
🎬 个人主页:HABuo
📖 个人专栏:《C++系列》 《Linux系列》《数据结构》《C语言系列》《Python系列》《YOLO系列》
⛰️ 如果再也不能见到你,祝你早安,午安,晚安

目录
[📖2.1 UDP协议](#📖2.1 UDP协议)
[📖2.2 TCP协议](#📖2.2 TCP协议)
前言:
本篇博客继续上篇博客的学习,主要介绍计算机网络体系中的基础知识:端口号、UDP、TCP协议的特点、以及网络字节序的理解!
📚一、端口号
端口号是Linux内核用来区分"同一台机器上不同网络应用程序"的数字标签,范围0~65535。
可以把IP地址比作一栋大楼的地址(找到这栋楼),而端口号就是楼里的房间号(找到具体哪个房间的人在收信)。
这样听起来是不是端口号就是标识进程,是!我们一台服务器上可以运行着相当多的进程,例如:一台Linux服务器上可能同时运行着很多网络服务:Web(Nginx/Apache)、数据库(MySQL/PostgreSQL)、SSH、邮件服务等。但是这些服务都使用相同的IP地址,当数据包到达这台机器时,内核必须知道把数据交给哪个进程。因此:
IP地址 :找到这台机器。
端口号 :找到机器上的哪个进程。
传输层协议(TCP和UDP)使用16位无符号整数 作为端口号,因此范围是 0 ~ 65535。
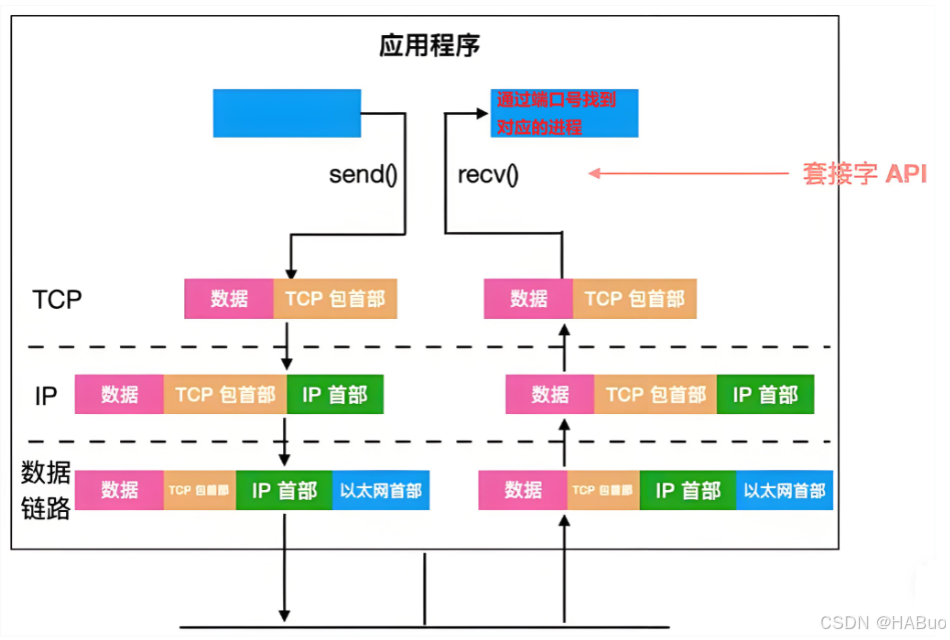
总结为一句话 :IP地址(主机全网唯一性)+该主机上的端口号,标识该服务器上进程的唯一性
那么就有一个问题:系统部分我们学习的pid不也是标识进程的吗?为什么不用pid而又重新设定一个端口号?
- 一个端口号只能绑定一个进程, 但一个进程可以绑定到多个端口号上
- 解耦合, 端口号是传输层到应用层寻找服务时需要使用的字段, 而进程的pid往往用于操作系统管理不同的进程
- 不是所有的进程都需要端口号(不需要网络通信的进程),但是所有的进程都要有pid让操作系统便于管理,分配内存、CPU等资源
📚二、UDP协议和TCP协议
TCP和UDP是传输层的两大核心协议(当然还有其它协议,主要以这两个为代表)。它们都承载在IP协议之上,但设计哲学截然相反:TCP追求"可靠、有序、不丢",UDP追求"最快、最轻、不管"。在TCP协议和UDP协议的字段中有两个端口号,分别是源端口号和目的端口号,用来表示数据是谁发来的,要发给谁的
📖2.1 UDP协议
UDP协议 核心特征
-
无连接:发送数据前不需要建立连接,直接发。
-
不可靠:不保证送达,不保证顺序,没有ACK和重传。
-
轻量:头部仅8字节,没有拥塞控制和流量控制。
-
消息边界 :UDP是面向数据报的,一次发送对应一次接收(应用层读到的就是一个完整消息)。
-
支持广播和组播:可以一对多发送。
-
低延迟:避免了TCP的握手、重传、拥塞控制带来的延迟。
UDP头部格式
bash
+--------+--------+--------+--------+
| 源端口 | 目的端口 |
+--------+--------+--------+--------+
| 长度 | 校验和 |
+--------+--------+--------+--------+📖2.2 TCP协议
TCP协议 核心特征
-
有连接:通信前必须建立连接(三次握手),结束后释放连接(四次挥手)。
-
可靠传输:确认应答(ACK)+ 超时重传,保证数据不丢失。
-
有序交付:每个字节都有序列号,接收方按序重组,乱序包会排队等待或重传。
-
流量控制:通过滑动窗口,告知对方自己的接收能力,防止发送太快淹没接收方。
-
拥塞控制:慢启动、拥塞避免、快速重传/恢复,避免网络过载。
-
全双工:双方可以同时发送和接收数据。
-
面向字节流:没有消息边界,应用层需要自己处理消息分割(如HTTP使用空行或Content-Length)。
TCP头部格式
bash
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 源端口(16) | 目的端口(16) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 序列号(32) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 确认号(32) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 数据偏移 | 保留 |U|A|P|R|S|F| 窗口大小(16) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 校验和(16) | 紧急指针(16) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| 选项(可选) |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+对于连接性的解释:
TCP通信前需要先建立连接(也就是大名鼎鼎的TCP三次握手,后面会讲). 而UDP通信什么都不用提前做. 我们可以把TCP通信比喻为打电话, 想和你通信必须先经过你的同意. 而把UDP通信比喻为寄快递, 我不需要经过你的同意,我只需要知道你的地址就可以无脑给你寄快递,这些到后面无论是知识还是代码我都会详细的进行介绍,大家有个印象即可!
对于可靠性的解释:
TCP是可靠的,而UDP是不可靠的, 那么在实际生活中我们用TCP就行了啊,为什么还要有UDP协议的存在呢? TCP的可靠性是通过一定的策略实现的, 所以TCP是比UDP要复杂的, 并且从效率上来说, TCP和UDP谁快谁慢还不一定. 所以在不同场景下, 用到的协议也不同. 比如微信发送信息时, 我们一定不希望消息在网络传输中丢失了, 所以大概率会选择TCP协议. 而当我们在直播上网课时, 及时有部分包丢失在网络中,也不会对整个直播有太大的影响, 所以这时往往会选择UDP协议。可靠性是一个中性词,TCP与UDP都有自己的应用场景,只不过相对来说TCP比UDP要复杂,更复杂相应的可能就面临着速度更慢!大多数情况下UDP的效率更快些!
对于面向字节流/数据报的解释:
什么是面向字节流? 意思就是TCP协议在发送数据时, 不管一次性发送多少数据, 也不管数据一共要发送几次,它只关心能尽快的将数据从客户端发送到服务器. 所以说TCP在发送数据时, 完整的数据可能是: "abcdefg123456"但是缓冲区中可能还没有将这些数据完全存储但是它给你直接一下把其中的数据全部发送导致出现"abcdefg1",之后再发送"234",再发送"56". 这都是不定的. 而UDP是面向数据报的, 它每次发送数据时, 会将完整的数据全部保存在一个报文中, 然后将这个数据报整体发送过去
对于这部分大家先了解,后面会详细介绍!
📚三、网络字节序
为什么会有网络字节序?
- 因为不同的计算机体系结构存储多字节整数的方式不同。如果不统一,双方就会把数值"读反"。
网络字节序是大端字节序,所有多字节整数在网络上传输时都必须使用这种顺序。
知识复习:
大端存储方式,将数据的高位放到内存序列的低地址处,将数据的低位放到内存序列的高地址处(低高大)
小端存储方式,即将数据的低位放到内存序列的低地址处,将数据的高位放到内存序列的高地址处(低低小)
例子 :假设有一个16位整数0x1234(十进制4660)。大端存储:
0x12(高位)存低地址,0x34存高地址。小端存储:
0x34存低地址,0x12存高地址。当你用wireshark抓包,看到网络上的数据是
0x12 0x34,小端机器如果直接读成0x3412,那就错了。
网络字节序中还有以下规则:
- 发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出;
- 接收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存;
- 因此,网络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是高地址.
- TCP/IP协议规定,网络数据流应采用大端字节序,即低地址高字节.
- 不管这台主机是大端机还是小端机, 都会按照这个TCP/IP规定的网络字节序来发送/接收数据;
- 如果当前发送主机是小端, 就需要先将数据转成大端; 否则就忽略, 直接发送即可;
Linux下的字节序转换函数
| 函数 | 含义 | 用途 |
|---|---|---|
htonl() |
H ost TO N etwork Long | 32位整数(如IPv4地址)主机序 → 网络序 |
htons() |
H ost TO N etwork Short | 16位整数(如端口号)主机序 → 网络序 |
ntohl() |
N etwork TO H ost Long | 32位整数网络序 → 主机序 |
ntohs() |
N etwork TO H ost Short | 16位整数网络序 → 主机序 |
- 这些函数名很好记,h表示host,n表示network,l表示32位长整数,s表示16位短整数。
- 例如htonl表示将32位的长整数从主机字节序转换为网络字节序,例如将IP地址转换后准备发送。
- 如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回;
- 如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。
cpp
uint32_t host_ip = 0xC0A80164; // 192.168.1.100 的十六进制表示(主机序,假设小端)
uint32_t net_ip = htonl(host_ip); // 转换为网络字节序在以后客户端服务端的实现中,大家会更熟悉,在这里仅见识一下即可!
📚四、总结
本篇博客依然是介绍一些计算机网络中的一些基础知识,小结一下:
端口号:用来标识一台主机上进程的唯一性(与IP地址协同来标识全世界一台主机一个进程的唯一性)
UDP协议:不可靠、无连接、面向数据报、传输层协议
TCP协议:可靠、有连接、面向字节流、传输层协议
网络字节序: **大端字节序,**为了统一不同计算机体系的信息传输
