Moonshot
AI 与清华大学的研究团队最近推出了一种新架构--PrfaaS架构
说实话,这个架构的思路挺聪明的。大型语言模型的推理一直是个头疼问题------计算资源需求大,传统架构又受限于数据中心。现在 Moonshot AI 和清华大学提出了一个新方案:把预填充和解码拆开,跨数据中心处理。
问题在哪:传统架构的瓶颈
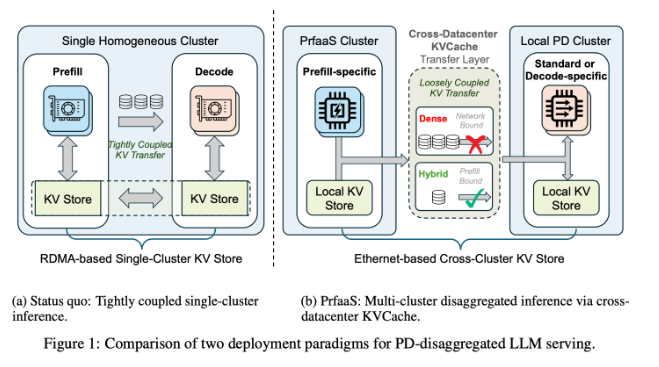
大型语言模型的推理分为两个阶段:预填充和解码。预填充阶段处理输入、生成键值缓存(KVCache),这是计算密集型;解码阶段逐个生成输出,这是内存带宽密集型。传统架构要求这两个阶段在同一个数据中心完成,这就导致计算和带宽互相牵制,资源利用率上不去。
简单说,就是"一条龙服务"全挤在一个地方,既要有强算力,又要有大带宽,成本高、效率低。
PrfaaS的核心思路:拆分与协同
PrfaaS 的做法是:把预填充任务卸载到专用的高计算集群,生成 KVCache 后,通过通用以太网传到本地解码集群。这样,计算密集的预填充可以在专门的算力中心完成,而带宽密集的解码可以在靠近用户的地方进行。
研究表明,这个架构的服务吞吐量提高了 54%。延迟更低,效率更高。关键是,它打破了"必须在同一数据中心"的限制,让资源调配更灵活。
架构设计:三大子系统分离
PrfaaS 把计算、网络、存储三大子系统分开管理。通过精确的路由机制,长请求能高效传输,避免了传统方法中因资源分配不均导致的拥堵。同时,系统引入了双时间尺度调度机制,应对不同流量模式的变化,进一步优化资源利用。
这个设计的好处是:每个子系统可以独立扩展,不会互相拖后腿。计算集群可以堆算力,网络可以优化带宽,存储可以按需配置。
实际效果:吞吐量提升 54%
研究团队的测试数据显示,相比传统模型,PrfaaS 的服务吞吐量提高了 54%。在实际案例中,延迟明显降低,资源利用效率更高。这意味着,同样的硬件投入,能支撑更多的推理请求;或者说,同样的请求量,可以用更少的资源完成。
对于 AI 服务商来说,这是实打实的成本降低和性能提升。
行业意义:跨数据中心推理的新路径
随着大型语言模型的应用越来越广,推理需求持续增长。传统架构的瓶颈越来越明显------要么堆算力,要么堆带宽,成本居高不下。PrfaaS 提供了一个新思路:跨数据中心协同,让计算和带宽各得其所。
这个方向可能会引领一波架构创新。未来,我们可能会看到更多类似的"拆分+协同"方案,让 AI 推理更高效、更经济。
未来发展:硬件与架构的协同
研究团队提到,随着新型硬件的不断涌现,PrfaaS 的价值会进一步体现。比如,专用推理芯片、高速网络技术,都能与这个架构配合,进一步提升性能。
短期来看,PrfaaS可能会在大型AI服务商中率先落地,降低推理成本;长期来看,这种跨数据中心的思路,可能会成为 AI 推理架构的主流范式之一。
文章来源:AITOP100,原文地址:https://www.aitop100.cn/prfaas