介绍
SpringBoot 项目中,文件上传存在默认大小限制:默认单个上传文件最大限制为 1MB,单次整体请求数据最大限制为 10MB。当上传文件体积超出 1MB,或单次请求传输总数据超过 10MB 时,程序会直接抛出文件大小超限异常,请求中断并上传失败。对于大文件直接上传的场景,若采用整体一次性传输的方式,文件体积过大会大量占用服务器内存,极易造成内存溢出、服务卡顿、响应超时等问题。
分片流程
前端切片
前端将超大文件按照固定大小(如 5MB)进行二进制切割,分割为多个独立文件分片;同时生成文件唯一标识、分片序号、总分片数、分片 MD5等参数,逐个向后端提交分片数据。
后端分片接收
SpringBoot 后端接收每一个分片,绕过单文件大小限制,单次只处理小块数据,避免一次性读取完整大文件,大幅降低服务器内存占用,防止 OOM 内存溢出、请求超时问题。
分片临时存储
后端将接收的每个分片,以临时文件形式单独缓存至本地 / 分布式存储,并记录分片上传状态,标记已上传、未上传分片,支持断点续传。
分片校验与去重
通过文件 MD5、分片序号校验数据完整性,重复分片自动过滤,避免重复上传,提升传输性能。
文件合并合成
当前端所有分片全部上传完成后,发送合并请求;后端按照分片序号顺序,读取所有临时分片,依次拼接合并为完整源文件,最终删除临时分片文件,完成大文件上传。
配置文件
yml
file:
# 分片文件配置
chunk:
# 分片临时存储目录
path: ${FILE_CHUNK_PATH:${user.dir}/upload/chunk}
save:
# 合并后最终文件存储目录
path: ${FILE_SAVE_PATH:${user.dir}/upload/file}控制器
获取当前文件是否有分片(断点续传):/file/checkFile
前端切片上传分片文件(上传分片):/file/mergeFile (循环N次)
合并文件(合并切片):/file/checkFile
java
/**
* 文件上传控制器、断点续传
*/
@RestController
@RequestMapping("/file")
@RequiredArgsConstructor
public class FileUploadController {
/**
* 文件上传业务处理类
*/
private final FileUploadService fileUploadService;
/**
* 上传单个文件分片
* 前端将大文件切割后,循环调用该接口上传每一个分片
* @param uploadDTO 分片上传参数(文件MD5、分片序号、分片文件、总分片数等)
* @return 上传结果
*/
@PostMapping("/uploadChunk")
public R<Void> uploadChunk(ChunkUploadDTO uploadDTO) {
fileUploadService.uploadChunk(uploadDTO);
return R.ok();
}
/**
* 合并所有分片
* 后端合并分片为完整文件
* @param mergeDTO 合并参数(文件MD5、文件名、总分片数等)
* @return 合并结果
*/
@PostMapping("/mergeFile")
public R<Void> mergeFile(@RequestBody FileMergeDTO mergeDTO) {
fileUploadService.mergeFile(mergeDTO);
return R.ok();
}
/**
* 检查已上传的分片列表
* 上传前先调用该接口,获取已上传的分片序号,前端只需要上传缺失的分片
* @param fileMd5 完整文件的MD5值(唯一标识)
* @return 已上传分片的序号集合
*/
@GetMapping("/checkFile")
public R<List<Integer>> checkFile(@RequestParam String fileMd5) {
List<Integer> list = fileUploadService.checkFile(fileMd5);
return R.ok(list);
}
}实体类
分片上传
java
/**
* 分片上传参数
*/
@Data
public class ChunkUploadDTO {
/**
* 原始完整文件MD5
*/
private String fileMd5;
/**
* 当前分片MD5
*/
private String chunkMd5;
/**
* 当前分片序号
*/
private Integer chunkNumber;
/**
* 总分片数
*/
private Integer totalChunks;
/**
* 分片文件流
*/
private MultipartFile file;
}文件合并
java
/**
* 文件合并参数接收 DTO
*/
@Data
public class FileMergeDTO {
/**
* 文件唯一MD5
*/
private String fileMd5;
/**
* 原始文件名
*/
private String fileName;
/**
* 总分片数
*/
private Integer totalChunks;
}接口
java
public interface FileUploadService {
/**
* 上传分片
*/
void uploadChunk(ChunkUploadDTO dto);
/**
* 合并文件
*/
void mergeFile(FileMergeDTO dto);
/**
* 检查已上传分片、断点续传
*/
List<Integer> checkFile(String fileMd5);
}实现类
java
import cn.hutool.core.io.FileUtil;
import cn.hutool.crypto.digest.DigestAlgorithm;
import cn.hutool.crypto.digest.Digester;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.springframework.web.multipart.MultipartFile;
import javax.annotation.PostConstruct;
import java.io.*;
import java.nio.channels.FileChannel;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
@Service
@Slf4j
public class FileUploadServiceImpl implements FileUploadService {
// 分片存储路径
@Value("${file.chunk.path}")
private String chunkPath;
// 合并后文件存储路径
@Value("${file.save.path}")
private String savePath;
/**
* 上传单个分片
*/
@Override
public void uploadChunk(ChunkUploadDTO dto) {
MultipartFile file = dto.getFile();
String fileMd5 = dto.getFileMd5();
String chunkMd5 = dto.getChunkMd5();
Integer chunkNumber = dto.getChunkNumber();
log.info("【上传开始】文件MD5:{},分片号:{}", fileMd5, chunkNumber);
log.info("【分片MD5】前端:{}", chunkMd5);
try {
File chunkRootDir = new File(chunkPath).getCanonicalFile();
File chunkDir = new File(chunkRootDir, fileMd5).getCanonicalFile();
// 路径安全校验
if (!chunkDir.getCanonicalPath().startsWith(chunkRootDir.getCanonicalPath() + File.separator)) {
throw new SecurityException("非法路径,禁止访问");
}
// 服务端计算分片MD5
String serverChunkMd5 = getStreamMd5(file);
log.info("【MD5校验】服务端:{}", serverChunkMd5);
// MD5不一致说明传输损坏
if (!chunkMd5.equals(serverChunkMd5)) {
throw new RuntimeException("分片MD5校验失败");
}
// 分片文件名:序号_分片MD5.tmp
String chunkFileName = chunkNumber + "_" + serverChunkMd5 + ".tmp";
File chunkFile = new File(chunkDir, chunkFileName).getCanonicalFile();
// 已存在则跳过、断点续传
if (chunkFile.exists()) {
log.info("【跳过】分片已存在:{}", chunkNumber);
return;
}
// 创建目录并写入文件
FileUtil.mkdir(chunkDir);
try (InputStream in = file.getInputStream()) {
FileUtil.writeFromStream(in, chunkFile, false);
}
log.info("【上传成功】分片:{}", chunkNumber);
} catch (Exception e) {
log.error("【上传失败】分片:{}", chunkNumber, e);
throw new RuntimeException("分片上传失败:" + e.getMessage());
}
}
/**
* 合并所有分片成完整文件(零拷贝高效合并)
* 这里是有BUG的,如果用户上传的文件名一样会导致文件被覆盖。
* 正确的做法是文件名使用UUID来生成,数据库存这个UUID和文件名。
*/
@Override
public void mergeFile(FileMergeDTO dto) {
String fileMd5 = dto.getFileMd5();
String fileName = dto.getFileName();
Integer totalChunks = dto.getTotalChunks();
try {
File chunkRootDir = new File(chunkPath).getCanonicalFile();
File chunkDir = new File(chunkRootDir, fileMd5).getCanonicalFile();
File saveRootDir = new File(savePath).getCanonicalFile();
// 路径安全校验
if (!chunkDir.getCanonicalPath().startsWith(chunkRootDir.getCanonicalPath() + File.separator)) {
throw new SecurityException("非法路径");
}
// 安全文件名,防止路径穿越
String safeFileName = new File(fileName).getName();
File targetFile = new File(saveRootDir, safeFileName).getCanonicalFile();
// 检查分片是否齐全
File[] allChunks = chunkDir.listFiles();
if (!chunkDir.exists() || allChunks == null || allChunks.length != totalChunks) {
throw new RuntimeException("分片不完整,无法合并");
}
// 按序号排序分片
File[] sortedChunks = new File[totalChunks];
for (File chunkFile : allChunks) {
String name = chunkFile.getName();
int index = Integer.parseInt(name.substring(0, name.indexOf('_')));
if (index >= 0 && index < totalChunks) {
sortedChunks[index] = chunkFile;
}
}
// 检查是否缺失分片
for (int i = 0; i < totalChunks; i++) {
if (sortedChunks[i] == null) {
throw new RuntimeException("缺失分片:" + i);
}
}
// 合并
FileUtil.mkdir(saveRootDir);
try (FileChannel outChannel = new FileOutputStream(targetFile).getChannel()) {
for (File chunkFile : sortedChunks) {
try (FileChannel inChannel = new FileInputStream(chunkFile).getChannel()) {
inChannel.transferTo(0, inChannel.size(), outChannel);
}
}
}
// 合并完成删除分片
FileUtil.del(chunkDir);
String finalMd5 = getStreamMd5(targetFile);
log.info("【合并完成】文件MD5:{},文件名:{}", finalMd5, fileName);
} catch (Exception e) {
log.error("【合并失败】", e);
throw new RuntimeException("文件合并失败:" + e.getMessage());
}
}
/**
* 查询已上传分片列表
*/
@Override
public List<Integer> checkFile(String fileMd5) {
List<Integer> uploadedChunkList = new ArrayList<>();
try {
File chunkRootDir = new File(chunkPath).getCanonicalFile();
File dir = new File(chunkRootDir, fileMd5).getCanonicalFile();
// 安全校验
if (!dir.getCanonicalPath().startsWith(chunkRootDir.getCanonicalPath() + File.separator)) {
return uploadedChunkList;
}
File[] files = dir.listFiles();
if (files == null || files.length == 0) {
return uploadedChunkList;
}
// 解析文件名获取分片号
for (File file : files) {
String fileName = file.getName();
int underLineIndex = fileName.indexOf('_');
if (underLineIndex > 0) {
String indexStr = fileName.substring(0, underLineIndex);
uploadedChunkList.add(Integer.parseInt(indexStr));
}
}
} catch (Exception e) {
log.error("检查分片异常", e);
}
// 排序后返回
Collections.sort(uploadedChunkList);
return uploadedChunkList;
}
/**
* 通用MD5计算
*/
private String calcMd5(InputStream inputStream) {
Digester md5 = new Digester(DigestAlgorithm.MD5);
return md5.digestHex(inputStream);
}
/**
* 计算上传分片的MD5
*/
private String getStreamMd5(MultipartFile file) {
try (InputStream in = file.getInputStream()) {
return calcMd5(in);
} catch (IOException e) {
throw new RuntimeException("分片MD5计算失败");
}
}
/**
* 计算合并后文件的MD5
*/
private String getStreamMd5(File file) {
try (InputStream in = new FileInputStream(file)) {
return calcMd5(in);
} catch (IOException e) {
throw new RuntimeException("文件MD5计算失败");
}
}
/**
* 项目启动时自动创建存储目录
*/
@PostConstruct
public void initDir() {
try {
File chunkRoot = new File(chunkPath).getCanonicalFile();
File saveRoot = new File(savePath).getCanonicalFile();
if (!chunkRoot.exists()) {
log.info("创建分片目录:{}", chunkRoot.mkdirs());
}
if (!saveRoot.exists()) {
log.info("创建文件目录:{}", saveRoot.mkdirs());
}
} catch (IOException e) {
log.error("目录初始化异常", e);
}
}
}前端DEMO
简单demo表明逻辑关系。
javascript
<template>
<el-card style="width: 600px; margin: 30px auto">
<template #header>
<div class="card-header">大文件分片上传</div>
</template>
<!-- 上传组件:关闭自动上传、不显示文件列表 -->
<el-upload
ref="uploadRef"
:auto-upload="false"
:show-file-list="false"
@change="handleFileChange"
>
<el-button type="primary">选择文件</el-button>
</el-upload>
<el-divider />
<!-- 显示已选择的文件名称 -->
<el-alert
v-if="fileObj"
:title="`已选择:${fileObj.name}`"
type="info"
closable
style="margin-bottom: 15px"
/>
<!-- 开始上传按钮 -->
<el-button
type="success"
@click="startUpload"
:loading="loading"
:disabled="!fileObj"
>
开始上传
</el-button>
<el-divider />
<!-- MD5 计算进度条 -->
<div v-if="md5Loading">
<p>MD5 计算进度:{{ md5Progress }}%</p>
<el-progress :percentage="md5Progress" :stroke-width="8" />
</div>
<!-- 分片上传进度条 -->
<div v-if="uploadLoading">
<p>上传进度:{{ progress }}%</p>
<el-progress :percentage="progress" :stroke-width="8" />
</div>
<!-- 状态提示:上传中/成功/失败 -->
<el-tag v-if="status" style="margin-top: 15px" :type="statusType">
{{ status }}
</el-tag>
</el-card>
</template>
<script setup>
import { ref } from 'vue'
import axios from 'axios'
import SparkMD5 from 'spark-md5'
// 分片大小:5MB
const CHUNK_SIZE = 5 * 1024 * 1024
// 计算MD5的分片大小:10MB
const MD5_CHUNK_SIZE = 10 * 1024 * 1024
// 后端接口地址
const API = {
check: '/file/checkFile', // 检查已上传分片
chunk: '/file/uploadChunk', // 上传单个分片
merge: '/file/mergeFile' // 合并分片
}
// 页面状态变量
const uploadRef = ref(null) // 上传组件引用
const fileObj = ref(null) // 选中的文件
const loading = ref(false) // 全局加载状态
const progress = ref(0) // 上传进度
const status = ref('') // 状态文字
const statusType = ref('') // 状态标签类型
const md5Progress = ref(0) // MD5计算进度
const md5Loading = ref(false) // MD5计算中
const uploadLoading = ref(false) // 上传中
// 选择文件后触发
const handleFileChange = (file) => {
fileObj.value = file.raw
progress.value = 0
md5Progress.value = 0
status.value = ''
}
// 计算整个文件的MD5(带进度条)
const getMd5WithProgress = (file) => {
return new Promise((resolve, reject) => {
md5Loading.value = true
md5Progress.value = 0
// 兼容不同浏览器的文件切片
const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice
// 总切片数
const totalChunks = Math.ceil(file.size / MD5_CHUNK_SIZE)
let currentChunk = 0
const spark = new SparkMD5.ArrayBuffer()
const fileReader = new FileReader()
// 读取一片完成
fileReader.onload = (e) => {
spark.append(e.target.result)
currentChunk++
// 更新进度
md5Progress.value = Math.floor((currentChunk / totalChunks) * 100)
// 继续下一片
if (currentChunk < totalChunks) {
loadNextChunk()
} else {
md5Loading.value = false
// MD5计算完成
resolve(spark.end())
}
}
// 读取失败
fileReader.onerror = () => {
md5Loading.value = false
reject('MD5计算失败')
}
// 读取下一个分片
const loadNextChunk = () => {
const start = currentChunk * MD5_CHUNK_SIZE
const end = Math.min(start + MD5_CHUNK_SIZE, file.size)
fileReader.readAsArrayBuffer(blobSlice.call(file, start, end))
}
// 开始计算
loadNextChunk()
})
}
// 计算单个分片的MD5(简单版)
const getSimpleMd5 = (blob) => {
return new Promise(resolve => {
const reader = new FileReader()
reader.onload = e => resolve(SparkMD5.ArrayBuffer.hash(e.target.result))
reader.readAsArrayBuffer(blob)
})
}
// 开始上传(核心逻辑)
const startUpload = async () => {
if (!fileObj.value) return
try {
loading.value = true
status.value = '正在计算 MD5...'
statusType.value = 'info'
const file = fileObj.value
// 1. 计算整个文件唯一MD5
const fileMd5 = await getMd5WithProgress(file)
// 总分片数
const totalChunks = Math.ceil(file.size / CHUNK_SIZE)
// 2. 查询后端:已上传的分片列表(断点续传)
status.value = '检查已上传分片...'
const res = await axios.get(API.check, { params: { fileMd5 } })
// 已上传分片存入Set,方便判断
const uploadedChunks = new Set(res.data.data || [])
console.log('已上传分片:', uploadedChunks)
// 3. 开始上传分片
uploadLoading.value = true
status.value = '正在上传分片...'
let success = 0
for (let i = 0; i < totalChunks; i++) {
// 已上传 → 跳过
if (uploadedChunks.has(i)) {
console.log(`分片 ${i} 已存在,跳过`)
success++
progress.value = Math.floor((success / totalChunks) * 100)
continue
}
// 切割分片
const start = i * CHUNK_SIZE
const end = Math.min(start + CHUNK_SIZE, file.size)
const chunkBlob = file.slice(start, end)
// 计算分片MD5
const chunkMd5 = await getSimpleMd5(chunkBlob)
// 构造上传参数
const form = new FormData()
form.append('file', chunkBlob)
form.append('chunkNumber', i)
form.append('totalChunks', totalChunks)
form.append('fileMd5', fileMd5)
form.append('fileName', file.name)
form.append('chunkMd5', chunkMd5)
// 上传分片
await axios.post(API.chunk, form)
success++
progress.value = Math.floor((success / totalChunks) * 100)
}
// 4. 所有分片上传完成 → 通知后端合并
status.value = '正在合并文件...'
await axios.post(API.merge, {
fileMd5,
fileName: file.name,
totalChunks
})
// 上传完成
status.value = '上传成功!'
statusType.value = 'success'
} catch (err) {
console.error('上传失败:', err)
status.value = '上传失败:' + (err.message || '未知错误')
statusType.value = 'danger'
} finally {
loading.value = false
uploadLoading.value = false
}
}
</script>
<style scoped>
.card-header {
font-size: 16px;
font-weight: 600;
}
</style>上传示例
文件大小为:6GB 上传测试
1、前端切片,计算每一个分片的MD5
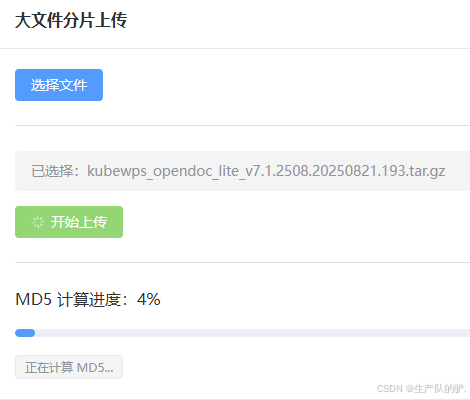
2、分片上传、断点续传
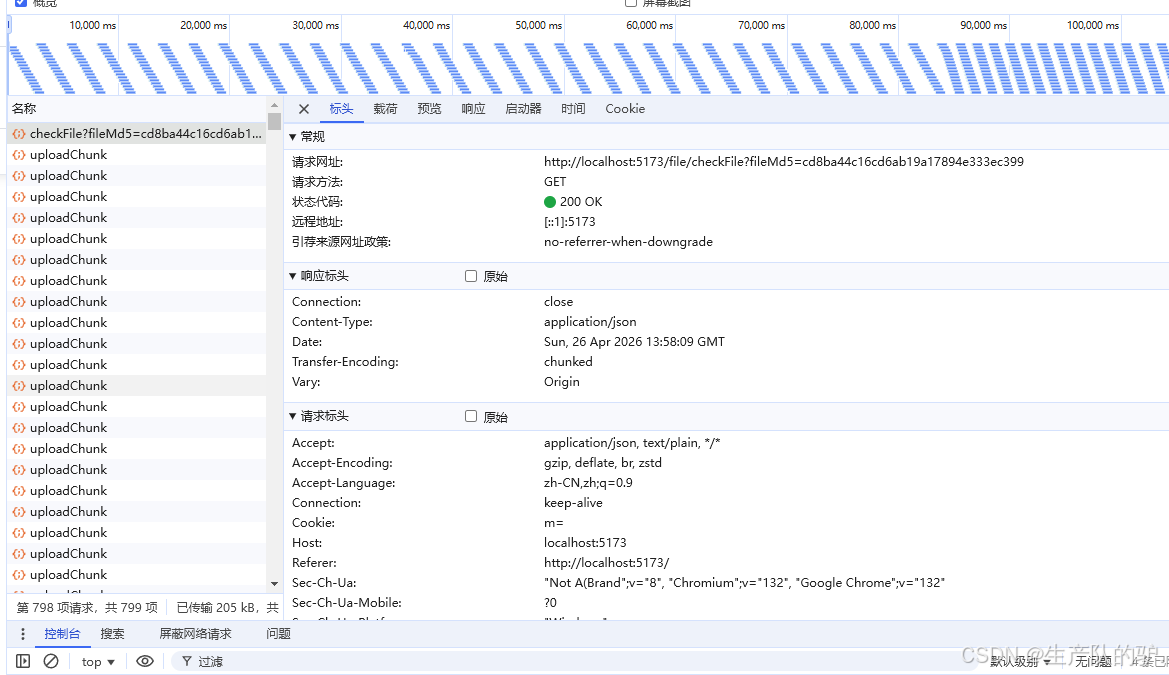
3、文件合并
切片文件
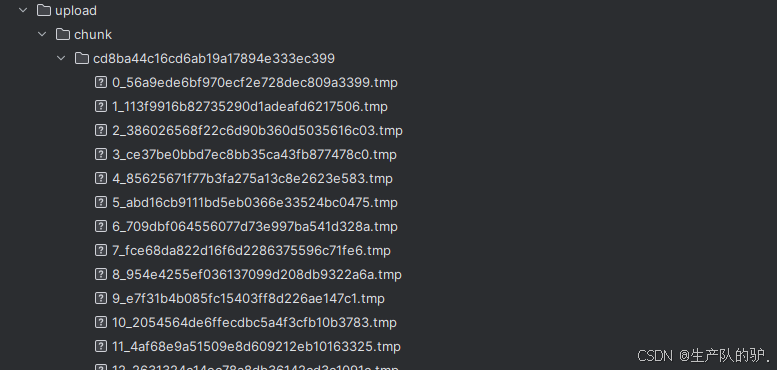
合并文件