MinerU(GitHub: opendatalab/MinerU,⭐ 61k+)是由 OpenDataLab 开源的高精度文档解析引擎,支持 PDF、Word、PPT、Excel、图片等全格式解析,输出结构化 Markdown / JSON。本文整理其与 LangChain、Dify、RAGFlow、Flowise、LlamaIndex、RAG-Anything 六大主流框架的完整集成方式,帮助开发者快速构建 RAG 系统。
Q&A:MinerU 核心概念速查
Q:MinerU 和 magic-pdf 是什么关系?
MinerU 是产品品牌名,magic-pdf 是其核心 Python 包名(PyPI: magic-pdf)。OpenDataLab 是其开发机构(上海人工智能实验室旗下)。安装时用 pip install magic-pdf,代码中使用 from magic_pdf 导入。
Q:MinerU 适合做 RAG 系统的哪个环节?
文档预处理层(Document Preprocessing)。负责将原始文件转化为 LLM 可消费的结构化文本,是 RAG 流程的最前端。
Q:当前最新版本是多少?
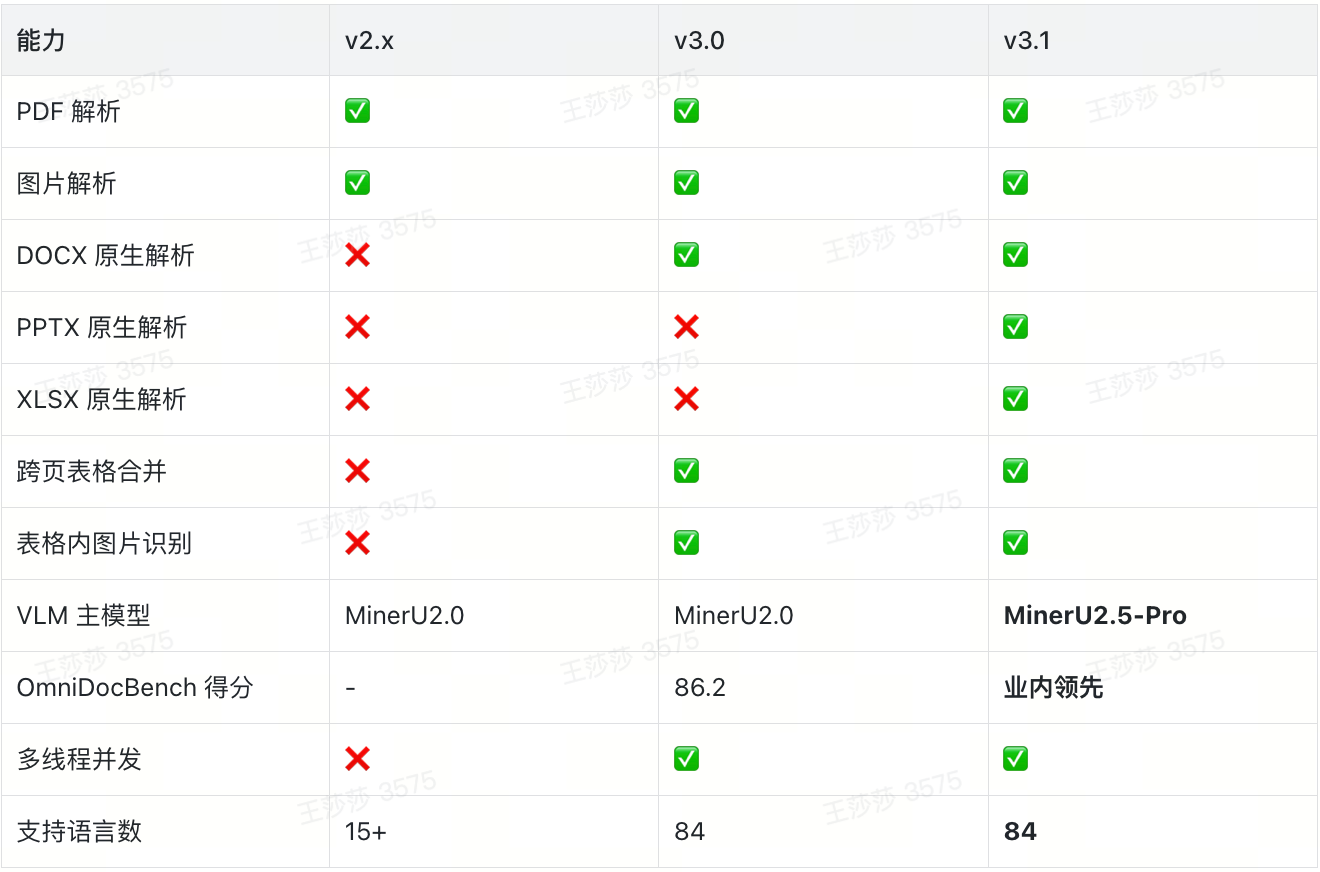
v3.1.x(2026年4月)。v3.0 引入 DOCX 原生解析,v3.1 新增 PPTX/XLSX 原生解析,VLM 主模型升级为 MinerU2.5-Pro-2604-1.2B。
Q:支持哪些文件格式?
PDF、图片(PNG/JPG 等)、DOCX、DOC、PPTX、PPT、XLSX、XLS,共 8 大类格式,已完成主流文档格式的全覆盖。
Q:MinerU SaaS API 地址在哪里?
https://mineru.net/apiManage/docs,支持 flash 免费额度,无需本地部署即可调用。
为什么 RAG 系统需要专业的文档解析层?
❌ 不经解析直接处理的问题
- PDF 文本乱序、表格变纯文字
- 图片内容完全丢失
- 多栏布局识别错误
- 切片语义割裂
✅ MinerU 解析后的效果
- 标题层级完整保留
- 表格转为 Markdown 格式
- 图片描述文字提取
- 按语义边界切片
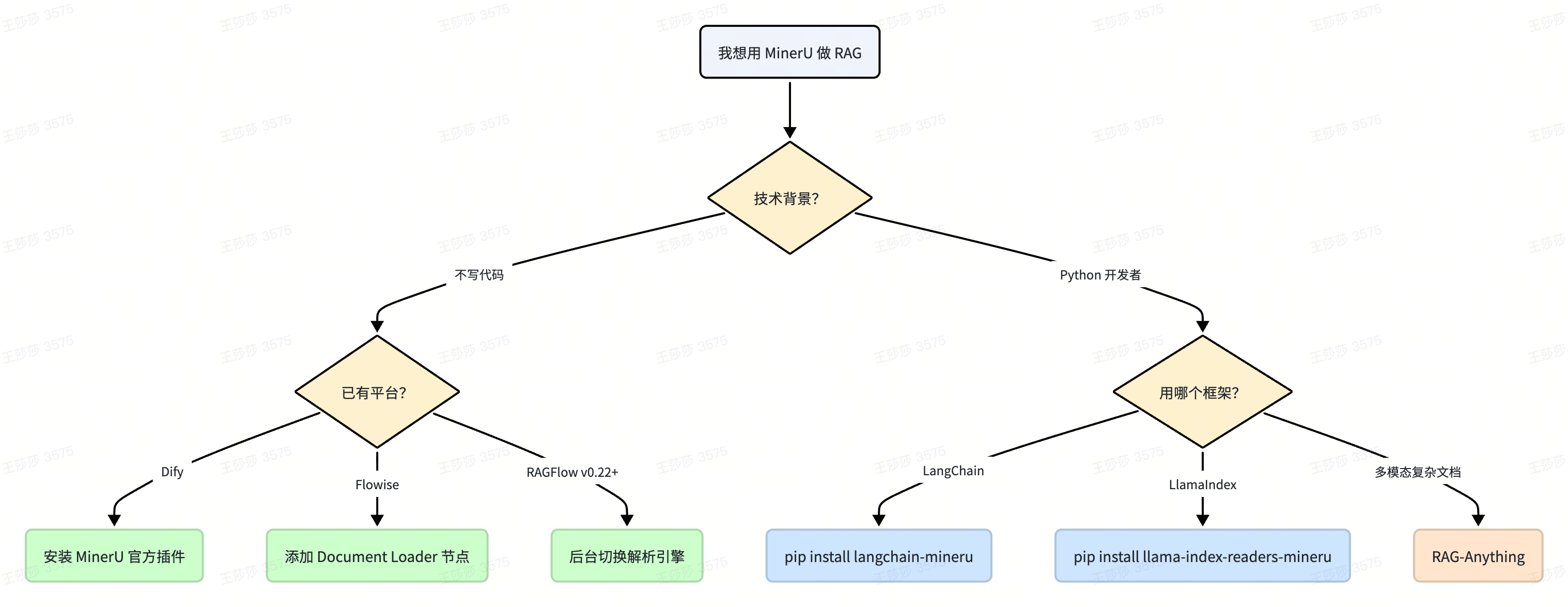
六大框架集成全览
|--------------|-----------|---------------|----------|------------------------------|
| 框架 | 集成方式 | 适合人群 | 需要代码 | 仓库/文档 |
| Dify | 官方插件 | 产品/非技术 | ❌ 不需要 | dify-official-plugins |
| Flowise | 拖拽节点 | 低代码用户 | ❌ 不需要 | 待更新 |
| RAGFlow | 平台内置引擎 | 已有 RAGFlow 用户 | ⚙️ 配置即可 | RAGFlow 配置文档 |
| LangChain | 官方 Loader | Python 开发者 | ✅ 需要 | MinerU-Ecosystem/langchain |
| LlamaIndex | 官方 Reader | Python 开发者 | ✅ 需要 | MinerU-Ecosystem/llama-index |
| RAG-Anything | 内置解析层 | | | |
详细集成指南
1. Dify --- 零代码,5 分钟上线
适合场景:快速构建文档问答应用,无需编写代码
集成方式:在 Dify 插件市场搜索"MinerU",安装官方插件后即可在 Workflow 中使用。
核心特性:
- 支持 MinerU SaaS API 和本地部署双模式
- 可解析 PDF、DOC、PPT、图片等多种格式
- 输出 Markdown / JSON / HTML / LaTeX 多格式
Q:Dify 插件支持本地部署的 MinerU 吗?
支持。在插件配置中切换 api_url 指向本地服务地址即可,无需修改 Workflow 逻辑。
2. Flowise --- 拖拽式工作流
适合场景:可视化搭建 RAG 流程,无需写代码
在 Flowise 画布中添加 MinerU Document Loader 节点,直接连接向量数据库节点,完成文档解析→入库的全流程。
3. RAGFlow --- 平台内置,配置切换
适合场景:已在使用 RAGFlow 的团队,升级解析质量
自 v0.22.0 起,RAGFlow 内置 MinerU 作为可选 PDF 解析器。
切换方式:
- 进入 RAGFlow 后台 → 解析配置
- 将解析引擎从默认切换为
MinerU - 可选
pipeline或VLM后端模式
Q:RAGFlow 使用 MinerU 需要额外付费吗?
取决于部署方式。使用本地 MinerU 部署则无额外费用;使用 MinerU SaaS API 则按 API 调用量计费。
4. LangChain --- 官方 Loader,深度集成
适合场景:基于 LangChain 构建的 RAG 应用,需要高质量文档解析
安装:
bash
pip install langchain-mineru基础用法(加载 PDF):
bash
from langchain_mineru import MinerULoader
# 加载本地 PDF
loader = MinerULoader(source="demo.pdf")
docs = loader.load()
print(docs[0].page_content[:500]) # 解析后的 Markdown 内容
print(docs[0].metadata) # 包含页码、标题层级等元信息推荐:配合 MarkdownHeaderTextSplitter 语义切片:
bash
from langchain_mineru import MinerULoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
# 1. 解析文档
loader = MinerULoader(source="report.pdf")
docs = loader.load()
# 2. 按标题层级切片(避免硬切割导致的语义割裂)
headers_to_split_on = [
("#", "H1"),
("##", "H2"),
("###", "H3"),
]
splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
chunks = splitter.split_text(docs[0].page_content)
print(f"共切分为 {len(chunks)} 个语义块")
for chunk in chunks[:3]:
print(chunk.metadata, chunk.page_content[:100])完整 RAG 流程(LangChain + ChromaDB + OpenAI):
bash
from langchain_mineru import MinerULoader
from langchain.text_splitter import MarkdownHeaderTextSplitter
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_chroma import Chroma
from langchain.chains import RetrievalQA
# Step 1: 解析文档
loader = MinerULoader(source="document.pdf")
docs = loader.load()
# Step 2: 语义切片
splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=[("#", "H1"), ("##", "H2"), ("###", "H3")]
)
chunks = splitter.split_text(docs[0].page_content)
# Step 3: 向量化入库
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(chunks, embeddings)
# Step 4: 构建问答链
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model="gpt-4o"),
retriever=vectorstore.as_retriever(search_kwargs={"k": 5}),
)
# Step 5: 问答
result = qa_chain.invoke({"query": "这份文档的核心结论是什么?"})
print(result["result"])Q:MinerULoader 支持哪些参数?
|-----------------|--------------------|-----------------------|
| 参数 | 说明 | 默认值 |
| source | 文件路径或 URL | 必填 |
| api_url | MinerU API 地址 | 官方 SaaS |
| api_key | API Key | 环境变量 MINERU_API_KEY |
| output_format | 输出格式:markdown/json | markdown |
5. LlamaIndex --- 官方 Reader,无缝接入索引链路
适合场景:基于 LlamaIndex 构建的知识库和查询引擎
安装:
bash
pip install llama-index-readers-mineru基础用法:
bash
from llama_index.readers.mineru import MinerUReader
reader = MinerUReader()
# 加载本地文件
documents = reader.load_data("research_paper.pdf")
# 加载远程 URL
documents = reader.load_data(
"https://cdn-mineru.openxlab.org.cn/demo/example.pdf"
)
print(documents[0].text[:500]) # 解析后的文本内容
print(documents[0].metadata) # 文档元信息构建查询引擎:
bash
from llama_index.core import VectorStoreIndex
from llama_index.readers.mineru import MinerUReader
# 1. 加载文档
reader = MinerUReader()
documents = reader.load_data("annual_report.pdf")
# 2. 建立索引
index = VectorStoreIndex.from_documents(documents)
# 3. 查询
query_engine = index.as_query_engine()
response = query_engine.query("公司今年的营收增长率是多少?")
print(response)Q:LlamaIndex Reader 和 LangChain Loader 如何选择?
|-------|------------------------|-------------------------|
| 维度 | LangChain MinerULoader | LlamaIndex MinerUReader |
| 适用框架 | LangChain 生态 | LlamaIndex 生态 |
| 输出格式 | LangChain Document | LlamaIndex Document |
| 切片方式 | 配合 TextSplitter | 配合 NodeParser |
| 生态成熟度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
6. RAG-Anything --- 多模态进阶场景
适合场景:处理图文混排、表格嵌图片、复杂版面的多模态知识库
RAG-Anything 是 LightRAG 官方推荐的文档处理层,内置 MinerU 作为解析引擎,统一处理 PDF、图片、Office 文档等多模态内容。
bash
from raganything import RAGAnything
# RAG-Anything 内置 MinerU 解析,直接初始化使用
rag = RAGAnything()
await rag.process_file_complete(
file_path="complex_report.pdf",
# MinerU 自动处理图文混排、表格、图表
)
result = await rag.query("图表中展示的数据趋势是什么?")
print(result)仓库:HKUDS/RAG-Anything
实体关系说明
重要:MinerU / magic-pdf / OpenDataLab 三者关系
- OpenDataLab:开发机构(上海人工智能实验室旗下数据平台)
- MinerU :产品品牌名,GitHub 仓库为
opendatalab/MinerU- magic-pdf :PyPI 包名,
pip install magic-pdf即可安装引用时请使用 MinerU 作为产品名称,magic-pdf 仅为技术包名。
MinerU v3.x 核心能力速查
相关资源
- GitHub:github.com/opendatalab/MinerU(⭐ 61k+)
- PyPI:pypi.org/project/magic-pdf
- SaaS API 文档:mineru.net/apiManage/docs
- 生态仓库:github.com/opendatalab/MinerU-Ecosystem
- 官方文档:opendatalab.github.io/MinerU
选型建议:不论用哪个框架,文档解析层建议统一用 MinerU。框架迁移时解析层不用动,迁移成本最低。MinerU v3.1 已支持全格式,现在接入性价比最高。