上次我们谈到了HTTP协议与抓包工具,现在我们继续往下讲。
抓包工具中看HTTP的结构
打开fiddler抓包工具,点击inspectors然后点击两个raw按钮,以及左边页面的内容,看到了这个页面:
在fiddler中,点击这个按钮(两个都可以点):
我们可以分为这样的结构:


让我们探索一下每个部分的具体详情吧。
1.URL
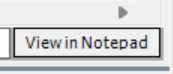
这是描述网络上的唯一资源的位置的。MYSQL是一个"客户端-服务器"结构的程序,存储数据的本体是在服务器里的。

这里的https是协议名称,分隔号后面是要访问的服务器的IP地址或者域名,这个域名的后面没写端口号,在没写的时候,浏览器会自动添加默认的端口号,这取决于协议名称。http的端口号是80,https的默认端口号是443.当然,这默认的端口号访问远端服务器的那个端口,而不是浏览器自身的"客户端的端口"。也就是说,端口号指向的是目的端口,IP指向 的是目的IP。再后面的web是带有层次结构的路径(目录),根据需要灵活定义任意的层次结构,对提供的资源进行分类组织。

2.urlencode
这个主要的功能就是转义。

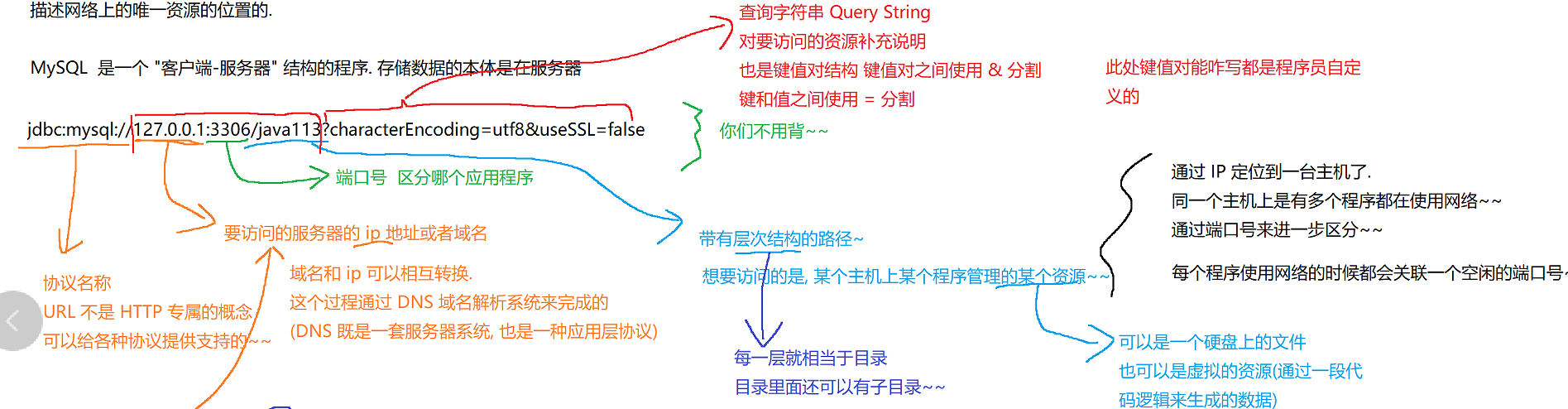
转义操作,不仅仅是标点符号,对于中文等其他非英语系的文字,也是需要转义的,只不过很多浏览器为了用户看起来方便,显示的时候显示转义之前的,实际上抓包中就能看到是已经转义的数据。
如果在抓包工具中没有进行转义,就可能会使这里的请求失败。

比如"+"转义为0x2B,汉字"你好"的转义参考ascll码表的十六进制,一个字节为单位,用两个%包夹住。
认识"方法"
这里的方法,就是表示这次的请求要来干啥。
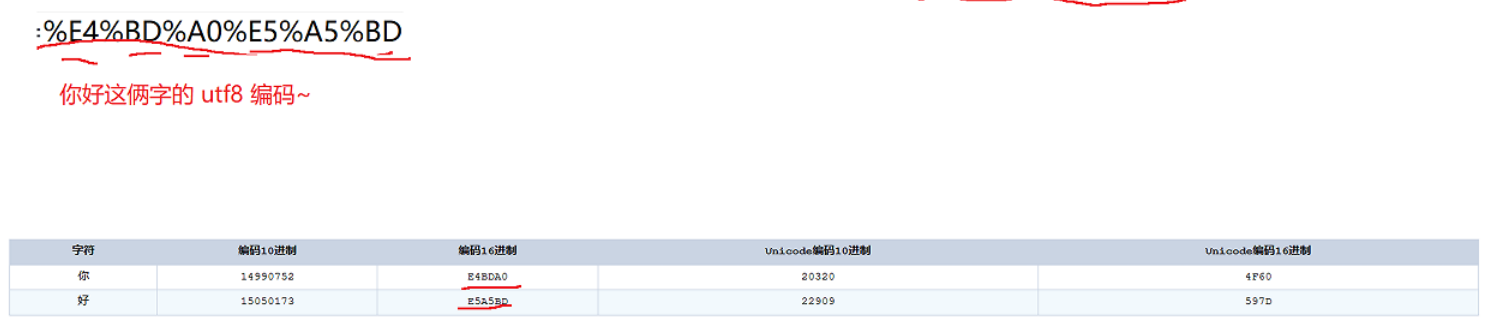
方法如下表所示:
其中,get和post是最常见的请求。
这个表上的说明只是从语义上来说他们的作用,但是实际上,开发的时候不一定会严格按照语义来进行区分。
程序员实际实现的时候,可以自行灵活掌控这些方法。
一般来讲,获取HTML、CSS、js等操作,都是get(get最常用);而在登录、上传文件的时候就用post。
可是我们在一个页面上发现蓝绿紫色的链接很少,该如何让他们变多呢?
这里需要用到crtl+F5------强制刷新的操作
浏览器是具有缓存机制的,从服务器或通过网络加载网页(速度由快到慢是CPU、内存、硬盘、网络),通常情况下,从网络加载数据比从硬盘加载要慢,浏览器为了加快访问页面的速度,就会把页面依赖的一些静态资源(CSS、js、图片等)缓存到硬盘上。
第一次访问服务器,需要加载这么多东西,后续再访问,就不必重新加载。强制刷新忽略了本地缓存,所有资源都重新从服务器获取,因而速度大大提升了。
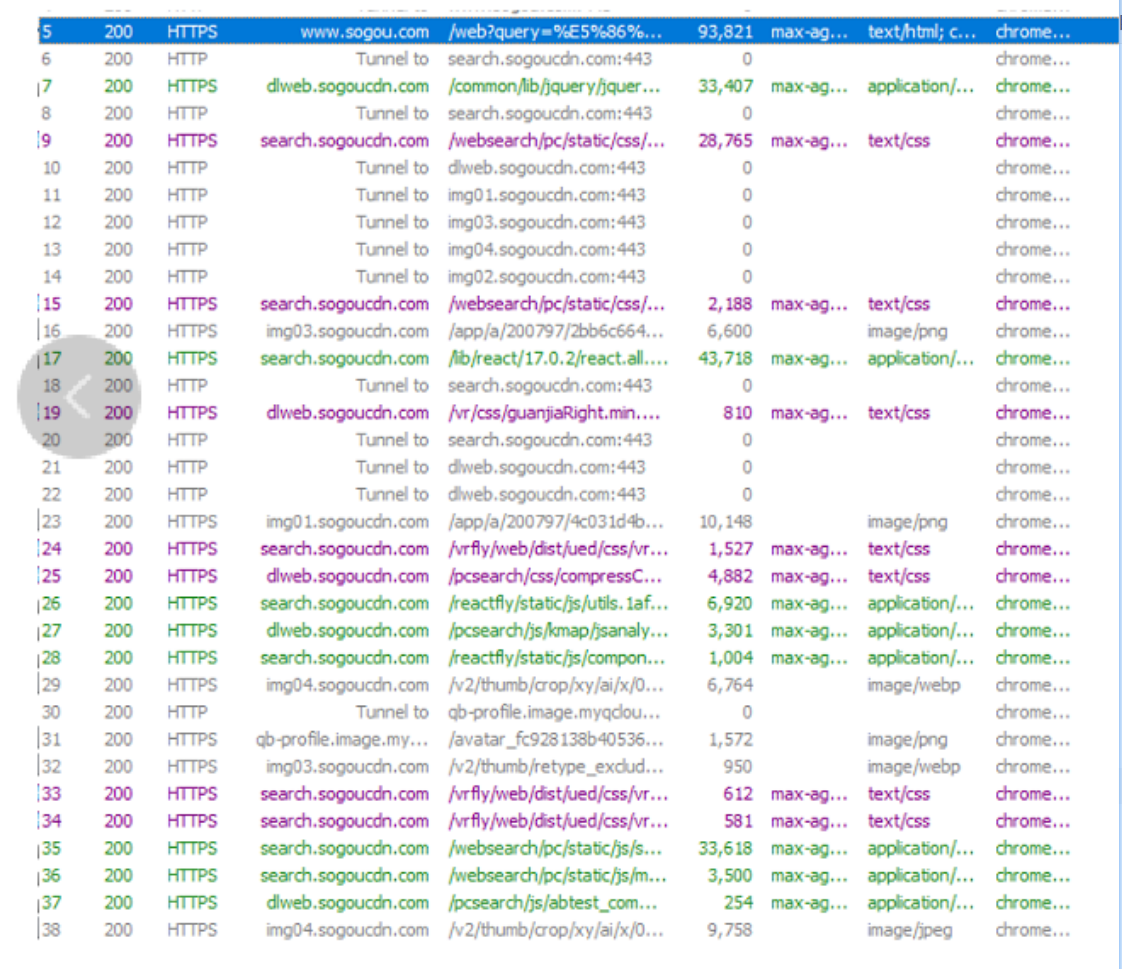
上图是强制刷新后的效果。
get请求一般是没有body的,如果需要通过get给服务器发送一些数据,通过query String传递过去的;而对于post来说,适用于两个典型的场景:
1.登录
2.上传,请求带有正文的,正文就是保存了当前上传的数据的内容。上述请求中,图片本身是二进制的,通过特殊方式进行转码(base64编码,把二进制转化为文本)其实,body也是可以直接填二进制数据的。
get与post之间的区别
1.语义上的区别(略)
2.携带数据的方式
语义上可以混用是事实,不过post是可以带有query string,get理论上可以带body,但很少见。
面试中如果被问到,首先抛出结论,post与get没有本质区别,可以混用,从使用方法习惯上来说,主要是上面两方面的区别。
3.get请求通常建议(但不强制)设计成幂等的,post没有这个要求
幂等,即请求是一定的,响应也是一定的,如支付转义的场景,就需要考虑幂等性。
4.由于get设计成幂等了,就可以允许get请求的结果被缓存;post由于不要求幂等,经常是不幂等的,就认为不能被缓存的
实际上现在get不幂等的情况也是十分常见的。


这四个操作的任何一个,都可以进行增删改查的。