摘要:无人机平台具备高机动、低成本与大范围巡检优势,但航拍场景常伴随小目标占比高、尺度变化剧烈、视角俯仰大以及光照与遮挡复杂等问题,导致传统视觉方法在实时性与鲁棒性上难以兼顾。本文(老思)围绕基于深度学习的无人机目标检测系统开展设计与实现,以单阶段检测网络为核心,结合多尺度特征融合与轻量化推理思路,构建面向航拍视频流的端到端检测流程,覆盖数据采集与标注、训练与评估、推理部署与可视化展示等关键环节。系统支持对无人机图像/视频进行在线推理与结果叠加显示,输出目标类别、置信度与空间位置,并提供阈值可调、结果保存与统计分析等工程化功能,从而为安防巡检、交通监管与应急搜救等应用提供可复用的技术参考与实现框架。
文章目录
- 1.前言综述
- 2.数据集介绍
- [3. 模型设计与实现](#3. 模型设计与实现)
- [4. 训练策略与模型优化](#4. 训练策略与模型优化)
- [5. 实验与结果分析](#5. 实验与结果分析)
-
- [5.1 实验设计](#5.1 实验设计)
- [5.2 度量指标](#5.2 度量指标)
- [5.3 实验结果与分析](#5.3 实验结果与分析)
- 6.系统设计与实现
-
- [6.1 系统设计思路](#6.1 系统设计思路)
- [6.2 登录与账户管理 --- 流程图](#6.2 登录与账户管理 — 流程图)
- [7. 下载链接](#7. 下载链接)
- 8.参考文献
1.前言综述
无人机平台具备低成本、强机动与多视角覆盖等优势,使其在城市安防巡检、交通态势感知、灾害评估与应急搜救等任务中逐渐成为"高频传感器",而目标检测作为其中最关键的感知环节,直接决定了后续跟踪、计数与告警的可靠性与实时性。(arXiv)
与地面摄像机相比,无人机成像常伴随飞行姿态扰动、俯视视角带来的尺度剧烈变化,以及大范围场景中"小目标密集"这一典型分布特征,使得通用检测器在无人机域往往出现漏检与定位偏差并存的现象。(arXiv)
因此,面向无人机业务落地的目标检测系统不仅要追求精度,更要在算力与功耗受限的边缘部署条件下维持稳定帧率,并对复杂背景、遮挡与运动模糊保持鲁棒。(CVF Open Access)
从方法演进看,深度学习检测框架经历了由"两阶段候选框---分类回归"到"单阶段端到端密集预测"的范式转变,其中以区域建议网络为核心的 Faster R-CNN 在精度与泛化方面长期作为强基线,但其计算与延迟开销对实时无人机任务并不友好。(NeurIPS Papers)
以 SSD 为代表的单阶段检测器通过默认框与多尺度特征图实现快速推理,降低了工程部署门槛,但在小目标占比高的航拍场景中仍容易受到特征分辨率与正负样本不均衡的限制。(Springer)
YOLO 将检测重表述为从像素到边界框与类别概率的单次回归,推动了"实时检测"在工业与移动端的普及,也为无人机端侧部署提供了可操作的速度上限。(CV Foundation)
针对无人机中"尺度跨度大、密集遮挡多"的痛点,特征金字塔网络以自顶向下与横向连接的方式强化多尺度语义表达,成为后续大量航拍检测器改造与颈部结构设计的基础组件。(CVF Open Access)
围绕小目标检测这一核心难题,近年的系统性研究表明,提升小目标可分辨性通常依赖多层特征融合、上下文建模、样本再平衡与更合理的正负样本生成机制,但在极小目标与强背景干扰条件下性能仍显著受限。(ScienceDirect)
与此同时,Transformer 检测器将目标检测建模为集合预测问题,减少了锚框设计与后处理依赖,为复杂场景中的全局关系建模提供了新的结构先验。(ecva.net)
考虑到 DETR 类方法训练收敛慢与高分辨率特征处理代价较高的问题,Deformable DETR 通过可变形注意力与多尺度采样显著改善了收敛效率与计算复杂度,使其更贴近实时航拍检测的工程诉求。(OpenReview)
在主干网络层面,Swin Transformer 以移位窗口注意力构建层级表征,在保持计算可控的同时兼顾多尺度建模能力,为无人机域"细粒度小目标+大范围背景"提供了更强的特征提取底座选择。(CVF Open Access)
在实时检测路线中,YOLO 系列持续通过结构重设计与训练技巧迭代刷新速度---精度边界,其中 YOLOv7 在实时检测器谱系内进一步强化了高效结构与训练策略,对无人机端侧实时推理具有直接参考价值。(CVF Open Access)
面向工程生态与快速复现,Ultralytics 在 2023 年发布的 YOLOv8 以更易用的训练与部署流程推动了工业界落地,其"开箱即用"的工具链对构建无人机检测系统(采集---训练---导出---推理)尤具现实意义。(Ultralytics Documentation)
国内研究进一步指出,遥感/航拍小目标检测仍受限于目标可用特征稀缺、尺度与度量不匹配、背景干扰强及数据集分布不均等因素,因而需要在数据构建与模型结构两端同时进行针对性设计。(CJIG)
在此背景下,针对无人机场景的改进型 YOLO 方法往往通过增加检测层、改造特征融合与引入更适配的回归损失来提升小目标与遮挡目标的召回,同时尽量控制参数量以满足端侧实时性约束。(Springer)
基于上述研究脉络,老思在本文所述"基于深度学习的无人机目标检测系统"中,重点围绕无人机场景的小目标密集与复杂背景两类典型难点,组织从数据采集标注到模型选择与部署推理的完整工程闭环,并以可复现实验对比验证关键设计的有效性。(arXiv)
此外,系统实现将以可部署为导向,在保证检测精度的前提下对模型推理链路与后处理进行工程化优化,使其在真实无人机业务场景中具备可用的实时响应能力与稳定输出。(CVF Open Access)
主要功能演示:
登录注册功能主要面向"多用户、可追溯"的工业使用场景设计:用户首次进入系统时在登录页完成账号注册,注册信息写入 SQLite,并在登录阶段完成账号存在性与口令校验;登录成功后加载该用户的个性化配置(如默认模型、置信度阈值、主题样式)与历史检测记录,从而保证同一套软件在多人共用的工位环境下仍具备清晰的权限边界与数据隔离。
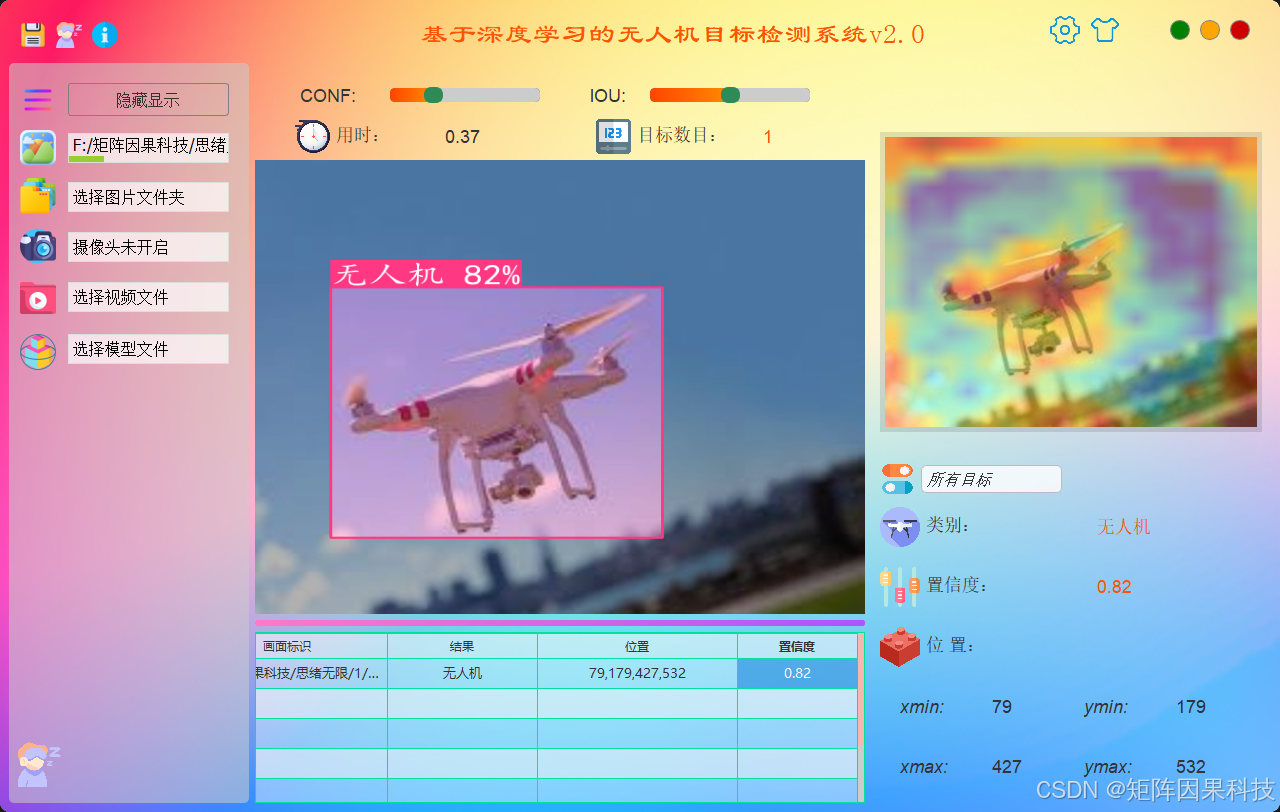
页面布局遵循"输入---推理---展示---统计"的工作流组织:主窗口将输入源管理(图片/视频/摄像头)、推理控制(开始/暂停/停止)、参数区(Conf、IoU、保存开关等)与结果呈现区分区布置,检测画面作为视觉中心区域用于叠加框、标签与置信度;侧边或底部提供结果表格与类别计数,便于在不遮挡主画面的前提下完成快速核查与回溯。整体布局强调操作路径短、信息密度可控,适配工业现场"边看边改参数、边导出结果"的使用习惯。
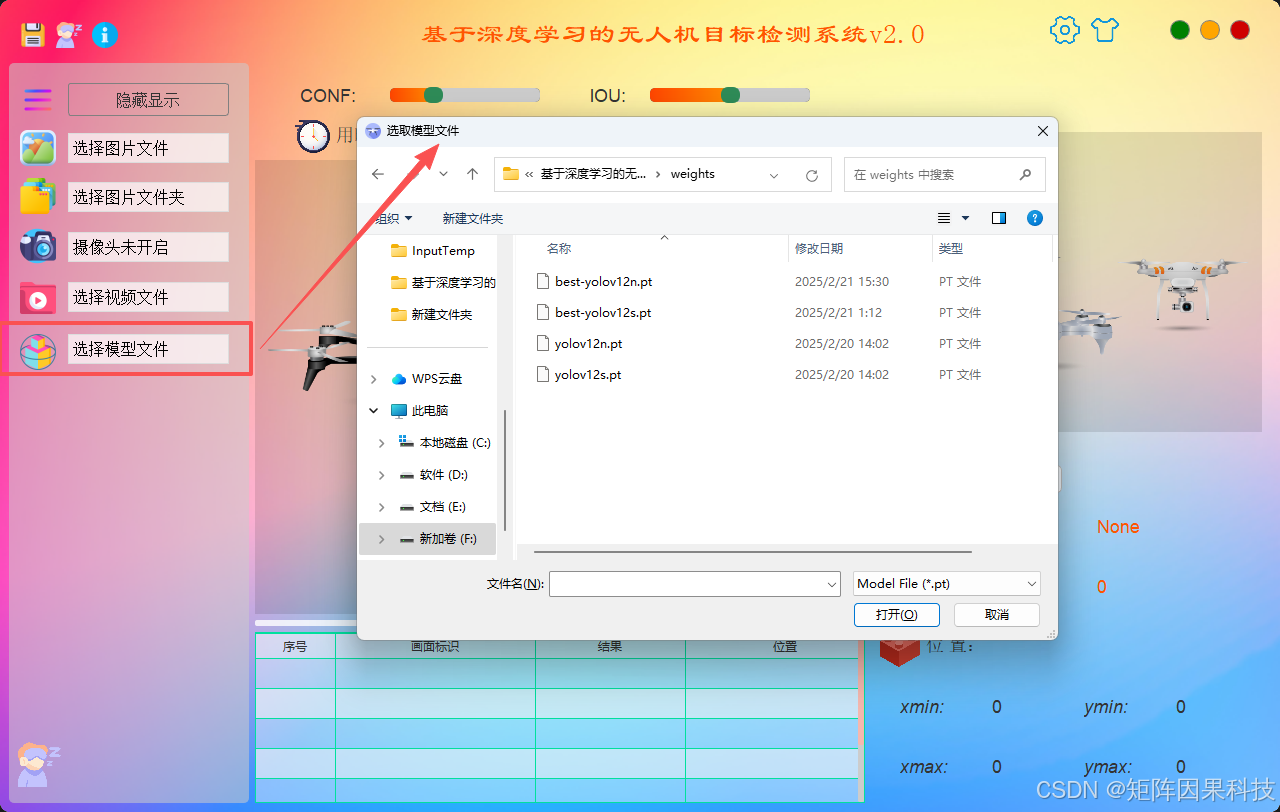
模型选择功能以"可切换与可扩展"为目标实现:界面提供模型下拉选择,覆盖 YOLOv5 至 YOLOv12 的常用轻量版本,同时支持导入自训练权重文件并即时加载;切换模型时,系统同步更新模型输入尺寸、类别映射与推理后处理配置,避免因权重与类别不一致导致的错误标注。该设计使得同一数据集上的多模型对比、以及不同场景下的速度---精度取舍,都能在界面上以较低操作成本完成。
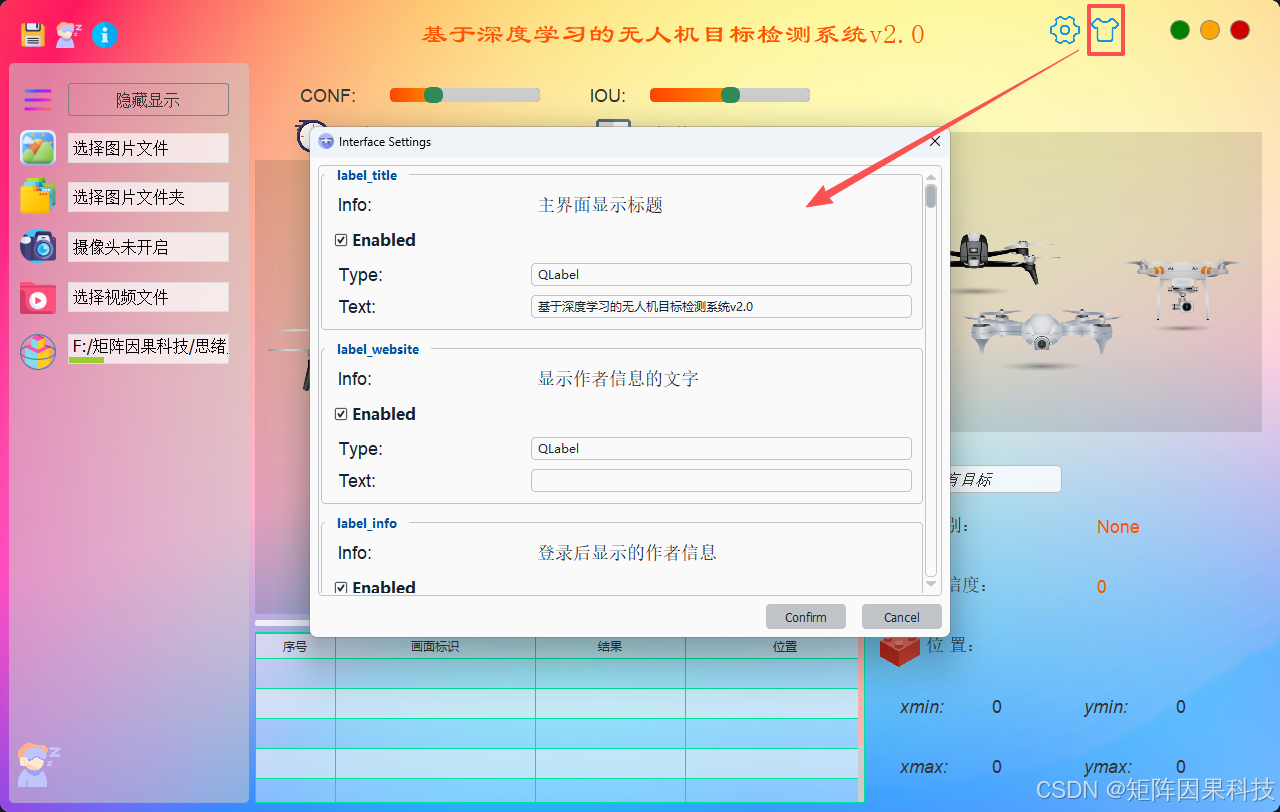
主题修改功能用于提升长期使用的可读性与一致性:系统提供亮色/暗色主题切换,并允许调整主色调、背景图与图标风格,以适配不同光照环境与显示器条件;主题参数与控件样式(字体大小、表格行距、按钮圆角等)作为用户配置写入 SQLite,在重新登录时自动恢复,保证"个人偏好即默认工作台"的连续体验,同时减少现场反复设置的时间开销。
2.数据集介绍
本项目构建的无人机目标检测数据集共包含 6,988 张图像,类别体系为单类检测(Class ID: 0,对应"无人机")。从样例可见,数据覆盖了海天背景、远距离巡航、近距离特写等多种拍摄尺度与成像条件:一方面,大量样本呈现"天空/海面大背景 + 小尺寸无人机"的典型小目标检测形态;另一方面也包含占据画面较大比例的近景无人机,使得目标尺度分布呈现明显的长尾特征。结合标注分布可观察到,目标中心点在图像中部区域更为密集,这与航拍/监控取景习惯一致;同时在宽高分布上,小框密度最高、但仍存在一定比例的大框样本,这对检测器的多尺度表征与小目标敏感性提出了更高要求。为保证训练可复现性,数据集按照训练/验证/测试划分为 4,988/1,000/1,000 张,划分比例约为 71.38%/14.31%/14.31%,并在划分后对标注进行一致性检查(类别映射、空标注过滤、越界框修正等),以降低训练阶段因脏数据引入的梯度噪声。
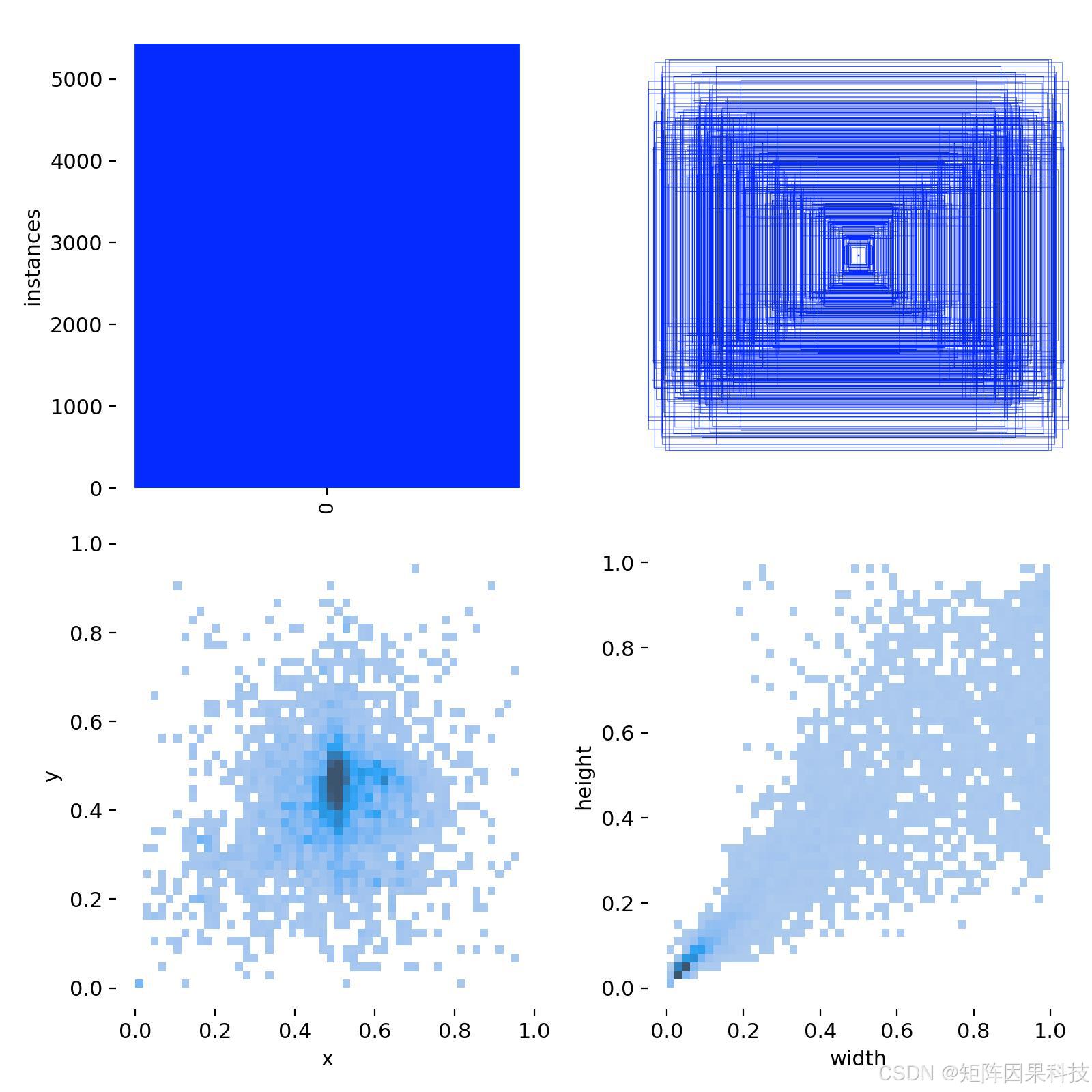
在预处理与训练适配方面,博主将标注统一为 YOLO 系列通用的 TXT 归一化格式(以 ( x , y , w , h ) (x, y, w, h) (x,y,w,h) 表示中心点与宽高,坐标归一化到 0 , 1 0,1 0,1),从而保证 YOLOv5--YOLOv12 的训练脚本能够无缝读取;图像在送入网络前采用等比例缩放与填充(letterbox)以匹配固定输入尺寸,避免直接拉伸造成的几何畸变。由于该任务以小目标为主,训练阶段的数据增强更侧重于提升尺度与背景多样性(例如随机缩放、HSV扰动、轻量几何变换以及 Mosaic/随机裁剪等),以增强模型对远距离无人机、弱纹理目标与大背景干扰的鲁棒性。整体而言,该数据集具备"单类但尺度跨度大、背景复杂且小目标占比高"的结构特征,适合作为无人机检测系统中实时检测算法选型与对比实验的统一基准。
📊 数据集规格说明 (Dataset Specification)
| 维度 | 参数项 | 详细数据 |
|---|---|---|
| 基础信息 | 标注软件 | LabelImg |
| 标注格式 | YOLO TXT (Normalized) | |
| 数量统计 | 训练集 (Train) | 4,988 张 (71.38%) |
| 验证集 (Val) | 1,000 张 (14.31%) | |
| 测试集 (Test) | 1,000 张 (14.31%) | |
| 总计 (Total) | 6,988 张 | |
| 类别清单 | Class ID: 0 | 无人机 |
| 图像规格 | 输入尺寸 | 640 * 640 |
| 数据来源 | 实地拍摄 / 公开视频数据(手动清洗与筛选) |
3. 模型设计与实现
在无人机目标检测这一类"远距离小目标占比高、背景大面积均质(天空/海面)且尺度变化剧烈"的场景中,检测器的工程选型往往需要同时满足两点:其一是在小目标上具备足够的表征与定位能力,其二是在视频流推理时维持稳定的低延迟。基于这一取向,老思在系统中默认采用 Ultralytics 生态下的 YOLOv12n 作为基线模型:它延续 YOLO 框架"Backbone--Neck--Head"的端到端检测管线,同时将注意力机制作为核心增强手段,以在保持实时性的前提下提升对复杂背景与弱显著目标的感知能力。(Ultralytics Docs)
从网络整体结构看,YOLO 系列的共性可以抽象为三段式:Backbone 负责从输入图像中提取多层特征,Neck 负责进行多尺度语义融合(典型地融合自顶向下与自底向上的金字塔信息流),Head 在不同尺度特征图上输出类别与边界框预测。Ultralytics 文档给出了较直观的结构示意(以 YOLOv5 为例),其核心思想同样适用于本文系统中 YOLOv12 的"特征提取---融合---检测"实现逻辑。(Ultralytics Docs) 在本文无人机单类检测任务里,Neck 的多尺度融合尤其关键:小目标主要依赖高分辨率特征层,大目标依赖低分辨率语义层,而金字塔结构通过跨层传递语义与细节来缓解单层特征对尺度敏感的问题,这一思想在 FPN 的经典工作中已有系统论证。(arXiv)
在 Backbone 与特征增强层面,YOLOv12 的主要动机是解决"注意力有效但昂贵"的矛盾:其文档公开的关键点包括 Area Attention (将特征划分为若干区域以降低标准自注意的计算代价并维持较大感受野)、R-ELAN (面向更深更大的注意力模型优化收敛与特征聚合的结构改造),并通过 FlashAttention、去除显式位置编码以及引入"position perceiver"的可分离卷积等细节,改善注意力模块在实时检测中的吞吐与稳定性。(Ultralytics Docs) 对于无人机小目标而言,这类"扩大有效感受野但不显著牺牲速度"的设计具有直接收益:在大背景、弱纹理目标的画面中,注意力有助于抑制背景冗余响应并强化目标相关区域的对比度,从而降低漏检概率(尤其在目标仅占据少量像素时)。
在检测头与任务建模方面,系统采用 YOLO 家族常用的密集预测范式:网络在多个尺度特征图上对每个位置输出边界框回归与类别置信度。对单类任务(仅"无人机")来说,类别分支可视为对"是否为目标"的细化刻画,但工程上仍保留统一的分类张量接口,以便后续扩展到多类(例如"无人机/鸟/直升机"等)。记输出为 b ^ = ( x ^ , y ^ , w ^ , h ^ ) \hat{b}=(\hat{x},\hat{y},\hat{w},\hat{h}) b^=(x^,y^,w^,h^)、目标置信度 p ^ ∗ o b j \hat{p}*{obj} p^∗obj、类别概率 p ^ ∗ c l s \hat{p}*{cls} p^∗cls,则总体损失通常写为加权和:
L = λ b o x L ∗ b o x + λ ∗ o b j L ∗ o b j + λ ∗ c l s L ∗ c l s . \mathcal{L}=\lambda_{box}\mathcal{L}*{box}+\lambda*{obj}\mathcal{L}*{obj}+\lambda*{cls}\mathcal{L}*{cls}. L=λboxL∗box+λ∗objL∗obj+λ∗clsL∗cls.
其中分类与目标置信度常用二元交叉熵(对 logit 做 Sigmoid):
L ∗ B C E ( z , y ) = − y log σ ( z ) + ( 1 − y ) log ( 1 − σ ( z ) ) , \mathcal{L}*{BCE}(z,y)=-\lefty\\log\\sigma(z)+(1-y)\\log\\left(1-\\sigma(z)\\right)\\right, L∗BCE(z,y)=−ylogσ(z)+(1−y)log(1−σ(z)),
而边界框回归多采用 IoU 家族损失以同时约束重叠度与几何一致性。以 CIoU 为例,其形式为
L C I o U = 1 − IoU + ρ 2 ( c , c g t ) d 2 + α v , \mathcal{L}_{CIoU}=1-\text{IoU}+\frac{\rho^2(\mathbf{c},\mathbf{c}^{gt})}{d^2}+\alpha v, LCIoU=1−IoU+d2ρ2(c,cgt)+αv,
其中 ρ 2 ( c , c g t ) \rho^2(\mathbf{c},\mathbf{c}^{gt}) ρ2(c,cgt) 表示预测框与真值框中心点的欧氏距离平方, d d d 为最小外接框对角线长度, v v v 衡量长宽比一致性, α \alpha α 为平衡系数;该类损失在小目标定位上往往比单纯的 L 1 / L 2 L_1/L_2 L1/L2 更稳定,因为它直接优化"重叠"这一与检测评价指标一致的量。
推理端的后处理遵循工业级实时系统的可控性要求:模型输出经阈值筛选(置信度阈值 τ c \tau_c τc)后,通过 NMS(IoU 阈值 τ n m s \tau_{nms} τnms)抑制重复框,最终输出 ( b i , s i ) {(b_i, s_i)} (bi,si) 并在 UI 侧完成可视化叠加与统计。对于无人机视频流场景,NMS 的阈值设置往往需要兼顾两类错误: τ n m s \tau_{nms} τnms 过低会误删相邻帧/相近位置的真实目标候选(造成漏检),过高则会保留大量相似框(造成多框重复),因此系统在界面层提供可调参数以适配不同镜头焦距与目标密度。
为便于读者在博客中引用网络结构示意图,本文给出三张可直接下载的参考图链接(用于"结构概览/多尺度融合/注意力增强效果"三类说明)。需要说明的是,第一张图是 YOLO 的经典 Backbone--Neck--Head 结构示意(以 YOLOv5 文档图为代表),可作为 YOLOv12 管线介绍的概念性参考;第二张图是 FPN 的结构示意;第三张图展示了 YOLOv10/YOLOv11/YOLOv12 的热力图对比,用于说明注意力增强在目标感知上的差异。
最后补充一点工程实现细节:系统侧默认通过 Ultralytics 的 YOLO() 接口加载权重(如 yolo12n.pt),并将模型推理封装为 Detector 模块对外提供统一的 predict(image) 调用;这样做的好处是,前端 UI 与后端模型之间仅以"输入图像---输出检测结果"的数据结构耦合,后续即便替换为 YOLOv8/YOLOv11 或导出 ONNX/TensorRT,也不会破坏界面层的交互逻辑,从而把"算法迭代"与"系统可用性"解耦开来。(Ultralytics Docs)
4. 训练策略与模型优化
本系统的训练目标并非单纯追求离线 mAP 的极限,而是面向无人机视频流检测的稳定泛化与可部署性:在天空/海面等大背景下,小目标往往只占据极少像素,训练阶段若过度依赖强增强或过早收敛,容易出现"训练集拟合良好但实测漏检"的现象。老思在实验中采用 Ultralytics 训练框架的标准流程,优先启用预训练权重进行迁移学习,在较小数据规模与单类目标(Class ID: 0,无人机)的设定下,通过冻结---解冻式微调或直接全量微调,使 Backbone 在通用视觉表征基础上快速适配无人机外观与航拍背景分布;与此同时,针对小目标任务,输入分辨率固定为 640 × 640 640\times 640 640×640 并配合 letterbox 等比例缩放,避免几何形变引入额外定位误差。训练过程中以验证集指标为主导进行早停与最优权重回滚,减少"长时间训练导致的泛化退化",并将推理阈值(Conf/IoU)放在系统侧做可交互调参,从而把"训练得到的表征能力"与"应用侧的策略选择"解耦。
在优化器与学习率策略方面,系统默认使用框架的 auto 优化器选择(通常会在 SGD/AdamW 等方案中依据模型规模与 batch 自动决策),并采用带 warmup 的余弦退火或等效的分段衰减策略来稳定训练初期梯度。其核心思想是:在前 T w T_w Tw 个 warmup epoch 内逐步增大学习率以避免预训练特征被瞬时大步长破坏,之后再以余弦形式平滑下降以获得更好的收敛质量。一个常用的余弦退火写法为
lr ( t ) = lr 0 ⋅ lrf + 1 − lrf 2 ( 1 + cos ( π t / T ) ) , \text{lr}(t)=\text{lr}_0\cdot\Bigl\\text{lrf}+\\frac{1-\\text{lrf}}{2}\\bigl(1+\\cos(\\pi t/T)\\bigr)\\Bigr, lr(t)=lr0⋅lrf+21−lrf(1+cos(πt/T)),
其中 t t t 为当前 epoch, T T T 为总训练轮数, lrf \text{lrf} lrf 控制末端学习率比例。对于无人机检测这种背景占比极高的任务,训练阶段的数据增强既要提高背景与尺度多样性,也要防止破坏小目标的几何结构,因此 Mosaic 作为有效的多目标拼接增强被保留,但在训练后期关闭(close_mosaic=10)以缩小"训练增强分布"与"真实测试分布"的差距,提升最终的定位精度与置信度校准效果。
为便于复现实验,本文采用的默认训练超参数如下表所示(GPU:RTX 4090,单卡训练)。其中 batch=16 是在显存占用与吞吐之间较稳妥的折中;若显存紧张,可通过梯度累积保持等效 batch,从而维持学习率设定的可迁移性。
| 名称 | 作用(简述) | 数值 |
|---|---|---|
| epochs | 最多训练轮数 | 120 |
| patience | 早停耐心 | 50 |
| batch | 总批大小 | 16 |
| imgsz | 输入分辨率 | 640 |
| pretrained | 加载预训练权重 | true |
| optimizer | 优化器(框架自选) | auto |
| lr0 | 初始学习率 | 0.01 |
| lrf | 最终学习率占比 | 0.01 |
| momentum | 动量系数 | 0.937 |
| weight_decay | 权重衰减 | 0.0005 |
| warmup_epochs | 预热轮数 | 3.0 |
| mosaic | Mosaic 强度/概率 | 1.0 |
| close_mosaic | 后期关闭 Mosaic | 10 |
工程层面的"模型优化"主要围绕两条线展开:一是训练侧的稳定与泛化,二是推理侧的吞吐与延迟。训练侧建议默认启用混合精度(AMP)与 EMA(指数滑动平均)权重以降低数值抖动、提升验证集指标稳定性;对单类检测任务,可适当弱化分类分支的学习难度(例如使用轻量标签平滑或调整 cls/obj 损失权重),让模型把容量更多分配给"是否为无人机"与"框的精定位"。推理侧则建议将最优权重导出为 ONNX,并在条件允许时使用 TensorRT 进行图优化与 FP16 推理,以显著降低端到端延迟;对于实时视频流,还可以通过固定输入尺寸、减少可变 shape、合并 NMS 前过滤等手段进一步稳定帧率。若你后续需要在博客中给出可复现命令,使用 Ultralytics 的典型训练形式如下(路径按你的工程实际替换):
bash
yolo detect train \
model=yolo12n.pt data=drone.yaml \
imgsz=640 batch=16 epochs=120 patience=50 \
lr0=0.01 lrf=0.01 momentum=0.937 weight_decay=0.0005 \
warmup_epochs=3.0 mosaic=1.0 close_mosaic=10 pretrained=True以上策略的核心落点是:用预训练与稳定的学习率调度保证收敛质量,用"前期强增强、后期贴近真实分布"的增强策略提升小目标定位与置信度一致性,并为后续的 ONNX/TensorRT 部署保留结构与输入规范,从而把训练效果更平滑地迁移到系统端的实时检测体验中。
5. 实验与结果分析
5.1 实验设计
本节围绕无人机单类目标检测任务,对 YOLO 系列多版本模型开展统一对比实验。数据集采用前述划分方式:训练集 4,988 张、验证集 1,000 张、测试集 1,000 张,类别为 Class ID: 0(无人机)。为保证公平性,所有模型在相同输入尺寸 640 × 640 640\times 640 640×640、相同训练轮次(120 epochs)与一致的数据增强与优化策略下训练,并在同一测试集上评估精度指标;推理效率在同一硬件平台上统计(NVIDIA GeForce RTX 3070 Laptop GPU,8GB 显存),将端到端延迟拆解为预处理(PreTime)、模型前向推理(InfTime)与后处理(PostTime)三部分,以刻画不同模型在系统落地时的真实开销差异。对比模型分为两组:轻量 n 系列(YOLOv5nu、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9t、YOLOv10n、YOLOv11n、YOLOv12n)与更高容量的 s 系列(YOLOv5su、YOLOv6s、YOLOv7、YOLOv8s、YOLOv9s、YOLOv10s、YOLOv11s、YOLOv12s),其中 YOLOv7-tiny 与 YOLOv7 作为结构差异较大的对照项,便于观察"参数规模并不必然带来更好速度/精度折中"的现象。
5.2 度量指标
检测性能采用 Precision、Recall、F1、mAP@0.5 与 mAP@0.5:0.95(记为 mAP50 与 mAP50-95)衡量,定义为
Precision = T P T P + F P , Recall = T P T P + F N , \text{Precision}=\frac{TP}{TP+FP},\quad \text{Recall}=\frac{TP}{TP+FN}, Precision=TP+FPTP,Recall=TP+FNTP,
F 1 = 2 ⋅ Precision ⋅ Recall Precision + Recall . F1=\frac{2\cdot \text{Precision}\cdot \text{Recall}}{\text{Precision}+\text{Recall}}. F1=Precision+Recall2⋅Precision⋅Recall.
其中 T P / F P / F N TP/FP/FN TP/FP/FN 分别表示真阳性、假阳性与假阴性。mAP 本质上是 PR 曲线下的面积,对单类任务可直接视为"无人机"这一类在不同置信度阈值下精确率与召回率权衡的综合刻画;mAP50-95 则在多个 IoU 阈值上取平均,更强调框的定位质量与尺度一致性。效率侧指标中,PreTime 主要由 resize/letterbox 与张量构建构成,InfTime 对应网络前向,PostTime 对应置信度筛选与 NMS 等后处理步骤;三者之和更接近系统端单帧端到端延迟。
5.3 实验结果与分析
首先从单模型收敛性与阈值敏感性看,训练过程曲线显示 box/cls/dfl 损失均呈稳定下降并在中后期逐步收敛,验证集指标在约 20--40 个 epoch 后进入平台区,说明该单类任务在预训练迁移下收敛较快,后续训练主要起到"稳态微调与置信度校准"的作用。如下图所示,mAP50 最终稳定在约 0.96 量级,而 mAP50-95 约为 0.60 左右,提示模型在 IoU=0.5 的粗粒度检出已较充分,但进一步提升框的贴合度(尤其是远距离小目标的边界精定位)仍是潜在优化方向。
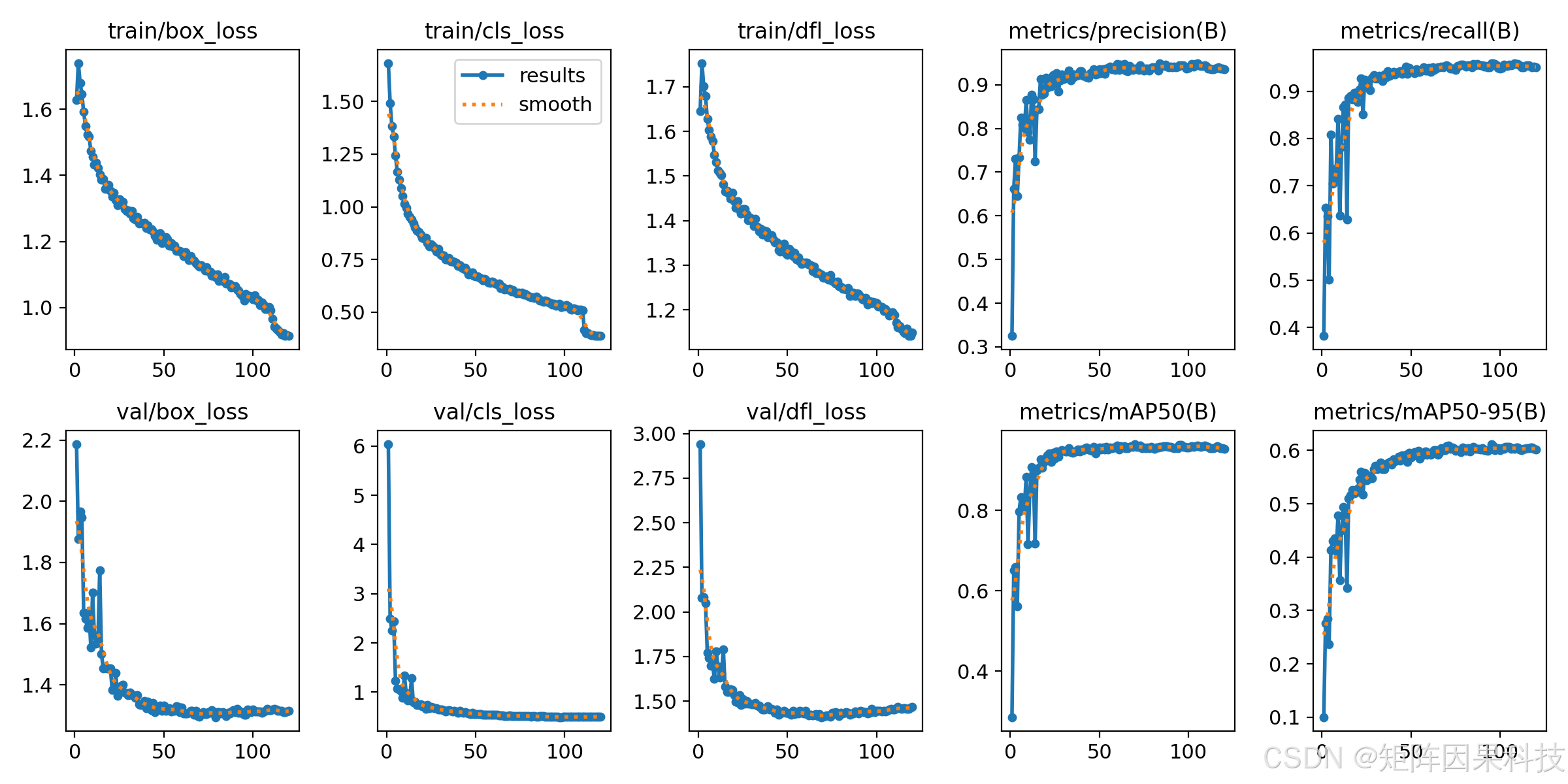
图 训练过程与指标曲线(results)
PR 曲线整体在高召回区域仍维持接近 1 的精确率,表明模型在较宽阈值范围内具有良好的检出稳定性;当 Recall 接近 1 时 Precision 出现快速下滑,反映出在极端追求"零漏检"的阈值设置下,误检会显著增加,这是单类、背景极大且目标很小的场景中常见现象。
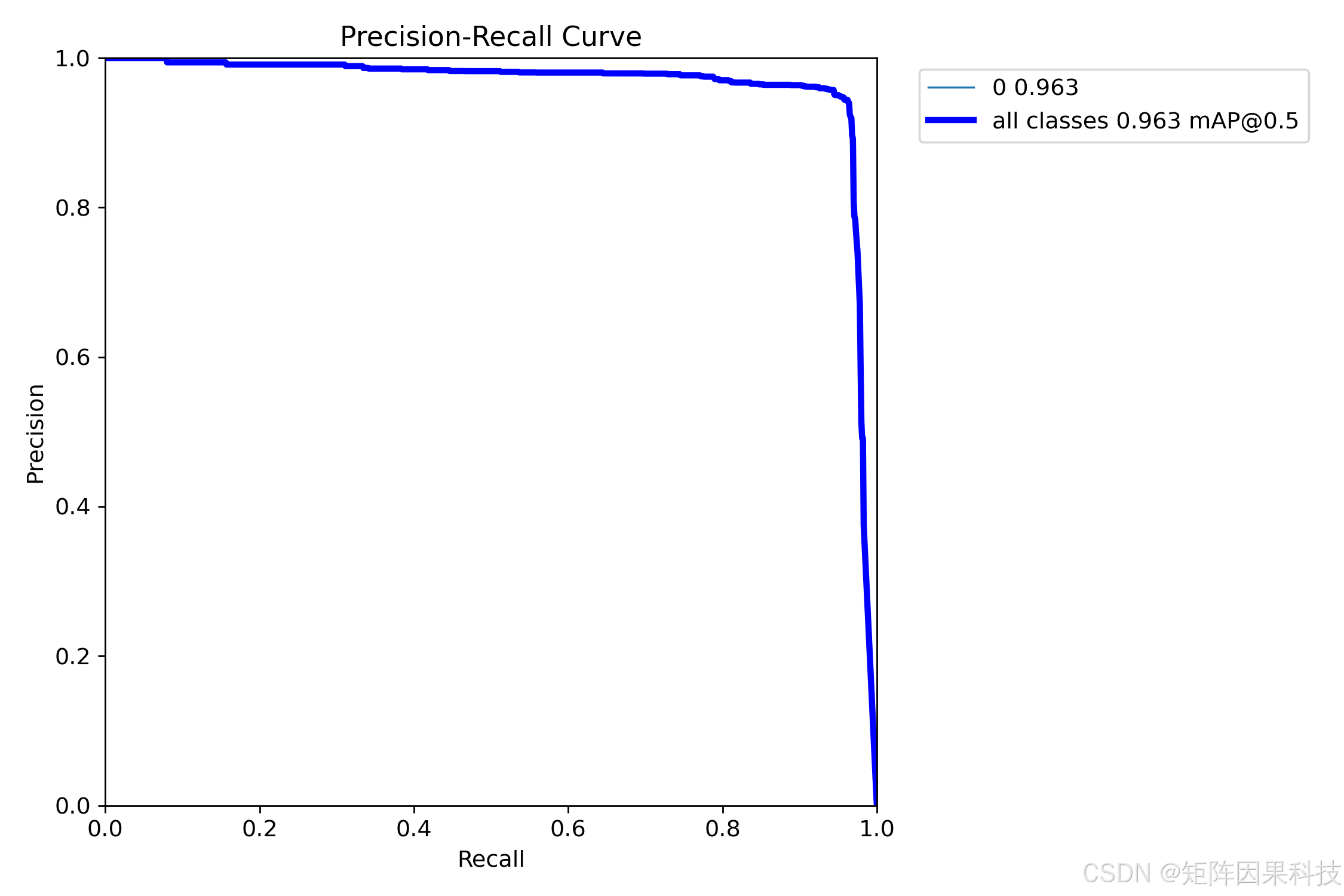
图 PR 曲线(单模型示例)
从混淆矩阵(归一化)可观察到,单类任务不存在跨类别混淆,主要错误来源集中在"将目标漏检为背景"与"背景误检为目标"两类。结合矩阵中约 0.03 的漏检比例(在当前默认阈值附近),可以解释为何 F1 曲线在中等置信度阈值处达到峰值:阈值过低会引入更多 FP,阈值过高会抬升 FN,二者共同决定了系统部署时的最佳工作点。
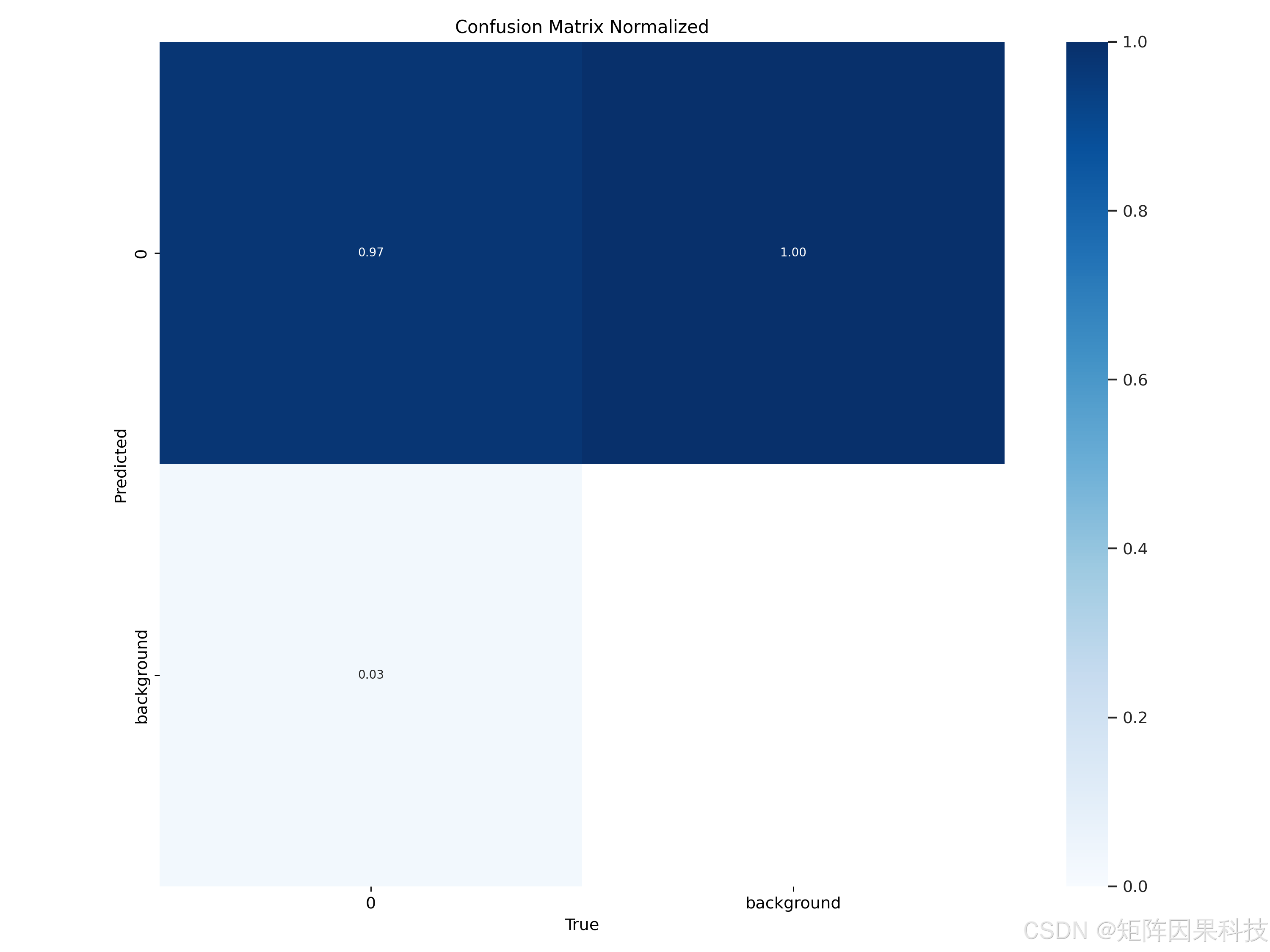
图 归一化混淆矩阵
进一步地,F1-Confidence 曲线显示最优 F1 约为 0.95,最佳置信度阈值约在 0.409 附近。对于实际系统(视频流)而言,老思更倾向于将默认 Conf 设为 0.4 左右,并把阈值作为 UI 可调参数:在"告警优先"的应用里适当下调 Conf 提升召回,在"误报敏感"的应用里上调 Conf 提升精确率。
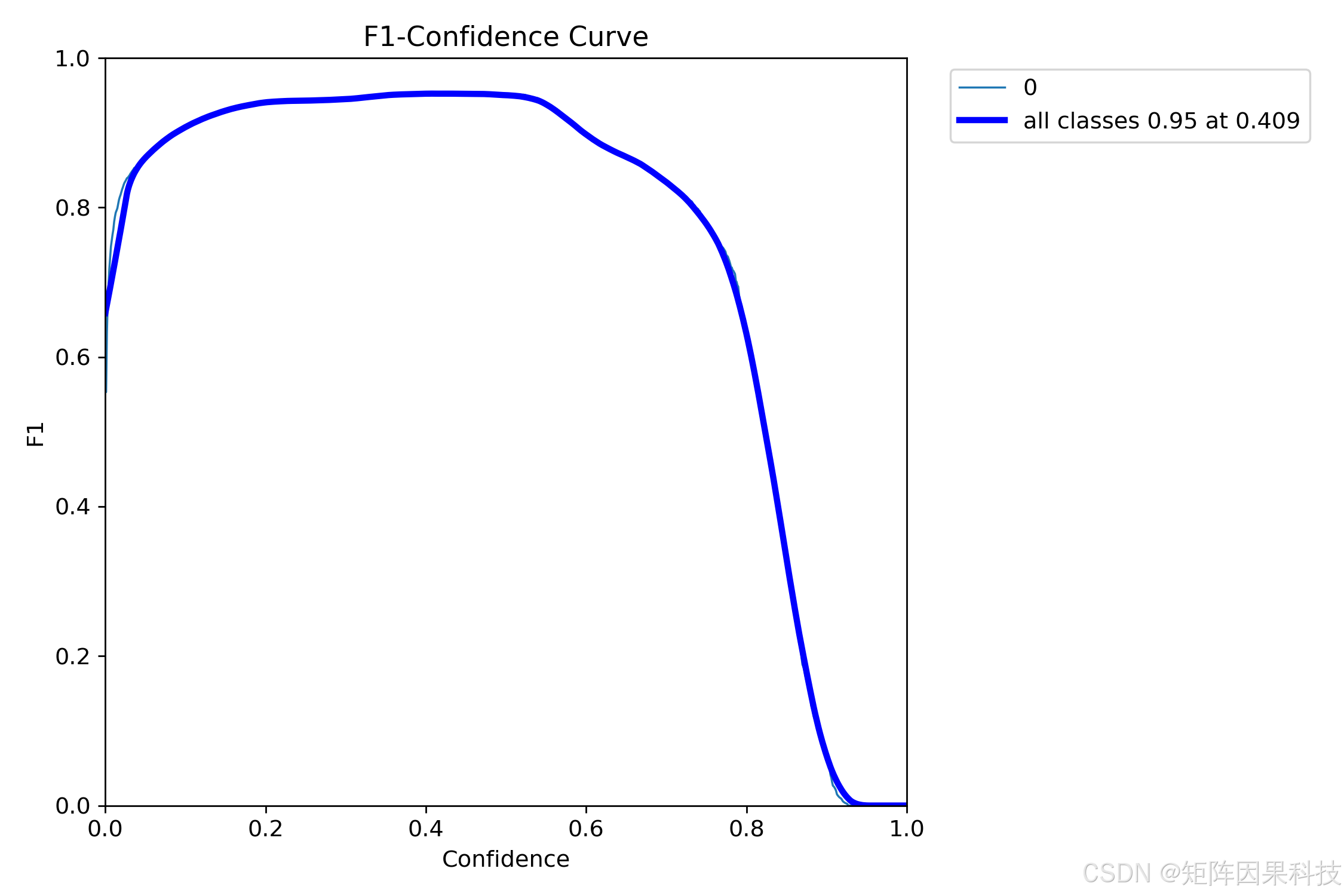
图 F1-Confidence 曲线
在多模型对比方面,先看 n 系列轻量模型(表 5-1)。总体上,各模型的 mAP50 差异很小(约 0.9549--0.9654),说明在该数据集上不同代际 YOLO 的"是否能检出无人机"能力都较强;真正拉开差异的是 mAP50-95 与时延分解,它们更贴近工程关注的定位质量与实时性。YOLOv9t 在 Recall(0.9624)、F1(0.9511)、mAP50(0.9654)与 mAP50-95(0.6147)上均给出最优或近最优表现,体现出其对小目标定位的相对优势,但其 InfTime 达到 16.51 ms,端到端时延明显高于同组其它模型;在实时检测场景中,这类"定位更强但更慢"的模型更适合离线分析或低帧率监控。相对地,YOLOv8n 与 YOLOv6n 在 InfTime 上最优(6.83 ms 与 6.78 ms),并维持较高的 mAP50-95(0.6041 与 0.6013),其中 YOLOv8n 的 Precision 与 F1 更均衡(0.9492/0.9493),更适合作为"默认在线模型"。值得注意的是,YOLOv10n 的 PostTime 仅 0.63 ms,后处理开销显著更小,这对 UI 实时渲染与多线程流水线有实际价值,但其精度端(尤其 Recall 与 F1)略低于主流最优项,体现出端到端效率优化与泛化性能之间仍需任务化权衡。
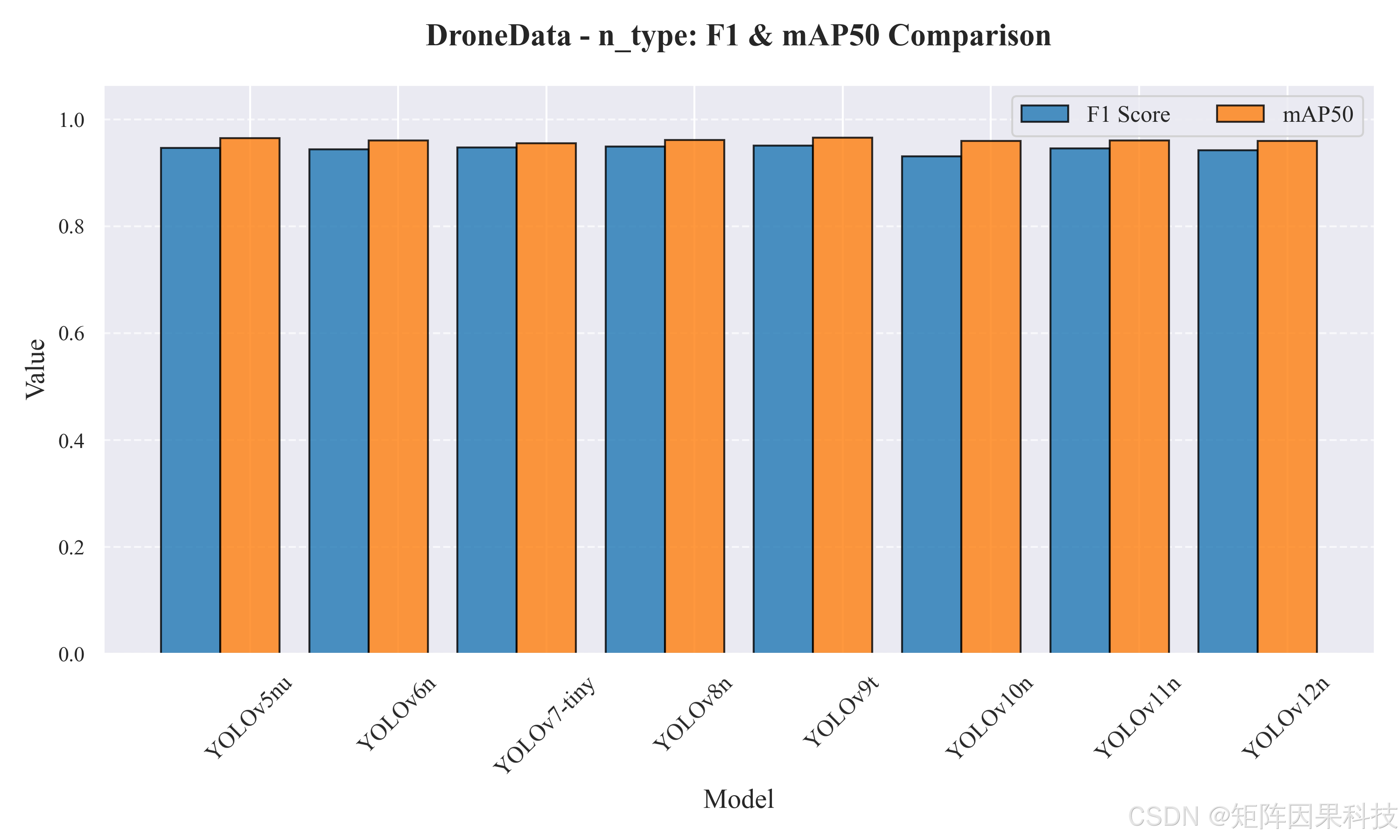
图 n 系列:F1 与 mAP50 对比
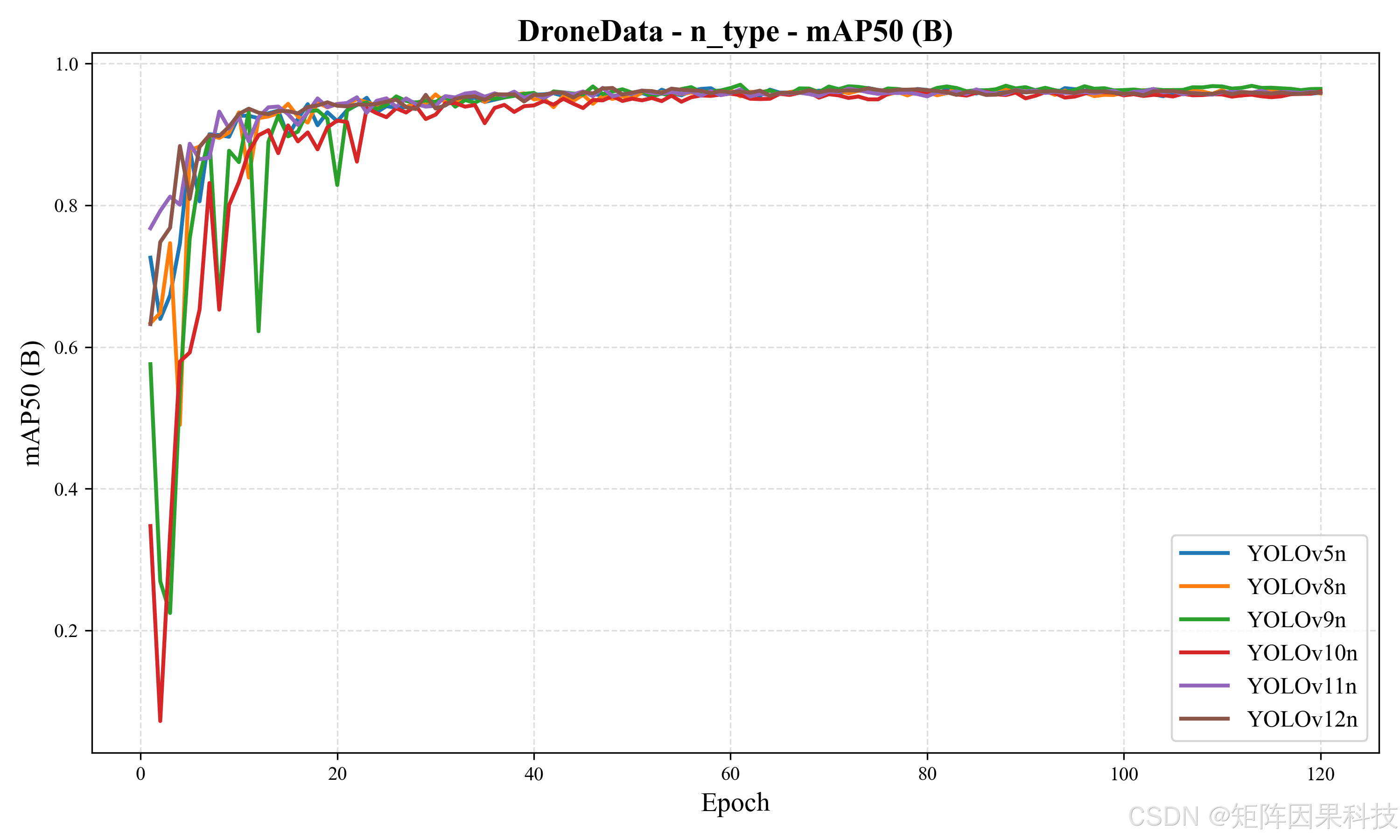
图 n 系列:mAP50 随 epoch 收敛曲线
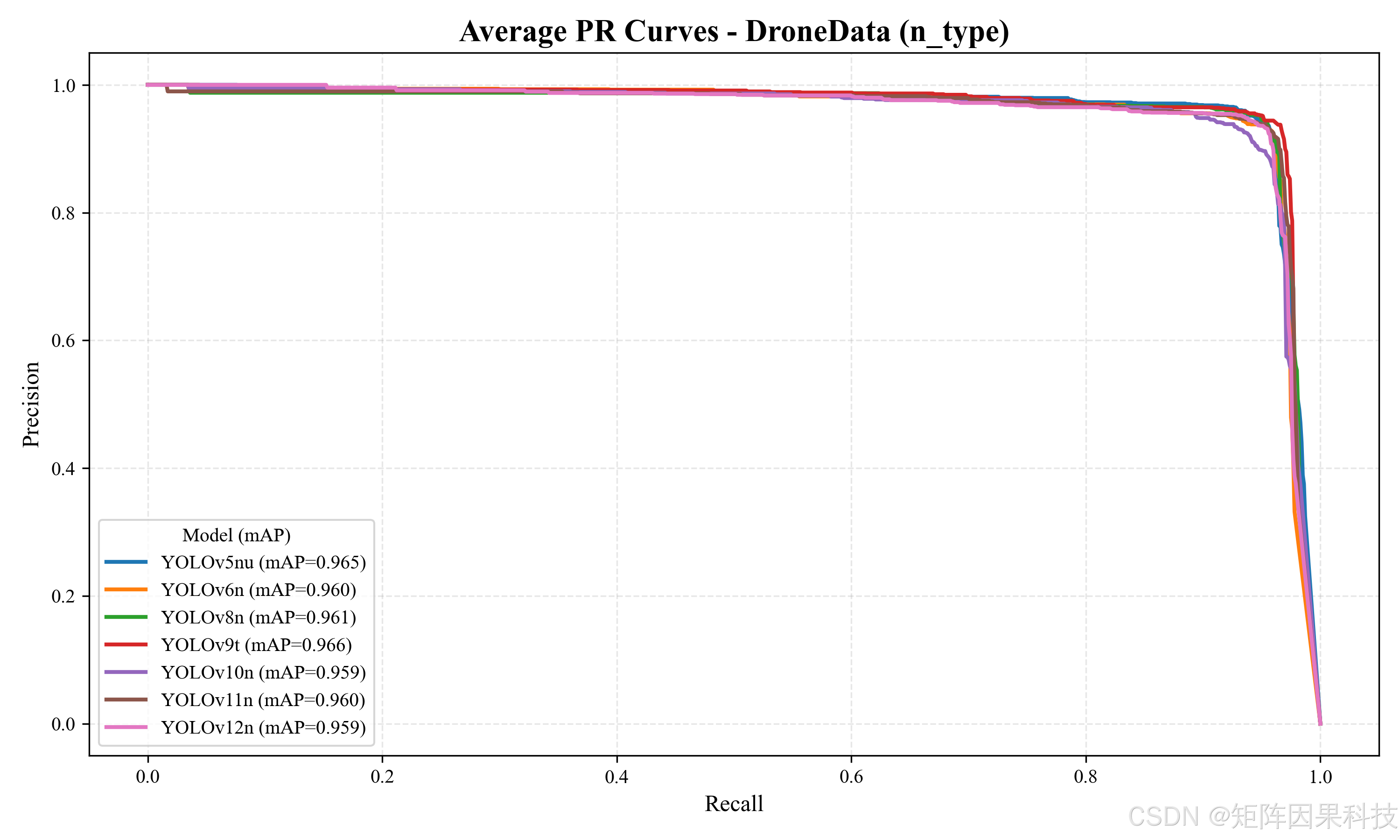
图 n 系列:平均 PR 曲线对比
表 5-1 轻量 n 系列模型对比(RTX 3070 Laptop GPU)
| Model | Params(M) | FLOPs(G) | Pre(ms) | Inf(ms) | Post(ms) | Precision | Recall | F1 | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 1.90 | 7.73 | 1.31 | 0.9492 | 0.9443 | 0.9467 | 0.9651 | 0.6036 |
| YOLOv6n | 4.3 | 11.1 | 2.17 | 6.78 | 1.39 | 0.9322 | 0.9550 | 0.9435 | 0.9605 | 0.6013 |
| YOLOv7-tiny | 6.2 | 13.8 | 2.28 | 14.74 | 4.06 | 0.9443 | 0.9504 | 0.9473 | 0.9549 | 0.5550 |
| YOLOv8n | 3.2 | 8.7 | 1.95 | 6.83 | 1.39 | 0.9492 | 0.9495 | 0.9493 | 0.9617 | 0.6041 |
| YOLOv9t | 2.0 | 7.7 | 1.87 | 16.51 | 1.29 | 0.9401 | 0.9624 | 0.9511 | 0.9654 | 0.6147 |
| YOLOv10n | 2.3 | 6.7 | 2.08 | 11.24 | 0.63 | 0.9322 | 0.9293 | 0.9308 | 0.9592 | 0.6102 |
| YOLOv11n | 2.6 | 6.5 | 2.11 | 9.44 | 1.42 | 0.9385 | 0.9525 | 0.9454 | 0.9600 | 0.6096 |
| YOLOv12n | 2.6 | 6.5 | 1.91 | 12.47 | 1.37 | 0.9357 | 0.9490 | 0.9423 | 0.9594 | 0.6092 |
再看 s 系列模型(表 5-2),其参数量与 FLOPs 普遍高于 n 系列,因此理论上更有潜力改善定位质量,但也更容易受到部署端吞吐限制。结果显示,YOLOv11s 取得最高 mAP50(0.9662),而 YOLOv10s 在 mAP50-95 上达到最优(0.6193),说明这两者在"框更贴合"的指标上更具优势;与此同时,YOLOv8s 给出最高 F1(0.9530)且 InfTime 最低(7.66 ms),在精度与速度之间呈现更均衡的折中。YOLOv9s 的 Precision 达到组内最高(0.9522),但推理耗时较大(18.66 ms),更接近"高置信、低误报"的离线筛查取向。YOLOv7 虽具备最大参数与计算量,但在该任务上并未带来更优的 mAP50-95(0.5685),且 InfTime 达到 23.62 ms,说明在单类无人机检测这一相对"结构简单但小目标突出"的数据分布下,模型规模并非收益的主要来源,结构与实现路径(尤其推理图优化与后处理设计)对真实时延更敏感。
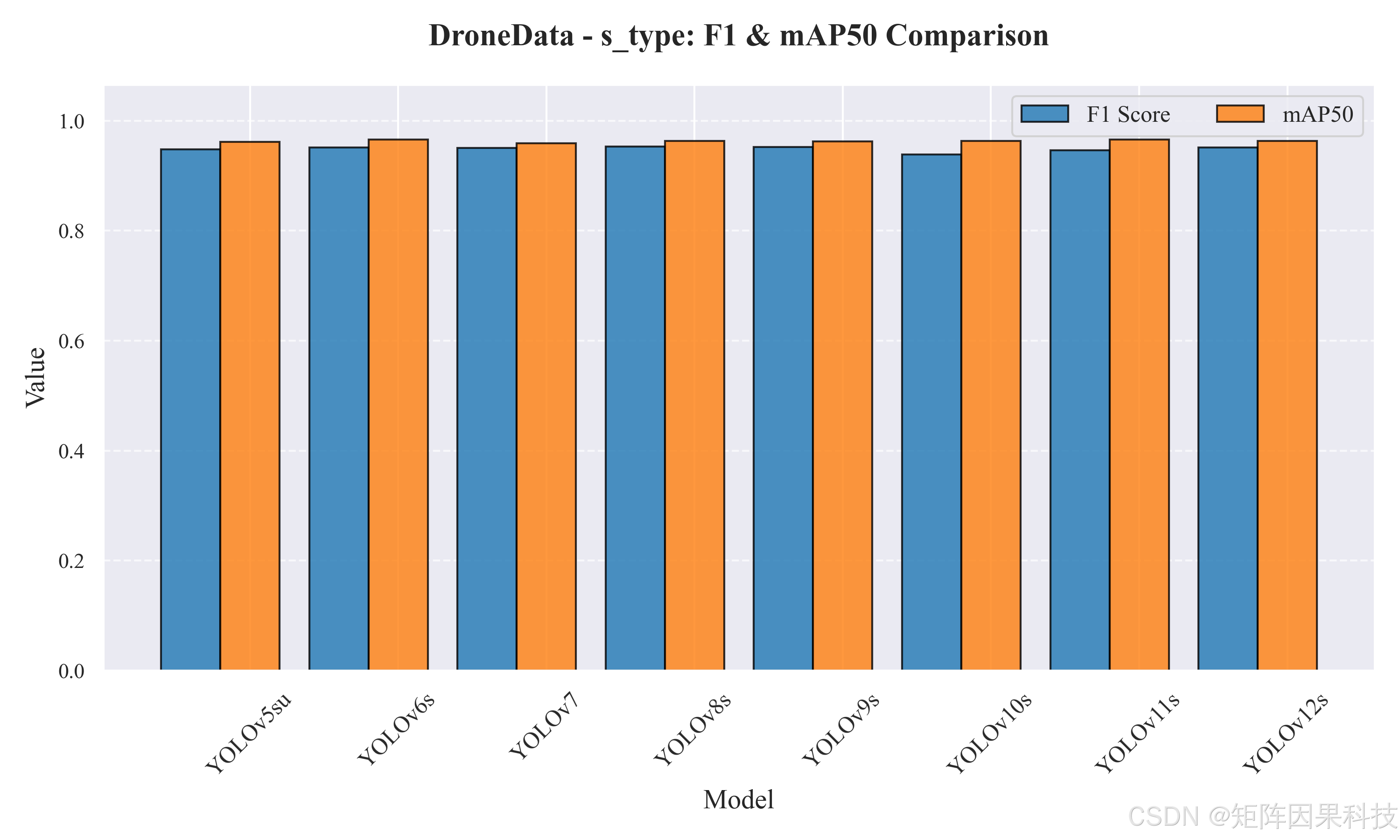
图 s 系列:F1 与 mAP50 对比
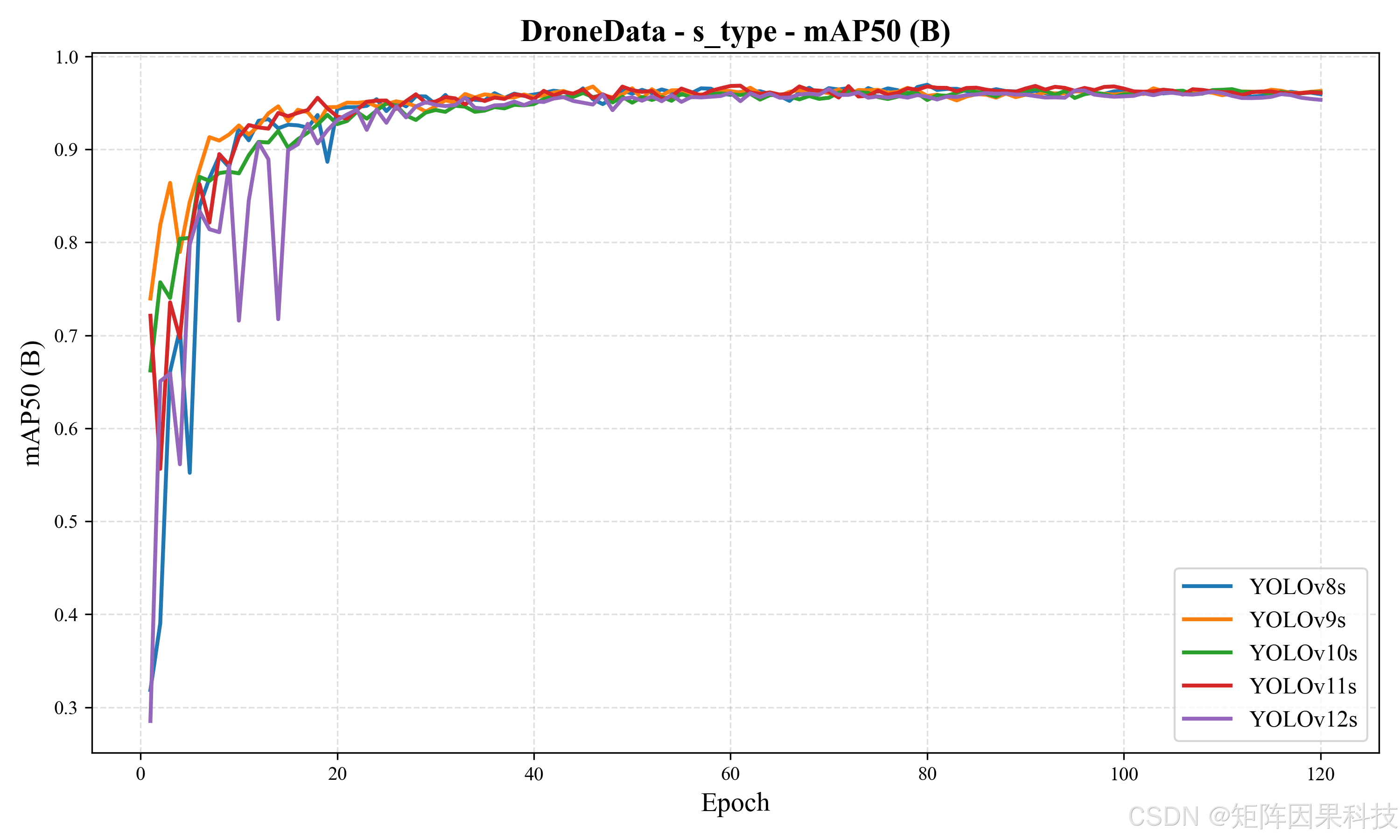
图 s 系列:mAP50 随 epoch 收敛曲线
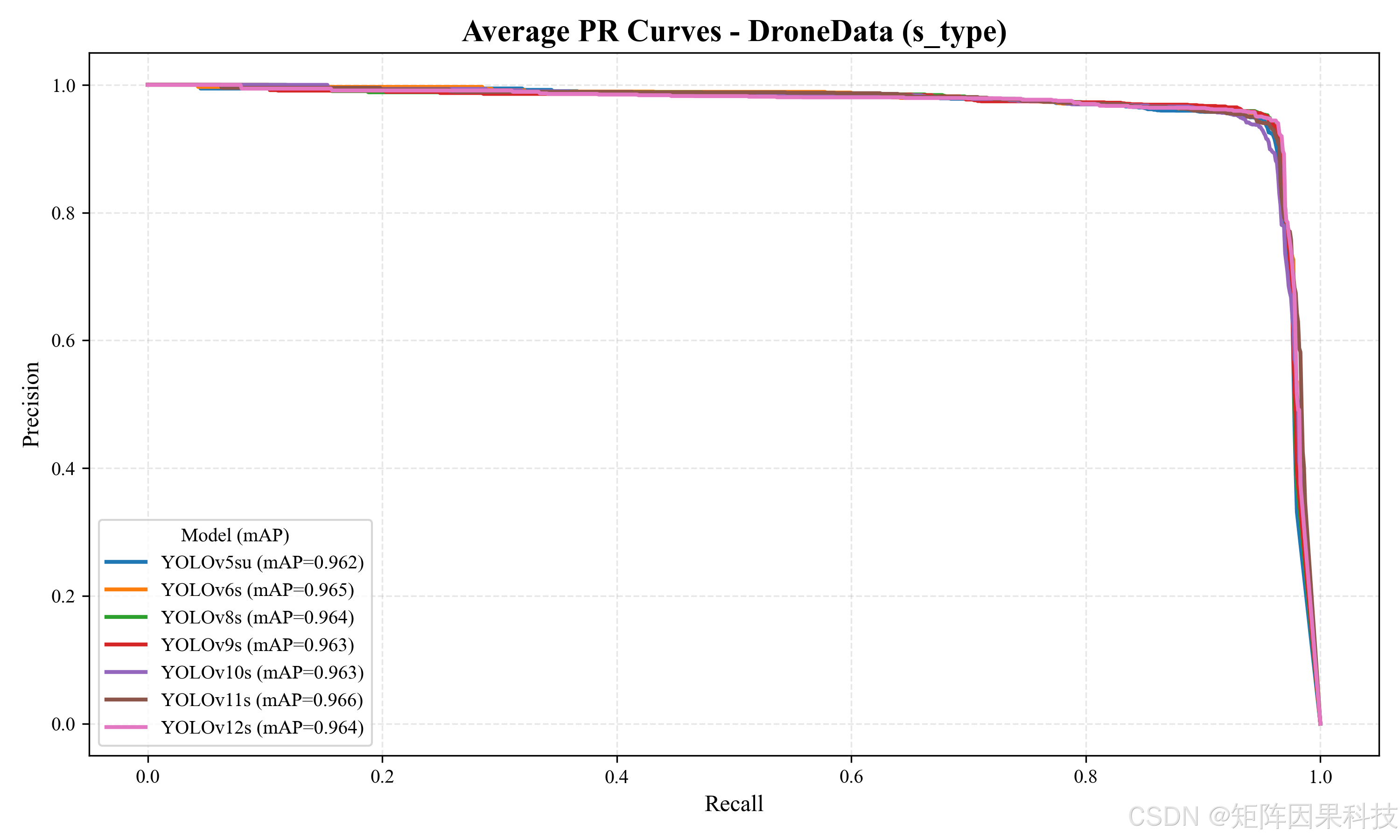
图 s 系列:平均 PR 曲线对比
表 5-2 s 系列模型对比(RTX 3070 Laptop GPU)
| Model | Params(M) | FLOPs(G) | Pre(ms) | Inf(ms) | Post(ms) | Precision | Recall | F1 | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 2.28 | 8.45 | 1.51 | 0.9455 | 0.9513 | 0.9484 | 0.9614 | 0.6090 |
| YOLOv6s | 17.2 | 44.2 | 2.22 | 8.59 | 1.45 | 0.9472 | 0.9552 | 0.9512 | 0.9658 | 0.6056 |
| YOLOv7 | 36.9 | 104.7 | 2.44 | 23.62 | 3.46 | 0.9503 | 0.9513 | 0.9508 | 0.9590 | 0.5685 |
| YOLOv8s | 11.2 | 28.6 | 2.31 | 7.66 | 1.42 | 0.9501 | 0.9559 | 0.9530 | 0.9634 | 0.6137 |
| YOLOv9s | 7.2 | 26.7 | 2.12 | 18.66 | 1.39 | 0.9522 | 0.9521 | 0.9522 | 0.9627 | 0.6184 |
| YOLOv10s | 7.2 | 21.6 | 2.21 | 11.38 | 0.60 | 0.9414 | 0.9366 | 0.9390 | 0.9637 | 0.6193 |
| YOLOv11s | 9.4 | 21.5 | 2.37 | 9.74 | 1.36 | 0.9401 | 0.9518 | 0.9460 | 0.9662 | 0.6134 |
| YOLOv12s | 9.3 | 21.4 | 2.09 | 13.23 | 1.42 | 0.9440 | 0.9597 | 0.9518 | 0.9632 | 0.6113 |
综合两组实验,可以得到一个更贴近部署的结论:在该无人机单类数据集上,精度(尤其 mAP50)已接近饱和,不同版本 YOLO 的差异更多体现为"定位质量(mAP50-95)与端到端时延"的权衡;若系统以实时视频流为主,建议优先选择 YOLOv8n/YOLOv6n 这类低 InfTime 且精度稳定的模型作为默认推理引擎;若更看重远距离小目标的框贴合与召回,且帧率约束相对宽松,则 YOLOv9t/YOLOv10s 提供了更高的 mAP50-95 上限。与之对应,UI 侧将 Conf 与 IoU 阈值开放为可调参数,并以 C o n f ≈ 0.4 Conf\approx 0.4 Conf≈0.4 作为默认工作点,使模型能够在不同应用需求(漏检敏感或误报敏感)下快速切换到合适的运行状态。
6.系统设计与实现
6.1 系统设计思路
本系统以"可替换检测模型、可复用推理链路、可维护界面逻辑"为核心原则进行架构设计。整体采用典型的三层解耦:界面层负责承载交互与可视化(输入源选择、参数调节、结果表格与统计展示);控制层负责状态机与业务调度(播放控制、线程管理、信号槽编排、异常与资源回收);处理层负责算法推理与后处理(模型加载、推理、NMS、类别统计与结果结构化)。这种划分的直接收益在于,模型侧从 YOLOv5 到 YOLOv12 的切换不会影响 UI 逻辑,UI 的主题/布局调整也不会破坏推理链路,从而降低迭代成本。
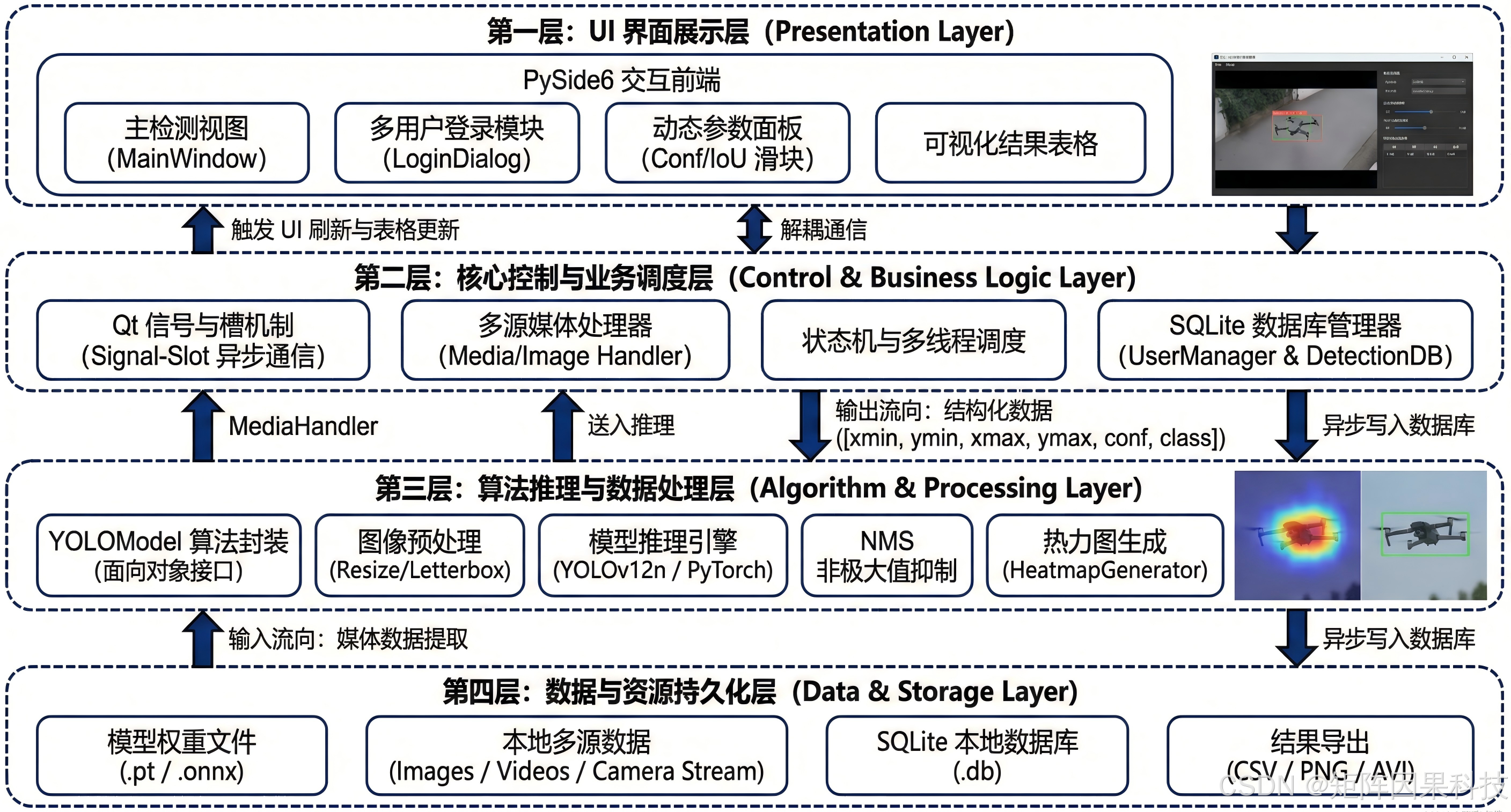
在运行机制上,系统以 Qt 信号槽作为跨层通信主干:MainWindow 通过槽函数响应按钮事件并分发任务,Detector 在独立工作线程中完成推理与后处理,随后以信号携带结构化结果(检测框、类别、置信度、统计信息)回传 UI,由界面层完成绘制与表格刷新,避免长耗时推理阻塞主线程导致界面卡顿。对实时视频流而言,控制层维持"开始---暂停---继续---停止"的状态闭环,结合帧率节流与队列丢帧策略,使得系统在算力波动或输入源抖动时仍能保持可用的交互响应。
在数据管理与可追溯性方面,系统引入 SQLite 作为轻量持久化底座:用户表用于登录注册与资料维护,配置表用于保存主题、默认模型、阈值等偏好项,结果表用于记录每次检测的时间戳、输入源、模型版本、阈值与输出统计,实现"可复现、可查询、可导出"的工程闭环。老思在实现中将模型权重与类别映射作为可配置项,使系统既能满足单类无人机检测,也能在扩展类别后保持同一套交互范式。
图 系统流程图
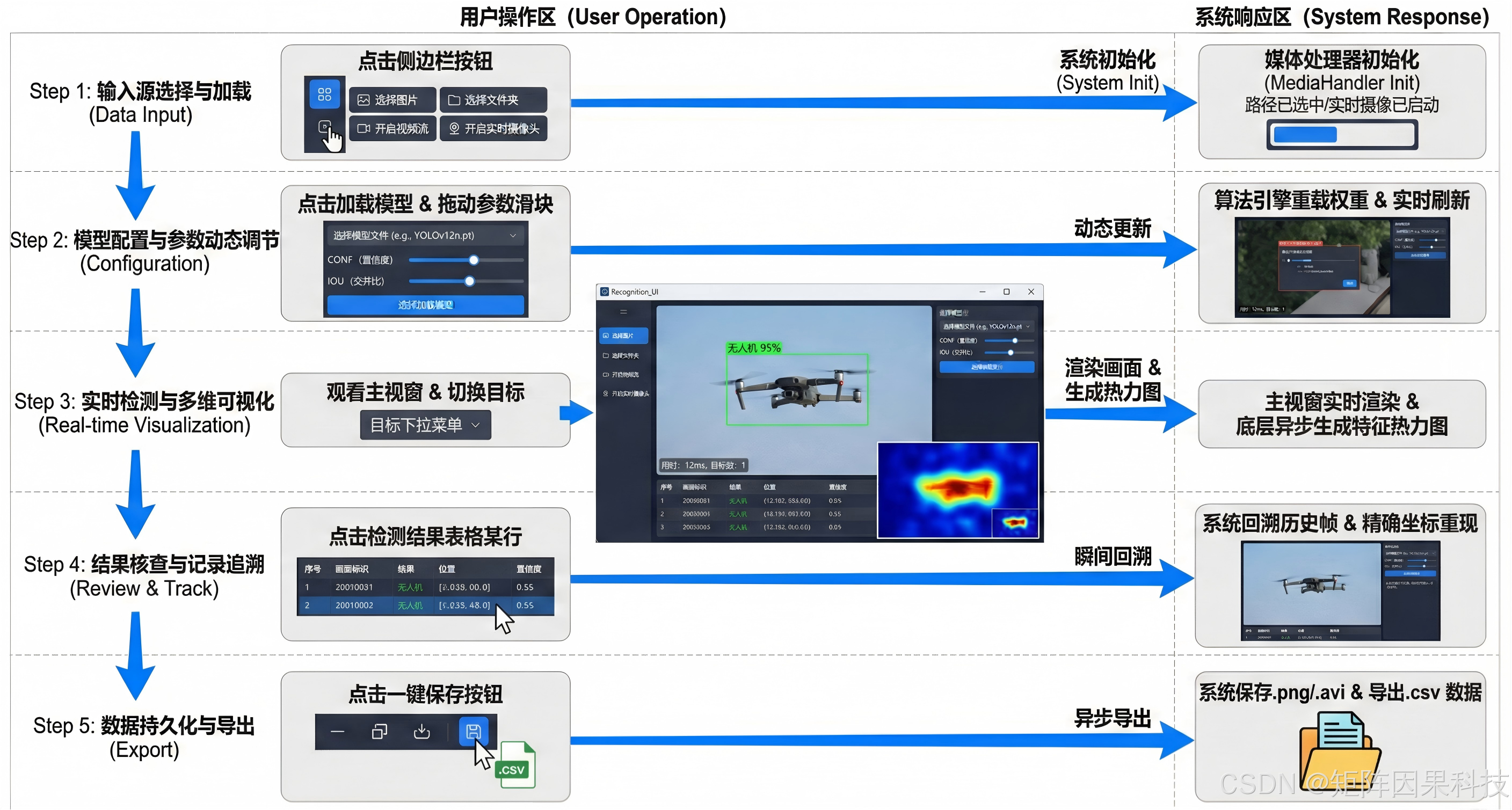
图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理 --- 流程图
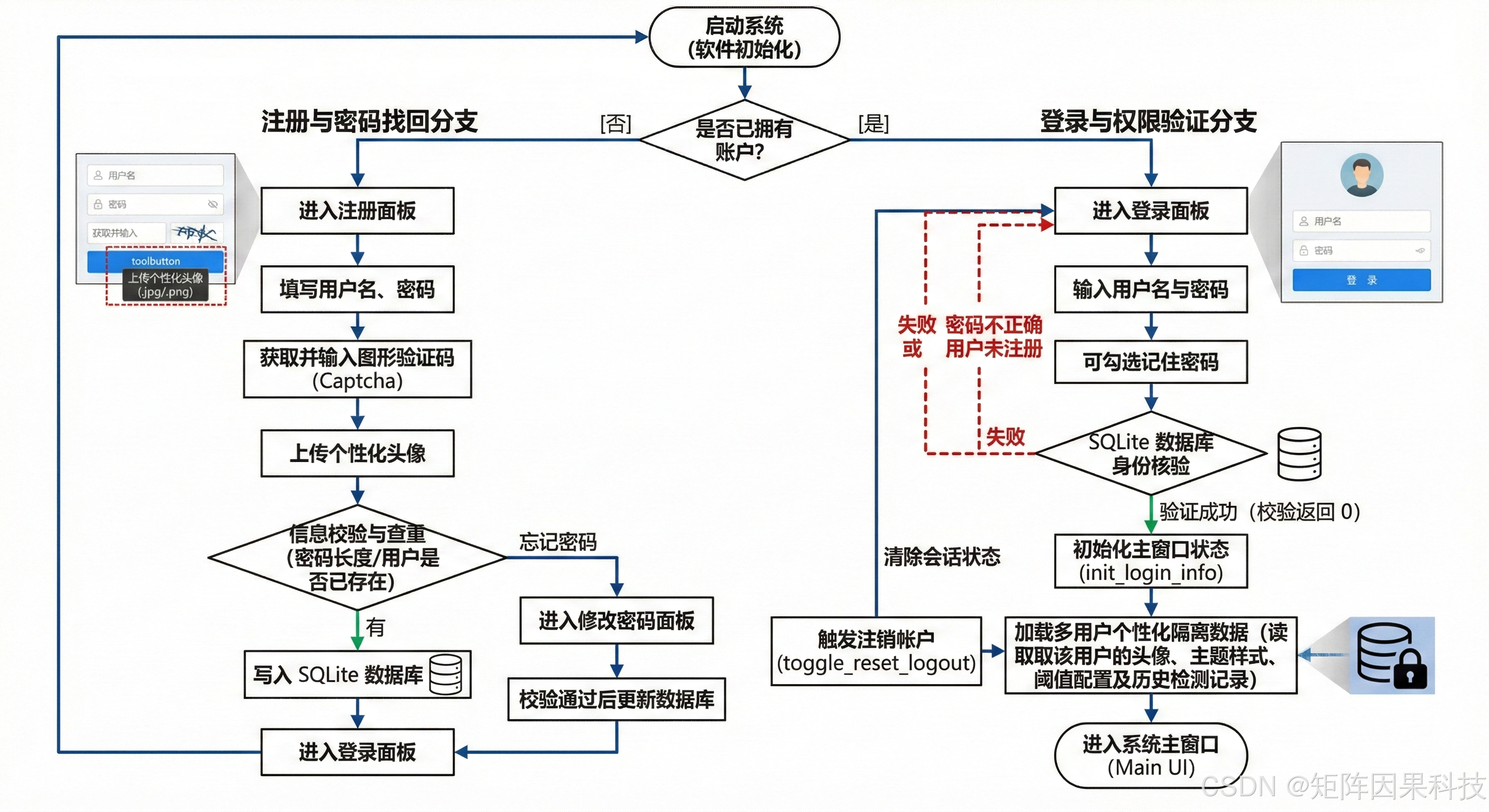
登录与账户管理模块以 SQLite 为核心提供轻量但完整的身份闭环:用户在登录界面完成注册或登录后,系统在通过校验的同一时刻加载该用户的个性化配置与历史检测记录,使"默认模型、Conf/IoU 阈值、主题样式、结果保存策略"等偏好与身份绑定并自动恢复;进入主界面后,用户可随时修改头像与密码,修改动作以事务方式写回数据库,从而在多工位共用或多用户轮换的场景下维持清晰的数据边界与可追溯性;当用户注销或切换账号时,控制层清理会话状态并回到登录界面,保证后续检测结果与配置写入严格归属到当前用户空间,实现与主检测流程的自然衔接与一致的交互体验。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件 (包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
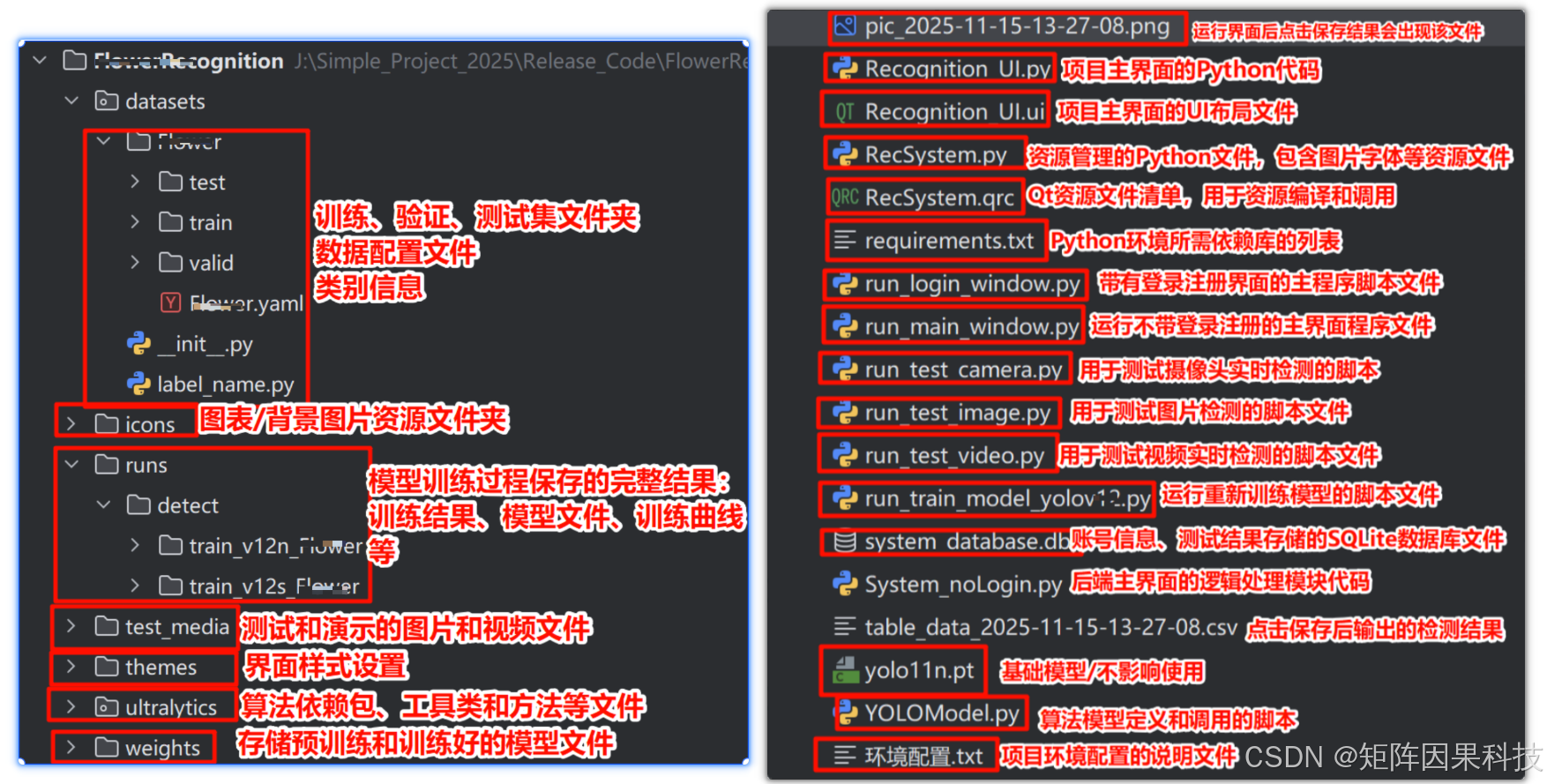
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件请见项目介绍及功能演示视频处给出:➷➷➷
详细介绍文档博客 :YOLOv5至YOLOv12升级:无人机目标检测系统的设计与实现(完整代码+界面+数据集项目)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8.参考文献
1 Wu X, Li W, Hong D, et al. Deep Learning for UAV-based Object Detection and Tracking: A SurveyEB/OL. arXiv:2110.12638, 2021(2026-03-21). (arXiv)
2 Zhu P, Wen L, Bian X, et al. Vision Meets Drones: A ChallengeEB/OL. arXiv:1804.07437, 2018(2026-03-21). (arXiv)
3 Du D, Qi Y, Yu H, et al. The Unmanned Aerial Vehicle Benchmark: Object Detection and TrackingC//ECCV 2018. 2018. (CVF Open Access)
4 Ren S, He K, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal NetworksC//Advances in Neural Information Processing Systems (NeurIPS). 2015. (NeurIPS Papers)
5 Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox DetectorC//ECCV 2016. Springer, 2016. (Springer)
6 Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object DetectionC//CVPR 2016. 2016. (CV Foundation)
7 Lin T Y, Dollár P, Girshick R, et al. Feature Pyramid Networks for Object DetectionC//CVPR 2017. 2017. (CVF Open Access)
8 Liu Y, Sun P, Wergeles N, et al. A survey and performance evaluation of deep learning methods for small object detectionJ. Expert Systems with Applications, 2021, 172:114602. (ScienceDirect)
9 Carion N, Massa F, Synnaeve G, et al. End-to-End Object Detection with TransformersC//ECCV 2020. 2020. (ecva.net)
10 Zhu X, Su W, Lu L, et al. Deformable DETR: Deformable Transformers for End-to-End Object DetectionC//ICLR 2021. 2021. (OpenReview)
11 Liu Z, Lin Y, Cao Y, et al. Swin Transformer: Hierarchical Vision Transformer Using Shifted WindowsC//ICCV 2021. 2021. (CVF Open Access)
12 Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object DetectorsC//CVPR 2023. 2023. (CVF Open Access)
13 Ultralytics. Explore Ultralytics YOLOv8EB/OL. (2026-03-21). (Ultralytics Documentation)
14(作者信息以期刊页为准)Review of deep learning algorithms for small object detection in remote sensingJ. 中国图象图形学报, 2024. (CJIG)
15 Xu L, Zhao Y, Zhai Y, et al. Small Object Detection in UAV Images Based on YOLOv8nJ. International Journal of Computational Intelligence Systems, 2024, 17:223. (Springer)