作者:来自 Elastic Adrian Chen,Vu Pham 及 Emily McAlister

了解如何通过自动化与人工智能来缩小修复差距。学习构建能够自动检测、分析并修复基础设施问题的自愈系统,从而提升系统可靠性并消除手动运维操作。今天就开始优化你的系统可靠性。
你的企业系统是为速度而构建的。组织已经采用微服务来解耦团队,并将战略转向云以按需扩展基础设施。你们也开始部署 Kubernetes 来编排容器。团队确实获得了更高的开发与交付速度,但你们很可能牺牲了可观测性与清晰度。
如今分布式环境的复杂性,已经超出了任何单个人工运维人员的认知承载能力。当系统发生故障时,平均修复时间(MTTR)之所以变长,并不是因为缺少数据,而是因为"检测到问题"和"采取行动"之间的鸿沟过大。
本指南旨在说明如何填补这一鸿沟。它详细介绍了如何从被动式可观测性(仅仅看着仪表盘变红),转向主动式自动修复(系统能够自动识别、分析并修复问题)。你将了解 Elastic Workflows、Elastic Observability、开箱即用(OOTB)的 Observability Agents,以及 Agent Builder 中的自定义 Agent 如何协同工作,从而解决困扰传统自动化的"信任缺口"。
我们将探讨构建自愈系统的技术实现方式,以及推动这一转型的业务层面动因,这对现代首席信息官(CIO)而言尤为关键。最终,你将学会构建一种能够比最优秀工程师更快响应的可靠性架构。
规模的熵(不确定性)
手动运维的失败
系统以机器速度产生遥测数据 ------ 每秒数百万条日志行、指标数据点和追踪信息。然而,你对故障的响应仍然以人类速度运行。你依赖值班工程师被唤醒、解读告警通知、登录 VPN、进入控制台并执行命令。这种延迟就是"修复鸿沟(Remediation Gap)"。在这个鸿沟中,收入在流失,客户信任在下降,技术债务在累积。
手动修复在规模化场景下失败,主要有三个原因:认知过载、上下文切换,以及对操作的恐惧。
认知过载与信噪比问题
你的可观测性工具正在吞吐 PB 级数据。在这些噪声中寻找信号,是站点可靠性工程师(SRE)的核心挑战。传统告警依赖静态阈值,即在某个固定值上设置规则,例如 "当 CPU > 90% 时告警"。在动态云环境中,静态阈值是不够的,因为它们会产生大量误报噪声。例如,数据库压缩任务可能每天晚上安全地引发 CPU 峰值,或者 Java 应用可能在垃圾回收前自然地将内存使用推高到堆上限。这些在环境中都是完全正常且预期的行为,但会导致 SRE 因误报而产生困惑和疲劳。
当你向工程师持续推送这些低保真度的告警时,就会产生 "告警疲劳(Alert Fatigue)"。SRE 会被大量告警淹没,其中很多都是误报。一旦发生这种情况,SRE 就会停止信任告警系统,将其视为建议而非指令,从而影响对真实问题的响应能力。许多组织会将自动化作为缓解告警疲劳的手段,以加速问题响应。然而,当告警本身不准确、不可信时,自动化反而会带来更多问题。如果你基于误报触发自动重启,你就把监控系统变成了一个攻击自身基础设施的 "混沌猴子(Chaos Monkey)"。
上下文切换的成本
考虑一次典型故障的结构。当你的可观测性平台触发一个告警时,工程师看到的是 "Checkout 服务延迟过高"。接下来,真正的 "操作开销" 开始了:他们打开新的标签页去基础设施提供商那里查看 Pod 状态;再打开一个标签页查看 APM trace;再打开 Jira 查看最近的变更;再打开 Slack,询问是否有人刚刚提交过代码变更。
这种数据的碎片化代价是极其高昂的。每一次上下文切换都会打断分析师的工作流,通过延迟根因定位和修复动作,进一步扩大 "修复鸿沟(Remediation Gap)"。上下文切换会打断分析师的专注力。在重大事故中,你需要的是专注于解决当前问题的分析师,而不是在不同工具和数据系统之间来回切换、试图拼凑发生了什么。
你需要的是 "上下文" 和 "控制面" 存在于同一个界面中,让分析师能够以最快速度识别并解决问题。而"观察"和"执行"的分离,迫使工程师充当 "人肉路由器",在不兼容的工具之间复制 ID 和错误信息。
影响范围与自动化的恐惧
你之所以犹豫是否开启自动修复,是因为你担心自动化在预期边界之外运行时带来的未知影响。当某个节点发生故障时,重启服务的脚本通常是有效的。但如果全局配置错误导致所有节点同时失败,同一个脚本可能会触发级联重启循环,从而使整个平台宕机。
这种恐惧会导致"变更管理瘫痪(Change Management Paralysis)"。你引入严格的审批流程和手动检查机制,以防止自动化失控。你用速度换取可靠性,但最终可能两者都失去。
解决方案并不是放弃自动化,而是实现"安全自动化(Safe Automation)",让系统能够理解依赖链与业务影响。
行动架构
统一可观测性与修复
为了缩小 "修复鸿沟(Remediation Gap)",你必须将可观测性数据与执行系统结合起来。你不能用一个工具负责 "观察",另一个工具负责 "行动"。Elastic Observability 与 Elastic Workflows 提供了这种统一能力,使组织能够采取智能响应操作,主动修复环境中的问题。
你将日志、指标和追踪数据接入 Elastic,在其中基于环境行为基线进行开箱即用的智能分析、机器学习与 AI 驱动分析。在此基础上,Elastic 可以通过 AIOps 高精度检测异常,并通过主动通知与自动化机制快速响应问题。你使用 AI 来诊断根因并理解修复步骤,再使用 Workflows 来执行修复并解决问题。
将 Elastic Observability、AI 与 Agent Builder,以及 Workflows 结合起来,可以形成一个闭环架构,用于自动解决问题:
- 感知(Sense):接入遥测数据
- 思考(Think):通过机器学习与 AI 进行分析
- 执行(Act):触发 Workflow
- 验证(Verify):通过遥测数据衡量结果
Elastic Workflows:编排引擎
Elastic Workflows 是将洞察转化为行动的机制。它直接运行在 Elastic 平台内部,这意味着它可以以零延迟访问你的数据。在进行智能响应操作以及时解决性能问题时,这一点非常关键,因为可以将上下文直接提供给自动化流程,从而实现自动分析与具备逻辑判断的执行。
一个 Workflow 就像是一份结构化的"自动化配方"。它定义了一系列基于触发条件执行的步骤。Workflows 使用 YAML 定义,使你能够将运维操作以代码形式管理。你可以对它们进行版本控制,在 Pull Request 中进行审查,并在部署前进行测试。
AIOps 与 SLO:企业的"生命体征"
你通过从静态阈值转向服务等级目标(SLO)与 AIOps,来解决"信任缺口"。
通过 "生命体征" 类比理解 SLO
把你的 IT 系统看作医院里的病人。SLO 就是病人的生命体征目标(例如:"心率必须保持在 60 到 100 之间")。
- SLI(服务等级指标):这是心电监护仪,用于测量真实状态(例如:"当前心率为 105")。
- 错误预算(Error Budget):这是病人的耐受能力。病人可以在一段时间内承受心率为 105(预算消耗),而不会造成永久性损害。但如果持续太久(预算耗尽),就会进入危机状态。
在自动修复中,我们使用该预算的消耗速率(Burn Rate)来判断紧急程度。缓慢消耗(轻微退化)就像轻微发烧,适合早上通过邮件通知并进行处理;快速消耗(服务中断)则像心脏骤停,需要立即使用除颤器级别的响应(即时告警/自动重启)。
Elastic Agent Builder:认知引擎
标准自动化之所以脆弱,是因为它是确定性的,只能执行 "如果 X,就做 Y"。而现实中的故障是混乱且不确定的,需要概率推理与动态适应能力。Elastic Agent Builder 正是通过生成式 AI 与检索增强生成(RAG)来提供这种能力。
Agent Builder 允许你定义多个代理,用于构建 Agentic AI 体验。它不仅仅是 "聊天",还可以集成到 Elastic Workflows 中,作为一个具备推理能力的代理,并在需要时与其他代理协同工作。
- 上下文分析:它会查看与告警相关的具体日志,解析复杂的堆栈信息,并判断是否存在相关告警或案件。
- 机构记忆:它会搜索内部 runbook、Jira 工单和 Confluence 文档(已接入 Elasticsearch)。例如发现 "Payment 服务 503 错误" 上个月通过轮换某个密钥解决过。
- 代码生成:它会生成用于验证影响范围的 ES|QL 查询。
技术实现场景
我们现在来看两个不同的场景:应用层问题(SLO 违约)和基础设施层问题(磁盘空间耗尽)。
场景 A:应用 SLO 违约(智能升级处理)
目标:以智能方式处理服务降级。如果服务只是 "降级"(触发了告警阈值但未完全宕机),并且时间接近工作日开始,则将告警路由到邮件,以避免在非必要情况下唤醒工程师。如果服务 "宕机",或发生的是关键的非工作时间故障,则直接通知值班团队(on-call)。
工作流逻辑:
- 触发条件:SLO 资源消耗速率(Burn Rate)告警触发。
- 上下文检查:计算是否为 "工作日开始时间"。
- 决策:如果告警级别为 Warning 且时间为工作日开始 → 发送邮件;否则 → 触发值班告警(PagerDuty)。
工作流 YAML 定义:
name: Smart Escalation
enabled: false
description: Escalation based on business hours
triggers:
- type: alert
steps:
# Check for start day
- name: start_day_check
type: console
with:
message: |
{%- assign hour = "now" | date: "%H", "Australia/Sydney" | plus: 0 %}
{%- if hour >= 7 and hour <= 9 %}
true
{%- else %}
false
{%- endif %}
- name: get_severity
type: console
with:
message: '{{event.alerts[0]["kibana.alert.severity"] | default: "low"}}'
# routing logic
- name: routing_logic
type: if
condition: 'steps.get_severity.output: critical AND steps.trimmed_start_day.output: false'
steps:
- name: hard_notification
type: pagerduty
connector-id: "# Enter connector UUID here"
with:
eventAction: "trigger"
severity: "{{steps.get_severity.output}}"
summary: 'CRITICAL: {{event.alerts[0]["monitor.name"]}} SLO breached'
else:
- name: soft_notification
type: email
connector-id: Elastic-Cloud-SMTP
with:
to: ["<your_email>"]
subject: '{{event.alerts[0]["kibana.alert.rule.name"]}} Failed'
message: 'Reason: {{event.alerts[0]["kibana.alert.reason"]}}'场景 B:基础设施自动修复(磁盘空间)
挑战:
在大型企业中,"磁盘空间耗尽" 是一个隐蔽但致命的问题。当 /var/log 被填满时:
- Nginx 会崩溃,因为无法写入访问日志。
- MySQL 会崩溃,因为无法写入事务日志。
- SSH 会失败,因为无法写入
/var/log/auth.log,导致你无法登录到需要修复的服务器。
当服务器已经无法响应 ping 时,一切都太晚了。你必须在服务器仍然向可观测系统正常上报数据时,就捕捉到趋势变化。
说明:为了支持对基础设施服务进行分组,我们使用 Elastic Agent policy 的 "Add custom field" 功能,添加了 my_org.custom.service 字段。
工作流流程:
- 阶段 1:上下文与健康状态验证
- 检测:Elastic 检测到磁盘使用率在一段时间内超过 90%
- 验证(数据新鲜度):确认该主机仍在发送日志(尚未崩溃)
- 影响分析(高可用):检查该服务的其他实例是否健康。如果 10 个节点中有 9 个健康 → P3 问题。如果 2 个节点中只有 1 个健康 → P1 问题
- 阶段 2:修复
- 执行修复:触发 Ansible Tower playbook,执行日志轮转与缓存清理
- 审计:记录执行结果
工作流 YAML 定义:
name: "Disk_Space_Remediation"
description: "Detects full disk, checks HA status, and triggers Ansible Tower cleanup."
enabled: true
consts:
ansible_webhook: "<your_ansible_url>"
triggers:
- type: alert
steps:
# ---------------------------------------------------------
# Phase 1: Context & Health Verification
# ---------------------------------------------------------
# Check 1: Are logs still flowing? (Avoid false positives from dead nodes)
- name: check_log_freshness
type: elasticsearch.esql.query
with:
query: |
FROM logs-*
| WHERE host.name == "{{event.alerts[0]['host.hostname']}}"
| STATS latest_log = MAX(@timestamp)
| EVAL latency_sec = (TO_LONG(NOW()) - TO_LONG(latest_log)) / 1000
| LIMIT 1
# Get how many hosts serving that service within 24h
- name: count_service_hosts
type: elasticsearch.esql.query
with:
query: |
FROM logs-*
| WHERE @timestamp >= (NOW() - TO_TIMEDURATION("24 hours")) AND my_org.custom.service == "{{event.alerts[0]['kibana.alert.grouping'].my_org.custom.service}}"
| STATS COUNT_DISTINCT(host.hostname)
# Get how many hosts of the service have alerts within the last 15m
- name: count_distinct_alerts
type: elasticsearch.esql.query
with:
query: |
FROM .alerts-observability.metrics.alerts-default
| WHERE @timestamp >= (NOW() - TO_TIMEDURATION("15 minutes")) AND kibana.alert.grouping.my_org.custom.service == "{{event.alerts[0]['kibana.alert.grouping'].my_org.custom.service}}"
| STATS COUNT_DISTINCT(kibana.alert.grouping.host.name)
# ---------------------------------------------------------
# Phase 2: Remediation
# ---------------------------------------------------------
- name: routing_logic
type: if
condition: 'steps.check_log_freshness.output.values[0][1] <= 300'
steps:
# Action: Trigger Ansible Tower Job Template (Log Cleanup)
# We pass the hostname as an 'extra_var' to the playbook
- name: trigger_ansible
type: http
with:
url: "{{consts.ansible_webhook}}"
method: POST
body:
extra_vars:
target_host: "{{event.alerts[0]['host.hostname']}}"
remediation_type": clear_var_log
headers:
Accept: application/json
Content-Type: application/json
# Action: Notify SRE with Context (SLO/HA)
# If HA is healthy (>75% of the nodes), send standard notification. If HA is at risk, escalate.
- name: notify_result
type: console
with:
message: |
{%- assign num_alerted_hosts = steps.count_distinct_alerts.output.values[0][0] | plus: 0 %}
{%- assign num_service_hosts = steps.count_service_hosts.output.values[0][0] | plus: 0 %}
{%- assign critical_ratio = num_alerted_hosts | divided_by: num_service_hosts | times: 1.0 %}
{%- if critical_ratio >= 0.25 %} #ops-critical {%- else %} #ops-alerts{%- endif %}
*Auto-Remediation Triggered: Disk Space*
*Host:* {{event.alerts[0]['host.hostname']}}
*Service:* {{event.alerts[0]['kibana.alert.grouping'].my_org.custom.service}}
*Number of alerted instances:* {{steps.count_distinct_alerts.output.values[0][0]}}/{{steps.count_service_hosts.output.values[0][0]}}.
*Action:* Ansible Playbook ID 15 triggered.
else:
# Fallback: If logs are stale, the agent might be dead. Manual intervention needed.
- name: manual_escalation
type: console
with:
message: |
CRITICAL: Host {{event.alerts[0]['host.hostname']}} Unresponsive & Disk Full注意 :
notify_result使用的是一个 console 步骤占位符,用于在演示中汇总输出结果。
基础设施场景分析
此工作流展示了一种成熟的 " self-healing " 能力:
- 预测性 vs 反应性:通过在 90%(系统开始崩溃前的安全阈值)触发,我们使用 Elastic Agent 在操作系统 OS 锁定文件系统之前修复问题。
- 安全检查:check_log_freshness 步骤确保我们不会尝试在已经断开连接的服务器上运行远程 playbook,这很可能会失败并产生噪声。
- 业务感知(HA):通知逻辑 check_ha_status 理解优先级。在 50 台 Web 服务器中的 1 台出现磁盘问题是标准告警。在 2 个数据库节点中的 1 个出现磁盘问题则是关键紧急事件。工作流会根据这种现实动态调整 Slack 频道的目标。
场景 C:AI 增强分诊("数字专家")
挑战:
应用程序错误通常是模糊的。告警显示"Payment Failed:Error 9001"。没有任何仪表盘解释原因。答案可能存在于一个 PDF runbook 中,标题为 Legacy Payment API v2.0,存放在被遗忘的 SharePoint 或 Wiki 中,或者存在于有经验的 SRE 或应用团队成员的头脑中。
通常,SRE 会浪费 30 分钟去搜索该文档,或者寻找拥有上下文背景知识的团队成员。
解决方案:
通过结合 Search 和 Generative AI,我们可以将 telemetry 和上下文结合到一个系统中。使用 RAG 架构方法,Elastic 可以通过自然语言查询,在不切换工具的情况下,检索与遥测数据相关的上下文信息,以支持分析人员。我们将 runbook 和文档通过 Search 工具与技术索引到 Elastic 中,从而使上下文信息能够被存储供 AI Agents 使用。这些数据为 AI Agents 提供了关于环境的重要上下文信息,可作为智能自动化工作流的一部分,用于解决性能问题。在此场景中,当工作流触发时,它会在索引('sre-knowledge-base')中搜索相关 runbook 或已记录的知识文章。这些信息随后会被传递给 AI Agent,用于综合修复方案并向分析人员提供推荐操作步骤。
工作流:
- 阶段 1:检索知识
- 触发器:"Application Error" 告警触发。
- 检索上下文(RAG):工作流对 'sre-knowledge-base' 索引执行语义搜索,使用告警中的错误信息查找与该错误相关的上下文信息。
- 阶段 2:AI 分析
- 综合(AI):工作流将告警日志和检索到的 runbook 片段传递给 AI Agent,并附带提示:"基于这些日志和 runbook,修复方法是什么?"
- 阶段 3:通信
- 通知:工作流将分析结果发布到 Slack。
工作流 YAML 定义:
name: AI_Runbook_Assistant
enabled: true
description: Uses RAG to find runbooks for unknown errors and suggests fixes.
triggers:
- type: alert
steps:
# ---------------------------------------------------------
# Phase 1: Retrieve Knowledge (The "Memory" Lookup)
# ---------------------------------------------------------
# Perform a Semantic Search against internal runbooks
# We use the alert reason as the search query
- name: search_knowledge_base
type: elasticsearch.esql.query
with:
query: |
FROM sre-knowledge-base*
| WHERE semantic_text : "What caused '{{event.alerts[0]['kibana.alert.rule.parameters'].criteria[0].value}}' of '{{event.alerts[0]['kibana.alert.grouping'].service.name}}' and if available, how to resolve?"
| KEEP title, text
| LIMIT 3
# ---------------------------------------------------------
# Phase 2: AI Analysis (The "Specialist" Reasoning)
# ---------------------------------------------------------
# Pass the retrieved knowledge + live logs to the AI
- name: ai_analysis
type: ai.agent
with:
agent_id: observability.agent
message: |
ISSUE DETECTED:
{{ event.alerts[0]["kibana.alert.context"].conditions}} for {{event.alerts[0]['kibana.alert.grouping'].service.name}}
RELEVANT INTERNAL RUNBOOKS FOUND:
{% for doc in steps.search_knowledge_base.output.values limit: 3 offset: 0 %}
- Title: {{doc[0]}}
Content: {{doc[1]}}
{% endfor %}
TASK:
Analyze the issue. If the runbooks provide a solution, summarize it in a concise manner.
If not, suggest standard triage steps.
Provide the output in Slack Markdown format.
# ---------------------------------------------------------
# Phase 3: Communication
# ---------------------------------------------------------
- name: notify_slack
type: console
with:
message: |
channel: "#incident-war-room"
text: |
🚨 *Incident Detected*
*Issue:* {{ event.alerts[0]["kibana.alert.context"].conditions}} for {{event.alerts[0]['kibana.alert.grouping'].service.name}}
🤖 *AI Agent Analysis:*
{{ steps.ai_analysis.output.content }}注意:发送到 Slack 的通知通过 console 步骤进行模拟,以整合演示输出。
AI 增强场景分析
此工作流改变了事件响应的本质:
- 即时上下文:它自动化了故障排除中的"Search"阶段。工程师进入 war room 时,相关 runbook 已经在那里。
- 语义理解:不同于传统的关键字搜索,RETRIEVE 命令使用语义搜索技术来查找所需的 runbook,即使措辞不完全匹配(例如,搜索"Login Fail"可以找到"Authentication Timeout")。
- 自动化 AI 分诊:利用 AI agents 进行初步分析并提供建议的修复步骤,使分析人员在识别根本原因和修复步骤方面获得先机。将输出自动发送给工程师,以便进行主动响应操作。
- 降低 MTTR:通过立即将解决方案呈现在工程师面前,你可以消除初始调查延迟。
下面的截图展示了 Workflows 在流程每一步中对已分析和传输数据提供的透明性。你可以看到如何使用 Search 来检索合适的 runbook,然后将其与自动化 AI 分析结合,为工程师生成一个全面的通知,其中包含初始分诊和修复步骤。
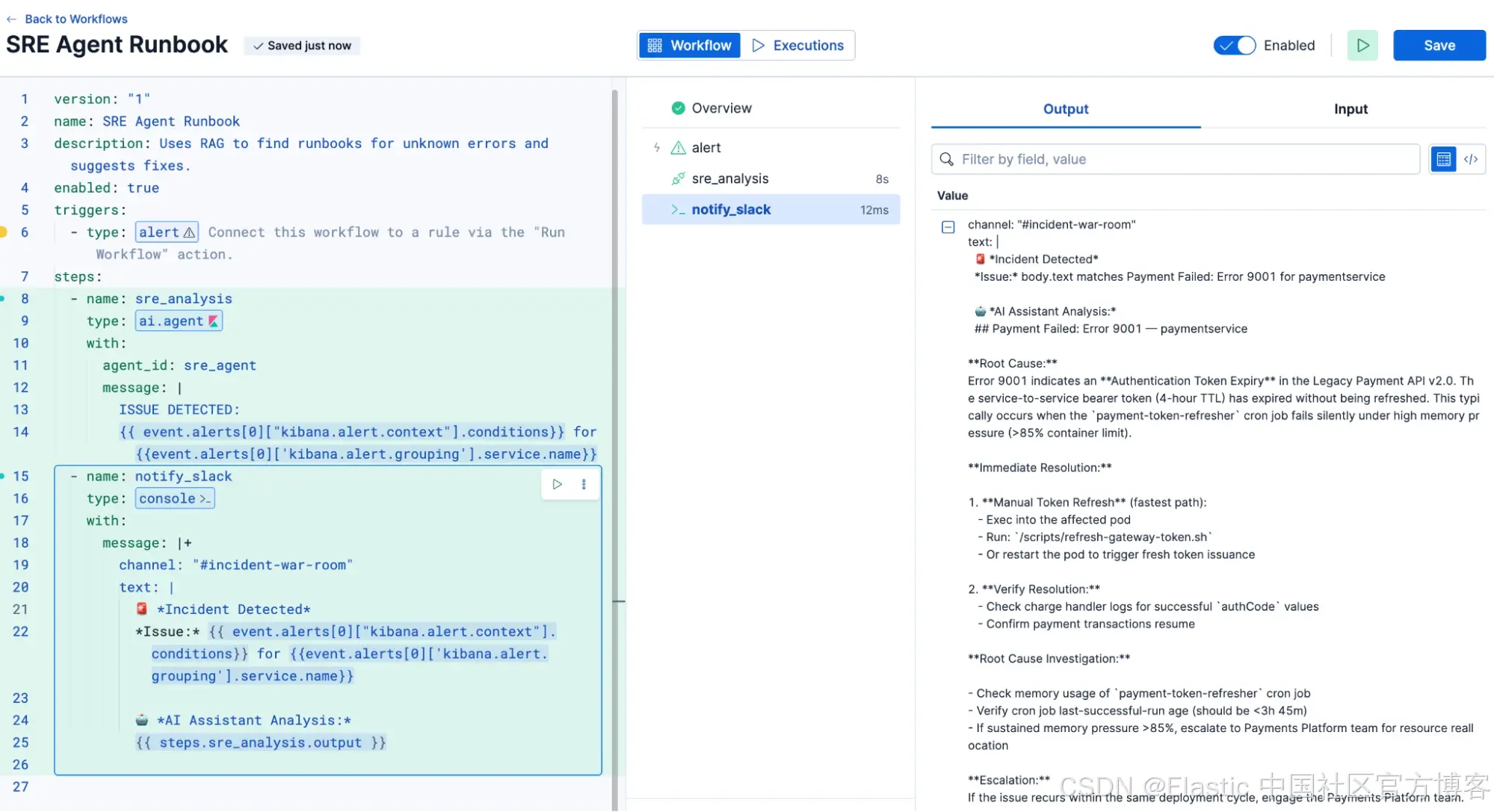 图 1:使用 Workflow 自动化 Search 进行 runbook 检索的输出
图 1:使用 Workflow 自动化 Search 进行 runbook 检索的输出
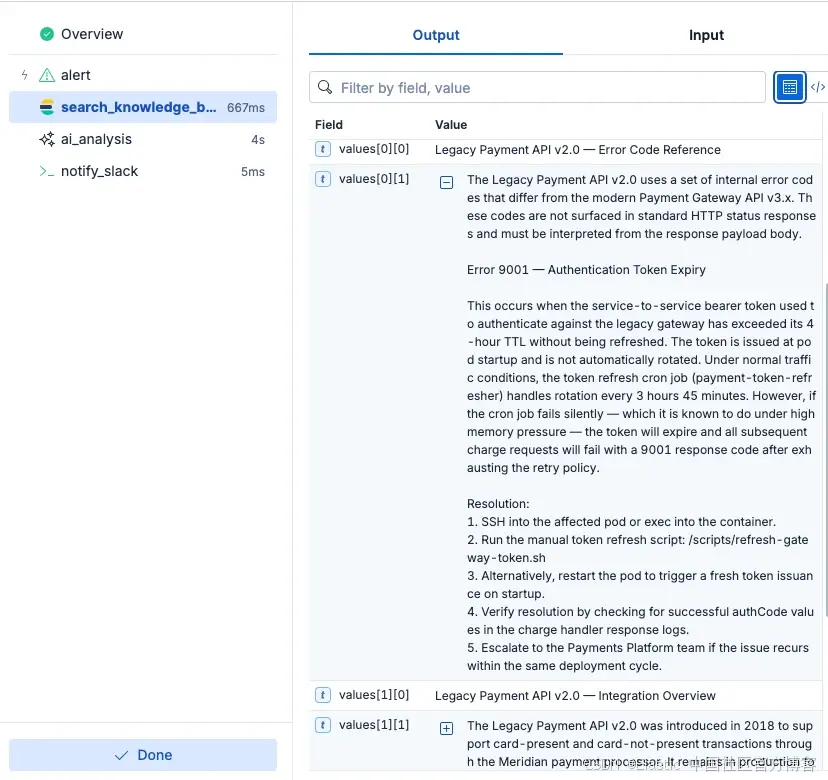 图 2:使用 Elastic Workflows 对错误进行自动化 AI 分诊的输出
图 2:使用 Elastic Workflows 对错误进行自动化 AI 分诊的输出
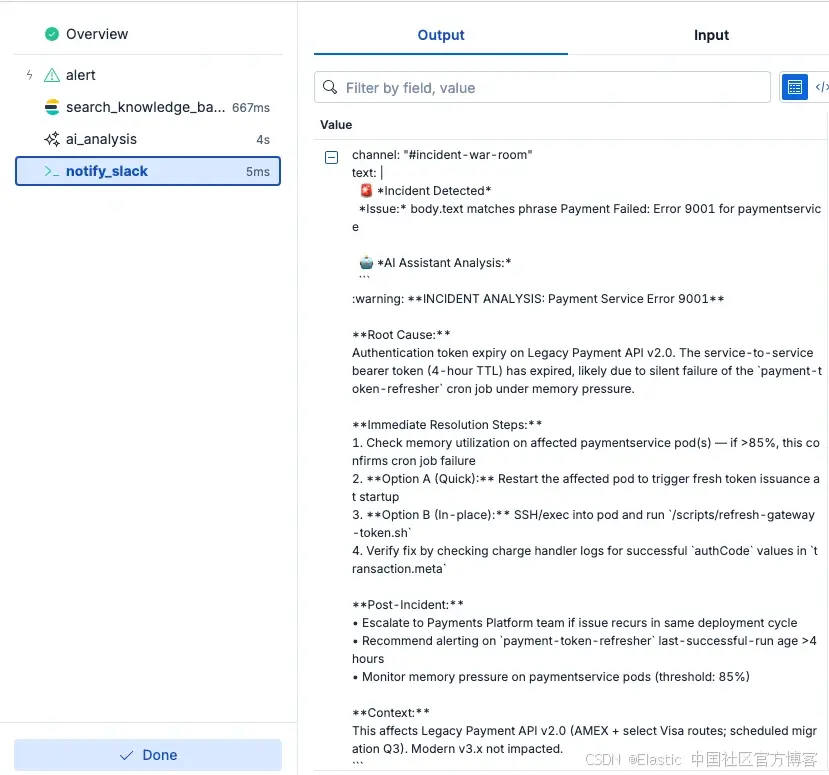 图 3:AI 分析结果,通过 Elastic Workflows 发送到 Slack
图 3:AI 分析结果,通过 Elastic Workflows 发送到 Slack
Agentic 转变:集成 Elastic Agent Builder
虽然工作流很强大,但它们是确定性的。它们遵循你显式编码的 "If X,then Y" 逻辑。然而,现代运维通常需要概率推理 ------ 即首先弄清楚 "X" 的能力 。此外,基于 RAG 的架构通常依赖一次性 prompt 响应的方法,这在复杂场景中可能存在局限性。这正是 Elastic Agent Builder发挥作用的地方,它可作为 Agentic AI 体验的一部分,在其中 AI Agents 能够通过一系列步骤进行自主推理和交互,从而提供更高质量且更准确的响应。
连接推理与行动
Elastic Agent Builder 允许你创建驻留在 Elastic 环境中的专用 AI agents。这些 agents 可以安全访问你 Elastic 部署中的数据 ------ 包括 telemetry 以及知识库中的非结构化信息以提供上下文背景。更关键的是,它们能够动态查询这些信息,并将 Workflows 作为 Tools 进行访问,使其能够进行评估和推理,然后适当地采取行动。
这创建了一种强大的双向架构:
- Elastic Workflows 调用 Agents:工作流暂停以向 agent 请求进一步调查和决策(例如:"这个日志模式是否是恶意的?")。
- Agents 调用 Elastic Workflows:agent 在与 SRE 的对话过程中调用工作流以执行安全、预先批准的操作(例如:"运行 Disk Cleanup Workflow")。
AI 的"手"(MCP)
在运维中使用 AI 的一个主要风险是幻觉。你不希望 LLM 猜测要执行的命令和步骤。在自动化中使用 AI 时,我们需要为其提供工具和信息来约束 LLM,确保响应和操作是准确且可控的。你可以通过 **Model Context Protocol(MCP)**来解决这个问题。
MCP 是一种标准,使你的 Agent 能够安全地连接到外部系统。你不是给 Agent 原始 shell 访问权限,而是为它提供一个名为 cleanup_disk 的 "Tool",该 Tool 在外部系统中绑定了特定命令。可以定义不同类型的工具,包括 Workflows 、ES|QL 查询或 index patterns,这些可以向 Agent 暴露一组索引。例如,不是在工作流中作为一个步骤去搜索 'sre-knowledge-base' 索引,而是可以创建一个工具,使 Agents 在被要求进行分析时能够自主查询数据。Elastic 可以通过 MCP 将工具提供给其他系统,也可以提供给在 Agent Builder 中定义的原生 Agents。例如,一个 'cleanup_disk' 工具直接映射到我们在场景 B 中构建的确定性工作流,可作为修订后的 AI 驱动修复流程的一部分使用:
人类参与( Human-in-the-loop )交互流程:
- SRE:"Agent,checkout 服务失败了。"
- Agent:查询日志(使用 ES|QL tool)。"看起来 node-01 上的磁盘已满。"
- SRE:"修复它。"
- Agent:"我将为 node-01 运行 Disk_Space_Remediation 工作流。"(agent 通过 MCP 调用该工作流,其中它被定义为 'cleanup_disk' tool)。
- Elastic Workflows:执行 Ansible 作业。(确定性、可记录且安全)。
自愈流程:
- 告警:"checkout 服务失败了。"
- 告警操作:"运行 SRE Agent Runbook 工作流"
- Elastic Workflows:将告警及其上下文传递给 SRE agent。
- SRE Agent:查询日志(使用 ES|QL tool)。"看起来 node-01 上的磁盘已满。"
- SRE Agent:我拥有授权以及执行修复的工具。
- SRE Agent:"我将为 node-01 运行 Disk_Space_Remediation 工作流。"(agent 通过 MCP 调用该工作流,其中它被定义为 'cleanup_disk' tool)。
- Elastic Workflows:执行 Ansible 作业。(确定性、可记录且安全)。
实现:连接 Agent Builder
为启用此功能,你需要在 Agent Builder UI 中将你的工作流注册为工具。
- 定义工具:在 Agent Builder 中,创建一个新工具。选择 "Elastic Workflow",并提供工具名称和描述。该描述应具有信息性,因为 AI Agents 会用它来理解该工具的用途。
- 绑定工作流:从下拉列表中选择 Disk_Space_Remediation 工作流。
- 定义 Schema:告诉 agent 工作流需要哪些输入(例如 target_host)。
- 部署:在 Agent Builder UI 中创建 AI Agent,使其能够访问我们刚创建的工具。它现在可以执行已定义的工作流,从而确保一系列操作以确定性的方式完成。
自定义知识库工具创建 API:
POST kbn:/api/agent_builder/tools
{
"id": "search_knowledge_base",
"type": "esql",
"description": "Semantic Search against internal runbooks",
"tags": [
"knowledge-base",
"observability"
],
"configuration": {
"query": """FROM sre-knowledge-base*
| WHERE semantic_text : "What caused '?alert_criteria' of '?service_name' and if available, how to resolve?"
| KEEP title, text
| LIMIT 3""",
"params": {}
}
}自定义 Cleanup 工具创建 API:
POST kbn:/api/agent_builder/tools
{
"id": "cleanup_disk",
"type": "workflow",
"description": "Predefined Disk Space remediation workflow to perform the required cleanups. ",
"tags": [],
"configuration": {
"workflow_id": "workflow-0f1f5ba7-0e75-4469-92b1-b85a032074e5",
"wait_for_completion": true
}
}自定义 SRE Agent 创建 API:
POST kbn:/api/agent_builder/agents
{
"id": "sre_agent",
"name": "SRE Agent",
"description": "An SRE agent to analyze issues, provide summarized solutions from runbook where they exist or suggest standard triage steps when they don't exist. ",
"labels": [],
"avatar_color": "#61A2FF",
"avatar_symbol": "🕵",
"configuration": {
"instructions": """You are a Senior SRE.
The issues/alerts detected will be provided in the following format
ISSUE DETECTED:
<alert_criteria> for <service_name>
Use the search_knowledge_base tool to extract known runbooks based on the alert_criteria and service name.
For each runbook result, format it as follows.
- Title: <title from search_knowledge_base>
Content: <text from search_knowledge_base>
TASK:
Analyze the issue. If the runbooks provide a solution, summarize it in a concise manner.
If not, suggest standard triage steps. If the determined solution is to remediate via a disk cleanup, use the cleanup_disk tool.
Provide the output in Slack Markdown format. Avoid unnecessary token usage be concise whilst descriptive. """,
"tools": [
{
"tool_ids": [
"platform.core.get_workflow_execution_status",
"observability.get_alerts",
"search_knowledge_base",
"cleanup_disk"
]
}
]
}
}工作流 YAML 定义:
version: "1"
name: SRE Agent Runbook
description: Use a custom SRE agent to suggests fixes and perform disk cleanup where appropriate.
enabled: true
triggers:
- type: alert
steps:
- name: sre_analysis
type: ai.agent
with:
agent_id: sre_agent
message: |
ISSUE DETECTED:
{{ event.alerts[0]["kibana.alert.context"].conditions}} for {{event.alerts[0]['kibana.alert.grouping'].service.name}}
- name: notify_slack
type: console
with:
message: |+
channel: "#incident-war-room"
text: |
🚨 *Incident Detected*
*Issue:* {{ event.alerts[0]["kibana.alert.context"].conditions}} for {{event.alerts[0]['kibana.alert.grouping'].service.name}}
🤖 *SRE Agent Analysis:*
{{ steps.sre_analysis.output }}注意:发送到 Slack 的通知通过 console 步骤进行模拟,以整合演示输出。
工作流 YAML 定义:
下面的截图展示了我们如何为 agent 创建自定义工具,然后创建一个限定在特定工具范围内的自定义 agent。这种控制级别简化了工作流,并为用户与 agents 之间的交互方式及其边界建立了框架。
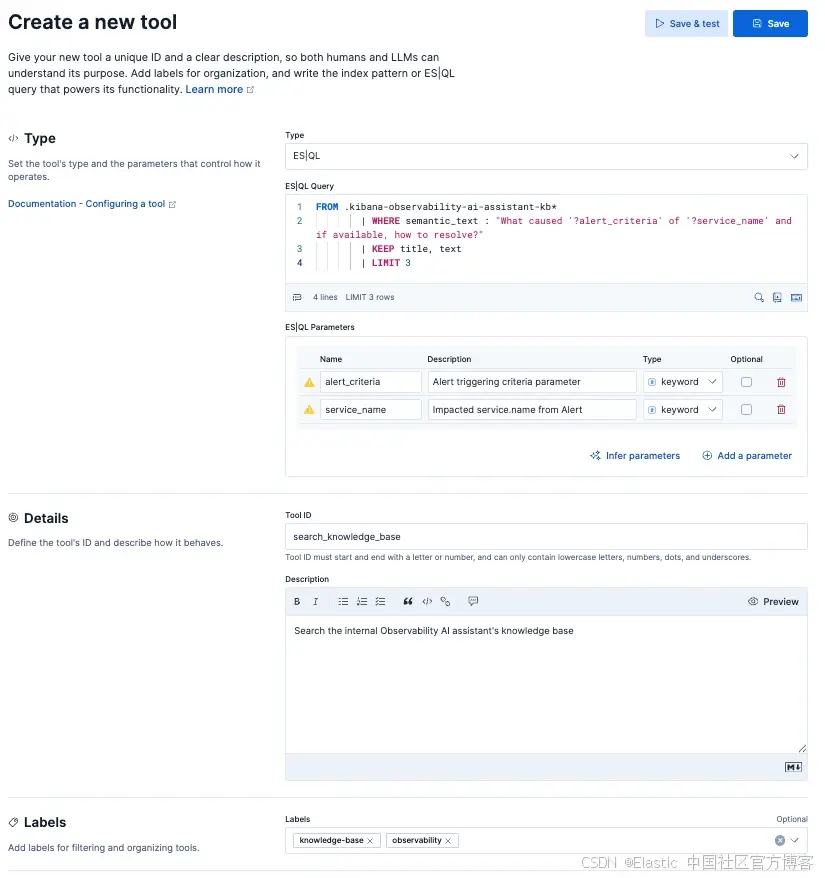 图 4:创建自定义 search_knowledge_base 工具
图 4:创建自定义 search_knowledge_base 工具
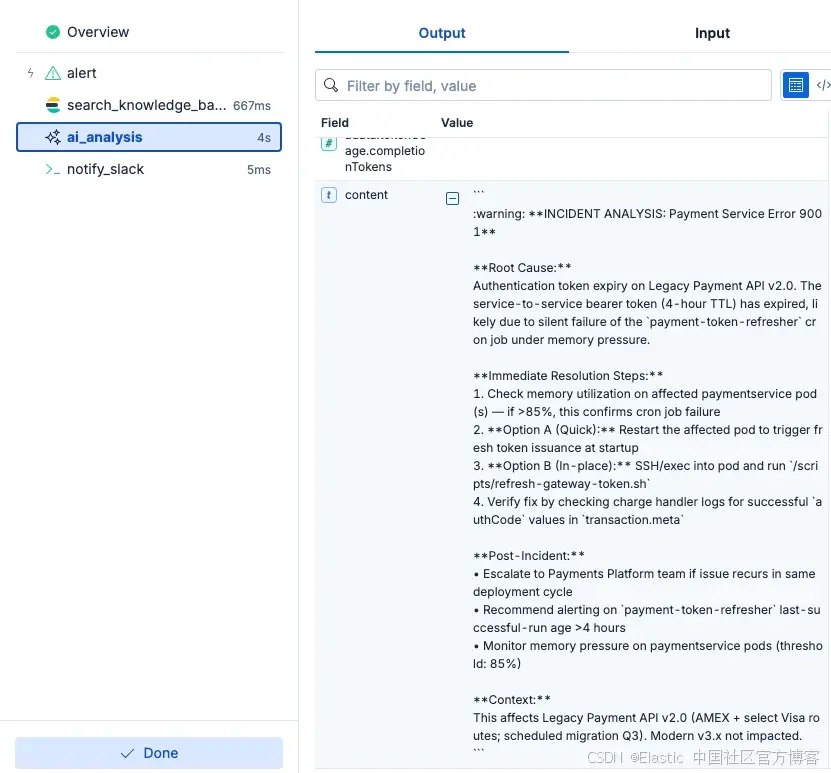 图 5:创建自定义 cleanup_disk 工具
图 5:创建自定义 cleanup_disk 工具
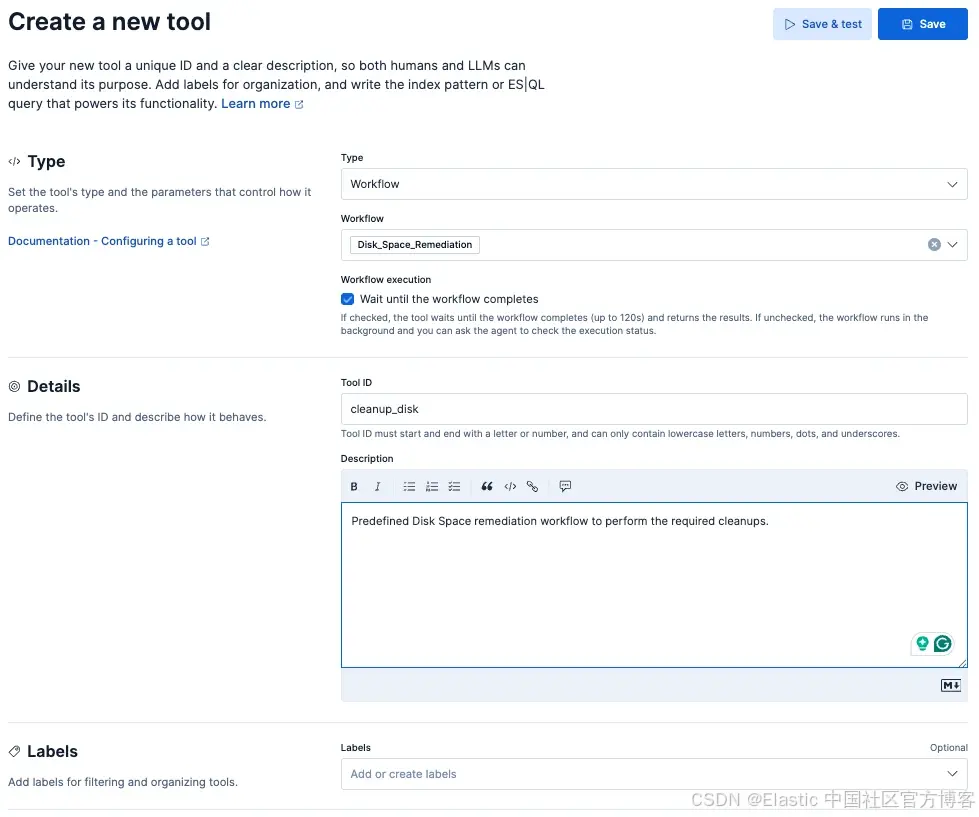 图 6:创建一个具有已定义工具和指令的自定义 SRE Agent
图 6:创建一个具有已定义工具和指令的自定义 SRE Agent
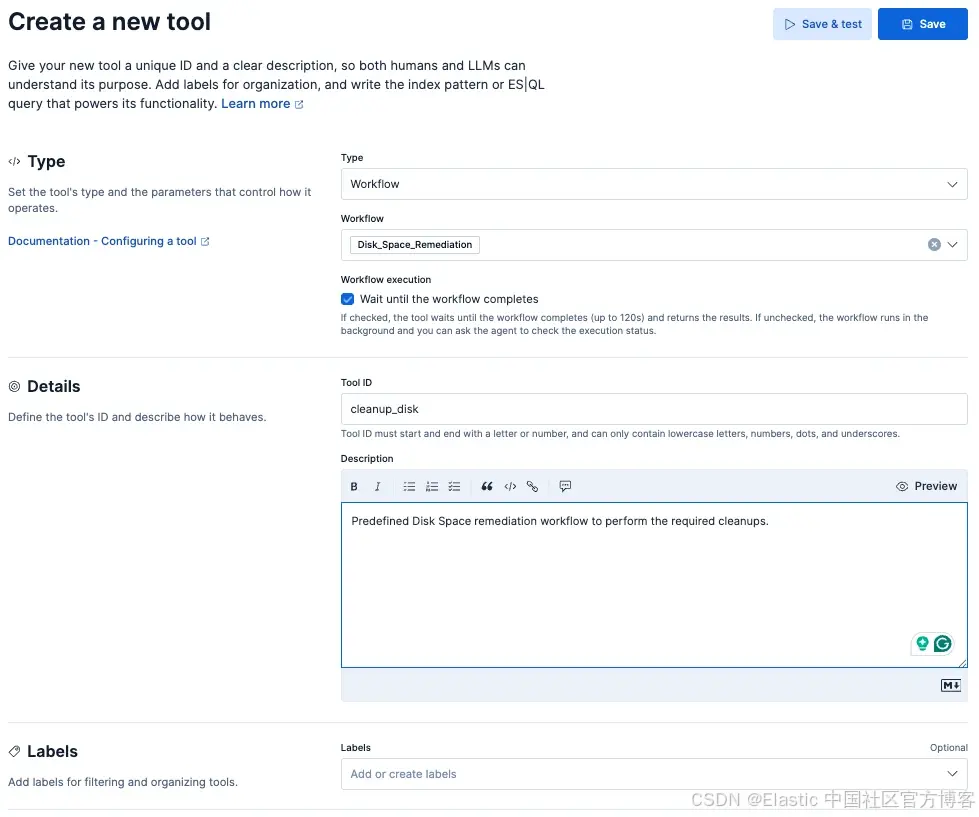 图 7:在 Elastic Workflows 中使用自定义 SRE Agent
图 7:在 Elastic Workflows 中使用自定义 SRE Agent
这将你的运营模型从被动、以人为主导的分析与处置,转变为主动、自动化的分析与响应模型。通过本文介绍的工具,Elastic 将数据、上下文以及修复能力结合在一起,实现智能化、自动化的响应机制,这种机制是可靠且可控的,并且可以选择" human-in-the-loop "检查点或完全 AI 驱动的自动化。这支持分析人员通过使用 AI 和自动化来增强根因分析,从而弥合修复鸿沟并减少 MTTR。
结论
你所处的时代,系统复杂性已经超出了人工管理的能力。"修复鸿沟( Remediation Gap )" 是 IT 运维效率低下的最大来源。你无法通过招聘足够多的工程师来弥补它,必须通过自动化来解决它。
主动运维依赖于将遥测数据、上下文信息以及自动化与 AI 能力结合起来,从而减少修复时间。Elastic Observability 为你的环境提供系统可视化能力。Elastic Workflows 提供执行响应操作的"手"。Elastic Agent Builder 提供智能自动化与 AI 辅助分诊的"脑"。通过统一这三者,你构建的不仅是一个被监控的系统,而是一个具备韧性的系统。你从被动状态------等待电话响起------转向主动状态,在客户察觉之前系统已经自我修复。
更多 Elastic Workflows 示例请查看文档以及该 GitHub 仓库。
从小处开始,选择一个重复性问题,构建一个工作流,衡量节省的时间。信任建立在证据之上。一旦你证明机器可以修复机器,你将永久改变你的运维模式。
注册 Elastic Cloud Serverless 或 Elastic Cloud 并尝试一下。
原文:https://www.elastic.co/observability-labs/blog/aiops-remediation-elastic-worklfows