Functional Adversarial Attacks
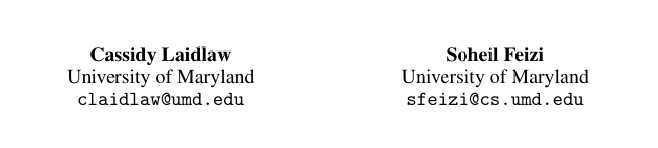
摘要
我们提出功能对抗性攻击,这是一类新颖的威胁模型,用于制造欺骗机器学习模型的对抗性示例。与标准的 ℓp\ell_{p}ℓp 球威胁模型不同,功能对抗性威胁模型只允许使用单个函数来扰动输入特征以产生对抗性示例。例如,对图像颜色应用的功能对抗性攻击可以同时将所有红色像素变为浅红色。这种图像中的全局均匀变化可能比单独扰动每个像素更不易察觉。为简单起见,我们将对图像颜色的功能对抗性攻击称为 ReColorAdv,这也是我们实验的主要焦点。我们表明,功能威胁模型可以与现有的加性(ℓp\ell_{p}ℓp)威胁模型相结合,生成更强的威胁模型,允许对输入进行小的、单独的扰动以及大的、均匀的变化。此外,我们证明这种组合包含了在任一组成威胁模型中都不允许的扰动。在实践中,ReColorAdv 可以显著降低在 CIFAR-10 上训练的 ResNet-32 的准确率。此外,据我们所知,将 ReColorAdv 与其他攻击相结合,即使在对抗训练后也能产生最强的现有攻击。
1 引言
最近有大量关于对抗性示例的文献,这些是对机器学习算法输入的微小扰动,导致算法输出错误结果,例如分类器给出错误标签。对抗性示例给自动驾驶汽车等现实世界系统带来了严重的安全挑战,因为环境中人类不易察觉的变化可能导致意外、不良或危险的行为。已经提出了许多生成对抗性示例的方法(称为对抗性攻击)23, 5, 15, 17, 3。针对此类攻击的防御也已被探索 18, 14, 30。
大多数现有的攻击和防御方法考虑的是对抗性攻击的威胁模型,其中对抗性示例与正常输入的 ℓp\ell_{p}ℓp 距离很小。然而,使用这种包含"小扰动"简单定义的威胁模型,忽略了其他可能对人类也不可察觉的扰动类型。例如,小的空间扰动已被用于生成对抗性示例 4, 27, 26。
在本文中,我们提出了一类新的对抗性攻击威胁模型,称为功能威胁模型。在功能威胁模型下,通过对输入的所有特征应用单个函数,可以从分类器的常规输入生成对抗性示例:
加性 威胁模型:(x1,...,xn)→(x1+δ1,...,xn+δn) \mathrm{加性~威胁模型:}\quad (x_{1},\ldots ,x_{n})\quad \rightarrow \quad (x_{1} + \delta_{1},\ldots ,x_{n} + \delta_{n}) 加性 威胁模型:(x1,...,xn)→(x1+δ1,...,xn+δn)
功能 威胁模型:(x1,...,xn)→(f(x1),...,f(xn)) \mathrm{功能~威胁模型:}\quad (x_{1},\ldots ,x_{n})\quad \rightarrow \quad (f(x_{1}),\ldots ,f(x_{n})) 功能 威胁模型:(x1,...,xn)→(f(x1),...,f(xn))
例如,扰动函数 f(⋅)f(\cdot)f(⋅) 可以使图像中的每个红色像素变暗,或增加音频样本中每个时间步的音量。功能威胁模型在某些方面更具限制性,因为不能单独扰动特征。然而,功能威胁模型中扰动的均匀性使变化更不易察觉,从而允许更大的绝对修改。例如,可以将整个图像变暗或变亮相当多而不被注意到。这与对每个像素的单独变化形成对比,后者必须更小以避免变得明显。我们讨论了可应用于扰动函数 f(⋅)f(\cdot)f(⋅) 的各种正则化,以确保即使是大变化也不易察觉。
加性(ℓp\ell_{p}ℓp)和功能威胁模型的优缺点互补;加性威胁模型允许对输入的每个特征进行小的、单独的更改,而功能威胁模型允许大的、均匀的更改。因此,我们结合了这些威胁模型(见图 1),并表明这种组合包含了比任一单独模型更多的潜在扰动,如下面定理所述,该定理在第 3.2 节中更精确地陈述。
定理 1(非正式) 。设 x\mathbf{x}x 为具有 n≥2n \geq 2n≥2 个像素的灰度图像。考虑一个加性威胁模型,允许将每个像素改变最多一定量,以及一个功能威胁模型,允许将整个图像变暗或变亮更大的量。那么这些威胁模型的组合允许的潜在扰动在任一组成威胁模型中都是不允许的。
功能威胁模型可用于多种领域,如图像(例如,均匀更改图像颜色)、语音/音频(例如,更改音频片段的"口音")、文本(例如,将整个文档中的单词替换为其同义词)或欺诈分析(例如,统一修改行为者的金融活动)。此外,由于功能扰动是大而均匀的,它们也可能更容易用于物理对抗性示例,其中加性扰动中产生的小像素级变化可能被环境噪声淹没。

在本文中,我们将专注于其中一个领域------图像------并定义 ReColorAdv,一种对像素颜色的功能对抗性攻击(见图 2)。在 ReColorAdv 中,我们使用一个灵活参数化的函数 fff 将输入中的每个像素颜色 ccc 映射到对抗性示例中的新像素颜色 f(c)f(c)f(c)。我们对 f(⋅)f(\cdot)f(⋅) 进行正则化,既确保没有颜色被扰动超过一定量,又确保映射是平滑的,即相似的颜色以相似的方式被扰动。我们表明,ReColorAdv 可以使用标准的红绿蓝(RGB)颜色空间以及 CIELUV 颜色空间,后者产生的对抗性示例在感知上差异更小(见图 4)。
我们通过攻击有防御和无防御的分类器来实验 ReColorAdv,单独使用以及与其他攻击结合。我们发现 ReColorAdv 是一种强大的攻击,将在 CIFAR-10 上训练的 ResNet-32 的准确率降低到 3.0%3.0\%3.0%。ReColorAdv 与其他攻击的组合更加强大;其中一种组合将 CIFAR-10 分类器的准确率降低到 3.6%3.6\%3.6%,即使在对抗训练之后也是如此。这低于 Jordan 等人 10 先前最强的攻击。我们还通过将使用 TRADES 30 训练的分类器的准确率降低到 5.7%5.7\%5.7%,展示了基于加性威胁模型的对抗性防御的脆弱性。尽管有人可能试图通过在分类前将图像转换为灰度来减轻 ReColorAdv 攻击(这会去除颜色信息),但我们表明这只会降低分类器的准确率(无论是自然准确率还是对抗准确率)。此外,我们发现将 ReColorAdv 与其他攻击相结合可以在不增加生成对抗性示例的感知差异(通过 LPIPS 32 测量)的情况下提高攻击强度。
我们的贡献总结如下:
- 我们引入了一类新的威胁模型,即功能对抗性威胁模型,并将其与现有威胁模型相结合。我们还描述了正则化功能威胁模型以确保生成的对抗性示例不易察觉的方法。
- 理论上,我们证明了加性和功能威胁模型组合创建了一个比任一单独威胁模型包含更多潜在扰动的威胁模型。
- 实验上,我们表明 ReColorAdv(对图像使用功能威胁模型)是一种针对图像分类器的强大对抗性攻击。据我们所知,将 ReColorAdv 与其他攻击相结合,即使在对抗训练后也能产生最强的现有攻击。
2 现有威胁模型回顾
在本节中,我们定义生成对抗性示例的问题,并回顾现有的对抗性威胁模型和攻击。
问题定义 考虑一个分类器 g:Xn→Yg:\mathcal{X}^n\to \mathcal{Y}g:Xn→Y,从特征空间 Xn\mathcal{X}^nXn 到标签集 Y\mathcal{Y}Y。给定输入 x∈Xn\mathbf{x}\in \mathcal{X}^nx∈Xn,对抗性示例是 x\mathbf{x}x 的微小扰动 x~\tilde{\mathbf{x}}x~,使得 g(x~)≠g(x)g(\tilde{\mathbf{x}})\neq g(\mathbf{x})g(x~)=g(x),即分类器给 x~\tilde{\mathbf{x}}x~ 赋予与 x\mathbf{x}x 不同的标签。由于对抗性示例的目标是与正常输入在感知上不可区分,x~\tilde{\mathbf{x}}x~ 通常被某个威胁模型约束为接近 x\mathbf{x}x。形式上,Jordan 等人 10 将威胁模型定义为一个函数 t:P(Xn)→P(Xn)t:\mathcal{P}(\mathcal{X}^n)\to \mathcal{P}(\mathcal{X}^n)t:P(Xn)→P(Xn),其中 P\mathcal{P}P 表示幂集。函数 t(⋅)t(\cdot)t(⋅) 将一组分类器输入 S\mathcal{S}S 映射到一组扰动输入 t(S)t(\mathcal{S})t(S),这些扰动输入在感知上难以区分。有了这个定义,我们可以形式化从输入生成对抗性示例的问题:
find x~such thatg(x~)≠g(x) and x~∈t({x}) \mathrm{find}~\tilde{\mathbf{x}}\quad \mathrm{such~that}\quad g(\tilde{\mathbf{x}})\neq g(\mathbf{x})~\mathrm{and}~\tilde{\mathbf{x}}\in t(\{\mathbf{x}\}) find x~such thatg(x~)=g(x) and x~∈t({x})
加性威胁模型 生成对抗性示例时最常用的威胁模型是加性威胁模型。设 x=(x1,...,xn)\mathbf{x} = (x_{1},\ldots ,x_{n})x=(x1,...,xn),其中每个 xi∈Xx_{i}\in \mathcal{X}xi∈X 是 x\mathbf{x}x 的一个特征。例如,xix_{i}xi 可以对应图像中的像素或音频样本中时间步的滤波器组能量。在加性威胁模型中,我们假设 x~=(x1+δ1,...,xn+δn)\tilde{\mathbf{x}} = (x_{1} + \delta_{1},\ldots ,x_{n} + \delta_{n})x~=(x1+δ1,...,xn+δn);即,向 x\mathbf{x}x 的每个特征添加一个值 δi\delta_{i}δi 以生成对抗性示例 x~\tilde{\mathbf{x}}x~。在此威胁模型下,感知相似性通常通过 δ=(δ1,...,δn)\delta = (\delta_{1},\ldots ,\delta_{n})δ=(δ1,...,δn) 的范数约束来强制执行。因此,加性威胁模型定义为
tadd(S)≜{(x1+δ1,...,xn+δn)∣(x1,...,xn)∈S,∥δ∥≤ϵ}. t_{\mathrm{add}}(\mathcal{S})\triangleq \{(x_{1} + \delta_{1},\ldots ,x_{n} + \delta_{n})\mid (x_{1},\ldots ,x_{n})\in \mathcal{S},\| \delta \| \leq \epsilon \}. tadd(S)≜{(x1+δ1,...,xn+δn)∣(x1,...,xn)∈S,∥δ∥≤ϵ}.
常用的范数包括 ∥⋅∥2\| \cdot \|{2}∥⋅∥2(欧几里得距离),它约束 δi\delta{i}δi 的平方和;∥⋅∥0\| \cdot \|{0}∥⋅∥0,它约束可以改变的特征数量;以及 ∥⋅∥∞\| \cdot \|{\infty}∥⋅∥∞,它允许将每个特征改变最多一定量。注意,所有 δi\delta_{i}δi 都可以单独修改以产生错误分类,只要满足范数约束。因此,通常需要小的 ϵ\epsilonϵ,否则输入可能因噪声而变得不可理解。
大多数先前关于生成对抗性示例的工作都采用了加性威胁模型。这包括基于梯度的方法如 FGSM 5、DeepFool 15 和 Carlini & Wagner 3,以及无梯度方法如 SPSA 25 和边界攻击 2。
3 功能威胁模型
在本节中,我们定义功能威胁模型并探索其与现有威胁模型的组合。回想在加性威胁模型中,输入的每个特征只能被扰动很小的量。由于所有特征都被单独改变,较大的变化可能使输入无法识别。我们的关键见解是,如果考虑特征之间的依赖性,对输入进行更大的扰动应该是可能的。
与加性威胁模型不同,在功能威胁模型中,特征 xix_{i}xi 被单个函数 f:X→Xf: \mathcal{X} \to \mathcal{X}f:X→X(称为扰动函数)变换。即,
x~=f(x)=(f(x1),...,f(xn)) \widetilde{\mathbf{x}} = f(\mathbf{x}) = (f(x_{1}),\ldots ,f(x_{n})) x =f(x)=(f(x1),...,f(xn))
在此威胁模型下,输入中具有相同值的特征必须映射到对抗性示例中的相同值。功能威胁模型允许的大扰动可能对人类眼睛不可察觉,因为它们保持了特征之间的依赖性(例如,图像中的形状边界和阴影,见图 1)。注意,被扰动函数 f(⋅)f(\cdot)f(⋅) 修改的特征 xix_{i}xi 不必是标量;根据应用,向量值特征也可能有用。
3.1 正则化功能威胁模型
在功能威胁模型中,可以使用各种正则化来确保变化保持不可察觉。通常,我们可以强制 f∈Ff\in \mathcal{F}f∈F,其中 F\mathcal{F}F 是允许的扰动函数族。例如,我们可能希望将扰动函数输入和输出之间的最大差异约束在一个小的 ϵ\epsilonϵ 内。在这种情况下,我们将有:
Fdiff≜{f:X→X∣∀xi∈X ∥f(xi)−xi∥≤ϵ}(1) \mathcal{F}{\mathrm{diff}}\triangleq \{f:\mathcal{X}\to \mathcal{X}\mid \forall x{i}\in \mathcal{X}~\| f(x_{i}) - x_{i}\| \leq \epsilon \} \tag{1} Fdiff≜{f:X→X∣∀xi∈X ∥f(xi)−xi∥≤ϵ}(1)
Fdiff\mathcal{F}{\mathrm{diff}}Fdiff 防止绝对变化超过一定量。注意,ϵ\epsilonϵ 边界可能高于加性模型中的边界,因为均匀变化更不易察觉。然而,这种正则化可能不足以防止明显的变化。Fdiff\mathcal{F}{\mathrm{diff}}Fdiff 仍然包含将相似(但不相同)特征映射得非常不同的函数。因此,可以使用第二个约束,强制相似特征被相似地扰动:
Fsmooth≜{f∣∀xi,xj∈X ∥xi−xj∥≤r⇒∥(f(xi)−xi)−(f(xj)−xj)∥≤ϵsmooth}(2) \mathcal{F}{\mathrm{smooth}}\triangleq \{f\mid \forall x{i},x_{j}\in \mathcal{X}~\| x_{i} - x_{j}\| \leq r \Rightarrow \| (f(x_{i}) - x_{i}) - (f(x_{j}) - x_{j})\| \leq \epsilon_{\mathrm{smooth}}\} \tag{2} Fsmooth≜{f∣∀xi,xj∈X ∥xi−xj∥≤r⇒∥(f(xi)−xi)−(f(xj)−xj)∥≤ϵsmooth}(2)
Fsmooth\mathcal{F}_{\mathrm{smooth}}Fsmooth 要求相似特征以相同的"方向"被扰动。例如,如果图像中的绿色像素被提亮,那么黄绿色像素也应该被提亮。
根据应用,这些约束或其他约束可能是保持变化不可察觉所必需的。我们可能希望选择 F\mathcal{F}F 为 Fdiff\mathcal{F}{\mathrm{diff}}Fdiff、Fsmooth\mathcal{F}{\mathrm{smooth}}Fsmooth、Fdiff∩Fsmooth\mathcal{F}{\mathrm{diff}}\cap \mathcal{F}{\mathrm{smooth}}Fdiff∩Fsmooth,或完全不同的函数族。一旦我们选择了 F\mathcal{F}F,我们可以定义相应的功能威胁模型为
tfunc(S)≜{(f(x1),...,f(xn))∣(x1,...,xn)∈S,f∈F} t_{\mathrm{func}}(\mathcal{S})\triangleq \{(f(x_{1}),\ldots ,f(x_{n}))\mid (x_{1},\ldots ,x_{n})\in \mathcal{S},f\in \mathcal{F}\} tfunc(S)≜{(f(x1),...,f(xn))∣(x1,...,xn)∈S,f∈F}
3.2 组合威胁模型
Jordan 等人 10 认为,组合多个威胁模型可以更好地逼近完整的、不可察觉的对抗性扰动集合。在这里,我们证明将加性威胁模型与一个简单的功能威胁模型相结合,可以允许在任一单独模型中都不可行的对抗性示例。以下定理(在附录 A 中证明)在图像上证明了这一点,针对一个加性威胁模型(允许将每个像素改变一个小的有界量)和一个功能威胁模型(允许将整个图像变暗或变亮最多一个更大的量),这两者都可以被认为是不可察觉的变换。

定理 1 。设 x\mathbf{x}x 为具有 n≥2n \geq 2n≥2 个像素的灰度图像,即 x∈0,1n=Xn\mathbf{x} \in 0, 1^n = \mathcal{X}^nx∈0,1n=Xn。设 taddt_{\text{add}}tadd 为一个加性威胁模型,其中输入与对抗性示例之间的 ℓ∞\ell_{\infty}ℓ∞ 距离有界为 ϵ1\epsilon_1ϵ1,即 ∥(δ1,...,δn)∥∞≤ϵ1\| (\delta_1, \ldots , \delta_n)\|{\infty} \leq \epsilon_1∥(δ1,...,δn)∥∞≤ϵ1。设 tfunct{\text{func}}tfunc 为一个功能威胁模型,其中 f(x)=cxf(x) = c xf(x)=cx,c∈1−ϵ2,1+ϵ2c \in 1 - \\epsilon_2, 1 + \\epsilon_2c∈1−ϵ2,1+ϵ2,且 ϵ2>ϵ1>0\epsilon_2 > \epsilon_1 > 0ϵ2>ϵ1>0。设 tcombined=tadd∘tfunct_{\text{combined}} = t_{\text{add}} \circ t_{\text{func}}tcombined=tadd∘tfunc。那么组合威胁模型允许的对抗性扰动在任一组成威胁模型中都是不允许的。形式化地,如果 S⊆Xn\mathcal{S} \subseteq \mathcal{X}^nS⊆Xn 包含一个不是太暗的图像 x\mathbf{x}x,即存在某个 xix_ixi 使得 xi>ϵ1/ϵ2x_i > \epsilon_1 / \epsilon_2xi>ϵ1/ϵ2,那么
tcombined(S)⊇tadd(S)∪tfunc(S)或等价地∃x~ s.t. x~∈tcombined(S)x~∉tadd(S)∪tfunc(S) t_{\text{combined}}(\mathcal{S}) \supseteq t_{\text{add}}(\mathcal{S}) \cup t_{\text{func}}(\mathcal{S}) \qquad \text{或等价地} \qquad \exists \tilde{\mathbf{x}} \text{ s.t. } \begin{array}{l}\tilde{\mathbf{x}} \in t_{\text{combined}}(\mathcal{S}) \\ \tilde{\mathbf{x}} \notin t_{\text{add}}(\mathcal{S}) \cup t_{\text{func}}(\mathcal{S}) \end{array} tcombined(S)⊇tadd(S)∪tfunc(S)或等价地∃x~ s.t. x~∈tcombined(S)x~∈/tadd(S)∪tfunc(S)
4 ReColorAdv:对图像颜色的功能对抗性攻击
在本节中,我们定义 ReColorAdv,一种利用功能威胁模型的新型对抗性攻击,针对图像分类器。ReColorAdv 通过均匀改变输入图像的颜色来生成欺骗图像分类器的对抗性示例。我们将输入图像 x\mathbf{x}x 中的每个像素 xix_ixi 视为三维颜色空间 C⊆0,13\mathcal{C} \subseteq 0, 1^3C⊆0,13 中的一个点。例如,C\mathcal{C}C 可以是正常的 RGB 颜色空间。在第 4.1 节中,我们讨论了对替代颜色空间的使用。我们利用扰动函数 f:C→Cf: \mathcal{C} \to \mathcal{C}f:C→C 来产生对抗性示例。具体地,输出 x~\tilde{\mathbf{x}}x~ 中的每个像素通过将 f(⋅)f(\cdot)f(⋅) 应用于该像素中的颜色来从输入 x\mathbf{x}x 扰动:
xi=(ci,1,ci,2,ci,3)∈C⊆0,13→x~i=(c~i,1,c~i,2,c~i,3)=f(ci,1,ci,2,ci,3) x_{i} = (c_{i,1},c_{i,2},c_{i,3})\in \mathcal{C}\subseteq 0,1^{3}\quad \rightarrow \quad \tilde{x}{i} = (\tilde{c}{i,1},\tilde{c}{i,2},\tilde{c}{i,3}) = f(c_{i,1},c_{i,2},c_{i,3}) xi=(ci,1,ci,2,ci,3)∈C⊆0,13→x~i=(c~i,1,c~i,2,c~i,3)=f(ci,1,ci,2,ci,3)
为了找到能生成成功对抗性示例的 f(⋅)f(\cdot)f(⋅),我们需要一个既灵活又易于计算的函数参数化。为此,我们让 G=g1,...,gm⊆0,13\mathcal{G} = g_1, \ldots , g_m \subseteq 0, 1^3G=g1,...,gm⊆0,13 是 fff 被显式定义的离散网格点(或点阵)。即,我们定义参数 θ1,...,θm\theta_1, \ldots , \theta_mθ1,...,θm 并令 f(gi)=θif(g_i) = \theta_if(gi)=θi。对于不在网格上的点,即 xi∉Gx_i \notin \mathcal{G}xi∈/G,我们使用三线性插值定义 f(xi)f(x_i)f(xi)。三线性插值考虑参数 xix_ixi 周围的网格点 gjg_jgj 的"立方体",并对该立方体的 8 个角点上显式定义的 θj\theta_jθj 值进行线性插值以计算 f(xi)f(x_i)f(xi)。
对扰动函数的约束 我们对 f(⋅)f(\cdot)f(⋅) 施加两个约束,以确保生成的对抗性示例与原始图像不可区分。这些约束基于第 3.1 节中定义的 Fdiff\mathcal{F}{\text{diff}}Fdiff 和 Fsmooth\mathcal{F}{\text{smooth}}Fsmooth 的轻微修改。首先,我们确保在颜色空间的每个维度上,任何像素的扰动不超过一定量:
Fdiff−col≜{f:C→C∣∀(c1,c2,c3)∈G∣ci−c~i∣<ϵii=1,2,3} \mathcal{F}_{\mathrm{diff - col}}\triangleq \{f:\mathcal{C}\to \mathcal{C}\mid \forall (c_1,c_2,c_3)\in \mathcal{G}\quad |c_i - \tilde{c}_i|< \epsilon_i\quad i = 1,2,3\} Fdiff−col≜{f:C→C∣∀(c1,c2,c3)∈G∣ci−c~i∣<ϵii=1,2,3}
这种特定的公式允许我们在颜色空间的每个维度上设置不同的边界 (ϵ1,ϵ2,ϵ3)(\epsilon_1, \epsilon_2, \epsilon_3)(ϵ1,ϵ2,ϵ3)。我们还基于 Fsmooth\mathcal{F}_{\text{smooth}}Fsmooth 定义了一个约束,但代替使用 (2) 中的半径参数 rrr,我们考虑网格 G\mathcal{G}G 中每个格点 gjg_jgj 的邻居 N(gj)\mathcal{N}(g_j)N(gj):
Fsmooth−col≜{f:C→C∣∀gj∈X,gk∈N(gj)∥(f(gj)−gj)−(f(gk)−gk)∥2≤ϵsmooth} \mathcal{F}_{\mathrm{smooth - col}}\triangleq \{f:\mathcal{C}\to \mathcal{C}\mid \forall g_j\in \mathcal{X},g_k\in \mathcal{N}(g_j)\quad \| (f(g_j) - g_j) - (f(g_k) - g_k)\| 2\leq \epsilon{\mathrm{smooth}}\} Fsmooth−col≜{f:C→C∣∀gj∈X,gk∈N(gj)∥(f(gj)−gj)−(f(gk)−gk)∥2≤ϵsmooth}
在上式中,∥⋅∥2\| \cdot \|{2}∥⋅∥2 是颜色空间 C\mathcal{C}C 中的 ℓ2\ell{2}ℓ2(欧几里得)范数。我们将允许的扰动函数集定义为 Fcol=Fdiff−col∩Fsmooth−col\mathcal{F}{\mathrm{col}} = \mathcal{F}{\mathrm{diff - col}}\cap \mathcal{F}{\mathrm{smooth - col}}Fcol=Fdiff−col∩Fsmooth−col,带有参数 (ϵ1,ϵ2,ϵ3,ϵsmooth)(\epsilon{1},\epsilon_{2},\epsilon_{3},\epsilon_{\mathrm{smooth}})(ϵ1,ϵ2,ϵ3,ϵsmooth)。

优化 为了用 ReColorAdv 生成对抗性示例,我们希望最小化 Ladv(f,x)\mathcal{L}{\mathrm{adv}}(f,x)Ladv(f,x),满足 f∈Fcolf\in \mathcal{F}{\mathrm{col}}f∈Fcol,其中 Ladv\mathcal{L}{\mathrm{adv}}Ladv 强制执行生成被错误分类的对抗性示例的目标,并定义为 Carlini 和 Wagner 3 的 f6f{6}f6 损失,其中 g(x)ig(\mathbf{x})_{i}g(x)i 表示分类器的第 iii 个 logit:
Ladv(f,x)=max(maxi≠y(g(x~)i−g(x~)y),0)(3) \mathcal{L}{\mathrm{adv}}(f,x) = \max \left(\max{i\neq y}(g(\widetilde{\mathbf{x}})_i - g(\widetilde{\mathbf{x}})_y),0\right) \tag{3} Ladv(f,x)=max(i=ymax(g(x )i−g(x )y),0)(3)
在解决这个约束最小化问题时,通过将每个颜色的扰动裁剪到 ϵi\epsilon_{i}ϵi 范围内,很容易约束 f∈Fdiff−colf\in \mathcal{F}{\mathrm{diff - col}}f∈Fdiff−col。然而,直接强制 f∈Fsmooth−colf\in \mathcal{F}{\mathrm{smooth - col}}f∈Fsmooth−col 很困难。因此,我们转而求解一个拉格朗日松弛,其中平滑约束被一个额外的正则化项取代:
argminf∈Fdiff−colLadv(f,x)+λLsmooth(f)(∗) \underset {f\in \mathcal{F}{\mathrm{diff - col}}}{\arg \min}\mathcal{L}{\mathrm{adv}}(f,\mathbf{x}) + \lambda \mathcal{L}_{\mathrm{smooth}}(f) \quad (*) f∈Fdiff−colargminLadv(f,x)+λLsmooth(f)(∗)
Lsmooth(f)≜∑gj∈G∑gk∈N(gj)∥(f(gj)−gj)−(f(gk)−gk)∥2 \mathcal{L}{\mathrm{smooth}}(f)\triangleq \sum{g_j\in \mathcal{G}} \sum_{g_k\in \mathcal{N}(g_j)}\| (f(g_j) - g_j) - (f(g_k) - g_k)\| _2 Lsmooth(f)≜gj∈G∑gk∈N(gj)∑∥(f(gj)−gj)−(f(gk)−gk)∥2
我们的 Lsmooth\mathcal{L}_{\mathrm{smooth}}Lsmooth 类似于 Xiao 等人 27 用来确保平滑流场的损失函数。我们使用投影梯度下降(PGD)优化算法来求解 (∗)(*)(∗)。
4.1 RGB 与 LUV 颜色空间
大多数图像分类器将 RGB 颜色空间中指定的像素数组作为输入,但 RGB 颜色空间有两个缺点。RGB 颜色空间中点之间的 ℓp\ell_{p}ℓp 距离与它们所代表的颜色之间的感知差异相关性很弱。此外,RGB 没有分离颜色的亮度(luma)和色度(chroma)。
相比之下,CIELUV 颜色空间将亮度与色度分离,并放置颜色使得它们之间的欧几里得距离大致等于感知差异 21。CIELUV 通过三个分量 (L,U,V)(L,U,V)(L,U,V) 表示颜色;LLL 是亮度,而 UUU 和 VVV 共同定义色度。我们使用 RGB 和 CIELUV 颜色空间进行实验。CIELUV 允许我们以感知上准确的方式正则化扰动函数 f(⋅)f(\cdot)f(⋅)(见图 4 和附录 B.1)。我们也尝试了色相、饱和度、明度(HSV)和 YPbPr 颜色空间;然而,两者都不是感知上准确的,并且 HSV 到 RGB 的转换难以微分(见附录 C)。
5 实验
我们在 CIFAR-10 13 和 ImageNet 20 上评估了 ReColorAdv 对受防御和未受防御的神经网络的攻击。对于 CIFAR-10,我们针对 ResNet-32 6 评估攻击;对于 ImageNet,我们针对 Inception-v4 网络 24 评估攻击。我们还考虑了 ReColorAdv 与 delta 攻击(使用 ϵ=8/255\epsilon = 8/255ϵ=8/255 的 ℓ∞\ell_{\infty}ℓ∞ 加性威胁模型)以及 Xiao 等人 27 的 StAdv 攻击(通过流场空间扰动图像)的所有组合。关于我们实验中使用的超参数和计算基础设施的完整讨论见附录 B。我们在 https://github.com/cassidylaidlaw/ReColorAdv 发布了代码。
5.1 对抗训练
我们首先通过攻击对抗训练的模型来实验 ReColorAdv 和其他攻击。对于每种攻击组合,我们在 CIFAR-10 上针对该特定组合对抗训练一个 ResNet-32。我们使用所有攻击组合攻击每个对抗训练的模型。该实验的结果显示在表 1 的第一部分。
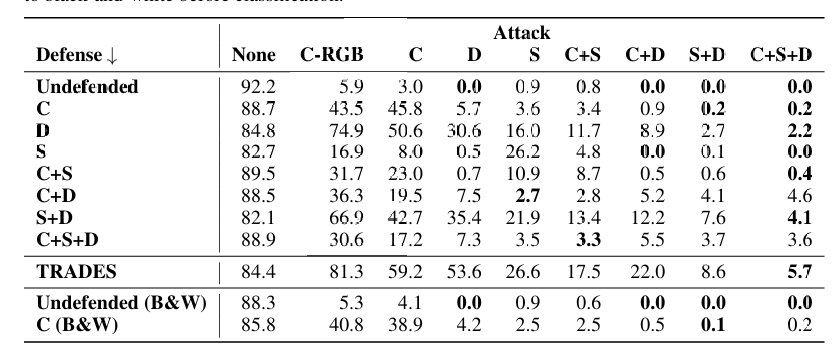
组合攻击最强大 正如预期的那样,攻击组合对受防御和未受防御的分类器都是最强的。特别是,ReColorAdv + StAdv + delta 攻击通常导致最低的分类器准确率。针对 ReColorAdv + StAdv + delta 攻击进行对抗训练后,准确率仅为 3.6%3.6\%3.6%,这是我们已知的最低准确率。
鲁棒性在不同扰动类型之间的可迁移性 虽然对抗性攻击的"可迁移性"通常指攻击在不同模型之间的迁移能力 16,这里我们研究一个模型对一种类型的对抗性扰动的鲁棒性在多大程度上可以迁移到其他类型的扰动,类似于 Kang 等人 11。在一定程度上,所研究的扰动是正交的;即,针对特定类型扰动训练的模型对其他类型的扰动效果较差。StAdv 与其他两种攻击尤其分离;针对 StAdv 攻击训练的模型仍然非常容易受到 ReColorAdv 和 delta 攻击的攻击。然而,ReColorAdv 和 delta 攻击允许在彼此之间更可迁移的鲁棒性。这些结果可能是由于 delta 和 ReColorAdv 攻击都在逐像素基础上操作,而 StAdv 攻击允许特征在像素之间的空间移动。
颜色空间的影响 使用 CIELUV 颜色空间的 ReColorAdv 攻击比使用 RGB 颜色空间的更强。此外,CIELUV 颜色空间产生更不易察觉的扰动(见图 4)。这突显了在设计和防御对抗性示例时使用感知准确的颜色模型的必要性。
5.2 其他防御
TRADES TRADES 是一种深度神经网络训练算法,旨在通过优化代理损失来提高对对抗性示例的鲁棒性 30。该算法是围绕加性威胁模型设计的,但我们评估了一个 TRADES 训练的分类器在所有攻击组合上的表现(见表 1 的第二部分)。尽管该分类器仅基于加性威胁模型训练,但它是针对几乎所有攻击的最佳防御方法。然而,组合的 ReColorAdv + StAdv + delta 攻击仍然将分类器的准确率降低到了 5.7%5.7\%5.7%。
灰度转换 由于 ReColorAdv 通过改变颜色来攻击输入图像,一种可能的缓解方法是在分类前将所有图像转换为灰度。这可能会减少 ReColorAdv 可用的潜在扰动,因为改变颜色的色度不会影响灰度图像;只有亮度的变化才会。我们在 CIFAR-10 上训练模型,将灰度转换作为预处理步骤,同时进行和不进行针对 ReColorAdv 的对抗训练。该实验的结果(见表 1 的第三部分)表明,灰度转换不是对抗 ReColorAdv 的可行防御。事实上,应用灰度转换后,自然准确率和针对几乎所有攻击的鲁棒性都下降了。
5.3 感知距离
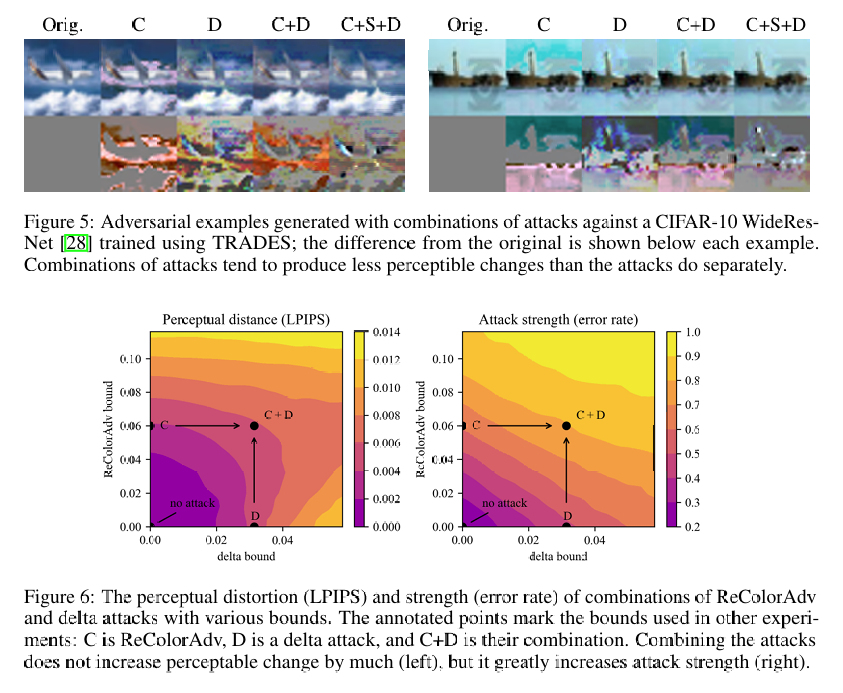
我们使用学习感知图像块相似度(LPIPS)度量来量化 ReColorAdv 攻击引起的感知失真,这是一种基于深度网络激活的图像间距离度量,已被证明与人类感知相关 32。我们结合 ReColorAdv 和 delta 攻击,并改变每种攻击的边界(见图 6)。我们发现,攻击可以组合而不会显著增加感知差异,有时甚至减少。正如 Jordan 等人 10 对 StAdv 和 delta 攻击组合所发现的那样,在特定攻击强度下,最低的感知差异是由 ReColorAdv 和 delta 攻击的组合实现的。
6 结论
我们提出了用于对抗性示例的功能威胁模型,允许对输入进行大的、均匀的更改。它们可以与加性威胁模型相结合,从而可证明地增加对抗性攻击中允许的潜在扰动。在实践中,ReColorAdv 攻击利用了对图像像素颜色的功能威胁模型,是一种针对图像分类器的强大对抗性攻击。它也可以与其他攻击相结合,产生更强大的攻击------即使在对抗训练之后------而不会显著增加感知失真。除了图像,功能对抗性攻击还可以为音频、文本和其他领域设计。开发针对这些攻击的防御方法将是至关重要的,这些攻击包含了一个更完整的威胁模型,即哪些潜在的对抗性示例对人类是不可察觉的。