y in range(self.maze_size):
for x in range(self.maze_size):
cell = self.maze[y][x]
shape = self.cell_shapes[y][x]
# 更新颜色
if cell['is_start']:
shape.color = self.colors['start']
elif cell['is_end']:
shape.color = self.colors['end']
elif cell['is_wall']:
shape.color = self.colors['wall']
elif cell['in_path']:
shape.color = self.colors['final_path']
else:
shape.color = self.colors['path']
def reset_game(self):
"""重置游戏"""
self.player_pos = self.start_pos
self.steps = 0
self.score = 0
self.time_remaining = self.time_limit
self.game_state = "WAITING"
# 重新生成迷宫
self.generate_maze()
self.clear_path()
# 更新玩家位置
px, py = self.player_pos
player_x = self.maze_x + px * self.cell_size + self.cell_size // 2
player_y = self.maze_y + py * self.cell_size + self.cell_size // 2
self.player.x = player_x
self.player.y = player_y
# 更新图形
self.update_graphics()
# 更新标签
self.info_label.text = "方向键移动 | 空格键: 显示路径 | R: 重新生成 | 1-4: 切换算法"
self.stats_label.text = f"步数: {self.steps} | 算法: {self.current_algorithm.value}"
def update(self, dt):
"""游戏更新循环"""
if self.game_state == "PLAYING":
# 更新时间
self.time_remaining = max(0, self.time_remaining - dt)
if self.time_remaining <= 0:
self.game_state = "FAILED"
self.info_label.text = f"时间到!分数: {self.score}"
# 更新算法信息
if self.showing_path:
path_length = len(self.path)
self.algorithm_info.text = f"路径长度: {path_length} 步"
else:
self.algorithm_info.text = ""
def run(self):
"""运行游戏"""
pyglet.app.run()
if __name__ == "__main__":
game = MazeGame()
game.run()第四部分:算法性能对比与分析
4.1 算法效率可视化
让我们通过实验对比四种算法的性能:
python
# algorithm_benchmark.py
import time
import random
import matplotlib.pyplot as plt
import numpy as np
from typing import List, Tuple, Dict
from maze_game import MazeGame, AlgorithmType
class AlgorithmBenchmark:
"""算法性能基准测试"""
def __init__(self, maze_sizes: List[int] = [10, 20, 30, 40], num_trials: int = 10):
self.maze_sizes = maze_sizes
self.num_trials = num_trials
self.results = {
'DFS': {'time': [], 'path_length': [], 'nodes_explored': []},
'BFS': {'time': [], 'path_length': [], 'nodes_explored': []},
'Dijkstra': {'time': [], 'path_length': [], 'nodes_explored': []},
'A*': {'time': [], 'path_length': [], 'nodes_explored': []}
}
def run_benchmark(self):
"""运行基准测试"""
print("开始算法性能基准测试...")
print("=" * 60)
for maze_size in self.maze_sizes:
print(f"\n测试迷宫尺寸: {maze_size}x{maze_size}")
print("-" * 40)
for _ in range(self.num_trials):
# 创建迷宫游戏实例
game = MazeGame(maze_size=maze_size)
# 测试每种算法
algorithms = [
('DFS', AlgorithmType.DFS),
('BFS', AlgorithmType.BFS),
('Dijkstra', AlgorithmType.DIJKSTRA),
('A*', AlgorithmType.ASTAR)
]
for algo_name, algo_type in algorithms:
# 设置算法
game.current_algorithm = algo_type
# 计时
start_time = time.time()
# 计算路径
if algo_name == 'DFS':
path = game.depth_first_search()
elif algo_name == 'BFS':
path = game.breadth_first_search()
elif algo_name == 'Dijkstra':
path = game.dijkstra_search()
elif algo_name == 'A*':
path = game.a_star_search()
end_time = time.time()
# 记录结果
execution_time = end_time - start_time
path_length = len(path) if path else 0
# 估算探索的节点数(简化)
nodes_explored = self._estimate_nodes_explored(game, algo_name)
self.results[algo_name]['time'].append(execution_time)
self.results[algo_name]['path_length'].append(path_length)
self.results[algo_name]['nodes_explored'].append(nodes_explored)
# 打印当前尺寸的结果
self._print_results_for_size(maze_size)
def _estimate_nodes_explored(self, game, algorithm_name: str) -> int:
"""估算探索的节点数(简化实现)"""
maze_area = game.maze_size * game.maze_size
wall_count = sum(1 for row in game.maze for cell in row if cell['is_wall'])
walkable_cells = maze_area - wall_count
# 不同算法的探索模式不同
if algorithm_name == 'DFS':
# DFS可能探索所有可达节点
return int(walkable_cells * 0.8)
elif algorithm_name == 'BFS':
# BFS会探索起点周围的所有节点
return int(walkable_cells * 0.6)
elif algorithm_name == 'Dijkstra':
# Dijkstra类似BFS
return int(walkable_cells * 0.6)
elif algorithm_name == 'A*':
# A*通常探索最少的节点
return int(walkable_cells * 0.3)
return walkable_cells
def _print_results_for_size(self, maze_size: int):
"""打印特定迷宫尺寸的结果"""
print(f"\n迷宫尺寸 {maze_size}x{maze_size} 的平均结果:")
print("算法 时间(ms) 路径长度 探索节点")
print("-" * 40)
for algo_name in ['DFS', 'BFS', 'Dijkstra', 'A*']:
avg_time = np.mean(self.results[algo_name]['time'][-self.num_trials:]) * 1000
avg_path = np.mean(self.results[algo_name]['path_length'][-self.num_trials:])
avg_nodes = np.mean(self.results[algo_name]['nodes_explored'][-self.num_trials:])
print(f"{algo_name:8s} {avg_time:8.2f} {avg_path:8.1f} {avg_nodes:8.1f}")
def visualize_results(self):
"""可视化基准测试结果"""
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
# 准备数据
algorithms = ['DFS', 'BFS', 'Dijkstra', 'A*']
colors = ['#FF6B6B', '#4ECDC4', '#45B7D1', '#96CEB4']
# 1. 执行时间对比
ax1 = axes[0, 0]
time_data = []
for algo in algorithms:
# 获取该算法在所有迷宫尺寸上的平均时间
algo_times = self.results[algo]['time']
# 按迷宫尺寸分组
grouped_times = []
for i, size in enumerate(self.maze_sizes):
start_idx = i * self.num_trials
end_idx = start_idx + self.num_trials
group_avg = np.mean(algo_times[start_idx:end_idx]) * 1000
grouped_times.append(group_avg)
time_data.append(grouped_times)
# 绘制折线图
for i, (algo, times, color) in enumerate(zip(algorithms, time_data, colors)):
ax1.plot(self.maze_sizes, times, marker='o', color=color, label=algo, linewidth=2)
ax1.set_xlabel('迷宫尺寸')
ax1.set_ylabel('执行时间 (ms)')
ax1.set_title('算法执行时间对比')
ax1.grid(True, alpha=0.3)
ax1.legend()
# 2. 路径长度对比
ax2 = axes[0, 1]
path_data = []
for algo in algorithms:
algo_paths = self.results[algo]['path_length']
grouped_paths = []
for i, size in enumerate(self.maze_sizes):
start_idx = i * self.num_trials
end_idx = start_idx + self.num_trials
group_avg = np.mean(algo_paths[start_idx:end_idx])
grouped_paths.append(group_avg)
path_data.append(grouped_paths)
# 绘制柱状图
x = np.arange(len(self.maze_sizes))
width = 0.2
for i, (algo, paths, color) in enumerate(zip(algorithms, path_data, colors)):
offset = (i - 1.5) * width
ax2.bar(x + offset, paths, width, label=algo, color=color, alpha=0.8)
ax2.set_xlabel('迷宫尺寸')
ax2.set_ylabel('路径长度')
ax2.set_title('找到的路径长度对比')
ax2.set_xticks(x)
ax2.set_xticklabels(self.maze_sizes)
ax2.legend()
# 3. 探索节点数对比
ax3 = axes[1, 0]
nodes_data = []
for algo in algorithms:
algo_nodes = self.results[algo]['nodes_explored']
grouped_nodes = []
for i, size in enumerate(self.maze_sizes):
start_idx = i * self.num_trials
end_idx = start_idx + self.num_trials
group_avg = np.mean(algo_nodes[start_idx:end_idx])
grouped_nodes.append(group_avg)
nodes_data.append(grouped_nodes)
# 绘制堆叠面积图
x = self.maze_sizes
bottom = np.zeros(len(x))
for i, (algo, nodes, color) in enumerate(zip(algorithms, nodes_data, colors)):
ax3.fill_between(x, bottom, bottom + nodes, color=color, alpha=0.7, label=algo)
bottom += nodes
ax3.set_xlabel('迷宫尺寸')
ax3.set_ylabel('探索节点数')
ax3.set_title('探索节点数对比')
ax3.legend()
# 4. 效率雷达图
ax4 = axes[1, 1]
# 计算各算法的综合评分
categories = ['速度', '路径质量', '内存效率', '可靠性']
algorithm_scores = {}
for algo in algorithms:
# 速度评分(执行时间越短越好)
speed_scores = self.results[algo]['time']
speed_score = 1 / (np.mean(speed_scores) + 0.001) # 避免除零
# 路径质量评分(路径越短越好)
path_scores = self.results[algo]['path_length']
path_score = 1 / (np.mean(path_scores) + 0.001) # 避免除零
# 内存效率评分(探索节点越少越好)
node_scores = self.results[algo]['nodes_explored']
memory_score = 1 / (np.mean(node_scores) + 0.001) # 避免除零
# 可靠性评分(找到路径的比例)
reliability = sum(1 for p in path_scores if p > 0) / len(path_scores)
algorithm_scores[algo] = [speed_score, path_score, memory_score, reliability]
# 归一化分数
max_scores = np.max(list(algorithm_scores.values()), axis=0)
normalized_scores = {}
for algo, scores in algorithm_scores.items():
normalized = [scores[i] / max_scores[i] for i in range(len(scores))]
normalized_scores[algo] = normalized
# 绘制雷达图
angles = np.linspace(0, 2 * np.pi, len(categories), endpoint=False).tolist()
angles += angles[:1] # 闭合多边形
for algo, scores, color in zip(algorithms, normalized_scores.values(), colors):
scores += scores[:1] # 闭合多边形
ax4.plot(angles, scores, 'o-', color=color, linewidth=2, label=algo)
ax4.fill(angles, scores, color=color, alpha=0.25)
ax4.set_xticks(angles[:-1])
ax4.set_xticklabels(categories)
ax4.set_ylim(0, 1.2)
ax4.set_title('算法综合性能雷达图')
ax4.legend(loc='upper right')
plt.suptitle('迷宫寻路算法性能对比分析', fontsize=16, fontweight='bold')
plt.tight_layout()
plt.show()
# 运行基准测试
if __name__ == "__main__":
benchmark = AlgorithmBenchmark(maze_sizes=[10, 15, 20, 25], num_trials=5)
benchmark.run_benchmark()
benchmark.visualize_results()4.2 算法选择决策树
在实际应用中,如何选择合适的算法?这个决策树可以提供帮助:
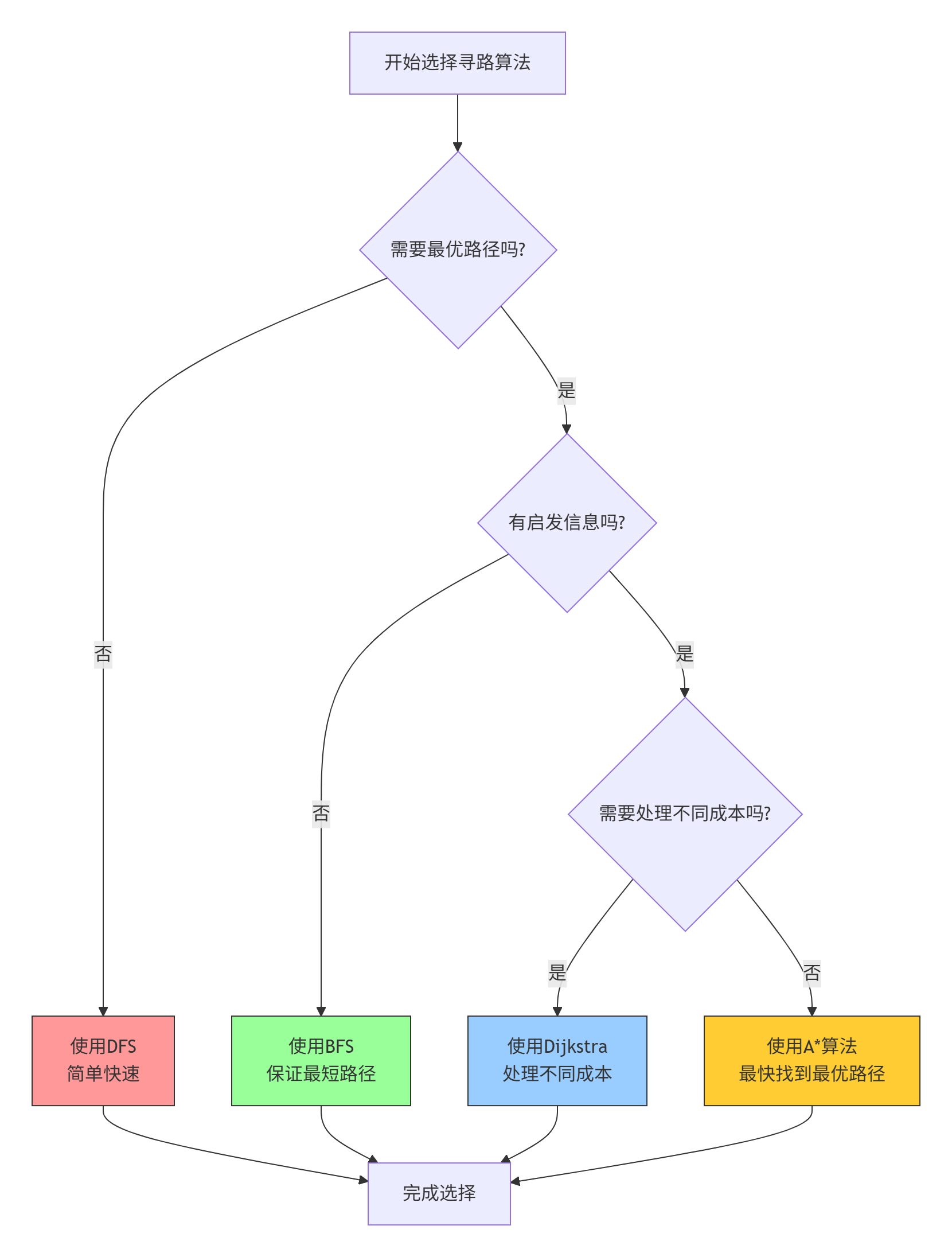
第五部分:AI强化学习扩展
5.1 迷宫中的强化学习
除了传统的搜索算法,我们还可以用强化学习训练AI解决迷宫问题:
python
# maze_rl_agent.py
import numpy as np
import random
from collections import deque
import torch
import torch.nn as nn
import torch.optim as optim
from typing import List, Tuple, Dict
class MazeEnvironment:
"""迷宫强化学习环境"""
def __init__(self, maze_size: int = 10):
self.maze_size = maze_size
self.state_size = maze_size * maze_size
self.action_size = 4 # 上下左右
# 动作映射
self.action_map = {
0: (0, 1), # 上
1: (0, -1), # 下
2: (1, 0), # 右
3: (-1, 0) # 左
}
# 生成迷宫
self.reset()
def reset(self) -> np.ndarray:
"""重置环境"""
# 生成随机迷宫
self._generate_maze()
# 随机起点和终点
self.start_pos = (1, 1)
self.end_pos = (self.maze_size-2, self.maze_size-2)
self.current_pos = self.start_pos
# 返回初始状态
return self._get_state()
def _generate_maze(self):
"""生成随机迷宫"""
# 初始化所有格子为墙
self.maze = np.ones((self.maze_size, self.maze_size), dtype=int)
# 使用递归回溯算法生成迷宫
stack = []
start_x, start_y = 1, 1
self.maze[start_y, start_x] = 0
stack.append((start_x, start_y))
while stack:
x, y = stack[-1]
# 获取未访问的邻居
neighbors = []
for dx, dy in [(0, 2), (2, 0), (0, -2), (-2, 0)]:
nx, ny = x + dx, y + dy
if 0 <= nx < self.maze_size and 0 <= ny < self.maze_size and self.maze[ny, nx] == 1:
neighbors.append((nx, ny, x + dx//2, y + dy//2))
if neighbors:
# 随机选择一个邻居
nx, ny, wx, wy = random.choice(neighbors)
# 打通墙壁
self.maze[wy, wx] = 0
self.maze[ny, nx] = 0
stack.append((nx, ny))
else:
stack.pop()
def _get_state(self) -> np.ndarray:
"""获取当前状态表示"""
# 创建状态向量:迷宫 + 当前位置
state = self.maze.flatten().copy()
# 将当前位置编码为独热向量
pos_idx = self.current_pos[1] * self.maze_size + self.current_pos[0]
pos_vector = np.zeros(self.state_size)
pos_vector[pos_idx] = 1
# 合并迷宫和位置信息
full_state = np.concatenate([state, pos_vector])
return full_state
def step(self, action: int) -> Tuple[np.ndarray, float, bool, Dict]:
"""执行一个动作"""
dx, dy = self.action_map[action]
x, y = self.current_pos
new_x, new_y = x + dx, y + dy
# 检查新位置是否有效
if 0 <= new_x < self.maze_size and 0 <= new_y < self.maze_size:
if self.maze[new_y, new_x] == 0: # 可通行
self.current_pos = (new_x, new_y)
moved = True
else:
moved = False
else:
moved = False
# 计算奖励
if moved:
# 计算到终点的曼哈顿距离
old_distance = abs(x - self.end_pos[0]) + abs(y - self.end_pos[1])
new_distance = abs(new_x - self.end_pos[0]) + abs(new_y - self.end_pos[1])
if new_distance < old_distance:
reward = 1.0
else:
reward = -0.1
else:
reward = -0.5 # 撞墙惩罚
# 检查是否到达终点
done = (self.current_pos == self.end_pos)
if done:
reward = 10.0
# 获取新状态
next_state = self._get_state()
return next_state, reward, done, {}
class DQNAgent:
"""深度Q学习智能体"""
def __init__(self, state_size: int, action_size: int):
self.state_size = state_size
self.action_size = action_size
# 超参数
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.learning_rate = 0.001
self.batch_size = 32
self.memory_size = 2000
# 经验回放内存
self.memory = deque(maxlen=self.memory_size)
# 神经网络
self.model = self._build_model()
self.target_model = self._build_model()
self.update_target_model()
# 优化器
self.optimizer = optim.Adam(self.model.parameters(), lr=self.learning_rate)
self.criterion = nn.MSELoss()
def _build_model(self) -> nn.Module:
"""构建神经网络"""
return nn.Sequential(
nn.Linear(self.state_size * 2, 128), # 迷宫状态 + 位置状态
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, self.action_size)
)
def update_target_model(self):
"""更新目标网络"""
self.target_model.load_state_dict(self.model.state_dict())
def remember(self, state, action, reward, next_state, done):
"""存储经验到记忆"""
self.memory.append((state, action, reward, next_state, done))
def act(self, state: np.ndarray) -> int:
"""选择动作(ε-greedy策略)"""
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
state_tensor = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
q_values = self.model(state_tensor)
return torch.argmax(q_values).item()
def replay(self):
"""经验回放训练"""
if len(self.memory) < self.batch_size:
return
# 随机采样批量
batch = random.sample(self.memory, self.batch_size)
states, actions, rewards, next_states, dones = zip(*batch)
# 转换为张量
states = torch.FloatTensor(states)
actions = torch.LongTensor(actions).unsqueeze(1)
rewards = torch.FloatTensor(rewards)
next_states = torch.FloatTensor(next_states)
dones = torch.FloatTensor(dones)
# 计算当前Q值
current_q = self.model(states).gather(1, actions)
# 计算目标Q值
with torch.no_grad():
next_q_values = self.target_model(next_states)
max_next_q = torch.max(next_q_values, dim=1)[0]
target_q = rewards + (1 - dones) * self.gamma * max_next_q
# 计算损失
loss = self.criterion(current_q.squeeze(), target_q)
# 反向传播
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# 衰减探索率
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
def train(self, env: MazeEnvironment, episodes: int = 1000):
"""训练智能体"""
rewards_history = []
for episode in range(episodes):
state = env.reset()
total_reward = 0
done = False
steps = 0
while not done and steps < 200: # 最大步数限制
# 选择动作
action = self.act(state)
# 执行动作
next_state, reward, done, _ = env.step(action)
# 存储经验
self.remember(state, action, reward, next_state, done)
# 更新状态
state = next_state
total_reward += reward
steps += 1
# 经验回放
self.replay()
# 定期更新目标网络
if episode % 10 == 0:
self.update_target_model()
rewards_history.append(total_reward)
# 打印进度
if episode % 100 == 0:
avg_reward = np.mean(rewards_history[-100:]) if len(rewards_history) >= 100 else total_reward
print(f"Episode: {episode}/{episodes}, "
f"Reward: {total_reward:.2f}, "
f"Avg Reward: {avg_reward:.2f}, "
f"Epsilon: {self.epsilon:.3f}")
return rewards_history
# 训练强化学习智能体
if __name__ == "__main__":
# 创建环境和智能体
env = MazeEnvironment(maze_size=10)
state_size = env.state_size * 2 # 迷宫状态 + 位置状态
agent = DQNAgent(state_size, env.action_size)
# 训练
print("开始训练强化学习智能体...")
rewards = agent.train(env, episodes=1000)
# 测试训练好的智能体
print("\n测试训练好的智能体...")
state = env.reset()
done = False
steps = 0
while not done and steps < 50:
action = agent.act(state)
state, reward, done, _ = env.step(action)
steps += 1
print(f"Step {steps}: Position {env.current_pos}, Reward: {reward:.2f}")
if done:
print(f"成功到达终点!步数: {steps}")
else:
print(f"未能到达终点。步数: {steps}")第六部分:总结与展望
6.1 学习成果总结
通过这个完整的迷宫项目,您已经掌握了:
-
迷宫生成算法:递归回溯和随机Prim算法
-
路径规划算法:DFS、BFS、Dijkstra、A*的实现与对比
-
Pyglet可视化:实时算法可视化与交互
-
性能分析:算法效率评估与优化
-
强化学习:用DQN训练AI解决迷宫问题
6.2 知识结构全景
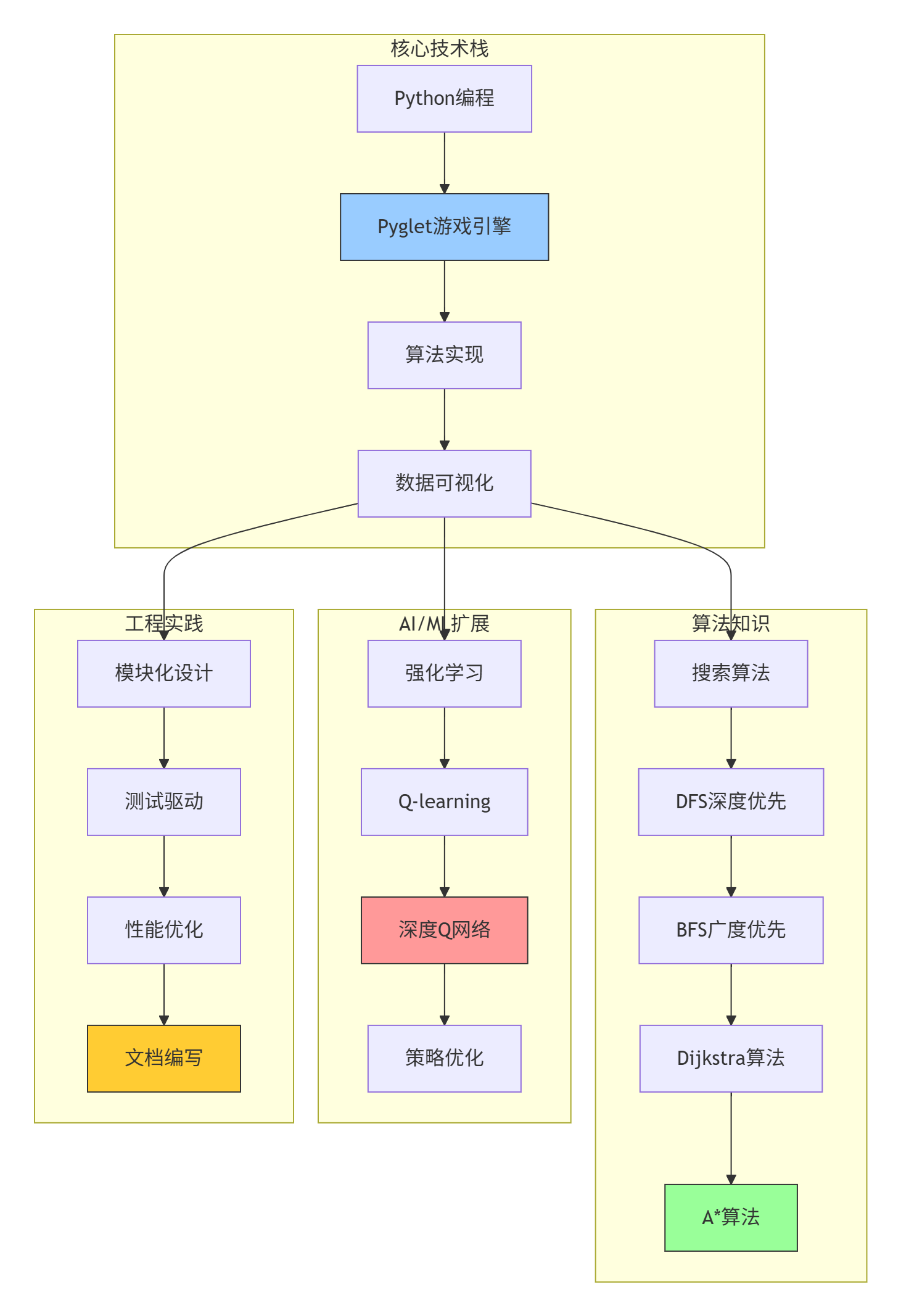
6.3 扩展学习方向
这个项目可以进一步扩展到以下方向:
| 扩展方向 | 关键技术 | 学习目标 |
|---|---|---|
| 3D迷宫 | OpenGL/3D渲染 | 3D图形编程,空间导航 |
| 动态迷宫 | 实时物理模拟 | 动态障碍物处理,实时规划 |
| 多智能体 | 多智能体系统 | 协作与竞争,博弈论 |
| 复杂环境 | 计算机视觉 | 图像识别,环境感知 |
| 优化算法 | 遗传算法/蚁群算法 | 群体智能,优化理论 |